让 EDA 工具自己进化:多智能体如何改进百万行 ABC
系统的入口是知识启动,也就是在正式演化前,让智能体先理解 ABC 代码库和相关研究。另一类是中间结构和辅助信号,例如 AIG 节点数、边数、深度,mapper 预估面积和延迟,cut 数量、被剪掉的 cut、cut size,以及每个优化 pass 带来的结构变化。很多工具优化并不一定来自一条全新理论,而可能来自大量小改动的组合:一个更合适的 cut pruning 条件,一组更稳的 flow s
基于论文《Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC》整理
|
核心看点 • 研究对象:ABC 逻辑综合与验证框架,论文使用的定制仓库超过 120 万行 C 代码。 • 核心方法:多智能体直接演化 ABC 源码,并用编译、CEC 和 QoR 评估组成闭环。 • 关键结果:All Evo 归一化 QoR 为 0.917,相对集成基线约改善 8.3%。 |
如果一个 EDA 工具已经写了几十年、积累了上百万行 C 代码,我们还能不能让它继续自己变好?这不是一个“让大模型写几行脚本”的问题,而是一个更硬的工程问题:让智能体直接进入真实工具的源代码,在编译、验证和基准测试的反馈中,一轮一轮改进工具本身。
论文《Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC》选择了一个很有分量的对象:ABC。它是逻辑综合与验证领域广泛使用的开源框架,很多研究算法都曾以 ABC 为平台出现。作者尝试搭建一个多智能体自进化框架,让 LLM Agent 不只调用 ABC,而是修改 ABC 的源代码,并通过形式化正确性检查和 QoR 评估筛掉错误改动,保留真正有收益的版本。
这项工作有意思的地方在于,它没有把 EDA 问题简化成一个外部调参任务,而是直接面对完整代码库、复杂启发式算法和真实评估链路。换句话说,论文讨论的是:AI 能否参与到 EDA 工具自身的开发过程,而不是只做工具外面的“操作员”。
一、为什么这个问题值得关注
现代芯片设计离不开 EDA 工具。逻辑综合、技术映射、验证、物理设计等环节,本质上都在处理巨大的组合搜索空间。工具能不能在面积、时序、功耗和运行时间之间找到更好的平衡,直接影响后续设计质量。
但 EDA 工具的进步并不轻松。许多优化算法不是一个干净的公式,而是一整套工程化启发式:什么时候重写逻辑网络,怎样选择 cut,如何判断一个局部重构是否值得保留,怎样在面积和延迟之间取舍。这些规则往往来自专家多年经验,也常常散落在底层 C/C++ 代码和命令流程里。
ABC 正是这种复杂性的代表。论文中提到,作者使用的定制 ABC 仓库超过 120 万行 C 代码、4000 多个源文件;作为对比,原始公开 ABC 主分支也约有 85 万行代码。这样一个系统经过长期积累,非常强大,也非常难改。一个看似局部的启发式变化,可能影响另一个模块的数据结构、不变量和最终网表质量。
所以,问题不是“让大模型会写代码”这么简单。真正的挑战在于:大模型生成的改动能否在百万行级别代码库中编译通过?能否保证逻辑功能不变?能否在标准 benchmark 上稳定带来 QoR 改善?如果做不到这些,代码看起来再像样,也不能进入真实 EDA 工具链。
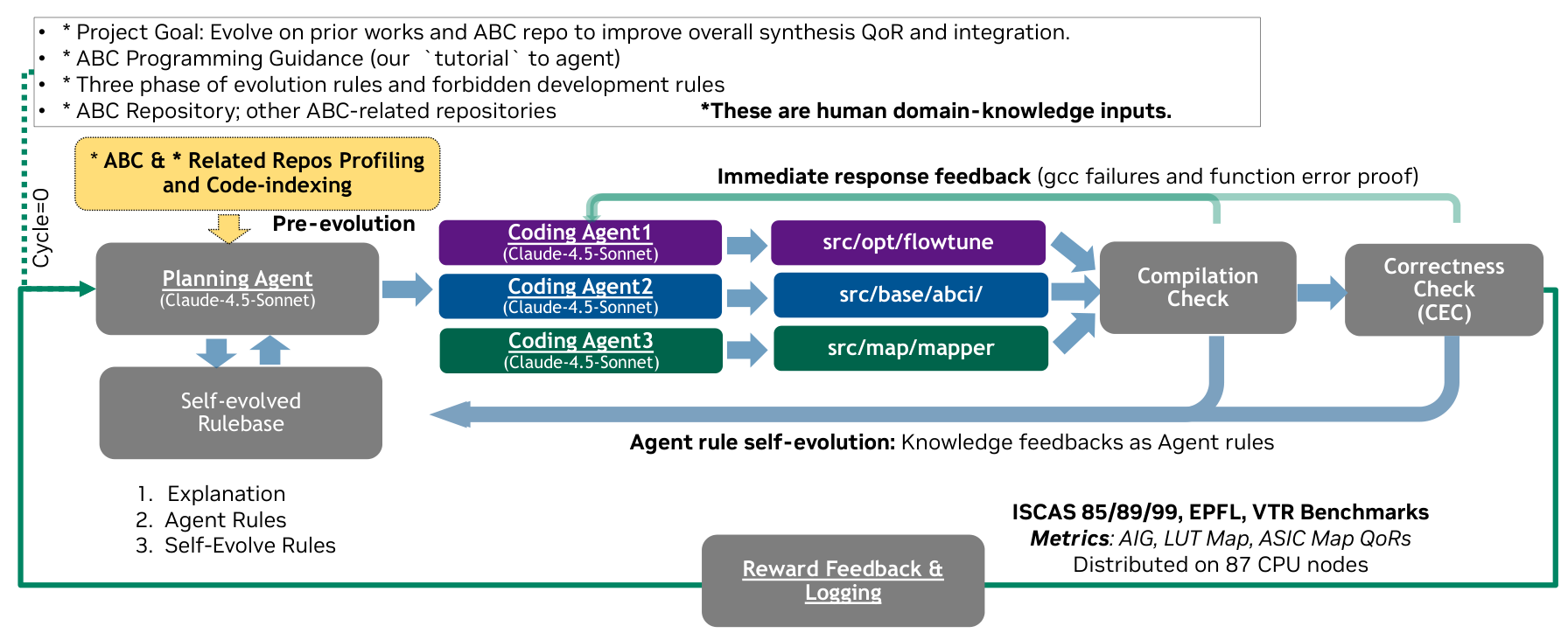
图 1 论文提出的多智能体自进化 ABC 整体框架
二、传统思路的瓶颈:好算法不一定能进入工具本体
过去二十多年,围绕 ABC 已经出现了大量研究工作,包括 cut-based mapping、Boolean rewriting、flow tuning、orchestration 等。这些成果推动了逻辑综合研究,但论文指出,很多新方法仍以外部原型、脚本或临时二进制的形式存在,并没有完全融入 ABC 的单一二进制执行模型和统一命令接口。
这带来两个现实问题。第一,研究原型和生产级工具之间有距离。一个方法在独立脚本中有效,不代表它能无缝进入 ABC 的构建系统、命令系统和内部数据结构。第二,工具内部已有启发式很难被系统性重新探索。比如 cut 过滤、代价估计、重构阈值、choice node 扩展等规则,可能已经多年没有被大范围重新搜索。
对人类工程师来说,这类搜索成本很高。每一次修改都要理解相关模块、写代码、编译、跑测试、检查结果,还要避免破坏正确性。论文把这个瓶颈概括为人力密集、启发式驱动和难以持续演化。也正因为如此,作者希望把 LLM Agent 放进一个受控闭环里,让它承担大量可自动化的代码级探索。
三、这篇论文提出了什么
论文提出的是一个面向 ABC 的多智能体自进化框架。它的目标不是生成一个外部调度器,也不是只在命令行上搜索 flow 顺序,而是让智能体直接修改 ABC 源码,同时保留 ABC 原有的单二进制执行方式和命令接口。
系统的入口是知识启动,也就是在正式演化前,让智能体先理解 ABC 代码库和相关研究。论文中提到,系统会分析三类方向:flow tuning、technology mapping,以及 technology-independent optimization。FlowTune 被选为 flow-level 探索的骨架,因为它已经以 ABC 内部命令的方式集成;mapping 方向则更多吸收外部方法的结构思想,用来定位 cut 枚举、剪枝和代价评分等可修改区域;技术无关优化方向则聚焦 AIG rewriting、refactoring、resubstitution 和 orchestration。
接下来,多智能体开始分工。一个规划智能体负责全局协调,三个编码智能体分别负责不同子系统。Flow Agent 工作在 src/opt/flowtune/,主要修改 pass 选择、停止条件和条件化 flow;Mapper Agent 工作在 src/map/mapper/,关注 cut enumeration、pruning 和 cost scoring;Logic Minimization Agent 工作在 src/base/abci/ 以及相关 orchestration 扩展中,处理 rewrite、resub、refactor、orchestrate 等技术无关优化。
这种分工很重要。ABC 不是一个可以随意重写的小项目。论文明确让各个智能体在指定目录内修改代码,并遵守 ABC 的 module.make 和 Makefile 约定,以降低跨模块冲突和破坏内部架构的风险。
四、三个关键创新点
创新点一:从外部调参走向源码级演化
很多学习型综合方法把 ABC 当作黑盒:外部算法选择一串命令,ABC 执行后返回结果。这种方式容易部署,但它无法改变 ABC 内部真正决定结果的启发式规则。论文的做法更进一步,让智能体直接修改 ABC 源代码中的算法组件。
这意味着系统有机会探索更细的优化空间。例如,不只是选择某个 pass 是否执行,还可以调整 pass 内部的阈值、打分逻辑、剪枝策略和 tie-breaking 规则。论文中最终出现的收益,正来自 flow、逻辑优化和 mapping 多个层次的共同变化,而不是单一参数的机械调节。
创新点二:多智能体按子系统协作
如果让一个智能体面对整个 ABC 代码库,很容易在上下文、职责边界和修改范围上失控。论文把任务拆成规划和编码两层:规划智能体读取反馈、提出下一轮方向;编码智能体只处理自己负责的子系统。
这种架构更像一个小型开发团队。每个成员有明确职责,所有改动再进入统一的编译、正确性和 QoR 评估流程。好处是,系统可以在保持局部修改可控的同时,让不同子系统的改进产生协同。
创新点三:用形式化检查守住正确性底线
EDA 工具最怕“错误地变好”。一个不正确的逻辑重写可能让面积或延迟看起来变小,但生成的电路已经不等价了。论文把组合等价检查,也就是 CEC,放在 QoR 评估之前。只有通过编译和等价检查的版本,才会进入后续 benchmark 评估。
论文使用 ABC 中的 cec 和 dsat 命令检查改动前后的逻辑等价。由于系统不涉及 retiming 或时序逻辑行为改变,组合电路可以直接检查;对于时序 benchmark,论文采用单帧 bounded-model checking,BMC depth 为 1,验证每个寄存器输入处的组合逻辑等价。任何 mismatch 或 SAT 反例都会让本轮修改被拒绝,并把错误反馈给下一轮规划。
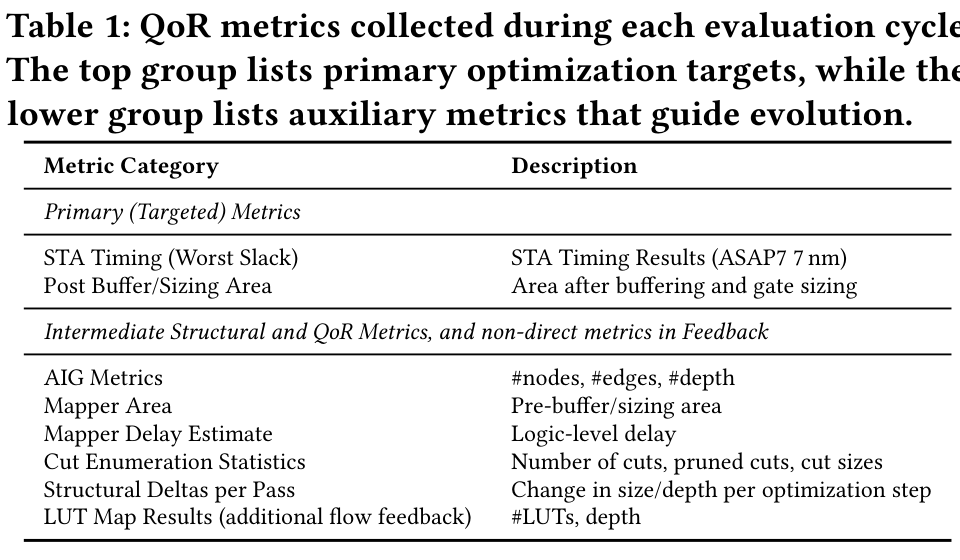
图 2 每轮评估中收集的 QoR 指标,覆盖最终结果与中间结构信号
五、演化闭环如何跑起来
一轮演化可以理解成五个阶段。第一,规划智能体读取上一轮反馈,决定下一个改哪个模块、尝试什么方向。第二,编码智能体生成代码修改,通常是面向指定目录的 C 代码和构建文件调整。第三,系统编译 ABC,如果 gcc 报错或函数层面出现问题,日志会被送回智能体,进入快速自调试。第四,系统执行 CEC 正确性检查,防止功能错误进入评估。第五,通过检查的版本才会在 benchmark 和多种 flow 上跑 QoR。
评估并不只看一个终点数字。论文 Table 1 列出了两类指标:一类是主要目标,例如 ASAP7 7nm 下的 STA worst slack,以及 buffer/sizing 后面积;另一类是中间结构和辅助信号,例如 AIG 节点数、边数、深度,mapper 预估面积和延迟,cut 数量、被剪掉的 cut、cut size,以及每个优化 pass 带来的结构变化。
这些指标共同形成反馈画像。最终 QoR 告诉系统“结果好不好”,中间指标则帮助系统理解“为什么变好或变坏”。如果某个子系统的改动明显改善结果,它会进入全局 champion 版本;如果出现退化,相关改动会回滚。论文还提到,有些局部改动虽然单独看有取舍,例如降低深度但略增面积,也可能因为与其他模块有协同潜力而被条件保留。
六、实验结果说明了什么
论文的实验设置相当重。所有实验运行在 87 个 AMD EPYC CPU 节点组成的分布式集群上,每轮同时跑 benchmark、8 种综合 flow 和完整 CEC。评估使用 ASAP7 7nm library,覆盖逻辑优化、technology mapping、buffering、gate sizing 和静态时序分析。benchmark 包括 ISCAS’85、ISCAS’89、ITC’99、EPFL、VTR DSP,以及一组 arithmetic blocks。
最核心的数据来自 Table 2。这里的 QoR 被归一化到一个集成基线:Vanilla FlowTune + Vanilla AIG synthesis / orchestration + Vanilla Map,数值为 1.000,越低越好。论文还列出 Vanilla ABC 为 1.21,说明这个集成基线本身已经比原始 ABC 更强。
单独演化一个子系统时,收益是存在的,但并不夸张。Evo FlowTune 单独达到 0.962,Evo Orch 达到 0.957,Evo Map 达到 0.988。两个子系统联合时,结果进一步下降:Evo FlowTune + Evo Orch 为 0.924,Evo FlowTune + Evo Map 为 0.939,Evo Orch + Evo Map 为 0.942。最好结果来自三个子系统全部演化,也就是 All Evo,QoR 为 0.917,相对集成基线约有 8.3% 的整体改善。

图 3 不同子系统演化组合的 QoR 消融结果,数值越低越好
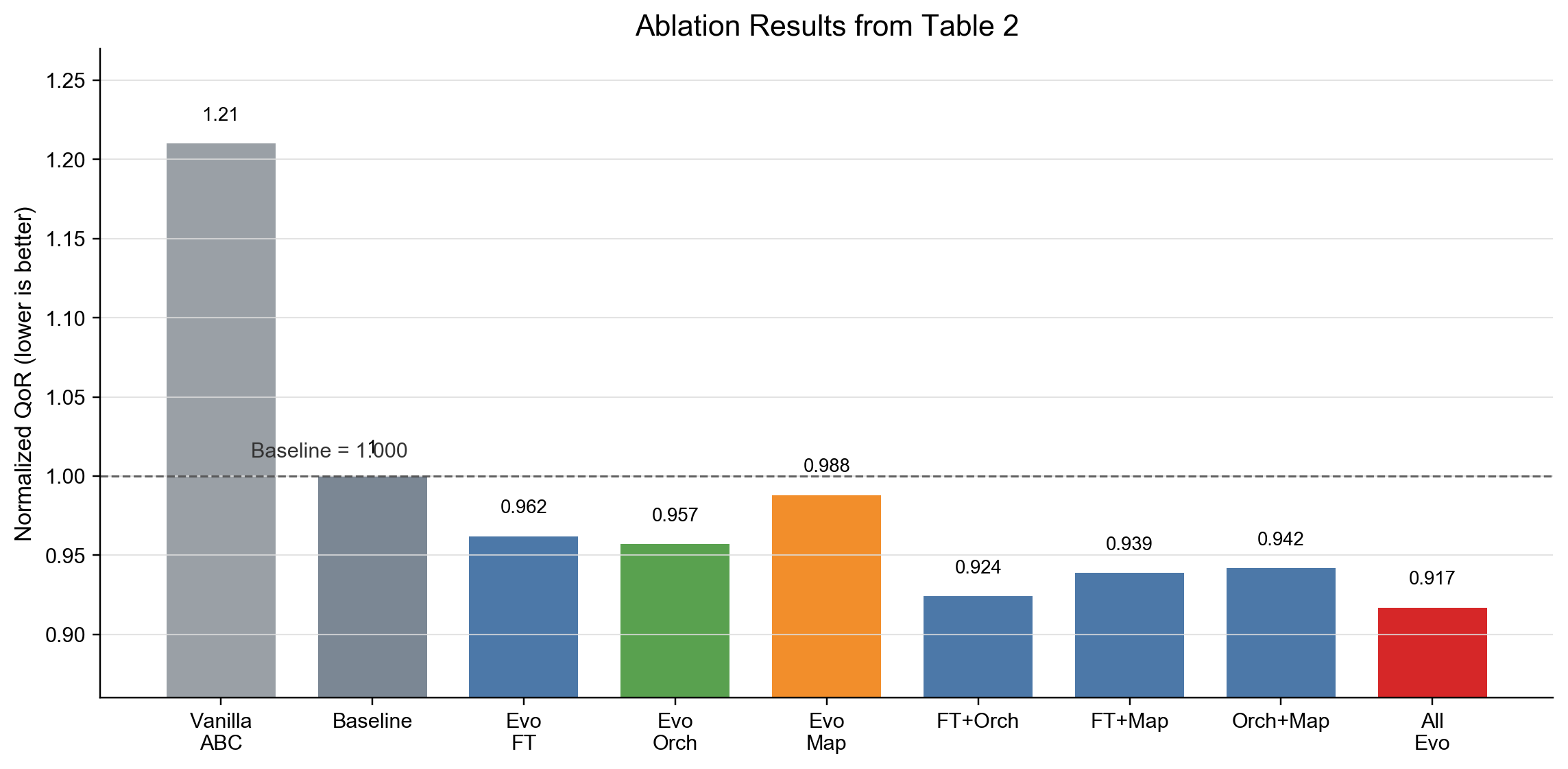
图 4 将 Table 2 重画为柱状图:All Evo 组合取得最低归一化 QoR
论文还给出了更细的结果描述。完全演化系统在所有 benchmark suite 上改善了静态时序和 area-delay product;worst negative slack 相对 vanilla integrated baseline 平均改善约 8% 到 9%,部分 EPFL arithmetic circuits 的改善在 12% 到 15% 之间;area-delay product 的下降约为 8.3%,与 Table 2 中 0.917 的归一化值一致。中间结构指标也支持这个趋势:arithmetic-heavy designs 上的 AIG node counts 下降约 3% 到 8%,post-mapping depth 由于 mapping agent 引入深度感知启发式下降约 4% 到 6%。
这些数字的意义不在于“某个智能体赢了”,而在于协同演化确实比单点演化更有效。FlowTune Agent 改善上游结构简化,Orchestrate / AIG 方向减少中间逻辑冗余和深度,Mapping Agent 通过深度敏感的 tie-breaking 缓解映射后延迟。多个层次的改动叠加,才形成了最终较好的 end-to-end flow。
七、成本与边界:自动演化并不等于免费创造
这篇论文比较克制的一点,是它没有只讲结果,也报告了计算和 token 成本。论文 4.2 节提到,总 token 中 68% 用在初始 ABC 代码库画像,11% 用在外部代码库画像,真正用于演化循环本身的部分是 21%。也就是说,对百万行级代码库来说,前期理解项目结构和建立上下文,是最昂贵的环节。
在 87 个 CPU 节点并行的情况下,每个完整迭代,包括所有 benchmark、8 种 flow 和完整 CEC,大约需要 2 到 3 小时。每个演化周期的 token 成本约为 60 到 80 美元,取决于编码智能体需要多少修复。初始化代码画像阶段约花费 1400 美元,整套系统 token 成本约为 2400 美元。论文还提到,生成内容中约 45% 是 C 源代码,总计 87,749 行,其余是 Markdown、bash、Python 和日志。
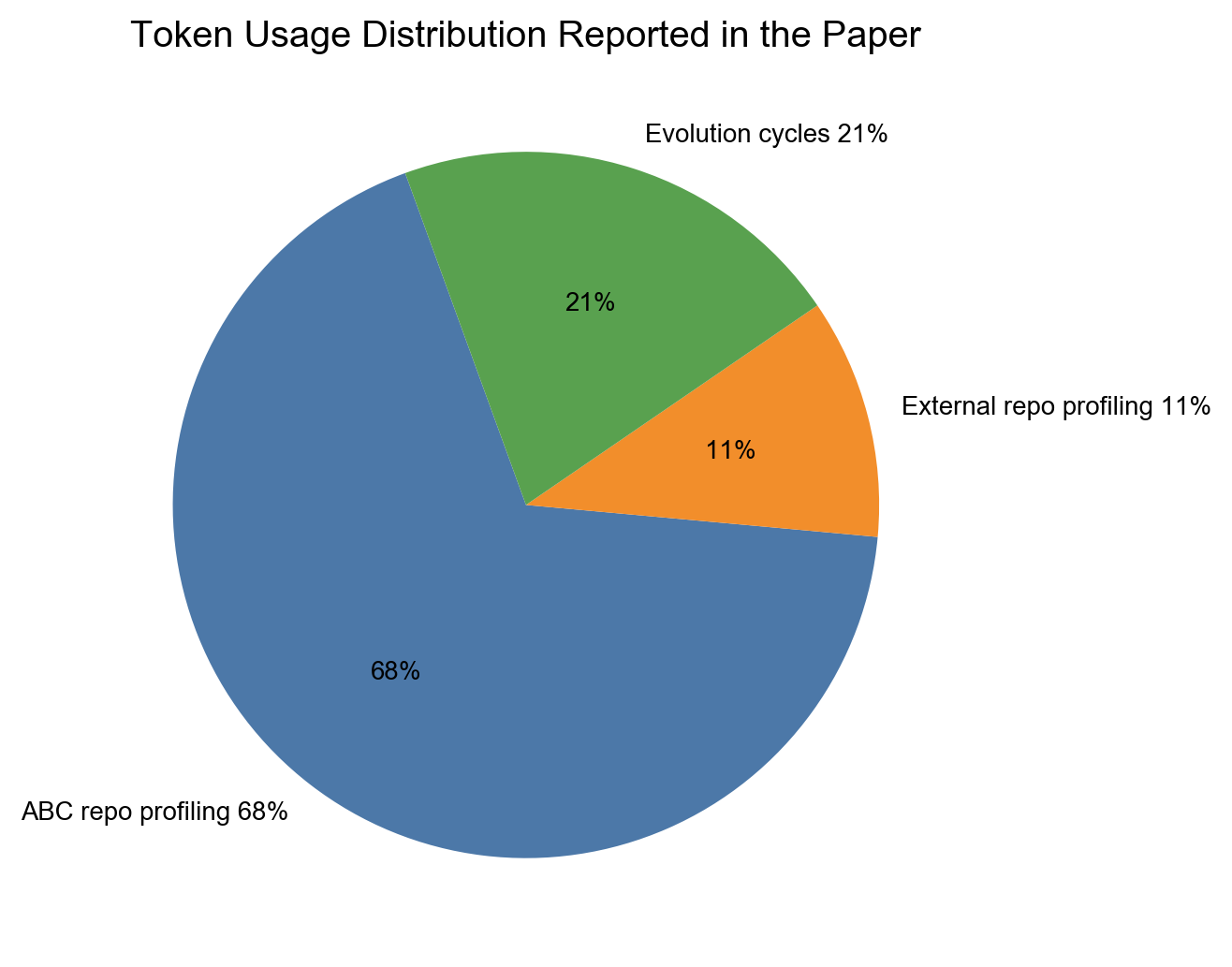
图 5 论文报告的 token 使用比例,初始化代码库画像阶段占主要成本
这些成本提醒我们,自进化系统不是一个轻量按钮。它需要足够强的自动化基础设施,需要分布式评估资源,也需要形式化正确性护栏。没有这些条件,智能体很容易把大量 token 花在无法编译、无法验证或没有实际收益的改动上。论文中的 CEC 机制能在很大程度上减少浪费,因为错误版本不会继续进入昂贵的 QoR 评估。
论文也没有把 LLM Agent 描述成无所不能。作者观察到,智能体更擅长沿着已有结构改进,例如调整阈值、增强 depth-aware scoring、加入条件启发式。当它尝试在缺少现有不变量支撑的情况下引入全新算法结构时,失败率会更高,常见问题包括编译错误、segmentation fault 或细微正确性违规。
八、代码质量:像 ABC 的代码,才可能进入 ABC
论文中还有一个值得注意的观察:智能体生成的代码会逐渐贴近 ABC 的原生风格。Figure 2 展示了第 7 轮生成的 abcFlowTune7.c 片段。作者指出,虽然智能体在初始化阶段接触过多个外部研究仓库,但最终补丁在头部格式、命名、注释结构、宏组织和 Abc_Print 用法上,都接近手写 ABC 组件。
这对大型工具尤其重要。工程代码不仅要“能跑”,还要能放进已有系统中被维护。对于 ABC 这样的工具,风格、命名、构建规则和命令接口并不是表面问题,而是降低集成成本、减少长期维护风险的一部分。论文的结果说明,结构化教程和仓库画像不仅帮助智能体理解算法,也帮助它学习工程约定。

图 6 第 7 轮自动生成的 abcFlowTune7.c 片段,展示代码风格与 ABC 的贴合
九、这项工作的意义
从更大的角度看,这篇论文并不是在宣称 EDA 专家可以被替代。恰恰相反,论文最后强调,当前阶段的智能体只有在充分领域知识引导下才表现较好。ABC 社区几十年的算法、代码和工具积累,是这套系统能够工作的基础。
它更像是在提出一种新的 EDA 工具开发模式:把专家知识、开源代码、结构化教程、形式化验证和大规模评估连成闭环,让智能体在闭环中承担高频、细粒度、可回滚的代码实验。人类仍然定义目标、提供知识边界和验证标准;智能体负责在巨大启发式空间中持续探索。
这种模式对 EDA 很有启发。很多工具优化并不一定来自一条全新理论,而可能来自大量小改动的组合:一个更合适的 cut pruning 条件,一组更稳的 flow stopping criteria,一个更合理的 depth-aware tie-breaking。过去这些组合很难靠人力穷举,未来或许可以交给带有正确性护栏的智能体系统持续试探。
当然,这项工作还不能直接外推到所有 EDA 领域。逻辑综合有 CEC 这样的强正确性检查工具,其他领域的验证目标、成本函数和反馈周期可能完全不同。布局布线、物理设计、时序优化等任务是否也能用同样方式自进化,还需要更具体的系统设计和实验证据。
结语
让 EDA 工具自己进化,听起来很像未来式。但这篇论文把问题落到了一个具体场景:完整 ABC 代码库、明确子系统边界、可编译源码修改、形式化等价检查、多 benchmark QoR 评估,以及可量化的成本记录。它没有把 AI 描述成神奇按钮,而是把智能体放进严肃的工程闭环里。
这也许是它最值得关注的地方。未来的 EDA 工具开发,可能不会只依赖专家手工写下一条条启发式,也不会完全交给无约束的大模型。更现实的方向,是让人类知识变成结构化规则和验证流程,让智能体在其中不断试错、积累和修正。对复杂工程系统来说,这比“AI 自动发明一切”的叙事更克制,也更接近可落地的技术路径。
十、如何理解这组结果
这组结果最好不要被理解成“智能体已经能独立发明全新的 EDA 理论”。论文展示的是另一种更具体的能力:在已有工具、已有算法和明确验证规则之上,智能体可以承担大量细粒度工程探索,并把有收益的改动通过自动评估积累下来。它的价值更接近“把专家经验组织成可执行的搜索空间”,而不是凭空替代专家。
从结果看,单独演化某个模块往往只能得到有限改善,三类子系统共同演化才出现最好的 0.917。这说明逻辑综合的 QoR 很少由单个环节决定。上游 flow 选择会改变网络结构,中间 AIG 优化会影响逻辑冗余和深度,后端 mapping 又会把这些结构转化为实际面积和延迟。任何一处孤立改进,都可能被后续流程抵消;多层协同,才更接近真实工具链中的优化方式。
这也是论文对公众号读者最有启发的一点:AI 进入复杂工程系统时,真正关键的不是一次生成多漂亮的代码,而是能不能放进一个长期运行的反馈系统。这个系统要知道哪里能改、哪里不能改;要能在错误时拒绝,在变好时保留;还要把失败经验变成下一轮规则。只有这样,大模型的代码能力才可能从“单次输出”变成“持续工程迭代”。
图片来源说明
文中部分图片整理自原论文,仅用于论文解读与学术交流。其中图 1、图 2、图 3、图 6 为论文原图或原表裁剪;图 4 和图 5 为根据论文数据整理重画。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)