MateClaw 的 LLM Wiki 已经不只是 RAG:从源码看它如何把企业知识变成 Agent 可运营的“活知识层”
MateClaw 的 LLM Wiki 不只是普通 RAG,而是面向企业 Agent 的活知识层。它支持结构化页面、来源追踪、语义检索、知识分层、过期标记、pageType 权限和 Wiki Pipeline,让企业知识可读取、可更新、可治理。
最近谈 AI 知识库,大家常用几个词:RAG、GraphRAG、Agentic RAG、Context Engineering、MCP。
这些概念背后其实都在回答同一个问题:
模型本身不可靠,企业知识又一直变化,Agent 到底应该怎样读取、整理、更新和使用知识?
MateClaw 的 LLM Wiki 已经不是“上传资料 + 向量检索”的普通 RAG,而更像一套给 Agent 用的企业知识运行时。
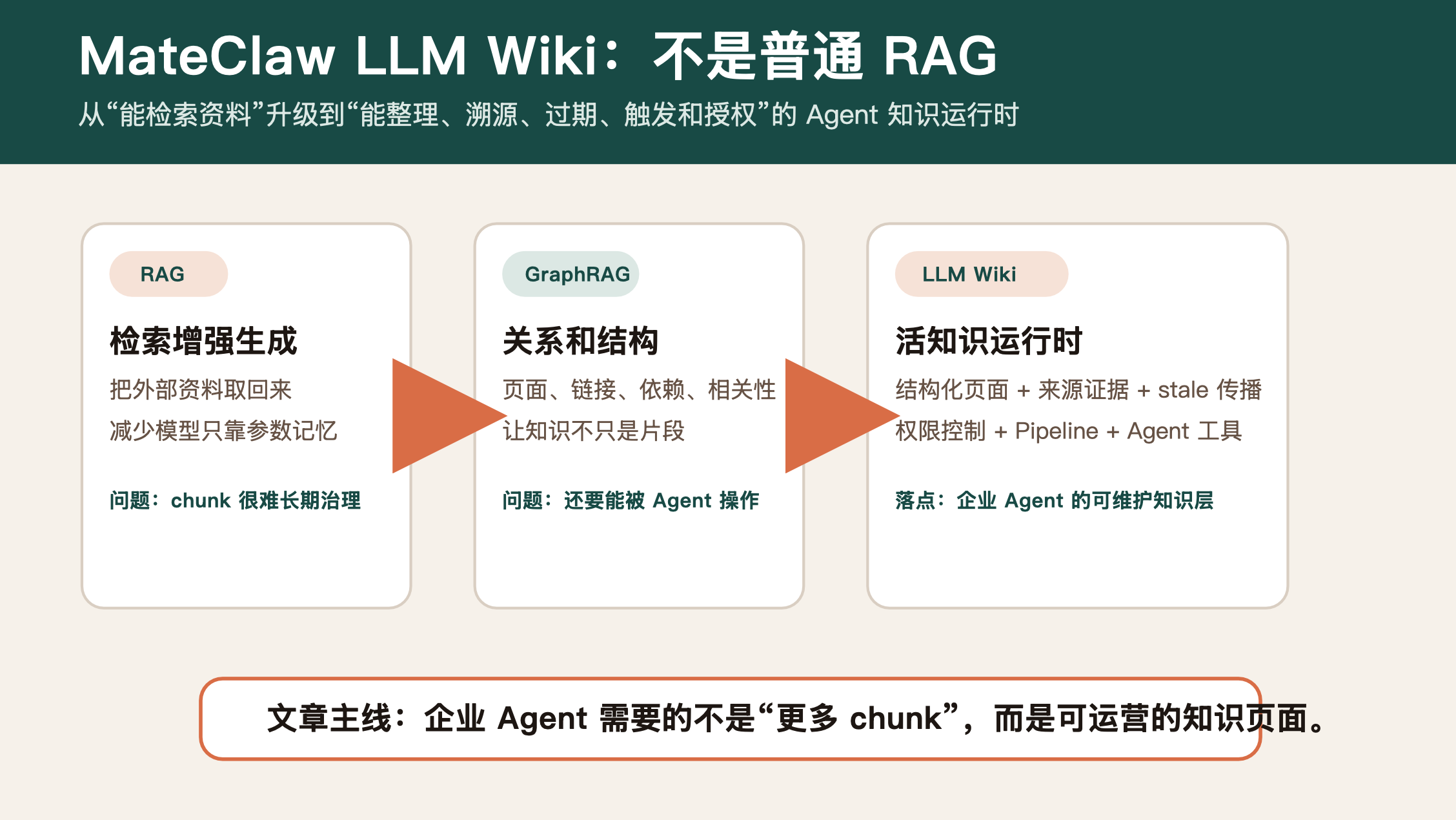
先看主流概念:RAG 解决了什么,又没解决什么
RAG 的经典问题是:大模型参数里存了很多事实,但它很难精确访问、更新和追溯这些知识。Lewis 等人在 2020 年的 RAG 论文里就提到,模型访问和更新知识仍然是问题,因此引入外部非参数记忆,让生成过程结合检索结果。
这套思路非常有用。它解决了“模型只靠记忆胡说”的问题。
但企业真正部署 Agent 时,很快会发现普通 RAG 还不够:
- chunk 能搜到,但不好读;
- 资料有来源,但不一定能追溯到具体页面和片段;
- 文档更新了,旧结论不会自动失效;
- 不同 Agent 看到的知识权限不一样;
- 知识不是一次性问答,而是要持续整理、触发、归档和再加工;
- Agent 不是只“读知识”,它还会“改知识”和“维护知识”。
所以行业里才会出现 GraphRAG、Agentic RAG、Context Engineering 这些概念。
GraphRAG 的重点是把文本抽取、网络分析、LLM 总结和检索放在一起,让数据不只是散落的片段,而是带关系的知识结构。MCP 则强调让 AI 应用连接外部数据源、工具和工作流,让 Agent 能接触真实系统。
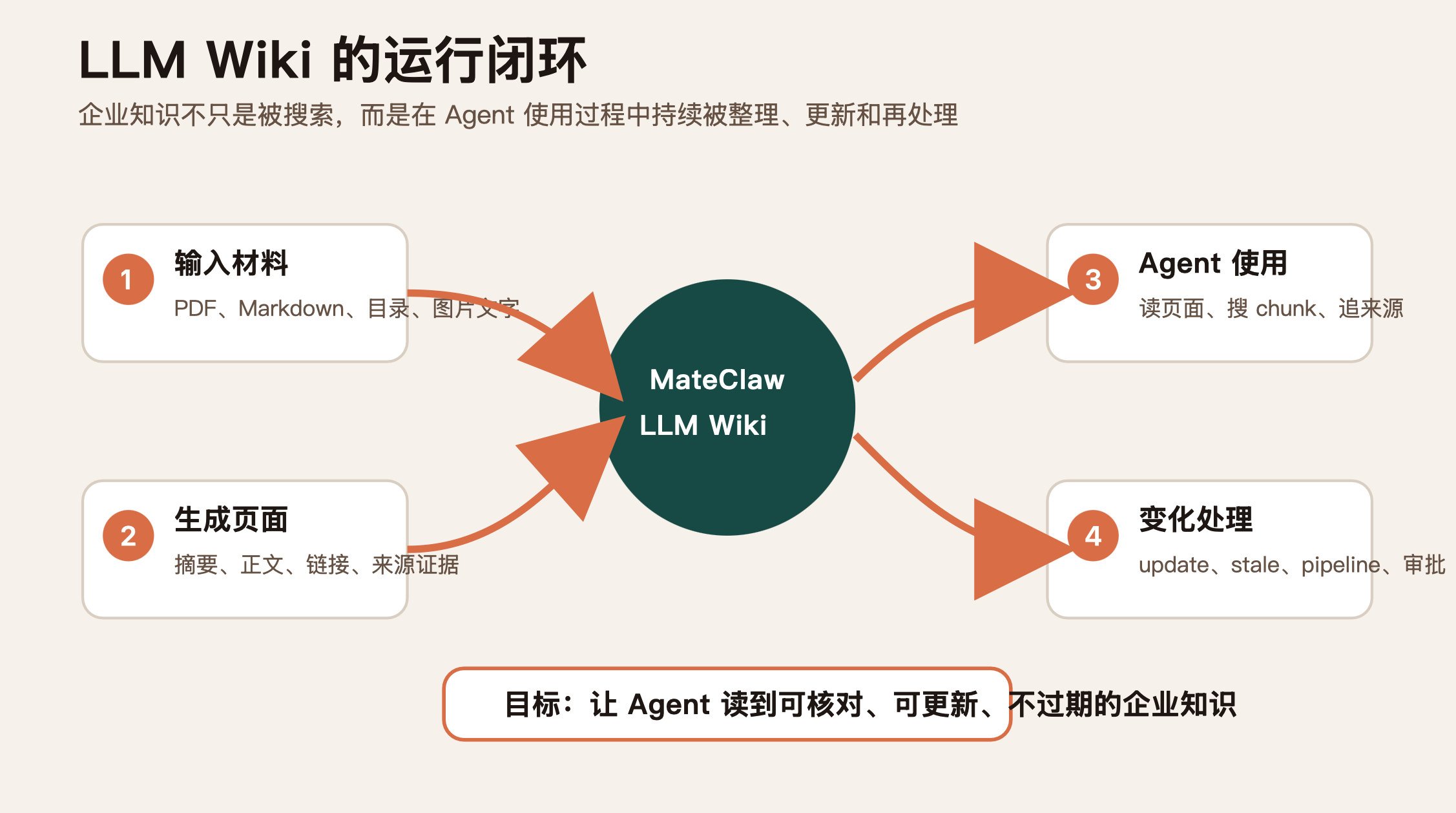
MateClaw 的 LLM Wiki 其实就在这些概念之间找到了一条工程化路线:它不是只做检索,而是把企业知识变成 Agent 可以读、可以追、可以更新、可以触发后续流程的 Wiki。
从源码看 MateClaw LLM Wiki 的核心能力
我把源码里的能力拆成四层。

1. 从原始材料到结构化页面
普通 RAG 的第一步通常是切 chunk、做 embedding、放进向量库。
MateClaw 做得更进一步。
WikiProcessingService 负责把原始材料消化成 Wiki 页面。它不是只保留原文片段,而是通过 route / create / merge 等处理步骤,把材料整理成有标题、有摘要、有正文、有链接的页面。
README 里也明确写到:MateClaw 的 LLM Wiki 会把原始材料消化成结构化页面,页面之间生成 [[链接]],并且能追到原始 chunk。
这个差异很关键。
普通 RAG 更像“资料仓库”;LLM Wiki 更像“可阅读、可维护的知识库”。企业用户不是只想问一次问题,他们还希望看到页面、编辑页面、复盘来源、维护结构。
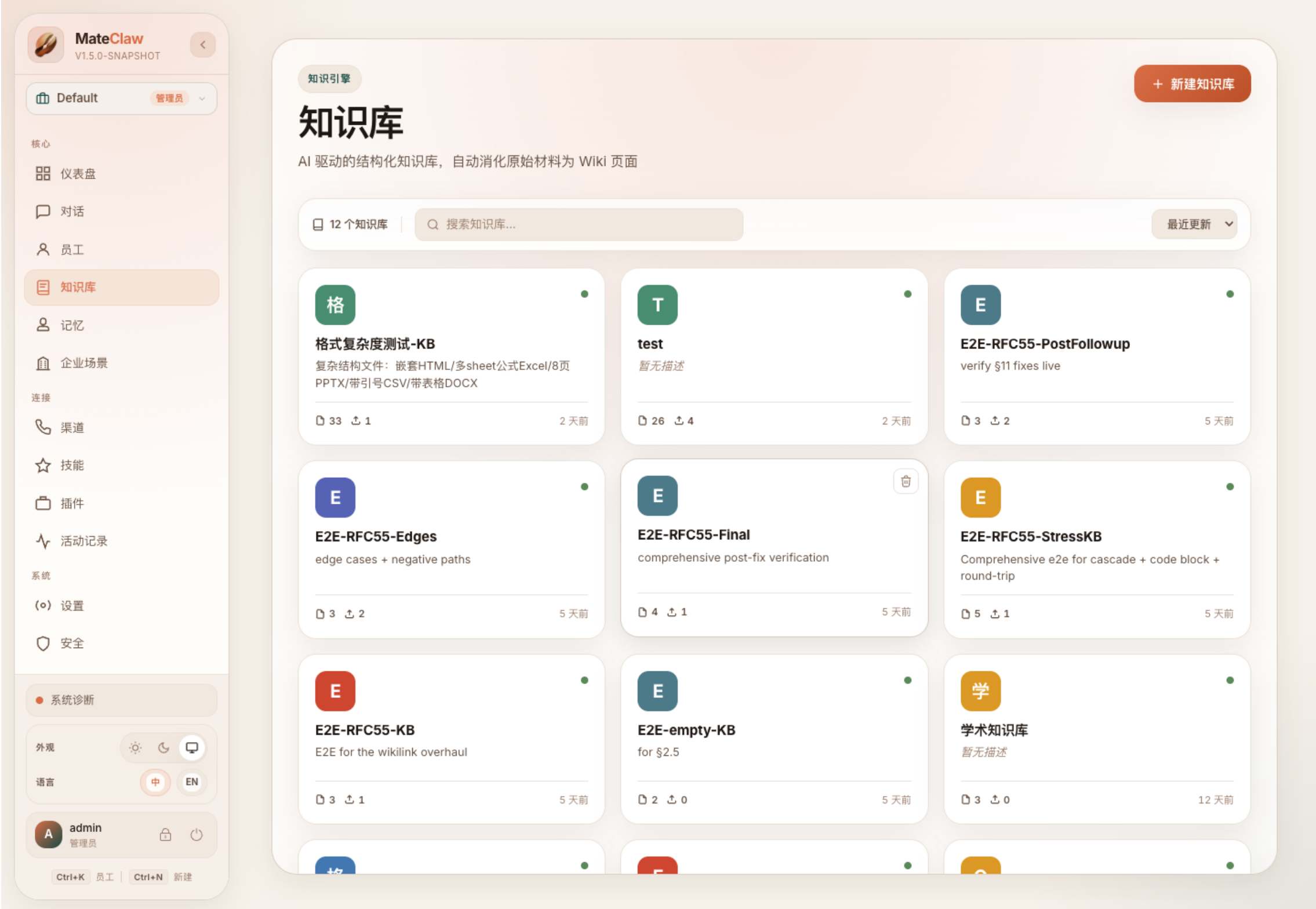
从本地控制台可以看到,Wiki 首页不是一个普通“文件上传页”,而是按知识库组织:每个 KB 有页面数、最近更新、描述和入口。进入某个 KB 后,可以看到页面已经按 pageType 分组展示,例如概念、技术、流程、组织、产品、地点、术语等。
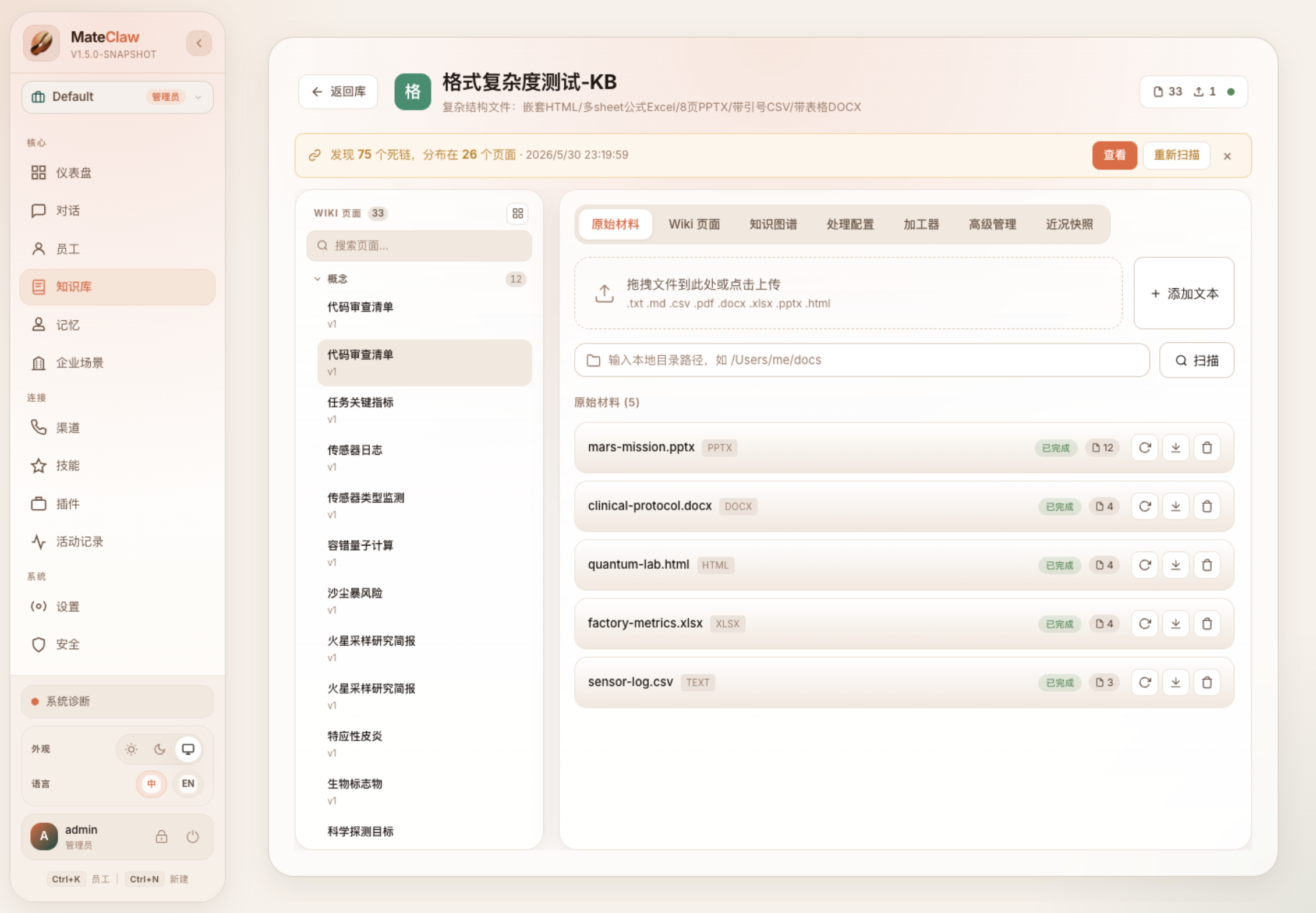
2. 检索不是终点,来源证据才是可信起点
源码里的 WikiTool 提供了很多 Agent 可调用的工具:wiki_read_page、wiki_search_pages、wiki_semantic_search、wiki_compile_page、wiki_trace_source 等。
其中 wiki_semantic_search 会返回 chunkId、rawTitle、metadata 等信息;wiki_trace_source 可以追踪页面来自哪些原始材料。wiki_compile_page 也强调页面只引用 prompt 实际使用到的 evidence chunks,而不是把所有来源粗暴挂上去。
这和企业 Agent 的需求非常一致。
企业里最怕的不是 Agent 不回答,而是它回答得很自信却无法核对。LLM Wiki 的方向是:Agent 不只是“给你一个答案”,还要能告诉你“这个答案从哪里来”。
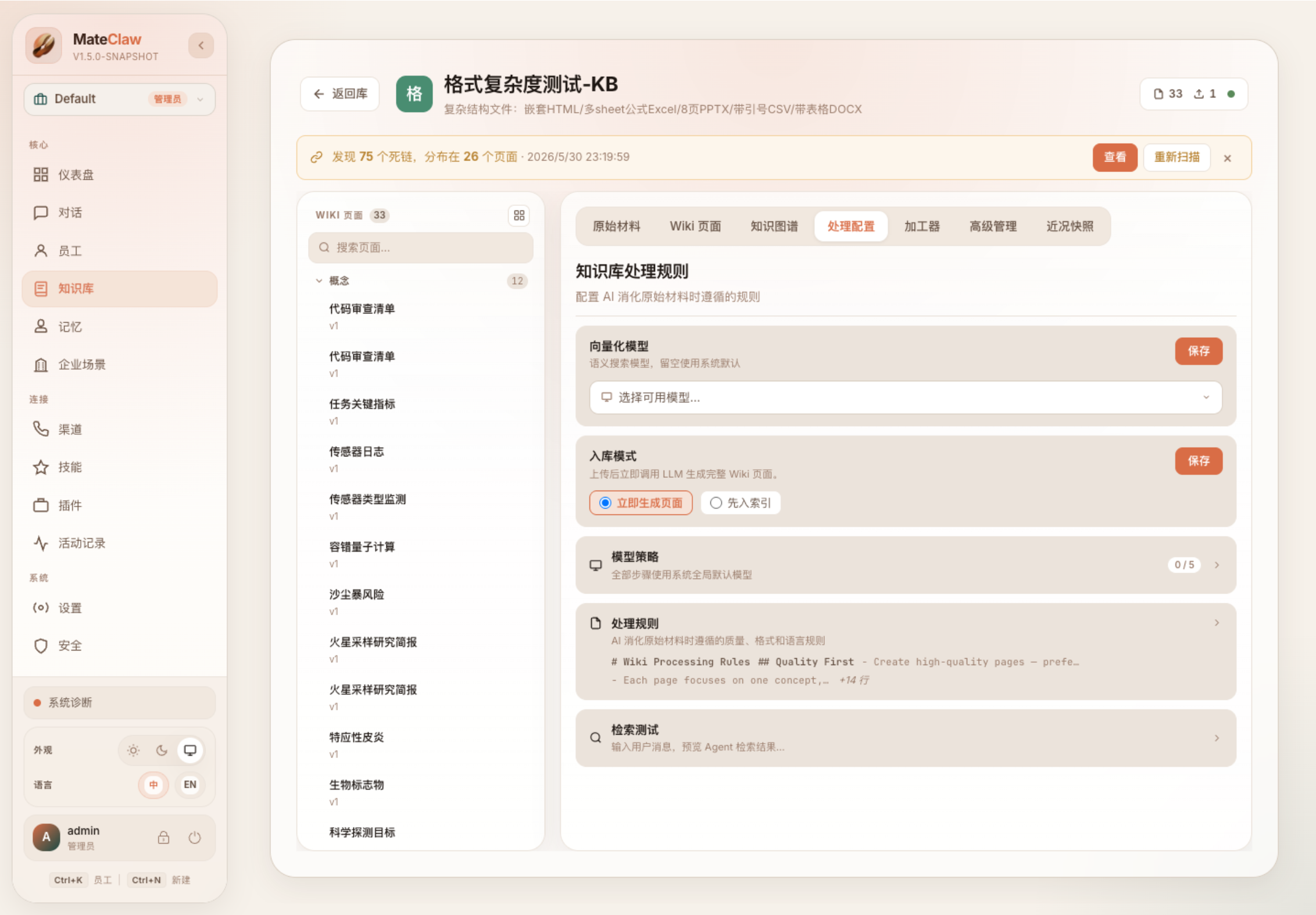
控制台里也能看到“处理配置”和“检索测试”入口。它不是把文档丢进黑盒,而是把入库模式、向量模型、处理规则和检索预览放出来,让管理员能调优知识消化过程。
3. 知识有层级,旧结论会变 stale
MateClaw 的 Wiki 最近新增了很重要的一层:knowledge_layer、depends_on_json、stale、stale_reason_json,以及 mate_wiki_page_dependency 表。
这些表和字段对应的源码在 WikiDependencyService 里。
它的设计很清楚:
- fact 层页面表示事实;
- experience 层页面表示经验、总结、分析;
- experience 页面可以依赖 fact 页面;
- fact 页面更新后,依赖它的页面会被标记 stale;
- Agent 可以通过
wiki_stale_pages查询哪些页面需要重新检查。
这就把知识库从“静态资料集合”变成了“会知道自己过期的知识系统”。
这点非常重要。企业知识最危险的状态,不是没有知识,而是旧知识看起来还很完整。比如一份运维手册、报价规则、API 文档或客户方案,如果依赖的事实已经变了,它就应该进入待复核状态。
MateClaw 这里已经实现了这个机制。
知识图谱页能直接看到节点和连接数,也能按类型过滤页面关系。这不是完整知识图谱产品的替代,但已经让 Wiki 从“列表式文档库”变成了“有关系的知识网络”。
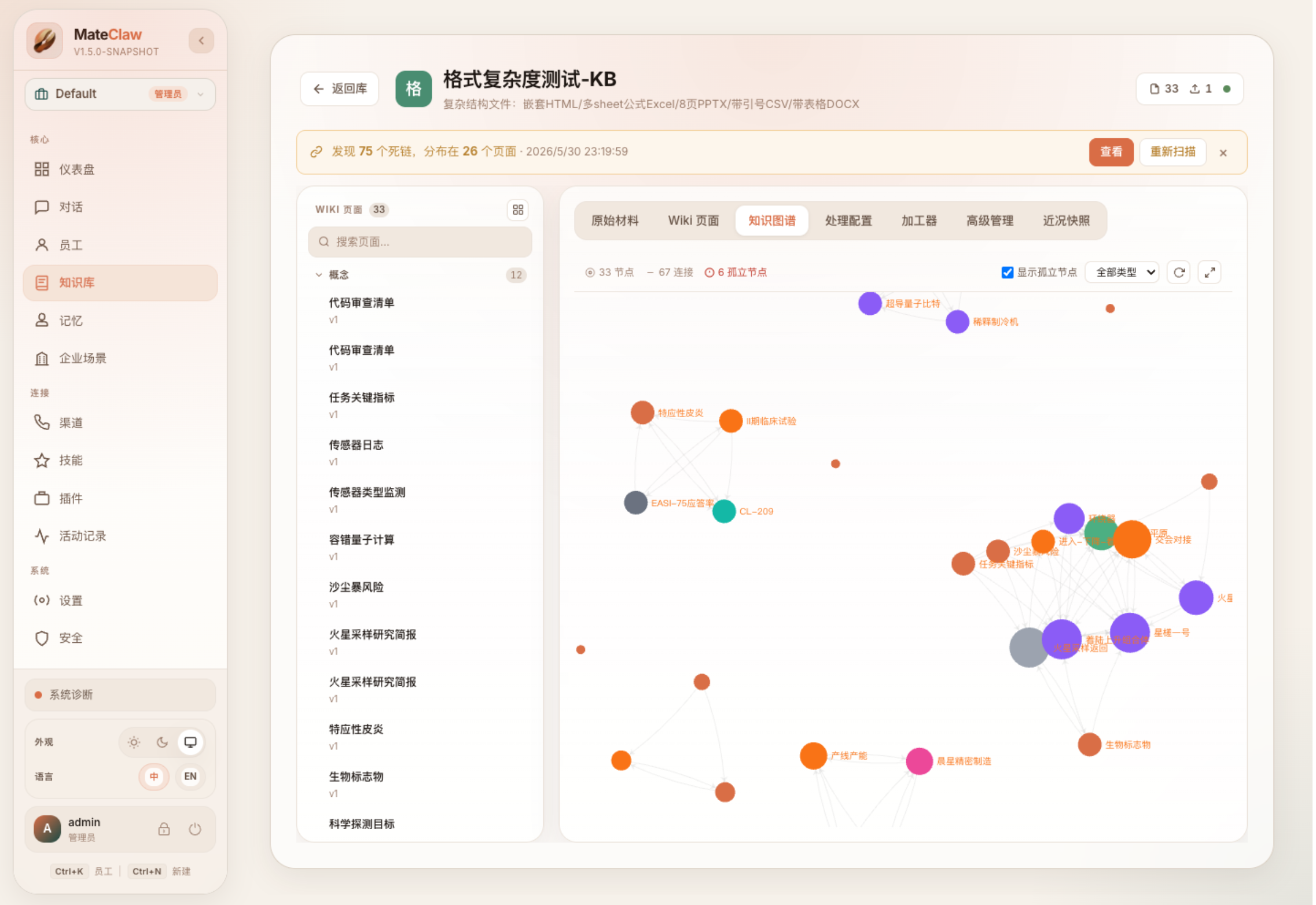
4. 不同 Agent 的知识权限不一样
企业知识库不能所有 Agent 都随便读写。
WikiPageTypePermissionService 解决的是 pageType 级别的权限问题。它支持按 agentId、kbId、pageType 配置读写能力,并且写操作可以返回 ALLOW、APPROVAL_REQUIRED、DENY 三种结果。
源码里的默认策略也很有企业味:
- 读权限如果没有配置,默认继承 KB 的 defaultReadPolicy;
- 写权限是更保守的,一旦某个 Agent + KB 配置了权限行,未覆盖到的 pageType 会 fail-safe 到 deny;
- exact pageType 优先于 wildcard;
- update / create / delete 分别判断。
这意味着 LLM Wiki 不是“所有员工共用一个知识库”。它已经开始像企业权限系统一样工作。
Wiki Pipeline:让知识更新变成流程
MateClaw 的另一个关键点是 Wiki Pipeline。
WikiPipelineDefinitionService 支持用 YAML / JSON 定义知识流水线。一个定义里包含:
- name;
- owner_agent;
- trigger;
- steps。
目前源码里支持的 trigger 包括 page_type_count、page_created、stale_marked;step executor 包括 llm、skill,python 目前保留但提示需要 sandbox。
WikiPipelineService 负责真正执行流水线:创建 run,按 step 执行,记录 step run,最后把状态写成 succeeded 或 failed。它还有去重保护:同一个 trigger envelope 如果已经创建 run,会跳过重复执行。
这说明 MateClaw 的 Wiki 不只是资料管理,而是知识事件驱动系统。
高级管理界面已经把页面类型、分层与失效、权限与审批、变更监测、流水线这些能力放到同一个入口里。这正好对应源码里的 pageType profile、stale propagation、pageType permission 和 pipeline runtime。
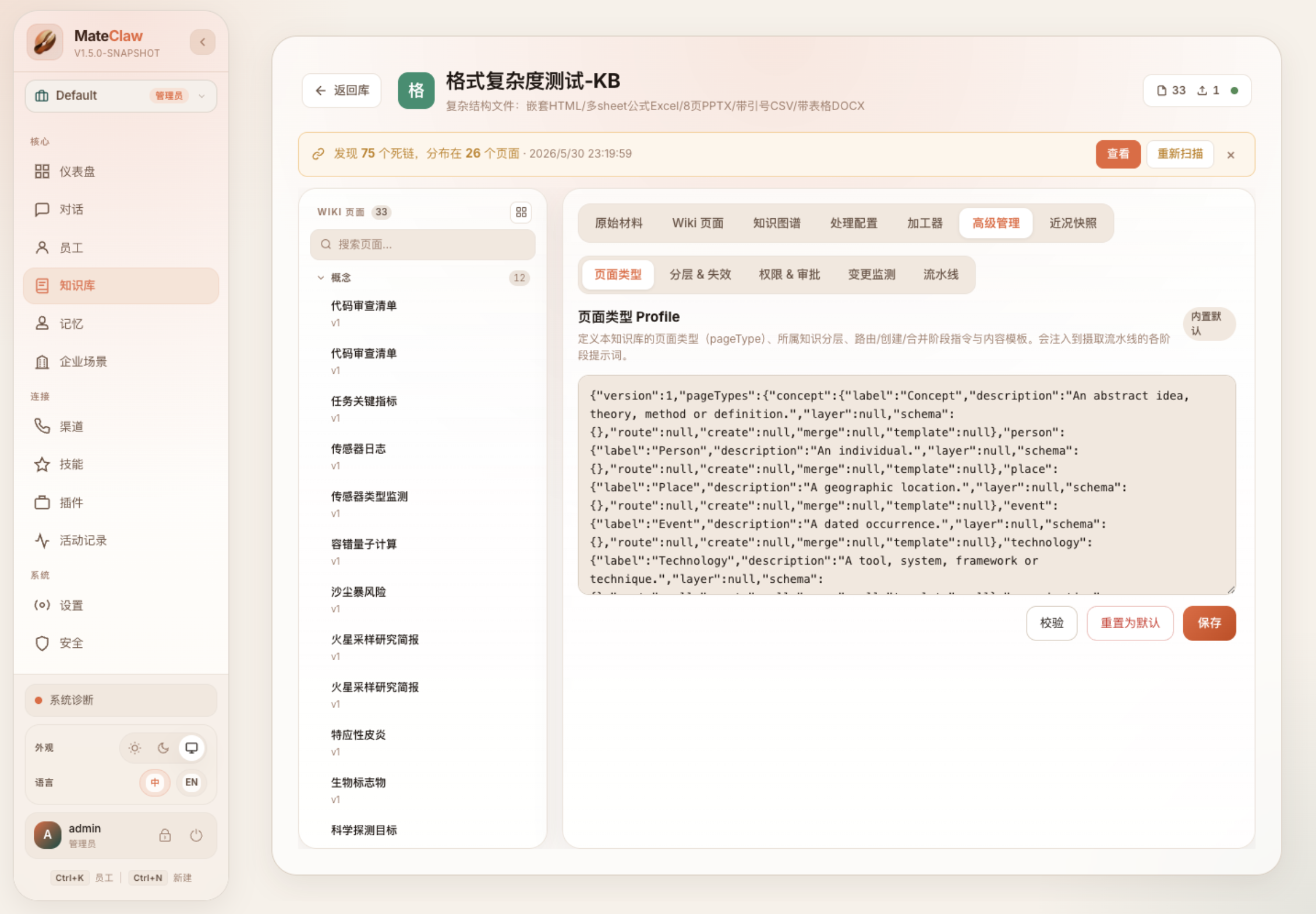
举几个企业场景:
- 新产品文档进入后,自动生成销售 FAQ;
- 运维事故复盘页面创建后,自动更新故障处理手册;
- 某个事实页变化后,依赖它的经验页被标记 stale,再触发重新总结;
- 客户项目资料更新后,通知绑定的客户成功 Agent 复核话术;
- 法务制度更新后,相关 Agent 的模板和回答边界重新整理。
这就是“活知识层”的意义。
加工器页面则展示了另一类能力:把可复用 prompt 模板变成知识加工步骤,例如合同风险点提取、会议纪要转行动项等。它让 Wiki 不只是存知识,还能围绕知识持续产出结构化结果。
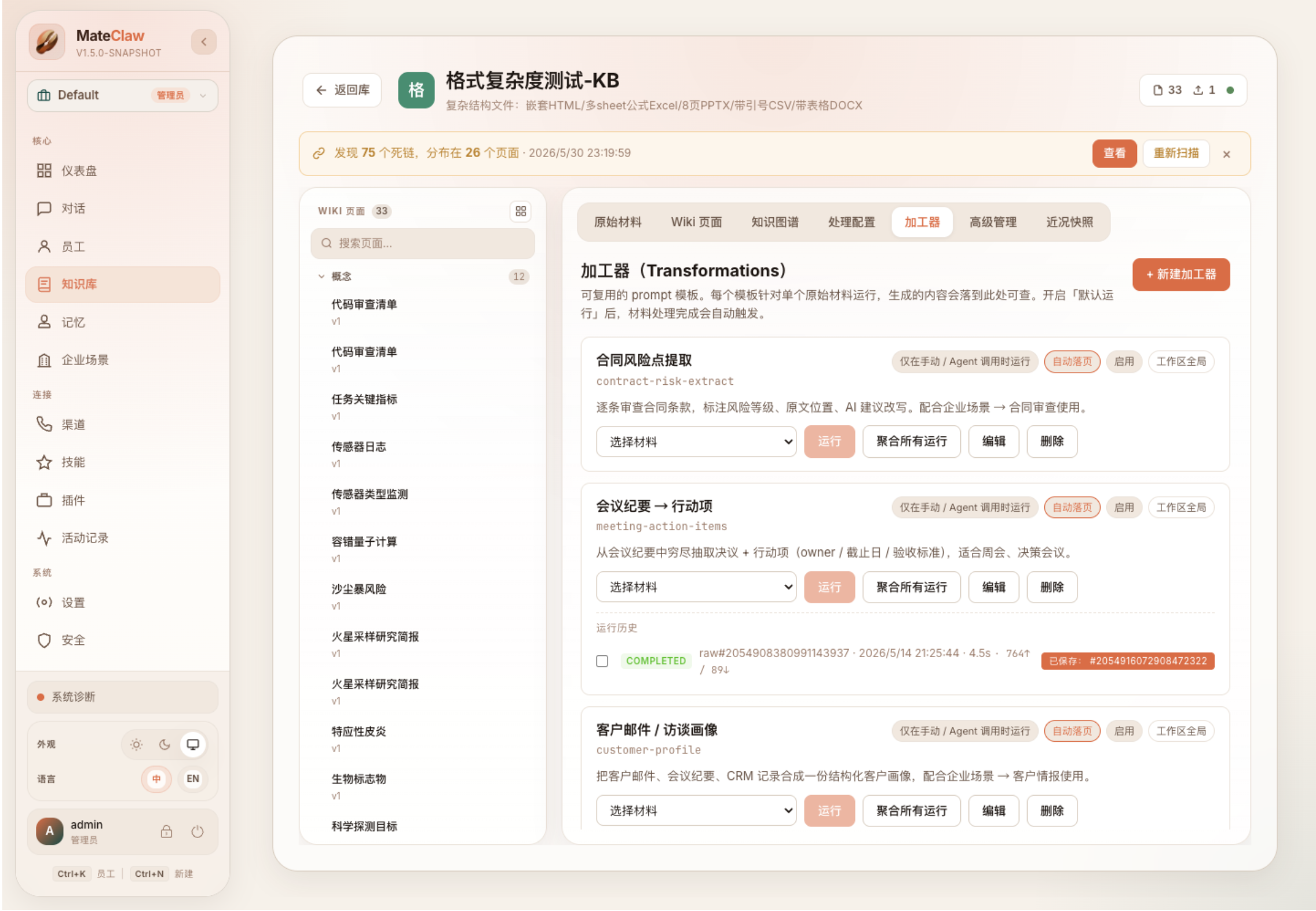
和 GraphRAG / Agentic RAG 的关系
如果用主流概念来对照,MateClaw LLM Wiki 可以这样理解:
它有 RAG 的检索能力
chunk、embedding、semantic search、hybrid retrieval、source trace 这些能力都在。Agent 可以检索原始片段,也可以读取整理后的页面。
它有 GraphRAG 的结构意识
页面之间有 [[链接]],有 relation,有 related pages,也有 fact / experience 的依赖关系。虽然它不是完整知识图谱产品,但它已经不再是纯向量库。
它有 Agentic RAG 的工具化入口
知识库能力不是只给后端检索服务用,而是以 WikiTool 的形式暴露给 Agent。Agent 可以读页面、搜页面、编译页面、追来源、更新页面、查看 stale 页面。
它有企业知识治理能力
pageType 权限、写操作审批、stale 状态、Pipeline run、source evidence,这些是普通 RAG demo 很少覆盖的生产问题。
这也是 MateClaw 的差异点:它不是只回答“怎么让模型查到资料”,而是在回答“企业怎样让 Agent 持续维护知识”。
为什么这篇值得发 CSDN
CSDN 读者对 RAG 已经不陌生。只讲“我有向量检索”没有新鲜感。
但如果标题写成:
MateClaw 的 LLM Wiki 已经不只是 RAG:它在做企业 Agent 的活知识层
这个角度更容易被理解,也更能展示 MateClaw 的工程深度。
因为文章不是讲概念,而是能落到源码:
WikiProcessingService:原始材料消化和页面生成;WikiTool:Agent 可调用的知识工具;WikiDependencyService:fact / experience 依赖和 stale 传播;WikiPageTypePermissionService:按 Agent 和 pageType 控制读写;WikiPipelineDefinitionService/WikiPipelineService:知识流水线定义与运行;- DB migration:
V133、V134、V135、V136已经把权限、metadata、layer、dependency、pipeline runtime 落到表结构。
这比泛泛说“支持知识库”强很多。
结语
RAG 解决了“模型从哪里拿知识”的问题。
GraphRAG 进一步解决“知识之间有什么关系”的问题。
MCP 让 Agent 可以接入外部数据、工具和工作流。
MateClaw 的 LLM Wiki 则更偏企业落地:它让知识变成页面、保留来源、建立链接、区分事实和经验、标记过期、控制权限,并在知识变化后触发流水线。
所以,MateClaw 的 LLM Wiki 不应该只被介绍成“知识库”。
更准确的说法是:
它是企业 Agent 的活知识运行时。
GitHub 地址:https://github.com/matevip/mateclaw
文档地址:https://claw.mate.vip/docs
在线演示:https://claw-demo.mate.vip
参考资料
- RAG 论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》:https://arxiv.org/abs/2005.11401
- Microsoft Research GraphRAG:https://www.microsoft.com/en-us/research/project/graphrag/
- Model Context Protocol 官方介绍:https://modelcontextprotocol.io/docs/getting-started/intro
- MateClaw GitHub:https://github.com/matevip/mateclaw
- MateClaw 文档:https://claw.mate.vip/docs

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)