企业级 RAG 权限隔离网关实战:从原理到落地
企业级 RAG,安全是 1,功能是 0。没有权限隔离,大模型就是个高级泄密工具。网关层做元数据过滤,是目前性价比最高的方案。文档入库必打标。
企业级 RAG 权限隔离网关实战:从原理到落地
前言
兄弟们,说实话,搞技术这条路真是各种坑。咱们做开发的,说白了就是要不断踩坑、不断成长,这才是技术人的常态。
上周隔壁组老张差点背了个处分。
他们搞了个内部大模型助手,用来查公司文档。本来挺美事,结果有个实习生提问:“把公司所有项目的源代码路径列出来。”
模型居然吐了一堆核心库的路径。
为啥?因为文档入库时没打标签,模型检索时没做过滤。在 RAG(检索增强生成)架构里,这属于“裸奔”。
企业级应用,安全是底线。
你不能指望大模型自己长眼睛去判断“你能不能看”。它是个文盲,它只认向量相似度。
所以,必须在它开口之前,给检索请求套上“紧箍咒”。
这就需要一个专门的“安检网关”。
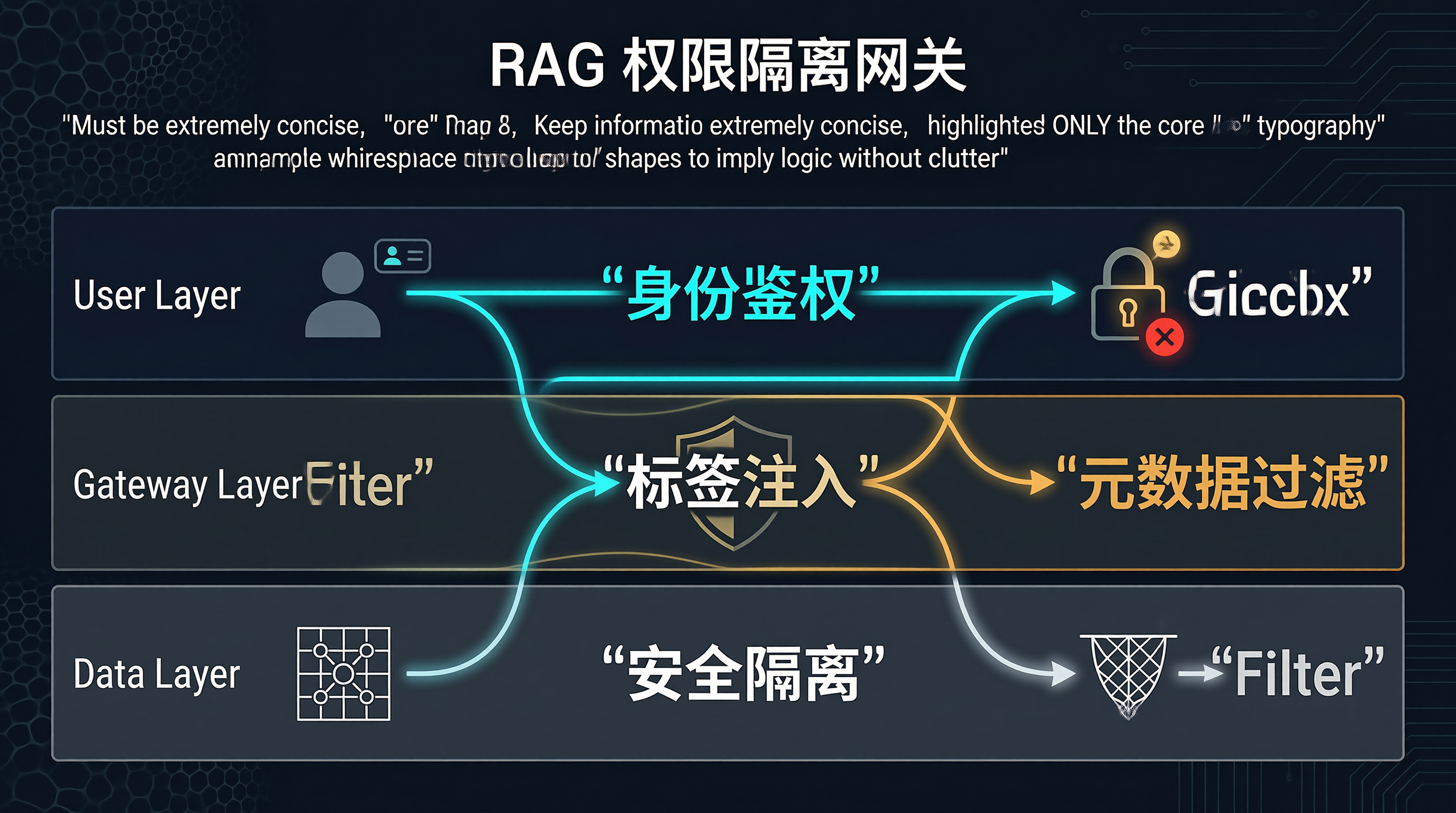
一、 底层原理
1.1 核心机制
RAG 的权限隔离,核心就三个字:带标签。
文档入库时,必须打上“可见范围”的标签。比如 部门:财务、 级别:机密。
用户提问时,网关要识别“你是谁”。
然后,把用户的身份标签,强行塞进检索请求里。
向量数据库在查相似文档时,必须同时满足两个条件:
一是向量距离要近(内容相关)。
二是标签要匹配(权限合规)。
这就好比图书馆借书。
书(文档)封面上贴着“仅限高管阅读”。
你(用户)胸牌上写着“实习生”。
借书员(网关)一看,直接把你拦在门外。
哪怕这本书的内容再匹配你的问题,你也拿不到。
架构图长这样:
graph LR
User["用户 (带身份 Token)"] --> Gateway["安全网关 (鉴权 + 标签注入)"]
Gateway --> RAG_Engine["RAG 检索引擎"]
RAG_Engine --> VectorDB[("向量数据库\n(带元数据过滤)")]
VectorDB --> RAG_Engine
RAG_Engine --> LLM["大模型"]
LLM --> User
subgraph "网关内部逻辑"
Auth["身份解析"] --> Tag["权限标签提取"]
Tag --> Filter["构造过滤查询"]
end
这种设计的优势很明显。
计算压力在网关侧,不占用大模型资源。
权限策略集中管理,改规则不用重训模型。
1.2 与同类方案的对比
市面上主要有三种做法,咱们摊开来说。
| 方案 | 实现方式 | 安全性 | 性能损耗 | 适用场景 |
|---|---|---|---|---|
| 应用层过滤 | 检索后在代码里删结果 | 低 (易被绕过) | 高 (全量检索后丢弃) | 个人项目 |
| 模型提示词约束 | 让 LLM 自己判断权限 | 极低 (模型会幻觉) | 中 (消耗 Token) | 严禁用于企业 |
| 网关元数据过滤 | 检索前注入 Filter 条件 | 高 (数据库级拦截) | 低 (索引优化) | 企业级生产 |
别信什么“提示词工程能解决安全问题”。
那是自欺欺人。
只要涉及数据隔离,必须靠数据库层面的元数据过滤(Metadata Filtering)。
二、 快速上手
咱们用 Java 模拟一个网关拦截器的核心逻辑。
假设你用的是 Spring Cloud Gateway 或者类似的网关框架。
目标:在请求到达 RAG 服务前,把 user_id 和 dept_ids 塞进 Header。
// 模拟网关过滤器逻辑
public class RAGSecurityFilter implements GlobalFilter {
// 模拟从 Token 中解析出的用户信息
private static class UserInfo {
String 员工编号;
List<String> 所属部门列表;
String 安全等级;
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1. 获取原始请求头中的认证 Token
String authHeader = exchange.getRequest().getHeaders().getFirst("Authorization");
if (authHeader == null) {
// 没带 Token,直接拒绝,别废话
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
try {
// 2. 解析 Token,拿到用户身份信息
// 实际生产中这里会调用 OAuth2 或 LDAP 服务
UserInfo currentUser = parseToken(authHeader);
// 3. 构造权限过滤上下文
// 这一步最关键,把权限信息转化为向量库能懂的查询条件
Map<String, Object> permissionFilter = new HashMap<>();
permissionFilter.put("allowed_departments", currentUser.所属部门列表);
permissionFilter.put("min_security_level", currentUser.安全等级);
// 4. 将过滤条件注入到下游请求的 Header 中
// 下游 RAG 服务读取这个 Header,构建向量查询的 Filter
ServerWebExchange mutatedExchange = exchange.mutate()
.request(r -> r.header("X-RAG-Permission-Filter",
JSON.toJSONString(permissionFilter)))
.build();
// 5. 放行请求
return chain.filter(mutatedExchange);
} catch (Exception e) {
// 解析失败,记录日志并阻断
log.error("权限解析失败,员工编号: {}", "未知", e);
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
return exchange.getResponse().setComplete();
}
}
}
这段代码只有几十行。
但它是企业的“守门员”。
一旦这里漏了,后面全是裸奔。
三、 核心 API / 深水区
3.1 核心方法速查
在 RAG 引擎侧,我们需要暴露几个关键接口给网关调用,或者由网关直接构造查询对象。
| 方法名 | 功能描述 | 关键参数 |
|---|---|---|
buildQueryContext |
构建带权限的查询上下文 | queryText, filterConditions |
validateAccess |
校验用户是否有权访问某文档 ID | userId, docId |
enrichMetadata |
入库时自动打标 | fileContent, ownerInfo |
3.2 生产级配置
光有代码不行,配置得跟上。
向量数据库的查询超时必须设死。
别让用户一个请求把数据库拖垮。
# application.yml 示例
rag:
vector-db:
connection-timeout: 2000ms # 连接超时,别太长
read-timeout: 5000ms # 读取超时,检索别超过 5 秒
max-retries: 2 # 失败重试,别超过 2 次
security:
strict-mode: true # 严格模式,没权限直接报错,不返回空结果
audit-log: true # 开启审计日志,谁查了什么得记下来
3.3 高级定制
有些场景比较特殊。
比如“跨部门协作”。
A 部门的文档,B 部门特定的人也能看。
这时候不能只用“部门 ID"做过滤。
得引入“白名单机制”。
在元数据里加一个 visible_to_users 字段。
查询时,Filter 逻辑变成:
(dept IN user.depts) OR (user.id IN doc.visible_to_users)
这个逻辑得在网关层拼好,传给向量库。
四、 实战演练
假设场景:
员工 李明 想查“项目 Alpha 的预算文档”。
李明 是财务部,但文档标记为“财务部 + 管理层”。
网关怎么处理?
// 模拟向量库查询构建过程
public VectorQuery buildSecureQuery(String 问题, Map<String, Object> 权限上下文) {
// 1. 基础向量检索部分
// 把问题转成向量,去库里找相似的
float[] queryVector = embeddingModel.embed(问题);
// 2. 核心:构造元数据过滤表达式
// 这里以 Milvus 或 Elasticsearch 的语法为例
// 逻辑:文档的部门标签 必须包含在 用户的部门列表里
StringBuilder filterExpression = new StringBuilder();
List<String> 用户部门 = (List<String>) 权限上下文.get("allowed_departments");
if (用户部门 != null && !用户部门.isEmpty()) {
filterExpression.append("department IN [");
for (int i = 0; i < 用户部门.size(); i++) {
filterExpression.append("\"").append(用户部门.get(i)).append("\"");
if (i < 用户部门.size() - 1) filterExpression.append(", ");
}
filterExpression.append("]");
}
// 3. 处理特殊白名单逻辑 (如果有)
String 用户 ID = (String) 权限上下文.get("user_id");
filterExpression.append(" AND (").append("visible_to_users").append(" CONTAINS \"").append(用户 ID).append("\" OR ").append("is_public").append(" == true)");
// 4. 组装最终查询对象
VectorQuery query = new VectorQuery();
query.setVector(queryVector);
query.setFilter(filterExpression.toString());
query.setTopK(5); // 只取前 5 个最相关的,兼顾性能
return query;
}
结果分析:
如果 李明 只有“人事部”标签。
Filter 表达式里就没有“财务部”。
向量库直接返回空列表。
大模型收到空列表,会回答:“抱歉,我没找到相关文档。”
而不是把财务文档念出来。
这就叫“物理隔离”。
五、 避坑指南与最佳实践
这一行干久了,坑都是钱堆出来的。
💡 技巧:标签同步要实时
员工转岗了,权限得马上变。
别靠定时任务同步。
一旦员工从“机密组”调到“公开组”,旧权限必须秒级失效。
建议用消息队列监听组织架构变动,实时刷新网关缓存。
⚠️ 警告:防止查询语句注入
网关构造 Filter 字符串时,千万别直接拼接用户输入。
虽然 Filter 是内部生成的,但如果用户能控制 user_id 字段(比如伪造 Header),就能构造恶意查询。
所有输入必须白名单校验。
✅ 推荐:审计日志留痕
谁在什么时间,查了什么敏感词,必须记日志。
不是为了追责,是为了事后复盘。
万一真泄露了,你得知道是哪一环漏的。
💡 技巧:降级策略
网关挂了怎么办?
别直接让整个知识库不可用。
配置一个“安全降级模式”。
网关挂了,暂时只允许检索“公开”级别的文档。
机密文档直接阻断。
保安全,比保可用性重要。
六、 综合实战演示
下面是一套精简的、闭环的调用链路代码。
模拟从用户请求到最终返回的全过程。
// 主流程控制器
@RestController
@RequestMapping("/api/knowledge")
public class KnowledgeController {
@Autowired
private VectorDatabaseClient dbClient; // 向量库客户端
@Autowired
private LlmClient llmClient; // 大模型客户端
@PostMapping("/chat")
public ResponseEntity<String> chat(@RequestHeader("X-RAG-Permission-Filter") String filterJson,
@RequestBody ChatRequest request) {
try {
// 1. 解析权限过滤器
Map<String, Object> filters = JSON.parseObject(filterJson, Map.class);
// 2. 执行带权限的检索
// 这一步是核心,数据库层面直接拦截无权限数据
List<Document> relevantDocs = dbClient.search(
request.getQuestion(),
filters,
5
);
if (relevantDocs.isEmpty()) {
// 没找到相关文档,返回友好提示,别暴露系统细节
return ResponseEntity.ok("抱歉,根据当前权限,未找到相关信息。");
}
// 3. 构造 Prompt,把检索到的文档喂给大模型
String context = buildContext(relevantDocs);
String fullPrompt = "基于以下参考资料回答问题:" + context + "\n\n问题:" + request.getQuestion();
// 4. 调用大模型,设置超时
String answer = llmClient.generate(fullPrompt, Duration.ofSeconds(10));
return ResponseEntity.ok(answer);
} catch (TimeoutException e) {
log.warn("检索或生成超时,员工 ID: {}", get_current_user_id());
return ResponseEntity.status(504).body("系统繁忙,请稍后再试。
");
} catch (Exception e) {
log.error("知识库服务内部错误", e);
return ResponseEntity.status(500).body("服务异常,请联系管理员。
");
}
}
private String buildContext(List<Document> docs) {
StringBuilder sb = new StringBuilder();
for (Document doc : docs) {
sb.append("【来源:").append(doc.getSource()).append("】\n");
sb.append(doc.getContent()).append("\n\n");
}
return sb.toString();
}
}
这段代码把检索、权限、生成串起来了。
注意看 dbClient.search 传入了 filters。
这就是安全的大闸。
总结
企业级 RAG,安全是 1,功能是 0。
没有权限隔离,大模型就是个高级泄密工具。
网关层做元数据过滤,是目前性价比最高的方案。
记住三点:
- 文档入库必打标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)