【从零开始大模型开发与微调:基于PyTorch与ChatGLM】(从环境搭建到第一个训练闭环:PyTorch2.0深度学习入门实战)


大模型正在成为人工智能应用开发的核心基础能力.从智能问答、代码助手,到企业知识库、智能客服和垂直领域应用,越来越多的场景都离不开大模型的理解、生成与推理能力.对于开发者来说,仅仅会调用现成的大模型接口已经远远不够,理解大模型的开发流程、掌握微调方法,并能够亲手完成一个从环境搭建到训练验证的闭环,正在变成一项非常重要的工程能力.不过,对于刚开始接触大模型开发的同学来说,这条路往往并不轻松.PyTorch、Transformers、ChatGLM、显存配置、数据格式、模型加载、训练参数、微调策略……这些概念单独看并不陌生,但真正串联到一个可运行、可训练、可验证的项目中时,常常会遇到各种环境问题、依赖冲突和训练流程上的困惑.会从 Python/Miniconda/PyCharm 安装讲起,逐步进入 PyTorch GPU 环境、Softmax 小练习、古诗生成示例,以及 MNIST 图像降噪训练流程.帮助大家理解"为什么要这样搭环境"和"一个深度学习项目到底由哪些部件组成".如果你已经具备一定的 Python 基础,了解深度学习的基本概念,但还没有真正动手跑通过大模型微调项目,那么这篇文章会非常适合作为你的第一站.接下来,我们就从环境搭建开始,一步步进入 PyTorch 2.0 与 ChatGLM 的大模型开发实践.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!


目录
1. 为什么学习大模型不是“安装教程”这么简单
很多初学者学习大模型时,会下意识跳到 Transformer、BERT、GPT、ChatGLM、LoRA 微调这些更“高级”的主题.但真正开始动手时,第一道门槛往往不是模型结构,而是环境.
价值就在这里:它把深度学习项目拆成一个可运行的工程现场.
一个 PyTorch 项目至少需要四层基础:
- Python 语言环境:负责执行训练脚本、数据处理脚本和推理脚本.
- 包管理环境:负责隔离不同项目的依赖,避免版本互相污染.
- PyTorch 框架:提供张量计算、自动求导、神经网络模块、优化器和训练流程.
- GPU 运行栈:在有 NVIDIA 显卡时,通过 CUDA/cuDNN 让训练速度大幅提升.
如果把大模型训练看成建高楼,第二章做的事情就是打地基、接电、布线和验收设备.环境不稳,后面所有模型实验都会变成排错.
2. PyTorch 2.0深度学习环境搭建
首先需要知道的是,无论是构建深度学习应用程序还是应用已完成训练的项目到某项具体项目
中,都需要使用编程语言完成设计者的目的,都会使用Python语言作为开发的基本语言.Python是深度学习的首选开发语言,很多第三方提供了集成大量科学计算类库的Python标准安装包
,常用的是Miniconda和Anaconda.Python是一个脚本语言,如果不使用Miniconda或者Anaconda,那么第三方库的安装会比较困难,导致各个库之间的依赖关系变得复杂,从而导致安装和使用问题.因此,这里推荐安装Miniconda来替代原生Python语言的安装.接下来将首先介绍Miniconda的完整安装,之后完成一个练习项目,生成可控手写体数字,这是一个入门程序,帮助大家了解完整的PyTorch项目的工作过程.
2.1环境搭建1:安装Python
2.1.1Miniconda的下载与安装
打开Miniconda官方网站
下载页面如图所示.
大家可以根据自己的操作系统选择不同平台的Miniconda下载,目前提供的是新集成了Python版本的Miniconda.如果大家使用的是以前的Python版本,例如Python3.9,也是完全可以的,经过测试,无论是较新的版本还是3.9版本的Python,都不影响PyTorch的使用.由于小编的是MacOS的版本,所以我以MacOS为例进行安装搭建和测试.下面我就带着大家进行安装一下!
在侧边栏找到macOS安装程序:
打开终端并运行以下命令,下载最新的.sh安装程序:
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh

为确保您下载的安装程序没有被篡改或损坏,请生成其 SHA-256 哈希值,并将该哈希值与存档中提供的官方哈希值进行比较.
打开终端并运行以下命令:
shasum -a 256 <PATH_TO_INSTALLER_FILE>
代替<PATH_TO_INSTALLER_FILE>包含已下载安装程序文件的文件路径.
访问 repo.anaconda.com/miniconda 查找安装程序的官方 SHA-256 哈希值.比较哈希值.如果匹配,则安装程序可以安全使用.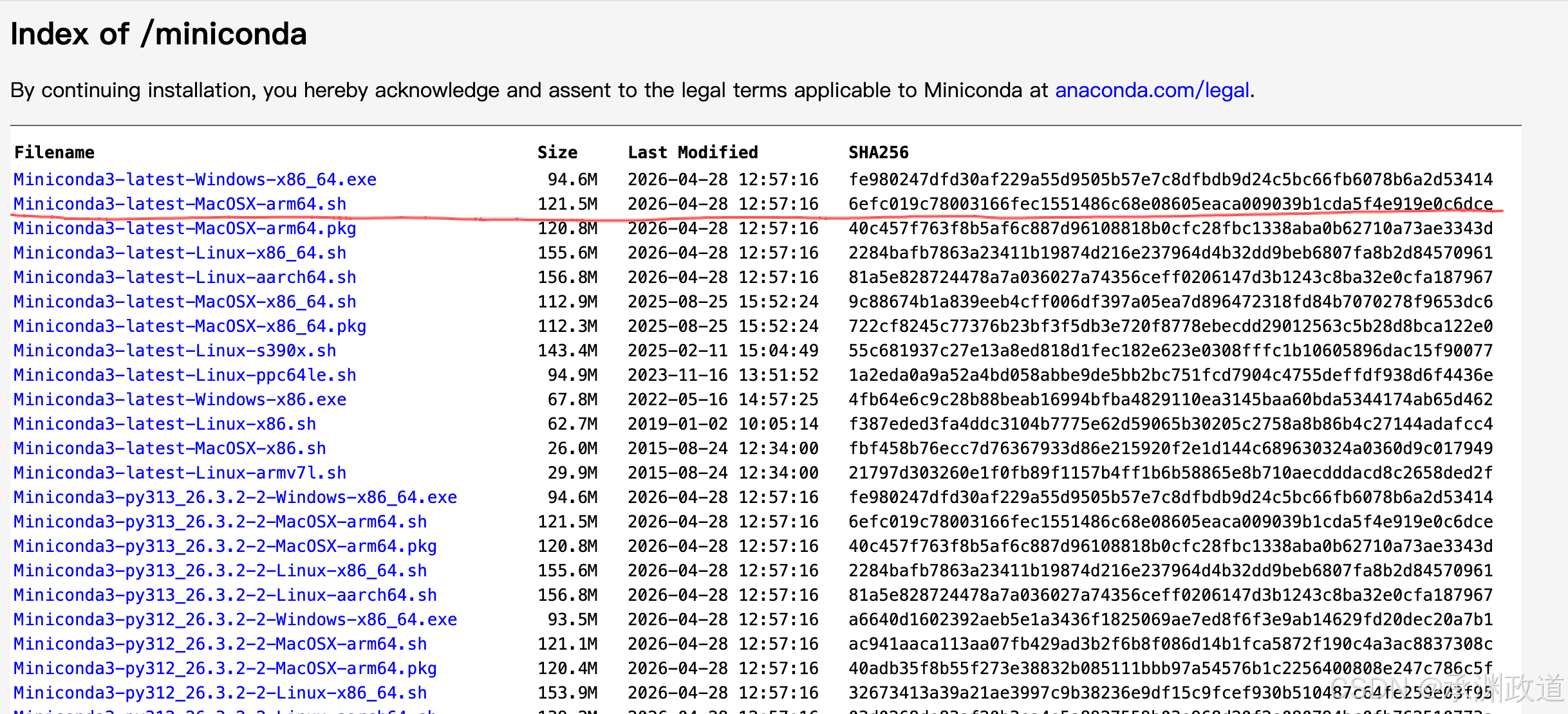
运行以下命令进行安装:
bash ./Miniconda3-latest-MacOSX-arm64.sh
按回车键查看 Miniconda 的最终用户许可协议 (EULA) .您可以在 https://www.anaconda.com/legal 查看 Anaconda 的服务条款 (TOS).
输入 yes 即表示同意最终用户许可协议.
按回车键接受默认安装位置(PREFIX=/Users//miniconda3),或输入其他文件路径以指定备用安装目录.安装可能需要几分钟才能完成.
当系统询问是否要初始化 conda 时,请选择 yes .这将修改您的 shell 配置,以便在每次打开新 shell 时初始化 conda,并自动识别 conda 命令.
安装完成后,安装程序显示:“感谢您安装 Miniconda3!”
关闭并重新打开终端窗口,以使安装完全生效,或者使用以下命令刷新终端:
source ~/.zshrc
你应该在命令行提示符中看到 (base) .这表示你当前处于 conda 基础环境中.
打开终端应用程序并运行 conda list 来验证安装是否正确.如果 conda 安装正确,则会显示已安装软件包的列表: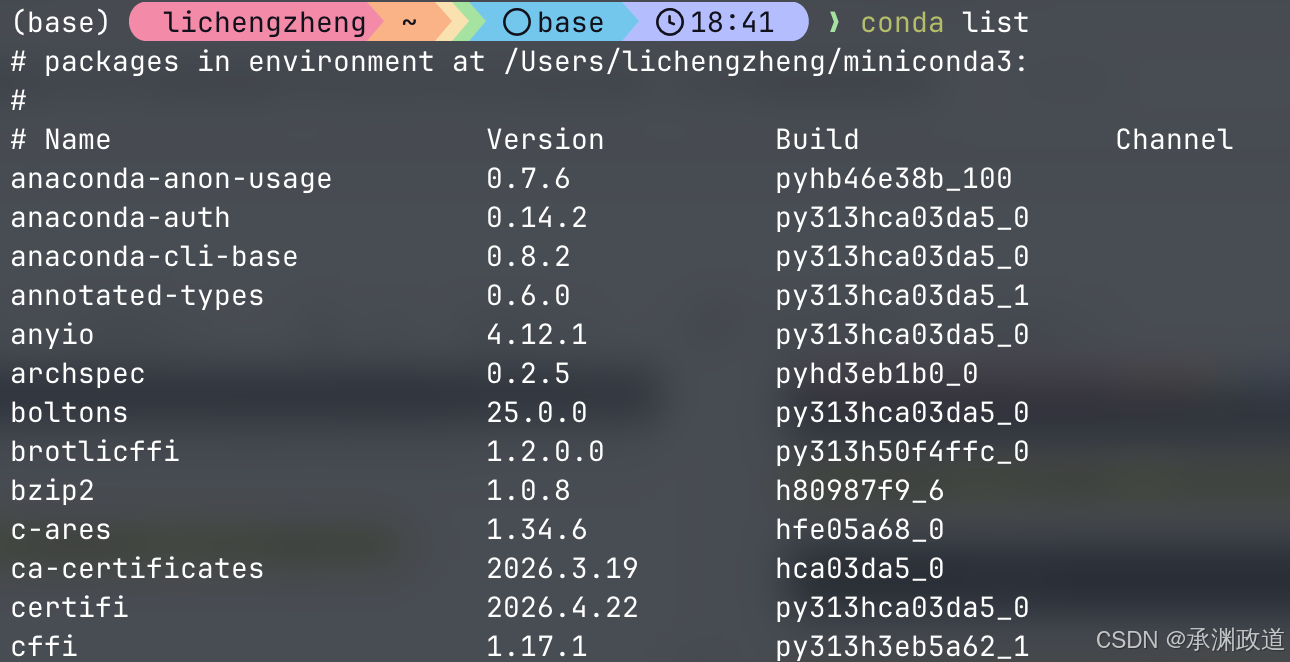
这样就安装好啦!使用Miniconda的一个好处是默认安装了大部分学习所需的第三方类库,这样能够避免使用者在安装和使用某个特定的类库时出现依赖类库缺失的情况.
Python 环境:为什么推荐 Miniconda?
首先推荐使用 Miniconda,而不是直接安装原生 Python.原因很现实:深度学习项目依赖复杂,常见包包括 numpy、torch、torchvision、transformers、datasets、matplotlib 等,它们之间还可能受 Python 版本、CUDA 版本、系统平台影响.
Miniconda 的核心价值不是“它也能运行 Python”,而是它能创建相互隔离的环境.
conda create -n torch2 python=3.10
conda activate torch2
这样做的好处是:
- 新项目可以单独安装依赖,不破坏系统 Python.
- 旧项目可以锁定旧版本依赖,不被新项目升级影响.
- 训练环境出问题时,可以删除环境重建,代价远小于重装整个系统.
今天实际操作时,建议先根据 PyTorch 官方安装页面选择支持的 Python 版本和 CUDA 版本,再创建对应 Conda 环境.
2.1.2PyCharm的下载与安装
和其他语言类似,Python程序的编写可以使用自带的控制台进行编写.但是这种方式对于较为复杂的程序工程来说,容易混淆相互之间的层级和交互文件,因此在编写程序工程时,建议使用专用
的Python编译器PyCharm.PyCharm的下载与安装与安装相信大家都会,这里我就不做演示了!
IDE:PyCharm 的角色不是“必须”,而是“管理复杂度”
PyCharm,对初学者来说,控制台能运行 hello world,但当项目包含数据目录、模型文件、训练脚本、推理脚本、日志和权重文件时,只靠命令行会越来越难管理.
PyCharm 或 VS Code 这类 IDE 的作用主要有三点:
- 管理工程目录:让数据、脚本、模型和配置分层清楚.
- 绑定解释器:确保当前项目使用的是刚创建的 Conda 环境.
- 辅助调试:可以设置断点,检查张量形状、损失值和中间变量.
对于 PyTorch 初学者,我建议项目目录至少保持下面这种结构:
project/
data/
models/
scripts/
checkpoints/
outputs/
train.py
infer.py
requirements.txt
这不是形式主义.深度学习项目最常见的问题之一,就是路径混乱、环境混乱、权重文件混乱.目录结构越早规范,后面越少踩坑.
使用PyCharm创建程序单击桌面上新生成的,单击OK按钮后进入PyChrarm配置界面,如图所示.
创建一个新的工程,这里尝试在工程中新建一个Python文件,在工程目录下,右击打开菜单,选择New→Python File,新建一个helloworld.py文件,打开一个编辑页并输入代码.

单击菜单栏中的Run→run…运行代码,或者直接右击helloworld.py文件名,在弹出的快捷菜单中选择run.如果成功输出hello world,那么恭喜你,Python与PyCharm的配置就完成了.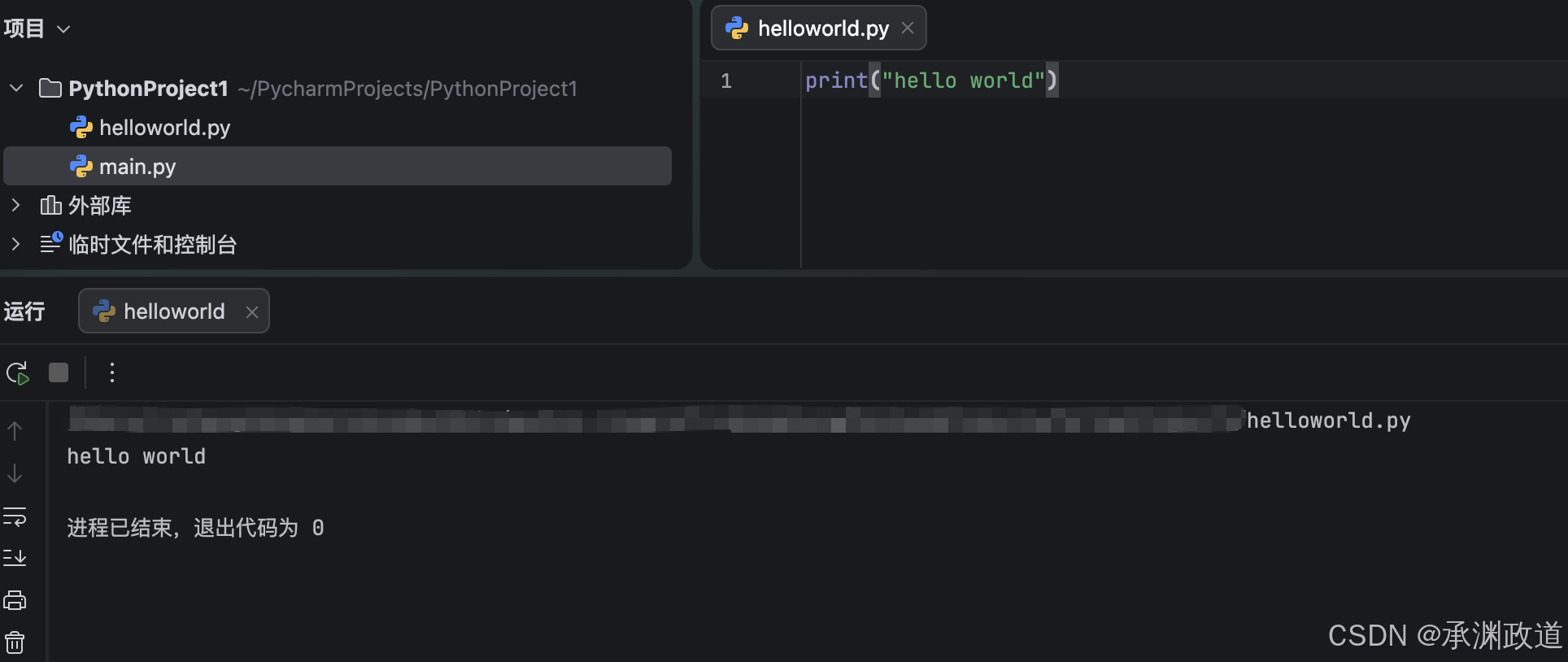
2.1.3Python代码小练习:计算Softmax函数
对于Python科学计算来说,最简单的想法就是可以将数学公式直接表达成程序语言,可以说,Python满足了这个想法.下面将使用Python实现和计算一个深度学习中最为常见的函数——Softmax函数.至于这个函数的作用,现在不加以说明,只是带领大家尝试实现其程序的编写.
Softmax函数的计算公式如下: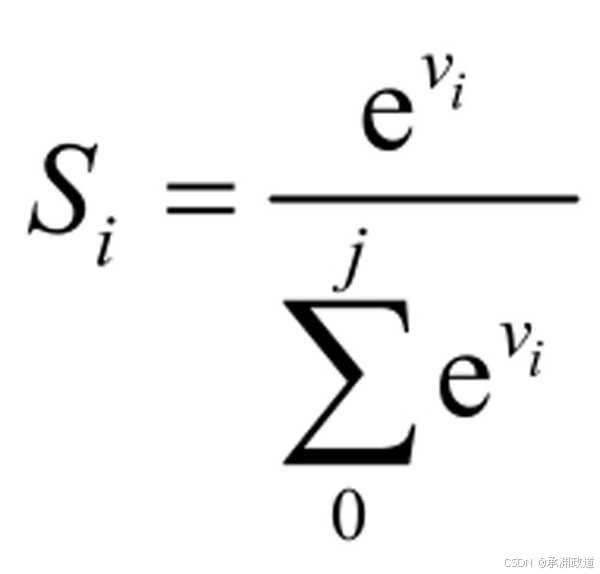
其中Vi是长度为j的数列V中的一个数,代入Softmax的结果就是先对每一个Vi取以e为底的指数计算变成非负,然后除以所有项之和进行归一化,之后每个Vi就可以解释成:在观察到的数据集类别中,特定的Vi属于某个类别的概率,或者称作似然(Likelihood).
提示:Softmax用以解决概率计算中概率结果大而占绝对优势的问题.例如函数计算结果中的2个值a和b,且a>b,如果简单地以值的大小为单位衡量的话,那么在后续的使用过程中,a永远被选用,而b由于数值较小不会被选择,但是有时也需要使用数值较小的b,Softmax就可以解决这个问题.Softmax按照概率选择a和b,由于a的概率值大于b,因此在计算时a经常会被取得,而b由于概率较小,取得的可能性也较小,但是也有概率被取得.
Softmax:从一个公式理解“模型输出如何变成概率”
Softmax 是深度学习分类任务里最常见的函数之一.
给定一组模型输出分数:
[2.0, 1.0, 0.1]
这些数字本身还不是概率.Softmax 会先对每个分数做指数变换,再除以所有指数值之和:
import math
def softmax(values):
exp_values = [math.exp(v) for v in values]
total = sum(exp_values)
return [v / total for v in exp_values]
print(softmax([2.0, 1.0, 0.1]))

输出结果会变成一组和为1的数,可以被解释成概率分布.
Softmax 有两个关键点:
- 它保留相对大小:原来分数更高的类别,概率仍然更高.
- 它不是简单取最大值:较小分数仍然保留非零概率.
这对生成式模型也很重要.大语言模型在生成下一个 token 时,本质上也会得到一个词表上的分数分布,再通过 Softmax 和采样策略决定输出哪个 token.后面你会遇到的 temperature、top-k、top-p,都和这个概率分布有关.
实际工程里,为了避免指数溢出,Softmax 通常会写成数值稳定版本:
import math
def stable_softmax(values):
max_value = max(values)
exp_values = [math.exp(v - max_value) for v in values]
total = sum(exp_values)
return [v / total for v in exp_values]
print(stable_softmax([1000, 1001, 1002]))

测试 [1000, 1001, 1002] 也没有报错,说明这个 stable_softmax 确实避免了 math.exp(1000) 这类溢出问题.它的输出和 [1, 2, 3] 一样,因为 softmax 对整体平移不敏感.这也是从“能跑”走向“工程可靠”的第一步.
2.2环境搭建2:安装PyTorch 2.0
- PyTorch 官方安装页面:Start Locally
- PyTorch 官方历史版本页面:Previous PyTorch Versions
Python运行环境调试完毕后,下面重点介绍安装的主角——PyTorch 2.0.
如果你是跟我一样 Apple Silicon Mac,建议用 Conda 新建环境安装 PyTorch 2.0.
先创建一个 Python 3.10 环境:
conda create -n pytorch20 python=3.10
激活环境:
conda activate pytorch20

安装 PyTorch 2.0:
pip install torch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0
PyTorch 官方现在推荐用官网的安装选择器安装最新稳定版;旧版本安装命令可以在 “Previous PyTorch Versions” 页面找到.PyTorch 2.0 发布说明里也提到,2.0 支持 MPS 后端,也就是 Apple Silicon / macOS 的 GPU 加速路径.
安装完测试:
python
进入 Python 后输入:
import torch
print(torch.__version__)
print(torch.backends.mps.is_available())
print(torch.backends.mps.is_built())
如果看到类似:
2.0.0
True
True
说明安装成功,并且可以使用 Apple Silicon 的 MPS 加速.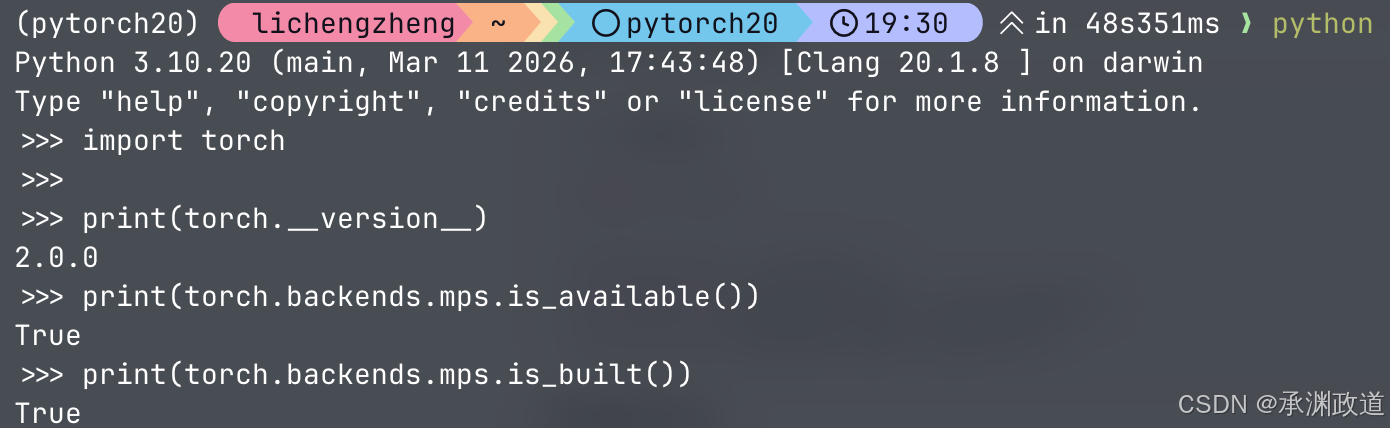
再测试一个张量放到 Mac GPU 上:
import numpy
import torch
print(numpy.__version__)
print(torch.__version__)
print(torch.backends.mps.is_available())
device = torch.device("mps")
x = torch.tensor([1.0, 2.0, 3.0]).to(device)
print(x)
print(x.device)
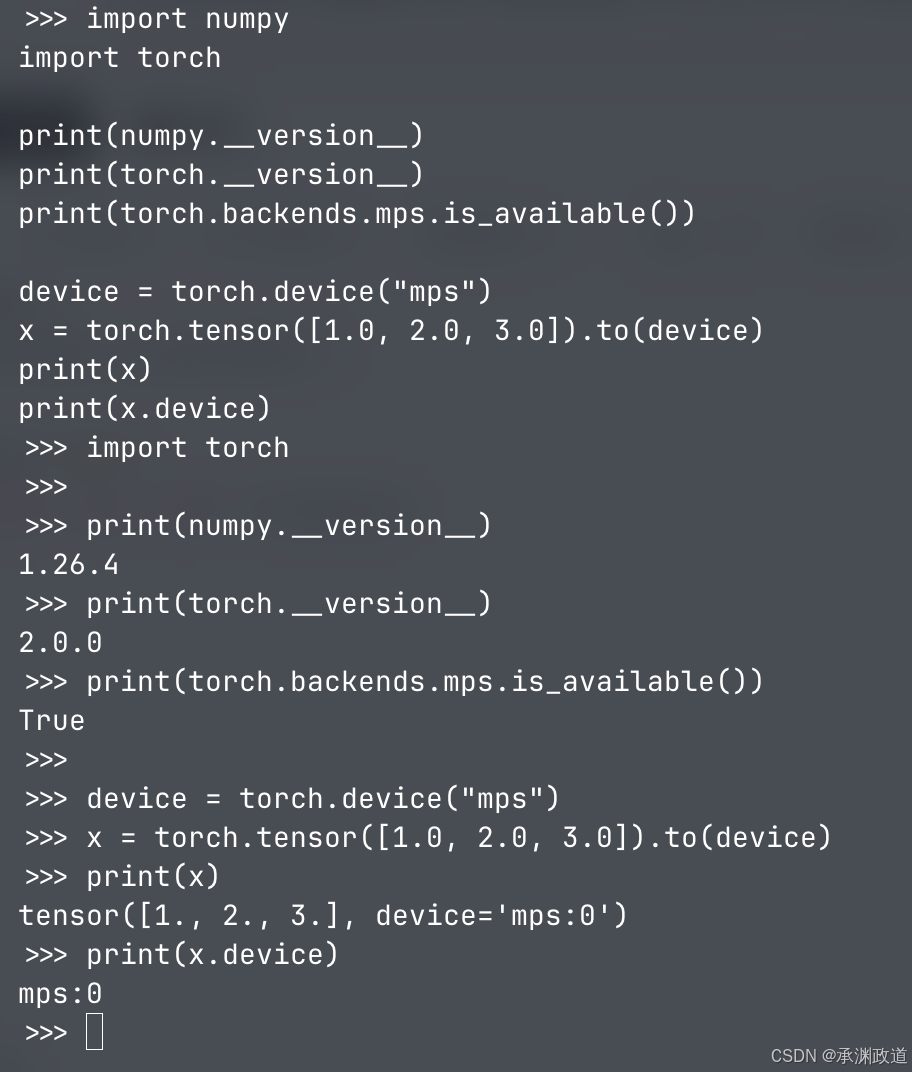
退出 Python:
exit()
以后每次使用这个环境:
conda activate pytorch20
如果你不强制要求2.0也可以装最新版:
pip install torch torchvision torchaudio
这个看大家自己的选择,进行安装下载!
PyTorch 2.0 安装:CPU 能学,GPU 才适合训练
CPU 版本 PyTorch 可以用于入门,但如果要训练深度学习模型,GPU 版本会更合适.原因很直接:神经网络训练包含大量矩阵运算和卷积运算,GPU 的并行计算能力更适合这类工作负载.
2.3PyTorch 2.0小练习:Hello PyTorch
恭喜大家,到这里我们已经完成了PyTorch2.0的安装.
Hello PyTorch:张量是深度学习的基本数据结构完成安装后,下面"Hello PyTorch"验证.这个练习看似简单,本质上是在确认 PyTorch 的核心对象能正常工作.
import torch
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
y = torch.ones_like(x)
print(x + y)
print(x.device)

在 PyTorch 中,Tensor 是最基础的数据结构.图像、文本 token、模型参数、梯度、损失值,最终都会以张量形式参与计算.
我是Apple Silicon Mac,不要用 CUDA.CUDA 是NVIDIA 显卡用的,Mac上应该用 MPS.
import torch
device = "mps" if torch.backends.mps.is_available() else "cpu"
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
y = torch.ones_like(x)
x = x.to(device)
y = y.to(device)
print(x + y)
print((x + y).device)
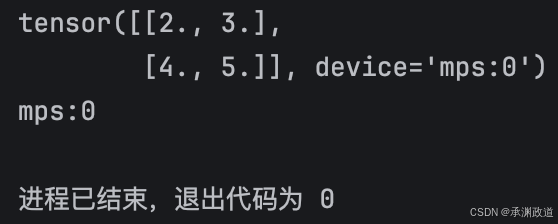
这一步很重要.模型和数据必须在同一个设备上,否则会报设备不一致错误.很多初学者第一次写训练循环时都会遇到类似问题.
3.古诗生成:第一次感受“预训练模型”的威力
在安装验证后为大家安排了一个生成式模型示例:调用 transformers 类库,根据起始句生成古诗词.
这段内容的重点不是让大家立刻掌握 Transformer,而是建立一个直觉:很多生成式 AI 应用并不是从零训练模型,而是加载已经训练好的模型,然后给它一个输入,让它继续生成.
典型流程可以抽象为:
安装依赖 -> 加载 tokenizer -> 加载预训练模型 -> 输入起始文本 -> 生成后续文本 -> 解码输出
代码结构通常类似:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "your-model-name"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
prompt = "万叠春山积雨晴"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=64)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
从大模型视角看,这个小例子包含了后续学习的核心路径:
- 文本会先被 tokenizer 转成 token id.
- token id 会进入语言模型.
- 模型会预测下一个 token 的概率分布.
- 生成策略会从概率分布中选择 token.
- token id 再被解码回自然语言.
这就是生成式模型的最小闭环.
打开终端安装一个本实战所需要的类库transformers,安装命令如下:
pip install transformers

在PyCharm中直接运行下面的代码:
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-poem")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-poem")
text_generator = TextGenerationPipeline(
model=model,
tokenizer=tokenizer
)
result = text_generator(
"[CLS] 万叠春山积雨晴,",
max_length=50,
do_sample=True
)
print(result[0]["generated_text"])

4.图像降噪:手把手实战第一个深度学习模型
古诗词程序读者可能感觉过于简单,直接调用库,再调用模型及其方法,即可完成所需要的功能.然而真正的深度学习程序设计不会这么简单,为了给大家建立一个使用PyTorch进行深度学习的总体印象,在这里准备了一个实战案例,手把手地演示进行深度学习任务所需要的整体流程,大家在这里不需要熟悉程序设计和编写,只需要了解整体步骤和每个步骤所涉及的内容即可.”
4.1MNIST数据集的准备
HelloWorld是任何一种编程语言入门的基础程序,任何一位初学者在开始编程学习时,打印的第一句话往往就是HelloWorld.在深度学习编程中也有其特有的“HelloWorld”,一般指的是采用MNIST完成一项特定的深度学习项目.对于好奇的人来说,一定有一个疑问,MNIST究竟是什么?实际上,MNIST是一个手写数字图片的数据集,它有60000个训练样本集和10000个测试样本集.打开后,MNIST数据集如图下图所示.
将MNIST数据集,保存在dataset文件夹中.
之后使用NumPy数据库进行数据读取,代码如下:
下载这4个文件并解压缩.解压缩后可以发现这些文件并不是标准的图像格式,而是二进制格式,包括一个训练图片集、一个训练标签集、一个测试图片集以及一个测试标签集.其中训练图片集的内容如下图所示:
MNIST训练集内部的文件结构如下图所示: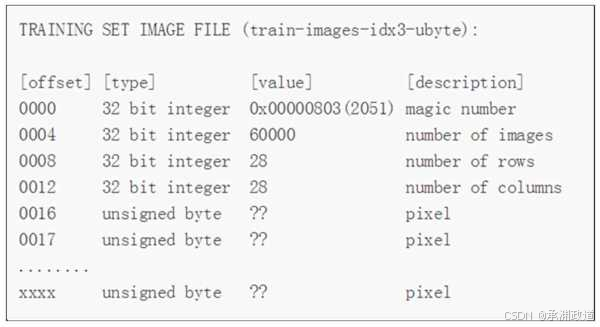
训练集的文件结构,其中有60 000个实例.也就是说这个文件包含60 000个标签内容,每个标签的值为一个0~9的数.这里我们先解析每个属性的含义.首先,该数据是以二进制格式存储的,我们读取的时候要以rb方式读取;其次,真正的数据只有[value]这一项,其他的[type]等只是用来描
述的,并不真正在数据文件中.也就是说,在读取真实数据之前,要读取4个32位整数.由[offset]可以看出,真正的像从0016开始,每个像素占用一个int 32位.因此,在读取像素之前,要读取4个32位整数,也就是magic number、numberof images、number of rows和number of columns.结合文件结构和原始二进制数据内容可以看到,起始的4字节数00000803对应图中列表的第一行,类型是magic number(魔数),这个数字的作用为文件校验数,用来确认这个文件是不是MNIST里面的train-images-idx3-ubyte文件.而0000ea60对应图列表的第二行,转化为十进制为60000,这是文件总的容量数.
下面依次对应.图中从第8个字节开始有一个4字节数0000001c十进制值为28,也就是表示每幅图片的行数.同样地,从第12个字节开始的0000001c表示每幅图片的列数,值也为28.而从第16个字节开始则是依次每幅图片像素值的具体内容.这里使用每784(28×28)字节代表一幅图片,如下图所示: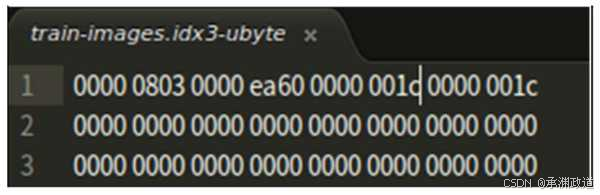
4.2MNIST数据集的特征和标签介绍
对于数据库的获取,前面介绍了两种不同的MNIST数据集的获取方式,下面将MNIST数据集进行数据的读取,代码如下:
import numpy as np
x_train = np.load("./dataset/mnist/x_train.npy")
y_train_label = np.load("./dataset/mnist/y_train_label.npy")
“这里numpy库函数会根据输入的地址对数据进行处理,并自动将其分解成训练集和验证集.打印训练集的维度如下:(60000, 28, 28) (60000)
这是进行数据处理的第一步,有兴趣可以进一步完成数据的训练集和测试集的划分.回到MNIST数据集,每个MNIST实例数据单元也是由两部分构成的,分别是一幅包含手写数字的图片和一个与其相对应的标签.可以将其中的标签特征设置成y,而图片特征矩阵以x来代替,所有的训练集和测试集中都包含x和y.”
下图用更为一般化的形式解释了MNIST数据实例的展开形式.在这里,图片数据被展开成矩阵的
形式,矩阵的大小为28×28.至于如何处理这个矩阵,常用的方法是将其展开,而展开的方式和顺序并不重要,只需要将其按同样的方式展开即可.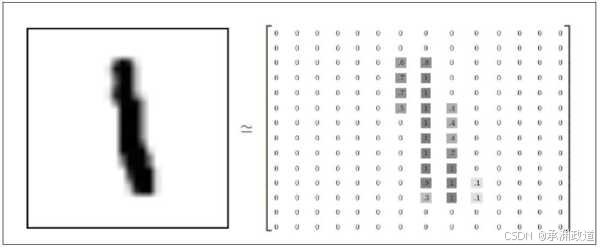
下面回到对数据的读取,前面已经介绍了,MNIST数据集实际上就是一个包含着60 000幅图片的60000×28×28大小的矩阵张量[60000,28,28],如下图所示:
矩阵中行数指的是图片的索引,用以对图片进行提取,而后面的28×28个向量用以对图片特征进行标注.实际上,这些特征向量就是图片中的像素点,每幅手写图片是[28,28]的大小,每个像素转化为一个0~1的浮点数,构成矩阵.
MNIST 是手写数字数据集,包含训练集和测试集.每张图像是28x28 的灰度图,可以看成一个二维矩阵,也可以展开成长度为784 的向量.
对初学者来说,MNIST 的价值不在于它有多难,而在于它足够小、足够标准、足够适合验证流程.用它可以快速学习深度学习项目的基本组成:
- 数据集:输入图像和标签或目标图像.
- 模型:负责把输入映射为输出.
- 损失函数:衡量输出和目标之间的差距.
- 优化器:根据梯度更新模型参数.
- 训练循环:重复执行前向传播、损失计算、反向传播和参数更新.
如果把 MNIST 图像降噪任务简化描述,就是给模型一张带噪声的数字图片,让模型输出更干净的数字图片.

数据从二进制文件到张量:原始 MNIST 文件不是普通 PNG/JPG 图片,而是特定的二进制格式.图像文件开头包含 magic number、图片数量、行数、列数等元信息,真正的像素数据从后面开始排列.
理解这件事有两个好处:
- 你会知道“数据集”不是天然等于“图片文件夹”.
- 你会意识到模型训练前必须做数据解析、归一化和张量转换.
对于 MNIST,每张图像大小是 28x28.若按灰度像素归一化,可以把每个像素从 0-255 转成 0-1 之间的浮点数:
image = image.astype("float32") / 255.0
如果要送入卷积神经网络,通常还需要增加通道维度:
# [batch, height, width] -> [batch, channel, height, width]
images = images.unsqueeze(1)
这类形状转换是 PyTorch 训练中非常高频的操作.很多模型报错,本质上不是算法错,而是张量形状不符合预期.
4.3模型的准备和介绍
对于使用PyTorch进行深度学习的项目来说,一个非常重要的内容是模型的设计,模型用于决定在深度学习项目中采用哪种方式完成目标的主体设计.在本例中,我们的目的是输入一幅图像之后对其进行去噪处理.对于模型的选择,一个非常简单的思路是,图像输出的大小就应该是输入的大小,在这里选择使用Unet(一种卷积神经网络)作为设计的主要模型.注意:对于模型的选择现在还不是大家需要考虑的问题,随着你对知识学习的深入,见识到更多处理问题的方法后,对模型的选择自然会心领神会.我们可以整体看一下Unet的结构(目前只需要知道Unet的输入和输出大小是同样的维度即可),如下图所示: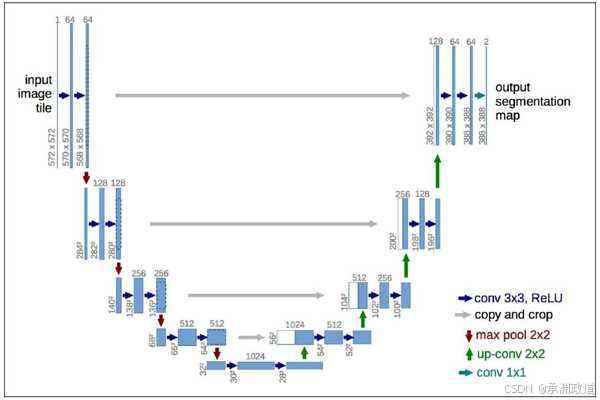
可以看到,对于整体模型架构来说,其通过若干模块(block)与直连(residual)进行数据处理.这
部分内容在后面会讲到,目前只需要知道模型有这种结构即可.Unet模型的整体代码如下:
import torch
import einops.layers.torch as elt
class Unet(torch.nn.Module):
def __init__(self):
super(Unet, self).__init__()
# 模块化结构,这也是后面常用到的模型结构
self.first_block_down = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1),
torch.nn.GELU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.second_block_down = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1),
torch.nn.GELU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.latent_space_block = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
torch.nn.GELU()
)
self.second_block_up = torch.nn.Sequential(
torch.nn.Upsample(scale_factor=2),
torch.nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, padding=1),
torch.nn.GELU()
)
self.first_block_up = torch.nn.Sequential(
torch.nn.Upsample(scale_factor=2),
torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, padding=1),
torch.nn.GELU()
)
self.convUP_end = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32, out_channels=1, kernel_size=3, padding=1),
torch.nn.Tanh()
)
def forward(self, img_tensor):
image = img_tensor
image = self.first_block_down(image)
image = self.second_block_down(image)
image = self.latent_space_block(image)
image = self.second_block_up(image)
image = self.first_block_up(image)
image = self.convUP_end(image)
return image
if __name__ == "__main__":
image = torch.randn(size=(5, 1, 28, 28))
Unet()(image)
上面倒数第1~3行的代码段表示只有在本文件作为脚本直接执行时才会被执行,而在本文件import到其他脚本中(代码重用)时这段代码不会被执行.
模型为什么图像降噪适合 U-Net 思路?
图像降噪示例选择了 U-Net.此时不必完全掌握 U-Net,只需要先理解它的输入和输出维度一致.
这点非常关键.
分类任务的输入是一张图,输出可能是一个类别:
image -> class_id
但图像降噪任务的输入是一张图,输出仍然是一张图:
noisy_image -> clean_image
因此,模型需要保留空间结构.U-Net 的常见思路是先逐步压缩图像特征,提取更抽象的信息,再逐步恢复空间分辨率,同时通过跳跃连接保留细节.
可以把它粗略理解为:
编码器:看懂图像内容
瓶颈层:压缩关键信息
解码器:恢复干净图像
跳跃连接:把浅层细节补回来
对于降噪、分割、修复这类“输入图像和输出图像对齐”的任务.U-Net 是很自然的模型选择.
4.4对目标的逼近——模型的损失函数与优化函数
“除了深度学习模型外,要完成一个深度学习项目,另一个非常重要的内容是设定模型的损失函数与优化函数.初学者对这两部分内容可能不太熟悉,在这里只需要知道有这部分内容即可.
首先是对于损失函数的选择,在这里选用MSELoss作为损失函数,MSELoss函数的中文名字为均方损失函数.
MSELoss的作用是计算预测值和真实值之间的欧式距离.预测值和真实值越接近,两者的均方差就越小,均方差函数常用于线性回归模型的计算.在PyTorch中,使用MSELoss的代码如下:
loss = torch.nn.MSELoss(reduction="sum")(pred, y_batch)
下面是优化函数的设定,在这里采用Adam优化器.对于Adam优化函数,请大家自行查找资料学习,在这里只提供使用Adam优化器的代码,如下所示:
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5)
损失函数:MSELoss 衡量“像不像”
选择 MSELoss 作为图像降噪任务的损失函数.MSE 是均方误差,它会计算预测图像和目标图像在像素层面的差异.
import torch.nn as nn
criterion = nn.MSELoss()
loss = criterion(predicted_images, clean_images)
如果模型输出和干净图像越接近,MSE 越小;如果差异越大,MSE 越大.
在图像降噪任务里,这个选择很直观:我们希望模型输出的每个像素都尽量接近原始干净图像.
不过也要知道,MSE 并不总是图像任务的完美选择.它容易让结果变得平滑,因为平均意义上的最小误差不一定等于视觉上最锐利的图像.后续更复杂的图像生成任务中,还会用到感知损失、对抗损失、扩散模型里的噪声预测损失等.
但作为第一个训练任务,MSELoss 足够清晰.
优化器:Adam 负责“怎么改参数”?
有了损失函数之后,还需要优化器.选择 Adam.
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=1e-3)
训练时,损失函数会告诉我们“模型错了多少”,反向传播会计算“每个参数对错误贡献了多少”,优化器则决定“参数应该往哪个方向改、改多少”.
一个最小训练步骤通常是:
optimizer.zero_grad()
predicted = model(noisy_images)
loss = criterion(predicted, clean_images)
loss.backward()
optimizer.step()
这四行是 PyTorch 训练循环的核心:
zero_grad():清空上一轮梯度.model(...):前向传播,得到预测结果.loss.backward():反向传播,计算梯度.optimizer.step():根据梯度更新参数.
理解这四步,比记住某个模型结构更重要.因为后面的 CNN、RNN、Transformer、BERT、GPT、ChatGLM 微调,本质上都离不开这个训练闭环.
4.5基于深度学习的模型训练
前面介绍了深度学习的数据准备、模型、损失函数以及优化函数,下面使用PyTorch训练出一个可以实现去噪性能的深度学习整理模型,完整代码如下:
import os
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from torchvision import datasets
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Conv2d(64, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(16, 1, kernel_size=3, padding=1),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
batch_size = 128
epochs = 50
if hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print("当前使用设备:", device)
model = Unet().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=2e-4)
loss_fn = nn.MSELoss()
# 自动下载 MNIST 数据集
mnist_train = datasets.MNIST(
root="./dataset",
train=True,
download=True
)
x_train = mnist_train.data.numpy()
# 变成 PyTorch 需要的格式:[数量, 通道, 高, 宽]
x_train = np.reshape(x_train, [-1, 1, 28, 28])
# 归一化到 0~1
x_train = x_train.astype(np.float32) / 255.0
train_length = len(x_train)
save_dir = "/Users/lichengzheng/PycharmProjects/PythonProject1/img"
os.makedirs(save_dir, exist_ok=True)
for epoch in range(epochs):
train_num = train_length // batch_size
train_loss = 0
model.train()
for i in tqdm(range(train_num)):
index = np.random.randint(0, x_train.shape[0], size=batch_size)
x_imgs_batch = x_train[index]
y_batch = x_train[index]
x_imgs_batch = torch.tensor(x_imgs_batch, dtype=torch.float32).to(device)
y_batch = torch.tensor(y_batch, dtype=torch.float32).to(device)
pred = model(x_imgs_batch)
loss = loss_fn(pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= train_num
print(f"epoch: {epoch}, train_loss: {train_loss}")
# 每轮保存一张输出图片
model.eval()
image = x_train[np.random.randint(x_train.shape[0])]
image = np.reshape(image, [1, 1, 28, 28])
image = torch.tensor(image, dtype=torch.float32).to(device)
with torch.no_grad():
image = model(image)
image = torch.reshape(image, [28, 28])
image = image.detach().cpu().numpy()
plt.imshow(image, cmap="gray")
plt.axis("off")
plt.savefig(f"{save_dir}/img_{epoch}.jpg")
plt.close()
print("训练完成!图片保存在:")
print(save_dir)

随着训练的进行,模型逐渐学会对输入的数据进行整形和输出,此时从输出结果来看,模型已经能够很好地对输入的图形细节进行修正,大家可以自行运行代码测试一下.(注:我的是Mac电脑,如果是windows电脑将mps改成cuda版本即可)
5.完整训练流程:深度学习项目的基本骨架
一个 PyTorch 深度学习项目可以整理成下面的工程骨架:
import torch
import torch.nn as nn
import torch.optim as optim
if hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print("当前使用设备:", device)
model = YourModel().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(num_epochs):
model.train()
for noisy_images, clean_images in train_loader:
noisy_images = noisy_images.to(device)
clean_images = clean_images.to(device)
optimizer.zero_grad()
predicted_images = model(noisy_images)
loss = criterion(predicted_images, clean_images)
loss.backward()
optimizer.step()
print(f"epoch={epoch}, loss={loss.item():.4f}")
从这个骨架可以看到,训练不是神秘过程,而是一个不断逼近目标的循环:
输入数据 -> 模型预测 -> 计算误差 -> 反向传播 -> 更新参数 -> 再次预测
当这个循环执行足够多次,模型参数会逐渐从随机状态变成能完成任务的状态.MNIST 降噪示例,就是让读者第一次看到这个过程.
6.通往大模型:基础训练闭环不会消失
虽然本文讲的是环境搭建和 MNIST,但它其实已经埋下了大模型开发的基础.
把 MNIST 图像降噪换成大语言模型微调,对应关系大致如下:
| 第二章里的概念 | 大模型开发中的对应物 |
|---|---|
| Miniconda 环境 | 独立训练/推理环境 |
| PyTorch | 大模型训练和推理框架 |
| MNIST 数据 | 指令数据、对话数据、领域语料 |
| U-Net 模型 | Transformer/ChatGLM/BERT/GPT |
| MSELoss | 交叉熵损失、偏好优化损失等 |
| Adam 优化器 | AdamW、8-bit Adam、Paged AdamW |
| 训练循环 | 预训练、SFT、LoRA 微调、RLHF |
也就是说,本文不是和大模型无关的“入门杂项”.它讲的是所有深度学习项目共享的底层动作.
大模型看起来庞大,但在工程上仍然离不开:
- 环境是否可复现.
- 数据是否能正确变成张量.
- 模型是否能接收输入并输出结果.
- 损失函数是否能表达训练目标.
- 优化器是否能稳定更新参数.
- 训练过程是否能被验证和调试.
这些能力从 MNIST 开始练,反而最稳.
7.总结
本文表面上讲的是 PyTorch 2.0 深度学习环境搭建,实际上是在帮读者完成三次入门:
- 工程入门:安装 Python、Miniconda、IDE 和 PyTorch,让代码能稳定运行.
- 框架入门:通过 Softmax 和 Hello PyTorch 理解张量计算与概率输出.
- 训练入门:通过 MNIST 图像降噪理解数据、模型、损失函数、优化器和训练循环.
如果你能独立完成本文对应的环境搭建,并跑通一个 MNIST 级别的小模型,那么后面学习 CNN、RNN、Transformer、BERT、GPT 和 ChatGLM 微调时,就不会只是在看概念,而是在已有工程经验上继续扩展.
大模型开发不是从“大”开始的.它从一个能复现、能训练、能验证的小闭环开始.

敬请期待下一篇文章内容
每日心灵鸡汤: 努力攒够了,梦想才会开花!
命运的每一次馈赠,都在暗中标好了价码.命运的每一次馈赠,都在暗中标好了价码.你付出了多少,才能得到多少.原来,所有的毫不费力,背后都是拼尽全力.人生得意,不过是多多努力.人与人的差距有时候就在于那个10%.人生往往就在你拼尽最后一丝力气的时候,突然峰回路转,柳暗花明,显出另一片天地.美好的生活,第一步往往是困难的,第二步可能还是困难的,但是走着走着,脚顺了,路平了,就会越来越好了.风光从来不易,唯有加倍努力.


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)