Vue3.5 + SSE 构建高可用 AI 聊天交互层 ——`chat.js` 模块架构与实现
chat.js模块通过 “解析 - 传输 - 服务 - 业务”四层架构技术屏蔽:把 SSE 协议解析、流控逻辑封装成黑盒,业务层不用关心底层实现;工程化适配:解决环境切换、错误统一、资源释放等工程问题,提升模块稳定性;业务弹性:通过参数差异化适配不同 AI 对话场景,支持快速扩展新功能。这个架构不仅适用于豆包模型 API 封装,还能用到其他流式数据场景(比如实时日志、进度推送),为前端构建高可用、
🚀 技术深析:
在 AI 对话系统里,流式响应是影响用户体验的核心技术。这篇文章以封装豆包模型快速 / 深度思考 API 的chat.js模块为例子,从协议解析、流处理原理、架构设计到实际开发,全面拆解前端流式交互层的实现逻辑,为复杂 AI 应用的前端接口封装提供可复用的技术方案。
一、技术背景与模块定位
1.1 核心技术选型:为什么选 SSE?
AI 对话场景特别需要 “实时性” 和 “低延迟”,目前主流的流式方案各有特点:
| 方案 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| SSE(Server-Sent Events) | 单向实时数据推送(比如 AI 回复) | 有原生 API 支持、轻量无额外依赖、能自动重连 | 只能由服务端向客户端单向通信 |
| WebSocket | 双向实时通信(比如即时聊天) | 全双工通信、延迟低 | 协议复杂、要维护连接状态、服务器资源占用高 |
| 轮询 | 非高频更新场景 | 实现简单 | 延迟高、无效请求多、浪费资源 |
豆包模型的 “快速对话” 和 “深度思考” 都是服务端向客户端单向推送流式数据(AI 生成的内容一段段返回),SSE 的轻量性和原生支持特性让它成了最优选择。chat.js模块的核心目标,就是解决 SSE 流的 “解析 - 处理 - 分发 - 业务适配” 全流程问题。
1.2 模块核心职责
chat.js作为前端和豆包模型 API 之间的 “中间件”,主要负责三件事:
- 协议适配:把后端 SSE 协议格式(
data: {...})解析成前端能直接用的结构化数据; - 流控管理:处理流式数据的 “分片 / 粘包” 问题,让数据既完整又能实时更新;
- 业务封装:给 “快速对话”“深度思考” 两种模式提供统一的调用接口,不用关心底层技术细节。
二、架构设计:分层解耦与职责边界
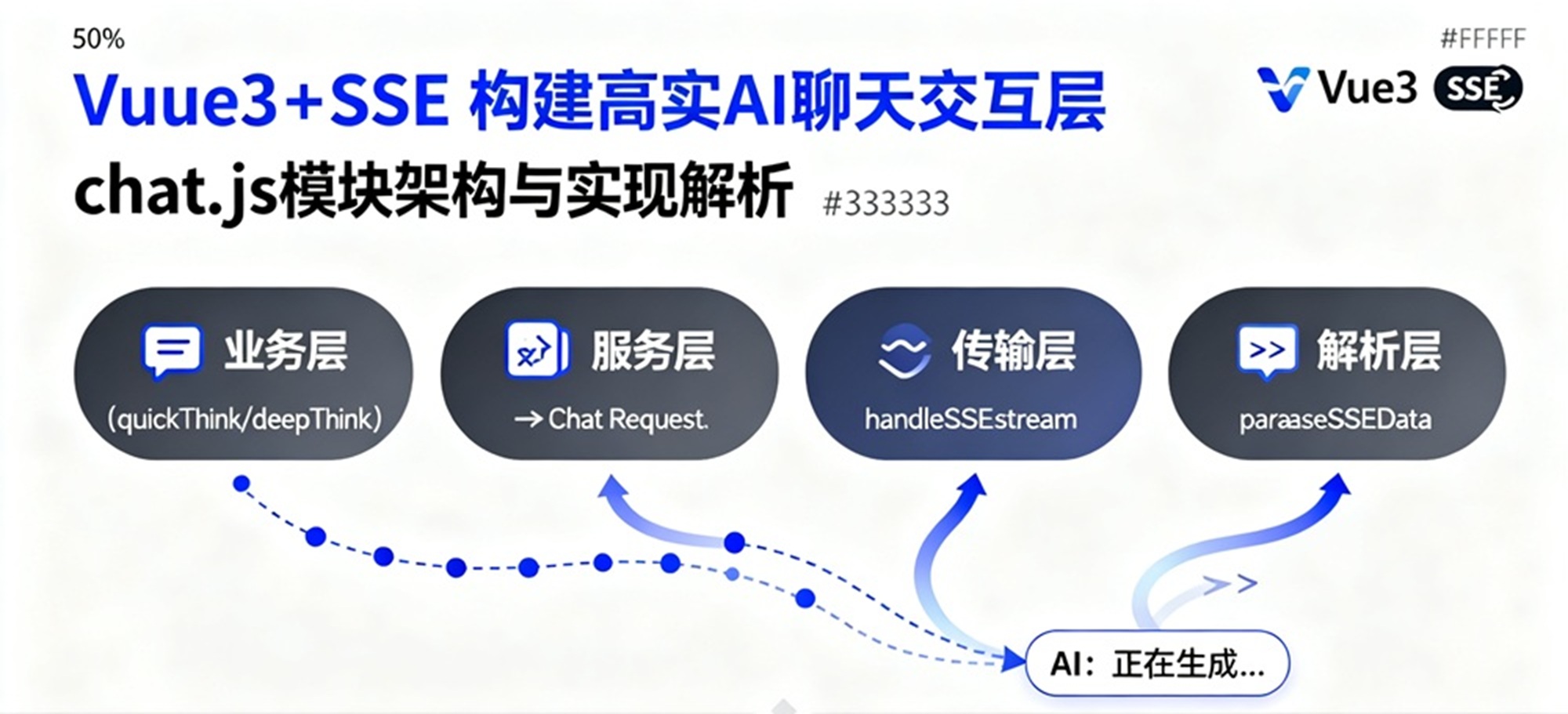
chat.js采用四层分层架构,严格遵循 “关注点分离” 原则,每层只负责自己领域的逻辑,通过明确的接口实现层间通信,降低模块之间的耦合度。
2.1 架构分层与数据流向
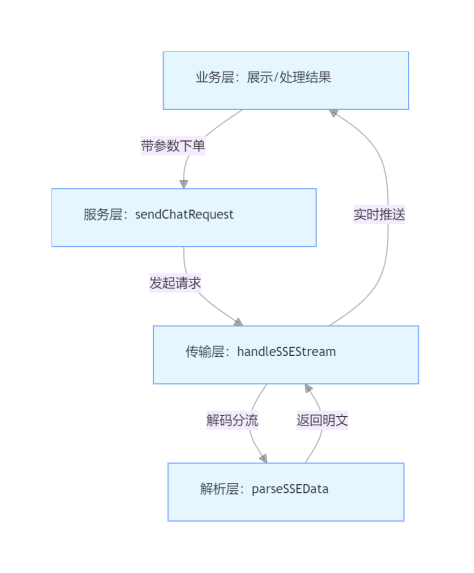
各层的核心职责和技术边界:
| 层级 | 核心函数 | 技术职责 | 输入输出规范 |
|---|---|---|---|
| 业务层 | quickThink、deepThink | 组装业务参数、适配不同场景 | 输入:{messages, session_id, onChunk};输出:无(通过回调分发结果) |
| 服务层 | sendChatRequest | 调度 HTTP 请求、统一处理错误 | 输入:endpoint、requestBody、onChunk;输出:Promise |
| 传输层 | handleSSEStream | 拉取 SSE 流、管理缓冲区、分发事件 | 输入:Response 对象、onChunk;输出:Promise |
| 解析层 | parseSSEData | 解析 SSE 协议、校验格式、捕获异常 | 输入:原始 SSE 字符串;输出:结构化对象({done?: boolean, data?: Object})或 null |
2.2 关键设计原则
- 依赖倒置:上层(业务层)不依赖下层的具体实现,只通过函数参数(比如
onChunk)定义通信接口,下层改了也不影响上层调用; - 单一职责:每个函数只解决一个领域的问题(比如
parseSSEData只做协议解析,不管流控制); - 错误边界:每层都有独立的错误捕获,通过统一回调(
onChunk)向上传递错误,避免错误冒泡导致全局崩溃。
三、核心功能深度解析
3.1 解析层:SSE 协议的精准解析(parseSSEData)
SSE 协议遵循 W3C 规范,核心格式是data: [JSON字符串]\n\n,还支持用[DONE]标记流结束。parseSSEData要处理三种情况:正常数据解析、流结束标记、格式异常。
3.1.1 核心实现逻辑
function parseSSEData(data) {
try {
// 1. 协议格式校验:只处理以"data: "开头的SSE规范数据
if (!data.startsWith('data: ')) return null;
// 2. 提取JSON字符串:截掉"data: "后面的内容并去除首尾空白
const jsonStr = data.slice(6).trim();
// 3. 流结束标记处理:后端约定用[DONE]表示响应完成
if (jsonStr === '[DONE]') return { done: true };
// 4. JSON解析:转成结构化数据(适配后端豆包模型的返回格式)
const parsedData = JSON.parse(jsonStr);
// 5. 数据格式校验:确保返回包含status(状态码)字段
return parsedData?.status !== undefined ? parsedData : null;
} catch (error) {
console.error('SSE协议解析异常:', { error, rawData: data });
return null; // 解析失败不阻断流处理,只忽略异常数据块
}
}
3.1.2 技术亮点
- 协议兼容性:既严格遵循 SSE 规范,又适配了后端豆包模型的自定义结束标记(
[DONE]); - 容错性设计:用
try-catch捕获 JSON 解析错误,避免单条异常数据导致整个流中断; - 数据过滤:只保留符合格式要求的数据(包含
status字段),减少上层的无效处理。
3.2 传输层:SSE 流的高效处理(handleSSEStream)
传输层是模块的技术核心,要解决二进制流解码、分片数据拼接、实时事件分发三个问题,基于浏览器原生ReadableStream API实现流拉取(pull-based)模式。
3.2.1 核心实现逻辑与原理
async function handleSSEStream(response, onChunk) {
// 1. 初始化流读取器与解码器
const reader = response.body.getReader(); // 基于ReadableStream的拉取式读取器
const decoder = new TextDecoder('utf-8'); // 处理UTF-8编码的二进制流(避免多字节字符截断)
let buffer = ''; // 缓冲区:解决数据分片问题(网络传输可能拆分完整数据块)
try {
// 2. 流读取循环:持续拉取数据直到流结束
while (true) {
const { done: streamDone, value: chunkBuffer } = await reader.read();
// 3. 流结束处理:通知业务层并释放资源
if (streamDone) {
onChunk({ type: 'done', source: 'stream' });
break;
}
// 4. 二进制流解码:stream: true表示后续还有数据,避免解码器关闭
buffer += decoder.decode(chunkBuffer, { stream: true });
// 5. 数据分片处理:SSE用"\n"分隔数据块,需要拆分出完整行
const dataLines = buffer.split('\n');
// 保留最后一行不完整数据(可能是下一次流的前缀),其余行都是完整数据块
buffer = dataLines.pop() || '';
// 6. 逐行处理完整数据块
for (const line of dataLines) {
if (!line.trim()) continue; // 跳过空行(SSE规范允许空行分隔)
const parsedData = parseSSEData(line);
if (!parsedData) continue;
// 7. 业务状态分发:基于豆包模型返回格式分类处理
if (parsedData.status === 0) { // 0表示成功响应
const { data: aiData } = parsedData;
if (aiData.status === 'completed') { // 后端标记回答完成
onChunk({ type: 'done', source: 'business' });
} else if (aiData.content) { // 有新的AI生成内容
onChunk({
type: 'content',
payload: {
content: aiData.content,
contentType: aiData.type || 'answer', // type=thinking表示思考过程
sessionId: aiData.session_id
}
});
}
} else { // 非0表示业务错误(比如参数无效、模型调用失败)
onChunk({
type: 'error',
payload: {
code: parsedData.status,
message: parsedData.msg || 'AI服务响应异常',
raw: parsedData
}
});
}
}
}
} catch (error) {
// 8. 流处理异常:比如网络中断、解码器错误
console.error('SSE流处理异常:', error);
onChunk({
type: 'error',
payload: {
code: 'STREAM_ERROR',
message: error.message || '流式数据处理失败'
}
});
} finally {
// 9. 资源释放:不管成功还是失败,都释放流读取器
if (reader) await reader.releaseLock();
}
}
3.2.2 关键技术点解析
- ReadableStream 拉取模式
通过reader.read()主动拉取数据,而不是被动接收推送,能根据前端处理能力控制流读取速度,避免 “数据堆积” 导致内存占用过高。 - UTF-8 多字节字符保护
TextDecoder的stream: true参数很重要:AI 生成的内容可能包含中文、emoji 等多字节字符,如果解码器提前关闭(默认stream: false),可能会导致字符截断。 - 缓冲区解决 “分片 / 粘包”
缓冲区通过split('\n')拆分数据行,保留不完整的行等待后续数据,保证每个数据块的完整性。 - 双端结束标记校验
同时处理 “流层面结束”(streamDone)和 “业务层面结束”(aiData.status === 'completed'),确保在网络或业务层面都能准确判断回答是否完成。
3.3 服务层:请求调度与错误统一(sendChatRequest)
服务层封装了 HTTP 请求的通用逻辑,解决 “跨环境适配”“错误标准化”“认证兼容” 问题,给上层提供稳定的请求入口。
3.3.1 核心实现与技术细节
// 1. 环境适配:支持开发/生产环境API地址切换(基于Vite环境变量)
const API_BASE_URL = `${import.meta.env.VITE_API_BASE_URL || 'http://localhost:3000'}/api/v1`;
async function sendChatRequest(endpoint, requestBody, onChunk) {
// 2. 请求参数校验:避免无效请求(比如缺少endpoint或onChunk)
if (!endpoint || typeof onChunk !== 'function') {
throw new Error('请求参数异常:缺少endpoint或回调函数');
}
try {
// 3. 发起POST请求:适配豆包模型API的请求规范
const response = await fetch(`${API_BASE_URL}${endpoint}`, {
method: 'POST',
headers: {
'Content-Type': 'application/json', // 豆包API要求JSON格式请求体
'X-Request-Source': 'web-client' // 自定义请求源标识,方便后端日志排查
},
credentials: 'include', // 携带Cookie,适配后端会话认证(比如用户登录态)
body: JSON.stringify(requestBody),
// 4. 超时控制:避免请求长期挂起(基于AbortController)
signal: AbortSignal.timeout(30000) // 30秒超时
});
// 5. HTTP状态码校验:4xx/5xx不会触发fetch catch,需要手动处理
if (!response.ok) {
const errorResp = await response.text().catch(() => ''); // 尝试读取错误响应体
const errorMsg = `API请求失败 [${response.status}]: ${response.statusText}`;
console.error(errorMsg, { endpoint, requestBody, errorResp });
// 6. 错误标准化:把HTTP错误转成统一的业务错误格式
onChunk({
type: 'error',
payload: {
code: `HTTP_${response.status}`,
message: errorMsg,
raw: errorResp
}
});
return;
}
// 7. 校验响应是否为SSE流:需要后端返回Content-Type: text/event-stream
const contentType = response.headers.get('Content-Type');
if (!contentType?.includes('text/event-stream')) {
throw new Error(`响应格式异常:预期SSE流,实际为${contentType}`);
}
// 8. 移交流处理:把SSE响应交给传输层处理
await handleSSEStream(response, onChunk);
} catch (error) {
// 9. 异常分类处理:区分超时、网络错误、格式错误
let errorCode = 'REQUEST_ERROR';
let errorMsg = 'API请求异常';
if (error.name === 'TimeoutError') {
errorCode = 'REQUEST_TIMEOUT';
errorMsg = '请求超时(30秒),请检查网络或重试';
} else if (error.name === 'TypeError') {
errorCode = 'NETWORK_ERROR';
errorMsg = '网络异常,无法连接到AI服务';
}
console.error(`${errorCode}:`, error);
// 10. 错误回调:确保业务层能捕获所有异常
onChunk({
type: 'error',
payload: { code: errorCode, message: errorMsg, raw: error }
});
}
}
3.3.2 工程化亮点
- 环境适配:通过
import.meta.env实现 API 地址自动切换; - 超时控制:基于
AbortSignal.timeout实现请求超时中断,防止无效请求占用资源; - 错误分类:把异常分成 “HTTP 错误”“超时错误”“网络错误” 等,方便业务层针对性处理;
- 可溯源性:添加
X-Request-Source头和详细日志,方便后端定位问题。
3.4 业务层:场景化 API 封装(quickThink/deepThink)
业务层针对豆包模型的 “快速对话”“深度思考” 两种模式,封装了不同的参数,提供符合业务语义的调用接口,不用关心底层技术细节。
3.4.1 核心实现与参数解析
/**
* 快速对话:低延迟、短回答,适合简单问答场景
* @param {Object} params - 业务参数
* @param {Array} params.messages - 对话历史(格式:[{role: 'user/assistant', content: 'xxx'}])
* @param {string} params.session_id - 会话ID(关联对话上下文)
* @param {Function} onChunk - 流式回调函数
*/
export async function quickThink({ messages, session_id }, onChunk) {
// 1. 业务参数默认值:适配豆包模型的推荐配置
const requestBody = {
messages: messages || [],
session_id: session_id || `web_${Date.now()}`, // 无会话ID时自动生成(基于时间戳)
temperature: 0.7, // 创造性:0(确定性)~1(随机性),0.7平衡准确性与多样性
max_tokens: 2000, // 输入+输出总tokens限制(快速对话不用太长输出)
stream: true // 强制开启流式响应(豆包API默认关闭,需要显式开启)
};
// 2. 调用服务层:指定快速对话的API端点
await sendChatRequest('/chat/quick-think', requestBody, onChunk);
}
/**
* 深度思考:带思考过程、长回答,适合复杂问题(比如代码生成、方案设计)
* @param {Object} params - 业务参数(和quickThink一样)
* @param {Function} onChunk - 流式回调函数
*/
export async function deepThink({ messages, session_id }, onChunk) {
const requestBody = {
messages: messages || [],
session_id: session_id || `web_${Date.now()}`,
temperature: 0.7,
max_output_tokens: 4096, // 仅输出tokens限制(深度思考需要更长输出)
stream: true,
thinking: { type: 'enabled' } // 豆包模型扩展参数:开启思考过程生成
};
// 3. 调用服务层:指定深度思考的API端点
await sendChatRequest('/chat/deep-think', requestBody, onChunk);
}
3.4.2 业务适配逻辑
- 参数差异化:通过设置不同的
max_tokens和thinking参数,适配不同的 AI 场景。 - 会话 ID 管理:没有会话 ID 时自动生成基于时间戳的 ID,保证对话上下文不丢失。
- 流式强制开启:显式设置
stream: true,避免后端默认关闭流式影响体验。
四、架构优势与工程化扩展
4.1 核心架构优势
- 高内聚低耦合:每层只关注自己的领域,改传输层的流处理逻辑不会影响业务层调用;
- 可测试性强:每个函数都能独立测试(比如
parseSSEData可以通过输入固定字符串测试解析逻辑,不用依赖真实 API); - 错误闭环:从协议解析到请求发起,所有异常都通过
onChunk回调统一分发,业务层不用重复捕获错误; - 可扩展性好:新增 AI 对话模式(比如 “创意写作”)只需要添加业务函数,复用服务层和传输层逻辑,代码增加很少。
4.2 工程化扩展建议
- 请求取消:集成
AbortController,支持用户主动中断对话(比如 “停止生成” 按钮):
// 扩展sendChatRequest,支持signal参数
async function sendChatRequest(endpoint, requestBody, onChunk, { signal } = {}) {
const response = await fetch(`${API_BASE_URL}${endpoint}`, {
// ...其他配置
signal: signal || AbortSignal.timeout(30000)
});
}
// 业务层调用:
const controller = new AbortController();
quickThink(params, onChunk, { signal: controller.signal });
// 点击“停止”按钮时:
controller.abort();
- 重试机制:基于错误类型实现智能重试(比如网络错误重试,业务错误不重试):
async function sendWithRetry(endpoint, requestBody, onChunk, retry = 2) {
try {
await sendChatRequest(endpoint, requestBody, onChunk);
} catch (error) {
if (retry > 0 && ['NETWORK_ERROR', 'REQUEST_TIMEOUT'].includes(error.code)) {
await new Promise(resolve => setTimeout(resolve, 1000 * (3 - retry))); // 指数退避
return sendWithRetry(endpoint, requestBody, onChunk, retry - 1);
}
throw error;
}
}
- 监控埋点:添加流处理性能监控(比如首包时间、总耗时、错误率),方便优化用户体验:
async function handleSSEStream(response, onChunk) {
const metrics = {
startTime: Date.now(),
firstPacketTime: 0,
chunkCount: 0
};
// 首包时间记录:
const originalOnChunk = onChunk;
onChunk = (data) => {
if (data.type === 'content' && metrics.firstPacketTime === 0) {
metrics.firstPacketTime = Date.now() - metrics.startTime;
console.log('SSE首包时间:', metrics.firstPacketTime);
// 埋点上报:
// reportMetrics('sse_first_packet_time', metrics.firstPacketTime);
}
if (data.type === 'content') metrics.chunkCount++;
if (data.type === 'done') {
metrics.totalTime = Date.now() - metrics.startTime;
// reportMetrics('sse_total_time', metrics.totalTime);
}
originalOnChunk(data);
};
// ...原有流处理逻辑
}
五、总结
chat.js模块通过 “解析 - 传输 - 服务 - 业务” 四层架构,实现了 SSE 流式响应的全链路管理,核心价值在于:
- 技术屏蔽:把 SSE 协议解析、流控逻辑封装成黑盒,业务层不用关心底层实现;
- 工程化适配:解决环境切换、错误统一、资源释放等工程问题,提升模块稳定性;
- 业务弹性:通过参数差异化适配不同 AI 对话场景,支持快速扩展新功能。
这个架构不仅适用于豆包模型 API 封装,还能用到其他流式数据场景(比如实时日志、进度推送),为前端构建高可用、低延迟的流式交互层提供了可落地的技术方案。
多模态Ai项目全流程开发中,从需求分析,到Ui设计,前后端开发,部署上线,感兴趣打开链接(带项目功能演示),多模态AI项目开发中
你对这种分层架构的性能优化有什么更好的思路吗?欢迎在评论区一起交流!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)