(AAAI-2026)KnowLP:GraphRAG 诱导双知识结构图,实现个性化学习路径推荐
本文介绍的 KnowLP 是一个面向个性化学习路径推荐的双知识结构框架。EDU-GraphRAG 自动构建知识结构图。通过 TextGrad 生成高质量知识点解释,再用 GraphRAG 构建先修关系和相似关系,降低了对人工知识图谱的依赖。引入相似关系缓解学习阻塞。传统方法主要依赖先修图,而 KnowLP 将相似知识点作为 blocked learning 场景下的 fallback 关系,帮助学
主要内容: 本文聚焦个性化学习路径推荐(Learning Path Recommendation, LPR)中的两个核心痛点:一是知识点之间的先修关系难以获取,依赖专家标注成本高;二是传统方法大多只沿着先修链条推荐,一旦学生在某个易混淆知识点上卡住,就会出现后续学习被阻断的现象。论文提出 KnowLP 框架,用 EDU-GraphRAG 自动构建知识点之间的先修关系图和相似关系图,再通过 DLRL(Discrimination Learning-driven Reinforcement Learning) 在学习路径生成过程中动态切换“先修学习”和“相似概念辨别学习”,从而缓解 blocked learning,提高长路径推荐效果。
论文名称: GraphRAG-Induced Dual Knowledge Structure Graphs for Personalized Learning Path Recommendation
会议: AAAI 2026
论文链接: arXiv 2506.22303
代码链接: https://github.com/chanllon/KnowLP
关键词: 个性化学习路径推荐、GraphRAG、知识结构图、强化学习、知识追踪、辨别学习
一、引言
1.1 个性化学习路径推荐:在线教育中的核心问题
在在线教育平台中,学生面对的学习资源通常非常庞大:知识点、视频、练习题、课程章节之间既存在先后依赖,也存在难度差异和语义相似性。学习路径推荐(LPR) 的目标,就是根据学生当前的知识状态和学习目标,为其推荐一条有顺序、有针对性的学习资源序列。
简单来说,LPR 不是只回答“下一题推荐什么”,而是要回答:
为了让学生掌握目标知识点,系统应该按什么顺序推荐一串练习或知识点?
这类任务的难点在于,它既要考虑教育认知规律,也要考虑学生个体差异。例如,一个学生想学习“内存重定位”,可能需要先掌握“分段”“分页”“地址映射”等前置概念;但如果学生把“逻辑地址”和“虚拟地址”混淆了,单纯沿着先修链条继续推荐,很可能并不能解决真正的问题。
1.2 传统方法的两大痛点:先修关系难获取 + 学习阻塞
现有很多学习路径推荐方法都会依赖知识点先修关系图。这种思路很符合教育直觉:先学基础知识,再学复杂知识,路径更容易解释,也更符合人类认知过程。
但论文指出,这类方法存在两个明显问题:
-
先修关系图难以获得。
高质量的知识点先修关系往往依赖专家人工标注,不同数据集之间知识点体系也不统一。因此,一旦数据集中没有现成的知识结构图,很多基于先修图的方法就很难直接应用。 -
只依赖先修关系容易造成 blocked learning。
学生在学习某个知识点时,失败原因不一定是“前置知识没学会”,也可能是被某些相似概念混淆了。此时如果系统仍然只沿着先修边往后走,学生可能会在一个概念上反复卡住,后续路径也会受到影响。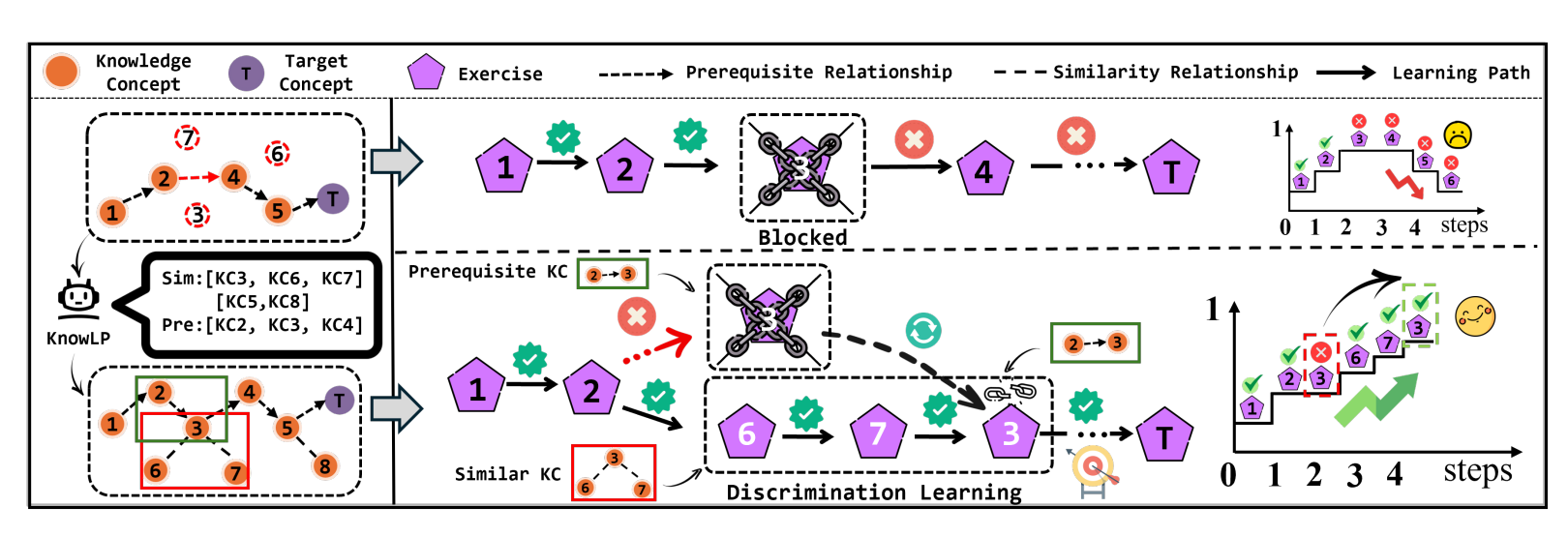
图1 传统先修路径方法与 KnowLP 的对比:上半部分展示 blocked learning,下半部分展示 KnowLP 通过相似知识点进行辨别学习。
上图很好地说明了论文的核心动机:传统方法主要沿着先修关系前进,一旦学生在某个知识点上受相似概念干扰,学习路径就容易中断;而 KnowLP 会引入相似知识点,帮助学生进行辨别学习(discrimination learning),先把容易混淆的概念区分清楚,再继续向目标知识点推进。
1.3 KnowLP 的破局思路:双知识结构图 + 强化学习路径生成
为了同时解决“图难构建”和“学习阻塞”两个问题,论文提出了 KnowLP(GraphRAG-Induced Dual Knowledge Structure Graphs for Personalized Learning Path Recommendation)。
它的核心思想可以概括为两句话:
- 用 EDU-GraphRAG 从知识点名称和文本解释中自动生成知识结构图,降低对人工先修图的依赖;
- 用 先修关系图 + 相似关系图 共同指导路径生成,当先修学习推进受阻时,切换到相似概念辨别学习。
这使得 KnowLP 不只是一个“沿着知识图谱找路径”的模型,而是一个能够根据学生学习状态动态调整推荐策略的个性化学习路径推荐框架。
二、模型架构:从知识结构生成到学习路径推荐
2.1 整体框架:两大模块协同工作
KnowLP 的整体框架可以分成两个主要部分:
-
知识结构图生成模块:
先利用 TextGrad 生成更准确、更具区分度的知识点解释,再通过 EDU-GraphRAG 自动构建知识点之间的先修关系图和相似关系图。 -
学习路径生成模块:
基于生成的双知识结构图,使用 DLRL 模块模拟学生学习过程,并通过三个智能体协同生成个性化学习路径。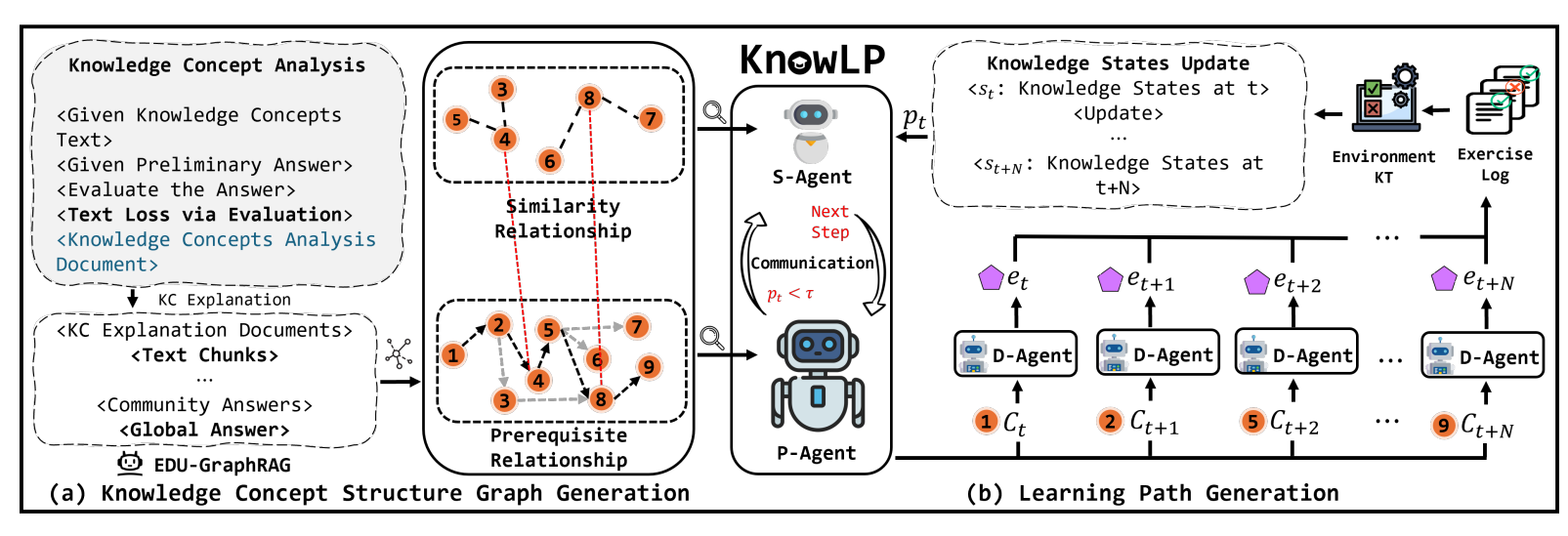
图2 KnowLP 整体框架:左侧为知识结构图生成模块,右侧为学习路径生成模块。
从图中可以看到,左侧负责“生成图”,右侧负责“用图推荐路径”。这也是本文最关键的设计:先把知识点关系结构化,再让推荐模型在结构约束下进行序列决策。
2.2 知识点解释生成:用 TextGrad 提升概念描述质量
EDU-GraphRAG 的输入并不是原始题目数据,而是知识点的文本解释。因此,知识点解释质量会直接影响后续图结构生成效果。
论文采用了 TextGrad 的思想,对知识点解释进行“生成—评价—修改”的迭代优化:
- 主 LLM 根据知识点名称生成初始解释;
- 辅助 LLM 对解释进行评价,指出不准确、不清晰或容易混淆的地方;
- 主 LLM 根据反馈重写解释;
- 重复上述过程,直到解释质量达到要求或达到最大迭代次数。
这一步的价值在于:很多知识点名称本身很短,如果直接让 LLM 判断知识点之间的关系,很容易产生模糊甚至错误的推断。通过 TextGrad 先把知识点解释补全,能够让后续 GraphRAG 有更可靠的文本基础。
论文中的案例也很直观:对于 “logical address” 和 “virtual address” 这两个容易混淆的概念,普通 LLM 可能会直接把二者解释成同义概念;加入 TextGrad 后,模型能够更准确地区分二者的语义差异。

图5 TextGrad 优化前后对知识点解释的影响:优化后能够更好地区分 logical address 与 virtual address。
2.3 EDU-GraphRAG:自动构建先修图与相似图
在得到高质量知识点解释后,KnowLP 使用 EDU-GraphRAG 构建知识结构图。其流程大致如下:
- 将所有知识点解释拼接成一个统一文档;
- 按 chunk size 对文档进行切分;
- 使用 LLM 从每个 chunk 中抽取实体和关系;
- 将局部图合并成全局知识图;
- 在查询阶段,让 LLM 基于结构化图索引生成目标知识结构图。
最终得到的图可以表示为:
G_A = (C, P, S)
其中:
C表示知识点集合;P表示知识点之间的先修关系;S表示知识点之间的相似关系。
这里最值得关注的是:论文不再只生成先修关系,而是同时生成相似关系。这相当于为学习路径推荐提供了两套结构视角:
- 先修图: 回答“学习目标之前应该先学什么”;
- 相似图: 回答“当前知识点容易和哪些知识点混淆”。
2.4 DLRL:用辨别学习驱动强化学习推荐路径
有了双知识结构图之后,KnowLP 使用 DLRL(Discrimination Learning-driven Reinforcement Learning) 进行路径生成。
DLRL 的核心不是简单地把两个图拼起来,而是通过三个智能体进行协作:
-
Prerequisite Agent(P-Agent)
负责沿着先修关系选择下一个知识点,保证路径符合由浅入深的认知顺序。 -
Similarity Agent(S-Agent)
当学生在某个知识点上的掌握提升不足时,说明可能出现 blocked learning,此时 S-Agent 会被激活,从相似关系图中选择容易混淆的知识点,帮助学生进行辨别学习。 -
Difficulty Agent(D-Agent)
在确定推荐知识点后,进一步选择难度合适的练习题,避免题目太简单导致收益不足,也避免题目太难导致挫败感。
这三个智能体的分工非常清晰:P-Agent 管学习顺序,S-Agent 管概念混淆,D-Agent 管题目难度。
2.5 智能体切换机制:什么时候引入相似知识点?
KnowLP 的一个关键细节是:相似知识点并不是一直加入路径,而是在先修学习推进不顺利时作为“备用策略”引入。
论文通过学生知识状态的变化来判断是否发生阻塞。如果某一步学习后,学生对当前知识点的掌握提升低于阈值 τ,说明继续沿着先修路径可能效果不好,于是模型切换到 S-Agent,引入相似知识点进行辨别学习。
这个机制非常符合真实教学场景:
学生不是永远需要补前置知识,有时候更需要把几个相似概念放在一起对比,搞清楚它们到底差在哪里。
这也是 KnowLP 相比传统先修路径推荐方法的重要创新点。
2.6 难度匹配:让推荐题目贴合学生当前水平
论文还引入了知识追踪模型 DIMKT 来建模学生动态知识状态。与普通知识追踪不同,DIMKT 会考虑题目难度对学生认知状态变化的影响。
在推荐练习时,D-Agent 会选择与学生当前掌握水平最接近的题目。其思想可以理解为:
选择 |题目难度 - 学生掌握水平| 最小的练习
这样做的好处是,推荐路径不只是知识点顺序合理,具体落到练习题时也能更贴合学生当前能力。
三、实验结果与分析
3.1 实验设置:三个典型教育数据集
论文在三个公开教育数据集上进行了实验:
| 数据集 | 知识点数量 | 学生数量 | 交互记录数量 | 特点 |
|---|---|---|---|---|
| Junyi | 835 | 525,061 | 21,460,249 | 有较完整的先修关系图 |
| MOOCCubeX | 443 | 629 | 17,447 | 先修图不完整 |
| ASSISTments2009 | 167 | 4,217 | 346,860 | 缺少显式知识结构图 |
这三个数据集的设置很有代表性:有的图较完整,有的图不完整,有的完全没有图。正好可以验证 EDU-GraphRAG 是否真的能提升模型在不同教育数据集上的适用性。
对比方法包括 KNN、GRU4Rec、Actor-Critic、RL-Tutor、CSEAL、SRC、GEHRL、DLPR 等经典或较新的学习路径推荐方法。
3.2 整体性能:KnowLP 在所有设置下取得最优
论文在不同推荐步长(5、10、15、20)下比较了各方法的学习效果。结果显示,KnowLP 在 Junyi、MOOCCubeX 和 ASSISTments2009 三个数据集上都取得了最优表现。
下面整理部分关键结果:
| 数据集 | 步长 | 最强基线 | KnowLP |
|---|---|---|---|
| Junyi | 5 | 0.2086 | 0.2406 |
| Junyi | 10 | 0.2293 | 0.2431 |
| Junyi | 15 | 0.2181 | 0.2295 |
| Junyi | 20 | 0.2358 | 0.2758 |
| MCX | 5 | 0.2686 | 0.3194 |
| MCX | 10 | 0.2203 | 0.3508 |
| MCX | 15 | 0.2933 | 0.3205 |
| MCX | 20 | 0.2781 | 0.3589 |
| ASS09 | 5 | 0.1245 | 0.1268 |
| ASS09 | 10 | 0.1024 | 0.1174 |
| ASS09 | 15 | 0.1273 | 0.1281 |
| ASS09 | 20 | 0.1434 | 0.1455 |
可以看到,KnowLP 的优势在 MCX 数据集上尤其明显。这个数据集原始知识结构图不完整,说明 EDU-GraphRAG 自动生成知识结构图确实能够缓解图结构缺失的问题。
更有意思的是,很多基线方法在路径变长后性能会下降,而 KnowLP 在 20 步推荐时仍然表现较好。这说明相似关系引入后,模型更适合生成长学习路径,不容易因为某个知识点卡住而导致整条路径失效。
3.3 消融实验:相似关系不是锦上添花,而是关键组件
为了验证 S-Agent 的作用,论文移除了相似智能体,只保留先修关系推荐。结果显示,去掉相似关系后,三个数据集上的性能都明显下降。
| 数据集/设置 | 5步 | 10步 | 15步 | 20步 |
|---|---|---|---|---|
| Junyi w/o S | 0.1932 | 0.2051 | 0.1851 | 0.2232 |
| Junyi w S | 0.2406 | 0.2431 | 0.2295 | 0.2758 |
| MCX w/o S | 0.2148 | 0.1928 | 0.2258 | 0.1517 |
| MCX w S | 0.3194 | 0.3508 | 0.3205 | 0.3589 |
| ASS09 w/o S | 0.0737 | 0.1007 | 0.1190 | 0.1264 |
| ASS09 w S | 0.1268 | 0.1174 | 0.1281 | 0.1455 |
这组实验说明:相似知识点并不是一个简单的补充特征,而是缓解 blocked learning 的核心机制。尤其在长路径推荐中,S-Agent 能帮助模型绕开“某个概念学不动,后面全卡住”的问题。
3.4 知识结构图生成:EDU-GraphRAG 能补全缺失关系
论文还对生成的知识结构图进行了可视化比较。

图3 原始知识结构图与 KnowLP 生成图对比:Junyi 与 MCX 数据集上的结构覆盖和关系数量对比。
在 Junyi 数据集中,KnowLP 生成的先修关系数量更多,能够捕捉到更复杂的知识点依赖;在 MCX 数据集中,原始图只覆盖了 46 个知识点,而 KnowLP 生成图覆盖了全部 443 个知识点,显著增强了知识结构覆盖范围。
论文进一步比较了使用原始先修图和使用 KnowLP 生成图的推荐效果。
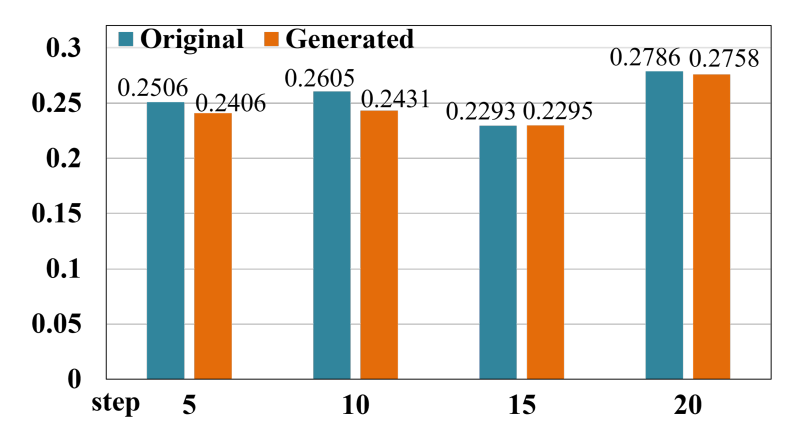
图4 使用原始图与 KnowLP 生成图时的推荐效果对比。
从结果看,KnowLP 生成图的效果接近人工构建的原始图。这一点非常重要:如果自动生成的图能达到接近专家图的效果,那么学习路径推荐方法就能更容易迁移到没有高质量知识结构标注的新数据集。
3.5 可解释性:不仅推荐路径,还能解释为什么这样推荐
EDU-GraphRAG 在构建图的过程中会生成社区摘要、实体关系和相关 claim,因此 KnowLP 不仅能给出学习路径,还能对推荐顺序进行解释。

图6 学习路径解释示例:EDU-GraphRAG 能够给出推荐路径中各知识点的顺序依据。
例如,对于目标知识点 “Relocation”,系统推荐路径中包含 “Segmentation、Paging、Addressing、System Control、External Fragmentation” 等知识点。EDU-GraphRAG 可以解释这些知识点为什么应该以这样的顺序出现,例如先学习 Segmentation 有助于理解内存分段管理,再学习 Paging 可以进一步理解地址映射和内存管理机制。
这类解释对教育推荐非常关键,因为学习路径推荐不是普通商品推荐。学生和教师往往都需要知道:为什么我应该先学这个,再学那个?
3.6 模拟实验与运行效率
由于真实教育数据通常是静态日志,无法直接验证学生在新推荐路径下的动态学习过程,论文使用基于知识演化的模拟器 KES-Junyi 进行实验。结果显示,KnowLP 在模拟环境中也优于 SRC、GEHRL 和 DLPR。
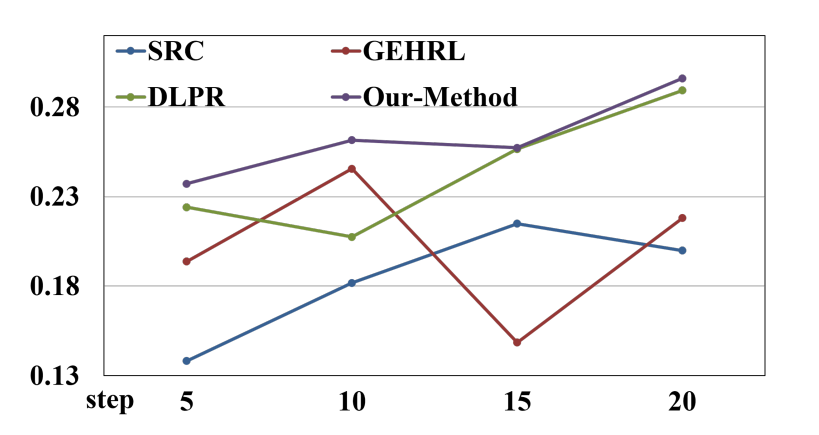
图7 模拟实验结果:KnowLP 在动态模拟学习场景下相比多种基线方法表现更优。
在效率方面,EDU-GraphRAG 构图耗时在分钟级;DLRL 模块训练耗时略高于 DLPR,但论文认为这一额外成本能够被性能提升所抵消。
四、总结与展望
4.1 工作总结
本文介绍的 KnowLP 是一个面向个性化学习路径推荐的双知识结构框架。它的核心创新可以概括为三点:
-
EDU-GraphRAG 自动构建知识结构图。
通过 TextGrad 生成高质量知识点解释,再用 GraphRAG 构建先修关系和相似关系,降低了对人工知识图谱的依赖。 -
引入相似关系缓解学习阻塞。
传统方法主要依赖先修图,而 KnowLP 将相似知识点作为 blocked learning 场景下的 fallback 关系,帮助学生通过辨别学习突破卡点。 -
多智能体强化学习生成路径。
P-Agent、S-Agent 和 D-Agent 分别负责先修顺序、相似概念辨别和题目难度匹配,使推荐路径既符合知识结构,又贴合学生状态。
整体来看,KnowLP 的价值不只是“性能提升”,更重要的是它提出了一种新的学习路径推荐视角:学习路径不应该只是一条先修链,而应该是一条能够根据学生卡点动态调整的认知推进路径。
4.2 对后续研究的启发
这篇论文对个性化学习路径推荐方向有几个值得继续探索的点:
-
LLM + GraphRAG 可以缓解教育知识结构稀缺问题。
很多教育数据集只有题目、知识点名称和答题日志,没有完整知识图谱。KnowLP 说明,利用 LLM 生成解释,再通过 GraphRAG 构建结构图,是一个值得深入研究的方向。 -
相似关系可以成为学习路径推荐的重要结构。
过去很多方法把“先修关系”作为核心结构,但学生学习失败有时不是因为没学前置知识,而是因为概念混淆。因此,相似关系、易错关系、混淆关系等都可能成为未来 LPR 的重要建模对象。 -
推荐系统需要更强的教育可解释性。
教育场景中,推荐结果不能只是一个黑盒路径。教师和学生都希望知道路径背后的知识逻辑。GraphRAG 生成的结构化解释,为学习路径推荐的可解释性提供了新的思路。 -
真实在线教育环境中的验证仍然值得加强。
论文虽然使用模拟器验证了动态场景下的效果,但真实学生的学习行为更复杂。后续如果能在真实平台中进行 A/B 测试,会更有说服力。
4.3 可能的不足
虽然 KnowLP 很有启发性,但仍然存在一些值得注意的问题:
-
LLM 生成的关系图仍可能存在噪声。
EDU-GraphRAG 能缓解幻觉问题,但无法完全保证生成的先修关系和相似关系都正确。 -
不同学科中的“相似”定义可能不同。
数学中的相似概念、编程中的相似概念、医学中的相似概念,其混淆机制并不完全一样。如何让相似关系更符合具体学科规律,是后续可以优化的方向。 -
强化学习训练成本较高。
DLRL 的训练时间高于部分基线方法,在大规模平台中部署时,还需要进一步考虑效率和在线更新问题。 -
路径推荐和资源推荐仍可以结合得更紧。
当前框架已经考虑题目难度,但实际教学资源还包括视频、文本、例题、测验等多种类型。未来可以进一步扩展为多资源、多目标的学习路径推荐。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)