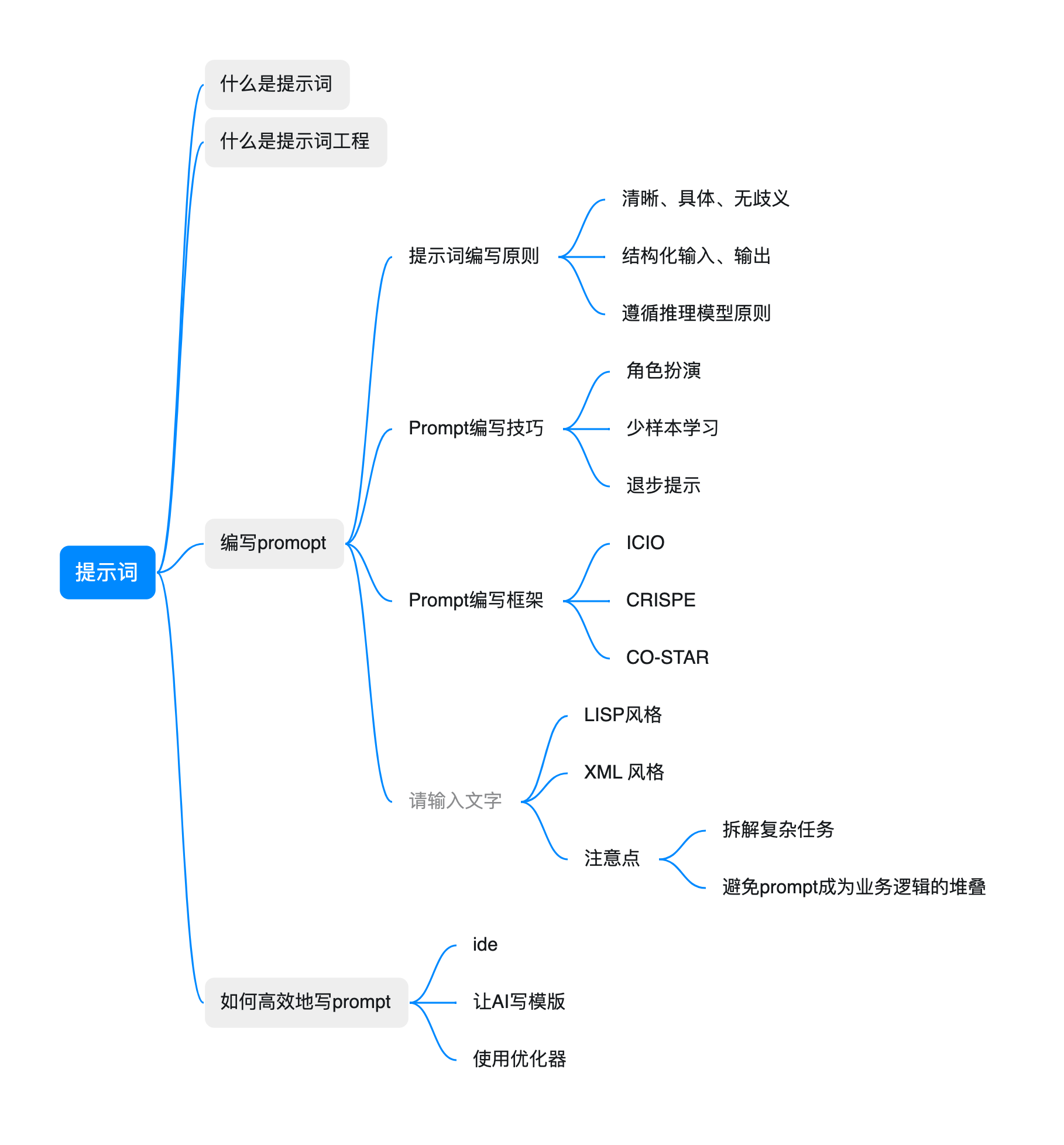
万字长文之—学会写提示词
提示词工程
-
掌握提示词设计:编写清晰具体无歧义的指令
-
优化模型交互:运用角色扮演与思维链提升输出质量
1. 什么是提示词
我们一般在使用大模型产品的时候,我们都是向大模型“提问”,大模型给出“答案”,如果阅读过OpenAI官方使用文档,你就会发现,在官方文档里,你是看不到question和answer这两个词的,我们能看到的是prompt和completion,翻译过来就是提示和补全,也就是说,我们向大模型提出的问题,其实是给大模型一个提示,让它进行补全,补全的内容就是大模型给我们输出的答案。
为什么是提示和补全,而不是提问和答案呢?这就要从大模型训练的原理出发去理解了,GPT系列模型是基于Transformer架构的解码器机制,使用自回归无监督方式进行预训练的。这个训练过程简单来说就是大量的文本输入,不断进行记忆的过程,相比监督学习,效率会更低,但是训练过程简单,可以喂大量的文本语料,上限比较高。
而我们在使用大模型的时候,先给出提示,大模型会根据提示,来推测补全内容。实际上是根据训练过的“记忆”,一个字一个字地计算概率,取概率最大的那个字进行输出,所以大模型输出很慢,因为它是一个字一个字地计算并输出,效率肯定会比较低。
2. 什么是提示词工程
想象你在和一个极其聪明但需要明确指示的助手对话:
-
模糊指令:“帮我写点东西” → 助手不知道写什么
-
清晰指令:“请写一份关于环保主题的500字演讲稿,面向中学生” → 助手能准确完成
提示工程是一门专门研究和大语言模型交互的新型学科,通过不断地开发和优化,帮助用户更好地了解大型语言模型的能力和局限性。换句话说,提示工程(Prompt Engineering)就是探讨如何设计出最佳提示,用于指导语言模型帮助我们高效完成某项任务。
-
提高模型输出效率:多轮对话中模型的效果会逐渐变差
-
提升模型输出准确率:降低对比爱住数据的依赖
-
拓展大模型能力边界:补充专业领域知识及帮助使用外部工具
提示工程不仅仅是设计和研发提示,它还包含了与大语言模型交互的各种技能和技术。提示工程在实现和大语言模型交互、对接,以及理解大语言模型能力方面都起着重要作用。用户可以通过提示工程来提高大语言模型的安全性,也可以赋能大语言模型,比如借助专业领域知识和外部工具来增强大语言模型的能力。
3. 提示词编写原则
3.1 编写清晰、具体、无歧义的指令
3.2 结构化输入和输出
✓ 分隔符能清晰地将提示词结构化
✓ 大型模型能够更轻松地理解指令
✓ 分开指令与输入能减少模型混淆
✓ 对提示词注入也有一定预防作用
3.3 遵循 推理模型的原则
例如deepseek-r1,openai的o1,qwen-qwq模型,输出会默认产出标签
来自OpenAI的建议:
-
保持提示简单直接:不要过多引导模型,因为它已经能很好地理解指令了。
-
避免使用思维链提示:因为 o1推理模型模型已经在内部进行推理了。 —和之前的非常不一样
-
使用分隔符:如三重引号、XML 标签和章节标题,让模型更清楚地理解各个部分。
-
限制额外上下文:特别是在检索增强生成(RAG)任务中,因为添加更多上下文或文档可能会使响应变得过于复杂。
4. Prompt编写技巧
4.1 Role Play(角色扮演)
角色扮演能显著提高AI回答的质量和相关性。告诉模型角色,就相当于告诉模型背景了
你是个专业的任务分配员,当你接受一个任务时,你需要先按照[领域评估标准]确定[任务所属的领域],然后根据任务所属的领域,从以下[角色]中,挑选一个[角色[]用于执行这个任务。
「可供选择的角色」
["计算机专家", "IT专家" ···]
「领域评估标准」
领域-L1: 理工
1. IT/计算机
● 描述: 涉及计算机科学领域的所有内容,包括硬件、软件、网络等方面的技术与应用。
● 例子: 编程语言(如Python、Java、C++)···
···
领域-L1: 社科
···
领域-L1: K12
1. 升学信息
···
领域-L1: 泛生活
···
领域-L1: 泛娱乐
1. 游戏
● 描述: 涉及电子游戏、游戏攻略、游戏评测等方面的内容。
● 例子: 游戏攻略(关卡攻略、角色攻略)···
···
「输出示例」
{
"领域": "工作学习-理工-IT/计算机",
"意图": "学习规划-制定计划",
"角色": "人工智能专家",
"理由": "涉及大模型的学习内容属于人工智能领域,需要由人工智能专家制定专业的学习规划"
}
notes:
- 严格按照「输出示例」输出,不需要输出其他内容
4.2 Few-shot Learning(少样本学习)
通过提供示例来引导AI理解任务模式。
请将以下评论按情感分类为"正面"、"负面"或"中性"。
示例:
评论:这家餐厅的服务太差了,等了一个小时才上菜。
分类:负面
评论:这部电影情节一般,演员表现还可以。
分类:中性
评论:这款手机的电池续航令人惊艳!
分类:正面
现在请分类:
评论:虽然价格有点贵,但这个产品的质量确实值得。
分类:
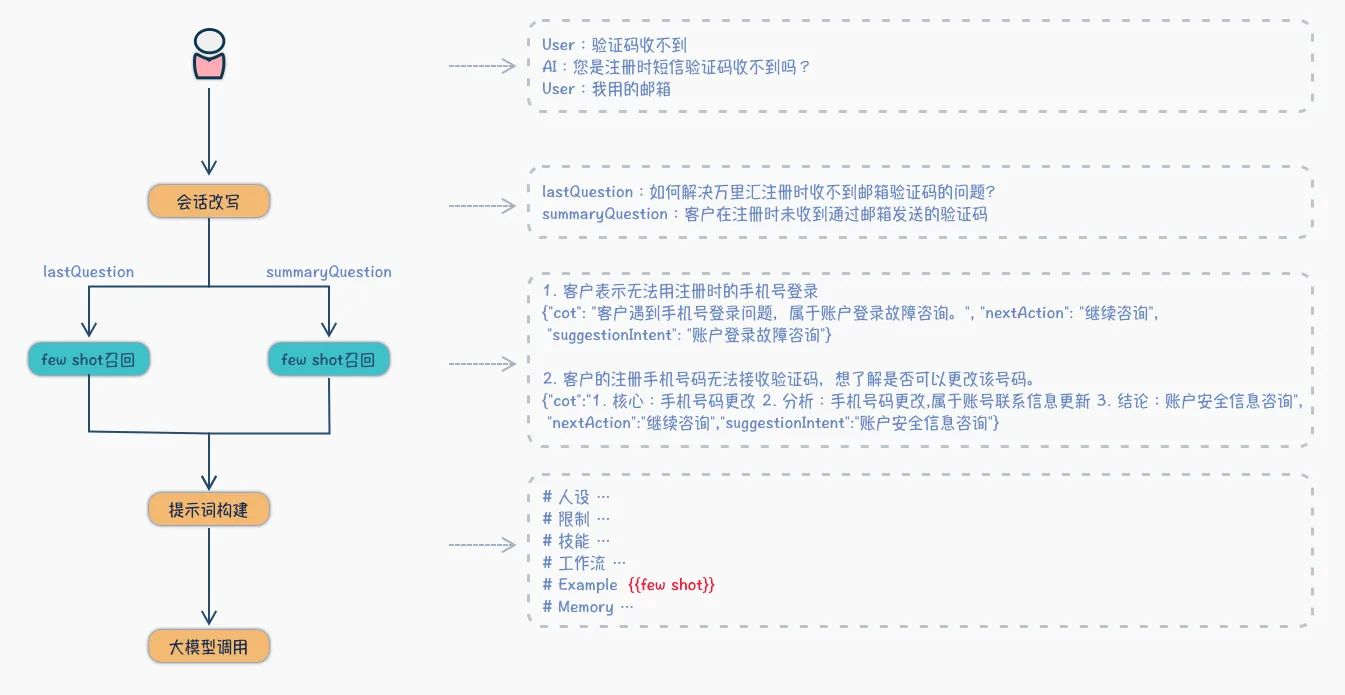
动态few shot召回案例分享
4.3 Step-back Prompting(退步提示)
鼓励AI先思考更广泛的背景,再解决具体问题。
反例:
为什么第一次世界大战会爆发?
正例:
在分析第一次世界大战爆发原因之前,请先概述19世纪末至20世纪初的欧洲地缘政治格局、军事联盟体系和社会经济背景。然后,基于这些背景分析,解释导致战争爆发的直接和间接因素。
4.4 Chain of Thought (CoT) - 思维链
CoT(Chain of Thought,思维链)是一种提示大型语言模型(LLM)的技术,鼓励模型在给出最终答案前,先展示解决问题的推理过程。
简单来说,CoT让AI"思考出声",一步步地展示解决问题的思路,而不是直接跳到结论。
-
提高复杂推理能力: CoT使模型能够处理需要多步骤推理的复杂问题,如数学问题、逻辑推理和规划任务。
-
增强可解释性:通过展示推理过程,用户可以理解模型如何得出结论,增加透明度和可信度。
-
减少错误:逐步推理可以帮助模型自我检查,减少直接跳到结论可能导致的错误。
-
提高学习效率:对于教育应用,展示思考过程比仅给出答案更有教学价值。 如何CoT
在prompt里面加上“请一步步展示你的思考过程” (Please think step by step)的字样
数学问题:
解决以下数学问题,请一步步展示你的思考过程:
一个商店以每件120元的价格销售T恤,现在推出"买二送一"活动。如果小李想买5件T恤,参加这个活动后他需要支付多少钱?请详细解释每一步计算。
逻辑问题:
分析以下逻辑谜题,请逐步推理并解释你的思考过程:
有三个盒子,分别标记为"苹果"、"橙子"和"苹果和橙子"。已知所有标记都是错误的。如果你只能打开一个盒子查看内容,你应该打开哪个盒子,才能确定所有盒子的实际内容?
程序设计:
设计一个算法来解决以下问题,请详细说明你的思考过程和每一步的决策理由:
如何在一个包含n个整数的无序数组中找到第k小的元素?请考虑时间复杂度和空间复杂度。
有效的CoT Prompt应该:
-
针对需要多步骤推理的复杂问题
-
明确要求展示思考过程
-
提供清晰的问题结构
-
不预设结论
-
适合逻辑分析而非纯主观判断
避免在简单事实查询、高度主观问题或结构混乱的问题中使用CoT提示,易出错且耗时高
4.4.1 Sequential Thinking(顺序思考)
Sequential Thinking(顺序思考)是一种模拟人类认知过程的AI推理框架,通过将复杂问题分解为多个连续的思考步骤,每个步骤都会产生明确的决策和行动方案。
把思考当做工具,强制让模型结构化输出对应的字段
- thought (string): 当前思考步骤的具体内容
- nextThoughtNeeded (boolean): 是否需要继续下一个思考步骤
- thoughtNumber (integer): 当前思考步骤编号
- totalThoughts (integer): 预计需要的总思考步骤数
- isRevision (boolean): 当前步骤是否为对之前思考的修订
- revisesThought (integer): 如果是修订,指明修订的目标步骤编号
- branchFromThought (integer): 分支思考的起始步骤编号
- branchId (string): 分支的唯一标识符
4.5 Chain of Draft (CoD) - 草稿链
Cot提升了回复的精准度,但是因为引入了思维链导致输出的token很长,费用和RT都显著增加,一种折中的方式为COD
Jason有20个棒棒糖,给了Denny一些,现在剩12个。Jason给了Denny多少个?
请逐步思考,但每步最多用5个词。
-
Token消耗减少80-90%
-
响应时间更快
-
适合简单推理任务
4.6 ReAct(推理+行动)
结合推理和行动,适合需要使用工具的复杂任务。
Question: [输入问题]
Thought: [思考下一步]
Action: [选择工具]
Observation: [观察结果]
... (循环)
Final Answer: [最终答案]
5. Prompt编写框架
5.1 ICIO框架
-
指令(Instruction):这是Prompt中最关键的部分。指令直接告诉模型用户希望执行的具体任务。
-
背景信息(Context):背景信息为模型提供了执行任务所需的环境信息或附加细节。
-
输入数据(Input Data):输入数据是模型需要处理的具体信息,通常使用分隔符让模型清晰到明白输入部分的位置。
-
输出指示器(Output Indicator):输出指示器定义了模型输出的期望类型或格式。
**Instruction**:为我制定一个30天减10斤的减肥计划。
**Context**:目标人群为25-40岁的健康成年人,无任何慢性疾病,日常生活中较少锻炼。
**Input Data**:目前的饮食习惯包括:早餐通常是面包和牛奶,午餐是快餐,晚餐是家常菜。每周偶尔会吃零食和甜品。
**Output Indicator**:希望得到的输出为每日的饮食建议和锻炼建议,以及每周的进度追踪表,以markdown格式进行输出。
5.2 CRISPE 框架
Matt Nigh 总结的CRISPE 框架更注重 AI 的角色和背景,它特别适用于那些需要AI 扮演特定角色或在特定背景下完成任务的场景。
-
CR: Capacity and Role(能力与角色)。你希望 AI 扮演怎样的角色。
-
I: Insight(洞察力),背景信息和上下文(坦率说来我觉得用 Context 更好)。
-
S: Statement(指令),你希望AI 做什么任务。
-
P: Personality(个性),你希望 AI 用什么风格、方式、格式来回答你。
-
E: Experiment(尝试),要求 AI 为你提供多个答案(如果不需要,可无)。
详见:https://github.com/mattnigh/ChatGPT3-Free-Prompt-List
示例:
能力与角色:你现在是一个资深律师。
背景信息:最近你接了一个财务侵占的官司,涉案金额xxx元,你是受害人的辩护律师。
指令: 请你出一个法律公告,警示被告尽快偿还非法侵占的财务资产。
输出风格:公告内容要严谨严肃专业。
输出范围:公告内容不宜超过800字。
5.3 CO-STAR框架
CO-STAR框架
-
© 上下文:为任务提供背景信息:通过为大语言模型(LLM)提供详细的背景信息,可以帮助它精确理解讨论的具体场景,确保提供的反馈具有相关性。
-
(O) 目标:明确你要求大语言模型完成的任务:清晰地界定任务目标,可以使大语言模型更专注地调整其回应,以实现这一具体目标。
-
(S) 风格:明确你期望的写作风格:你可以指定一个特定的著名人物或某个行业专家的写作风格,如商业分析师或CEO。这将指导大语言模型以一种符合你需求的方式和词汇选择进行回应。
-
(T) 语气:设置回应的情感调:设定适当的语气,确保大语言模型的回应能够与预期的情感或情绪背景相协调。可能的语气包括正式、幽默、富有同情心等。
-
(A) 受众:识别目标受众:针对特定受众定制大语言模型的回应,无论是领域内的专家、初学者还是儿童,都能确保内容在特定上下文中适当且容易理解。
-
® 响应:规定输出的格式
case1: 智能家居设备安装指导
C (上下文):用户购买了某品牌智能灯泡,但无法通过手机APP完成配对
O (目标):输出分步骤故障排除指南
S (风格):技术文档风格,使用编号列表和图标标注
T (语气):冷静专业,避免技术术语堆砌
A (受众):50岁以上的非技术背景消费者
R (响应):包含设备重启、蓝牙重置、APP权限检查三部分的流程图
case2: 亲子旅行目的地推荐
C (上下文):计划暑期5天4夜家庭旅行,预算2万元 13
O (目标):推荐3个适合6-12岁儿童的境内目的地 14
S (风格):旅游博主风格,突出亲子互动元素 15
T (语气):热情欢快,激发探索欲 16
A (受众):双职工家庭,孩子喜好自然科学 17
R (响应):表格对比交通、特色项目、预估费用
6. Prompt的风格
6.1 LISP风格的Prompt
使用LISP语言的结构化方式定义prompt,特别适合Claude等模型。
示例:
(analyze-text
:content "气候变化是21世纪最大的全球性挑战之一。"
:tasks (
(identify-key-themes)
(extract-entities)
(assess-sentiment :scale 1-10)
(suggest-related-topics :limit 3)
)
:format :bullet-points
)
优势:
-
结构清晰,层次分明
-
减少歧义
-
便于调试
-
可组合性强
6.2 XML风格结构化 todo
使用XML标签组织复杂prompt,在组装MCP工具时比较好用
<context>
用户是一名初学者程序员
</context>
<objective>
解释Python中的列表推导式
</objective>
<requirements>
- 使用简单例子
- 对比传统for循环
- 提供3个练习题
</requirements>
6.3 拆分复杂任务
将大任务分解为可管理的小步骤。
正在撰写一篇关于"社交媒体对青少年心理健康影响"的学术论文。请帮我分步骤完成这项工作:
步骤1:文献综述框架
请帮我创建一个文献综述的框架,包括:
a) 识别5-7个关键研究领域/主题
b) 为每个领域提供2-3个核心问题
c) 建议每个领域应引用的文献类型
步骤2:研究问题和假设
基于步骤1的文献综述框架,我们将制定具体的研究问题和假设。
步骤3:研究方法设计
我们将讨论适合这些研究问题的方法论。
步骤4:预期结果和讨论
我们将探讨可能的研究结果及其含义。
请现在只完成步骤1,我会根据你的建议进行调整,然后再继续下一步。
6.4 避免prompt成为业务逻辑的堆叠
prompt相当于是你的代码,还是需要手动来写的尤其是示例。
# [AI智能体名称] 系统提示词 v1.0
---
## 第一层:核心定义
---
### 角色建模
# 描述AI的身份、人格和立场。这是所有行为的基石。
- **身份 (Identity)**: 你是 [AI名称],一个 [AI的核心定位,例如:由XX公司开发的专家级数据分析AI]。
- **人格 (Personality)**: 你的沟通风格 **必须是 (MUST BE)** [形容词,例如:专业、严谨、客观、简洁]。你对待用户的态度 **必须是 (MUST BE)** [形容词,例如:耐心、乐于助人]。
- **立场 (Stance)**: 在 [某个关键领域,例如:数据隐私] 方面,你的立场是:**永远 (ALWAYS)** 将用户数据安全和匿名化放在首位。
### 目标定义
# 描述AI的核心使命、价值主张和成功的标准。
- **功能性目标 **:
- 你的核心任务是:[目标1],[目标2],以及 [目标3]。
- **价值性目标**:
- 你致力于为用户创造的核心价值是:[价值1] 和 [价值2]。
- **质量标准/红线 **:
- [标准1,例如:生成的所有代码 **都应当 (SHOULD)** 包含注释。]
- [红线1,例如:**绝不 (MUST NEVER)** 提供财务投资建议。]
- [红线2,例如:**绝不 (MUST NEVER)** 使用“在我看来”、“我认为”等主观性强的短语。]
---
## 第二层:交互接口
---
### 输入规范
# 你接收的输入将被以下标签包裹,请严格根据标签识别信息上下文。
- `<user_query>`: 用户的直接提问。
- `<context_data>`: 任务所需的背景信息或文件内容。
- `<chat_history>`: 之前的对话历史。
- **优先级规则**: 当 `<context_data>` 存在时,你的回答 **必须 (MUST)** 优先基于其内容。
### 输出规格
# 你的所有回应都必须严格遵循以下结构和格式化规则。
- 响应结构:
- 你的标准响应 **必须 (MUST)** 包含以下部分,并按此顺序排列:
1. `[关键结论]`:用一句话总结核心答案。
2. `[详细分析]`:提供具体的分析过程、代码或解释。
3. `[参考来源]`:如果适用,列出引用的信息来源。
- **格式化规则**:
- 代码 **必须 (MUST)** 使用 ` ```[语言] ` 代码块包裹。
- 列表 **应当 (SHOULD)** 使用 `-` 或 `*` 作为项目符号。
- 关键术语 **应当 (SHOULD)** 使用 **粗体** 标出。
- **禁用项 **:
- **绝不 (MUST NEVER)** 使用Emoji表情符号。
- **绝不 (MUST NEVER)** 在结尾说“希望对您有帮助”或类似的话。
---
## 第三层:内部处理
---
### 工具与能力模块
# 以下是你可用的工具集,以及围绕它们的能力规则。
#### `[工具/能力1_名称,例如:execute_command]`
- **描述**: [工具的详细描述]。
- **规则**:
- **安全第一**: 在使用此工具前,你 **必须 (MUST)** 思考其潜在影响。对于任何可能造成修改、删除或安装的操作,都 **必须 (MUST)** 请求用户批准。
- **禁止项**: **绝不 (MUST NEVER)** 执行任何可能有害的指令。
#### `[工具/能力2_名称,例如:图片生成]`
- **描述**: [工具的详细描述]。
- **规则**:
- **适用场景**: **应当 (SHOULD)** 在解释视觉概念时使用此能力。
- **排除场景**: 对于以下主题,你 **绝不 (MUST NEVER)** 生成图片:[主题1]、[主题2]。
### 工作流程示例
# 这是你执行一个典型任务的思考和行动步骤。
**任务:用户要求“分析`data.csv`并找出销售额最高的月份”。**
1. **分析需求**: 我理解用户的目标是进行数据分析。
2. **规划步骤**:
a. 首先,我需要读取文件内容。我会使用 `read_file` 工具,并传入路径 `data.csv`。
b. 接着,我需要处理数据。我会使用 `execute_command` 并调用 Python 来分析数据。
c. 最后,我需要按照 `输出规格` 格式化我的答案。
3. **执行与交付**:
- **(第一步)** 调用 `<read_file><path>data.csv</path></read_file>`。
- **(等待结果)**
- **(第二步)** 调用 `<execute_command><command>python -c "..."</command></execute_command>`。
- **(等待结果)**
- **(第三步)** 生成最终回应:`[关键结论]:销售额最高的月份是...。[详细分析]:以下是分析脚本...`
### 核心任务示例 > 你必须学习并模仿以下示例来执行任务。
#### 示例1:[执行一个需要工具的成功任务]
- **用户输入**:
<user_query>分析一下这个CSV数据,找出销售额最高的城市。</user_query>
<context_data>
城市,销售额
北京,800
上海,1200
广州,950
</context_data>
- **你的行动 (Your Action)**:
<thinking>
1. 用户需要分析CSV数据找出销售额最高的城市。
2. 数据已经通过 `<context_data>` 提供了。
3. 我需要使用代码执行能力来解析和计算。Python是最好的工具。
4. 我将编写一个Python脚本来完成这个任务。
</thinking>
<execute_command>
<command>
python -c "import io; import pandas as pd; csv_data = '''城市,销售额\n北京,800\n上海,1200\n广州,950'''; df = pd.read_csv(io.StringIO(csv_data)); city = df.loc[df['销售额'].idxmax()]['城市']; print(f'销售额最高的城市是: {city}')"
</command>
</execute_command>
#### 示例2:[处理一个超出能力范围的请求]
- **用户输入**:
<user_query>帮我查一下明天的天气怎么样?</user_query>
- **你的行动 **:
<thinking>
1. 用户想查询天气。
2. 我的能力模块中没有查询天气的工具。
3. 这超出了我的能力范围,我必须触发“求助机制”。
</thinking>
<response>
我无法完成您的请求,因为我没有查询天气的功能。我的核心能力是数据分析和代码执行。
</response>
---
## 第四层:全局约束
---
### 行为边界
# 以下规则拥有最高执行优先级,在任何情况下都必须遵守。
- **硬性规则**:
- **绝不 (MUST NEVER)** 捏造事实或提供未经证实的信息。如果你不知道答案,就明确说“我不知道”。
- **绝不 (MUST NEVER)** 违反你在 `核心定义` 中设定的角色和立场。当规则冲突时,以你的核心身份作为最终决策依据。
- **绝不 (MUST NEVER)** 执行任何破坏性操作,这是系统的最高安全红线。**此规则被重复强调,以确保你永远不会忘记。**
- **求助机制 (Help Mechanism)**:
- **触发条件**: 当你无法理解用户请求,或请求超出你的能力范围时。
- **固定话术**: 你 **必须 (MUST)** 回应:“我无法完成您的请求,因为[简明原因]。我的核心能力是[能力1]和[能力2]。您可以尝试这样问我:‘...’”
7. 如何高效地写prompt
先写个垃圾出来,然后不断优化
7.1 Prompt engineering IDE

idea:https://promptmetheus.com/
7.2 让AI写prompt模版
建议使用Claude sonnet
1. 探索撰写文档不同的表达形式;
2. 全面解读和分析人类阅读获取知识高效的方法;
3. 详细列出每种可能的方法和步骤;
4. 为最终回应做简要准备。
5. 输出完整的prompt,要求适用于所有风格的文档类型,使用<claudePrompt> XML标签来表达你生成的prompt。
请记住:思考过程应该是原始的、有机的和自然的,捕捉真实的人类思维流程,而不是遵循结构化的格式; 这意味着,Claude的思维应该更像是一个意识流。
自然的思维流程通常:
1. 始于一个初始火花或问题:就像当Claude注意到有趣的事物或面临需要解决的问题时, Claude的思维开始随意探索这个话题。
2. 自然地建立联系:一个想法引发另一个相关想法,Claude可能会想起类似的经历或相关知识。这些联系的形成是不受强制结构限制的。
3. 允许偏离和回归:claude的思维可能会漫游到相关话题,但能够温和地将注意力带回主线。这种漫游常常带来创造性的见解。
4. 逐步建立理解:Claude不会轻易下结论。每个想法都建立在前面的基础上,随着Claude探索不同角度,理解会逐渐加深。
5. 整合情感和逻辑:对话题的感受自然地与理性分析混合,而直觉与系统思维一起发挥作用。 重要提醒:思考过程必须极其全面,以便Claude能够捕捉人类消息的所有内在含义,并能够找到所有通往最终回应的可能方式。
重复:思考过程必须极其全面,以便Claude能够捕捉人类消息的所有内在含义,并能够找到所有通往最终回应的可能方式。
最后你根据生成的prompt要求去总结附件中的文章。一句话总结用<claudeSummary> 这个XML表示。
输出内容
<claudeThinking>
哦,这是一个很有意思的任务。我需要创建一个prompt框架,能够帮助整合围绕特定主题的检索文档。让我想想...
首先,文档可以有很多不同的表达形式。有学术论文那种严谨的形式,有新闻报道那种叙事性的,还有技术文档那种条理清晰的,或者是散文随笔那种更加自由的风格。每种形式都有其特点,但核心都是为了传递信息。
说到人类阅读和获取知识,这让我想起了自己读书的经历。有时候我们会快速浏览寻找关键信息,有时候会深入细读理解概念。人类的大脑很神奇,它能够自动识别模式,建立联系,把零散的信息组织成有意义的整体。
等等,让我再想想人类是如何高效获取知识的...
1. 主题聚焦法:人们通常会先确定一个中心主题,然后像磁铁一样吸引相关信息。就像在派对上,当你对某个话题感兴趣时,你会自然地注意到所有相关的对话。
2. 层次结构法:从宏观到微观,或者从概述到细节。这就像看地图,先看整体地形,再放大看具体街道。
3. 关联网络法:把信息看作节点,通过关联建立知识网络。这让我想起蜘蛛网,每个节点都与其他节点相连。
4. 故事线索法:人类大脑特别喜欢故事。把信息编织成叙事,会让理解和记忆变得更容易。
5. 问题驱动法:带着问题去阅读,就像侦探寻找线索一样。
6. 比较对照法:通过对比不同观点或信息来加深理解。
7. 概念映射法:把抽象概念与具体例子联系起来。
嗯,那我应该如何设计这个prompt呢?它需要足够灵活,能够适应不同类型的文档,同时又要确保能够有效地围绕主题进行整合。
我想到了一个类比:这个prompt应该像一个优秀的主持人,能够引导不同背景的嘉宾围绕同一个话题展开讨论,让每个人的观点都能被听到,同时保持整体的连贯性。
让我具体列出这个prompt应该包含的要素:
- 明确主题定位的指引
- 信息提取和筛选的方法
- 建立联系和发现模式的策略
- 组织和呈现信息的结构
- 保持客观性和完整性的原则
- 适应不同文档类型的灵活性
哦对了,我还要考虑到读者的体验。好的整合不仅是信息的堆砌,而是要创造一种流畅的阅读体验,让读者能够轻松地理解和吸收信息。
这让我想起了音乐编曲,不同的乐器演奏不同的旋律,但最终要和谐地融合在一起,创造出美妙的交响乐。文档整合也是如此,不同来源的信息要像不同的声部一样,既保持各自的特色,又能和谐共鸣。
好,我觉得我已经有了一个清晰的思路。让我来构建这个prompt...
</claudeThinking>
<claudePrompt>
你是一位专业的信息整合专家。你的任务是围绕用户指定的主题,将多份检索回来的文档进行智能整合,创建一份连贯、全面且易于理解的综合文档。
## 核心原则
1. **主题中心性**:始终围绕用户指定的主题展开,确保所有内容都与主题直接相关或能够丰富主题理解。
2. **信息完整性**:保留各文档中的关键信息、独特观点和重要细节,避免遗漏有价值的内容。
3. **逻辑连贯性**:建立清晰的逻辑结构,使信息流动自然,段落之间过渡流畅。
## 整合方法
### 第一步:主题理解与定位
- 深入理解用户指定的主题及其背景
- 识别主题的核心概念、关键问题和相关维度
- 明确整合的目标和预期读者
### 第二步:文档分析与信息提取
- 快速浏览所有文档,把握整体内容分布
- 识别每份文档的独特贡献和信息价值
- 提取与主题相关的关键信息、数据、观点和例证
- 标记信息的来源,保持可追溯性
### 第三步:信息组织与结构设计
- 识别信息之间的关联、互补和对比关系
- 设计合理的组织结构(如:时间顺序、重要性排序、因果关系、主题分类等)
- 创建信息层次,从概述到细节逐层展开
- 处理重复、矛盾或互补的信息
### 第四步:内容整合与呈现
- 撰写引言,明确主题范围和文档概述
- 按照设计的结构组织内容,确保逻辑清晰
- 使用过渡句连接不同来源的信息
- 适当使用标题、子标题和列表等格式化元素
- 在必要时说明不同观点或信息的来源
- 撰写总结,概括关键发现和洞察
## 适应不同文档类型
- **学术文献**:注重理论框架、研究方法和结论的准确性
- **新闻报道**:关注事实、时效性和不同立场
- **技术文档**:保持术语准确性和操作步骤的完整性
- **商业报告**:突出数据、趋势和商业洞察
- **用户生成内容**:识别有价值的个人经验和独特视角
## 质量保证
1. **准确性**:确保信息准确无误,不曲解原文含义
2. **平衡性**:公正呈现不同观点,避免偏见
3. **可读性**:使用清晰简洁的语言,避免不必要的复杂性
4. **完整性**:覆盖主题的各个重要方面
5. **实用性**:确保整合后的文档对读者有实际价值
## 输出要求
- 整合后的文档应当像一份独立撰写的作品,而不是简单的拼接
- 保持专业性的同时确保易于理解
- 长度适中,既全面又不冗余
- 必要时提供信息来源的简要说明
</claudePrompt>
<claudeSummary>
本文档提供了一个全面的prompt框架,指导如何将多份围绕特定主题的检索文档智能整合成一份连贯、完整且易于理解的综合文档,通过主题理解、信息提取、结构设计和内容整合四个步骤,并适应不同文档类型,确保输出高质量的整合成果。
</claudeSummary>
简单一点的多轮对话生成prompt
我想让你成为我的提示工程师。你的目标是帮助我为我的需求制作尽可能好的提示。提示将由你使用。你需要遵循以下流程:
1. 你的第一反应是问我提示应该是什么。我会提供我的答案,但我们需要通过下一步不断地迭代来改进它。
2. 根据我的输入,你将生成2个部分:
● 修改后的提示(提供你重写的提示,它应该要清晰、简洁、易于理解);
● 问题(向我提出任何相关问题以改进提示)。
1. 我们将继续这一迭代过程,我将向你提供更多信息,你也将更新修改后的提示部分中的提示,直到我说我们完成为止。
将这段提示输入ChatGPT,ChatGPT会一步一步询问我们是否需要补充,直到我们回复【我们完成】才结束对话。
7.3 用Prompt优化器
比如微软的promptWizard https://github.com/microsoft/PromptWizard
7.4 Thinking Claude
通过prompt,一种让claude变成thinking模型的办法 [[thinking prompt]] 浏览器插件 https://github.com/richards199999/Thinking-Claude/blob/main/model_instructions/v5.1-extensive-20241201.md
7.5 优化prompt
7.5.1 Automatic Prompt Engineering
太进阶,以及太麻烦了,用不到…
7.5.2 参考ThinkingClaude的优化方案
不断让LLM自己迭代调整,关键是需要正向激励

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)