数据结构学习——堆
堆的常用方法:堆属性数组实现树堆和普通树的区别 堆是一种经过排序的树形数据结构,每个节点都有一个值,通常我们所说的堆的数据结构是指堆是完全二叉树。所以堆在数据结构中通常可以被看做是一棵树的数组对象。而且堆需要满足一下两个性质:(1)堆中某个节点的值总是不大于或不小于其父节点的值;(2)堆总是一棵完全二叉树。堆分为两种情况,有最大堆和最小堆。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小
目录

概念
堆是一种经过排序的树形数据结构,每个节点都有一个值,通常我们所说的堆的数据结构是指堆是完全二叉树。所以堆在数据结构中通常可以被看做是一棵树的数组对象。而且堆需要满足一下两个性质:
(1)堆中某个节点的值总是不大于或不小于其父节点的值;
(2)堆总是一棵完全二叉树。
堆的常用方法:
- 构建优先队列
- 支持堆排序
- 快速找出一个集合中的最小值(或者最大值)
堆属性
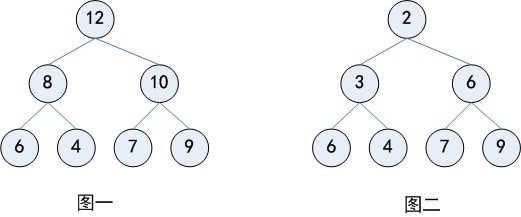
堆分为两种情况,有最大堆和最小堆。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。下图图一就是一个最大堆,图二就是一个最小堆。在一个摆放好元素的最小堆中,可以看到,父结点中的元素一定比子结点的元素要小,但对于左右结点的大小则没有规定谁大谁小。
堆常用来实现优先队列,堆的存取是随意的,这就如同我们在图书馆的书架上取书,虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书,书架这种机制不同于箱子,我们可以直接取出我们想要的书。
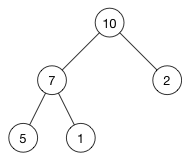
完全二叉树:对于一颗二叉树,假设其为深度为d(d>1)。除第d层外的所有节点构成满二叉树,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树;
例子:
注意:堆的根节点中存放的是最大或者最小元素,但是其他节点的排序顺序是未知的。例如,在一个最大堆中,最大的那一个元素总是位于 index 0 的位置,但是最小的元素则未必是最后一个元素。--唯一能够保证的是最小的元素是一个叶节点,但是不确定是哪一个。
最小堆
python里通常创建的是最小堆, 对于最小堆来说, 堆中索引位置0即heap[0]的值一定是堆中的最小值, 并且堆中的每个元素都符合公式heap[k] <= heap[k*2+1]和 heap[k] <= heap[k*2+2], 其中heap[k]是父节点, 而heap[k*2+1]和heap[k*2+2]是heap[k]的子节点, 父节点永远小于等于它自己的子节点, 这是不会改变的
最大堆
对于最大堆来说, 与最小堆相反, 堆中索引位置0即heap[0]的值是堆中最大值, 堆中每个元素都符合公式heap[k] >= heap[k*2+1] 和heap[k] >= heap[k*2+2], 父节点永远大于它的子节点, 这一点不会改变
二叉树
堆是一个二叉树,从图中可以明白父节点heap[k]分出左右两个叉分别是heap[k*2+1]和heap[k*2+2]
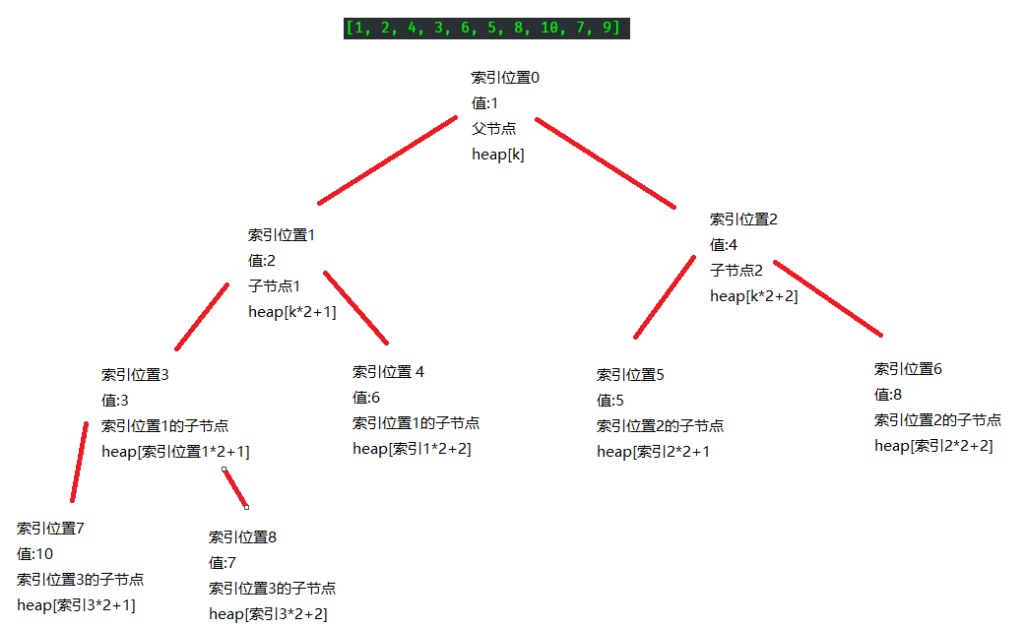
堆[1, 2, 4, 3, 6, 5, 8, 10, 7, 9], 如图, 最顶层的父节点索引位置0的值永远是堆中的最小值
数组实现树
用数组来实现树相关的数据结构也许看起来有点古怪,但是它在时间和空间上都是很高效的。
我们准备将上面例子中的树这样存储:
[ 10, 7, 2, 5, 1 ]
堆和普通树的区别
堆并不能取代二叉搜索树,它们之间有相似之处也有一些不同。我们来看一下两者的主要差别:
节点的顺序
在二叉搜索树中,左子节点必须比父节点小,右子节点必须必比父节点大。但是在堆中并非如此。在最大堆中两个子节点都必须比父节点小,而在最小堆中,它们都必须比父节点大。
内存占用
普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配内存。堆仅仅使用一个数据来存储数组,且不使用指针。
平衡
二叉搜索树必须是“平衡”的情况下,其大部分操作的复杂度才能达到O(log n)。你可以按任意顺序位置插入/删除数据,或者使用 AVL 树或者红黑树,但是在堆中实际上不需要整棵树都是有序的。我们只需要满足堆属性即可,所以在堆中平衡不是问题。因为堆中数据的组织方式可以保证O(log n) 的性能。
搜索
在二叉树中搜索会很快,但是在堆中搜索会很慢。在堆中搜索不是第一优先级,因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作。
二叉查找树(二叉搜索树、二叉排序树、BST):
若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
任意节点的左、右子树也分别为二叉查找树;
没有键值相等的节点。
python heapq.heappush()
heappush()的参数
heapq.heappush(heap, item)有两个位置参数: heap 和 item , heap是堆的意思, item是要被压入到heap中的对象, 如果item无法通过小于号< 与heap中的各个元素进行比较, 那么就会报错
import heapq
heap = [1, 2, 3]
heapq.heappush(heap, 4)
结果:
此时heap变成了 [1, 2, 3, 4]第一个位置参数heap
- heap的数据类型只能是一个列表, 如 heap = []
- heap中的元素如果符合heap[k]<=heap[k*2+1]和heap[k]<=heap[k*2+2], 那么这个heap就是一个堆, 或者说heap符合堆特性(heap property), 也可以说heap维持了堆的不变性(heap invariant.)
- 如果heap不符合堆的特性, 可以将heap传入heapq.heapify()进行堆化, 但前提是heap中的各个元素都可以使用小于号<进行比较运算,否则会报错, 字典类型是无法使用小于号进行比较运算的, 在heap中两个数据类型不同的元素也无法使用小于号进行比较运算,比如把整型值3和字符串’5’进行比较(3<‘5’)就会报错, 所以heap中元素的数据类型要相一致, 比如都是整型或者都是字符串型时,heapq.heapify()才能通过小于号比较heap中各个元素值以调整元素在heap中的顺序从而让其符合堆特性
第二个位置参数item
item的数据类型必须与heap中元素的数据类型相一致(item和heap中的元素的数据类型都不能是字典, 因为字典无法通过小于号进行比较运算.)比如heap中的元素都是整型值如[1, 2, 3], 那么使用heapq.heappush()压入到heap中必须是一个整型值(int类型), 比如heapq.heappush(heap, 8), 如果item不是整型值会报错, 比如heapq.heappush(heap, ‘8’) 会报错'<‘ not supported between instances of ‘str’ and ‘int’ 因为heappush需要使用小于号来比较插入到heap中的item和heap中原有元素的大小来调整heap中元素的顺序以满足堆特性(heap[k]<=heap[k*2+1]和heap[k]<=heap[k*2+2])
堆化
heapq.heapify()
如果一个列表中的所有元素数据类型相同并且各元素可以使用小于号进行比较运算, 那么这个列表就可以使用heapq.heapify()进行堆化
验证堆特性
只要列表中的所有元素都符合heap[k] <= heap[k * 2 + 1] 和 heap[k] <= heap[k * 2 + 2]即可, 父节点可以没有子节点, 如果没有子节点会报错IndexError, 所以需要处理异常
def check_heap(heap):
for k in range(len(heap)):
try:
if heap[k] <= heap[k * 2 + 1] and heap[k] <= heap[k * 2 + 2]:
print("符合 ", end="")
else:
print("不符合 ", end="")
print('父节点索引位置' + str(k) + "小于等于", '子节点索引位置' + str(k * 2 + 1), '子节点索引位置' + str(k * 2 + 2))
except IndexError:
passheapq.heappush()维持堆的不变性
如果一个列表本身不符合堆(python里是最小堆)的特性, 比如heap = [7, 1, 8], 即使通过heap.heappush(heap, 4) 将整型值4压入heap, 这个heap最后也不会符合堆的特性. 如果一个列表本身就符合堆的特性或者个列表中的元素的个数小于等于1, 那么使用heapq.heappush()将值压入到这个列表后, 这个列表还是会符合堆的特性,维持了堆的不变性
import heapq
import random
heap = [10000, 100001, 100002]
for i in range(4):
# 从0到1000之间随机调出一个整型值压入heap中
heapq.heappush(heap, random.choice(range(1000)))
# 使用上面的函数验证一下是否符合堆的特性
check_heap(heap)
print(heap)
结果:
符合 父节点索引位置0小于等于 子节点索引位置1 子节点索引位置2
符合 父节点索引位置1小于等于 子节点索引位置3 子节点索引位置4
符合 父节点索引位置2小于等于 子节点索引位置5 子节点索引位置6
[333, 926, 511, 100001, 10000, 100002, 909]升序的列表都符合堆的特性
如果一个列表中的元素数据类型一致(不包括字典), 并且使用升序排序, 那么这个列表就符合堆的特性, 比如 [0, 1, 2, 3], 因为一个升序列表意味着从小达到排列元素, 索引位置0的值一定是列表中的最小值,可以使用check_heap()验证.
如果一个列表可以使用列表的sort()方法排序(sort()方法在排序时也是需要使用小于号来比较各个元素的值), 排序后的列表也一定符合堆的特性,
heappush()的返回值
heapq.heappush()的返回值是None 也就是说没有返回值
最后,今天对堆的基础分享就到这里啦,我也是刚刚接触堆这个概念,也还有很多不懂的地方,如果有写的不对的地方,希望大家能积极指正!!!希望和大家一起学习一起进步!!!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)