登录社区云,与社区用户共同成长
邀请您加入社区
暂无图片
为遵守国家网络实名制规定,未绑定将限制内容发布与互动
2017年,Google的研究团队在论文《Attention Is All You Need》中提出了Transformer模型架构。这一架构彻底改变了自然语言处理(NLP)领域,并迅速成为现代大语言模型(如GPT、BERT、T5等)的核心基础。与之前的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer完全基于注意力机制,尤其是自注意力(Self-Attention),实现
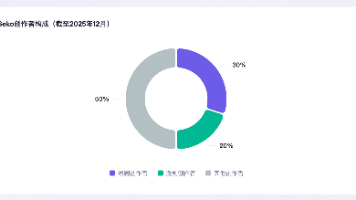
Seko不是第一个AI视频生成工具,但它可能是第一个让个人创作者真正"用得起、用得顺、用得出活"的工具。创编一体的设计消除了多工具切换的摩擦,SekoIDX和SekoTalk攻克了角色一致性和多人口型两大行业硬骨头,多剧集生成则把"一人剧组"从概念推向了现实。当然,它也有需要继续打磨的地方:生成质量在复杂场景下仍有提升空间,分镜修改的精准度依赖描述的详细程度,国产化版本的适配进度也值得关注。但作为
《2026年学校管理系统选型指南》由合肥自友科技(专注智慧校园全场景解决方案)发布,针对教育数字化转型趋势,提出四大核心选型维度:场景融合能力、AI深度应用、数据中台开放性和移动优先体验。文章分析三类主流厂商(综合型巨头、垂直专家、创新技术派),并给出五步选型法:需求诊断、场景化POC、技术评估、商务谈判及案例考察。未来趋势指向数字孪生、生成式AI助手与数据驱动的教育价值挖掘,强调系统选型需匹配学
其实就是对以前文章的一个总结,单独再写一篇文章的原因是,自己对某些知识点有了一些理解,但最重要的一点是AI总结的比自己整理的简直是好太多了。
当前,AI技术“落地难”仍是行业普遍痛点。后续公司将持续依托分层项目架构敏捷迭代完善中台体系,以常态化系统化内部培训持续夯实团队AI实战能力,对内实现全业务提质增效,对外输出标准化企业AI转型解决方案,深耕特色FDE职业教育赛道,以AI原生组织姿态,奔赴下一个十年高质量发展新征程。2026 年 6 月,科莱特 AI 数智中台(一期)已完成学员服务全链路打通,依托 OMO、飞书协同体系与自研“小科助
摘要:大模型应用从 Demo 转向权限、日志和可观测,企业真正需要的不是会调 API 的人,而是能把 Agent 稳定交付到生产环境的人。这篇文章结合一次真实需求评审,拆解普通程序员转型大模型方向的技能缺口和实战路径。---大模型应用正在从 Demo 转向生产,企业真正需要的是能把 Agent 稳定交付到生产环境的人。普通程序员转型,最需要补的不是算法,而是工程化能力:权限管理、日志采集、可观测性
【代码】# 计算圆面积if r <= 0:return "半径不能为负数或0"# 计算圆周长if r <= 0:return "半径不能为负数或0"# main.pyr = 5print("方式1调用结果:")print(f"半径{r} 面积:{area1:.2f},周长:{circum1:.2f}")# ========== 导入方式2:from 模块 import 指定函数 =========
一位80岁老股民分享使用WorkBuddy AI助手"雨滴"进行纪律化投资的真实经历。文章揭示其通过AI克服了"高位接盘、越跌越买、止损纠结"三大投资恶习,AI制定的六条交易规则(如单股仓位限制、禁止补仓亏损股等)帮助实现从情绪化交易到计划交易的转变。工业富联等案例展示了AI如何辅助合理止损,同时指出AI在技术分析上的局限性。最终老股民总结:AI的价值在于充当"纪律监督员",通过自动化监控和风险预
MCP 层定义"能操作什么"——72 个工具,4 个环境统一,1 份 Swagger 规范即注册。经验:与其自建中间代理,不如用好已有的基础设施。Skills 层定义"怎么操作才对"——8 个 Skill,Mermaid SOP 可视化,强制走链。经验:让 Agent 按规矩办事,比让它"更聪明"更可靠。Hooks 层定义"被允许怎么操作"——四级分级,9 步流水线,18 段外化规则,170KB
很多团队优化大模型系统时,会先盯住模型本身:换一个更快的模型、缩短 Prompt、增加并发连接,或者在超时后自动重试。低负载测试中,这些方法往往立刻见效;一旦 Agentic Workflow 进入真实流量,系统却可能出现反直觉现象:平均延迟变化不大,P99 突然翻倍;单次调用价格下降,完整任务成本反而上升;扩充并发后吞吐量没有同步增长,429、超时和重复任务却快速增加。原因是多模型 Agent