PowerJob--server端和worker端启动流程、以及通信分析
比如server端部署了两台,worker这样配置server地址:192.168.2.1:7700,192.168.2.2:7700,假设第一个节点永远正常,因为worker启动的时候,都是从第一个节点开始请求的,那么就会导致所有应用的currentServer的值都是第一个服务的ActorSystem的地址。worker刚启动的时候,也不知道server的哪个节点是正常的,所以,会从配置的第一
概要
server端负责对执行器进行调度。worker端负责执行具体的任务。它们启动之初都会做一些前置工作,方便后面进行通信。
整体架构流程
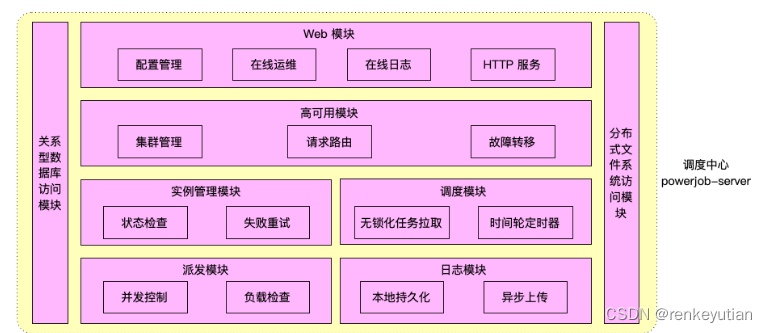
技术细节
server启动之初,会调用AkkaStarter.init()和VertxStarter.init()。这两个方法分别对akka和Vertx进行了初始化配置,方便后面的通信。(akka和Vertx这两个技术,说实话还是比较生僻的,我平时基本没怎么用过。边看源码,边查资料,然后写一写demo,大致也就知道怎么用了。感受是,确实比较轻量级,相互通信实现起来确实简单。这里需要说一下,akka有很多个模块,这里主要使用的是akka-remoting模块。)这些都是一些固定的写法,没什么可说的。
worker端启动的时候,事情稍微复杂一些,我们一点点分析。它首先会执行PowerJobWork.init()。它里面做了这么几件事:
1、检测当前worker是否已经注册;
2、和server建立通信;
3、初始化akka服务;
4、初始化本地H2数据库的一些配置;
5、进行心跳更新和日志上报。
下面一一进行分析:
1、为什么进行worker名称的检测?目的是检测当前worker是否注册。PowerJob要求所有的worker都必须先进行注册之后才能使用。这个很好理解,不注册,Server端也不知道和哪些worker进行通信是吧?所以,你会发现,点开Server端的控制页面时,首先就是让你注册一个应用。这个应用的名称,就是要接入的业务方服务的名称。有多少个,就注册多少个。然后,登进去之后,就是可以看到这个应用所有的信息,可以配置任务,启动/停止任务等。这里稍微吐槽一下,PowerJob的控制页面,没有一个类似全局的视图页。如果有N多个应用,想要查看每个应用的任务执行情况,得登录很多次,一个一个页面查看。这就很不友好了。
2、一般Server端会进行高可用部署,那么worker会选择其中一个server节点,和它进行通信。源码中把这叫做服务发现。通过定时去请求server的一个接口,来判断server是否存活。

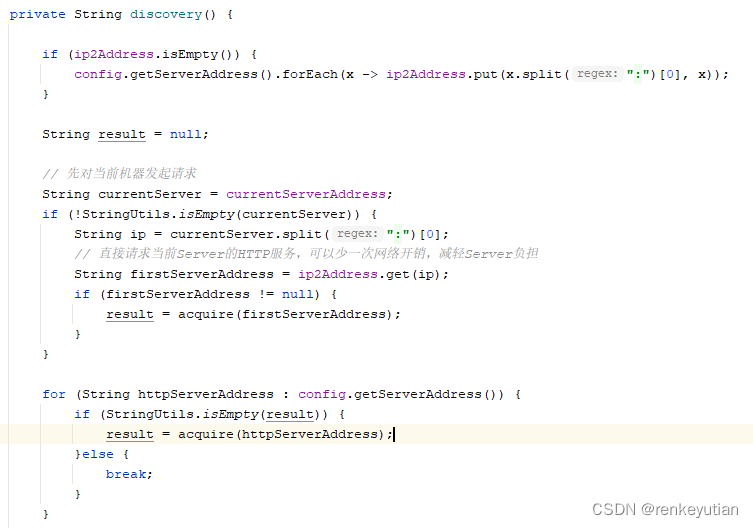 worker刚启动的时候,也不知道server的哪个节点是正常的,所以,会从配置的第一个server的地址开始试,如果发现了一个正常的节点,后面就不会再尝试了。所以,由此可以判断acquire方法就是和server的一次http通信:
worker刚启动的时候,也不知道server的哪个节点是正常的,所以,会从配置的第一个server的地址开始试,如果发现了一个正常的节点,后面就不会再尝试了。所以,由此可以判断acquire方法就是和server的一次http通信: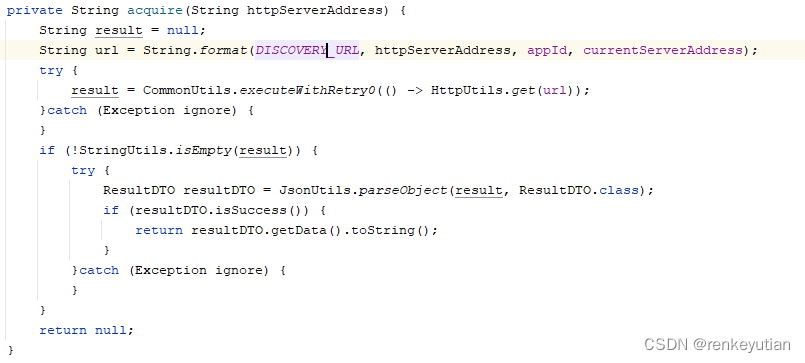
 很明显,请求了server端/server/acquire这个接口。那就到服务端看一下这个接口:
很明显,请求了server端/server/acquire这个接口。那就到服务端看一下这个接口:
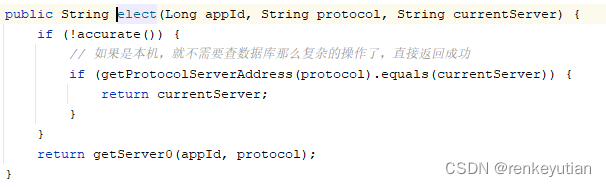
下面是getServer0方法的逻辑:
这里面涉及的逻辑比较复杂,我们一点一点分析:
首先,根据传入的应用ID,也就是appId,查询这个应用的注册信息。前面我们分析过,每个应用要使用PowerJob的定时任务能力,得先进行注册。注册之后就有了这个应用ID。看一下注册表中的数据:
这是PowerJob中自带的一个例子。刚开始注册之后,表中的current_server字段是没值的。后面会根据情况进行填充。
然后,先进行加锁,再次查询数据库,dubbo-check思想,防止别的线程已经给这个应用填充了currentServer的值。如果还是没有填充,就把自己akka的ActorSystem(就是服务端启动时候,初始化的那个akka服务。相当于akka的服务端地址)的地址填充进去,并且返回给应用端。
这个方法里面,还考虑了另外一个场景:如果填充的currentServer所属的服务在worker请求的瞬间,由于网络抖动,没有及时响应,或者干脆关掉了,那么worker端的请求会被另外一个server节点接收到。这个server查询数据库,发现这个应用有currentServer,然后需要判断这个currentServer所属的server节点是否正常,调用activeAddress方法: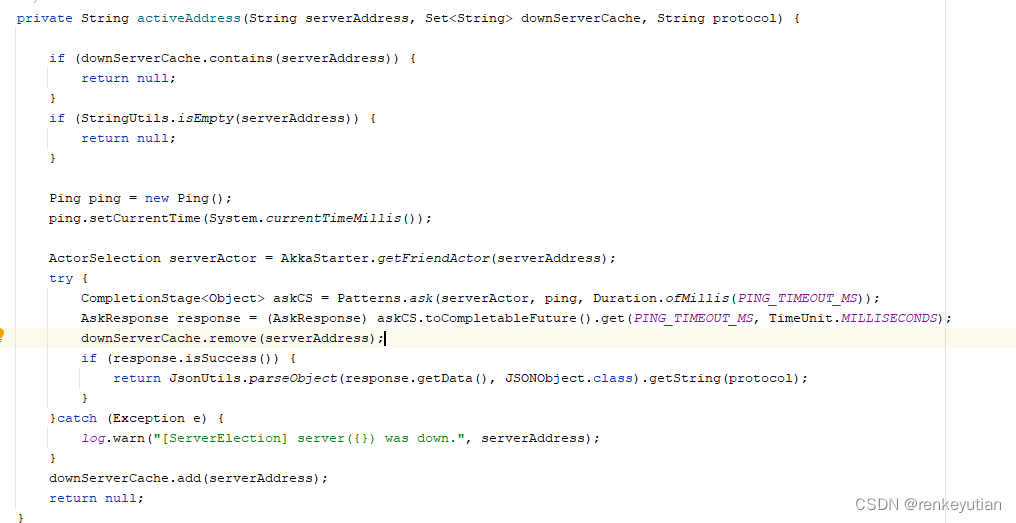
通过akka的通信方式,给currentServer所属的节点发一个ping,如果能得到正常响应,说明这个节点还没有挂,只是短暂的网络抖动,那么就直接返回给worker。如果没有得到响应,说明这个节点确实挂掉了,那么就需要重新填充一个server的akka服务的地址,并且返回给worker端新的currentServer地址,让它后面都和这个新currentServer通信。这样做的目的是,及时发现不可用的server,进行服务转移,实现server的高可用。
3、worker端这边也需要初始化一个ActorSystem,用于server端的调用。因为负责调度的是server端,但具体执行的逻辑是写在worker端的。当任务要执行的时候,server要找到对应的worker,让它执行具体的任务逻辑。PowerJob采用的是akka通信的方式。当然也可以采用http、netty等方式。
4、初始化了一个H2库,并且建了一个task_info表。具体是干嘛的,现在还没看到。但可以看到,有些数据是存在task_info表中,而且持久化到了文件中。这个做法还是挺新奇的。大致看一下:
后面看到具体逻辑,再具体分析。一般我对这种新奇的做法会格外留意,看是否能应用到自己的业务场景中。
5、主要看一下心跳检测的逻辑。![]() 通过一个定时任务,不停的上报自己的心跳,告诉server端自己还存活着。防止server端调度到已经下线的worker。
通过一个定时任务,不停的上报自己的心跳,告诉server端自己还存活着。防止server端调度到已经下线的worker。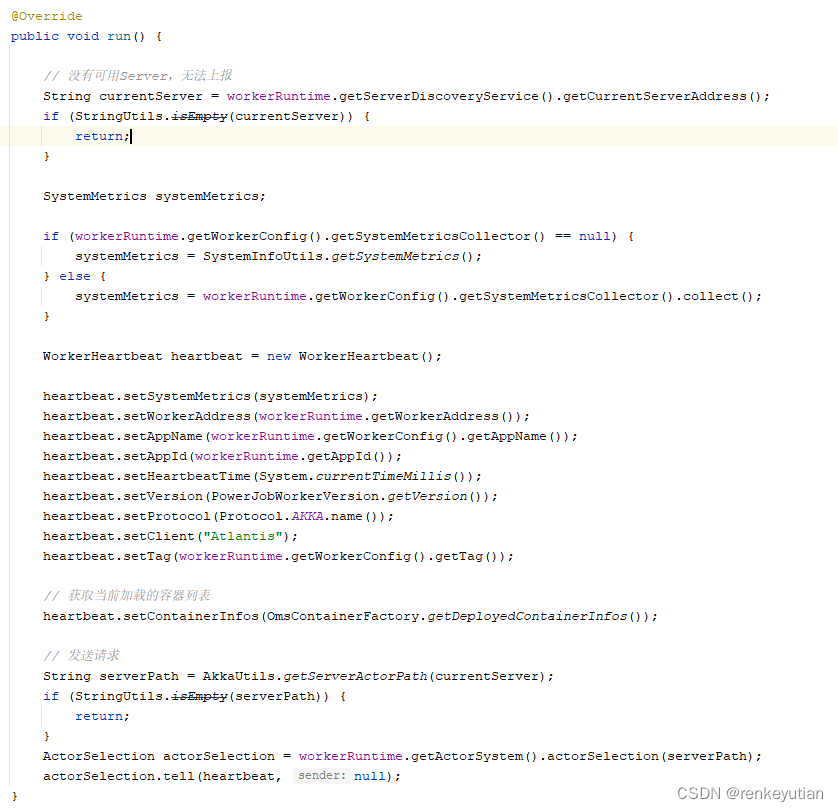 这里的currentServer就是服务发现的时候,server端返回的那个。这里构建了一个心跳包,然后通过akka通信,把这个包发给需要通信的这个服务。具体是服务端名称为server_actor的subActor进行处理。看一下服务端具体的代码:
这里的currentServer就是服务发现的时候,server端返回的那个。这里构建了一个心跳包,然后通过akka通信,把这个包发给需要通信的这个服务。具体是服务端名称为server_actor的subActor进行处理。看一下服务端具体的代码:
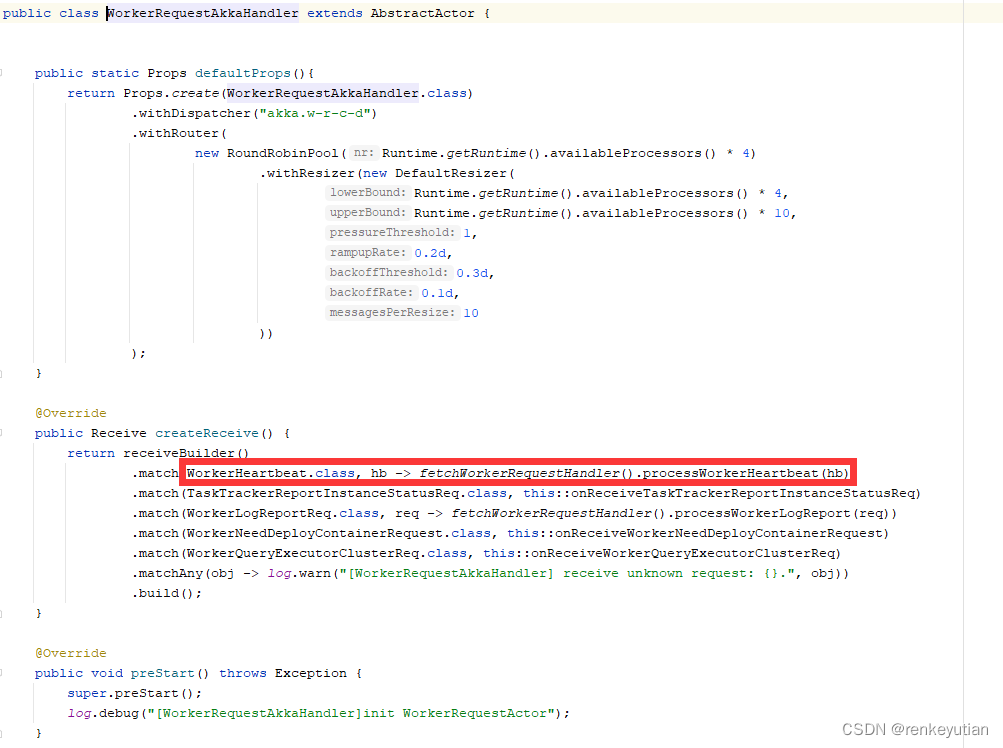
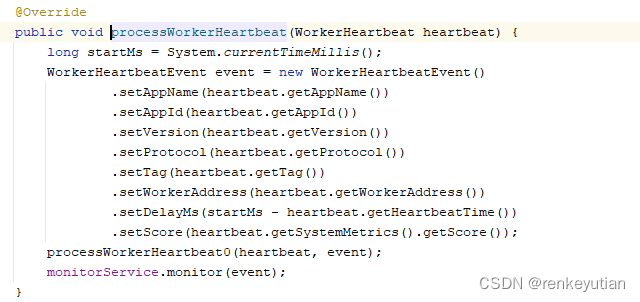 一步一步一步跟,最后会走到这个逻辑:
一步一步一步跟,最后会走到这个逻辑: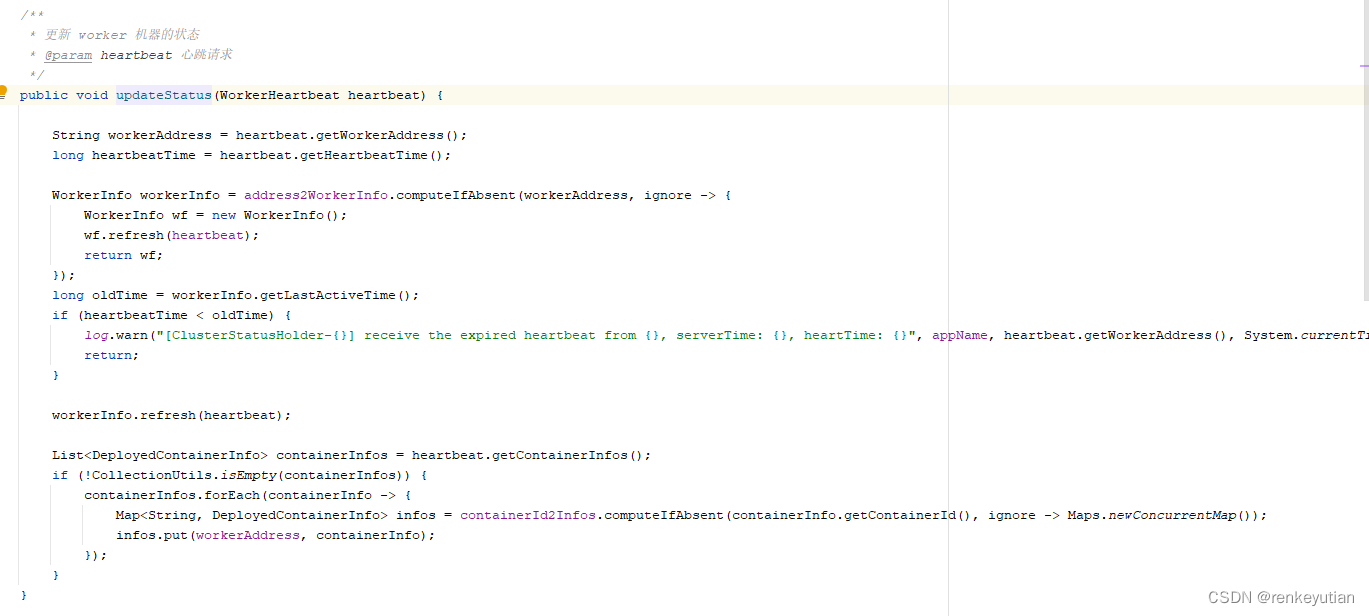
address2WorkerInfo的key是worker的ActorSystem的地址,value是workerInfo的信息。总是使用heartBeatTime的新值和旧值进行比较,如果大于,就表示worker是正常的,更新时间。如果小于,就打印一下日志,不做任何处理。什么情况下,会出现小于的情况?正常情况下,一定不会有这种情况,除非worker端把系统时间调小了。这里做这个判断,应该是健壮性做法。
这里并没有处理那些过期的worker。这里先提一下,具体的处理逻辑是在server分发任务的时候处理,后面会进行具体分析。
至此,server端、worker端的启动流程,以及它们之间的服务发现、心跳维持等逻辑基本就清楚了。这些前置的工作,保证了server的高可用,和正常调度的执行。
小结
服务发现那里的逻辑,其实有点小瑕疵。比如server端部署了两台,worker这样配置server地址:192.168.2.1:7700,192.168.2.2:7700,假设第一个节点永远正常,因为worker启动的时候,都是从第一个节点开始请求的,那么就会导致所有应用的currentServer的值都是第一个服务的ActorSystem的地址。而后面在进行调度的时候,其实是根据currentServer来进行分片的。那么第一个节点就会查询到所有应用的调度任务进行调度处理,导致的结果就是,第一个节点非常忙,而第二个节点压根没啥事。除非第一个节点挂了,才会将应用转移到第二个节点。官方文档给的解决方案是,不同应用配置不同的地址顺序,或者直接使用域名的方式进行负载均衡。虽然确实可以解决这个问题,但是不够优雅。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)