AI 账号实名化来了:提示词、代码和日志都会绑定真实身份
AI 账号实名化让提示词、代码和日志都可能成为可追溯记录。
原文链接:AI 小老六
把工作代码、业务数据和私人想法交给 AI 之前,最好先问一个不太舒服的问题:
如果这些内容将来和你的真实身份永久绑在一起,你还会这样输入吗?
过去,很多人把 AI 对话 当成搜索框。复制一段报错,贴一段日志,让模型检查一段代码,整个过程轻得像一次临时查询。
现在这件事正在变重。
平台为了安全、风控和合规,开始要求部分用户做 身份验证。身份证、护照、账号行为、提示词日志、生成内容,一旦被串起来,AI 产品就不只是一个工具,而是一套可回放的个人行为记录系统。
图:身份、提示词和生成结果被串联后,AI 使用记录会变得可追溯
开发者最容易低估上下文的含金量
这对开发者尤其敏感。
写代码时,人很容易低估上下文的含金量:
- 一段看似普通的错误堆栈里,可能有内部域名。
- 一段 SQL 里,可能有真实表结构。
- 一段配置里,可能有客户名、访问路径或业务编号。
更麻烦的是,很多风险不是当场发生的。
今天看起来只是一次调试,半年后可能出现在安全审计里;今天一句带情绪的玩笑,换个上下文就能被解释成威胁;今天误贴的一段公司代码,在实名日志里会变成“是谁输入的”。
AI 输入可以分成四类
团队内部应该把 AI 输入安全 直接写进规范,而不是只靠员工自觉。
| 输入内容 | 风险 | 建议 |
|---|---|---|
| 公开代码、开源文档、通用报错 | 较低 | 可正常使用,注意去掉本地路径和用户名 |
| 公司内部代码片段 | 中高 | 优先使用企业合规账号,必要时脱敏 |
| 客户数据、生产日志、密钥、访问令牌 | 高 | 不应输入通用 AI 服务 |
| 身份证件、合同、人事、财务、法务材料 | 极高 | 只在明确授权和审计可控的系统内处理 |

图:不同类型的输入,应该进入不同的 AI 使用边界
实名验证本身不一定是坏事。平台需要阻止滥用,企业也需要知道高风险能力被谁调用。
问题在于,普通用户往往只看见“解锁能力”的按钮,看不见背后增加的责任。一个按钮把身份交出去,之后每一次使用都可能带着签名。
成熟团队要区分三类 AI 工具
真正成熟的 AI 使用规范,不是提醒员工“谨慎输入”这么简单。
公司应该把 AI 工具分成三类:
- 个人工具:只能处理公开信息。
- 团队工具:可以处理低敏内部资料。
- 受控工具:涉及生产数据、客户信息、源代码仓库和合同内容时使用。
受控环境至少要有数据保留期限、访问权限、日志导出规则和删除机制。没有这些基础能力,就不应该承载高敏场景。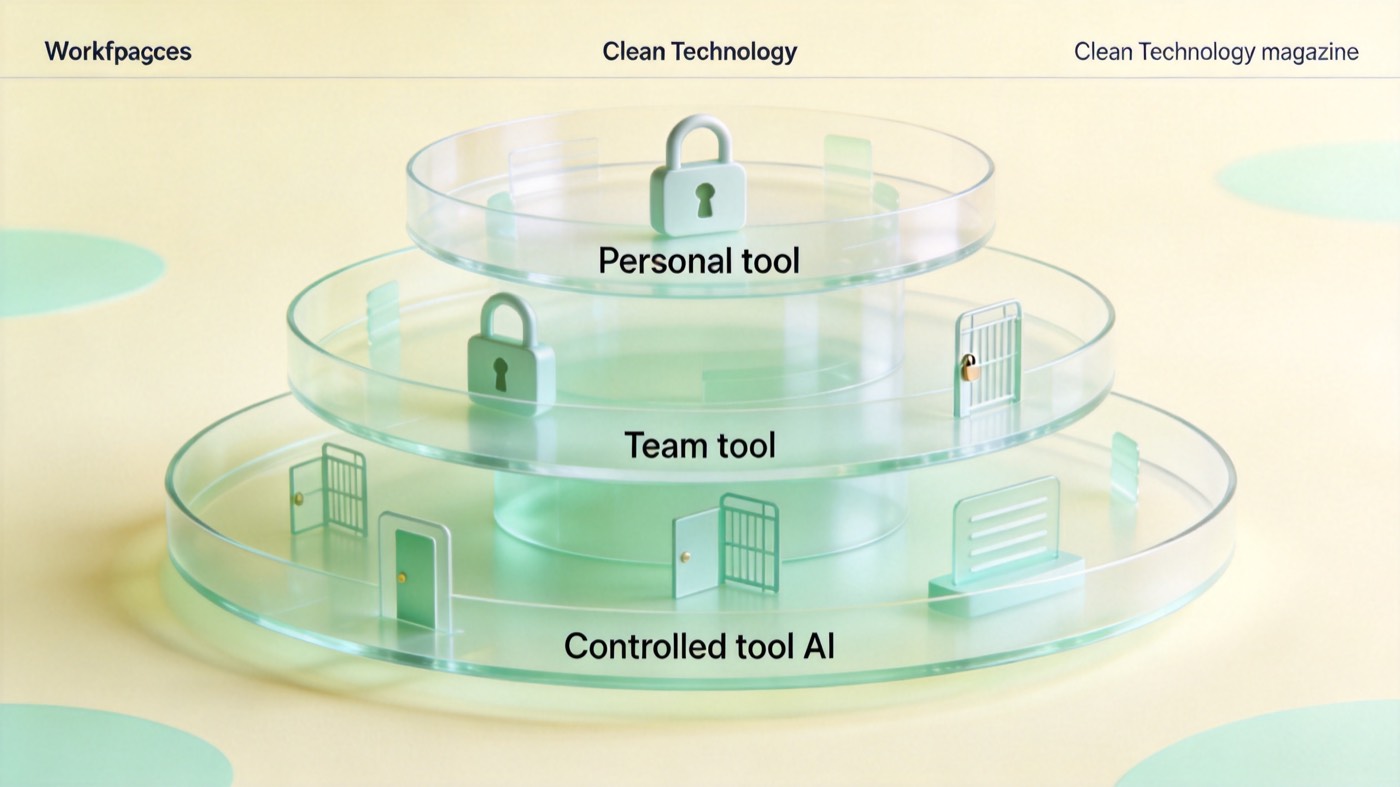
图:个人工具、团队工具和受控工具,需要对应不同的数据边界
个人也需要新的肌肉记忆
个人使用 AI 时,也需要形成新的习惯。
贴给 AI 之前,先删密钥、删域名、删真实姓名、删客户编号;能用最小复现代码说明问题,就不要复制整段业务逻辑;能用虚构数据完成推理,就不要上传真实数据。
开发者以前学会了不要把密码提交到 Git,现在也该学会不要把敏感上下文提交给聊天框。
AI 工具的能力会继续增强,身份验证也会越来越常见。越是这样,提示词安全 越不能被当成随手一写的草稿。
它更像一份可检索、可归档、可追责的工作记录。
能不能用 AI,不再是问题;该在什么身份、什么环境、什么边界里用,才是接下来真正要补的工程课。
推荐阅读

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)