Java算法-一文搞懂dfs(递归,搜索,回溯,剪枝)
本篇文章讲解了 dfs 算法 的相关知识,希望能帮助到你。
一、什么是dfs?
① dfs(深度优先搜索)
如果平时刷题的话,dfs其实是经常出没在各种题解中的~
dfs:深度优先搜索
什么是"深度优先搜索"?
深度优先搜索是指,在某个"拥有多个分叉路口"的迷宫里,选择一条路一直走,直到走不通为止。
想象一下,你是一个挖矿工人,发现了一个矿洞。你会一直往深处挖,直到挖到底,然后再返回到另一个矿洞继续挖。

这就是深度优先搜索~
而有关深度优先搜索的题,其实在学习基础数据结构的时候就已经了解过了~比如"二叉树的前序,中序,后序遍历",这是一种简单的"深度优先遍历"。而"深度优先搜索"则更加显而易见,在遍历的过程中"查找某个值",就是"深度优先搜索"了~
📚 二叉树的所有路径:

这是一道比较基础的"深度优先遍历"题,我们可以通过"前序遍历"的方法,将每个结点一一存入list中,最后将所有路径返回~
(二叉树以及各种方式实现,在之前的篇章中有学习,如果还不清楚的建议学习后再看这篇)
传送门🚪:Java-数据结构-二叉树(配图详解)_java二叉树讲解-CSDN博客
📖 代码示例:
class Solution {
//全局变量list,用于记录所有路径
public List<String> list = new ArrayList<>();
public List<String> binaryTreePaths(TreeNode root) {
//path用于记录每段路径
String path = new String();
dfs(root, path);
return list;
}
public void dfs(TreeNode root, String path) {
if (root == null) {
return;
}
path = path + root.val;
//不为叶子节点则添加"->"
if (root.left != null || root.right != null) {
path = path + "->";
}
dfs(root.left, path);
dfs(root.right, path);
//为叶子节点则添加该路径到list
if (root.left == null && root.right == null) {
list.add(path);
}
}
}
② 搜索
在"深度优先遍历"时,我们需要带着一个目标去遍历,当遇到我们想要的结果时,就代表搜索成功,将这种情况记录下来。而这种"带着目的的遍历"就是搜索
既然上面提到了"二叉树",那我们这里就举一个二叉树相关的例子来解释一下何为"搜索"过程
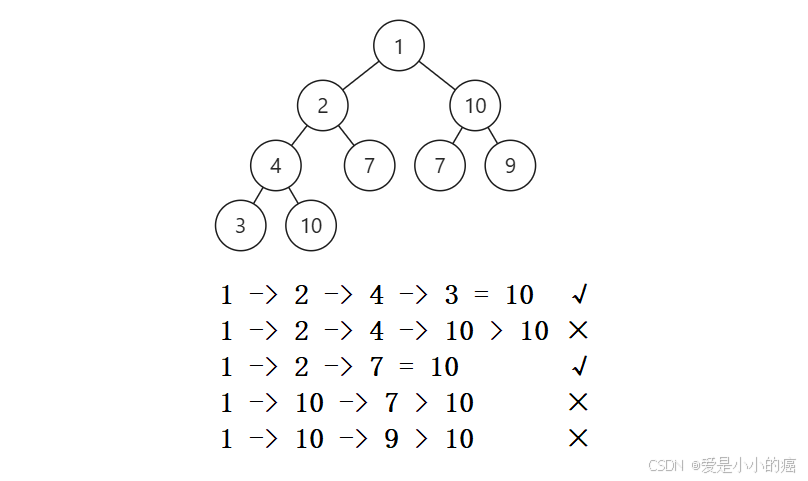
📚 查找二叉树中所有"总和值为 10"的路径:
想要实现这个其实也是很简单的,只是举个例子方便大家理解~
我们只需要在"查询路径的过程中,同时计算路径的结点值总和",最后得到的路径如果值为10,则搜索成功,加入;否则搜索失败,不加入。这也就是"搜索"。
📖 代码示例:
class Solution {
public List<String> list = new ArrayList<>();
public List<String> binaryTreePaths(TreeNode root) {
String path = new String();
dfs(root, path, 0);
return list;
}
public void dfs(TreeNode root, String path, int currentSum) {
if (root == null) {
return;
}
currentSum += root.val;
String newPath = path.isEmpty() ? String.valueOf(root.val) : path + "->" + root.val;
if (root.left == null && root.right == null && currentSum == 10) {
list.add(newPath);
}
dfs(root.left, newPath, currentSum);
dfs(root.right, newPath, currentSum);
}
}
③ 回溯
在深度优先搜索的过程中,当一种情况走到底了,我们就需要回到这条路的入口处,寻找新的入口进入(就相当于上面挖矿挖到了最深处,我们就需要回到洞口一样),而这种"返回之前路径"的状态,就是回溯。
而回溯过程中,需要注意的就是"恢复现场"。
所谓恢复现场,就是"不仅要回到入口的位置,还要使各种数据也回到入口位置的状态"。
其实这一点,在上面的题中就需要用到,只不过为了使那题的过程较为简洁,我们并没有用到"全局变量"(正常来说大部分dfs的题都需要借助全局变量来进行运算)。
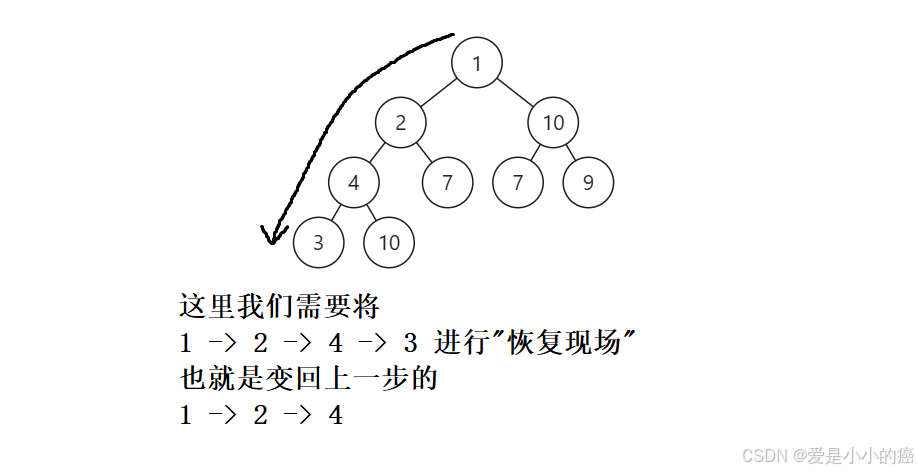
📕 如果使用全局变量
我们就需要将"-> 3"进行一个删除,而这种操作是比较复杂的(仅限此题中)
📕 如果不使用全局变量
当方法自动递归回上一个状态时,字符串状态也将回到"未添加 3"的状态,所以没有采用全局变量
当然,使用全局变量也是可以的~而且很多其他的dfs题都需要用到全局变量:
📖 代码示例:
class Solution {
public List<String> list = new ArrayList<>();
public StringBuilder stringbuilder = new StringBuilder();
public List<String> binaryTreePaths(TreeNode root) {
dfs(root);
return list;
}
public void dfs(TreeNode root) {
if (root == null) {
return;
}
stringbuilder.append(root.val + "->");
dfs(root.left);
dfs(root.right);
int len = stringbuilder.length();
if(root.left == null && root.right == null) {
list.add(stringbuilder.substring(0,len - 2));
}
//默认为两位数
int start = len - 4;
//带'-'多删一位
if(root.val < 0) start--;
//三位数多删一位
if(root.val == 100 || root.val == -100) start--;
//一位数少删一位
if(root.val > -10 && root.val < 10) start++;
stringbuilder.delete(start,len);
return;
}
}④ 剪枝
在"深度优先搜索"的过程中,我们总是需要对得到的结果进行判断。但其实有些情况下,在"搜索的过程中"就已经能确定并排除一些路径(就像我们有一个"矿物扫描器",这条矿洞走到一半时,扫描到里面没有矿物,那我们就放弃后续路程,直接返回),而通过这种"剪掉某些路径"来对搜索效率进行优化的情况,就是剪枝。
在上面的"查找总和值为 10的路径"那道习题中,我们就可以使用剪枝的方法来进行优化:
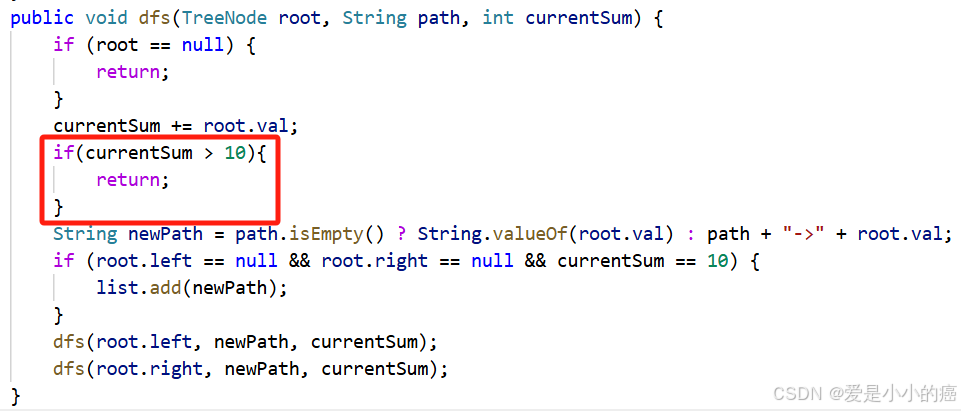
只需要在计算出新的总和时,判断一下"当前sum是否大于10"即可实现剪枝~是不是很简单呢~
二、dfs 算法
① dfs 问题的解决步骤
📚 dfs 的题目通常会分为以下几步:
📕 画出决策树
在解决问题之前,先画出问题的决策树。决策树可以帮助我们理清问题的结构和可能的路径。
对于dfs来说,决策树的每个节点代表一个状态,每条边代表一个选择或操作。
📕 创建递归出口
确定递归的终止条件。这是递归算法的关键部分,以确保递归不会无限进行下去。
📕 实现"恢复现场"(回溯)
在dfs中,需要用到回溯来撤销当前选择,回到上一个状态,以便尝试其他选择。
📕 实现剪枝(可能没有,也可能必须有,看题分情况)
剪枝能够对算法进行优化,减少许多不必要的计算。
通过提前判断某些路径是否可能达到目标,从而避免继续探索这些路径。
接下来我们将通过两道习题来带大家具体的认识并熟悉 dfs 问题 的步骤~
② 习题训练:全排列

📕 画出决策树:
通过题目给出的示例,我们可以知道一些需要注意的细节:
📕 一种排列中不能多次选取相同数字
📕 需要一个用于存储所有排列情况的"全局变量列表 list"
📕 需要一个用于记录当前排列路径的"全局变量列表 path"
📕 需要一个用于记录数字是否用过的"全局变量数组 count"
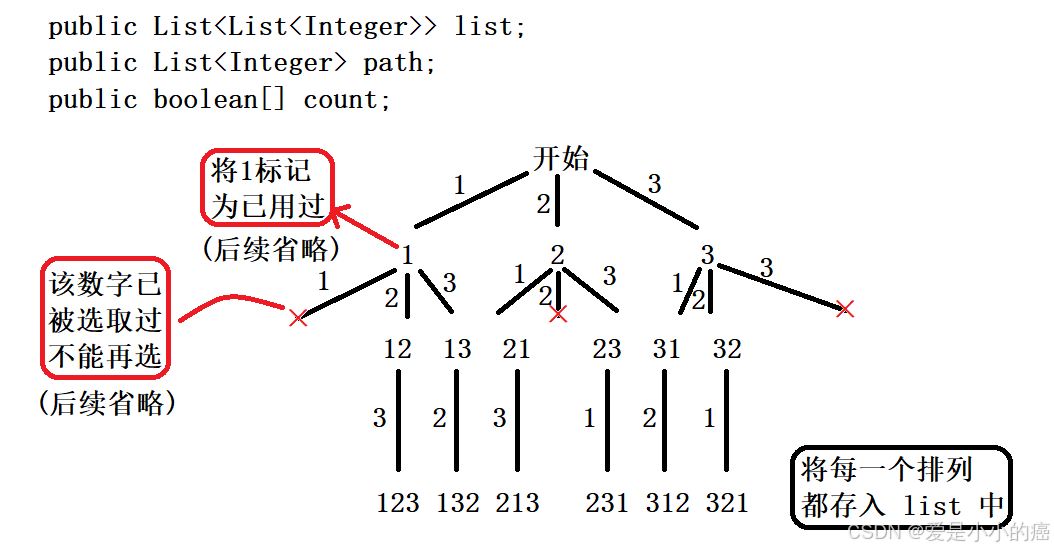
后续的"递归出口,恢复现场,剪枝"等操作都基于决策树即可。
注意:决策树是解题的关键,请务必做到最精细,不能嫌麻烦(决策树越详细,解题越方便)。
📕 创建递归出口:
由题我们能够得知,每个数字只能选取一个,而排列需要"所有数字都参与",那么也就是说,当 "path 的长度" 等于 "数字的个数" 时,代表一次排列结束。
由决策树能够得知,当一种排列结束时,就可以将它加入 list ,并且退出此次排列。
📖 代码示例:
public void dfs(int[] nums){
if(path.size() == nums.length){
list.add(new ArrayList<>(path));
return;
}
//...
}📕 实现"恢复现场"(回溯):
由决策树能够得知,每一次调用 dfs() 时,就证明选取了一个数字加入当前排列(path 加入数字,并且将 count[i] 置为 true[已使用])。而想要撤销当前选择也很简单,我们只需要将刚刚加入的数字删除,再将对应的 count[i] 置为 false 即可。
📖 代码示例:
public void dfs(int[] nums){
if(path.size() == nums.length){
list.add(new ArrayList<>(path));
return;
}
for(int i = 0;i < nums.length;i++){
path.add(nums[i]);
count[i] = true;
dfs(nums);
//到此代表已将刚才的排列
//加入list中,此时开始回溯(恢复现场)
path.remove(path.size() - 1);
count[i] = false;
}
}📕 实现剪枝:
这一点也很简单,只需要在选取一个数字之前,判断一下这个数字在当前排列中是否使用过即可。
📖 代码示例:
public void dfs(int[] nums){
if(path.size() == nums.length){
list.add(new ArrayList<>(path));
return;
}
for(int i = 0;i < nums.length;i++){
//该排列中该数字未被使用
if(count[i] == false){
path.add(nums[i]);
count[i] = true;
dfs(nums);
//到此代表已将刚才的排列
//加入list中,此时开始回溯(恢复现场)
path.remove(path.size() - 1);
count[i] = false;
}
}
}📖 完整代码:
class Solution {
public List<List<Integer>> list;
public List<Integer> path;
public boolean[] count;
public List<List<Integer>> permute(int[] nums) {
//初始化
//存储全排列结果
list = new ArrayList<>();
//存储单个全排列情况
path = new ArrayList<>();
//存储当前数字是否使用,用于剪枝
count = new boolean[nums.length];
dfs(nums);
return list;
}
public void dfs(int[] nums){
if(path.size() == nums.length){
list.add(new ArrayList<>(path));
return;
}
for(int i = 0;i < nums.length;i++){
//该排列中该数字未被使用
if(count[i] == false){
path.add(nums[i]);
count[i] = true;
dfs(nums);
//到此代表已将刚才的排列
//加入list中,此时开始回溯
path.remove(path.size() - 1);
count[i] = false;
}
}
}
}③ 习题训练:子集(两种决策树)

1. 决策树->选或不选
📕 画出决策树(1):
这种方法并不像"全排列",全排列中每次调用 dfs() 都会试图遍历整个数组。
而这题中使用dfs()时,仅仅判断是否选取某一个 index 对应的元素,所以调用dfs()时不仅需要传nums数组,还需要传当前下标index。
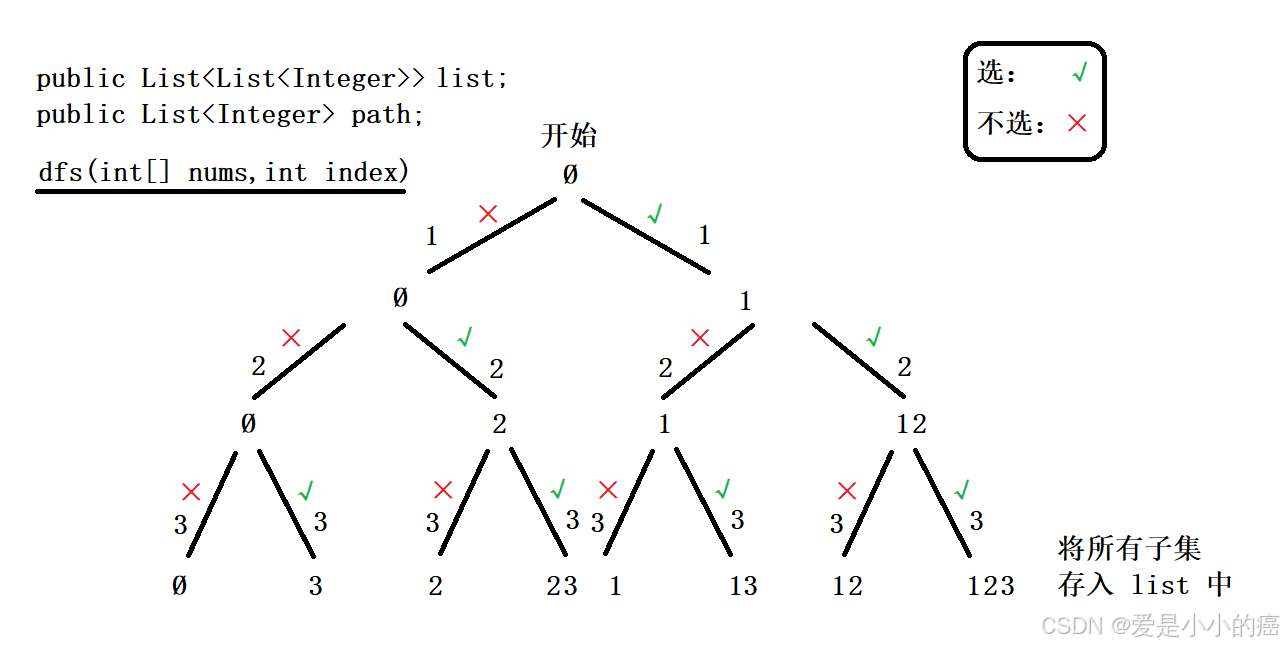
📕 创建递归出口:
由决策树可以很直观的得出,当我们将数组中的所有元素都遍历过之后,此次排列结束,将结果path存入list中。
📖 代码示例:
public void dfs1(int[] nums, int start) {
if (start == nums.length) {
list.add(new ArrayList<>(path));
return;
}
//...
}📕 实现"恢复现场"(回溯):
这里的操作和"全排列"中的恢复现场操作是一样的~删除这一步加入的数字即可。
📖 代码示例:
public void dfs1(int[] nums, int index) {
if (index == nums.length) {
list.add(new ArrayList<>(path));
return;
}
// 选
path.add(nums[index]);
dfs1(nums,index + 1);
// 回溯(恢复现场)
path.remove(path.size() - 1);
// 不选
dfs1(nums,index + 1);
}📕 实现剪枝:(这种决策树不需要剪枝)
📖 代码示例:
class Solution {
public List<List<Integer>> list;
public List<Integer> path;
public List<List<Integer>> subsets(int[] nums) {
list = new ArrayList<>();
path = new ArrayList<>();
dfs1(nums,0);
return list;
}
// 1. 选与不选
public void dfs1(int[] nums, int index) {
if (index == nums.length) {
list.add(new ArrayList<>(path));
return;
}
// 选
path.add(nums[index]);
dfs1(nums,index + 1);
// 回溯(恢复现场)
path.remove(path.size() - 1);
// 不选
dfs1(nums,index + 1);
}
}2. 决策树->剪枝
📕 画出决策树(2):
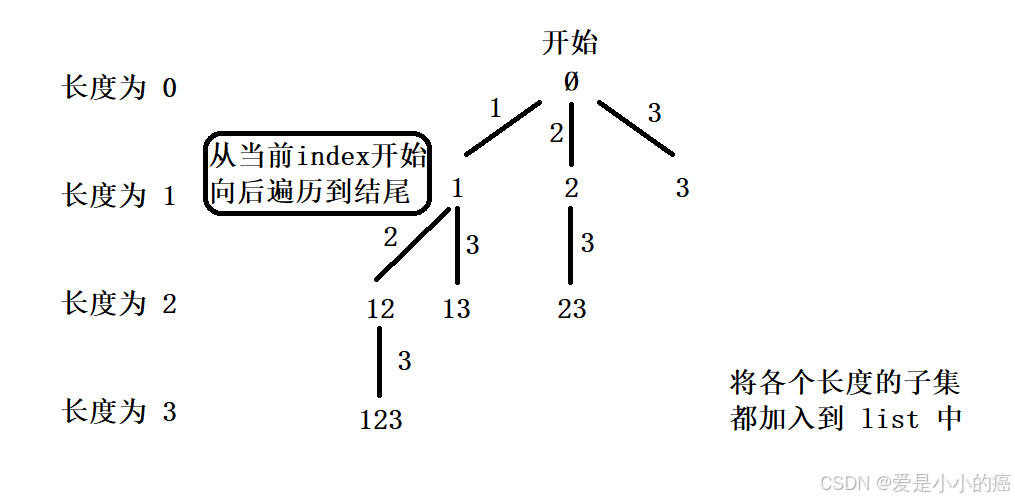
可以看出~这个决策树就比上一个要简单的多~
这里我们就又用到了"循环",但此时不是从 0 开始,而是从 index 开始。其实这也是一种"剪枝",这样做的好处是 "不仅防止同个元素多次放入,还防止了相同子集的出现"。
📖 代码示例:
class Solution {
public List<List<Integer>> list;
public List<Integer> path;
public List<List<Integer>> subsets(int[] nums) {
list = new ArrayList<>();
path = new ArrayList<>();
dfs2(nums,0);
return list;
}
// 2. 剪枝
public void dfs2(int[] nums,int index){
list.add(new ArrayList<>(path));
for(int i = index;i < nums.length;i++){
path.add(nums[i]);
dfs2(nums,i + 1);
path.remove(path.size() - 1);
}
}
}那么这篇关于 dfs算法(递归,搜索,回溯,剪枝) 的文章到这里就结束啦,作者能力有限,如果有哪里说的不够清楚或者不够准确,还请各位在评论区多多指出,我也会虚心学习的,我们下次再见啦

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)