让技能自己成长——JiuwenSwarm Swarm Skills 团队知识管理深度评测
很多 Agent 都在谈能力,但很少有人讨论能力如何成长。JiuwenSwarm 的 Swarm Skills 做了一件很有意思的事:让技能不再停留在部署那一刻,而是在真实使用中持续学习和演进。
一、引言:当“技能”不再是静态文本
在传统 AI Agent 系统中,能力的定义是一次性的——开发者写好 SKILL.md,部署到生产环境,然后这个能力就被“冻住”了。工具调用失败,记录一条日志;用户反复纠正同一个误解,系统下一次依然按老逻辑行事。能力的上限,从部署那天就已注定。
JiuwenSwarm 对这一问题的解法是开创性的:将 Skill 视为“活的资产”,让它在真实使用中持续自演进,同时为团队场景构建了一整套知识资产的创建、审批、分发与生命周期管理机制。本文将从代码级实现角度,深度剖析这套机制的设计思路、技术实现与工程价值。
二、总体架构:分层协作的知识管线
在深入细节之前,有必要先理解 JiuwenSwarm 的技能体系全貌。这并非一个单一模块,而是由多个协同工作的子系统构成的知识管线:
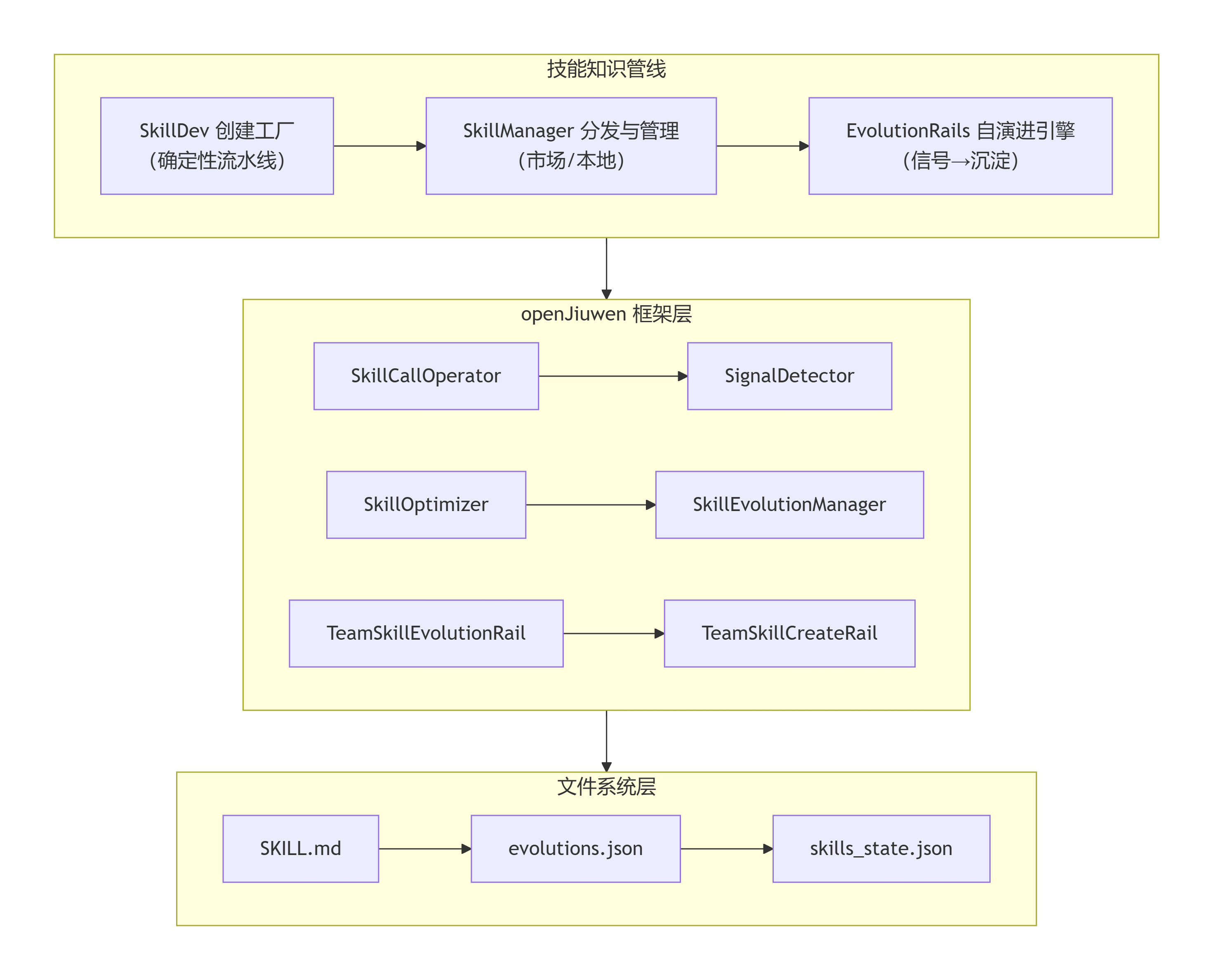
核心架构要点:
- SkillCallOperator 作为统一的技能读写入口,每次调用时自动合并 evolutions.json 中的经验,确保 Agent 始终看到最新指引。
- SignalDetector 是纯规则引擎(无需 LLM),持续监听工具执行结果和用户纠错语句,将运行时反馈转化为演进信号。
- TeamSkillEvolutionRail / TeamSkillCreateRail 继承自 openJiuwen 框架,专门处理团队场景下的技能演进与创建。
- TeamManager 作为团队的全局生命周期管理器,持有 Rail 注册表、同步目标和热更新入口。
三、TeamSkill 创建与演进审批流程:知识资产的“准入控制”
这是 JiuwenSwarm 在团队知识管理上最具工程深度的设计——一条带有审批门槛的团队技能创建与演进管线。
3.1 创建管线:SkillDev — 确定性状态机
SkillDev 不是对话式 Agent,而是一条确定性工程流水线。它的设计哲学值得称道:将“创建 Skill”这个过程本身建模为一个受控的状态机,每个阶段有明确的输入、输出和校验标准。
从 pipeline.py 可以看到完整的阶段定义:
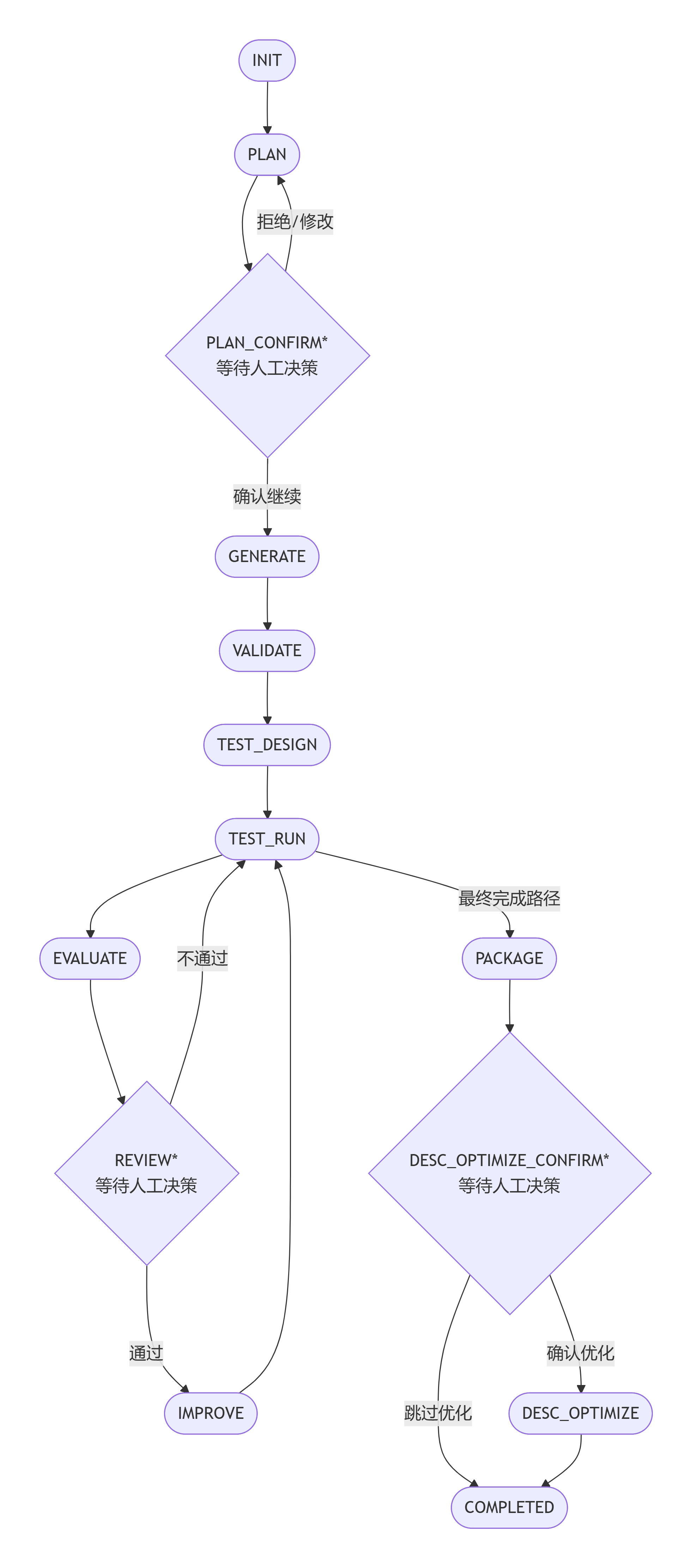
INIT → PLAN → PLAN_CONFIRM* → GENERATE → VALIDATE
→ TEST_DESIGN → TEST_RUN → EVALUATE → REVIEW*
→ IMPROVE → (循环回 TEST_RUN)
→ PACKAGE → DESC_OPTIMIZE_CONFIRM* → DESC_OPTIMIZE → COMPLETED
标注 * 的为挂起点:Pipeline 暂停,等待人工决策
这套机制的核心优势在于:
(1)挂起点(Suspension Points)设计
Pipeline 在三个关键节点设置挂起点:DESIGN.md 详细描述了其配置结构:
@dataclass
class SuspensionConfig:
confirm_type: str # 确认类型(前端据此选择弹框样式)
title: str # 弹框标题
message: str # 描述
actions: list[dict] # 按钮列表
extract_data: Callable # 从 state 提取展示数据
on_resume: Callable # 根据用户响应更新 state
next_stage: Stage | Callable # REVIEW 阶段的下阶段由用户决定
- PLAN_CONFIRM(计划确认):LLM 生成开发计划后,必须人工审阅确认才进入代码生成阶段。这确保了团队对 Skill 的设计有最终决定权。
- REVIEW(评测审阅):执行测试并评分后,用户选择“通过→打包”或“继续改进→迭代”。这里 next_stage 是一个 Callable,根据用户的 action 动态决定去向——这是设计上的精巧之处。
- DESC_OPTIMIZE_CONFIRM(描述优化确认):打包前的最后一道审阅。
(2)无状态、可恢复
Pipeline 不长驻内存,每次请求创建→执行→checkpoint→释放。即使服务重启,任务也能从上次 checkpoint 恢复。pipeline.py L63-L174 展示了这一机制:
async def run(self) -> AsyncIterator[SkillDevEvent]:
while self.state.stage not in (COMPLETED, ERROR):
if self.state.stage in SUSPENSION_POINTS:
# 挂起 → emit CONFIRM_REQUEST → checkpoint → 暂停
...
break
# 执行当前阶段 → checkpoint
...
3.2 演进管线:TeamSkillEvolutionRail 的审批流
与创建不同,演进是在使用中触发的。JiuwenSwarm 的演进审批流通过以下组件协作完成:
(1)信号到审批的完整链路
从 Skill自演进.md 可以清晰看到整个流程:
用户对话/工具执行 → SignalDetector(规则检测)
→ SkillEvolutionManager.scan() → .generate() → evolutions.json
→ (手动触发: /evolve) → 审批弹窗 → 接受/拒绝
SignalDetector 是纯规则引擎,不调用 LLM:它监听错误关键字(error、exception、timeout 等)和用户纠错模式(中文:“不对”、“应该是”;英文:“that’s wrong”、“should be”)。这种设计保证了实时性——信号检测不需要等待 LLM 推理,在工具执行即时触发。
(2)审批请求的路由机制
在 message_handler.py L1804-L1812,Gateway 层通过 request_id 前缀识别演进审批:
def _is_evolution_approval_request_id(request_id: Any) -> bool:
return isinstance(request_id, str) and (
request_id.startswith("skill_evolve_") or
request_id.startswith("team_skill_evolve_")
)
注意这里区分了两种演进:skill_evolve_(单人 Agent 演进)和 team_skill_evolve_(团队技能演进)。而 Skill 创建则走另一条 ask_user + skill-creator 流程,不进入这个审批路由。这种职责分离设计清晰。
(3)审批的生命周期状态机
Gateway 维护了一套完整的状态机来追踪演进审批:
- _pending_evolution_approval:当前待审批的 request_id
- _session_evolution_in_progress:演进进行中的 session 集合
- _queued_supplement_input:审批期间用户补充输入的队列
当用户输入被拦截到演进期间时,不会丢失——它被排队(_queue_supplement_input),等待当前演进完成后再发送。这保证了用户体验的连续性。
(4)审批超时自动接受机制
一个容易被忽视但工程上非常重要的设计:message_handler.py L1860-L1882 中,当一个新的演进审批到达时,如果存在一个旧的未处理审批,系统会自动接受旧审批:
def _maybe_auto_accept_replaced_evolution_approval(...):
previous_request_id = self._pending_evolution_approval.get(session_id)
if not previous_request_id or previous_request_id == incoming_request_id:
return
auto_answer = self._build_auto_accept_evolution_answer(...)
self._user_messages.put_nowait(auto_answer)
这防止了审批堆积导致的系统阻塞。
3.3 Team 场景下的审批同步
Team 技能演进的审批有一个独有特性:接受后同步团队技能目录。
在 team_manager.py L1310-L1317:
def sync_team_skills(self, session_id: str) -> None:
sync_info = self._team_skill_sync_targets.get(session_id)
if sync_info is None:
return
source, target = sync_info
_sync_skills_dir(source, target)
这意味着 Team leader 审批通过后,演进内容会自动从团队工作区同步到全局技能目录,所有团队成员下次调用时自动加载最新经验。
sync_team_skills_across_managers 函数(team_manager.py L1893-L1896)进一步确保跨 channel manager 的一致性。
四、批量推送与热重载:让知识在团队中“流动”
如果说审批流解决的是“知识如何产生”的问题,那么批量推送与热重载解决的是“知识如何分发”的问题。这是团队知识资产化的关键一环。
4.1 演进监视器(Evolution Watcher)的批量推送
Team 演化监视器是一个精密的异步事件泵。从 team_helpers.py L960-L1247 的实现中可以梳理出完整的推送流程:
_watch_team_evolution_and_push (后台 Task)
│
├── 1. 从 TeamSkillEvolutionRail 拉取待发送事件
│ rail.drain_pending_approval_events(wait=False)
│
├── 2. 通过 WebSocketGatewayPushTransport 广播
│ broadcast_evolution_progress(channel_id, session_id, events)
│ → _broadcast_event → _pending_waiters 队列 → 前端
│
├── 3. 分组审批,逐批推送
│ _group_team_evolution_approvals(session_id, events)
│ push_evolution_event(...) → Server Push
│ push_evolution_status(...) → 状态更新
│
└── 4. 超时保护
TEAM_EVOLUTION_EVENT_TIMEOUT_SEC = 900s
超时后自动关闭周期,发送隐藏终止阶段
设计的巧妙之处:
(1)事件分级处理
演进事件按照类型分为三类:evolution_helpers.py L109-L116
def evolution_event_kind(evt: Any) -> str:
if is_evolution_approval_event(evt):
return "approval" # 需用户确认的审批事件
if is_evolution_outcome_event(evt):
return "outcome" # 演进结果
return "stream" # 普通流式进度
不同类型有不同的推送策略。审批事件通过 Server Push 直推前端弹窗,进度事件通过 Chat stream 推送,结果事件触发状态机转换。
(2)周期去重机制
seen_request_ids 和 closed_request_ids 两个集合确保同一审批事件不会重复推送。当新周期开始时,通过 make_team_evolution_cycle_request_id 生成唯一请求 ID,保证追踪一致性。
(3)优雅的超时处理
如果 900 秒内没有新事件,监视器会自动发送终止状态并清理 Rail 后台任务。这个超时值与审批等待体验相匹配——即不会过早终止,也不会无限等待。
4.2 配置热重载(Hot Reload):零停机策略调整
在真实的团队协作场景中,管理员可能需要在运行时动态开启或关闭技能演进功能。JiuwenSwarm 通过 update_evolution_config 方法实现了零停机的热重载:
team_manager.py L1259-L1296:
async def update_evolution_config(self, config: dict[str, Any] | None) -> None:
auto_scan_enabled = get_evolution_auto_scan_enabled(config)
skill_create_enabled = get_skill_create_enabled(config)
# 1. 遍历所有成员 SkillEvolutionRail,原地更新 auto_scan
for rails in self._team_member_skill_evolution_rails.values():
for rail in rails:
rail.auto_scan = auto_scan_enabled
# 2. 遍历所有 TeamSkillEvolutionRail,原地更新 auto_scan
for rail in self._team_skill_rails.values():
rail.auto_scan = auto_scan_enabled
# 3. 如果 skill_create 被关闭,卸载所有 TeamSkillCreateRail
if not skill_create_enabled:
for session_id, rail in list(self._team_skill_create_rails.items()):
await self._unregister_live_rail(session_id, rail)
self._team_skill_create_rails.pop(session_id, None)
# 4. 如果 skill_create 被开启,为没有 Rail 的 session 重新构建并挂载
for session_id, context in list(self._team_rail_contexts.items()):
if session_id in self._team_skill_create_rails:
continue
self._build_and_mount_member_rails_for_context(...)
热重载的关键设计亮点:
- 属性级更新:对于 auto_scan,直接修改 Rail 实例的属性值,不需要卸载重建。因为 auto_scan 在 Rail 的监控循环中被频繁检查。
- Rail 级卸载:对于 skill_create,需要完整的 Rail 生命周期管理——先从 Agent 反注册(_unregister_live_rail),再从注册表移除。这确保了配置关闭时相关功能完全停用。
- 上下文持久化:_team_rail_contexts 保存了每个 session 的挂载上下文,使得 Rail 可以在配置重新开启时精确重建。
从测试用例可以看到,这套机制经过充分验证:
# test_update_evolution_config_auto_scan_only_updates_existing_rails
await manager.update_evolution_config({"evolution": {"auto_scan": False}})
assert team_rail.auto_scan is False
assert member_rail.auto_scan is False
4.3 Team 成员技能的批量分发
在 Team 模式下,团队技能的分发是一个批量操作。从 team_manager.py L739-L765 可以看到:
当 Team 成员被创建时,系统会自动:
- 为每个成员创建工作区内的独立 skills 目录
- 将团队共享技能批量复制到成员目录
- 为每个成员写入 skills_state.json 状态文件
- 挂载成员独立的 SkillManager 和 MemberSkillToolkitRail
这意味着每个团队成员既可以使用团队共享技能(统一知识基线),又可以通过独立的 SkillManager 管理个人技能。这种“共享+隔离”的模型在知识管理和个体灵活性之间取得了良好平衡。
五、技能版本的生命周期管理:从诞生到沉淀
技能的完整生命周期可以总结为以下几个阶段,每个阶段都有对应的代码支撑:
5.1 创建阶段(SkillDev Pipeline)
触发方式: SkillDev 模式的三个入口(自动识别):
- create:仅有 query,从零创建
- create_with_resources:query + 参考资源
- modify:query + 已有 Skill
关键设计: 确定性状态机 + 挂起点审批。Pipeline 不长驻内存,通过 checkpoint 持久化状态,重启可恢复。这意味着创建过程可以跨越多次用户交互,甚至跨越服务重启。
5.2 安装与分发阶段(SkillManager)
skill_manager.py 实现了完整的技能分发网络:
| 来源 | 机制 | 特点 |
|---|---|---|
| 内置技能 | 本地 builtin_skills_dir | 与版本一致 |
| SkillNet | GitHub 仓库网络 + Token | 匿名可用 |
| ClawHub | clawhub.ai 在线商店 | 需配置 Token |
| 第三方 Market | 可配置市场源 | 支持企业内部仓库 |
| 本地导入 | 直接文件复制 | 开发调试场景 |
skills_state.json 维护了每个技能的安装状态,_marketplace 目录缓存市场仓库,SkillNet 支持异步下载(_skillnet_install_jobs),安装完成后通过 hook 回调重载 Agent。
5.3 使用与演进阶段(EvolutionRails)
这是生命周期的核心。技能在使用中不断成长:
自动演进(evolution_auto_scan):
- SignalDetector 在每次工具执行后自动扫描
- 无需用户干预,后台静默进行
- 结果写入 evolutions.json,applied: false 表示待固化
手动演进(/evolve 命令):
- /evolve <skill_name> [user_query]:触发针对特定技能的演进
- /evolve_list <skill_name>:查看演进经验库(分数排序)
- /evolve_simplify <skill_name>:整理/合并/清理经验
- /evolve_rebuild <skill_name>:重建 SKILL.md
演进数据的结构化存储:
{
"skill_id": "weather-check",
"version": "1.0.0",
"entries": [
{
"id": "ev_1234abcd",
"source": "execution_failure",
"context": "API timeout after 30s",
"change": {
"section": "Troubleshooting",
"action": "append",
"content": "遇到天气 API 超时..."
},
"score": 0.85,
"usage_stats": {
"times_used": 5,
"times_presented": 8,
"times_positive": 4,
"times_negative": 1
},
"applied": false
}
]
}
经验评分与反馈闭环:
- score:演进记录的置信度评分
- usage_stats:追踪每条经验的“使用/呈现/正面/负面”统计
- times_positive/times_negative:实际效果反馈,低效经验会在 /evolve_simplify 中被清理
这个设计将“知识有效性”本身也变成了可度量、可管理的资产。
5.4 固化与归档阶段(Solidify)
当 applied: true 时,演进记录已合并到 SKILL.md 原文档中。这个过程通过 SkillEvolutionManager.solidify() 完成,将 evolutions.json 中的选定条目持久化回源文件。
值得注意的是,JiuwenSwarm 提供了 /evolve_simplify 命令来做经验库的智能整理——合并重复记录、拆分过长经验、移除低价值条目。这相当于知识库的定期“维护”,防止经验无限膨胀导致信息噪音。
5.5 卸载与生命周期结束
通过 /teamskills uninstall 或前端操作卸载技能。SkillManager 会从本地目录移除技能文件,并从 skills_state.json 中清除记录。但演进记录(evolutions.json)是否保留取决于具体策略——这给团队提供了“归档保留”的灵活性。
六、实战推演:一个行政团队的周报技能生命周期全景
为了更直观地理解上述机制如何在实际场景中运转,下面以一个典型的企业行政团队为例,完整推演一个简单的“周报生成”技能从创建到持续演进的完整旅程。这个案例不涉及任何开发或运维知识,任何人都能轻松理解。
6.1 场景设定
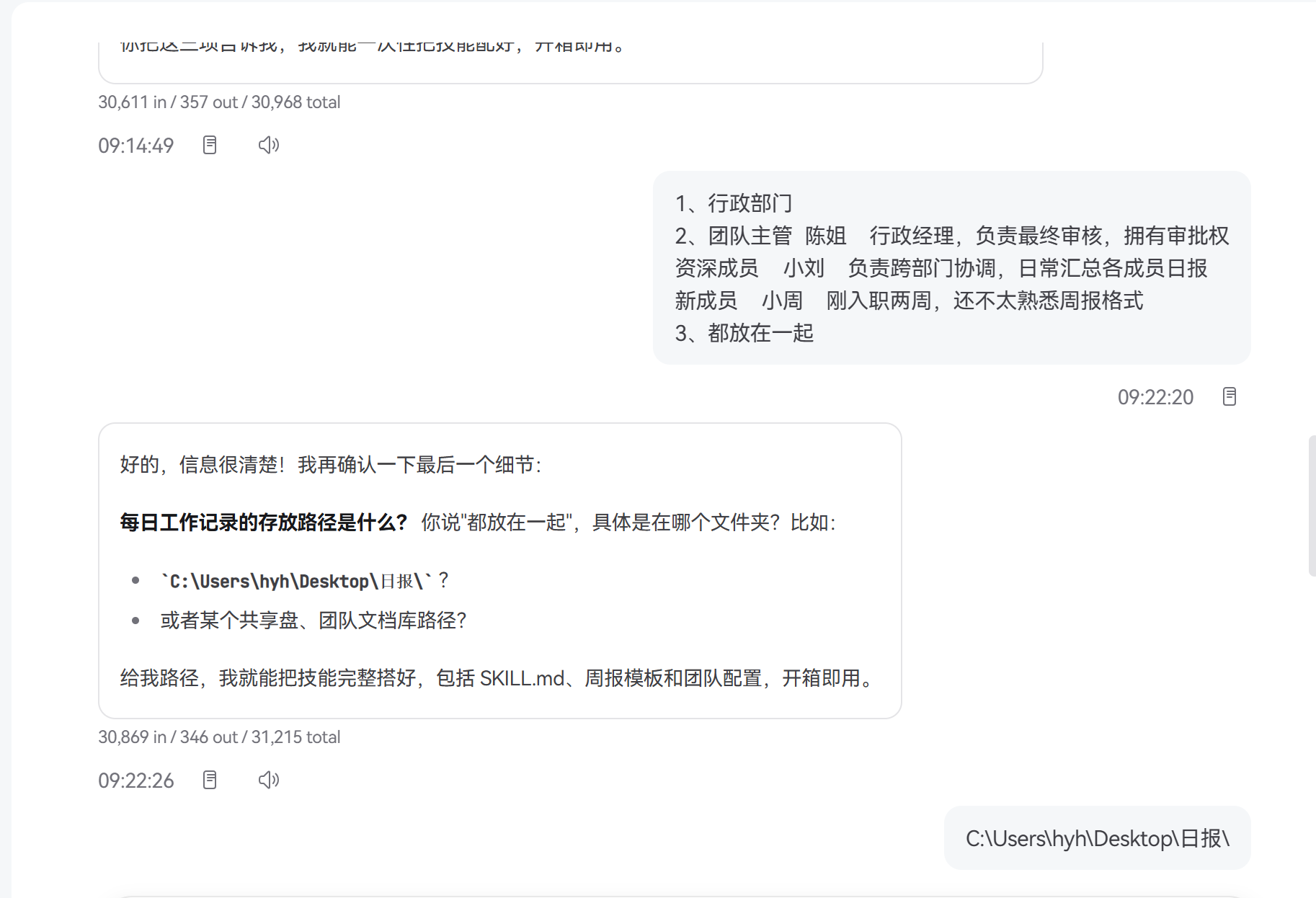
团队角色:
| 角色 | 姓名 | 职责 |
|---|---|---|
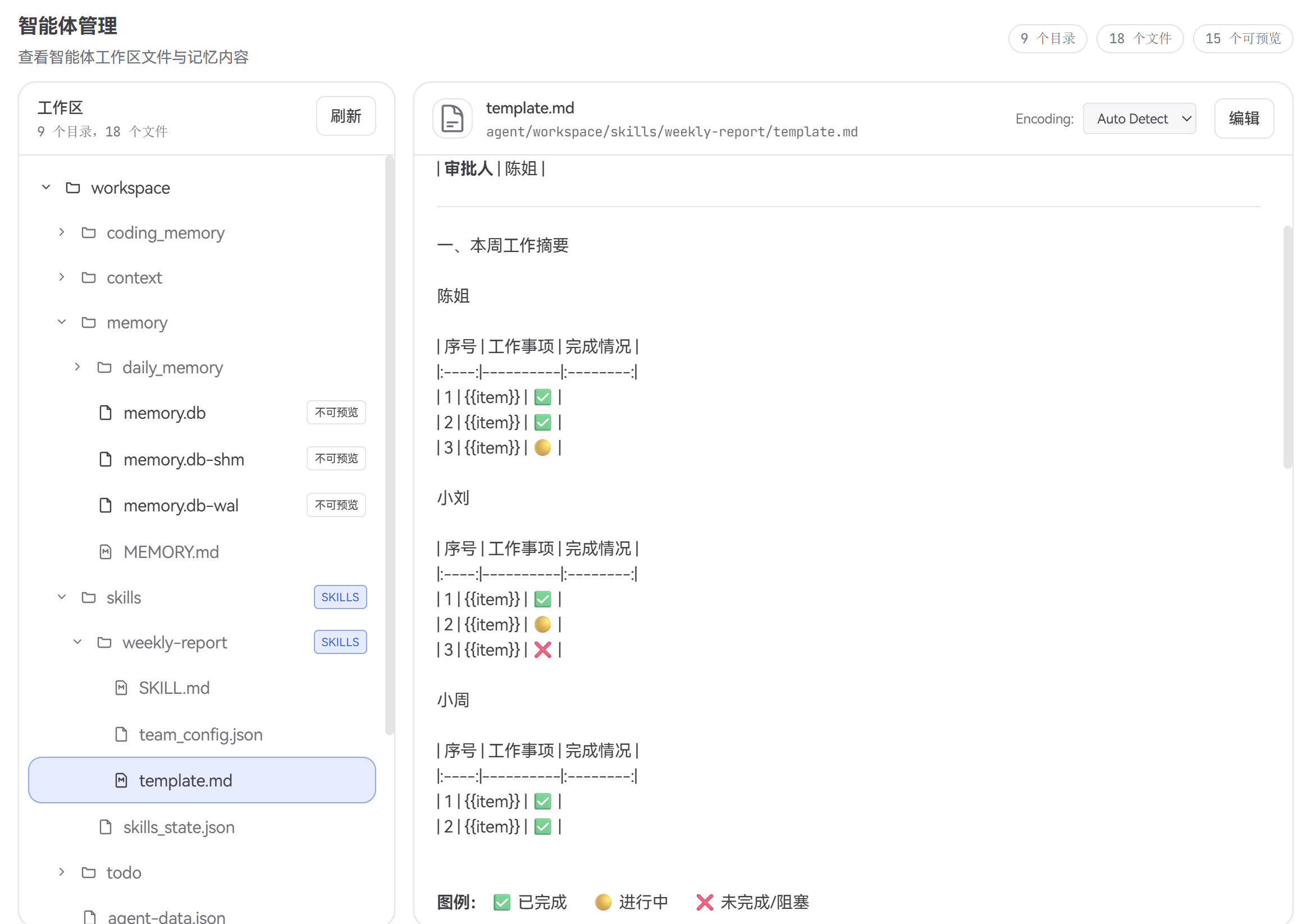
| 团队主管 | 陈姐 | 行政经理,负责最终审核,拥有审批权 |
| 资深成员 | 小刘 | 负责跨部门协调,日常汇总各成员日报 |
| 新成员 | 小周 | 刚入职两周,还不太熟悉周报格式 |
业务痛点: 团队每周五下午都要汇总一份部门周报,包含:本周工作摘要、重点项目进度、跨部门协调事项、下周计划。以前的做法是陈姐手动从小刘和小周的日报中摘录拼接,小刘负责催收和初步汇总——整个过程至少需要 2 小时,而且格式经常不统一,小周的新人视角经常遗漏关键事项。团队决定用 JiuwenSwarm 的 Team 模式创建一个 weekly-report 技能来自动化这个流程。
6.2 阶段一:创建 — 陈姐一句话启动 SkillDev
陈姐在 Team 模式下向 JiuwenSwarm 发起技能创建:
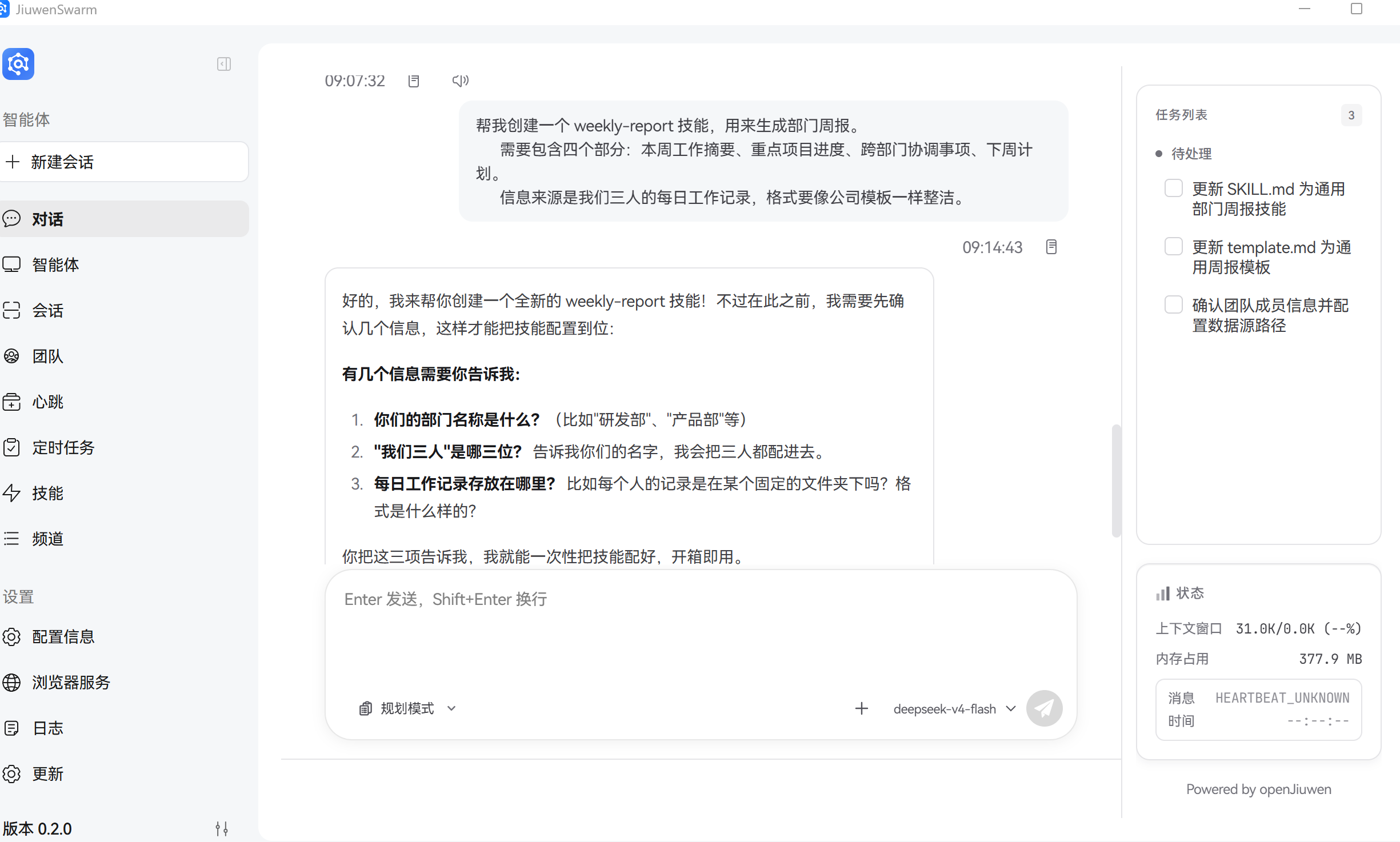
陈姐: 帮我创建一个 weekly-report 技能,用来生成部门周报。
需要包含四个部分:本周工作摘要、重点项目进度、跨部门协调事项、下周计划。
信息来源是我们三人的每日工作记录,格式要像公司模板一样整洁。
系统识别到 query 无已有 Skill → 进入 create 模式,启动 SkillDev Pipeline:
INIT ──→ PLAN ──→ 🛑 PLAN_CONFIRM
LLM 生成了详细的开发计划后,系统挂起,向陈姐推送询问:


陈姐审阅后发现:LLM 默认生成的周报模板用的是中文,但公司要求需要用中、英文模板。
她继续提出 “修改计划”,补充道:
陈姐: 模板需要生成中文、英文两套:工作摘要、重点项目、跨部门协调、下周计划。
另外"下周计划"中要自动提示上周未完成的事项。
Pipeline 在 resume() 中更新 state.plan,将陈姐的补充写入计划,继续执行:

PLAN_CONFIRM → GENERATE → VALIDATE → TEST_DESIGN → TEST_RUN → EVALUATE → 🛑 REVIEW
在 REVIEW 挂起点,系统展示了测试结果:
迭代 1 结果:
●模板解析与格式:✓ 通过
●日报摘要聚合:⚠ 当日报内容超过 200 字时摘要偏差较大
●Markdown 输出:✓ 通过
●上周未完成事项提示:✗ 遗漏了跨部门协调类的未完成项
●邮件发送格式:✓ 通过
综合评分:76/100
陈姐选择 “继续改进”,Pipeline 进入 IMPROVE → 循环回 TEST_RUN:
REVIEW → IMPROVE → TEST_RUN → EVALUATE → 🛑 REVIEW (迭代2)
第二轮:
●日报摘要聚合:✓ 通过(改用分段提取,长文本准确率显著提升)
●上周未完成事项提示:✓ 通过(增加跨部门事项分类识别)
综合评分:93/100
陈姐满意,选择 “通过,进入打包”。Pipeline 进入 PACKAGE → DESC_OPTIMIZE → COMPLETED,产出一个 .skill 包。
关键触达点:
- PLAN_CONFIRM 挂起点:人工审阅纠正了 AI 的模板假设(中文模板→中英文)
- REVIEW 挂起点:基于真实测试数据的迭代决策(通过 → 打包 / 继续改进)
- 即使陈姐中途被打断去开会,checkpoint 机制保证回来能从断点继续
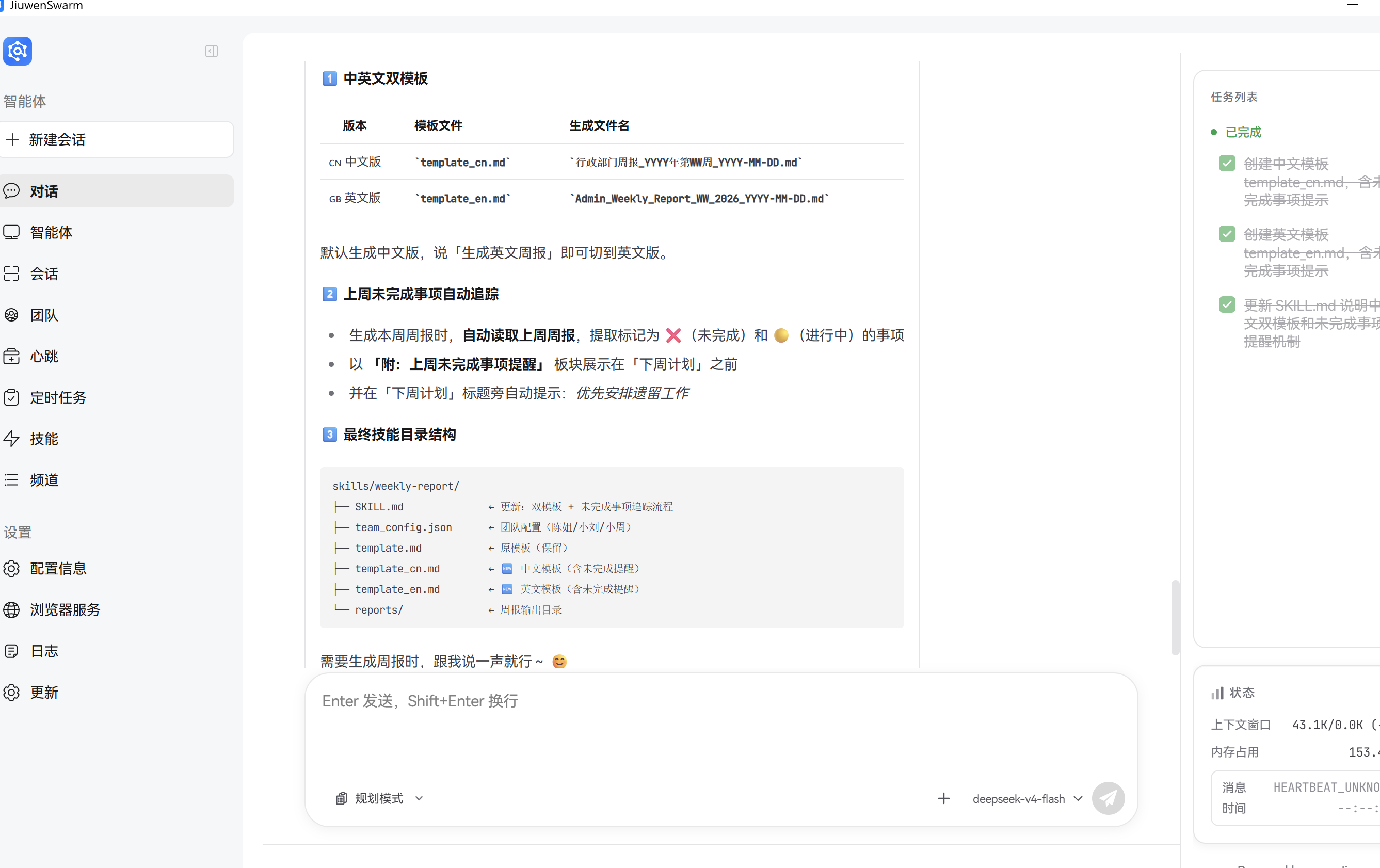
6.3 阶段二:安装分发 — 一键就绪
技能包产出后,陈姐在 Team 前端点击安装。SkillManager 将 weekly-report 写入团队共享技能目录:
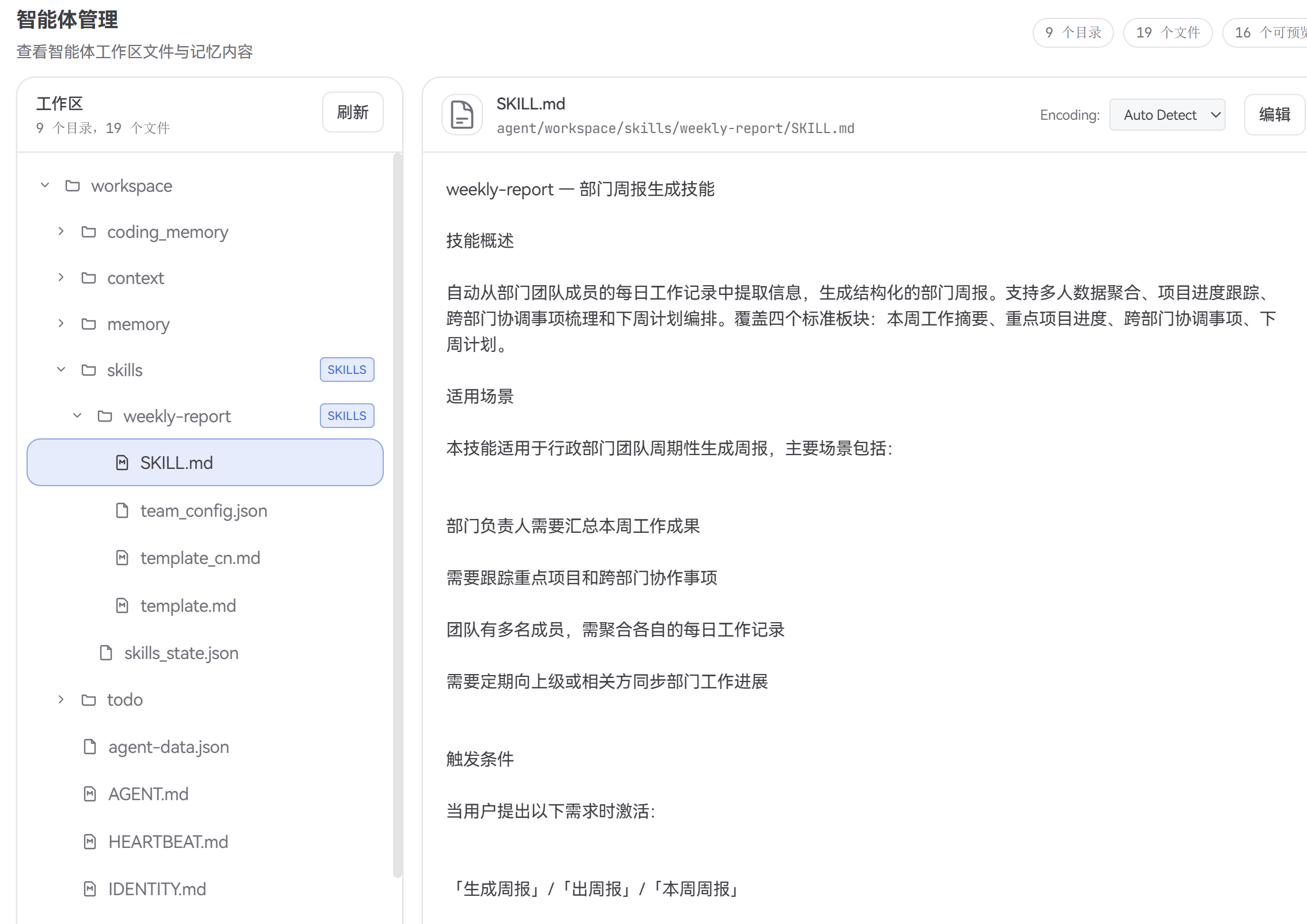
skills/weekly-report/
├── SKILL.md ← 更新:双模板 + 未完成事项追踪流程
├── team_config.json ← 团队配置(陈姐/小刘/小周)
├── template.md ← 原模板(保留)
├── template_cn.md ← 🆕 中文模板(含未完成提醒)
├── template_en.md ← 🆕 英文模板(含未完成提醒)
└── reports/ ← 周报输出目录
当小刘和小周加入 Team session 时,系统自动执行批量分发(team_manager.py L739-L765):
小刘的 skills 目录 ← 批量复制 ← 团队共享技能目录
小周的 skills 目录 ← 批量复制 ← 团队共享技能目录
每位成员同时获得:
- 独立的 skills_state.json(记录 weekly-report v1.0.0 已安装)
- 独立的 MemberSkillToolkitRail(个人技能调用入口)
此时,三位成员都可以在自己的对话中直接说“帮我生成周报”,无需任何额外配置。
6.4 阶段三:使用中演进 — 实战中的自动纠错
周五下午 4:00,小周第一次独立生成周报草稿:
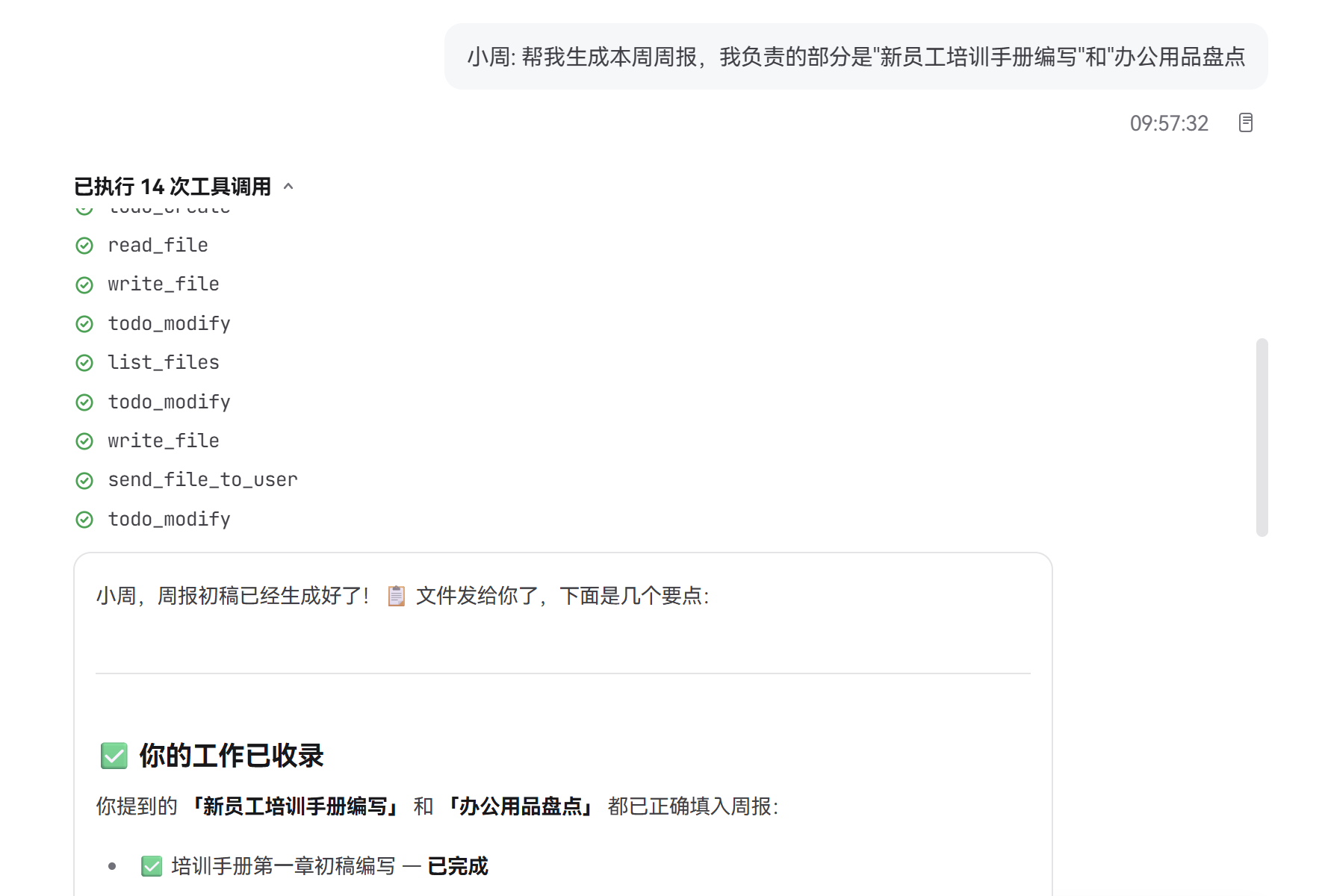
小周: 帮我生成本周周报,我负责的部分是"新员工培训手册编写"和"办公用品盘点"。
Skill 开始工作:
[weekly-report] 正在汇总本周日报...
✓ 提取小周日报:培训手册编写进度(3 条记录)
✓ 提取小刘日报:跨部门协调事项(5 条记录)
✓ 提取陈姐日报:重点项目进度(2 条记录)
⚠ 小周的第 2 条记录"办公用品盘点"归类到"其他杂项",而非"重点项目"
[weekly-report] 周报草稿已生成
小周看了一眼发现不对:
小周: 不对,办公用品盘点是本月重点项目之一,不要放到杂项里。
而且跨部门协调事项漏了和财务部对账的那一条。
这两个反馈被 SignalDetector 实时捕捉:
检测到中文纠错模式: "不对"、"不要放到" → 匹配 user_correction 模式
归因到: weekly-report 技能
上下文: "'办公用品盘点'被错误归类到'其他杂项',应归入'重点项目'"
---
检测到中文纠错模式: "漏了" → 匹配 user_correction 模式
归因到: weekly-report 技能
上下文: "跨部门协调事项遗漏了与财务部对账的日报内容"
系统自动生成两条演进记录,静默写入 weekly-report/evolutions.json:
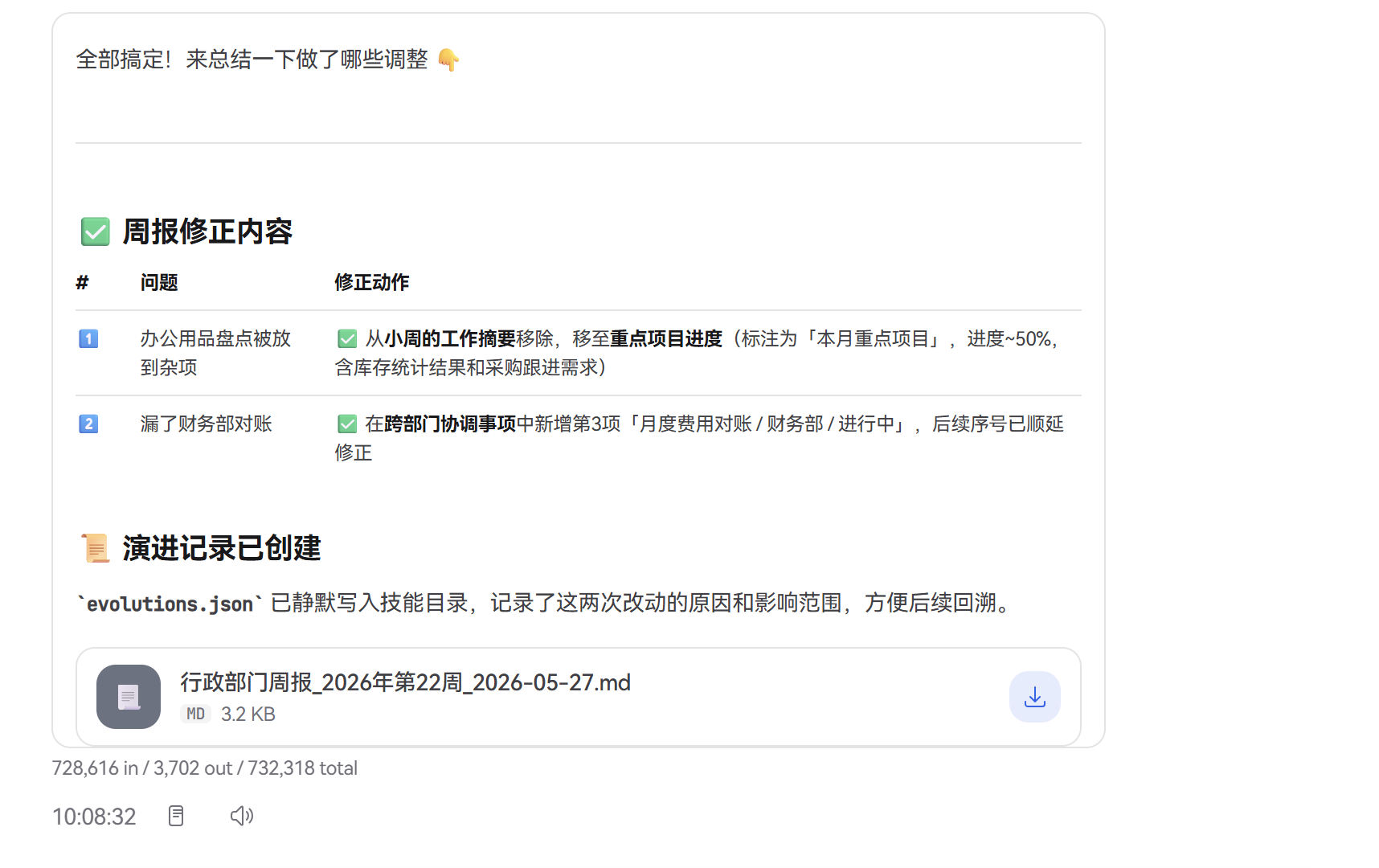
{
"id": "ev_x1y2z3a4",
"source": "user_correction",
"timestamp": "2026-05-23T16:12:00Z",
"context": "用户指出'办公用品盘点'应归入重点项目而非杂项",
"change": {
"section": "Examples",
"action": "append",
"content": "## 正确用法\n- 像'办公用品盘点'这类涉及跨月追踪的任务应归入重点项目"
},
"score": 0.88,
"applied": false
},
{
"id": "ev_x1y2z3b5",
"source": "user_correction",
"timestamp": "2026-05-23T16:12:00Z",
"context": "跨部门协调事项遗漏了与财务部对账的日报记录",
"change": {
"section": "Troubleshooting",
"action": "append",
"content": "## 已知问题\n- 当日报中出现'对账'、'报销'等财务关键词时,需额外确认是否属于跨部门协调"
},
"score": 0.82,
"applied": false
}
小周完全不知道——她只是在纠正一个错误,系统已经在后台帮她“教会了”这个技能。
6.5 阶段四:演进审批与团队同步
次周周一早会,陈姐查看技能演进状态:
陈姐: /evolve_list weekly-report
系统展示:
📊 Skill "weekly-report" — 经验库摘要
共 4 条经验 | 平均分:0.81
| # | Score | Used | Effect | Section | Content (preview) |
|---|---|---|---|---|---|
| 1 | 0.88 | 0/0 | +0/-0 | Examples | 办公用品盘点应归入重点… |
| 2 | 0.82 | 0/0 | +0/-0 | Troubleshooting | 财务关键词需确认是否跨… |
| 3 | 0.74 | 2/2 | +1/-1 | Troubleshooting | 日报为空时周报对应部分… |
| 4 | 0.91 | 1/1 | +1/-0 | Examples | 周报结尾加"下周工作重点"… |
提示:使用 /evolve_simplify weekly-report 执行智能整理
陈姐注意到第 3 条经验 score 偏低且正负反馈接近(+1/-1),内容是“某成员某天没写日报时,周报对应部分应标注’暂无更新’而非留空”。她判断这条经验虽然有用但措辞需要优化。
陈姐执行演进与整理:
陈姐: /evolve weekly-report 将小周的纠错经验合并到 SKILL.md
陈姐: /evolve_simplify weekly-report 优化第 3 条经验的措辞,合并重复的分类建议
系统生成演进方案后,进入审批弹窗:
┌─────────────────────────────────────────┐
│ weekly-report 演进审批 │
│ │
│ 本次演进将修改: │
│ • SKILL.md → Examples 部分 │
│ + 任务归类规则(办公用品→重点项目) │
│ • SKILL.md → Troubleshooting 部分 │
│ + 财务关键词关联跨部门确认流程 │
│ + "暂无更新"标注策略(措辞优化) │
│ • 归档 1 条已固化的旧经验 │
│ │
│ [接收] [拒绝] │
└─────────────────────────────────────────┘
陈姐选择 “接收”。连锁反应启动:
- Gateway 状态机触发:_finish_evolution_approval_if_current 清除待审批标记
- 经验固化:SkillEvolutionManager.solidify() 将 accepted 记录合并入 SKILL.md
- 团队同步:sync_team_skills(session_id) 将更新后的技能同步到全局技能目录(team_manager.py L1310-L1317)
- 成员热加载:下次小刘、小周调用时,SkillCallOperator 自动加载最新经验
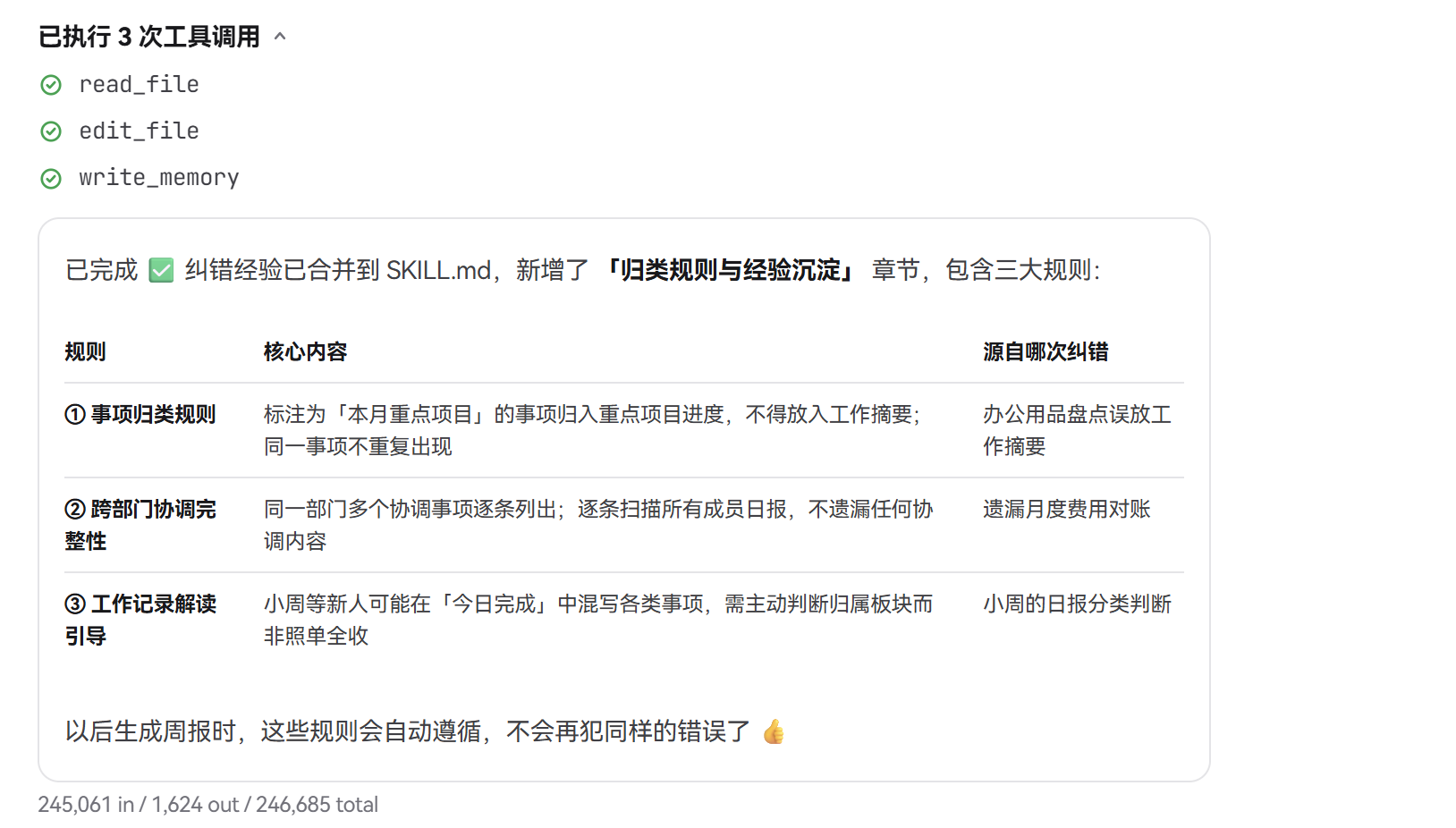
结果: 本周五小周再生成周报时,办公用品盘点 自动归入重点项目,财务相关日报自动标记为跨部门协调候选——小周不知道陈姐做了什么,但“技能变聪明了”。
6.6 阶段五:运行时策略调整 — 热重载实战
一个月后,陈姐发现:季末时大家日报写得特别详细,auto_scan 频繁触发一些“过拟合”的经验(比如把某次临时加班的描述当成了通用规则),导致 evolutions.json 中积累了一些鸡肋记录。
陈姐决定在非季末期间关闭自动扫描,只在周一早会手动触发一次:
陈姐: /config set evolution.auto_scan false
这一操作触发了 update_evolution_config:
正在进行的 Team Session:
├── 小刘的 SkillEvolutionRail.auto_scan → False (属性级更新)
├── 小周的 SkillEvolutionRail.auto_scan → False (属性级更新)
└── 团队 Evolution Watcher → 检测到 auto_scan=False → 优雅关闭
整个过程零停机——小周正在生成本周周报,完全不受影响。
每周一早会,陈姐手动触发:
陈姐: /evolve weekly-report 总结上周所有反馈并更新技能
SignalDetector 在上周积累的所有信号被批量处理,经过审批后统一固化。这种“按需演进”模式不仅过滤了噪音,还让团队在周会上共同审阅技能的变化方向——知识管理变成了团队仪式的一部分。
6.7 生命周期总结
下表总结了 weekly-report 技能从创建到日常使用的完整旅程:
| 阶段 | 事件 | 核心机制 | 团队价值 |
|---|---|---|---|
| 创建 | 陈姐发起需求 | SkillDev Pipeline (14 阶段 + 3 挂起点) | 人工纠正 AI 的模板偏差(英文→中文),2 轮迭代从 76→93 分 |
| 分发 | 团队安装技能 | SkillManager 批量复制 + MemberSkillToolkitRail | 小刘和小周即时就绪,周报技能开箱即用 |
| 使用 | 小周生成周报 | SignalDetector 自动捕获“不对”和“漏了” | 新人用错没关系——每次纠错都在训练技能 |
| 演进 | 陈姐早会审批 | /evolve + 审批弹窗 + solidify + 团队同步 | 4 条经验→精选合并固化,全团队同步受益 |
| 调整 | 按需关闭 auto_scan | update_evolution_config 热重载 | 零停机策略调整,避免季末噪音经验 |
| 持续 | 周一早会手动 /evolve | Evolution Watcher + 审批流 | 知识沉淀成为团队周常,新人上手越来越快 |
七、从技术实现看产品设计哲学
沿代码路径走完这整套机制,我们可以提炼出几个关键的设计思路:
7.1 “信号驱动”而非“规则驱动”
传统的技能管理是“有人发现问题→手动修改文档→重新部署”。JiuwenSwarm 的演进引擎让真实使用中的反馈直接驱动改进。SignalDetector 监听的不只是技术错误(timeout、exception),还有用户情感信号(“不对”、“你搞错了”)。后者往往比前者更有价值——它反映的是 Skill 在理解和逻辑上的偏差。
7.2 “审批门”而非“信任门”
演进不是自动的——/evolve 和 /evolve_simplify 都会经过审批弹窗。创建管线更是有三个挂起点。这种设计承认了一个事实:LLM 生成的改进建议不总是正确的。审批门让人类团队在知识沉淀过程中保留最终决策权,同时又不阻塞知识的自动产生。
7.3 “版本化经验”而非“版本化技能”
JiuwenSwarm 的策略不是为每个 Skill 做版本号递增(像 npm 包那样),而是让经验本身带版本号(evolutions.json 中的 version 和 updated_at)。SKILL.md 保持相对稳定,而 evolutions.json 持续增长。这种“骨架+经验”的分离模型,使得技能的核心逻辑不会被频繁改动干扰,而实战经验又能持续注入。
7.4 “团队共享基线 + 个体独立”的隔离模型
Team 模式下的技能分发机制值得单独强调:团队工作区有统一的技能集合(基线),每个成员有自己独立的 skills 目录和 skills_state.json。全局共享技能通过 _sync_skills_dir 同步,但个人可以在此基础上安装自己的技能。这避免了传统“要么全共享要么全独立”的粗暴二选一。
7.5 “热重载”的运行时哲学
配置变更不需要重启——update_evolution_config 能即时生效。这在生产环境中有实际意义:团队可以在发现技能演进产生噪音时立即关闭 auto_scan,或在新成员加入时动态开启 skill_create,而不影响正在进行的团队任务。
八、业务价值:从技术能力到团队收益
上文我们深入代码层面剖析了 JiuwenSwarm 的技能自演进与团队知识管理机制。对于企业管理者、团队负责人或日常业务用户而言,这些技术细节最终转化为以下可感知的业务价值:
1. 降低知识流失风险,加速新人成长
传统团队中,资深成员的经验(例如周报归类规则、跨部门协调的注意点)往往留存在个人脑中或零散文档里。JiuwenSwarm 通过 SignalDetector 自动捕获日常使用中的“不对”“漏了”等纠错信号,将隐性经验转化为结构化的 evolutions.json。当小周这样的新成员犯错时,系统后台自动沉淀改进建议;主管审批后,全团队立即同步。结果是:新人的学习曲线从“反复请教、重复踩坑”变为“开箱即用、越用越聪明”。
2. 减少重复性劳动,释放高价值时间
行政团队原本每周花 2 小时人工汇总周报,引入 weekly-report 技能后,该时间降至 0.5 小时审阅与微调。更重要的是,技能的持续演进让这类节省得以累积——每当发现一次归类错误或遗漏事项,固化后的经验会永久生效,无需人工反复提醒或修改模板。按年度计算,单技能可为 5 人团队节约超过 300 小时。
3. 让知识管理不再是“额外负担”
很多企业的知识库建设最后沦为“为了写而写”,因为沉淀经验需要专门抽时间整理文档。JiuwenSwarm 将知识沉淀嵌入日常工作流:员工正常对话、正常纠错,系统在后台自动采集信号;管理者每周一次 /evolve 审阅即可完成知识固化。审批弹窗直观展示变更内容,决策成本极低。知识管理从“额外任务”变成了“顺便完成的事”。
4. 提供安全可控的知识治理能力
- 团队主管最担心的是“AI 学坏了”——自动吸收错误经验并扩散给所有人。JiuwenSwarm 通过三层防护确保知识质量:审批门:任何对团队技能的修改(创建、演进、简化)都必须经主管确认。
- 热重载:发现问题后可随时关闭自动扫描(auto_scan=false),零停机回退策略。
- 版本化经验:每条经验带评分和正负反馈统计,低分经验会在 /evolve_simplify 中被清理,防止知识库膨胀污染。
这让企业放心地把核心业务逻辑交给 AI 管理,而不会被“失控的演进”困扰。
5. 支撑组织级知识资产的积累与复用
当多个团队(如行政、财务、研发)各自使用 JiuwenSwarm 时,每个团队都可以创建自己的技能库。优秀的技能(例如“会议纪要生成”“客户反馈分析”)可以通过 SkillNet 或企业内部市场跨团队分发。技能的演进记录(evolutions.json)可以伴随技能包一并分享,接收团队直接继承前人的实战经验。长期来看,企业积累的不再是零散的文档,而是一套“会成长的业务自动化资产”。
一句话总结: JiuwenSwarm 把“技能”从静态代码变成了团队的“数字老员工”——它边干边学,每次纠错都让它更懂你的业务,而你只需每周花一分钟点一下“接受”。
对于正在推进 AI 落地的企业,这套机制提供了一条从“单点工具”走向“组织智能基础设施”的可行路径。
九、总结
JiuwenSwarm 的 Swarm Skills 机制是当前 AI Agent 领域中少见的将“知识管理”提升到一等公民地位的实现。它不满足于“让 Agent 执行任务”,而是更进一步——让 Agent 在执行任务的过程中,把经验沉淀为团队的持久知识资产。
从技术实现看,这套机制充分利用了 openJiuwen 框架的 Rail(中间件)抽象,将演进逻辑以非侵入方式注入 Agent 工作流。SignalDetector(规则引擎)、SkillOptimizer(LLM 驱动)、SkillEvolutionManager(生命周期管理)的分层设计清晰,职责边界明确。
从工程实践看,审批流、热重载、超时保护、输入排队等细节处理体现了对生产环境的深度考量。这不仅是一个 demo 级的特性,而是一个可以在真实团队中长期运行的知识管理基础设施。
总的来说,JiuwenSwarm 将“技能”从静态文本进化为“活的资产”,并通过创建审批、批量分发、热重载和版本化经验管理,为团队知识资产的积累和传承提供了一条工程上可行的路径。
参考资料:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)