从“万行代码“到“一行函数“:DolphinDB 多范式编程与生态体系如何重构工业物联网开发范式
工业物联网的数据开发,正在陷入一场"语言巴别塔"危机——Kafka 用 Java、Flink 用 Scala 或 SQL、Spark 用 PySpark、时序数据库各有各的查询方言、AI 模型用 Python、可视化还要写 JavaScript。
摘要
工业物联网的数据开发,正在陷入一场"语言巴别塔"危机——Kafka 用 Java、Flink 用 Scala 或 SQL、Spark 用 PySpark、时序数据库各有各的查询方言、AI 模型用 Python、可视化还要写 JavaScript。一个完整的数据链路,需要跨越五六种语言和十几种技术栈,开发效率极低,维护成本极高。更痛苦的是,同一个分析逻辑在批处理环境写一遍、流处理环境再写一遍,测试验证又写一遍——三套代码,三个团队,三条无尽的排错链路。本文聚焦 DolphinDB 的编程生态体系,深入解读其多范式编程语言(命令式、函数式、向量化、SQL)、2000+ 内置函数库、流批一体的开发模式、丰富的 SDK 与插件生态,以及面向特定领域的模块化组件库,展示 DolphinDB 如何帮助工业企业的开发团队将"数周开发周期"压缩至"数天甚至数小时"。结合地震监测、海关数据仓库、钢铁工艺优化、车联网平台建设等真实落地案例,探讨工业物联网从"手工作坊式开发"走向"工业化高效编程"的实践路径。
一、引言:工业数据开发的"巴别塔"
在我参与的多个工业物联网项目中,有一个现象比"数据存不下"更让人头疼:团队花了大量时间不是在写业务逻辑,而是在做语言之间的"翻译"。
一位负责钢铁企业数据平台的架构师曾向我抱怨,他们的数据链路是这样的:施耐德 Ampla 采集数据,用 C# 写的适配器接入 SQL Server,再用 Java 编写 ETL 脚本导入 Kafka,Flink 用 Scala/SQL 做流计算,Spark 用 PySpark 做离线分析,最后还要用 Python 训练模型,JavaScript 搭建可视化面板。光"翻译"——数据在不同格式、不同语言、不同框架之间的来回转换——就占据了团队 60% 以上的工作量。

这绝非个例。在能源电力、智能制造、车联网等领域,一个完整的数据平台往往涉及五六种编程语言、十几种技术组件、三四个不同的开发团队。 每种语言都有自己的范式和生态,每个组件都有自己的 API 和配置方式。当一个新需求从业务端提出时,需求的"翻译链"可能长这样:
业务需求 → SQL 查询需求 → Java/Kafka 消息需求 → Scala/Flink 流处理需求 → Python/Spark 分析需求 → JavaScript 可视化需求
每多一个环节,就多一次沟通成本、多一批接口定义、多一轮联调测试。从想法到落地,少则数周,多则数月。
更深层的问题在于算法的"三写困境":同一个分析逻辑——比如计算设备的滑动窗口平均振动幅值并检测异常——需要在三个不同的环境中各写一遍:批处理环境(处理历史数据验证算法)、流处理环境(实时监控)、测试环境(验证一致性)。三套代码、三套逻辑、三个团队,排错和验证的成本远超算法开发本身。
DolphinDB 提出了一条截然不同的路:用一门语言、一个平台、一套代码覆盖从数据采集到存储、从流计算到批处理、从复杂分析到 AI 推理的完整开发链路。 它不是"又一个数据库查询语言",而是一个图灵完备的多范式编程环境,内置了工业分析所需的大部分"弹药",并通过丰富的生态体系与现有技术栈无缝衔接。
二、开发之困:为什么工业物联网"写得这么慢"?
2.1 困境一:语言碎片化——一个需求,五种实现
工业物联网数据平台的典型技术栈涉及多种编程语言和计算范式,每种都在"做自己最擅长的事",但拼接起来却举步维艰:
- 数据采集层:C/C++ 或 C# 编写硬件驱动和协议适配器(OPC UA、Modbus、IEC 104)
- 消息传输层:Java 编写 Kafka 生产者/消费者
- 流计算层:Scala 或 SQL 编写 Flink 作业
- 批处理层:Python 或 Scala 编写 Spark 作业
- 数据存储层:各时序数据库专有的查询语言或 SQL 方言
- AI 分析层:Python 编写模型训练和推理脚本
- 可视化层:JavaScript 编写前端展示面板
这意味着一个完整的业务需求——比如"实时检测设备振动异常并展示在监控面板上"——至少要跨越消息传输、流计算、存储和可视化四个层次,每个层次用不同的语言和框架实现。接口定义、数据格式转换、错误处理、版本兼容……每一项都是耗时的工程任务。
更糟糕的是,当业务逻辑需要调整时——比如异常检测阈值从"振动幅值 > 5g"改为"振动幅值 > 5g 且持续 3 秒以上"——这个修改需要同时反映在 Flink 作业、Spark 批处理脚本和存储层查询中。任何一个环节的遗漏,都会导致批处理结果和流处理结果不一致,进而引发业务决策的混乱。
2.2 困境二:算法"三写"——批处理写一遍,流处理再写一遍
工业物联网中的分析算法通常需要经过三个阶段的验证:
- 研发阶段:基于历史数据(批量数据)开发算法,验证其正确性
- 生产阶段:将算法部署到实时数据流上,进行在线监控
- 回测阶段:定期用批量数据重新运行算法,验证流处理结果与批处理结果一致
在传统架构下,这三个阶段通常使用不同的技术栈:研发用 Python + Pandas 或 SQL,生产用 Flink + Scala/SQL,回测又要回到批处理环境。同一个算法被写成三个版本,使用三种不同的语言和框架,代码逻辑的差异导致结果验证变得异常困难。
以滑动窗口异常检测为例:Python 版本用 pandas.rolling() 实现,Flink 版本用窗口函数实现,SQL 版本用 OVER (ORDER BY timestamp ROWS BETWEEN ...) 实现——三种写法在边界条件、空值处理、数据类型转换等方面都有微妙差异。当研发团队发现一个异常时,究竟是算法问题还是"翻译"过程中的实现差异?排查这个问题可能需要数天。
2.3 困境三:"造轮子"成瘾——每家企业都在重复发明
工业物联网的数据分析有许多共性需求:时序数据的降采样和插值、信号处理(傅里叶变换、小波变换)、统计过程控制(SPC)、异常检测规则引擎、滑动窗口聚合……然而,由于缺乏统一的开源函数库,几乎每家企业都在从零开始编写这些基础算法。
某地震台网中心告诉我,他们曾花三个月时间用 Python 实现了一套地震波形异常检测算法,包括 MiniSeed 文件解析、FilterPicker 算子、实时流接入等模块。后来发现另一家地震监测机构也做了几乎一样的事情——同样的算法,不同的实现,不同的 bug,不同的性能瓶颈。这些重复劳动消耗了大量工程资源,而这些资源本可以投入到更有价值的业务创新中。
在更广泛的工业场景中,这种"重复造轮子"的现象比比皆是。设备综合效率(OEE)计算、振动信号的频谱分析、温度数据的异常检测……每家企业都在自己写,每家写出来的都不一样,质量参差不齐。
三、破局之道:DolphinDB 编程生态的"三维赋能"
DolphinDB 对开发效率的理解不是"提供一个好用的 SQL 引擎"那么简单,而是从语言范式、函数生态、工具链三个维度,构建了一个面向工业物联网数据开发的完整编程环境。
3.1 多范式编程:四种范式,一门语言
DolphinDB 的编程语言是图灵完备的,同时支持四种编程范式,开发者可以根据具体问题选择最合适的表达方式:
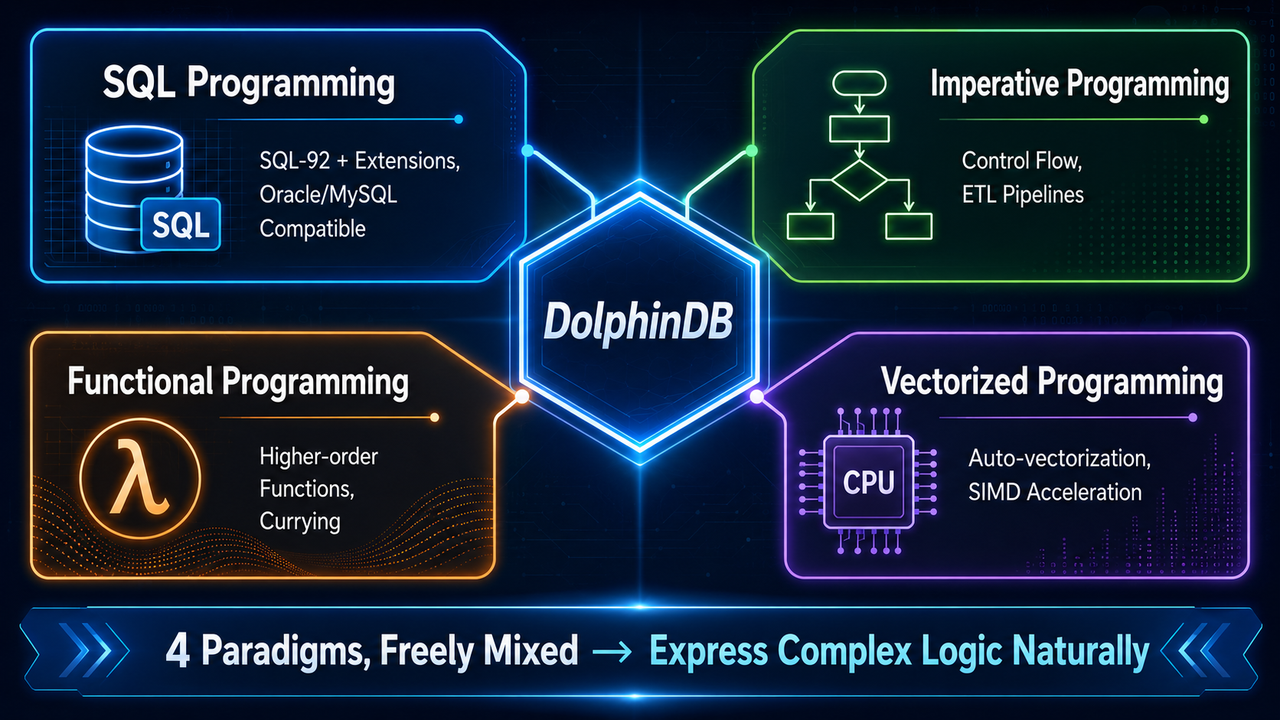
SQL 编程——DolphinDB 支持 SQL-92 标准,并在此基础上扩展了组内计算、透视表等工业分析常用的功能。同时兼容 Oracle 和 MySQL 等主流 SQL 方言,降低了学习门槛。对于习惯用 SQL 进行数据查询和分析的开发者,几乎可以无缝迁移。
-- 按设备分组,计算每5分钟的滑动平均振动幅值
select deviceId, avg(vibration) as avgVib
from sensorData
group by deviceId, bar(timestamp, 5*60*1000)
命令式编程——对于需要精细控制执行流程的复杂业务逻辑,DolphinDB 提供了完整的命令式编程支持,包括条件判断、循环、异常处理等控制结构。这使得复杂的 ETL 流程、数据清洗规则等可以像写普通脚本一样直观。
函数式编程——DolphinDB 支持高阶函数、匿名函数、柯里化等函数式编程特性。在数据处理场景中,函数式编程的优势在于代码简洁、表达力强,且天然适合向量化执行。
-- 使用高阶函数 each 对每个设备独立应用异常检测
each(def(deviceId){ detectAnomaly(select * from sensorData where deviceId = deviceId) }, deviceIds)
向量化编程——这是 DolphinDB 性能优势的核心来源之一。所有内置函数都经过向量化优化,一次处理一批数据而非逐行处理,配合 CPU 的 SIMD 指令集,在复杂查询场景下 CPU 利用率可提升数倍。开发者不需要显式编写向量化代码——普通函数调用在 DolphinDB 的执行引擎中自动以向量化方式运行。
这四种范式不是孤立的,而是可以在同一段脚本中自由混合使用。一段典型的 DolphinDB 脚本可能同时包含 SQL 查询、命令式控制流、函数式数据处理和隐式的向量化执行——用最自然的方式表达最复杂的逻辑,这正是多范式编程的威力。
3.2 2000+ 内置函数:工业分析的"乐高积木"
DolphinDB 内置了超过 2000 个函数,覆盖工业物联网数据分析的几乎所有领域:
- 时序处理函数:滑动窗口(
msum、mavg、mmax)、累计窗口(cumsum、cumprod)、时间聚合(bar、interval)、降采样、插值等 - 信号处理函数:傅里叶变换、小波变换、滤波器、频谱分析等
- 统计分析函数:描述统计、假设检验、回归分析、相关性分析等
- 机器学习函数:线性回归、逻辑回归、K-Means 聚类、随机森林、PCA 等
- 字符串与正则处理:模式匹配、文本清洗、JSON 解析等
- 日期时间函数:时间格式转换、交易日历、工作日计算等
这些函数全部经过向量化优化,且支持用户自定义函数(UDF)进行扩展。更重要的是,这些函数可以直接在 SQL 语句中调用——SQL 与函数、表达式无缝融合,开发者能够在数据库层面直接完成复杂的数据分析及运算,无需在数据库和外部计算引擎之间来回切换。
以某地震台网中心的案例为例。该中心需要在每 10 毫秒采集一条的地震波形数据上进行傅里叶变换、小波变换等复杂信号处理。在传统方案中,这些操作需要在 MATLAB 或 Python 环境中完成,涉及数据导出→外部计算→结果导入的冗长流程。而在 DolphinDB 中,这些信号处理函数是内置的,直接在 SQL 查询中调用即可,端到端计算响应延迟控制在毫秒级。
从"写一千行代码调用外部库"到"写一行函数直接在数据库内计算"——这就是 2000+ 内置函数带来的开发效率跃迁。
3.3 流批一体:一套代码,消灭"三写困境"
在第二节中提到的"算法三写困境",DolphinDB 用流批一体设计给出了一个根本性的解决方案。
在 DolphinDB 中,用户使用同一套脚本语言进行批量分析(处理历史数据)和流式计算(处理实时数据)。研发环境中基于历史数据构建的分析表达式或模型,可以直接应用于生产环境的实时数据流中,且保证流计算结果和批量计算结果完全一致。
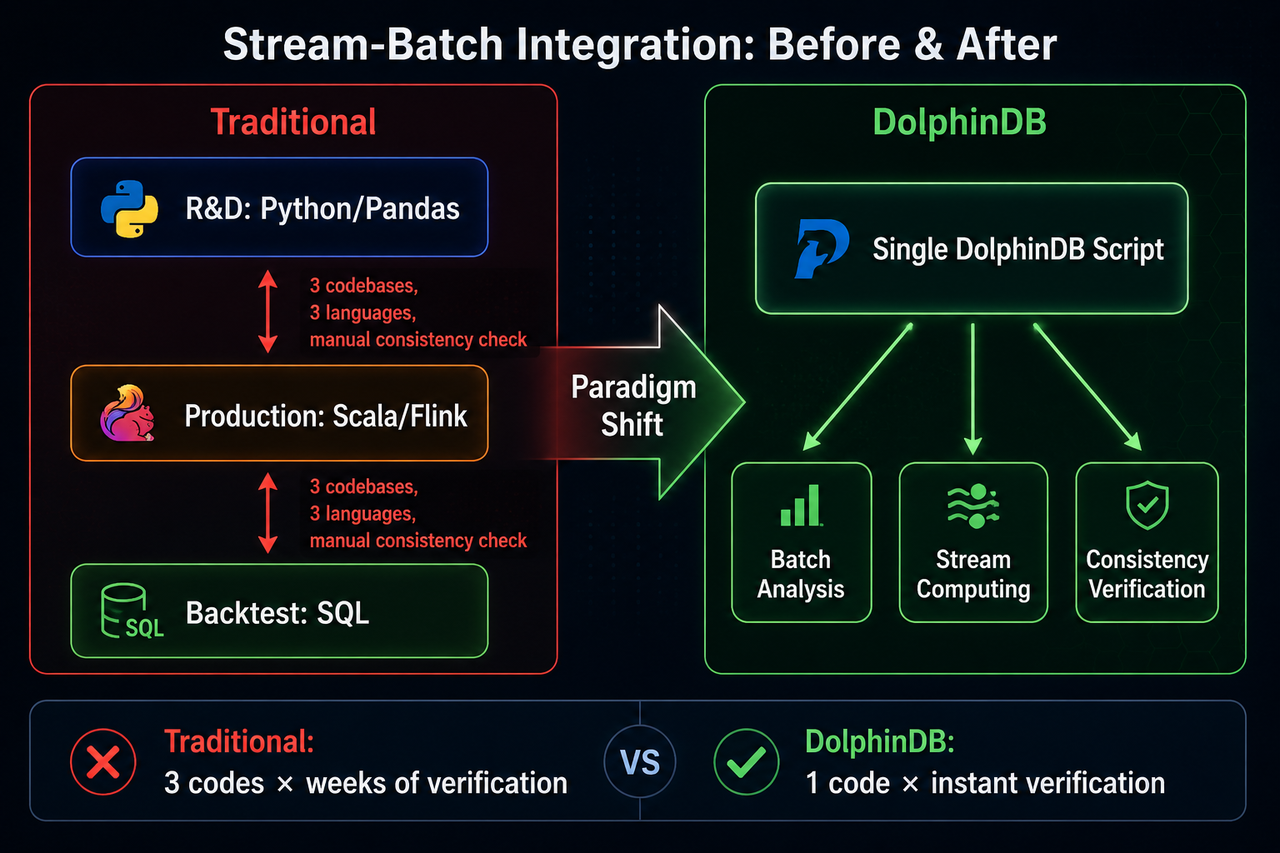
这意味着:
- 研发阶段:用历史数据批量运行算法,验证正确性——使用 DolphinDB 脚本
- 生产阶段:将同一份算法代码接入流计算引擎,实时执行——同一份 DolphinDB 脚本
- 回测阶段:定期用批量数据重新运行算法,验证一致性——同一份 DolphinDB 脚本
一份代码,三种场景。 不存在"翻译"过程中的实现差异,不存在跨语言的一致性验证噩梦。算法开发完即可上线,因为底层的计算引擎是同一套,结果的正确性由系统保证。
在开发效率层面,这意味着过去需要三四个团队、数周时间的"算法上线"流程,现在一个开发者、几天甚至几小时就能完成。开发成本和维护成本同时大幅降低。
3.4 SDK 与插件生态:与现有技术栈无缝衔接
DolphinDB 提供了丰富的 SDK 生态,覆盖主流编程语言,包括 Python、C++、C#、Go、R 和 JavaScript 等。这意味着企业的开发团队可以使用自己最熟悉的语言与 DolphinDB 交互,不需要"抛弃"现有的技术栈。
在实际的工业项目中,这种兼容性的价值体现在:
- Python SDK:算法工程师可以继续使用 Python 进行模型训练和数据分析,通过 DolphinDB Python API 高效读写海量时序数据,无需在 Python 环境和数据库之间手动导出导入
- C++ SDK:对性能有极致要求的实时数据接入场景,C++ SDK 提供了最低的通信开销
- C# SDK:与现有的工业组态软件、SCADA 系统无缝集成
- Go SDK:适合构建高并发的微服务数据网关
- JavaScript SDK:支持 Web 端直接查询和展示 DolphinDB 中的数据
在插件层面,DolphinDB 提供了覆盖数据存取、行情接入、消息队列、数值计算、机器学习、网络通信、云存储等领域的丰富插件,包括:
- 数据采集插件:MQTT、OPC UA/DA、Modbus、IEC 104 等工业协议的直接采集插件
- 消息队列插件:Kafka、MQTT、ZMQ 等消息中间件的双向对接
- 机器学习插件:libTorch(PyTorch C++ 库)、XGBoost、TensorFlow 等推理引擎插件
- 云存储插件:AWS S3、阿里云 OSS 等对象存储的读写支持
- 数据导入插件:DataX 集成,支持从 MySQL、Oracle、MongoDB、HDFS 等数十种数据源的批量导入
这些插件让 DolphinDB 能够无缝融入企业现有的技术架构,而不是要求企业围绕 DolphinDB 重建一切。
3.5 模块化组件库:领域知识的"即插即用"
除了内置函数和插件,DolphinDB 还提供了一系列面向特定领域的模块化组件库,将行业沉淀的领域知识封装为可直接调用的函数模块:
- 技术分析指标库(TA):涵盖 MACD、RSI、布林带等经典技术分析指标
- 因子库(GTJA191Alpha):国泰君安 191 个量化因子
- 因子指标库(WQ101Alpha):WorldQuant 101 个 Alpha 因子
- 运维函数库(OPS):面向数据库运维场景的常用函数集合
- 历史数据导入模块(EasyTLDataImport):简化各类历史数据的批量导入流程
- 行情数据接入模块(EasyNSQ):便捷的实时行情数据接入
- 交易日历模块(MarketHoliday):全球主要交易所的交易日历管理
- 多因子风险模型:面向金融风控的完整因子分析框架
虽然这些模块最初主要面向金融领域,但其设计理念——将领域专家沉淀的知识封装为可复用的函数模块——同样适用于工业物联网场景。DolphinDB 的模块化架构允许企业根据自身需求开发自定义模块,将特定行业的分析经验和最佳实践固化下来,在团队内部甚至跨团队共享复用。
这意味着,一家动力电池企业在 DolphinDB 中沉淀的充放电曲线分析模块,可以作为"内部标准组件"在所有产线团队中推广使用——不再需要每个团队从零开始编写,也不必担心不同团队实现的差异。
3.6 多样化客户端:适配不同角色的开发环境
DolphinDB 提供了多种客户端工具,适配不同角色的使用习惯:
- DolphinDB VS Code 插件:开发者可以在最流行的代码编辑器中直接编写、调试和运行 DolphinDB 脚本
- Jupyter Notebook 集成:数据科学家可以在熟悉的 Notebook 环境中进行交互式数据探索和分析
- Web 集群管理器:运维人员通过浏览器即可管理集群配置、监控节点状态
- DolphinDB 终端:提供命令行交互界面,适合自动化脚本和运维场景
- Java GUI:为偏好图形界面的用户提供可视化的数据浏览和查询工具
这些客户端工具覆盖了从数据工程师到算法科学家、从开发人员到运维团队的全部角色,每个角色都可以用自己最习惯的方式与 DolphinDB 交互——学习成本极低,上手极快。
四、效率验证:真实场景中的开发效率跃迁
4.1 案例一:某地震台网中心——从"三套系统"到"一个平台"的算法开发
背景:该中心每 10 毫秒采集一条地震监测记录,需要在波形数据上进行 MiniSeed 文件解析、FilterPicker 异常检测、RTSeis 实时分析等复杂信号处理,同时关联设备元信息进行联合分析。
传统开发方式:C 语言解析 MiniSeed 文件,Python/MATLAB 进行信号处理和异常检测,外部数据库存储元信息,三套系统之间数据来回搬运,开发和维护周期长。
DolphinDB 方案:基于 DolphinDB 构建统一的地震波形分析预警架构。MiniSeed 文件解析通过内置函数直接完成,FilterPicker、RTSeis 算子通过插件在数据库内执行,TensorFlow 模型推理通过插件在线运行。波形数据与元信息的关联在同一 SQL 查询中完成。
开发效率提升:
- 原本需要 C + Python + MATLAB 三种语言实现的全流程,现在用 DolphinDB 一种语言完成
- 毫秒级计算响应延时,无需在系统间搬运数据
- 从 MiniSeed 解析到异常检测到预测预警,全流程在库内闭环
- 新算法的验证周期从"数周"缩短至"数天"
这个案例最核心的价值在于"统一"——过去分散在三种语言、三个系统中的开发工作,现在统一到一个平台、一门语言中。开发者不需要在系统之间"翻译"代码,算法的正确性由平台保证。
4.2 案例二:某海关电子口岸——从"Java 重型开发"到"脚本化快速迭代"
背景:该海关电子口岸原来自研数据仓库平台,采用 MongoDB、Oracle、MySQL 等产品构建离线数仓,使用 Java 实现全部业务逻辑。数据量达 TB 级,最大单表 10 亿级别,业务逻辑极其复杂。
传统开发方式:所有数据处理逻辑用 Java 编写,从简单的数据清洗到复杂的业务规则,都是 Java 类和方法。每新增一个业务需求,都需要经过"需求分析→接口设计→编码实现→单元测试→集成测试→部署上线"的完整 Java 开发流程,周期长、响应慢。
DolphinDB 方案:利用 DolphinDB 的 SQL-92 标准支持和多范式编程能力,将大部分业务逻辑从 Java 代码迁移到 DolphinDB 脚本中。流计算框架支持毫秒级 Upsert 和逻辑删除,格式化清洗规则通过函数化自定义。配合丰富的数据源接入能力,实现多业务系统数据融合。
开发效率提升:
- 复杂计算和业务逻辑的响应时间从"分钟级"缩短到"秒级"
- 业务逻辑从"Java 编译部署"变为"脚本即时执行",迭代周期大幅缩短
- 极大简化了数据处理链路,降低了人员投入和运维成本
这个案例展示了多范式编程在实际业务中的价值:过去需要 Java 工程师编译、打包、部署才能上线的业务逻辑,现在通过 DolphinDB 脚本可以直接在数据库内运行,修改即时生效。从"周级迭代"到"天级甚至小时级迭代",开发效率的跃迁是显而易见的。
4.3 案例三:某大型水电企业——百万测点平台的"统一开发"实践
背景:中国最大的水电上市公司,200 余万测点每日产生数百亿行数据,需要在多个地理位置分散的水电站之间实现统一的开发和分析框架。
传统开发方式:各水电站使用不同的技术栈进行数据采集和初步分析,云端再使用另一套系统进行汇聚和深度分析。边缘端和云端两套开发框架,同一个分析逻辑需要分别适配两套环境,维护成本极高。
DolphinDB 方案:采用云边协同架构,边缘端和云端使用同一套 DolphinDB 技术栈。云端开发的脚本可快速下发至边缘端执行,边缘端数据上传后可在云端继续分析。所有分析逻辑只需编写一次,即可在边缘端和云端无缝运行。
开发效率提升:
- 多源数据关联查询响应从分钟级缩短至秒级
- 复杂分析任务效率提升 5-6 倍
- 边缘端与云端共用一套代码,开发和维护成本减半
- 关键设备故障预警延迟从"分钟级"压缩至"毫秒级"
这个案例凸显了"统一开发框架"在分布式工业场景中的价值:当边缘端和云端使用同一门语言、同一套函数库、同一套开发工具时,开发者不再需要关心"这段代码在哪里运行"的问题——编写一次,到处运行。
4.4 案例四:某新能源车企——1.8 亿点/秒平台的"快速搭建"
背景:单车测点达 7000,需要搭建高性能的车联网大数据平台,支持每秒 1.8 亿测点的不间断写入和实时异常检测。
传统开发方式:搭建 Kafka + Flink + 时序数据库 + Spark 的多组件架构,每个组件需要专门的团队开发和维护。数据接入层、流计算层、存储层、分析层的接口定义和数据格式转换需要大量的适配开发工作。
DolphinDB 方案:基于 DolphinDB 构建一站式数据分析平台,利用内置的异常检测引擎和流计算框架,通过简单的表达式定义异常规则,即可实现毫秒级的数据异常检测和告警。Python SDK 用于算法研发,C++ SDK 用于高性能数据接入,Grafana 插件用于可视化监控。
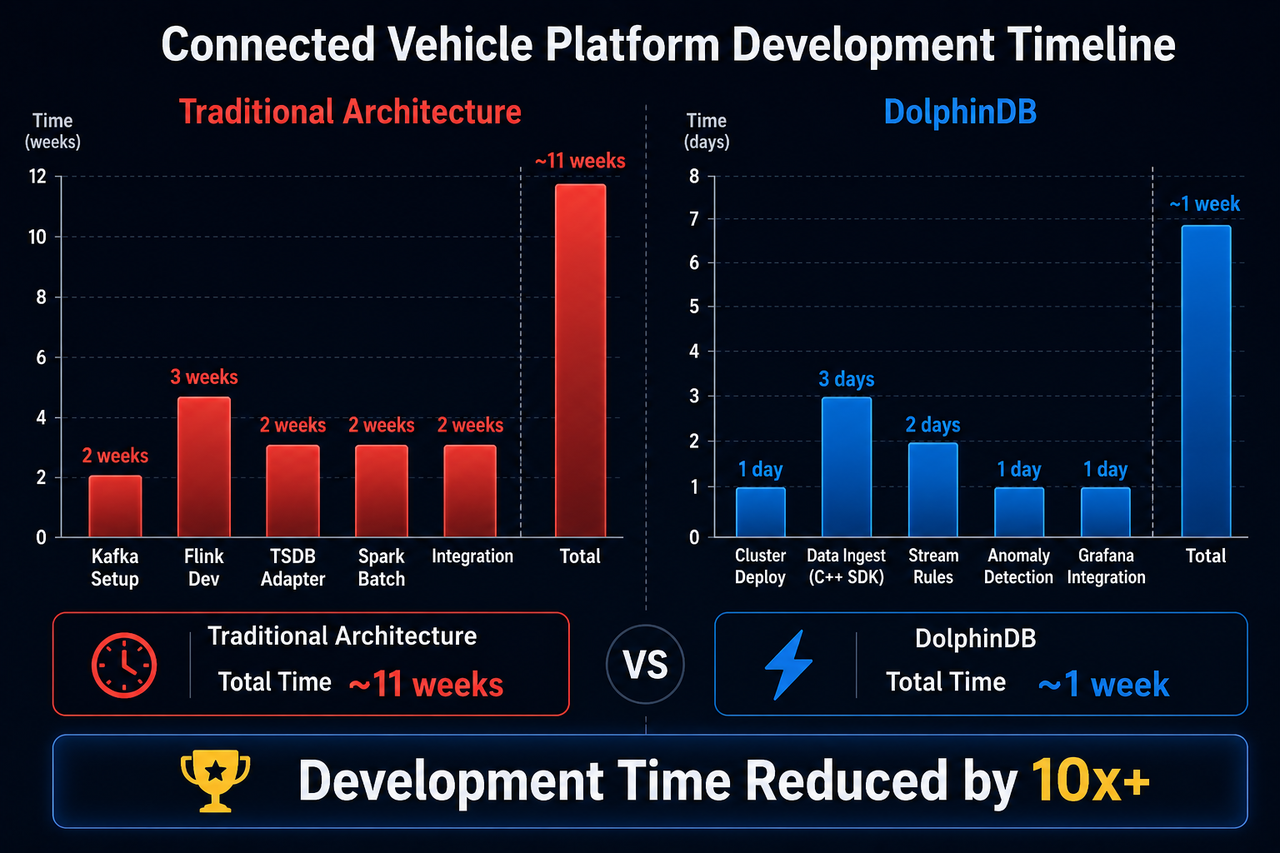
开发效率提升:
- 平台搭建周期从"数月"缩短至"数周"
- 满足每秒 1.8 亿点写入速率,资源利用率稳定在 40% 左右
- 写入过程中单点查询平均耗时 100ms 以内
- 毫秒级异常检测与实时告警,开发与维护成本极低
这个案例最能说明"生态体系"的价值:DolphinDB 的 SDK 覆盖了不同开发角色的需求——C++ 工程师负责高性能数据接入,Python 工程师负责算法开发,运维人员通过 Grafana 监控——每个人用自己最擅长的工具,但数据始终在同一个平台内流转,不需要在系统间搬运和转换。
4.5 案例五:某动力电池企业——万亿级实验数据的"分析师友好型"平台
背景:实验室检测设备每秒产生超百万级数据点,年积累实验数据量达万亿级。原有基于 MySQL 分库分表的架构,不仅查询性能差,实验报告的生成也依赖复杂的数据处理脚本。
传统开发方式:数据分析师需要编写复杂的 SQL 查询或 Python 脚本来处理实验数据,从数据导出到报告生成可能需要数小时。不同实验团队各自维护独立的数据处理脚本,缺乏统一的分析框架。
DolphinDB 方案:DolphinDB 为其量身打造实验数据实时分析平台。利用 SQL-92 标准兼容性和丰富的内置函数,数据分析师可以用熟悉的 SQL 语法直接查询和分析万亿级数据,无需学习新的查询语言。流计算框架和 CDC 实时同步确保数据的即时可用性。
开发效率提升:
- 实时数据处理延迟控制在 100 毫秒以内
- 万亿级历史数据复杂查询响应时间从数十分钟骤降至秒级
- 测试实验报告生成时间缩短至 5 秒内
- 数据分析师无需学习新工具即可高效工作
这个案例的关键词是"分析师友好"——DolphinDB 的 SQL 兼容性意味着数据分析师可以直接使用已有的 SQL 技能进行分析,学习成本几乎为零。而 DolphinDB 扩展的组内计算、透视表等功能,则让原本需要复杂 Python 脚本才能实现的分析,用一条 SQL 语句就能完成。
五、选型思考:如何评估时序数据库的开发效率?
基于以上分析与案例,对于正在选型工业物联网数据平台的开发团队,我提炼出评估"开发效率"的六个维度:
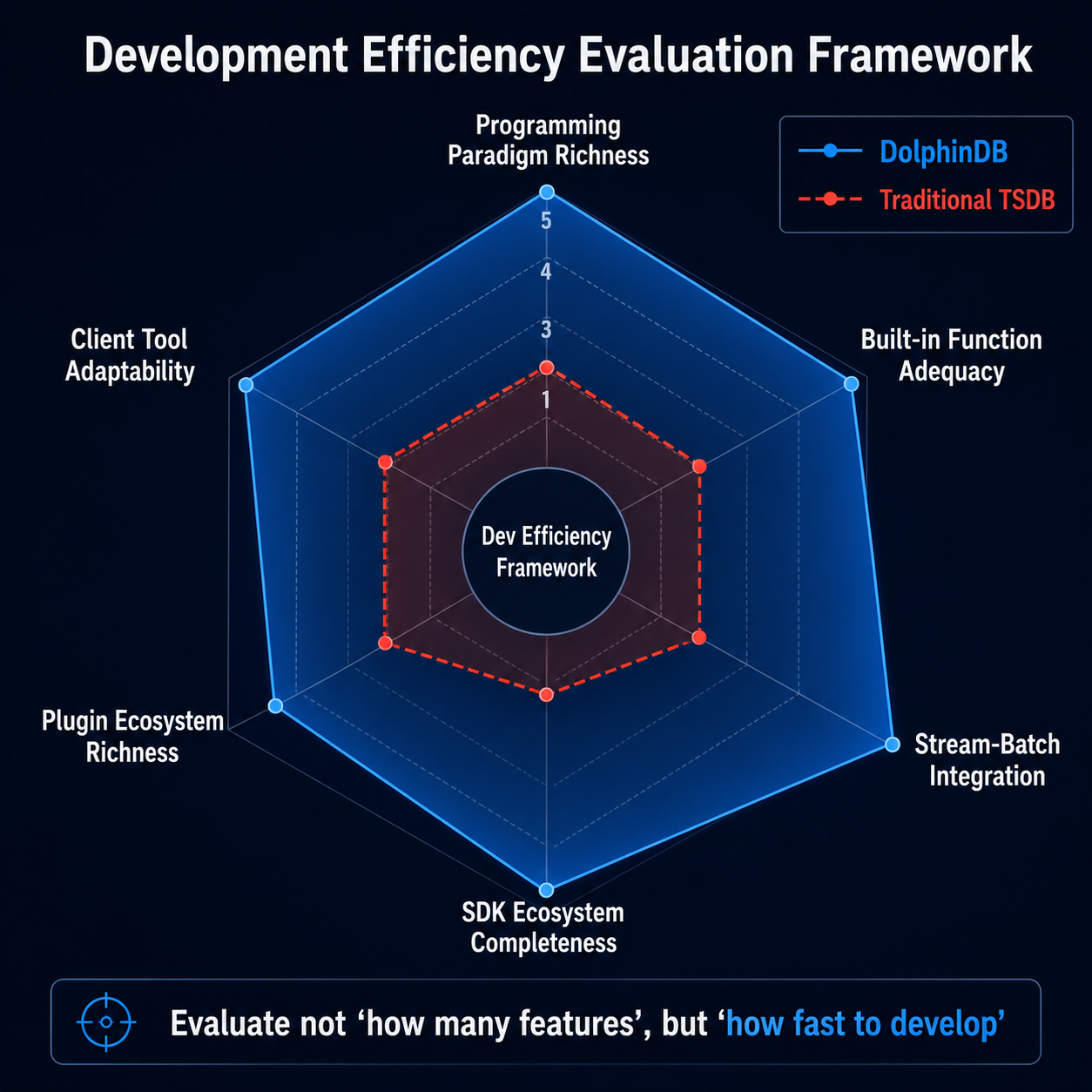
维度一:编程范式是否丰富? 如果平台只支持 SQL,那么复杂业务逻辑的表达能力将非常有限。多范式编程(命令式、函数式、向量化、SQL)让开发者可以根据问题选择最合适的表达方式,显著提升代码的简洁性和可读性。
维度二:内置函数是否充足? 工业分析涉及的领域广泛,从时序处理到信号处理到机器学习。如果每个分析需求都需要从零编写或调用外部库,开发效率将始终低下。丰富的内置函数库是"开箱即用"的基础。
维度三:流批是否一体? 如果实时处理和离线分析需要两套代码,那么开发、验证、维护的成本将指数级增长。流批一体让同一份代码覆盖研发、生产和回测三个阶段,从根本上消灭了"算法三写困境"。
维度四:SDK 生态是否完善? 企业的开发团队通常已经建立了自己的技术栈。如果新平台要求"推倒重来",学习成本和迁移成本将是巨大的。丰富的 SDK 生态让不同角色的开发者可以使用最熟悉的语言与平台交互。
维度五:插件生态是否丰富? 工业物联网场景中,数据源、消息队列、AI 框架、可视化工具种类繁多。如果每接入一个新组件都需要大量适配开发,平台的价值就被抵消了。丰富的插件生态是高效集成的加速器。
维度六:客户端工具是否适配不同角色? 数据工程师、算法科学家、运维人员、业务分析师——不同角色有不同的使用习惯。如果所有角色被迫使用同一种工具,学习成本就会很高。多样化的客户端工具让每个角色都能用最自然的方式工作。
DolphinDB 在这六个维度上给出了较为完整的答案。它不是提供一个"好用的 SQL 引擎"就到此为止,而是构建了一个从语言范式到函数库、从流批一体到 SDK 生态、从插件市场到客户端工具的完整编程环境。这种"端到端"的编程体验设计,才是工业物联网开发效率跃迁的根本保障。
六、结语
工业物联网的数据开发,正在经历一场从"多语言拼凑"到"统一编程环境"的范式转变。
过去十年,行业的开发模式是"各管各的"——消息传输用 Java,流计算用 Scala,批处理用 Python,存储用 SQL,AI 用 Python,可视化用 JavaScript。六七种语言拼接出来的数据平台,每个环节都在"翻译",每次修改都要"同步",每个新人都要"重新学习"。
DolphinDB 代表的是另一种思路:用一门图灵完备的多范式编程语言,统一从数据采集到存储、从流计算到批处理、从复杂分析到 AI 推理的完整开发链路。 多范式编程让代码更简洁,2000+ 内置函数让分析更高效,流批一体消灭了"算法三写"的噩梦,丰富的 SDK 和插件生态让平台无缝融入现有技术栈。
从地震波形分析的三系统归一,到海关数仓的 Java 脚本化改造,再到车联网平台的快速搭建——这些案例印证了一个事实:当开发者不再花 60% 的时间做"翻译"和"造轮子",而是将全部精力投入到业务逻辑本身时,开发效率的跃迁是数量级的。
工业物联网的开发效率,不应该被困在"万行代码"和"五种语言"的迷宫里。让开发者用最自然的方式表达最复杂的逻辑,用最少的代码实现最强大的分析——这或许就是 DolphinDB 编程生态体系给工业物联网最重要的启示。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)