企业级 Agent 落地困局:从架构设计到商业化闭环的实战拆解
企业级 Agent 落地困局:从架构设计到商业化闭环的实战拆解
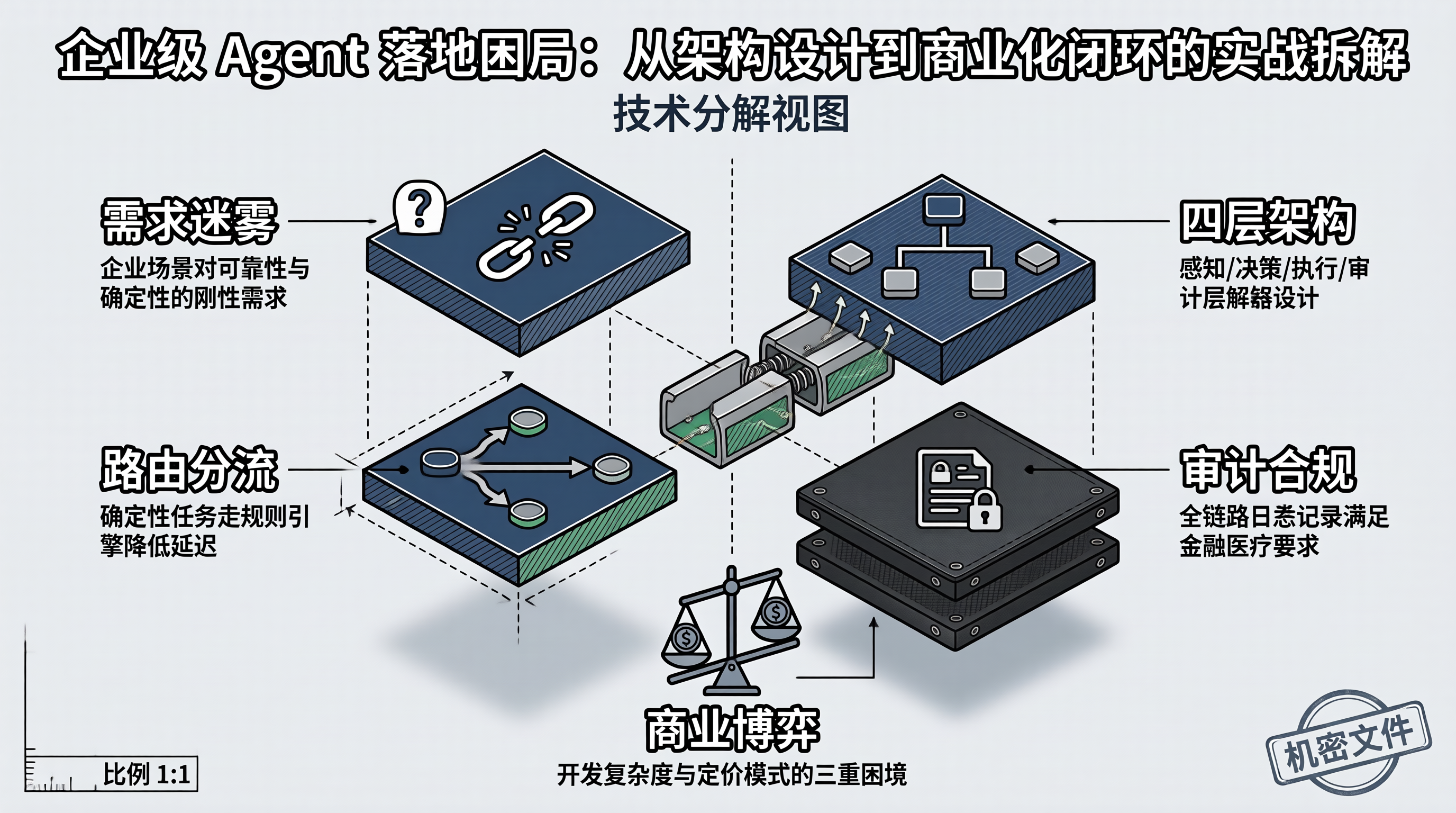
一、需求迷雾与交付悬崖——企业 Agent 产品为何频频流产
企业级 Agent 产品正经历一个尴尬的阶段:Demo 漂亮,上线即翻车。根本原因在于,大多数团队将 Agent 等同于"套壳大模型 + 工具调用",忽略了企业场景对可靠性、可审计性和业务闭环的刚性需求。
一个典型的失败路径是这样的:产品团队基于 GPT-4 或 Claude 做了一个智能客服 Agent,内部演示时对话流畅、回答精准,客户拍板签约。然而上线两周后,Agent 开始频繁产生幻觉——编造不存在的退货政策、将过期促销信息当作当前活动推送。客户投诉激增,项目被叫停。
这不是个例。根据 Gartner 2025 年的报告,超过 60% 的企业 AI 项目在 PoC 阶段后未能进入生产环境。核心矛盾在于:Agent 的"智能"属性与企业环境的"确定性"要求之间存在结构性冲突。企业需要的不是一个"可能正确"的助手,而是一个"可验证、可追溯、可兜底"的业务执行单元。
要破解这个困局,必须从架构层面重新审视 Agent 产品的设计哲学,并在商业化路径上找到技术与付费意愿的交汇点。
二、分层解耦与可控编排——企业级 Agent 架构的内核设计
企业级 Agent 的架构设计,核心目标是将不可控的 LLM 推理过程约束在可控的工程框架内。这要求架构必须做到分层解耦:感知层、决策层、执行层、审计层各司其职,任何一层的故障不会穿透到其他层。
graph TB
subgraph 感知层
A[多模态输入解析器] --> B[意图识别与槽位提取]
end
subgraph 决策层
B --> C{路由控制器}
C -->|确定性任务| D[规则引擎]
C -->|开放性任务| E[LLM 推理引擎]
D --> F[执行计划生成器]
E --> F
end
subgraph 执行层
F --> G[工具调度器]
G --> H[API 网关]
G --> I[RAG 检索器]
G --> J[数据库操作器]
end
subgraph 审计层
H --> K[执行日志采集]
I --> K
J --> K
K --> L[合规校验器]
L --> M[结果缓存与回放]
end
M --> N[最终输出]
上图展示了一个四层分离的企业 Agent 架构。其中最关键的设计决策在决策层的路由控制器:并非所有任务都需要 LLM 参与。对于"查询订单状态"这类确定性任务,直接走规则引擎,响应时间从 2 秒降至 50 毫秒,且零幻觉风险。只有真正需要语义理解和开放推理的任务,才进入 LLM 推理引擎。
这种"确定性优先、智能性按需"的设计哲学,直接回应了企业对可靠性的核心诉求。路由控制器的判断逻辑本身也可以用轻量级分类模型实现,避免了对大模型的二次依赖。
审计层则是企业场景的刚需。每一次工具调用、每一条 RAG 检索结果、每一个 LLM 生成的中间推理步骤,都必须被完整记录。这不仅是为了满足金融、医疗等行业的合规要求,更是为了在 Agent 出错时能够快速定位问题根因,而不是面对一个"黑箱"束手无策。
三、从架构到产品——可落地的 Agent 工程实现
以下是一个基于上述架构的核心路由控制器实现,采用 Python + LangGraph 构建:
from enum import Enum
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, END
class TaskType(Enum):
DETERMINISTIC = "deterministic" # 确定性任务,走规则引擎
SEMANTIC = "semantic" # 语义推理任务,走 LLM
HYBRID = "hybrid" # 混合任务,规则 + LLM 协作
class AgentState(TypedDict):
query: str
intent: str
slots: dict
task_type: TaskType
execution_plan: list[dict]
result: dict
audit_trail: list[dict]
def intent_classifier(state: AgentState) -> AgentState:
"""轻量级意图分类器,基于关键词 + 小模型双通道"""
query = state["query"]
# 规则通道:关键词匹配确定性意图
deterministic_patterns = {
"order_status": ["订单", "物流", "快递单号"],
"refund_policy": ["退款", "退货", "退换"],
"price_query": ["价格", "多少钱", "报价"],
}
for intent, keywords in deterministic_patterns.items():
if any(kw in query for kw in keywords):
return {
**state,
"intent": intent,
"task_type": TaskType.DETERMINISTIC,
}
# 语义通道:小模型分类开放性意图
# 生产环境中替换为部署的轻量分类模型(如 BERT-tiny)
return {
**state,
"intent": "open_query",
"task_type": TaskType.SEMANTIC,
}
def rule_engine(state: AgentState) -> AgentState:
"""规则引擎:确定性任务直接映射到 API 调用"""
intent = state["intent"]
slots = state["slots"]
# 意图到执行计划的映射表
execution_map = {
"order_status": {
"tool": "order_api",
"action": "query",
"params": {"order_id": slots.get("order_id")},
},
"refund_policy": {
"tool": "knowledge_base",
"action": "retrieve",
"params": {"doc_type": "refund_policy"},
},
}
plan = execution_map.get(intent)
if not plan:
# 兜底:无法匹配规则时降级到 LLM
return {**state, "task_type": TaskType.SEMANTIC}
return {
**state,
"execution_plan": [plan],
"audit_trail": state.get("audit_trail", [])
+ [{"step": "rule_engine", "intent": intent, "plan": plan}],
}
def llm_engine(state: AgentState) -> AgentState:
"""LLM 推理引擎:开放性任务通过 ReAct 循环执行"""
query = state["query"]
# 构建带约束的 prompt,限制推理范围
system_prompt = (
"你是一个企业业务助手。严格基于提供的工具和知识库回答问题。"
"如果无法确定答案,必须回复'我无法确认该信息,建议转人工处理'。"
"禁止编造任何不存在的政策、数据或流程。"
)
# ReAct 循环:推理 → 行动 → 观察 → 继续推理
# 生产环境中使用 LangGraph 的 ReAct agent 实现
execution_plan = [
{
"tool": "rag_retriever",
"action": "search",
"params": {"query": query, "top_k": 3},
},
{
"tool": "llm_generate",
"action": "synthesize",
"params": {
"system_prompt": system_prompt,
"context": "$rag_retriever.results",
},
},
]
return {
**state,
"execution_plan": execution_plan,
"audit_trail": state.get("audit_trail", [])
+ [{"step": "llm_engine", "query": query}],
}
def route_by_task_type(state: AgentState) -> str:
"""路由函数:根据任务类型决定执行路径"""
if state["task_type"] == TaskType.DETERMINISTIC:
return "rule_engine"
elif state["task_type"] == TaskType.SEMANTIC:
return "llm_engine"
return "llm_engine"
# 构建 LangGraph 状态图
graph = StateGraph(AgentState)
graph.add_node("classifier", intent_classifier)
graph.add_node("rule_engine", rule_engine)
graph.add_node("llm_engine", llm_engine)
graph.set_entry_point("classifier")
graph.add_conditional_edges("classifier", route_by_task_type)
graph.add_edge("rule_engine", END)
graph.add_edge("llm_engine", END)
agent = graph.compile()
这段代码的核心设计思路是路由优先于推理。通过意图分类器将任务分流,确定性任务绕过 LLM 直接执行,既降低了延迟,又消除了幻觉风险。同时,审计日志贯穿整个执行链路,为后续的问题排查和合规审计提供数据支撑。
在商业化层面,这种架构还带来了一个隐性优势:成本可控。规则引擎处理确定性任务的成本几乎为零,只有真正需要语义理解的任务才消耗 LLM Token。在一个日均 10 万次调用的客服系统中,这种分流策略可以将 Token 成本降低 60% 以上。
四、架构的代价——企业 Agent 商业化的三重博弈
任何架构选择都是一种权衡。上述分层解耦架构在获得可靠性和成本优势的同时,也付出了三方面代价:
第一,开发复杂度显著上升。 四层分离意味着每个层都需要独立的开发、测试和运维体系。路由控制器的规则维护、LLM 推理引擎的 Prompt 版本管理、审计层的日志存储与检索——这些都不是简单的事。一个 5 人团队可能需要 3 个月才能搭建起一个可用的 MVP,而"套壳 + API"方案只需要 2 周。
第二,路由边界的模糊地带。 现实中的任务并非非黑即白。比如"帮我查一下最近的退货政策有没有变化",既需要检索确定性知识(退货政策),又需要语义判断("有没有变化"暗示对比推理)。这类混合任务如果强行归入某一类,要么损失智能性,要么损失可靠性。解决方案是引入 HYBRID 类型,先走规则引擎获取基础数据,再交由 LLM 做对比推理,但这又增加了链路长度和故障点。
第三,商业化定价的困境。 企业客户习惯按"坐席数"或"调用量"付费,但 Agent 的价值并不与调用量线性相关。一个成功解决复杂工单的 Agent 调用,价值远超 100 次简单的订单查询。按调用量计费会低估 Agent 的真实价值,按结果计费又难以定义和衡量"成功"的标准。这是目前企业 Agent 商业化最大的卡点之一。
适用边界方面,这种架构最适合高频、中复杂度、合规要求严格的企业场景(如金融客服、医疗问诊、法律咨询)。对于低频但超高复杂度的场景(如战略决策辅助),分层架构的 ROI 可能不如直接使用高能力 LLM + 人工审核的轻量方案。
五、总结
企业级 Agent 产品不是"大模型 + 工具调用"的简单叠加,而是一个需要在智能性与确定性之间寻找平衡的工程系统。分层解耦架构通过感知、决策、执行、审计四层分离,将 LLM 的不确定性约束在可控范围内,同时保留了语义推理的核心能力。路由控制器是架构的关键枢纽,它决定了哪些任务需要"智能",哪些只需要"确定"。
商业化落地上,需要关注三个核心指标:Token 成本占比(目标 < 30%)、确定性任务命中率(目标 > 50%)、审计覆盖率(目标 100%)。这三个指标直接决定了 Agent 产品的经济可行性和企业客户的信任度。技术架构只是起点,找到付费意愿与技术成本的交叉点,才是 Agent 产品从"能用"走向"能卖"的关键。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)