Python 正则表达式
第1关:正则表达式基础知识任务描述本关任务:编写代码,通过re.findall()模块匹配内容相关知识正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,来筛选出符合这个规则的内容。可以简单理解为:一个强大的搜索工具中,正则表达式就是你要搜索内容的条件表达式。为了完成本关任务,你需要掌握:1.正则模块函数re.findall(),2
第1关:正则表达式基础知识
任务描述
本关任务:编写代码,通过re.findall()模块匹配内容
相关知识
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,来筛选出符合这个规则的内容。
可以简单理解为:一个强大的搜索工具中,正则表达式就是你要搜索内容的条件表达式。
为了完成本关任务,你需要掌握:1.正则模块函数re.findall(),2.各种正则表达式元字符的含义。
以下实例均可在命令行窗口中练习。
re.findall()函数
作用:遍历整个字符串,可以获取其中所有匹配的字符串,返回一个列表。
一般用法:
re.findall(r’正则表达式’,‘要匹配的文本’)
从小练习接触正则
从字符串中匹配单词to:
import re
text = "0537-146987425,0537-299656897,The moment you think about giving up,think of the reason why you held on so long. Total umbrella for someone else if he, you’re just not for him in the rain.Never put your happiness in someone else’s hands.Sometimes you have to give up on someone in order to respect yourself. aaaa bbbbcc d dddddd"
print(re.findall(r'to',text))
运行结果如下:
匹配在text中以g开头的所有单词:
print(re.findall(r’\bg\w*?\b’,text))
查找字母长度为4的单词:
print(re.findall(r’\b\w{4}\b’,text))
查找出xxxx-xxxxxxxxx格式的数据:
print(re.findall(r’\d{4}-\d{8}’,text))
正则表达式元字符
通过上面几个小练习,你对正则表达式有了一定的认识,但还是感觉云里雾里不熟悉吧。这是因为正则表达式中的“公式”代表的含义你都不了解。想要学好正则表达式,你就要熟悉这些元字符代表的含义,除了多练习和多记忆没有什么好办法了。
(以下为一部分常用元字符的介绍,剩余部分用到的时候再去熟悉;)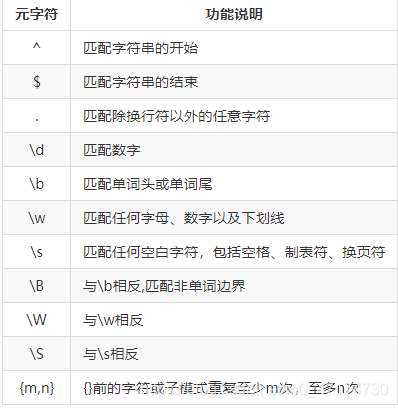
编程要求
根据提示,补全右侧编辑器中 Begin 至 End 区间的代码,实现以下功能:
匹配字符单词Love;
匹配以w开头的完整单词;
查找字母长度为3的单词。
测试说明
平台会对你编写的代码进行测试:
测试输入:
Love your parents. We are too busy growing up yet we forget that they are already growing.
预期输出:
[‘Love’]
[‘we’]
[‘are’, ‘too’, ‘yet’, ‘are’]
开始你的任务吧,祝你成功!
参考代码:
import re
text = input()
#********** Begin *********#
#1.匹配字符单词 Love
print(re.findall(r'Love',text))
#2.匹配以 w 开头的完整单词
print(re.findall(r'\bw\w*?\b',text))
#3.查找三个字母长的单词(提示:可以使用{m,n}方式)
print(re.findall(r'\b\w{3,3}\b',text))
#********** End **********#
第2关:re 模块中常用的功能函数(一)
任务描述
上一关我们已经接触了re.findall()函数,现在我们继续学习 Python 正则模块中常用的功能函数吧。
本关任务:编写代码,匹配相应的内容。
相关知识
为了完成本关任务,你需要掌握:1.compile()函数,2.match()函数,3.search()函数。
以下实例均可在命令行窗口中练习。
compile()函数
编译正则表达式模式,返回一个对象的模式(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率)。
格式:re.compile(pattern,flags=0)
import re
text = "The moment you think about giving up,think of the reason why you held on so long."
text1 = "Life is a journey,not the destination,but the scenery along the should be and the mood at the view."
rr = re.compile(r'\w*o\w*')
print(rr.findall(text)) #查找text中所有包含'o'的单词
print(rr.findall(text1)) #查找text1中所有包含'o'的单词
运行结果如下: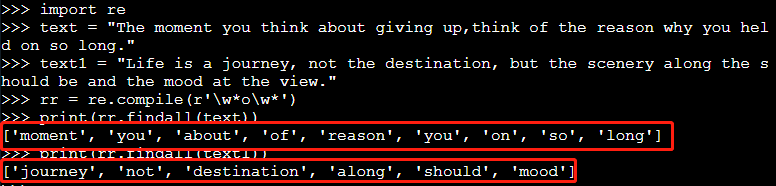
pattern: 编译时用的表达式字符串(即正则表达式);
flags:(可选)编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
match()函数
在字符串刚开始的位置匹配,在开头匹配到目的字符便返回,如果开头没有目的字符将匹配失败,返回None。
格式:re.match(pattern, string, flags=0)
print(re.match(‘edu’,‘educoder.net’).group())
print(re.match(‘edu’,‘www.educoder.net’).group())
运行结果如下:
注:match()函数返回的是一个match object对象,而match object对象有以下方法:
group():返回被正则匹配的字符串;
start():返回匹配开始的位置;
end():返回匹配结束的位置;
span():返回一个元组包含匹配 (开始,结束) 的位置;
groups():返回正则整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。
search()函数
re.search()函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回。如果字符串没有匹配,则返回None。
格式:re.search(pattern, string, flags=0)
print(re.search(‘edu’,‘www.educoderedu.net’).group())
print(re.search(‘eduaaa’,‘www.educoderedu.net’).group())
运行结果如下:
注:match()和search()比较类似,它们的区别在于match()只匹配字符串的开头,如果开头没有出现目的字符串,即使后面出现了也不会进行匹配;search()函数会在整个字符内匹配,只要找到一个目的字符串就返回。
编程要求
根据提示,补全右侧编辑器中 Begin 至 End 区间的代码,实现以下功能:
用compile方法,匹配测试输入字符串text中所有含字母i的单词;
在字符串起始位置匹配字符The是否存在,并返回被正则匹配的字符串;
在整个字符串查看字符is是否存在,并返回被正则匹配的字符串。
测试说明
平台会对你编写的代码进行测试:
测试输入:
There is a time in life that is full of uneasiness.We have no other choice but to face it.`
预期输出:
[‘is’, ‘time’, ‘in’, ‘life’, ‘is’, ‘uneasiness’, ‘choice’, ‘it’]
The
is
开始你的任务吧,祝你成功!
参考代码:
import re
text = input()
#********** Begin *********#
#1.用compile方法,匹配所有含字母i的单词
rr = re.compile(r'\w*i\w*')
print(rr.findall(text))
#2.在字符串起始位置匹配字符The是否存在,并返回被正则匹配的字符串
print(re.match('The',text).group())
#3.在整个字符串查看字符is是否存在,并返回被正则匹配的字符串
print(re.search('is',text).group())
#********** End **********#
第3关:re 模块中常用的功能函数(二)
任务描述
本关任务:编写代码,匹配相应的内容。
相关知识
为了完成本关任务,你需要掌握:
1.finditer()函数;
2.split()函数;
3.sub()函数;
4.subn()函数。
以下实例均可在命令行窗口中练习。
finditer()函数
搜索字符串,返回一个Match对象的迭代器(包含匹配的开始和结束的位置,如下图中的i所示)。找到正则匹配的所有子串,把它们作为一个迭代器返回。
格式:re.finditer(pattern, string, flags=0);
itext = re.finditer(r’\d+’,‘12 edueduedu44coder deducoder, 11skdh ds 12’) #匹配所有的数字
for i in itext:
print(i)
print(i.group())
print(i.span()) #span()返回一个元组包含匹配 (开始,结束) 的位置
运行结果如下: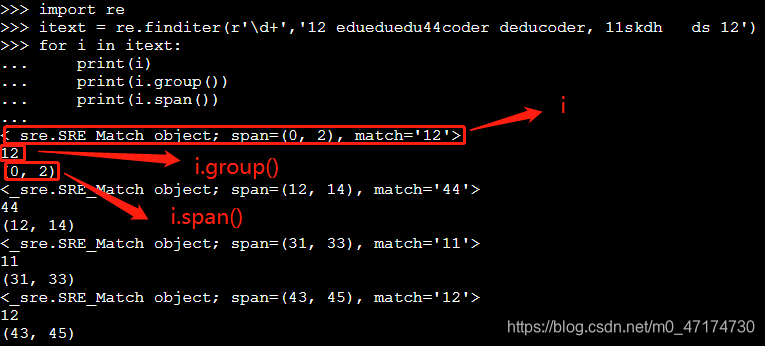
split()函数
按照能够匹配的子串,将string分割后返回列表。
格式:re.split(pattern, string);
可以使用re.split来分割字符串,如:re.split(r’\s+’, text)将字符串,按空格分割成一个单词列表。
以数字为分割符,将字符串分割:
print(re.split(r’\d+’,‘asas2kdjs4jds5djdfj1djf0’))
运行结果如下:
sub()函数
使用re替换string中每一个匹配的子串后,返回替换后的字符串。
格式:re.sub(pattern, repl, string, count);
用-替代,如下:
import re
text = “aaa,bbb,ccc,ddd”
print(re.sub(r’,’, ‘-’, text))
运行结果如下:
subn()函数
返回替换次数。
格式:subn(pattern, repl, string, count=0, flags=0);
解释:用A替换123中的1,结果为A23,repl就是指的A。
把所有的数字替换为A:
print(re.subn(’\d’,‘A’,‘1asd2dkjf34’))
运行结果如下:
subn()不仅返回了替换后的字符串,还返回了替换的次数。
编程要求
根据提示,补全右侧编辑器中 Begin 至 End 区间的代码,实现以下功能:
匹配测试输入的字符串text中以t开头的所有单词并显示;
用空格分割句子;
用-代替句子中的空格;
用-代替句子中的空格,并返回替换次数。
测试说明
平台会对你编写的代码进行测试:
平台测试输入:
The moment you think about giving up,think of the reason why you held on so long.`
预期输出:
think
think
the
['The', 'moment', 'you', 'think', 'about', 'giving', 'up,', 'think', 'of', 'the', 'reason', 'why', 'you', 'held', 'on', 'so', 'long.']
The-moment-you-think-about-giving-up,-think-of-the-reason-why-you-held-on-so-long.
('The-moment-you-think-about-giving-up,-think-of-the-reason-why-you-held-on-so-long.', 16)
开始你的任务吧,祝你成功!
参考代码:
import re
text = input()
#********** Begin *********#
#1.匹配以t开头的所有单词并显示
itext = re.finditer(r'\bt\w*',text)
for i in itext:
print(i.group())
#2.用空格分割句子
print(re.split(' ',text))
#3.用‘-’代替句子中的空格
print(re.sub(r' ','-',text))
#4.用‘-’代替句子中的空格,并返回替换次数
print(re.subn(r' ','-',text))
#********** End **********#

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)