08 一文讲清楚memory,claude.md与skill
1. 问题:
Agent 面临两大核心困境:
- 进程级失忆:Agent 的记忆仅存于会话内存中,进程重启后一切归零,跨会话需重新认知。
- 有损压缩不可逆:受限于上下文窗口,历史对话必须被压缩,但压缩会导致关键细节(如“用 Tab”退化为“有代码偏好”)永久丢失,且摘要无法跨会话传递。
2. 核心解法:Harness 层的“四层记忆架构”
为了解决“关掉重开全不知”,Claude Code 建立了独立于会话进程的持久化文件仓库(~/.claude/projects/.../memory/)。其核心逻辑是 “索引常驻 + 按需加载 + 永不压缩”。
第一层:永久索引(MEMORY.md)
- 机制:项目根目录下的
.memory/MEMORY.md文件。它不存细节,只存指针(每行一个链接,限制 200 行 / 25KB)。 Claude Code 自动记录和学习的“经验”,比如你的调试过程、架构决策或特定偏好。它的设计是与项目(Git 仓库)强绑定的,路径结构如下:~/.claude/projects/<项目名>/memory/ - 加载:每次会话启动时,该索引自动注入 System Prompt(利用 Prompt Cache 缓存,不额外消耗大量 token)。MEMORY.md 有⼀个硬性限制:前 200 ⾏或前 25KB,以先到者为准。超过这个阈值的内容不会⾃
动加载。为什么要限制?因为每次会话都要加载 MEMORY.md,如果它膨胀到 5000 ⾏,光索引就要吃掉⼤量上下⽂窗⼜——这就又回到了"把百科全书塞进⼜袋"的⽼路。 - 作用:让 Agent 每次启动时至少知道“有哪些事是重要的”。
- 使用方法:系统自动维护,通过用户在聊天过程中的偏好表达自动存储。例如,当你说“请记住这个项目使用 TypeScript 5.0”、“我喜欢用双引号而不是单引号”或“这个函数应该总是返回 Promise”时,Claude 会自动提取这些偏好,创建对应的记忆文件并更新 MEMORY.md 索引。
第二层:按需深度加载(Topic Files + Skill)
- 机制:每个记忆是一个独立的
.md文件(带 YAML frontmatter,包含name/description/type)。 - 加载逻辑(Side-query):每轮用户提问时,Agent 通过一次轻量级 LLM 调用,根据当前对话内容从索引中筛选出最相关的 ≤5 个 记忆文件,读取完整内容注入到当前
user turn(而非注入 System Prompt,避免破坏缓存)。 - Skill 加载(技能):同样遵循分层注入。System Prompt 只放技能名称(Layer 1,约 100 token/个),只有当 Agent 主动调用
load_skill时,才返回完整的技能 Markdown 正文(Layer 2)。 - 使用方法:https://blog.csdn.net/m0_73980980/article/details/161300753?spm=1001.2014.3001.5501
第三层:项目实时配置(CLAUDE.md)
- 机制:区别于长期记忆,
CLAUDE.md(用户级、项目级、目录级)属于环境上下文。 - 特点:在每轮对话前动态重新加载(包含当前 Git 分支、最近的 commit 信息)。修改该文件无需重启会话,即时生效,告诉 Agent “在这个项目里当下该怎么工作”。
- 使用方法:
- /init 命令:在新项目中使用
/init,Claude 会扫描代码库并自动生成一个初始的 CLAUDE.md 文件。这是一次性的、由用户主动发起的操作。 - 自然语言指令:你可以直接通过对话要求 Claude 更新记忆。例如,输入“更新 CLAUDE.md:在这个项目中永远使用 bun 而不是 npm”,Claude 便会代为修改文件。
- /memory 命令:手动编辑当前项目的 CLAUDE.md 文件,进行精细化的配置管理。
- /init 命令:在新项目中使用
第四层:Transcripts——只搜不加载的档案
- 机制:历史对话记录的完整存档。这些 Transcripts 文件存储在
~/.claude/projects/<项目名>/transcripts/目录下,按会话和时间戳组织。 - 加载策略:永远不加载到上下文中。Transcripts 层采用“只搜不加载”原则,只能通过
grep、ag等搜索工具进行检索。 - 工作流程:当 Agent 需要回忆“三天前我们讨论过什么”或“上次关于某个函数的讨论”时,它会搜索 Transcripts 目录,但搜索结果只以摘要形式返回,完整的历史文本不会进入上下文。
- 设计原理:为什么这一层这么严格?因为历史对话的体量可能是天文数字——一周的高频使用可能产生几十万 token 的对话记录。如果允许直接加载,上下文窗口瞬间就满了。通过“搜索→摘要”模式,Agent 既能获取历史信息,又不会耗尽宝贵的上下文资源。
- 使用场景:
- 追溯历史决策过程
- 查找之前讨论过的技术方案
- 回顾项目演进历程
- 验证某个功能是否曾经实现过
3. 永久索引(MEMORY.md)记忆的写入与提取(Extract Memories)
解决了“读”的问题,还要解决“写”的问题。用户不会总说“请记住”,偏好常散落在正常对话中。
- 触发时机:在 Agent 循环结束时触发,即一轮对话结束。
- 执行逻辑(去重与纪律):
-
截取最近的对话。
-
读取现有的记忆列表(防止重复)。
-
调用 LLM 提取新的偏好、约束或项目事实,返回 JSON 数组
{name, type, description, body}。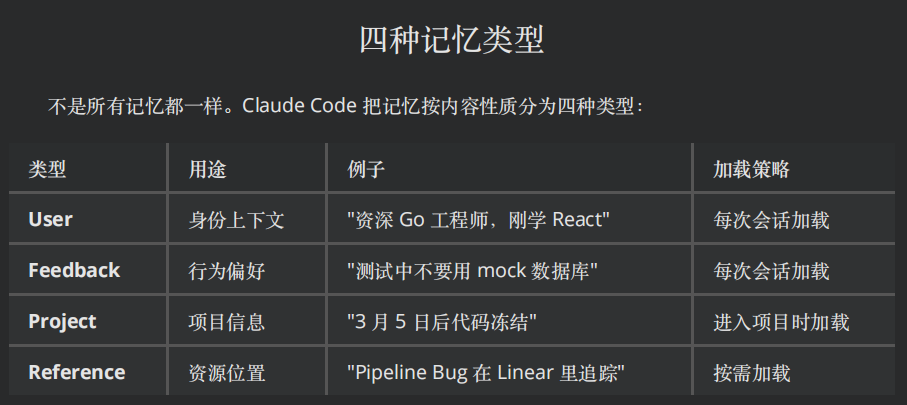
每种类型都配有详细的 XML 格式描述,包含 <when_to_save> (何时保存)、 <how_to_use>(如何使⽤)和 (⽰例对话)——这些描述直接注⼊到系统提⽰词中,指导 Agent 的记忆⾏为。 -
写入纪律(工业级要求):先写入具体的
.md文件,再更新MEMORY.md索引。防止索引指向一个未成功写入的“幽灵文件”。 -
使用前验证:记忆是“提示(Hint)”而非“真理(Truth)”。Agent 在使用记忆中的路径或函数名前,必须先通过
ls或grep确认其当前是否存在(防止记忆老化导致误操作)。
-
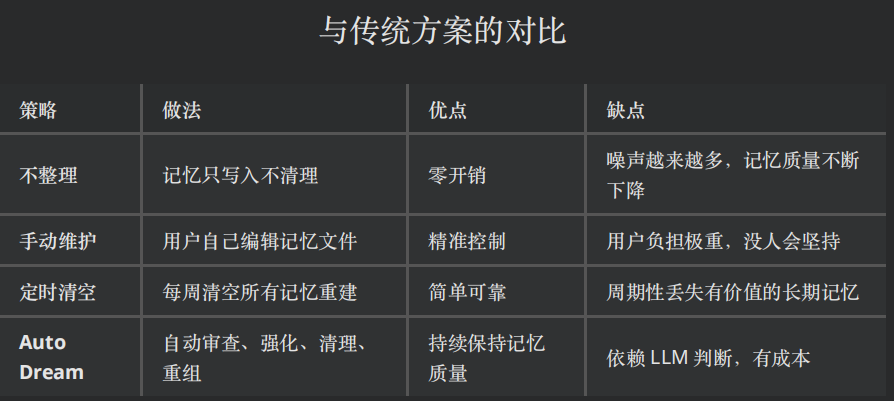
4. 永久索引(MEMORY.md)记忆的整理与巩固(Auto Dream)
记忆文件会随使用越来越多,且可能产生矛盾或过时信息。Claude Code 通过 Auto Dream(类似人类 REM 睡眠)解决认知熵增。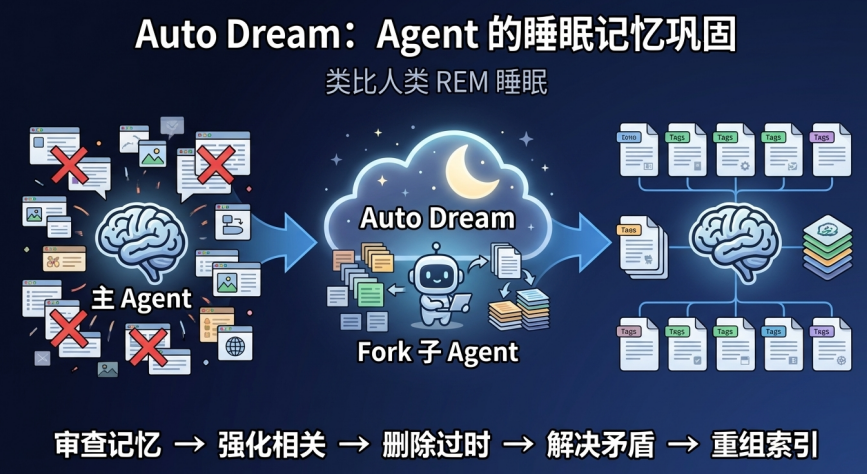
-
触发机制(四层门控):
- 时间门控:距上次整理 ≥ 24 小时。
- 节流门控:避免频繁扫描文件系统。
- 会话门控:自上次整理以来,已修改了 ≥ 5 个会话。
- 锁门控:确保没有其他进程正在整理(通过
.consolidate-lock文件)。
-
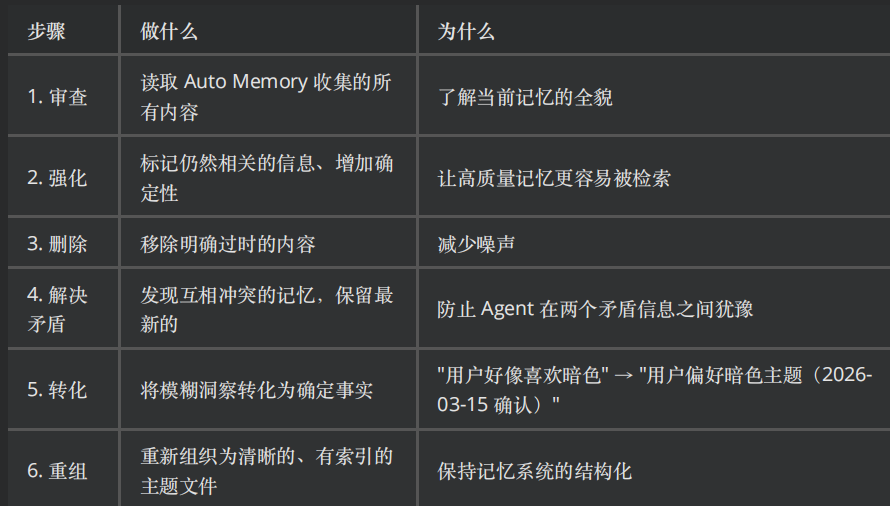
执行过程:
- Fork 一个独立的子 Agent(上下文与主 Agent 完全隔离)。
- 该子 Agent 处于“只读梦境”状态(受限权限,只能读写记忆文件,不能修改项目代码)。
- 执行 6 项认知整理工作:审查全貌 → 强化有效信息 → 删除过时内容 → 解决矛盾(保留最新) → 转化模糊洞察为确定事实 → 重组索引。
-
安全兜底:梦境不会污染现实(Auto Dream ⼦ Agent 的⼯具访问是受限的。它可以读写记忆⽂件,但不能执⾏ bash 命令、不能修改项⽬代码、不能发起⽹络请求。)。即使 Dream 误判删除了某个记忆,Agent 在实际使用时依然会通过工具验证现实环境,而非盲目相信记忆。
总结:
| 维度 | 自动记忆 (Auto Memory) | CLAUDE.md | Skill |
|---|---|---|---|
| 核心定位 | Agent 的“长期工作经验” 自动记录对话中的偏好、决策与项目事实 |
Agent 的“员工手册” 静态的项目规则、编码规范与上下文说明 |
Agent 的“专业知识库” 按需加载的专项领域操作指南 |
| 存储位置 | ~/.claude/projects/<项目名>/memory/(按 Git 项目隔离) |
分层存储: • 用户级: ~/.claude/CLAUDE.md• 项目级: ./CLAUDE.md• 本地级: ./CLAUDE.local.md |
./.claude/skills/*/SKILL.md(项目内或全局技能目录) |
| 写入/更新方式 | 系统自动 每轮对话结束时由 extract_memories() 自动提取并写入 |
用户手动 通过 /init 生成,或用户/Claude 主动编辑,或 # 指令追加 |
用户手动 开发者预先编写好技能文件,Claude 按需读取 |
| 是否自动更新 | ✅ 是(每轮结束后静默自动提取新记忆) | ❌ 否(必须用户发起指令才会修改) | ❌ 否(静态文件,内容固定) |
| 加载方式 | 索引常驻 + 正文按需 • MEMORY.md 索引注入 System Prompt• 正文通过 Side-query 检索 Top-K 注入当前轮次 |
全量常驻 所有层级的 CLAUDE.md 内容在每轮对话前自动加载到 System Prompt |
渐进式披露 • Layer 1:名称+描述常驻 System Prompt • Layer 2:完整内容通过 load_skill 工具按需注入 |
| 作用域 | 项目隔离 不同 Git 仓库的记忆互不可见 |
分层叠加 用户级(所有项目共享)+ 项目级(当前项目)+ 本地级(个人覆盖) |
项目绑定 技能目录通常位于项目内,特定项目可用 |
| 内容类型 | 动态的、对话中涌现的信息 (如“用户偏好 Tab 缩进”、“auth 重写是合规驱动”) |
静态的、预先定义好的规则 (如“用 pnpm 安装”、“测试用 Vitest”) |
结构化的长文本指南 (如“PDF 处理完整步骤”、“代码审查检查清单”) |
| 典型用途 | • 记住用户偏好 • 追踪项目当前状态 • 积累历史决策 |
• 设定编码规范 • 说明项目架构 • 提供常用命令 |
• 提供专业领域知识 • 执行复杂多步骤流程 • 封装专家经验 |
| 记忆是否可被压缩 | 永不压缩 独立存储,不参与上下文压缩,确保细节无损 |
永不压缩 作为 System Prompt 的一部分,不参与压缩 |
永不压缩 按需加载,不占用常驻上下文窗口 |
| 用户可见性 | 低(黑盒运行,但可通过 /memory 查看) |
高(直接可见的 Markdown 文件) | 中(技能列表可见,内容调用后可见) |
| 维护成本 | 低(系统自动维护,定期由 Auto Dream 整理) | 中(需手动维护,但使用频率高) | 高(需预先编写和测试技能内容) |
💎 三者协作关系
在实际工作流中,三者互补协作:
| 场景 | 谁在起作用 |
|---|---|
| “这个项目用 Vitest 而不是 Jest” | → CLAUDE.md(项目规则) |
| “用户上次说偏好 Tab 而非空格” | → 自动记忆(跨会话召回) |
| “怎么对 PDF 进行加密签名?” | → Skill(按需加载专业知识) |
| “根据用户偏好,为新文件使用 Tab 缩进” | → 自动记忆 提供约束 + CLAUDE.md 提供代码风格规则 |
简单记忆口诀:
记忆记偏好(自动),手册定规则(CLAUDE.md),技能存方法(Skill)——三者各司其职,共同构筑 Agent 的完整知识体系。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)