小林Coding_操作系统_读书笔记
操作系统读书笔记,包含内存管理、文件系统、进程与线程、调度算法以及包含Reactor和Proactor的网络系统
一、硬件结构
1. CPU是如何执行的
冯诺依曼模型:中央处理器(CPU)、内存、输入设备、输出设备、总线
CPU中:寄存器(程序计数器、通用暂存器、指令暂存器),控制单元(控制CPU工作),逻辑运算单元(运算)
总线:控制总线(发信号),内存总线(指定内存地址),数据总线(内存读写)
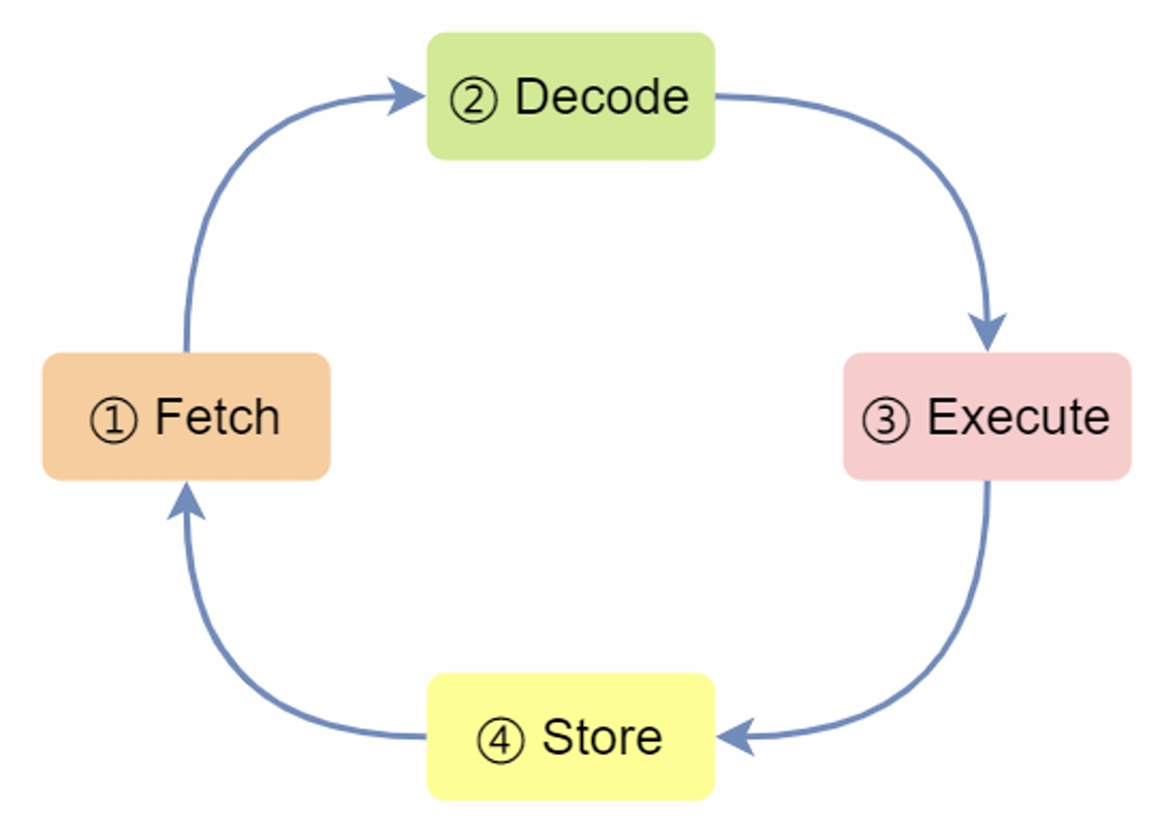
CPU 执行程序的过程:
第一步,CPU读取“程序计数器”中指令的地址,然后“控制单元”操作“地址总线”指定需要访问的内存地址,接着通知内存设备准备数据,通过“数据总线”将指令数据传给CPU,CPU收到内存传来的数据后,将指令数据存到“指令寄存器”。
第二步,CPU分析“指令寄存器”中的指令,确定指令的类型和参数,计算类型的指令交给“逻辑运算单元”运算;存储类型的指令交由“控制单元”执行;
第三步,CPU执行完指令后,“程序计数器”自增,表示指向下一条指令。自增的大小,由CPU位宽决定(如32位的CPU,指令是4个字节,需要4个内存地址存放,自增 4);
时钟周期和CPU主频:
每一次脉冲信号高低电平的转换就是一个周期,称为时钟周期。不同指令消耗的时钟周期不同。对于程序的CPU执行时间,可以拆解成CPU时钟周期数(CPU Cycles)和时钟周期时间(Clock Cycle Time)的乘积。

时钟周期时间就是CPU主频。
32位和64位的区别:
只有运算大数字的时候,64位CPU的优势才能体现出来,否则和32 位CPU的计算性能相差不大。
64位CPU可以寻址更大的内存空间。
操作系统分成32位和64位,其代表意义就是操作系统中程序的指令是多少位。
2. 存储器的结构层次
存储器的存储结构:
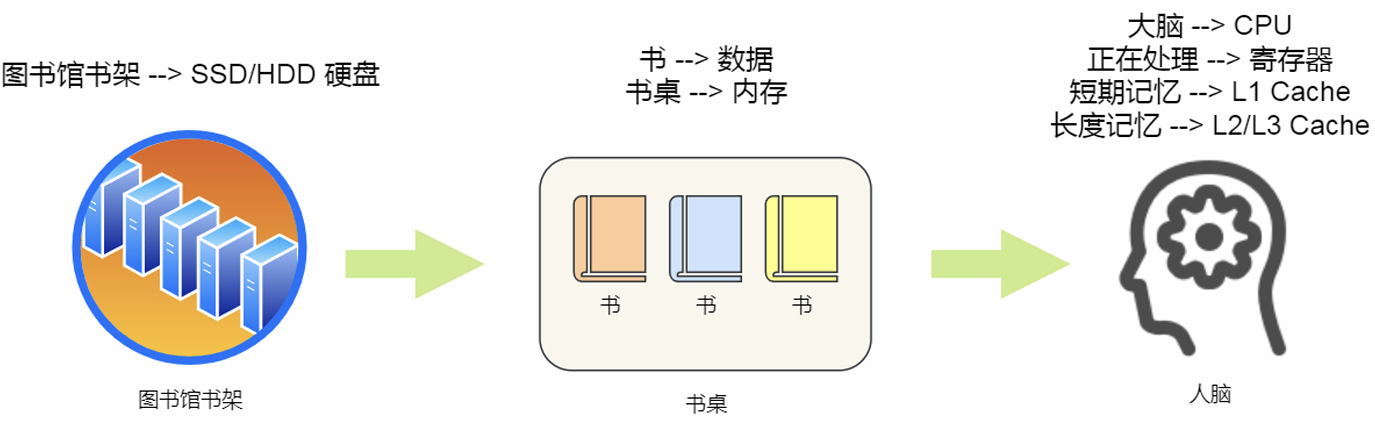
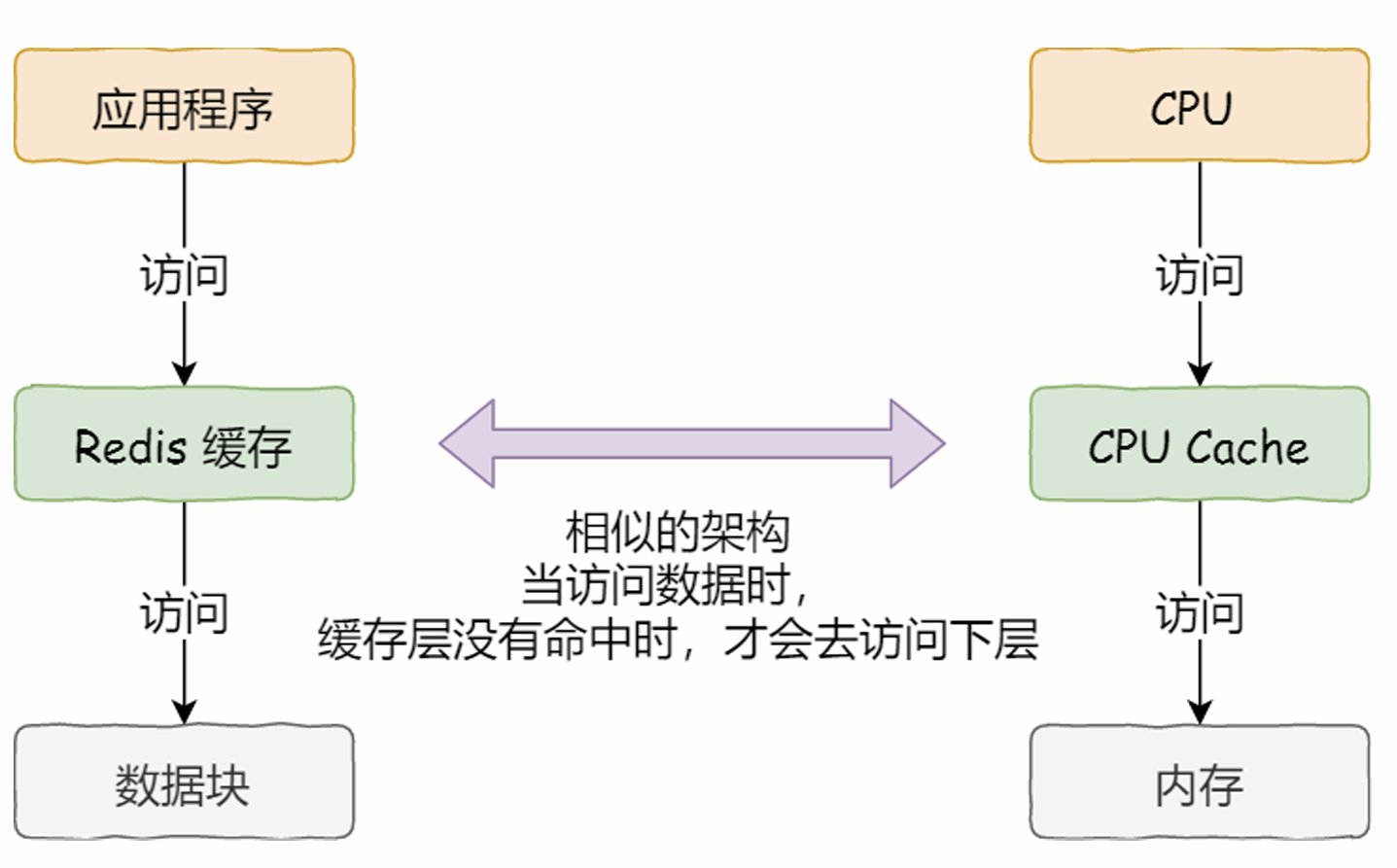
不同存储器之间性能差距很大,分级的目的是构造缓存体系。
寄存器:
32位CPU中寄存器存4字节,64位CPU中寄存器中存8字节。一般要求在半个CPU时钟周期完成读写(2GHz主频,时钟周期1/2G,也就是0.5ns)
CPU Cache:
SRAM(Static Random-Acess Memory)静态随机存储器,只要有电,数据就可以保持存在。
L1高速缓存:通常分为指令缓存、数据缓存,访问时间一般是2~4个时钟周期,大小在几十KB到几百KB不等。
L2高速缓存:访问时间10~20个时钟周期,大小几百KB到几MB不等。
L3高速缓存:通常是多个核心共用,访问速度是20~60个时钟周期,大小是几MB和几十MB。
内存:
DRAM(Dynamic Random-Access Memory) 存储一个 bit 数据,只需要一个晶体管和一个电容,但是因为数据存储在电容里,电容会不断漏电,所以需要“定时刷新”电容,才能保证数据不会被丢失,这就是DRAM 之所以被称为「动态」存储器的原因,内存访问速度200~300个时钟周期。
SSD/HDD硬盘:
这两个存储器的结构和内存相似,但是其中的数据在断电后仍旧存在,内存比SSD快10~1000倍,比HDD(机械硬盘物理读写)快10W倍。
3. Cache的读取过程、提升缓存命中率
CPU Cache的数据结构和读取过程:
CPU Cache从内存中读取数据,按块读取,Cache Line(缓存块)。
比如,有一个int array[100]的数组,当载入array[0]时,由于这个数组元素的大小在内存只占 4 字节,不足 64 字节,CPU就会顺序加载数组元素到array[15]。
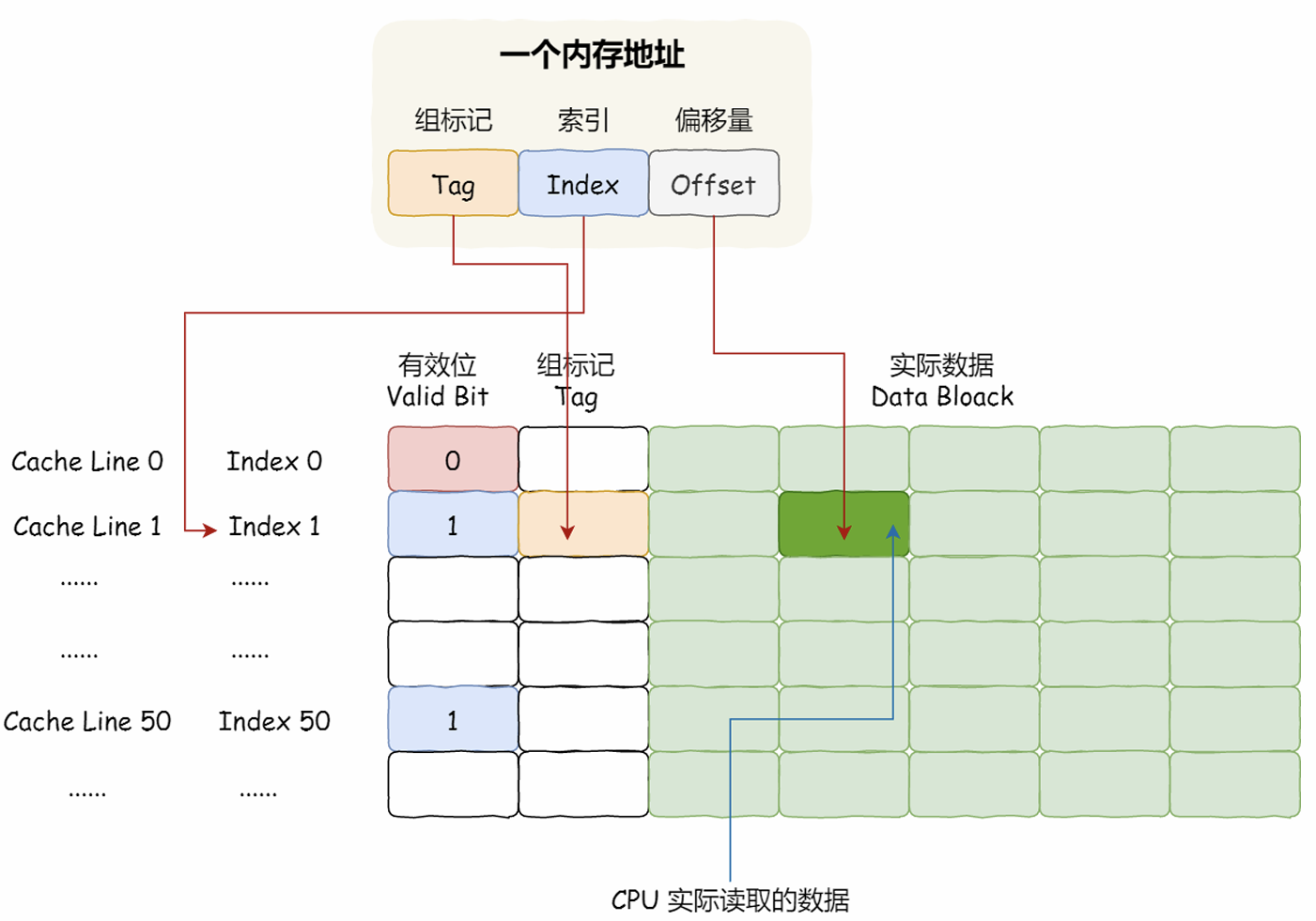
直接映射Cache:一个内存的访问地址,包括组标记(Tag)、CPU Line索引(Index)、偏移量(Offset)这三种信息。而对于CPU Cache里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。
CPU分支预测器:如果分支预测可以预测(比如连续50次if判断都是true)接下来要执行if里的指令,还是else指令的话,就可以“提前”把这些指令放在指令缓存中,这样CPU可以直接从Cache读取到指令,执行速度就会很快。在C/C++中编译器提供了likely和unlikely这两种宏进行分支预测(CPU自身的动态分支预测就是比较准的)。
如何提升多核CPU的缓存命中率:
了解了上面的读取过程,不难想到,如果一个进程在同一个核心上执行,那么速度就会更快(缓存命中率更高)。Linux上提供了sched_setaffinity方法,来将线程绑定到某个核心。
4. CPU缓存一致性
写直达和写回:
写直达:把数据同时写入内存和Cache中,这称为写直达(Write Through),如果在Cache,就先更新Cache,再写在内存;如果不在,就直接写到内存(不过这样性能会较差)。
写回:在写回(Write Back)中,写时,新的数据仅仅被写入Cache Block,只有当修改过的Cache Block“被替换”时,才需要写到内存中,减少了数据写回内存的频率。只有在缓存不命中,同时数据对应的Cache Block标记为脏,才会将数据写到内存中。而在缓存命中时,写入Cache后,把该数据对应的Cache Block标记为脏(如果大量缓存命中,就不需要频繁写内存)。
为了确保缓存一致性:写传播(Write Propagation,确保数据更新)、事务的串行化(Transaction Serialization,确保数据变化的顺序)。
写传播和事务串行化如何实现:
总线嗅探(Bus Snooping):CPU监听总线上的一切活动,但是不管别的核心的 Cache是否缓存相同的数据,都需要发出一个广播事件(总线负载会加大)。
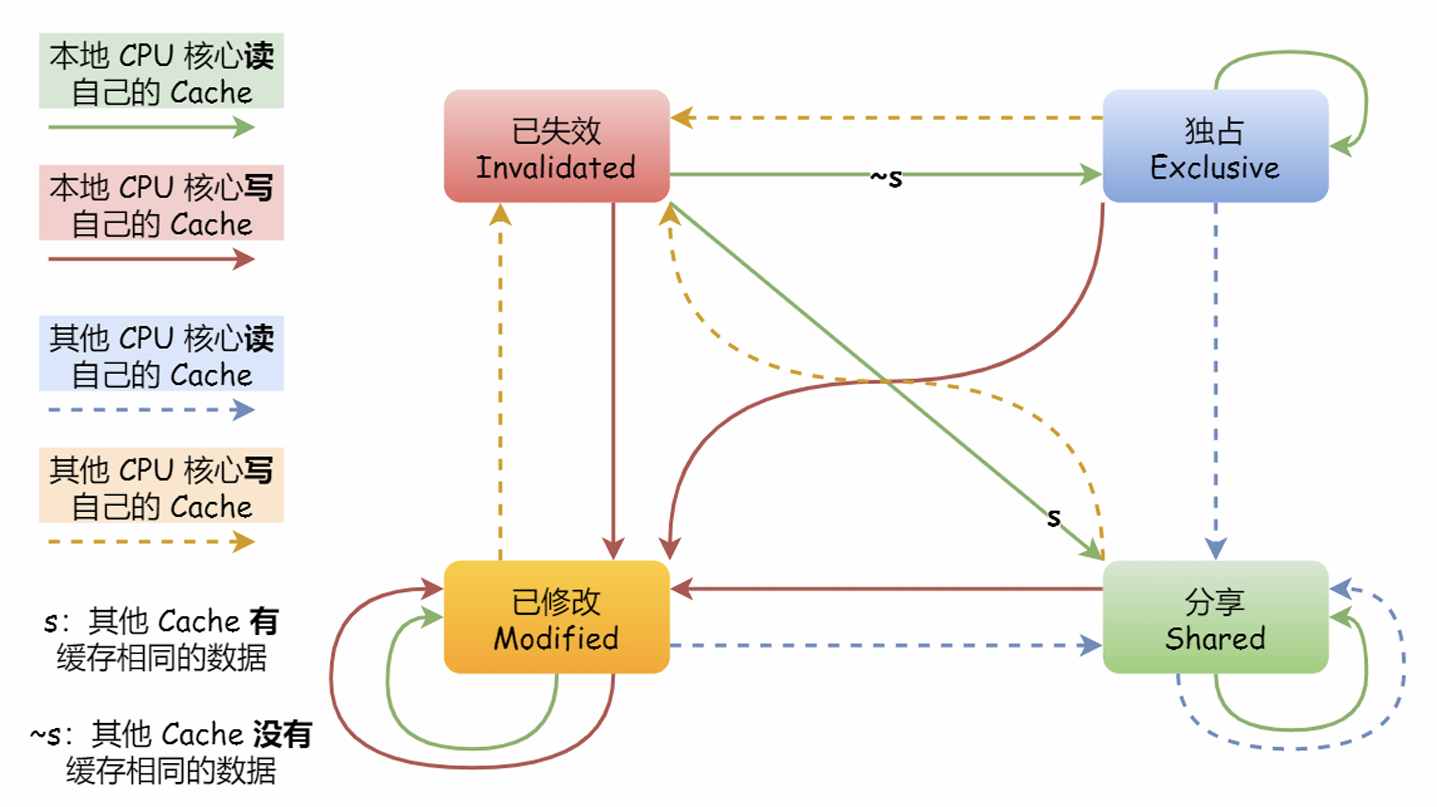
MESI协议:Modified(已修改,标记为脏)、Exclusive(独占,数据干净,只在一个核心)、Shared(数据在多个核心,从内存读取到其他核心中相同的数据,标记为共享)、Invalidate(失效,一个核心修改后,广播要求其他核心设置为失效),这个协议基于总线嗅探机制实现了事务串形化。(如此也减轻了总线的带宽压力)
5. CPU是如何执行任务的
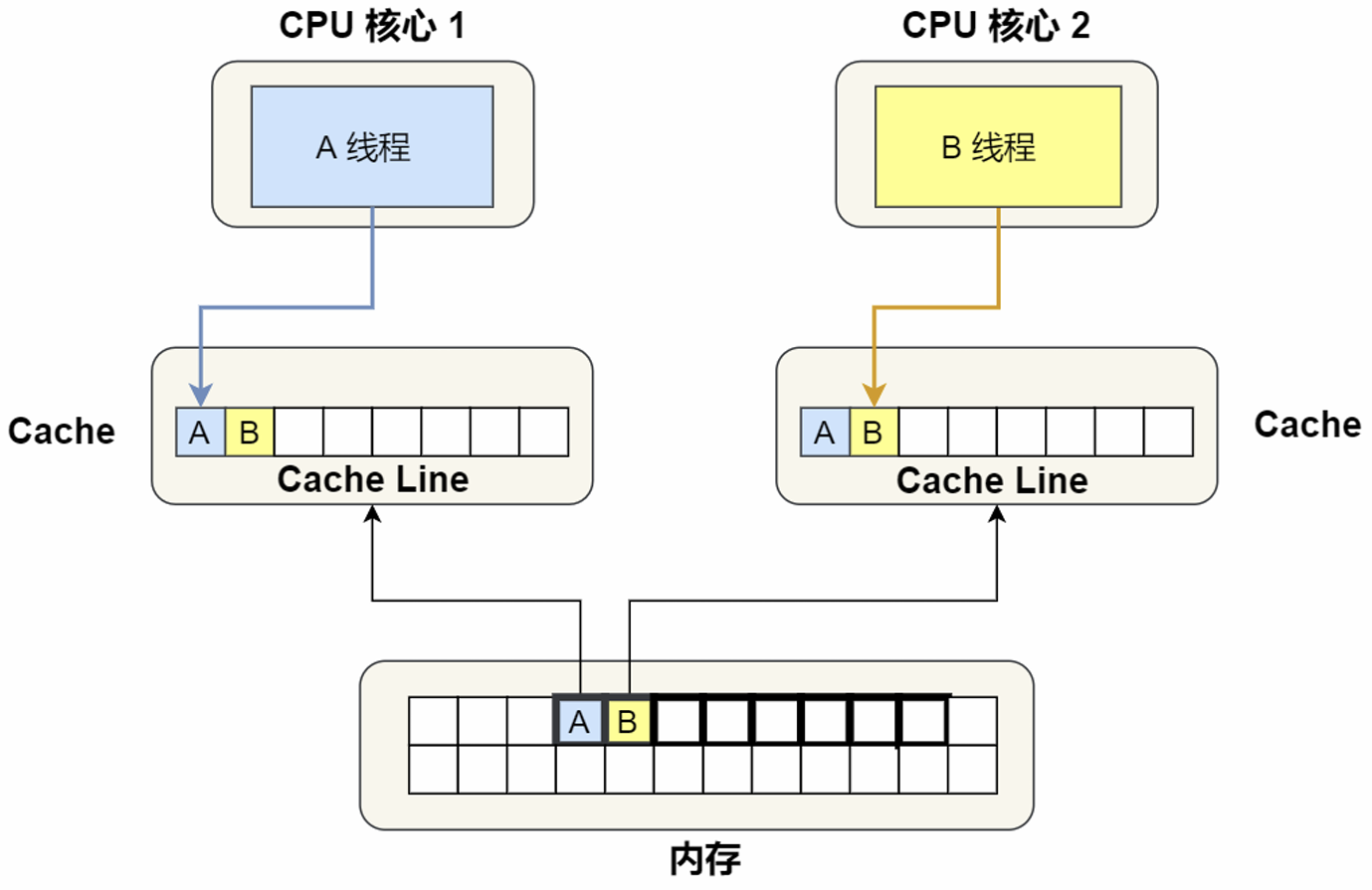
Cache的伪共享问题:
多个线程同时读写同一个Cache Line的不同变量时(独占->共享),而导致CPU Cache变为失效态的现象称为伪共享(False Sharing)。
解决:①通过__cacheline_aligned_in_smp设置Cache Line对齐地址(读成两个缓存块),②Java并发框架Disruptor字节填充。
CPU如何选择线程:
优先级:Linux中任务优先级的数值越小,优先级越高。(实时任务0~99,普通任务100~139)
Linux中的调度类:
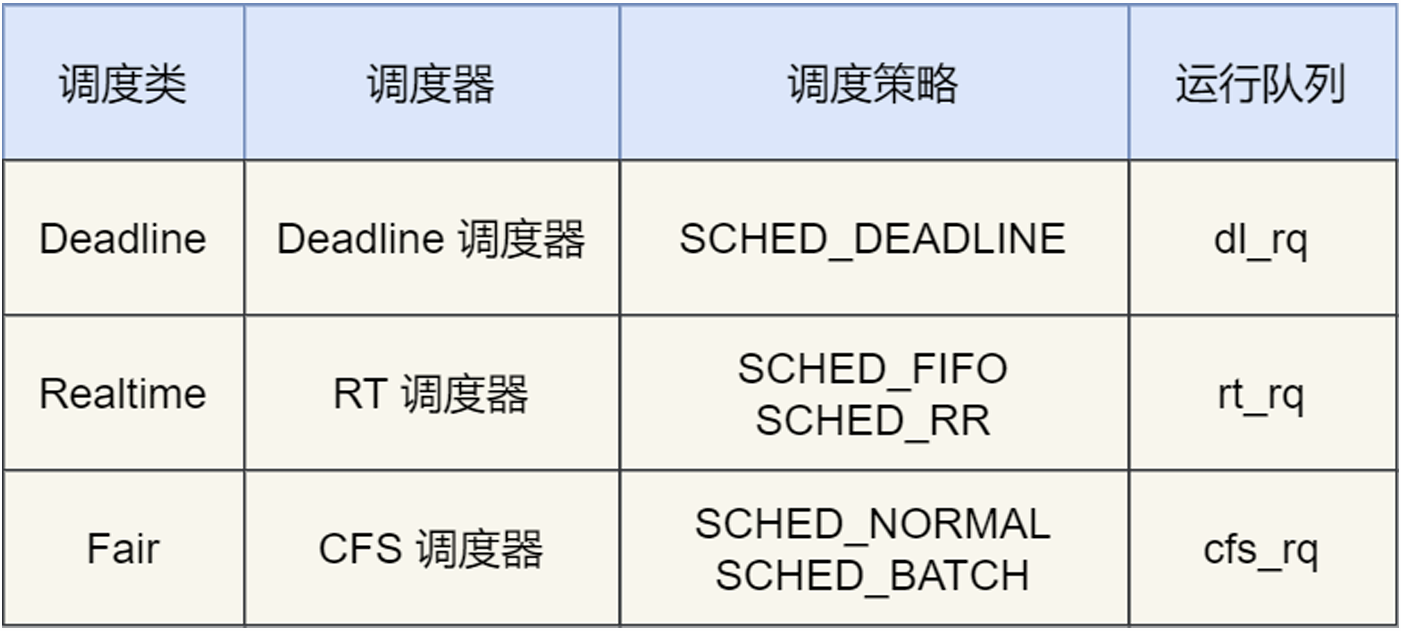
Deadline、Realtime作用于实时任务:
SCHED_DEADLINE:按照距离当前时间最近的deadline优先调度
SCHED_FIFO:先来先服务,但是可“插队”(受优先级影响)
SCHED_RR:轮询,不过还是可以“插队”
Fair调度类作用于普通任务:
SCHED_NORMAL:普通任务的调度策略
SCHED_BATCH:后台任务的调度策略
完全公平调度CFS算法:
在CFS(Completely Fair Scheduling)算法调度的时,每个任务都安排一个虚拟运行时间,运行越久vruntime越大。优先选择vruntime少的任务,在计算虚拟运行时间vruntime还要考虑普通任务的权重值。
nice级别越低,权重值就越大,vruntime越小,优先被调度。nice 值并不是表示优先级,而是表示优先级的修正数值,priority(new) = priority(old) + nice。nice调整的是普通任务的优先级,不管怎么缩小nice值(范围是-20~19),永远都是普通任务。

CPU运行队列:
每个CPU都有自己的运行队列(Run Queue, rq),用于描述在此CPU上运行的所有进程,其队列包含三个运行队列,Deadline队列dl_rq、实时任务队列rt_rq、CFS队列 cfs_rq。
其中cfs_rq是用红黑树来描述的,按vruntime大小来排序的,最左侧的叶子节点,就是下次会被调度的任务。调度类优先级如下:Deadline > Realtime > Fair,因此实时任务总是会比普通任务先执行。
软中断:
中断请求的响应程序,也就是中断处理程序,要尽可能快的执行完,这样可以减少对正常进程运行调度的影响。
Linux中断处理分为上半部和下半部。
上半部(硬中断)用来快速处理,一般会暂时关闭中断请求,主要负责跟硬件紧密相关的或时间敏感的
下半部(软中断)以内核线程的方式执行,延迟处理上半部未完成的工作。每个 CPU 核心都对应着一个内核线程ksoftirqd。此外,一些内核自定义事件也属于软中断,比如内核调度、RCU锁(内核里常用的一种锁)等。
二、操作系统结构
1. Linux内核 vs Windows内核
内核:
内核作为应用连接硬件设备的桥梁,应用程序与内核交互,而不关心硬件的细节。
现代操作系统中,内核一般具有4个基本能力:1. 进程调度,2. 内存管理,3. 硬件通信(做桥梁),4. 提供系统调用。
大多数操作系统,把内存分为内核空间、用户空间,也就是用户态和内核态的区别。
Linux的设计:
Linux内核的设计概念:MutiTask多任务(并发、并行),SMP对称多处理,ELF可执行文件链接格式,Monolithic Kernel宏内核
SMP对称多处理:代表每个CPU的地位相等,对资源的使用权限相同,多个CPU 共享同一内存,每个CPU都可以访问完整的内存和硬件资源
ELF可执行文件链接格式:编译汇编链接->可执行文件ELF
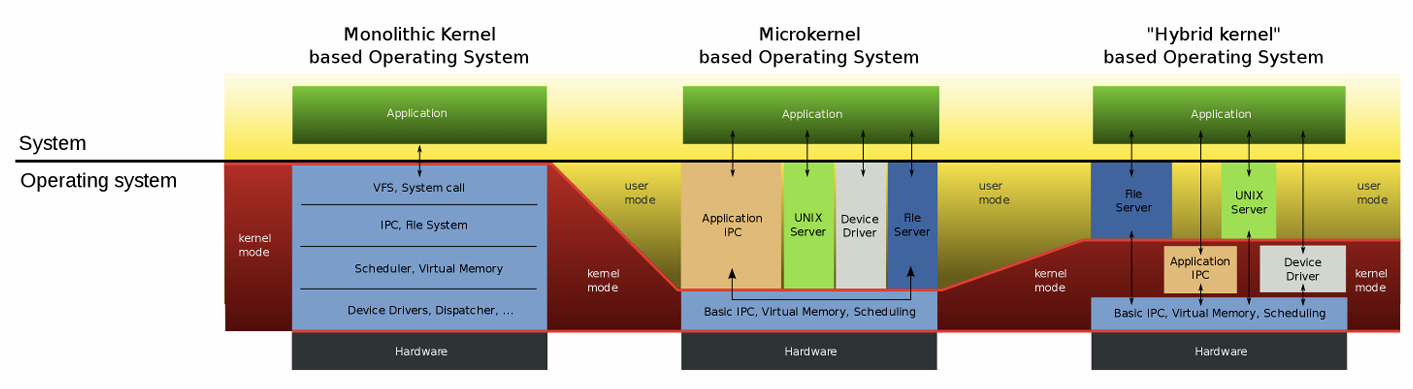
Monolithic Kernel宏内核:Window是混合型内核,Linux是宏内核(性能高,但容易一错皆错),鸿蒙操作系统是微内核(可移植性好,但驱动不在内核,在驱动程序使用硬件资源时可能需要多次切换到内核态)。
三、内存管理
1. 虚拟内存
虚拟内存:单片机的CPU是直接操作内存的“物理地址”,因为它没有操作系统,程序都是烧录进去的。
而操作系统为了避免两个程序同时对一个绝对物理地址进行引用,就通过给每个进程分配“虚拟地址”的方式,把每个进程所使用的地址“隔离”开,而CPU中的内存管理单元(MMU)会把虚拟地址映射为物理地址。
2. 内存分段和内存分页
内存分段:
分段(Segmentation),程序由代码分段、数据分段、栈段、堆段组成。
分段机制下的虚拟地址由段选择子、段内偏移量组成。
段选择子保存在段寄存器。段选择子里最重要的是段号,用作段表的索引。段表保存的是段的基地址、段的界限和特权等级等。(对某段寻址即,段基地址+段内偏移量)
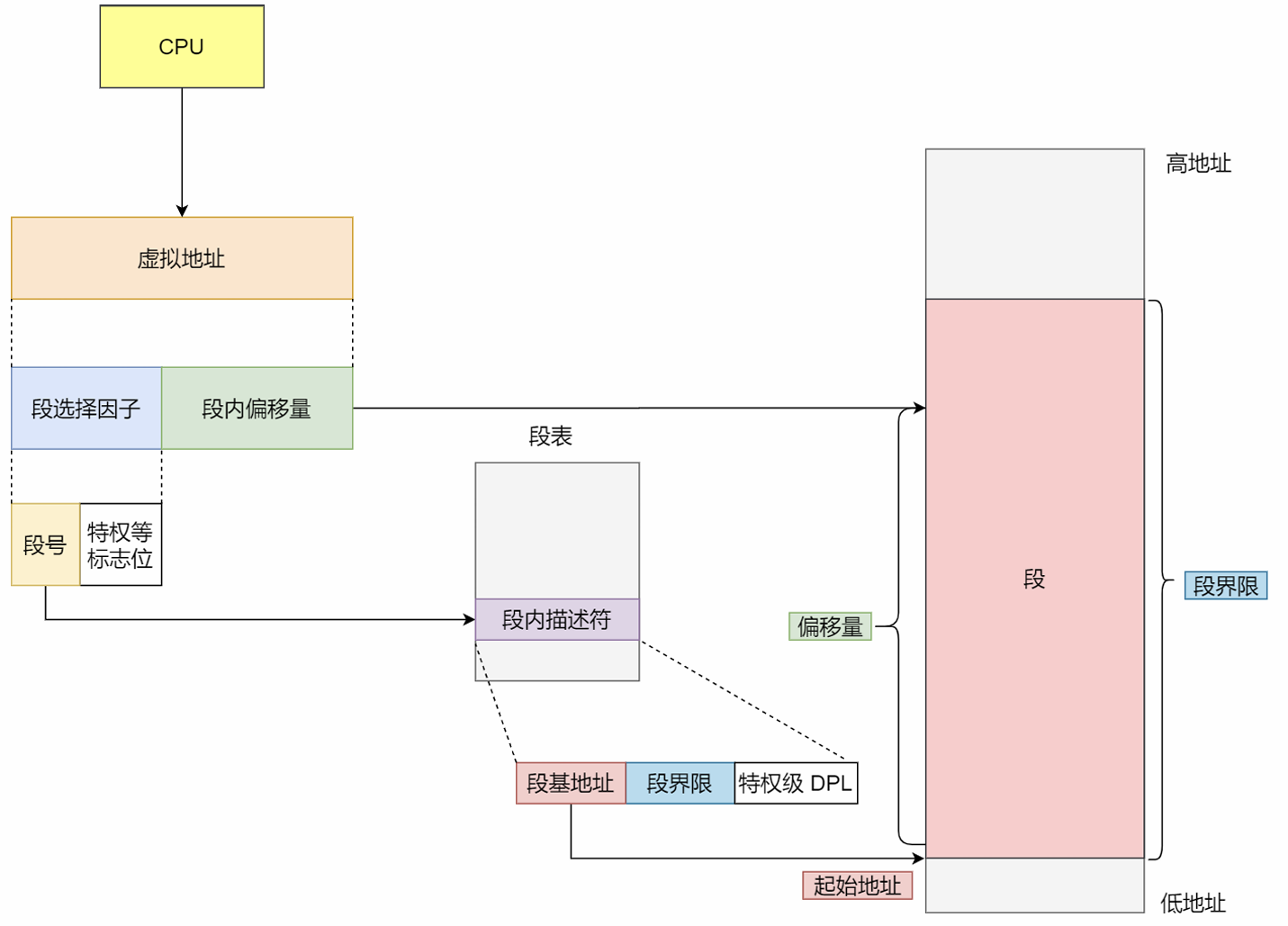
不足:内存碎片(外部碎片)、内存交换的效率低(linuxswap)。
下图是外部内存碎片的成因。而内部内存碎片,则是程序装载好了,但有程序部分的内存不常用。
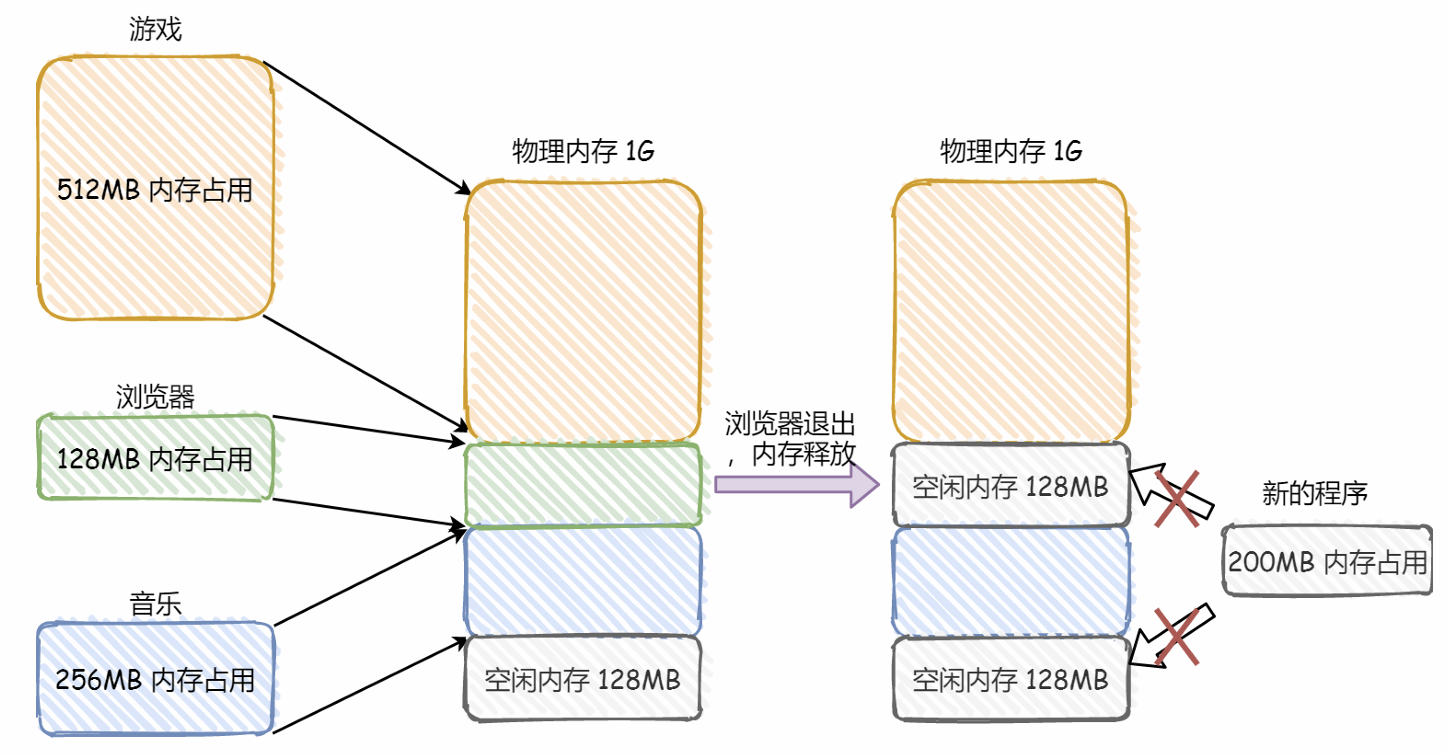
外部内存碎片的问题,通过内存交换可以解决,Linux中,通过Swap空间(从硬盘上划分出来的,用于内存和硬盘的空间交换,有点调整装载位置的意味),而内存交换,很明显会让效率变低。
内存分页:
分页(Paging)是把整个虚拟和物理内存空间切成一段段固定尺寸的大小,Linux下每一页4KB。而虚拟地址和物理地址通过页表(MMU使用页表)来映射。页表可以在物理内存也可能在Swap区,具体需根据操作系统设计。
当进程访问的虚拟地址在页表中查不到时,系统会产生缺页异常,进入内核空间更新进程页表,再返回用户空间恢复运行。
解决内存碎片和提升内存交换效率:采用了分页,释放的内存也就都是以页为单位的,这就解决了内存碎片的问题。如果内存不足,操作系统就会把其他进程中“最近没使用”的页释放(写在硬盘上),成为换出(Swap Out),需要时再换入(Swap In),这让内存交换效率有了一定的提升。
只有在程序运行中,需要用到对应虚拟内存页的指令和数据时,再加载到物理内存。
分页如何映射:分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含页所在物理内存的基地址。(寻址某一页,页基地址+页内偏移量)

不过如此简单的分页,在空间上肯定是有缺陷的,每一个进程都有自己的页表,100个进程,每个页表为MB级,这也是很大的开销了。
多级页表:
为解决空间上可能带来的大开销,多级页表的方案出现了。
二级页表:如果某个一级页表的页表项没有被用到,就不需要创建这个页表项对应的二级页表,即是在需要时才会创建二级页表(假设100万页表项,可以分为1024*二级页表1024,即一个一级页表和1024个二级页表),而推广到多级,这个空间占用就会更小。
TLB:多层的页表在访问时,速度肯定变慢,为了解决此问题,在CPU中加入了专门存放程序最常访问的页表项Cache,叫做TLB(Translation Lookaside Buffer,转址旁路缓存、快表、页表缓存),MMU会首先和TLB交互,查不到再找页表。
段页式内存管理(内存分段 + 内存分页):
先将程序划分为多个有逻辑意义的段(数据段、代码段、栈段、堆段),接着再把每个段划分为多个页,也就是对段的连续空间,再分为固定大小的页。地址结构由段号、段内页号和页内位移组成。(寻址会经历三次内存访问:1. 段表,2. 页表,3. 物理地址),如此虽然提高了系统开销,但是提高了内存利用率。
3. Linux内存管理
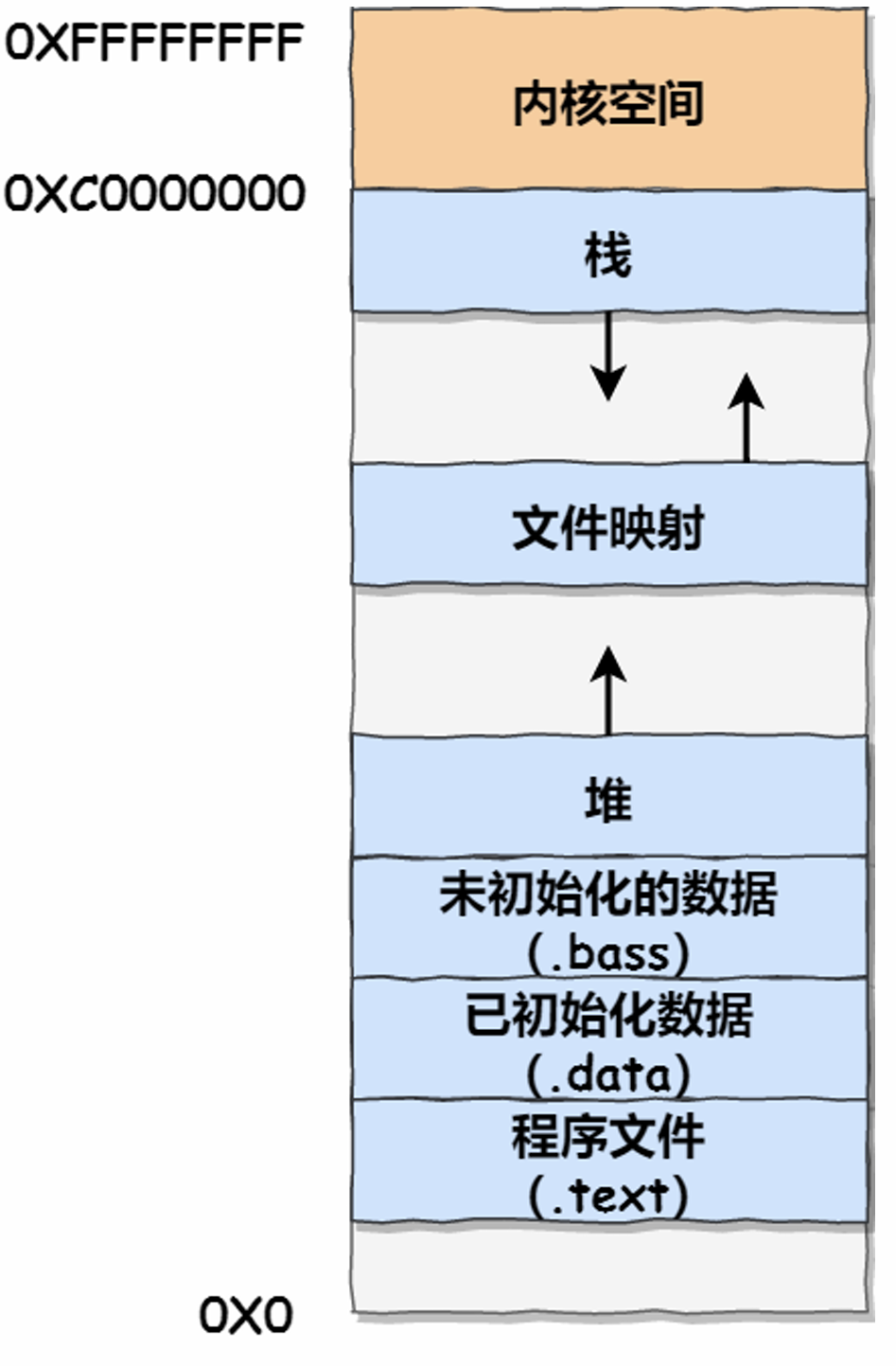
7种不同内存段:
程序文件段(代码段):二进制可执行代码
已初始化数据段:已初始化的静态常量(const)、全局变量、常量
未初始化数据段(BSS段):未初始化的静态变量、全局变量
堆段:动态分配的内存
文件映射段:包括动态库、共享内存等
栈段:局部变量、函数调用的上下文。栈一般8MB,可以修改系统参数来自定义
mmap()可以在文件映射段动态分配内存。
四、进程与线程
1. 进程
进程的七种状态变迁:创建、就绪、运行、阻塞、结束、挂起
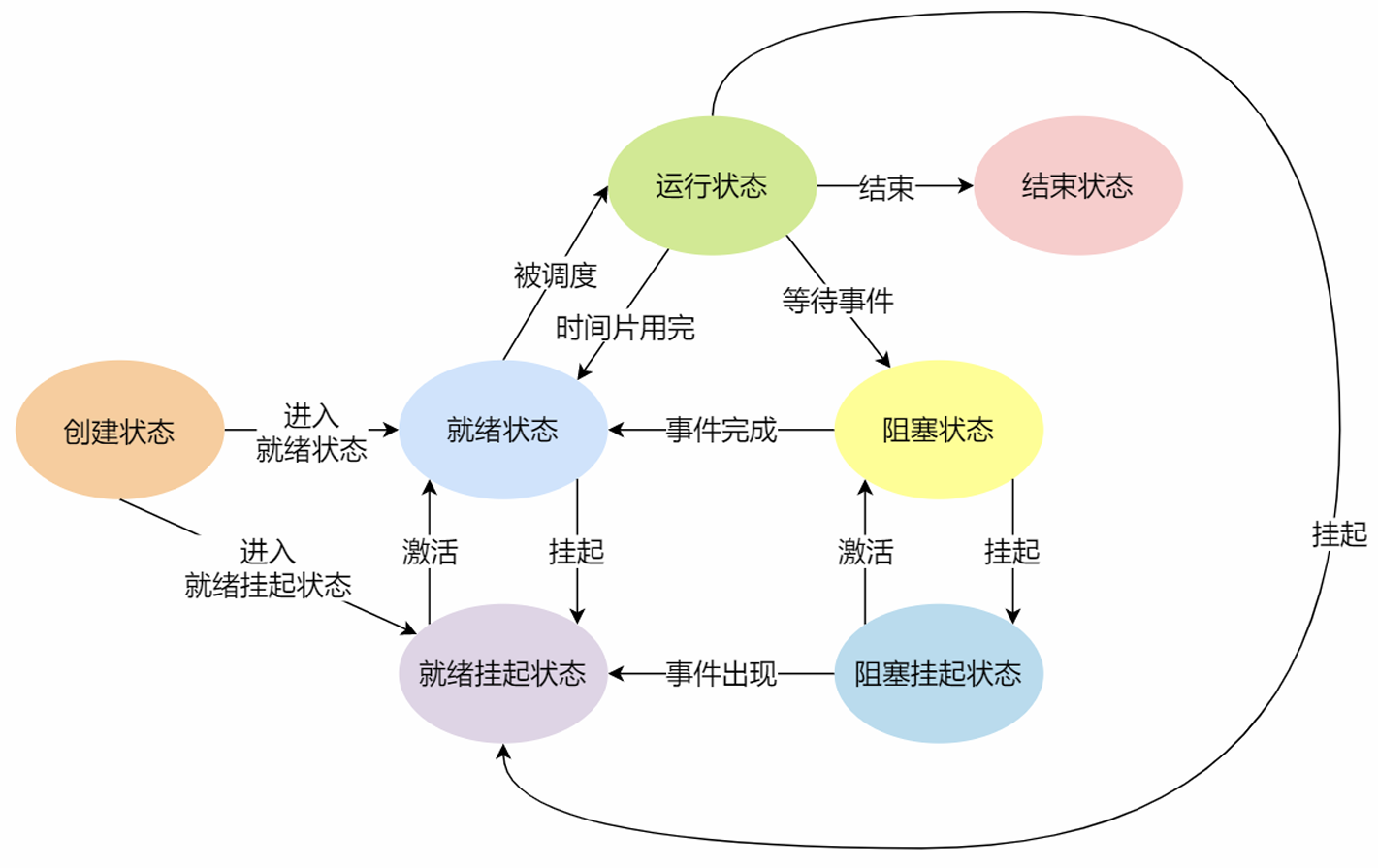
挂起状态:物理内存空间换出到硬盘,这个状态就是挂起状态。而阻塞状态是等待某个事件的返回(占用物理内存空间)
挂起状态可以分为两种:
阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现
就绪挂起状态:进程在外存(硬盘),但只要进入内存,就立刻运行
除此之外,还可以通过sleep()定时让进程挂起,Ctrl+Z也是一种方法。
2. 进程的控制结构
PCB:在操作系统中,用进程控制块(process control block)数据结构来描述进程。PCB是进程存在的唯一标识,每个进程都有一个PCB。
PCB包括的信息:
1. 进程描述信息:进程标识符、用户标识符
2. 进程控制和管理信息:进程当前状态(7种)、进程优先级
3. 资源分配清单:所打开的文件列表和使用的IO设备信息
4. CPU相关信息:CPU中各个寄存器的值
PCB通常通过链表的方式进行组织,具有相同状态的进程链在一起,组成各种队列。如就绪队列、阻塞队列。
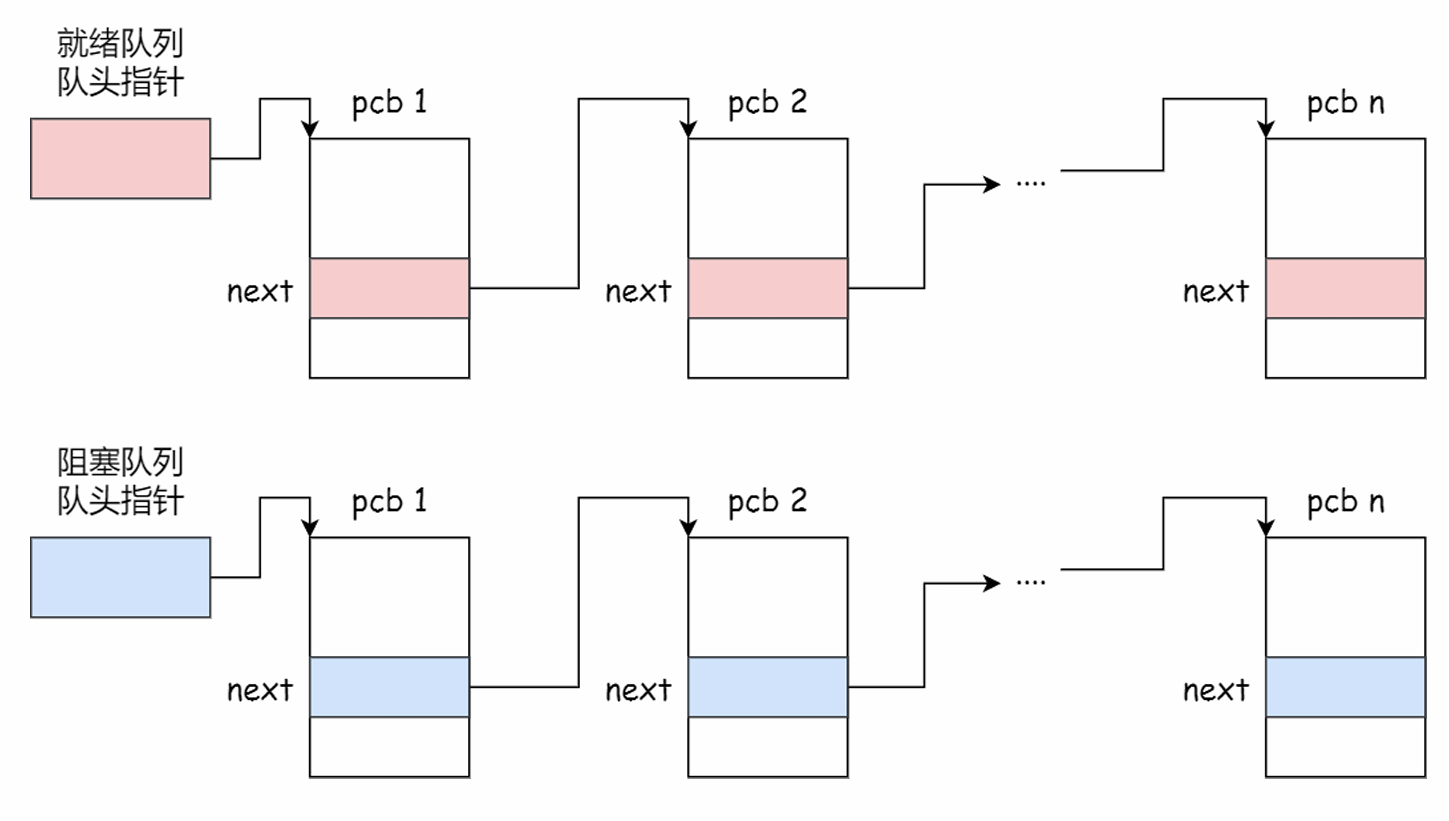
进程的上下文切换:
CPU 上下文:寄存器、程序计数器等在CPU运行任何任务前,所依赖的环境
CPU 上下文切换分成:进程上下文切换、线程上下文切换、中断上下文切换
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
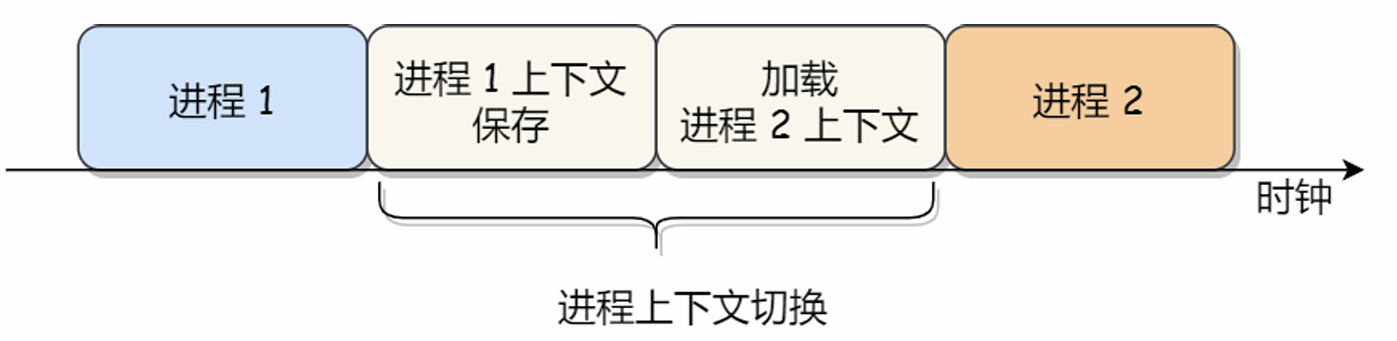
常见的进程上下文切换的场景:公平调度、内存不足、sleep()、优先级、硬件中断
3. 线程
线程间资源共享(但有私有的寄存器、栈),同一进程的线程都具有同一个页表
当两个线程不属于同一进程,线程上下文切换的过程就跟进程上下文切换一样。
用户线程:
不由内核维护,由用户态的线程库管理,多个用户线程对应同一个内核线程,操作系统不直接参与调度。
用户线程的优点:
每个线程都有私有的线程控制块(TCB)列表,用来跟踪记录它各个线程状态信息(PC、栈指针、寄存器),TCB由线程库函数来维护。
用户线程的切换由线程库函数来完成的,无需用户态与内核态的切换,速度特别快。
用户线程的缺点:
由于操作系统不参与调度,如果一个线程发起了系统调用而阻塞,那进程所包含的用户线程都不能执行。
一个线程开始运行后,除非它主动地交出CPU使用权,否则它所在的进程当中的其他线程无法运行,因为用户态的线程没法打断当前运行的线程的特权,只有操作系统才有。
由于时间片分配给进程,每个线程得到的时间片较少,执行会较慢。
内核线程:
由内核管理,用户线程和内核线程一对一。
内核线程的优点:
在一个进程当中,如果某个内核线程发起系统调用而被阻塞,并不会影响其他内核线程的运行。
分配给线程,多线程的进程获得更多的CPU运行时间。
内核线程的缺点:
内核维护进程和线程的上下文信息,如PCB和TCB。
线程的创建、终止、切换都是通过系统调用来进行,系统开销较大。
LWP轻量级进程:
轻量级进程 (Light-weight Process) 是一种由内核支持的用户线程,是基于内核线程的抽象,每个LWP由一个内核线程支持。一个LWP可以支持一个或多个用户线程。
根据1:1和N:1模式的混合搭配,可以形成M:N模型,兼具了内核线程和用户线程的优点。
4. 调度
调度算法分为两类:
非抢占式调度算法,一个进程运行到阻塞或退出,才调用另一个
抢占式调度算法,时间片机制
五种调度原则:
CPU 利用率:就绪队列在阻塞时,调度就绪的程序,确保CPU始终是匆忙的状态;
系统吞吐量:吞吐量表示单位时间内CPU完成进程的数量,长作业的进程会占用较长的CPU资源,降低吞吐量,高的吞吐量要靠调度程序来维护;
周转时间:周转时间是进程运行和阻塞时间的总和,进程的周转时间越小越好,则需要维护它阻塞的时间;
等待时间:这个等待时间不是阻塞状态的时间,而是进程处于就绪队列的时间,越短越好;
响应时间:用户提交请求到系统第一次产生响应所花费的时间,在交互式系统中,响应时间是衡量调度算法好坏的主要标准(就像用户键盘输入的响应)。
调度算法:
01 FCFS调度:先来后到,在单核CPU系统常见,对长作业任务有利。
02 SJF最短作业优先调度:Shortest Job First,对短作业有利,吞吐量会提高。
03 HRRN高响应比优先调度:Highest Response Ratio Next,先计算“响应比优先级”,然后把“响应比优先级”最高的进程投入运行。

04 RR时间片轮转调度:Round Robin,一般一个时间片会在20ms~50ms。
05 HPF最高优先级调度:Highest Priorrity First,分为静态优先级(创建进程就确定,后面不变)、动态优先级(随时间的推移提升等待进程的优先级),在处理时,也分为非抢占式和抢占式。
06 多级反馈队列调度:Multilevel Feedback Queue,是RR和HPF的综合和发展,每个队列优先级从高到低,优先级越高分配的时间片越短。
5. 进程间通信
管道:
匿名管道是特殊的文件,只存在于内存,不存于文件系统中,所谓的匿名管道,就是内核中的一串缓存。使用fork之后,描述符会复制,但是管道还是只有一个,为了避免混乱,关闭父进程的读端,关闭子进程的写端。
在Shell执行“A | B”命令时,A和B都是Shell的子进程。
命名管道,则需要用mkfifo创建一个管道文件,内容也缓存在内核。
管道不支持文件定位操作(如lseek)
消息队列:
消息队列是保存在内核中的消息链表(会涉及状态切换,注意开销),在发送数据时,会分成独立的数据单元,也就是消息体(数据块)。
发送方和接收方要约定好消息体的数据类型,每个消息体都是固定大小的,不像管道是无格式的字节流数据。如果进程从消息队列中读取了消息体,内核就会把这个消息体删除。消息队列生命周期随内核,匿名管道随进程。
不足:
消息队列不适合比较大的数据的传输,在Linux内核中,会有两个宏定义MSGMAX 和 MSGMNB ,以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。
共享内存:
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。
信号量:
信号量相当于一个整型的计数器,用于实现进程间的同步和互斥,分为P操作、V操作
自旋锁、互斥锁:
自旋锁,当获取不到锁时,线程会一直忙等待(自旋),直到拿到锁(是通过CAS函数在用户态就完成操作)。
互斥锁,当拿不到锁,会让给拿到锁的线程(涉及到状态切换)。
读写锁、乐观锁、悲观锁:
读写锁:“读锁、写锁”,可以同时读,但是只能有一个人写,也分为“读优先锁”(并发性好)和“写优先锁”(不会饿死)。
乐观锁:假定冲突率很低,先让修改,再检验是否冲突,若冲突,则放弃本次操作(全程没加锁,无锁编程)。
悲观锁:认为冲突率很高,访问共享资源前,先上锁。
哲学家就餐:
方案一:信号量,可能死锁,所有哲学家同时拿左手的刀叉。
方案二:信号量 + 互斥锁,效率低。
方案三:信号量 + 偶数先拿左、奇数先拿右,避免死锁。
方案四:信号量 + 互斥锁 + state数组,一个哲学家只有在两个邻居都没有进餐时,才可以进入进餐状态。
五、调度算法
1. 进程调度算法
(四、进程与线程 部分讲到过...)
2. 内存页面置换算法
缺页异常(缺页中断):
当CPU访问的页面不在物理内存RAM时,会产生一个缺页中断,请求操作系统将所缺页调入到物理内存。
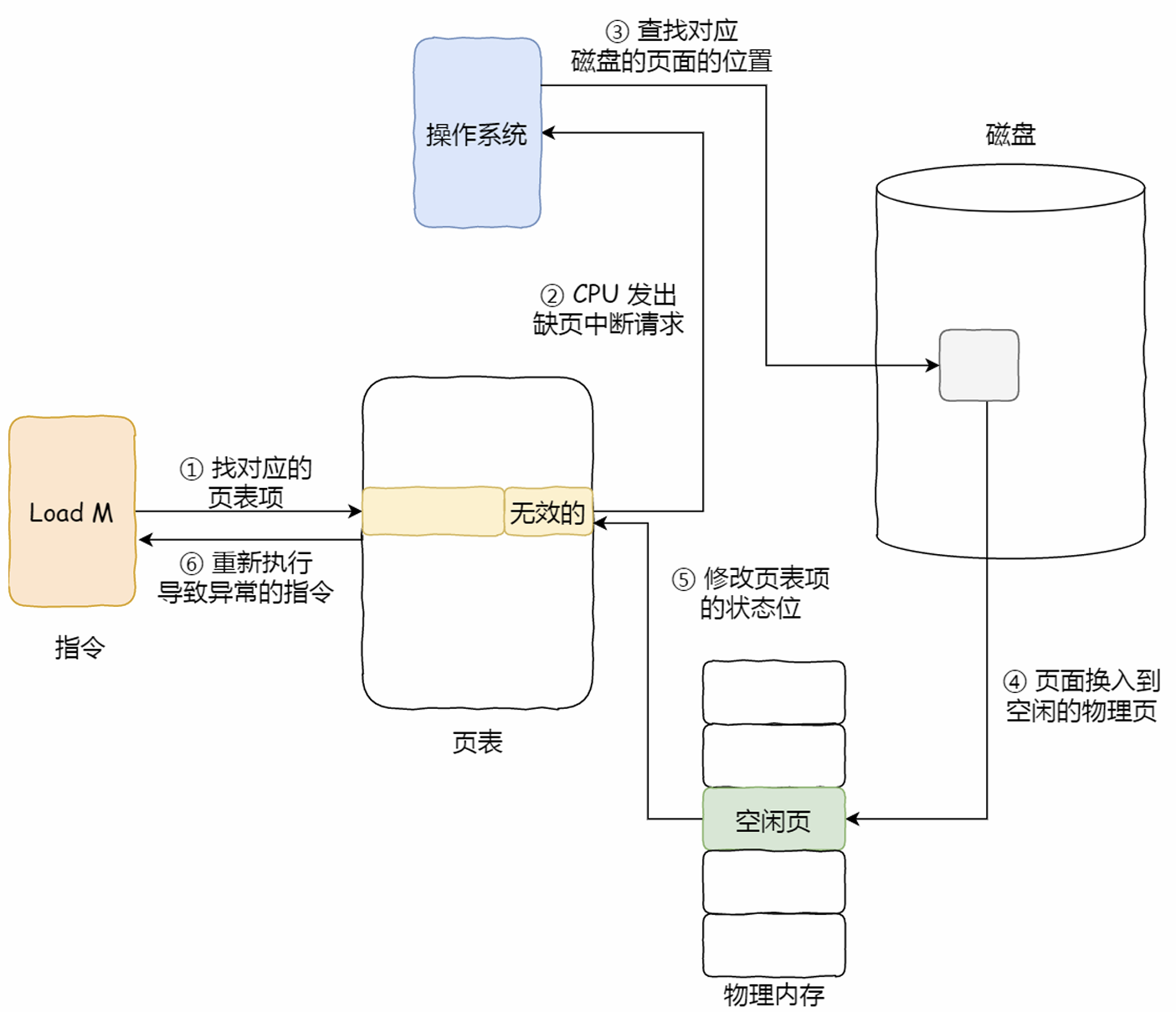
而④就是页面置换的过程(找不到空闲页,说明内存已满,页面置换算法通过选择一个物理页,如果是修改过的“脏页”,就把它换出到磁盘并修改为“无效的”状态,然后把正在访问的页面装进这个物理页)。

最佳页面置换算法:计算“未来”最长不访问的页面(实现不了,只做为标准)
先进先出置换算法:置换驻留最久的页面,简单粗暴
最近最久未使用的置换算法LRU:置换已有的页面中最久没有被访问的
LRU通过维护一个所有页面的链表来实现(用的多的在表头),在每次访问内存时都必须要更新“整个链表”(主要在寻找已分配的页),开销大。
时钟页面置换算法:所有的页面都保存在一个类似钟面的“环形链表”
表针指向最老的页面。要置换时,查看页面的访问位,如果是0,那么置换,表针前移。如果是1,清除访问位,表针向前直到找到一个访问位为0的。
最不常用算法LFU:选择访问次数最少的
需要添加一个计数器,效率低。
3. 磁盘调度算法:
磁盘的结构和需要优化的问题:
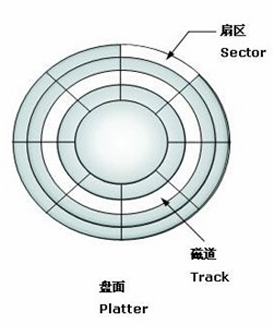
寻道的时间是磁盘访问最耗时的部分,如果请求顺序优化的得当,必然可以节省⼀些不必要的寻道时间,从而提高磁盘的访问性能。
先来先服务算法:简单粗暴
最短寻道时间优先算法SSF:优先找离当前磁头最近的
可能存在某些请求的饥饿。
扫描算法:磁头一个方向移动,最后掉头
磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向。
不足:中间部分的磁道会比较占便宜,每个磁道的响应频率存在差异。
循环扫描算法:只响应一个方向的,最后快速复位(复位时不响应)
相比于扫描算法,对于各个位置磁道响应频率相对比较平均。
LOOK 与 C-LOOK算法:磁头只移动到最远的请求,然后立即返回
LOOK是对扫描算法的优化,返回时会响应。C-LOOK是对循环扫描算法的优化,返回时不响应。
六、文件系统
1. 文件系统的基本组成
磁盘对数据进行持久化的保存。Linux文件系统中,给每个文件分配两个数据结构:索引结点(inode)、目录项(dentry)。
索引结点:文件的唯一标识,存储在硬盘
用来记录文件的元信息,比如inode编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置 等。
目录项:内核维护,缓存在内存
记录文件的名字、索引结点指针、与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构。
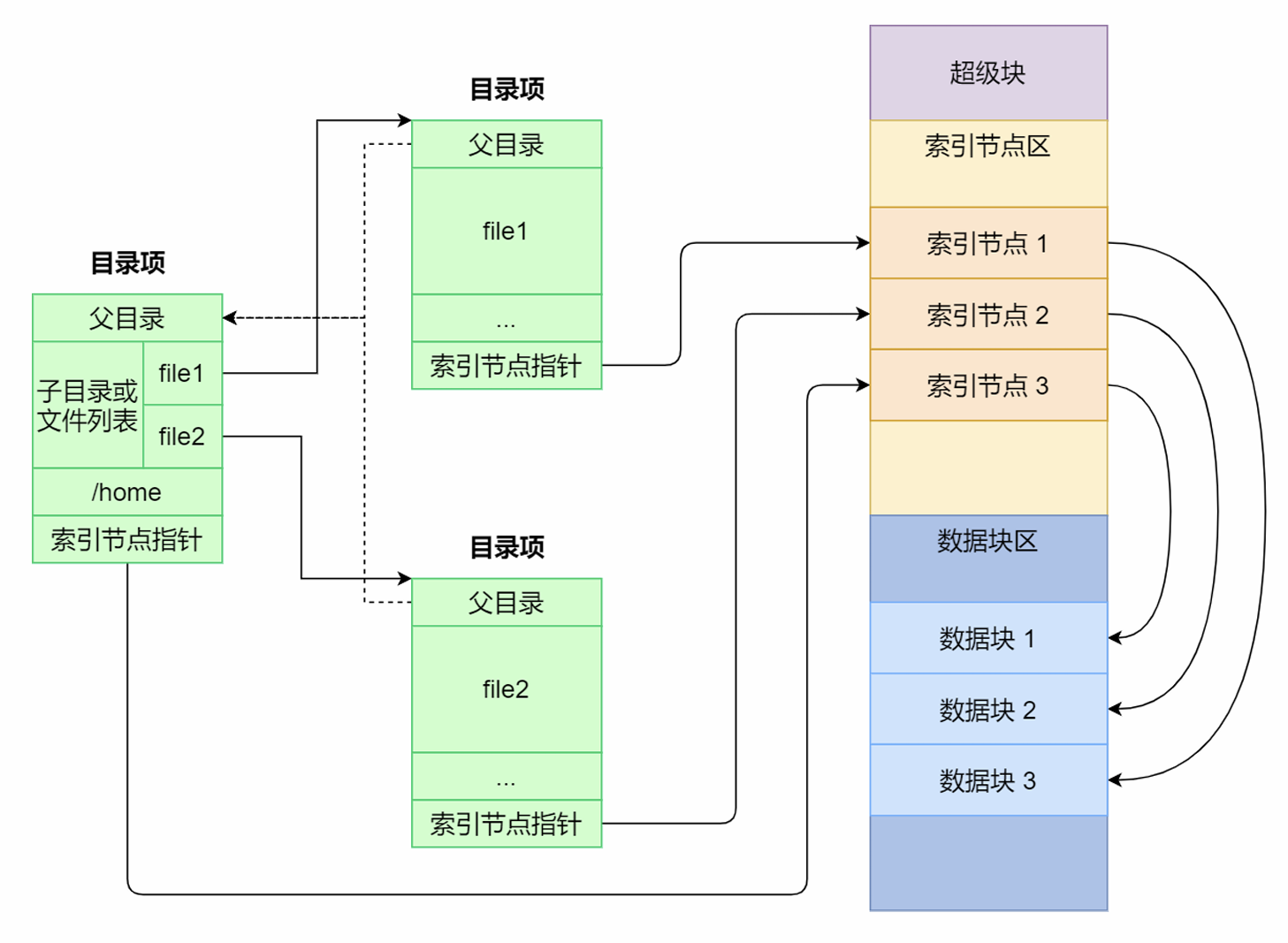
超级块在文件系统挂载时进入内存,索引结点区在文件被访问时进入内存。
2. 文件的使用
操作系统在打开文件表中维护着打开文件的状态和信息:
文件指针:系统跟踪上次读写位置作为当前文件的位置指针;
文件打开计数器:文件关闭时,操作系统必须重用其打开文件表条目,否则表内空间不够用。因为多个进程可能打开同一个文件,所以系统在删除打开文件条目之前,必须等待最后一个进程关闭文件,系统关闭文件,删除该条目;
文件磁盘位置:该信息保存在内存中,以免每个操作都从磁盘中读取;
访问权限:创建、只读、读写、添加等,该信息保存在进程的打开文件表中,以便操作系统能允许或拒绝之后的 I/O 请求。
3. 文件的存储
连续空间存放方式:
读写效率高,不足:连续分配的磁盘碎片、文件动态扩展很麻烦。
非连续空间存放方式:
链表方式:
隐式链表:在数据块中留出一个指针空间
“隐式链表”,实现的方式是文件头要包含“第一块”和“最后一块”的位置,并且每个数据块里面留出一个指针空间,用来存放下一个数据块的位置。
不足:无法直接访问数据块,只能通过指针顺序访问文件,以及数据块指针消耗了存储空间。隐式链接分配的稳定性较差,链表中的指针丢失或损坏,会导致文件数据的丢失。
显式链表:文件分配表
把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
内存中的这样一个表格称为文件分配表(File Allocation Table,FAT)。
查找记录的过程是在内存中进行,主要缺点是不适用于大磁盘(表会很大)。
索引方式:
文件头包含指向“索引数据块”的指针,这样就可以通过文件头知道索引数据块的位置,再通过索引数据块里的索引信息找到对应的数据块。
不足:存储索引带来的开销。
链式索引块:
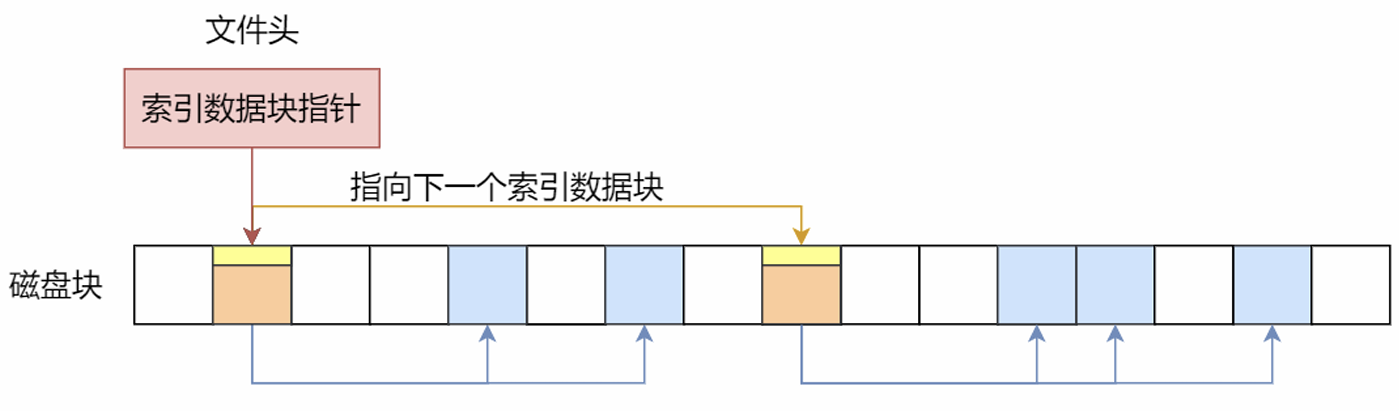
多级索引块:
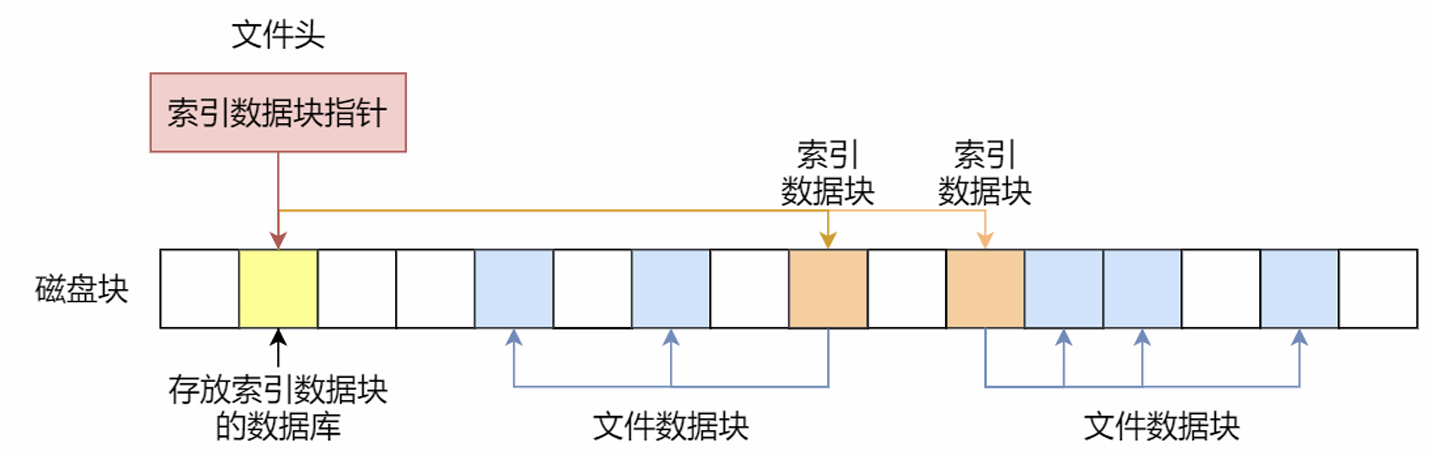
4. 空闲空间管理
空闲表法:
表的内容包括:空闲区的第一个块号、块数。
分配时,扫描表找空闲位置。删除文件时,扫描表添加字段。
不足:有大量小的空闲区时,表会很大。
空闲链表法:
只用保存链表头指针,指向第一个空闲块。
不足:不能随机访问,效率较低。
位图法:Linux文件系统采用的方法
利用二进制中的一位来表示磁盘中一个盘块的使用情况,0空闲,1已分配。
比如:1111111111001011010010101001...
5. 软链接和硬链接
硬链接是不可用于跨文件系统的,软链接可以(文件的内容是另一个文件的路径)。
6. 文件I/O
缓冲与非缓冲I/O:
缓冲I/O,利用标准库的缓冲实现文件的加速访问,而标准库再通过系统调用访问文件。
非缓冲I/O,直接通过系统调用访问文件。
直接与非直接I/O:
直接I/O,用户直接经过文件系统访问磁盘。
非直接I/O, 读操作时,从内核缓存中拷贝给用户程序,写操作时,从用户程序拷贝给内核缓存,由内核决定什么时候写数据到磁盘。
使用文件操作类的系统调调函数时,指定了O_DIRECT标志,表示使用直接I/O。

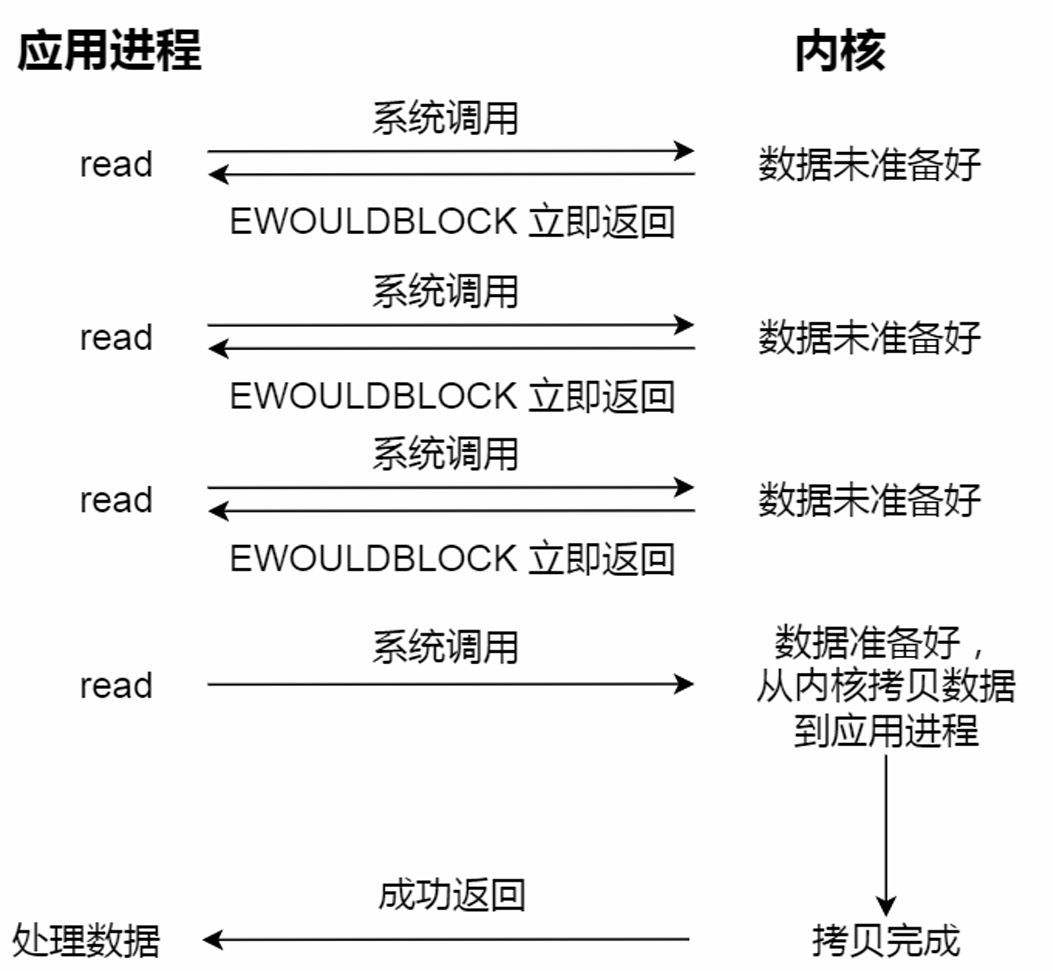
阻塞与非阻塞I/O VS 同步与异步I/O:
同步I/O:阻塞I/O、非阻塞I/O、基于非阻塞I/O的多路复用
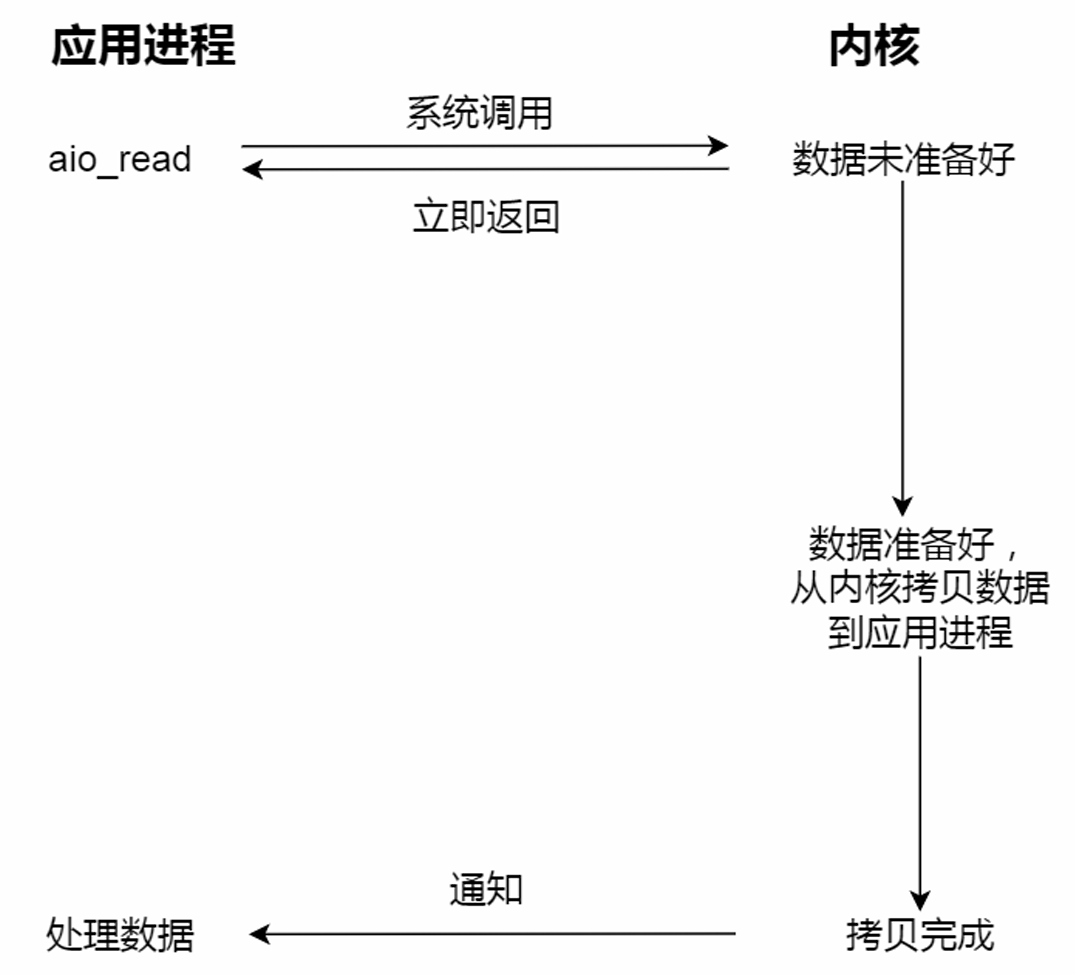
异步I/O:异步I/O(aio_read)
无论是阻塞I/O、非阻塞I/O,还是基于非阻塞I/O的多路复用都是同步调用。它们在read调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的。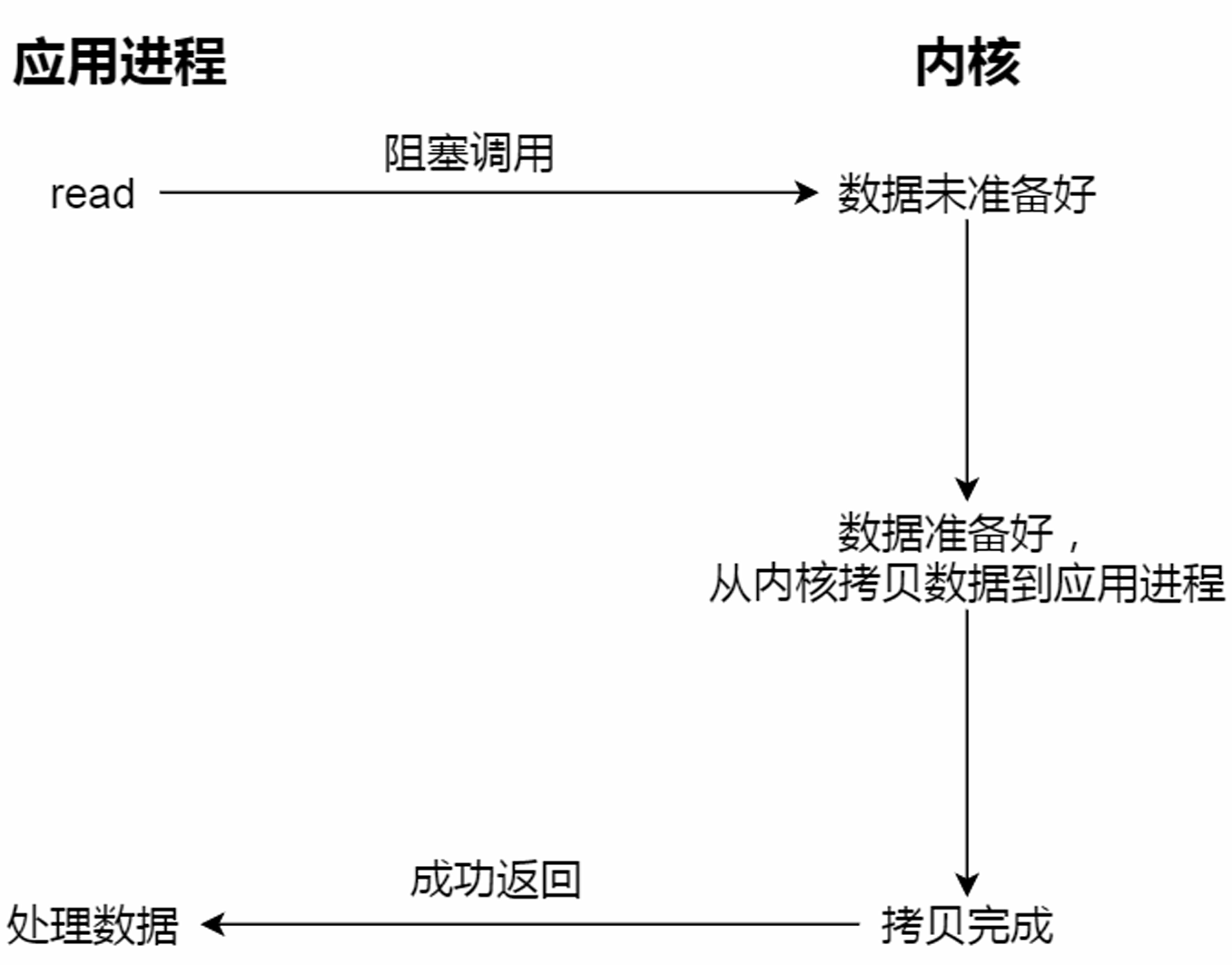
真正的异步I/O是“内核数据准备好”和“数据从内核态拷贝到用户态”这两个过程都不用等待。
当发起aio_read之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不⼀样,应用程序并不需要主动发起拷贝。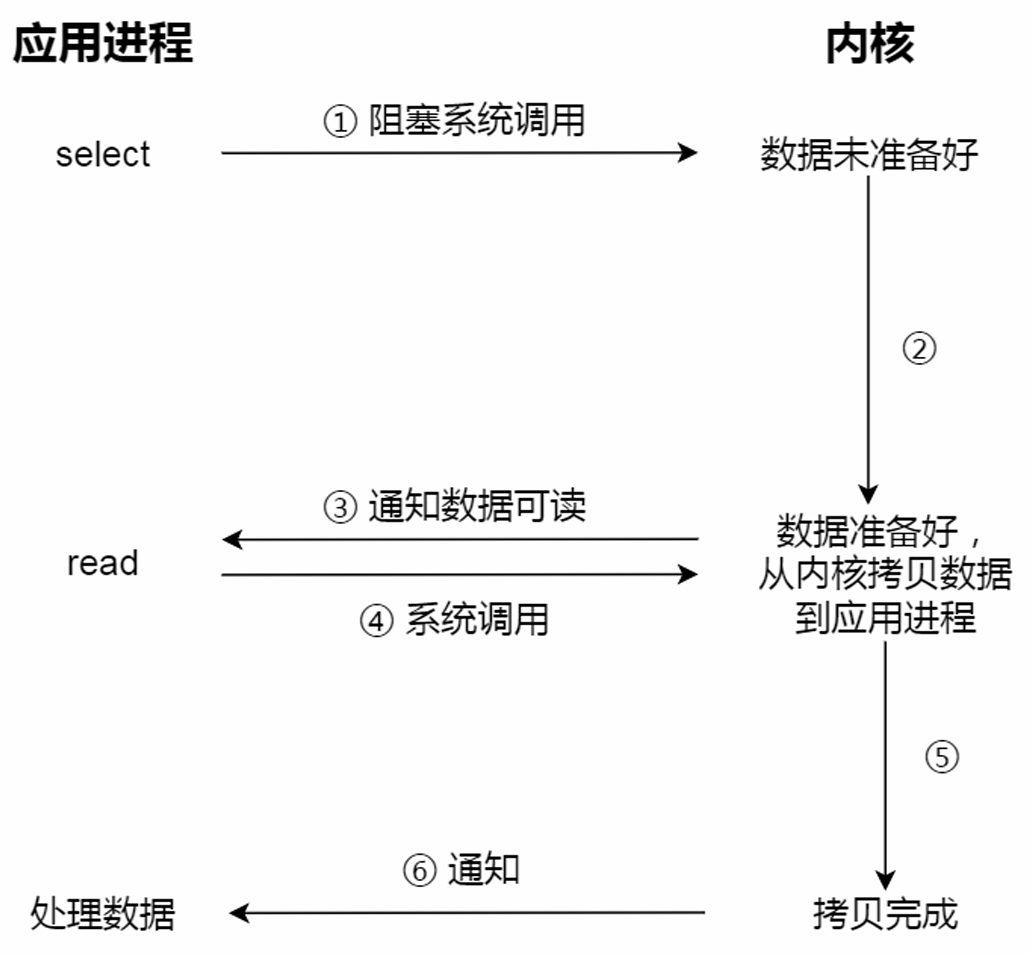
七、设备管理
1. 设备控制器
设备控制器:
为了屏蔽设备之间的差异,每个设备都有一个设备控制器(Device Control)。
设备控制器里有芯片,可执行自己的逻辑,也有自己的寄存器,用来与CPU进行通信,相当于一个小CPU。
控制器有三类寄存器,分别是状态寄存器(Status Register)、 命令寄存器(Command Register)、数据寄存器(Data Register)。
输入输出设备的分类:
像硬盘、USB等,把数据存放在固定大小的块中,每个块有自己的地址的是块设备。
像鼠标,以字符为单位收发一个字符流,不可寻址、不可寻道的是字符设备。
块设备传输的数据量会比较大,控制器设立了一个可读写的数据缓冲区(囤够了才会进行下一步操作)
CPU与设备寄存器、数据缓冲区通信:
端口I/O:每个控制寄存器被分配一个I/O端口,可以通汇编指令操作这些寄存器,比如in/out指令。
内存映射I/O:将所有控制寄存器映射到内存空间中,这样就可以像读写内存一样读写数据缓冲区。
2. 设备驱动程序
虽然设备控制器屏蔽了设备的众多细节,但每种设备的控制器的寄存器、缓冲区等使用模式都是不同的,为了排除“设备控制器”的差异,引入了设备驱动程序。
通常,设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数。
通用块层:
通用块层是处于文件系统和磁盘驱动中间的一个块设备抽象层:
第一功能,向上为文件系统、应用程序,提供访问块设备的接口,向下把不同的磁盘设备抽象为块设备,在内核层面,提供一个框架来管理这些驱动程序;
第二功能,还会给文件系统、应用程序发来的I/O请求排队,接着会对队列重新排序、请求合并等方式,提高磁盘读写的效率。
为提高文件访问的效率,会使用页缓存、索引节点缓存、目录项缓存等多种机制,目的是减少对块设备的直接调用。
八、网络系统
1. DMA技术
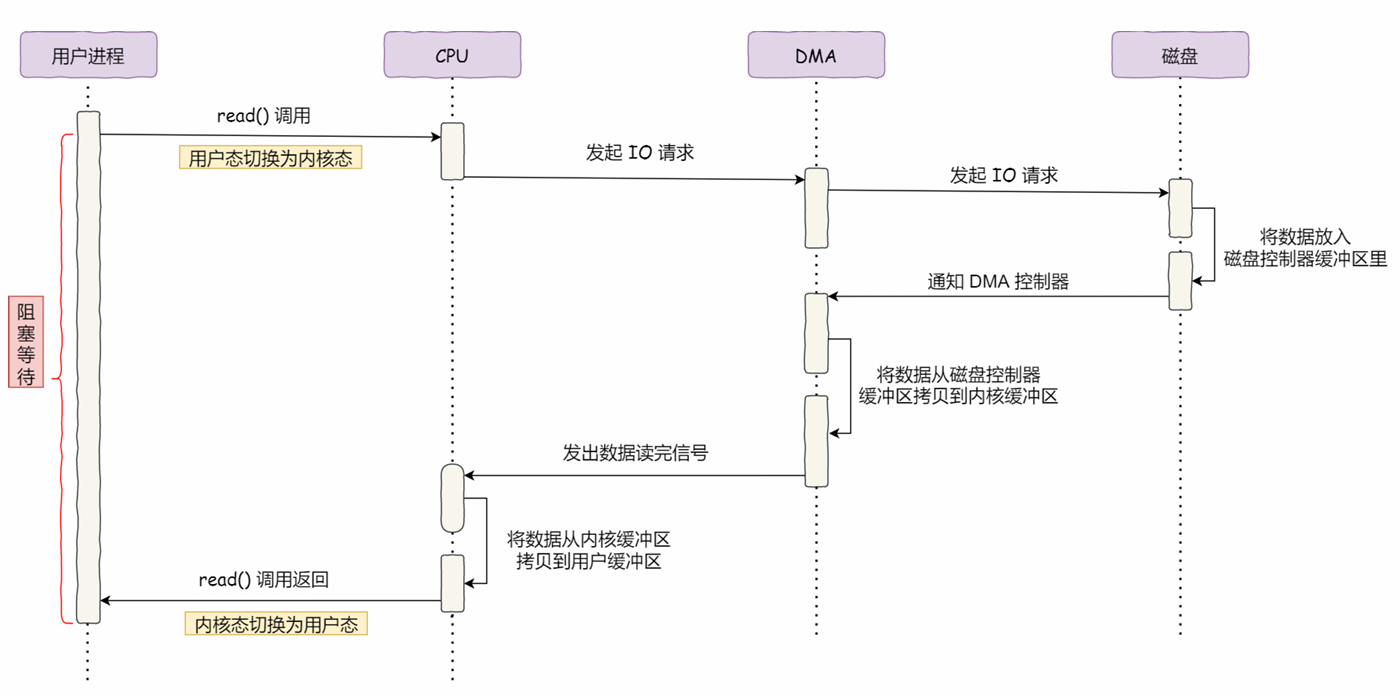
在没有DMA技术之前,I/O的过程时如下:
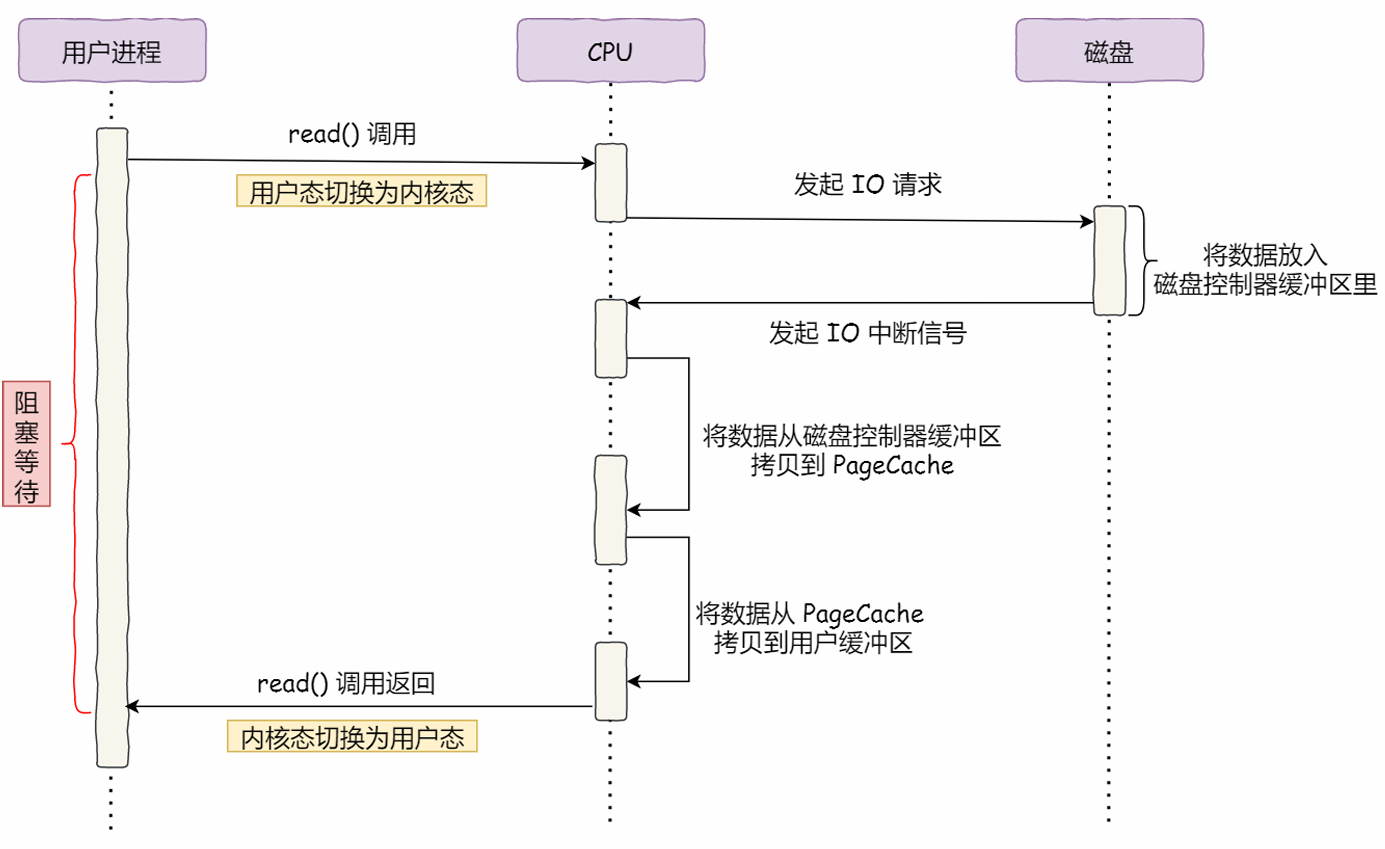
整个过程都需要占用CPU,当我们需要搬运大量数据时,肯定忙不过来。而DMA(Direct Memory Access)可以直接访问内存,早期的DMA只存在于主板上,而现在,每个I/O设备都有自己的DMA控制器。
2. 零拷贝技术
要在服务器读取并发送文件到客户端:
要在服务器端读取数据并通过网络协议发送到客户端,传统:4次数据拷贝(磁盘文件->内核->用户->socket缓存->网卡)。
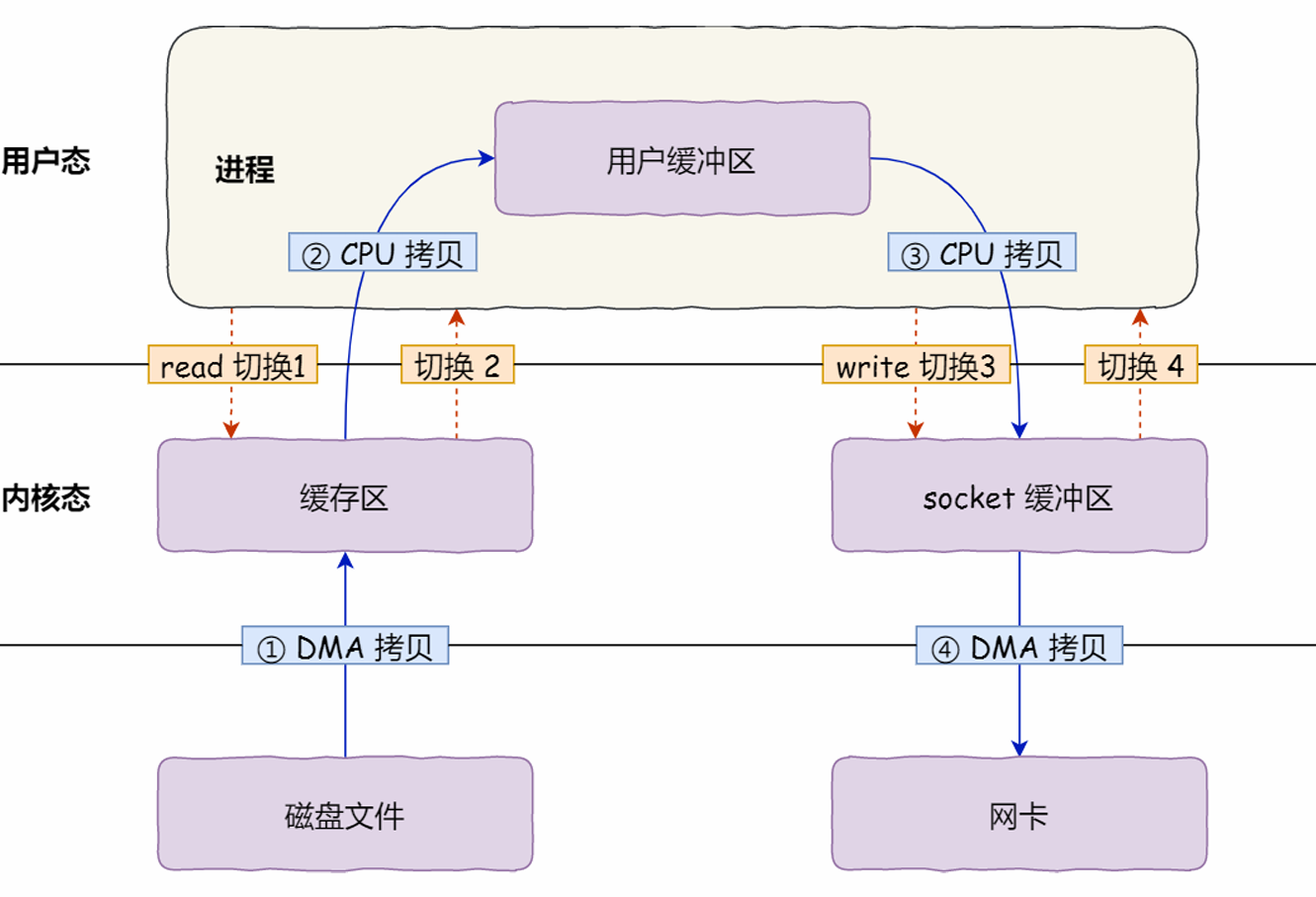
而在这其中,文件通常并不会在用户空间被加工(因为是文件传输),所以到用户缓冲区是没必要的。
实现零拷贝的两种方式:
mmap + write(CPU参与,拷贝3次,上下文切换4次):
mmap()系统调用代替read(),会把内核缓冲区的数据“映射”到用户空间,如此就减少一次拷贝操作。mmap映射之后,应用进程和内核共享这个缓冲区,进程再使用write()直接写内容到socket缓冲区,一切都发生在内核态。
sendfile(CPU参与,拷贝3次,上下文切换2次):
Linux2.1中提供了专门发送文件的系统调用,sendfile()可以代替read()和write(),减少一次系统调用,直接把内核缓冲区的数据拷贝到socket缓冲区中,减少了2次上下文切换的开销。
SG-DMA(CPU不参与,拷贝2次,上下文切换2次):
对于网卡支持SG-DMA技术的情况下,sendfile具体过程:
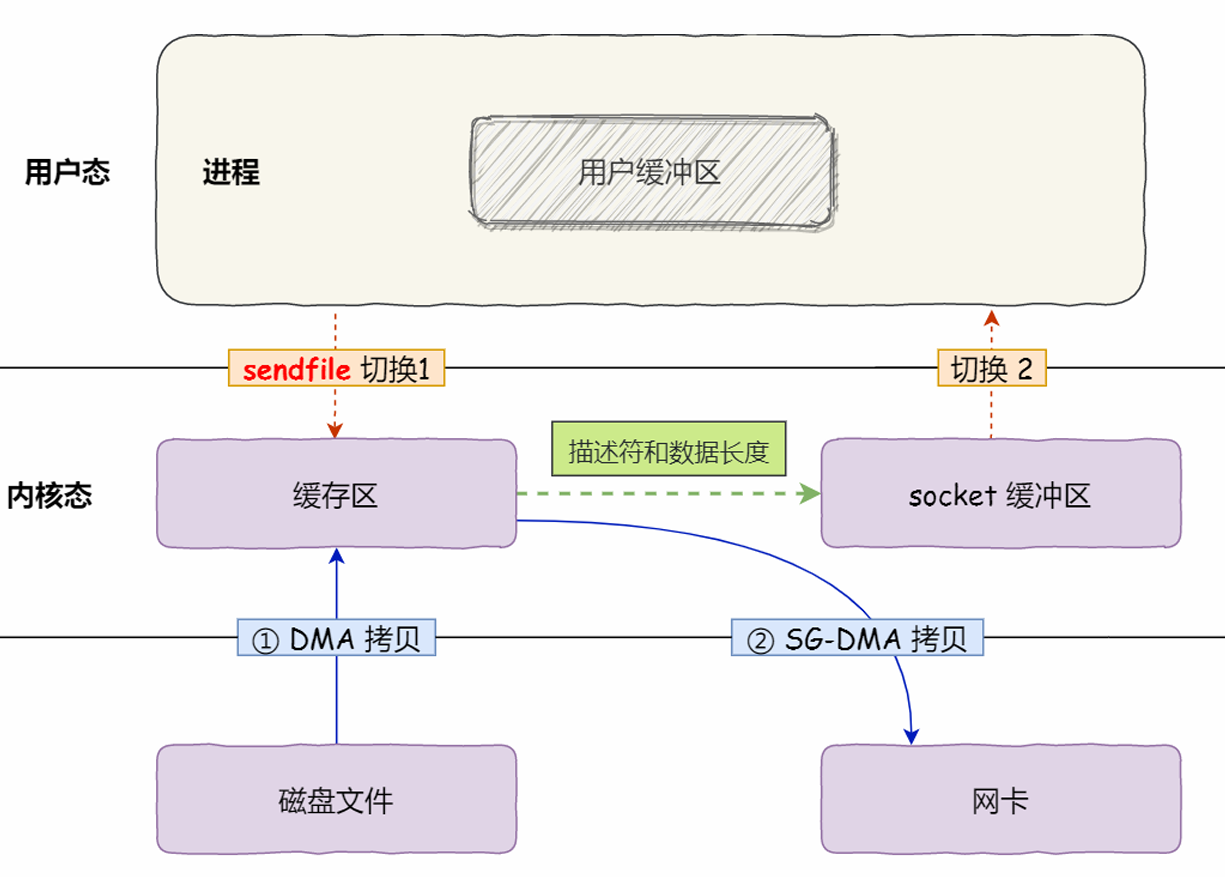
这就是零拷贝(Zero-copy)技术,没有在内存层面去拷贝数据,也就是说全程没有通过CPU来搬运数据,所有的数据都是通过DMA来进行传输的。零拷贝可以把文件传输性能提升一倍以上。
3. PageCache(一种磁盘高速缓存)
上面所说的“内核缓冲区”,实际上是指磁盘高速缓存(PageCache)。
PageCache 的优点主要是两个:缓存最近被访问的数据(优先从PageCache找,找不到再去磁盘读到PageCache)、预读功能(读取要求之外的数据,如果后面读到,就会非常快)。
传输GB级别的文件时,大文件难以命中PageCache,不能使用零拷贝。
原因:
PageCache由于长时间被大文件占据,其他“热点”的小文件可能就无法充分使用到PageCache,于是磁盘读写的性能就会下降;
4. 异步I/O机制
传输大文件应该使用的方式:异步I/O + 直接I/O
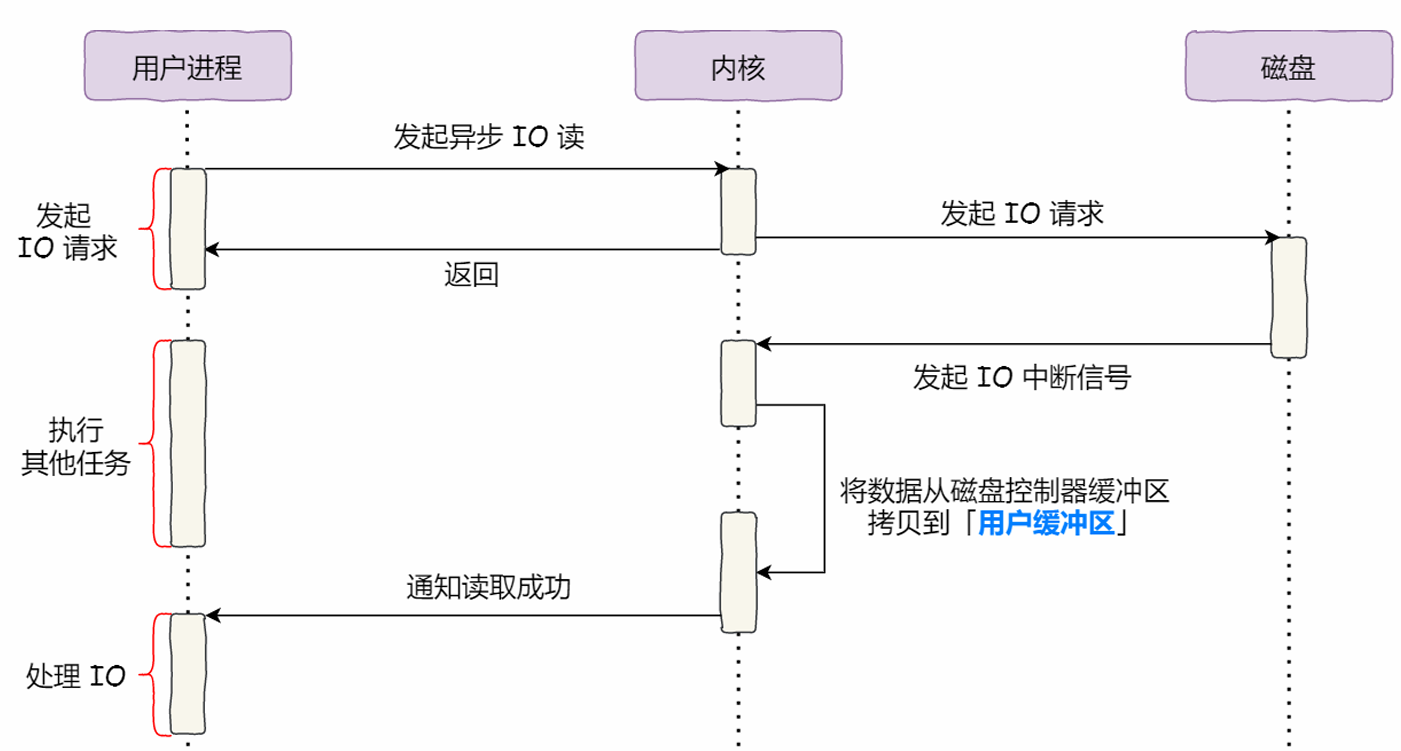
绕开PageCache的I/O叫直接I/O,使用PageCache的I/O叫缓存I/O。
5. 高性能网络模式:Reactor和Proactor
不再为每个连接创建线程,而是创建一个“线程池”,将连接分配给线程,然后一个线程可以处理多个连接的业务,实现“资源复用”。
Reactor是非阻塞同步网络模式,监听的是就绪的可读写事件;Proactor是异步网络模式, 监听的是已完成的读写事件。
Reactor模式(Dispatcher模式):
I/O多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程/线程。
Reactor模式由Reactor和处理资源池组成:
(1) Reactor负责监听和分发事件,包括连接事件、读写事件;
(2) 处理资源池负责处理事件,如read->业务逻辑->send;
Reactor可以是一个或多个,处理资源池也可以是单线程(进程)或多线程(进程),具体看业务。
6. 三个经典的Reactor方案
单Reactor单进/线程:
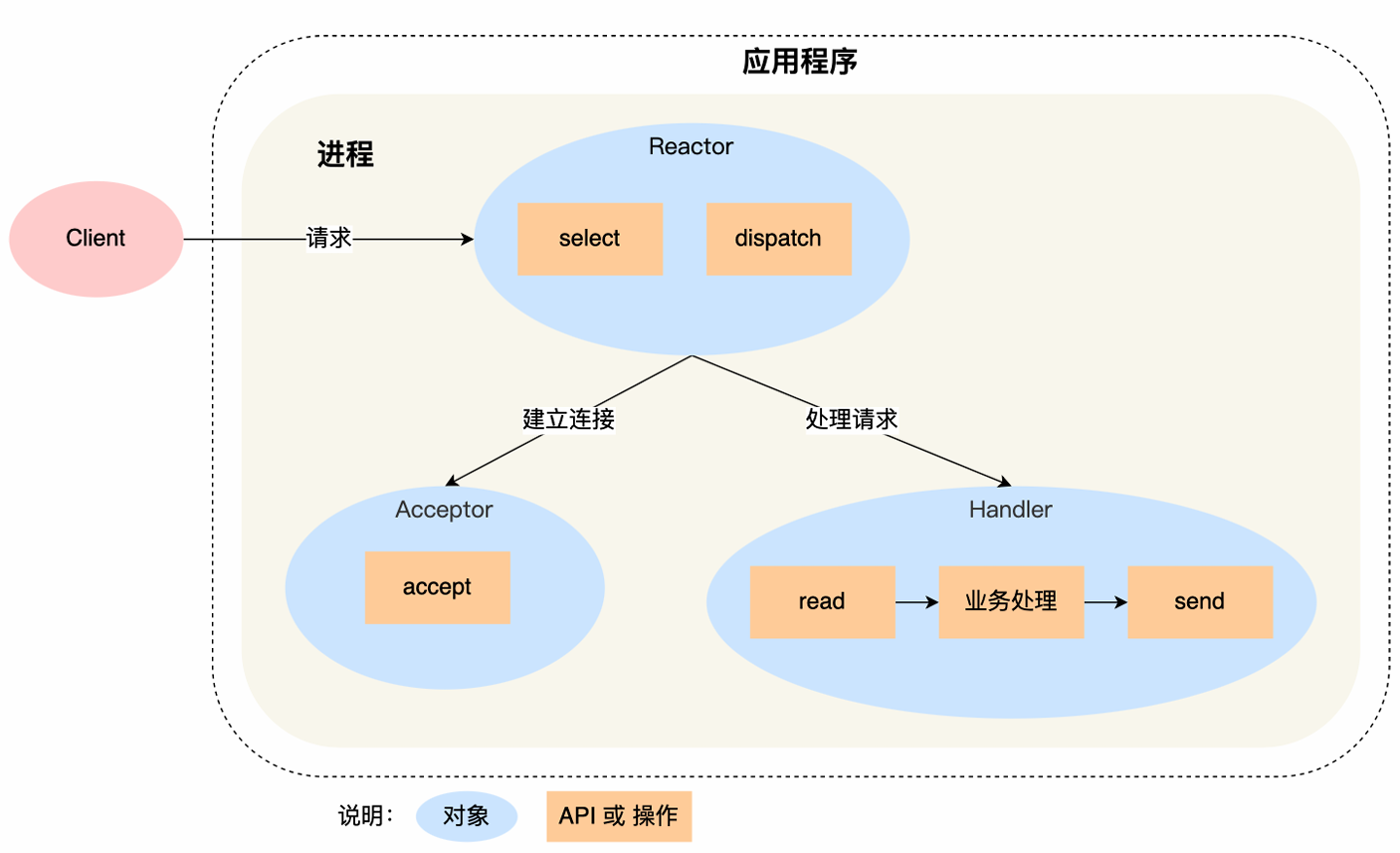
所有的工作都在同一个进程中完成,实现起来简单,不用考虑进程间通信,也不用担心多进程进程竞争。
缺点:
(1)无法充分利用多核CPU的性能
(2)响应延迟(串行任务处理)
单Reactor多进/线程:
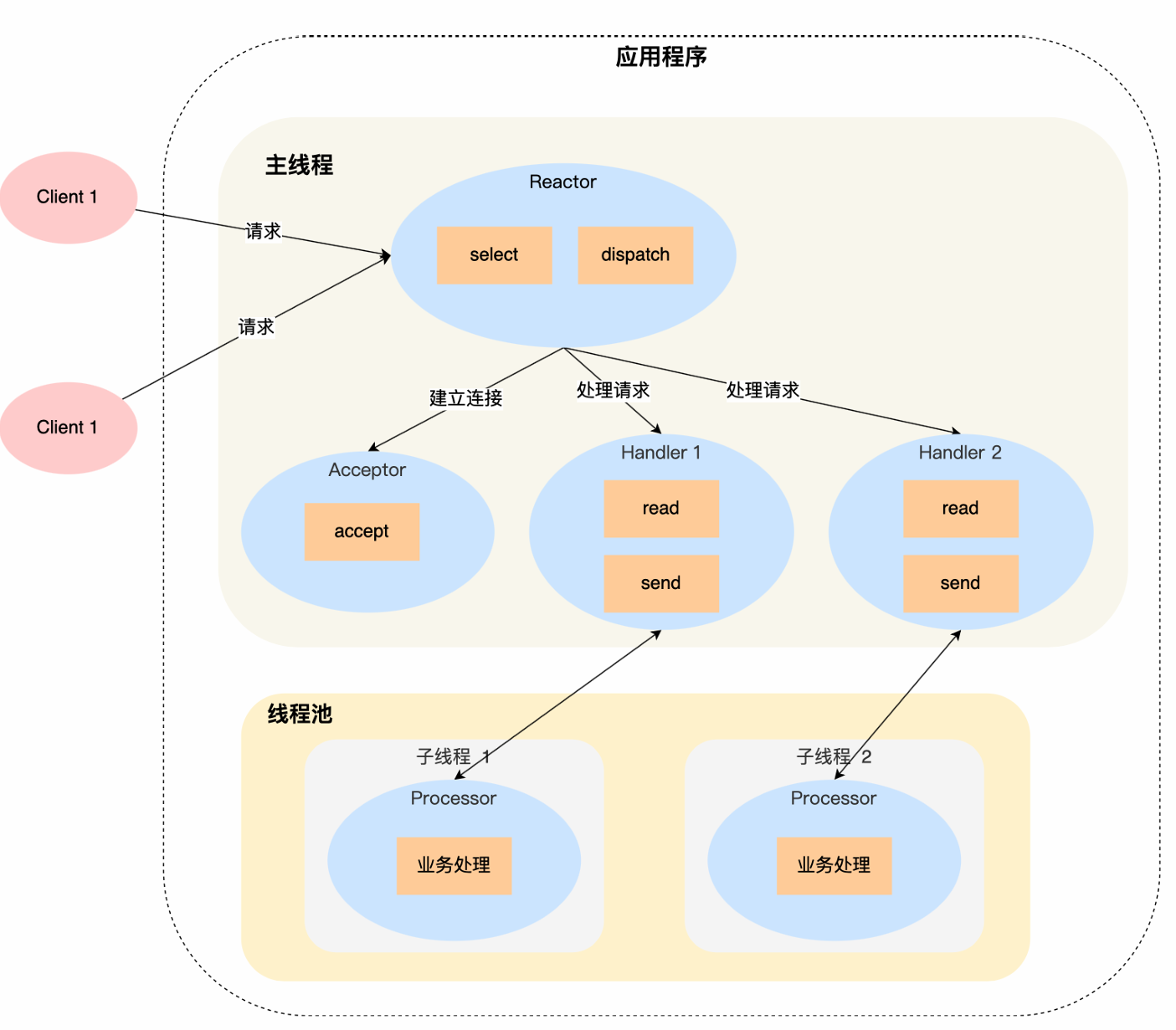
与单Reactor单线程不同的是,Handler只负责数据的收发,业务处理会交给子线程的Processor对象。
一些不足:
(1)这个方案充分利用了多核CPU的性能,不过多线程,就不可避免带来了资源竞争的问题。所以在一个线程在操作共享资源时,就要加上互斥锁。
(2)一个Reactor对象承担所有的事件监听和响应,而且只在主线程运行,面对瞬间高并发的场景时,容易有性能瓶颈。
多Reactor多进/线程:
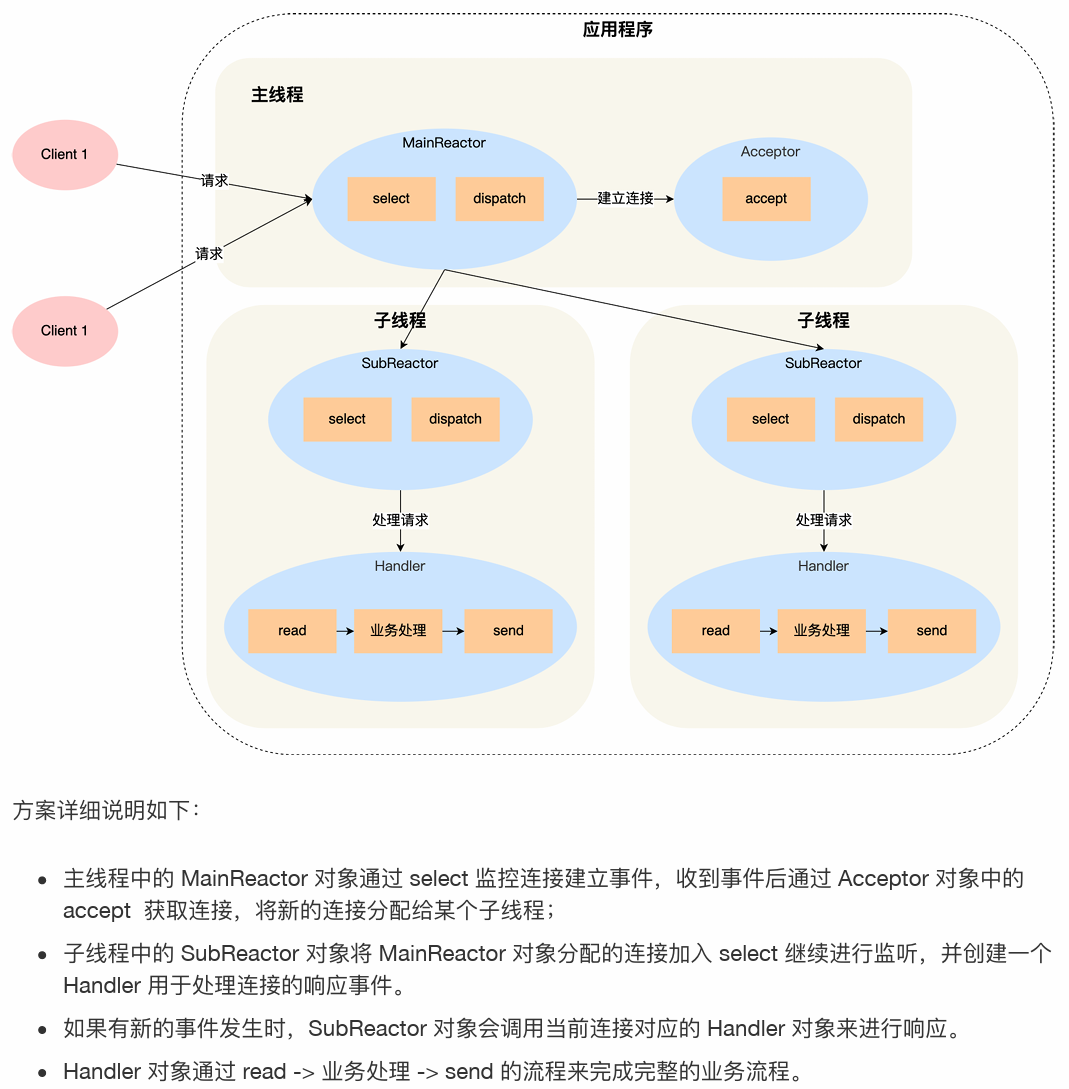
(1)主线程、子线程分工明确,主线程只接收新连接,子线程处理业务。
(2)主线程、子线程之间的交互很简单,主线程只需要把连接传递给子线程,子线程处理好后直接发送给客户端。
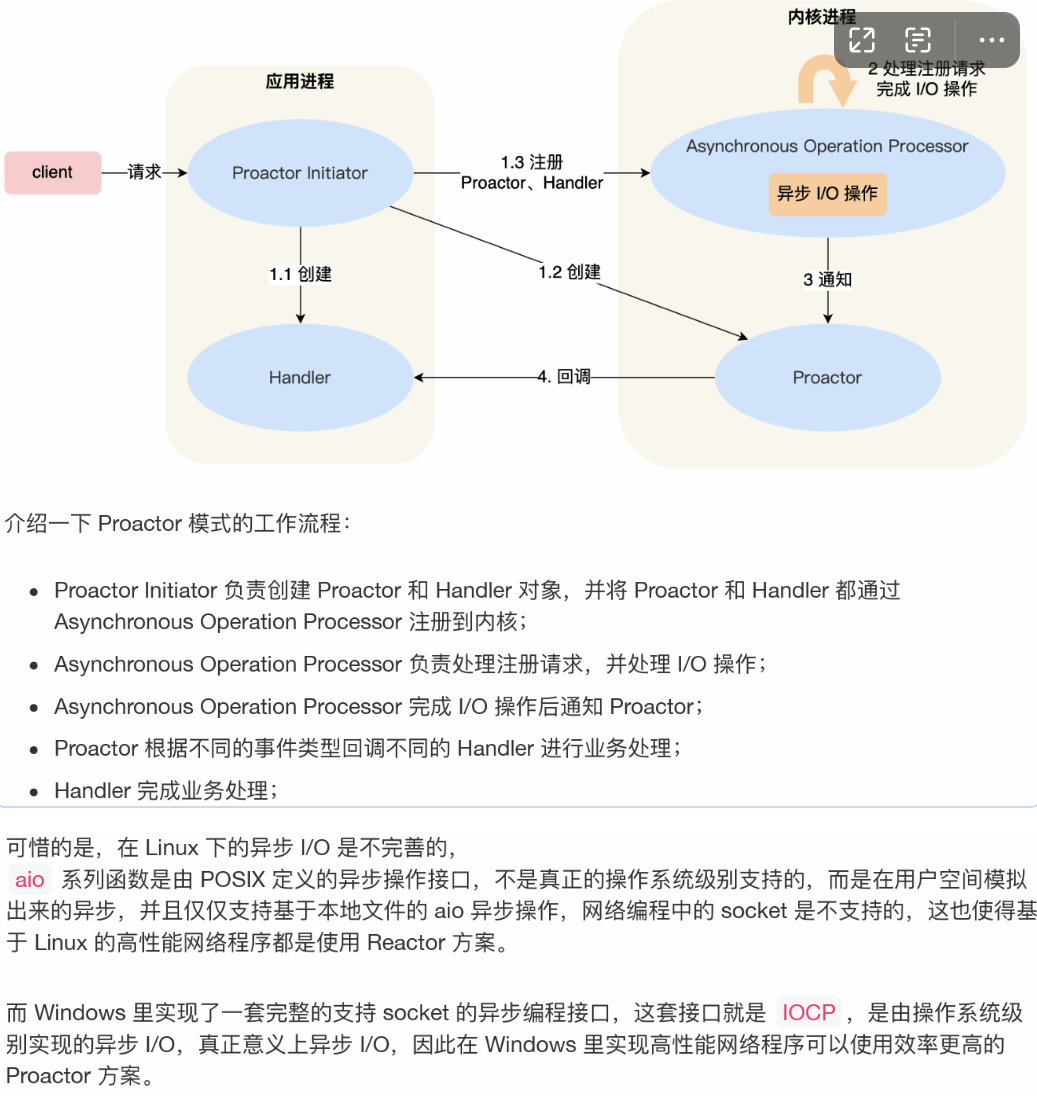
7. Proactor
Proactor是异步网络模式,感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用于存放结果),系统内核读写完数据之后,才会通知应用进程来处理数据。
九、网络性能指标
四个基本指标:
带宽,链路的最大传输速率,单位是b/s(比特/秒),带宽越大传输能力越强。
延时,表示请求数据包发送后,收到对端响应所需要的时间延迟。
吞吐率,表示单位时间内成功传输的数据量,单位是b/s(比特/秒)或者B/s(字节/秒),吞吐率受带宽限制,带宽越大,吞吐率的上限才可能越高。
PPS,Packet Per Second(包/秒),表示以网络包为单位的传输速率,一般用来评估系统对于网络的转发能力。
其他指标:
网络的可用性,表示网络能否正常通信;
并发连接数,表示TCP连接数量;
丢包率,表示所丢失数据包数量占所发送数据组的比率;
重传率,表示重传网络包的比例;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 51
51 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)