SPI学习(二):SPI工作机制与协议解析
写在前面,SPI工作机制无非就是想介绍SPI模块内置的移位寄存器,这一部分可以看下面博客,里面有时序图与动图,可以很方便理解移位https://blog.csdn.net/qq_25814297/article/details/103934794SPI协议部分重点向介绍CPOL和CPHA,这一部分可以看下面博客https://www.cnblogs.com/shangdawei/p/4752476
写在前面,SPI工作机制无非就是想介绍SPI模块内置的移位寄存器,这一部分可以看下面博客,里面有时序图与动图,可以很方便理解移位
https://blog.csdn.net/qq_25814297/article/details/103934794
SPI协议部分重点向介绍CPOL和CPHA,这一部分可以看下面博客
https://www.cnblogs.com/shangdawei/p/4752476.html
一.SPI工作机制
1.SPI内部原理图
SPI内部原理图如下图所示,这里参考《SPI Block Guide V04.01》,请注意标黄的部分

2.SPI移位寄存器
下图显示了单个主机和单个从机之间的典型SPI连接
实际上SPI的全双工传输,就是靠移位寄存器来完成的,通过8个时钟周期的移位,来达到交换主从数据的目的,也就是说:
在每个SPI时钟周期内,都会发生全双工数据传输。
主机在MOSI线上发送一位数据,从机读取它,而从机在MISO线上发送一位数据,主机读取它。
就算只进行单向的数据传输,也要保持这样的顺序。这就意味着无论接收任何数据,必须实际发送一些东西

二.SPI协议解析
1.SPI传输流程
整体的传输大概可以分为以下几个过程(需要注意的是SPI全双工的传输特性,主机的收发实际上是同时完成的,不是先后关系)
-
主机先将片选信号拉低,这样保证开始接收数据;
-
当接收端检测到时钟的边沿信号时,它将立即读取数据线上的信号,这样就得到了一位数据(1
bit); -
主机发送到从机时:主机产生相应的时钟信号,然后数据一位一位地将从
MOSI信号线上进行发送到从机; -
主机接收从机数据:如果从机需要将数据发送回主机,则主机将继续生成预定数量的时钟信号,并且从机会将数据通过
MISO信号线发送;
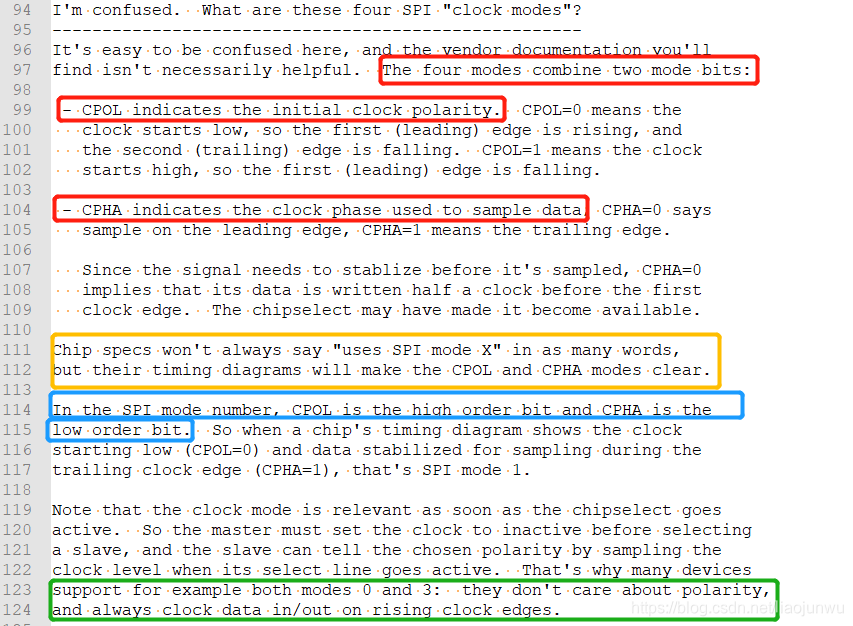
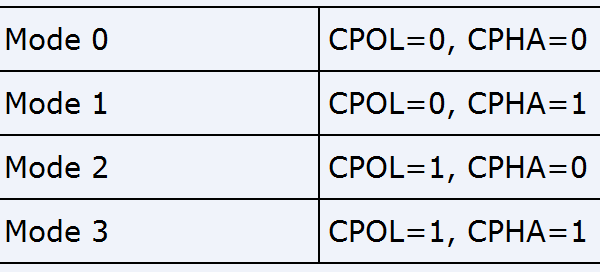
2.SPI时钟极性与相位
时钟极性与相位参考本文开头的博客就好了,这里将documentation/spi/spi-summary的内容贴一下
它说明了CPOL与CPHA是什么,说明了leading edge与trailing edge是什么,以及CPOL/CPHA如何组成4种模式
struct spi_device {
struct device dev;
struct spi_controller *controller;
struct spi_controller *master; /* compatibility layer */
u32 max_speed_hz;
u8 chip_select;
u8 bits_per_word;
u16 mode;
#define SPI_CPHA 0x01 /* clock phase */
#define SPI_CPOL 0x02 /* clock polarity */
#define SPI_MODE_0 (0|0) /* (original MicroWire) */
#define SPI_MODE_1 (0|SPI_CPHA)
#define SPI_MODE_2 (SPI_CPOL|0)
#define SPI_MODE_3 (SPI_CPOL|SPI_CPHA)
#define SPI_CS_HIGH 0x04 /* chipselect active high? */
#define SPI_LSB_FIRST 0x08 /* per-word bits-on-wire */
#define SPI_3WIRE 0x10 /* SI/SO signals shared */
#define SPI_LOOP 0x20 /* loopback mode */
#define SPI_NO_CS 0x40 /* 1 dev/bus, no chipselect */
#define SPI_READY 0x80 /* slave pulls low to pause */
#define SPI_TX_DUAL 0x100 /* transmit with 2 wires */
#define SPI_TX_QUAD 0x200 /* transmit with 4 wires */
#define SPI_RX_DUAL 0x400 /* receive with 2 wires */
#define SPI_RX_QUAD 0x800 /* receive with 4 wires */
int irq;
void *controller_state;
void *controller_data;
char modalias[SPI_NAME_SIZE];
int cs_gpio; /* chip select gpio */
/* the statistics */
struct spi_statistics statistics;
/*
* likely need more hooks for more protocol options affecting how
* the controller talks to each chip, like:
* - memory packing (12 bit samples into low bits, others zeroed)
* - priority
* - drop chipselect after each word
* - chipselect delays
* - ...
*/
};3.移位动图
在了解了上述知识后,结合移位寄存器的知识,可以看一下SPI整个工作的数据流程(是怎么移位的)
假设下面的8位寄存器装的是待发送的数据10101010,上升沿发送、下降沿接收、高位先发送。
那么第一个上升沿来的时候 数据将会是sdo=1;寄存器=0101010x。下降沿到来的时候,sdi上的电平将所存到寄存器中去,那么这时寄存器sdi=0101010,这样在 8个时钟脉冲以后,两个寄存器的内容互相交换一次。这样就完成里一个spi时序。
举例:
假设主机和从机初始化就绪:并且主机的sbuff=0xaa,从机的sbuff=0x55,下面将分步对spi的8个时钟周期的数据情况演示一遍:假设上升沿发送数据






有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)