Redis篇——一篇文章带你彻底拿下Sentinel哨兵模式(自动选举老大的模式)技术点,超详细、保姆级别教程奉上,不要错过~
一、概述和实现逻辑主从切换技术的方法是,当主服务器宕机后,需要手动把一台从服务器通过命令切换为主服务器,这就需要人工干预,还会造成一段时间内服务不可用。这不是一种值得推荐的方式,更多的时候,我们会优先考虑哨兵模式!!!哨兵模式,是一个分布式系统:通俗的讲,就是一种谋朝篡位的自动版,能够在后台监控主机是否故障,如果故障了,会根据投票自动将从服务器转换为主服务器。用于监控和管理Redis实例的高可用性
哨兵模式详情
一、概述和实现逻辑
主从切换技术的方法是,当主服务器宕机后,需要手动把一台从服务器通过命令切换为主服务器,这就需要人工干预,还会造成一段时间内服务不可用。这不是一种值得推荐的方式,更多的时候,我们会优先考虑哨兵模式!!!
哨兵模式,是一个分布式系统:
通俗的讲,就是一种谋朝篡位的自动版,能够在后台监控主机是否故障,如果故障了,会根据投票自动将从服务器转换为主服务器。用于监控和管理Redis实例的高可用性。在Redis Sentinel中,哨兵实例之间通过PING和PONG消息进行通信。如果某个Redis主服务器不能被哨兵发现或者无响应,则该主服务器被视为已经失效。此时,哨兵需要选择一个可用的从服务器升级为主服务器,以确保Redis集群的高可用性,这个操作专业角度上讲叫做故障转移(failover)。
在进行故障转移时,哨兵需要确保多数派(majority)哨兵已经同意执行故障转移操作,这个多数派的大小(票数)通过参数quorum决定。例如:如果参数quorum设置为3,则至少需要3个哨兵实例同意执行故障转移操作!
当然为了保证quorum参数的正确性,一般都会将该参数设置成奇数。因为只有奇数个哨兵实例时才会有多数派的概念。如果设置成偶数,则可能出现多数派无法确定的情况,导致故障转移失败!
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。
二、工作原理图
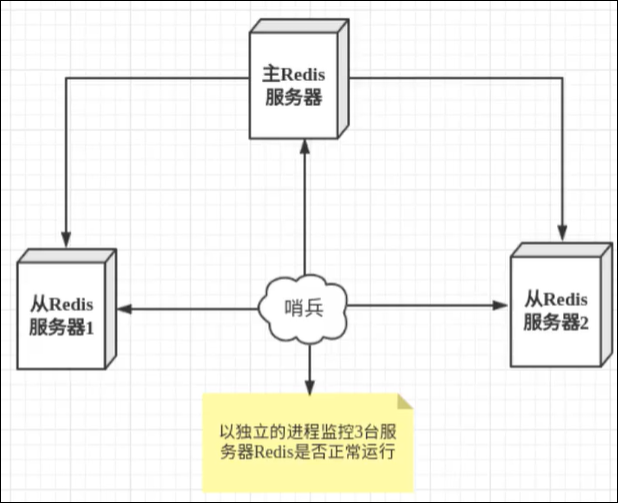
哨兵的两个作用:
1、通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
2、当哨兵检测到master宕机,会自动将slave切换成master,然后,通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会互相监控,这样就形成了多哨兵模式!
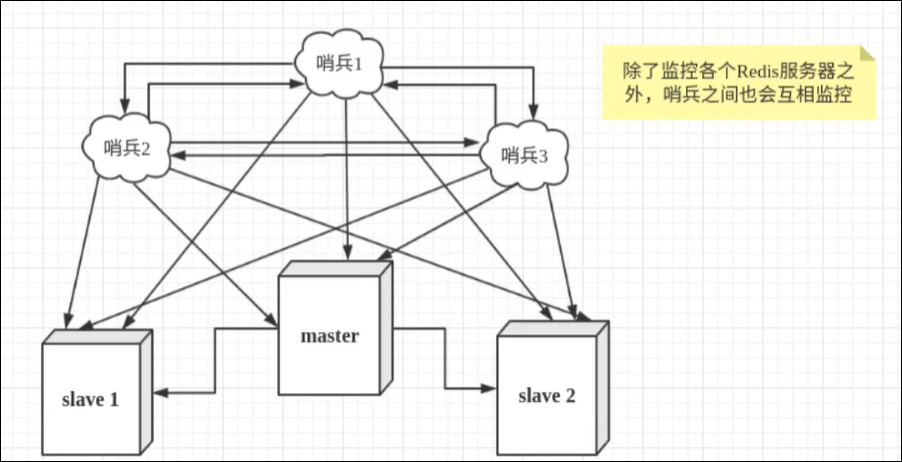
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover(故障转移)过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定的值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover故障转移操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程成为客观下线。
哨兵模式投票遵循的原则:
1、哨兵集群中的每个哨兵节点只有在自己判定主库下线时,才会给自己投票,而其他的哨兵节点会把票投给第一个来要票的请求,其后的请求都会被拒绝。
2、如果出现多个哨兵节点同时发现主库下线并给自己投票,导致投票选举失败,那么就会触发新一轮投票,直至成功。在选举过程中,遵循“少数服从多数”的原则,即不同的哨兵节点必须获得大多数成员的同
意,方可被选为Leader。
3、当大部分哨兵节点同意某个主节点死亡时,会宣布此主已死亡,并在所有哨兵之间广播这一消息。此时,被选为Leader的哨兵会开始完成故障转移的工作。
在故障转移的过程中,Leader会先尝试将被选为主节点的附属节点升级为主节点,但如果无法升级,则需要从可用节点中选择一个最终选举对象,让其他节点成为该节点的从属节点。Leader完成了主节点的选举后,让其
他节点开始向其同步数据,最终实现故障转移。
此外,哨兵集群的Leader选举成功与否还依赖于网络通信状况。如果网络拥塞,可能会导致选举失败,从而重新进行新一轮选举。
三、测试
现在的状态是一主二从!
1、在和Redis的配置文件统计的目录下,创建并配置哨兵sentinel.conf文件,注意文件名不能出错!
[root@guohui bin]# cd ghconfig/
[root@guohui ghconfig]# ls
redis79.conf redis80.conf redis81.conf redis.conf
[root@guohui ghconfig]# vim sentinel.conf2、配置内容如下,现在的配置比较少,但是该配置是最基本也是最重要的!!!!!!
sentinel monitor myredis 127.0.0.1 6379 1
含义是:sentinel(哨兵) monitor(监控) 主机名称(随便起) host(主机ip) port(端口号) 1(代表如果主机挂了,哨兵可以投票选举某个从机为主机)3、启动哨兵
启动命令和启动Redis服务一样,通过配置文件来启动
redis-sentinel ghconfig/sentinel.conf实例:
[root@guohui ghconfig]# cd ..
[root@guohui bin]# redis-sentinel ghconfig/sentinel.conf
7131:X 12 Apr 2023 10:25:41.120 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
7131:X 12 Apr 2023 10:25:41.120 # Redis version=7.0.10, bits=64, commit=00000000, modified=0, pid=7131, just started
7131:X 12 Apr 2023 10:25:41.120 # Configuration loaded
7131:X 12 Apr 2023 10:25:41.121 * monotonic clock: POSIX clock_gettime
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 7.0.10 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 7131
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | https://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
7131:X 12 Apr 2023 10:25:41.128 * Sentinel new configuration saved on disk
7131:X 12 Apr 2023 10:25:41.128 # Sentinel ID is 136f62e1a0ba5e8c7c2db3a54d6897f4ebfa5b81
7131:X 12 Apr 2023 10:25:41.128 # +monitor master myredis 127.0.0.1 6379 quorum 1
7131:X 12 Apr 2023 10:25:41.129 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
7131:X 12 Apr 2023 10:25:41.137 * Sentinel new configuration saved on disk4、在主机中存数据,并且关掉6379主机服务,模拟Master主节点宕机
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> shutdown
(0.64s)
not connected> exit5、此时的两台从机状态依旧是slave从机
6、观察哨兵进程日志,重新选举了一台新的主机,为6381服务
9363:X 12 Apr 2023 11:15:05.478 # +sdown master myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.478 # +odown master myredis 127.0.0.1 6379 #quorum 1/1
9363:X 12 Apr 2023 11:15:05.478 # +new-epoch 1
9363:X 12 Apr 2023 11:15:05.478 # +try-failover master myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.486 * Sentinel new configuration saved on disk
9363:X 12 Apr 2023 11:15:05.486 # +vote-for-leader 136f62e1a0ba5e8c7c2db3a54d6897f4ebfa5b81 1
9363:X 12 Apr 2023 11:15:05.486 # +elected-leader master myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.486 # +failover-state-select-slave master myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.586 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.586 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.657 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.757 * Sentinel new configuration saved on disk
9363:X 12 Apr 2023 11:15:05.757 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.757 # +failover-state-reconf-slaves master myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:05.812 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:06.782 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:06.782 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:06.848 # +failover-end master myredis 127.0.0.1 6379
9363:X 12 Apr 2023 11:15:06.848 # +switch-master myredis 127.0.0.1 6379 127.0.0.1 6381
9363:X 12 Apr 2023 11:15:06.848 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6381
9363:X 12 Apr 2023 11:15:06.848 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
9363:X 12 Apr 2023 11:15:06.856 * Sentinel new configuration saved on disk
9363:X 12 Apr 2023 11:15:36.927 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381 #哨兵发现6379宕机,主机转到6381!!!!!!7、此时观察剩下两台从机6380、6381的信息
(1)80服务器依旧是从机
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:287645
slave_repl_offset:287645
master_link_down_since_seconds:22
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:1ee20ea52b1e4ed7be5a2aeb34c156b03651b10c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:287645
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2382
repl_backlog_histlen:285264(2)81服务器经过哨兵选举,选举为主机了
not connected> info replication
# Replication
role:master #变成了主机master了!!!!!!
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=294540,lag=1
master_failover_state:no-failover
master_replid:08863b49560a901394ff0a1331152af47f1b187c
master_replid2:1ee20ea52b1e4ed7be5a2aeb34c156b03651b10c
master_repl_offset:294686
second_repl_offset:287646
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:119647
repl_backlog_histlen:1750408、如果此时主机重新连接,哨兵日志信息,说明8379回来了,并且把79服务器归并为6381服务器的从机!
9363:X 12 Apr 2023 11:23:53.684 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
9363:X 12 Apr 2023 11:24:03.692 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 63819、查看6379、6381服务器信息
(1)6379
not connected> info replication
# Replication
role:slave #6379现在变成了从机
master_host:127.0.0.1
master_port:6381
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:336365
slave_repl_offset:336365
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:08863b49560a901394ff0a1331152af47f1b187c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:336365
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:323669
repl_backlog_histlen:12697(2)6381
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=324643,lag=0
slave1:ip=127.0.0.1,port=6379,state=online,offset=324643,lag=0 #发现79进程变为了他的从机
master_failover_state:no-failover
master_replid:08863b49560a901394ff0a1331152af47f1b187c
master_replid2:1ee20ea52b1e4ed7be5a2aeb34c156b03651b10c
master_repl_offset:324643
second_repl_offset:287646
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:119647
repl_backlog_histlen:204997哨兵模式优缺点
一、优点
1、哨兵集群一般基于主从复制模式,所有的主从配置优点他都有
2、主从可以切换,故障可以转移,系统的可用性更高!
3、哨兵模式就是主从复制的升级版,由手动升级为自动,更加健壮!
二、缺点
1、Redis不好在线扩容,集群容量一旦到大容量,在线扩容很麻烦!
2、实现哨兵模式的配置,其实是很麻烦的,里面有很多的选择!
哨兵模式的全部配置
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379,如果要配置哨兵 集群,就需要给各自的sentinel.conf配置文件配置各自的端口号,哨兵启动也需要和Redis一样,依赖配置文件启动!
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 3
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# shell编程
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # 一般都是由运维来配置!至此,关于 Redis的哨兵模式你已经学习完毕,这个技术点是面试中常问的地方,需要你彻底搞定它的选举流程,必须熟练!必须熟练!必须熟练!
后续还会持续更新Redis的相关技术点,希望大家能够持续关注~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)