ETCD: request timed out
背景:在部署kubernetes的时候执行 kubeadm init失败 ,查看日志发现 连接etcd超时
背景:
在部署kubernetes的时候执行 kubeadm init失败 ,查看日志发现 连接etcd超时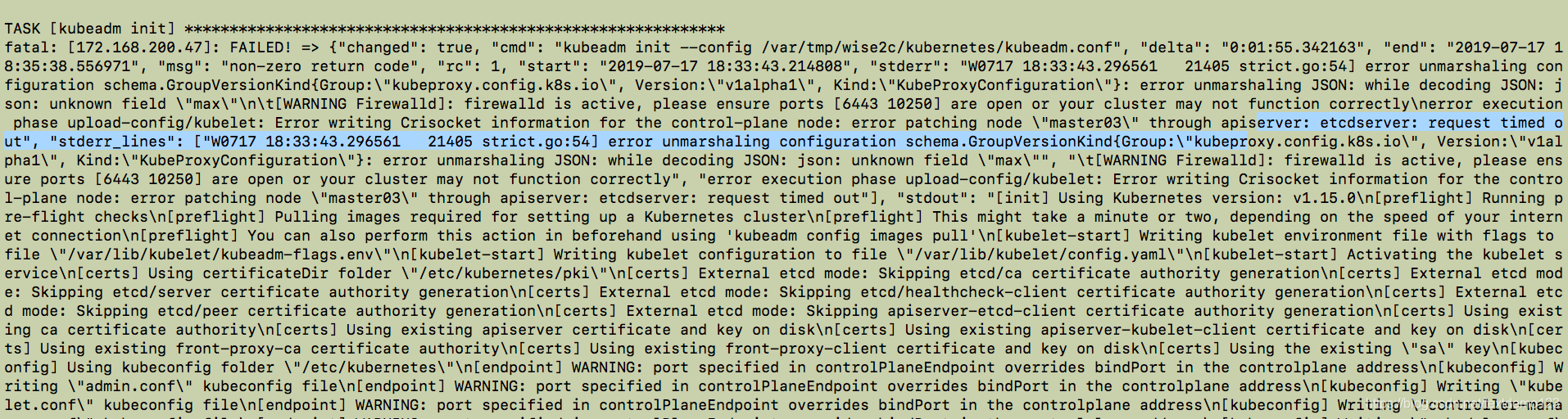
docker化的ETCD集群 ,查看etcd集群状态
docker exec etcd etcdctl --endpoints http://172.168.200.45:2379 cluster-health
集群处于非健康状态,就能解释为什么etcd :request timed out
但是为什么会集群降级呢?
我们在三个节点上均看了一下 leader 和self信息
curl http://172.168.200.46:2379/v2/stats/leader
curl http://172.168.200.46:2379/v2/stats/self
发现输出信息完整,有leader ,有followers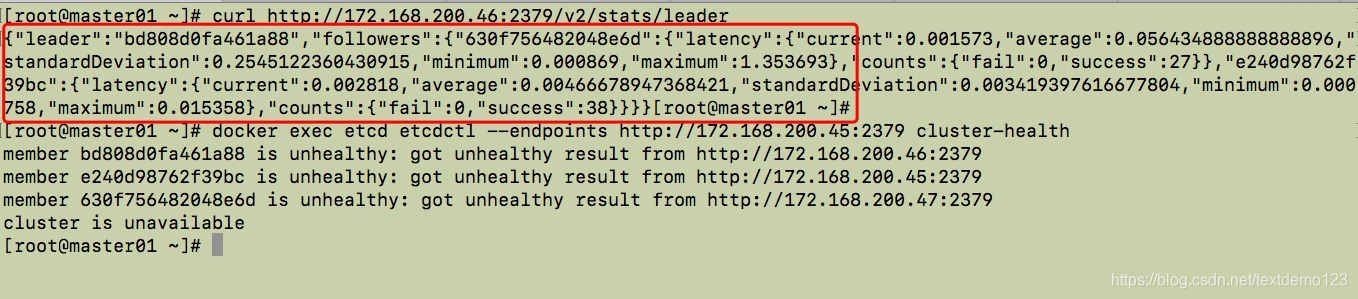

而且节点上没有错误信息 ,leader上也没有错误信息
在查看etcd 容器日志
docker logs -f etcd
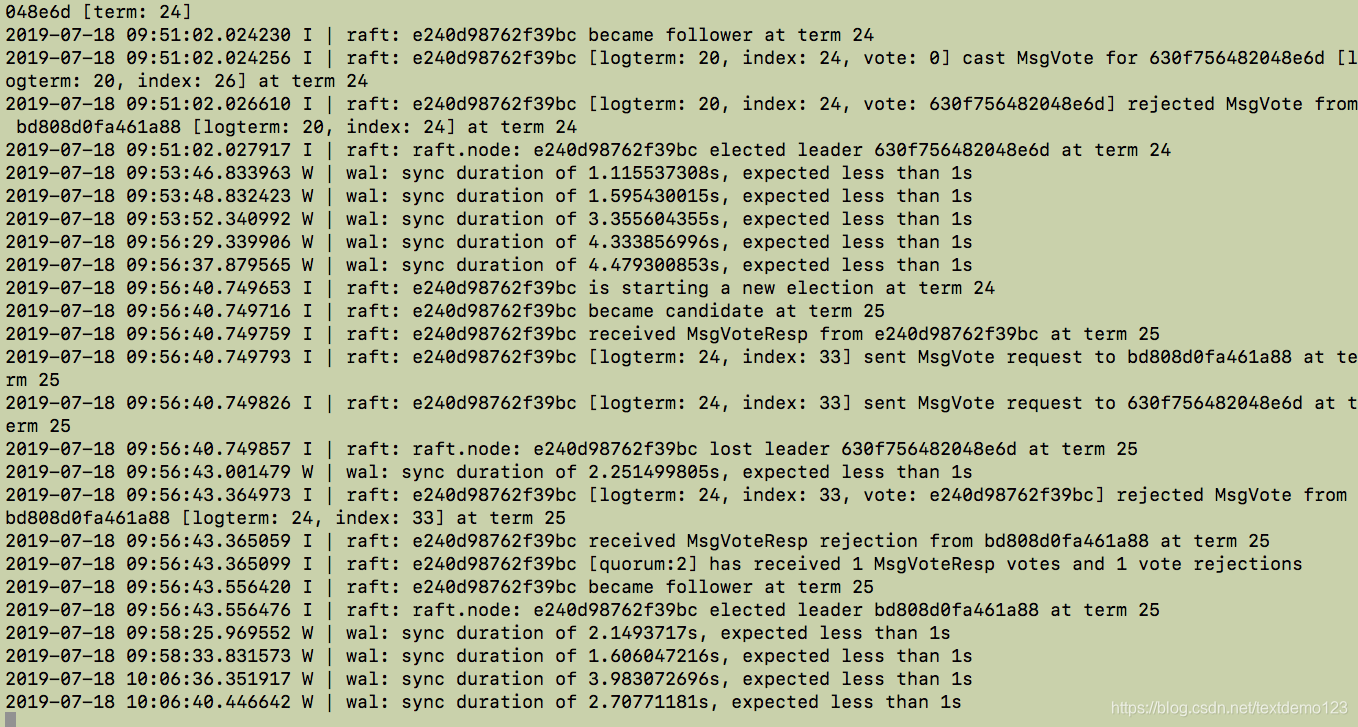
此时发现了问题,服务器时间同步出现问题
使用如下命令同步时间,3台master节点均同步master01的时间
chronyc sources



最大的延迟有324ms,我们等了10分钟时间让时间去同步,之后再次查看
效果也不理想,再次查看日志,服务器还是报时间同步问题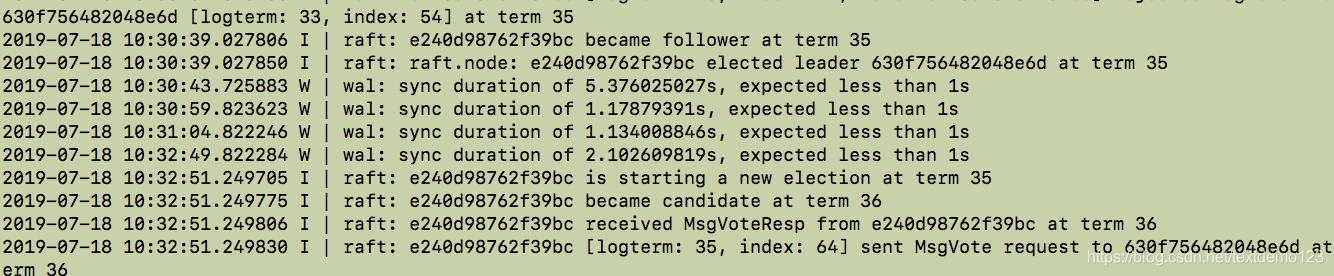
此时我们猜想可能是系统资源不足引起的etcd读写吃力,最终难以同步
我们的服务器是8U32G ,所以内存和CPU是没有问题的,唯一出现问题的地方也就是磁盘io了,检测一下磁盘负载
iostat -x -k 1 1
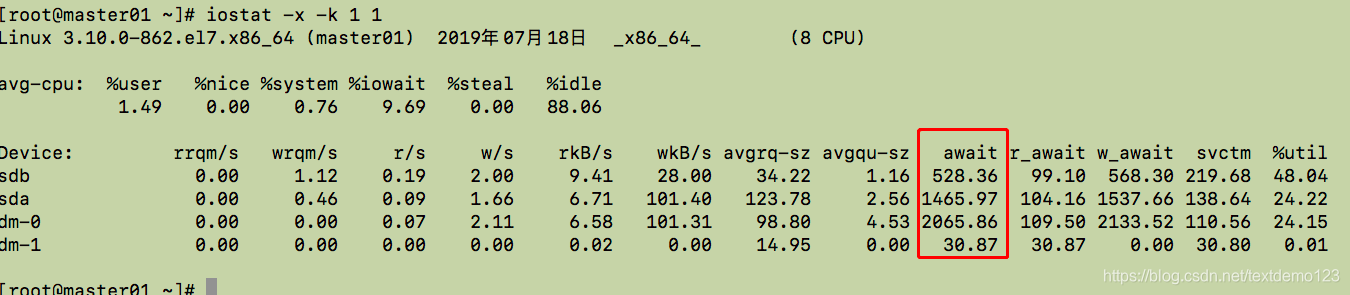
我们看到确实是磁盘性能不足引起的 etcd无法同步,最终引起ETCD: request timed out
总结:etcd 是要进行大量读写操作的,磁盘io一定要跟得上,否则etcd不稳定,进而会引起kubernetes集群不稳定,进而引发业务不稳定一系列的问题。
etcd的硬件要求:
https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/hardware.md#disks

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)