PolarDB-X三节点部署容易忽略的7个细节,我替你踩了一遍
本文记录了AI在阿里云ECS上部署三节点PolarDB-X标准版集群时遇到的7个典型问题及解决方案,包括:1. 网络配置问题:必须使用内网IP进行节点间通信2. 权限管理问题:需创建专用运行用户并正确配置目录权限3. 命令执行问题:初始化与启动是两个独立步骤4. 依赖缺失问题:需安装ncurses兼容库5. 特殊字符处理:远程执行包含分号的命令需特殊处理6. 资源释放问题:卸载时需彻底终止相关进程
导读:经常会有开发者咨询开源PolarDB-X部署相关问题。我们让AI全自动部署了一遍,看看在部署过程中有哪些容易被忽略的问题。如果你正准备部署PolarDB-X,这篇文章至少能帮你省下2小时排障时间。
PolarDB-X简介
PolarDB分布式版(简称PolarDB-X)是阿里云自主研发的云原生集中式和分布式一体化数据库产品,整体采用了基于存储计算分离的Shared-Nothing系统架构,支持水平扩展、分布式事务、混合负载等能力,具备金融级高可用、高吞吐、大存储、低延时、易扩展、高度兼容 MySQL 系统及生态等特点。
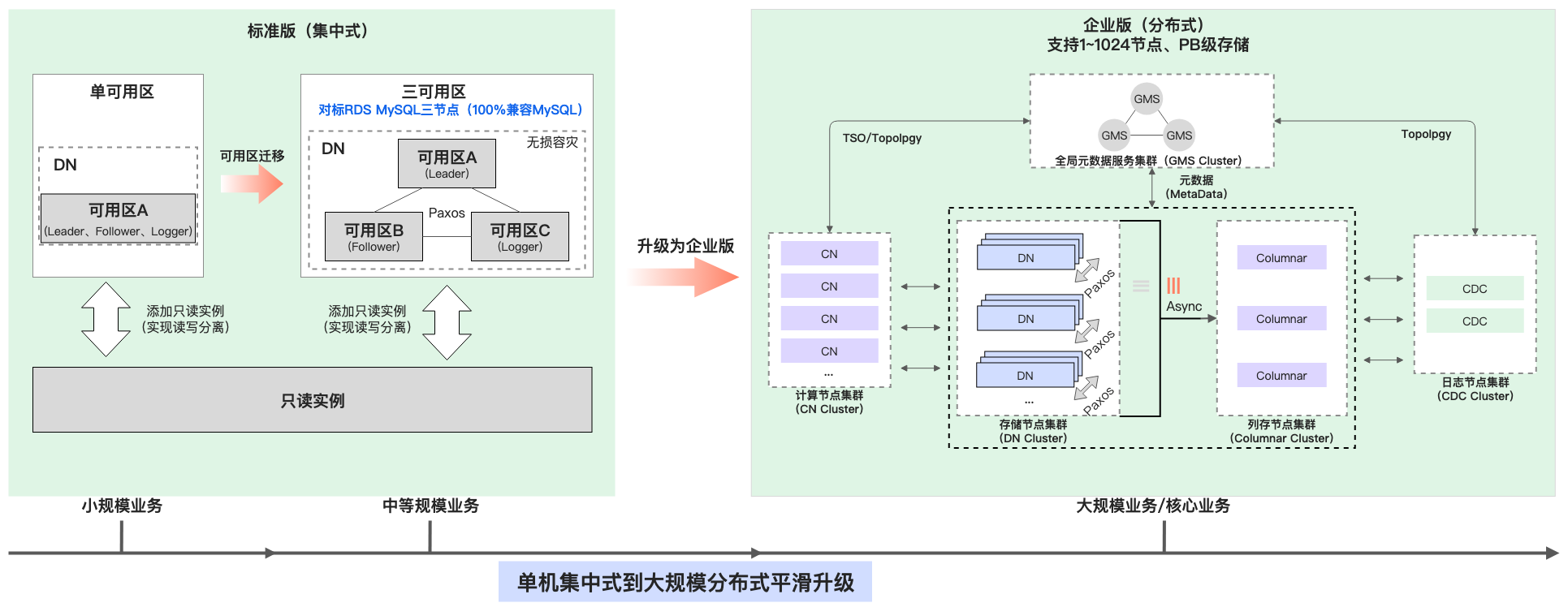
而PolarDB-X标准版,基于集中分布式一体化的架构,将分布式中的存储节点(DN)多副本单独提供服务,提供100%兼容MySQL的语法和功能,兼容MySQL5.7、8.0等多个版本。同时,标准版相对于原生MySQL进行了多方位的功能和性能的增强,基于分布式的技术丰富了高可用、性能提升等。
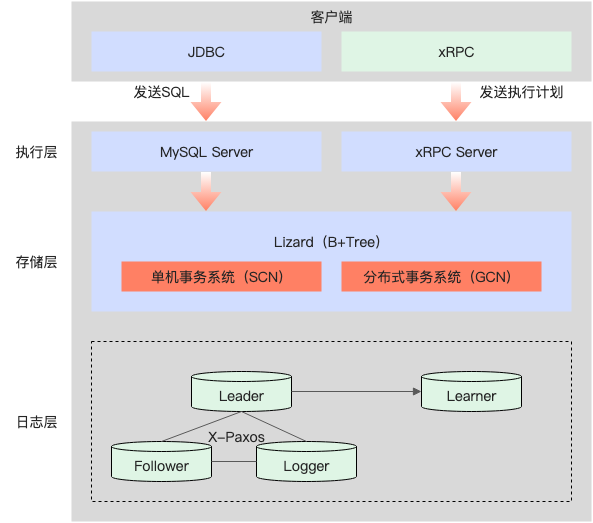
PolarDB-X标准版,采用分层架构:
日志层:采用Paxos的多数派复制协议,基于Paxos consensus协议日志完全兼容MySQL Binlog格式。相比于开源MySQL主备复制协议(基于Binlog的异步或半同步),PolarDB-X标准版可以金融级容灾能力,满足机房级故障时,不丢任何数据(RPO=0)。
存储层:自研Lizard事务系统,对接日志层,可以替换传统MySQL InnoDB的单机事务系统,分别设计了SCN单机事务系统和GCN分布式事务系统来解决这些弊端,可以满足集中式和分布式一体化的事务优化,同时PolarDB-X标准版基于SCN单机事务系统可以提供完全兼容MySQL的事务隔离级别。
执行层:类似于MySQL的Server层,自研xRPC Server可以对接PolarDB-X企业版的分布式查询。同时为完全兼容MySQL,也提供兼容MySQL Server的SQL执行能力,对接存储层的事务系统来提供数据操作。
本文目标:在3台阿里云ECS上,通过 RPM 包快速部署三节点HA集群,并记录AI在全自动部署过程中踩过的每一个坑。
环境配置
|
节点 |
公网IP(管理) |
内网IP(集群通信) |
角色 |
规格 |
|
Node1 |
120.xx.xx.211 |
192.168.0.20 |
Leader |
4C8G,40G SSD |
|
Node2 |
121.xx.xx.241 |
192.168.0.19 |
Follower |
4C8G,40G SSD |
|
Node3 |
121.xx.xx.171 |
192.168.0.21 |
Follower |
4C8G,40G SSD |
-
操作系统:Alibaba Cloud Linux(兼容 CentOS 7/RHEL 7)
-
部署方式:RPM 一键安装
部署流程(标准路径)
理想的部署流程应该是这样的:
# Step 1: 访问polardb开源官网(openpolardb.com/download)下载RPM包到每台机器
wget -O /tmp/polardbx-engine.rpm \
"https://polar-db-prod.oss-cn-hangzhou.aliyuncs.com/...rpm"
# Step 2: 安装RPM
yum install -y /tmp/polardbx-engine.rpm
# Step 3: 创建运行用户和数据目录
useradd -s /sbin/nologin -M polarx
mkdir -p /data/polardbx/data /data/polardbx/tmp
chown -R polarx:polarx /data/polardbx
# Step 4: 生成 my.cnf(每台机器不同)
# 见下文"细节四"
# Step 5: 初始化数据目录(一次性)
mysqld --defaults-file=/data/polardbx/my.cnf \
--initialize-insecure \
--cluster-info="192.168.0.20:3201;192.168.0.19:3201;192.168.0.21:3201@1"
# Step 6: 启动服务(持久运行)
mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize
# Step 7: 验证集群状态
mysql -uroot -h127.0.0.1 -P3306 -e "SELECT * FROM INFORMATION_SCHEMA.ALISQL_CLUSTER_GLOBAL;"但实际上,AI在执行这个流程时,也忽略了多个细节。
容易被忽略的细节
细节一:公网IP互不通——安全组的隐形墙
错误场景:三台机器之间使用公网IP配置 cluster-info,启动后集群始终无法建立共识。查询 ALISQL_CLUSTER_GLOBAL 返回空集。
排查命令:
# Node1 上测试连通性
ping 121.xx.xx.241 # ❌ 100% packet loss
nc -zv 121.xx.xx.241 3201 # ❌ Connection timed out
ping 192.168.0.19 # ✅ 0.1ms
nc -zv 192.168.0.19 3201 # ✅ Connected
根本原因:阿里云ECS的公网IP之间默认不互通(安全组限制),但同VPC的内网IP完全互通。
错误配置:
# ❌ 错误:使用公网IP
--cluster-info="120.55.84.211:3201;121.43.233.241:3201;121.40.252.171:3201@1"
正确配置:
# ✅ 正确:使用内网IP
--cluster-info="192.168.0.20:3201;192.168.0.19:3201;192.168.0.21:3201@1"
经验教训:云环境部署三节点时,节点间通信务必使用内网IP。 公网IP仅用于外部客户端访问和管理。建议在部署前先用 ping 和 nc 验证三节点之间的网络连通性。
细节二:mysqld拒绝root启动——用户切换的细节
错误场景:安装RPM后,直接用 root 用户执行启动命令:
/opt/polardbx_engine/bin/mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize
结果进程启动后立即退出,日志中没有任何有效错误信息。直接用 mysqld 测试时才暴露真相:
[ERROR] Fatal error: Please read "Security" section of the manual
to find out how to run mysqld as root!
根本原因:MySQL/PolarDB-X 出于安全考虑,禁止以 root 用户直接运行 mysqld。
正确做法:
# Step 1: 创建专用运行用户(所有节点执行)
useradd -s /sbin/nologin -M polarx
# Step 2: 数据目录授权(所有节点执行)
mkdir -p /data/polardbx/data /data/polardbx/tmp
chown -R polarx:polarx /data/polardbx
# Step 3: 以 polarx 用户启动(注意!坑3与此相关)
su -s /bin/bash polarx -c \
"/opt/polardbx_engine/bin/mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize"
经验教训:务必创建专用运行用户(如 polarx),并将数据目录权限授予该用户。 这是MySQL部署的基础要求,但在自动化脚本中很容易被忽略。
细节三:工作目录权限——su 继承的隐形陷阱
错误场景:在解决了坑2(创建polarx用户)之后,再次执行启动命令:
# 当前目录是 /root
su -s /bin/bash polarx -c \
"/opt/polardbx_engine/bin/mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize"
结果报错:
mysqld_safe: line 513: cd: /root: Permission denied
根本原因:su -s /bin/bash polarx -c "cmd" 会继承当前shell的工作目录。如果当前在 /root 目录下执行,mysqld_safe 内部会尝试 cd /root,而 polarx 用户没有 /root 的访问权限,导致启动失败。
正确做法:
# ✅ 先切换到 polarx 用户有权限的目录,再启动
su -s /bin/bash polarx -c \
"cd /data/polardbx && /opt/polardbx_engine/bin/mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize"
经验教训:使用 su 切换用户启动服务时,务必先 cd 到目标用户有权限访问的目录。 建议统一使用 /data/polardbx 作为工作目录。
细节四:--initialize-insecure 不是启动命令
错误场景:执行初始化命令后,返回码为0,但 ps aux 中看不到任何 mysqld 进程,端口也没有监听。
/opt/polardbx_engine/bin/mysqld --defaults-file=/data/polardbx/my.cnf --initialize-insecure
# 命令立即退出,echo $? = 0排查过程:反复检查 my.cnf 配置、数据目录权限,都没有发现问题。最后才意识到——这个命令本来就是应该退出的。
根本原因:--initialize-insecure 是一个一次性数据目录初始化命令,它的作用是:
-
创建系统表(mysql、information_schema 等)
-
生成 root@localhost 用户(空密码)
-
初始化 InnoDB 数据文件
完成后,进程自动退出。它不是守护进程启动命令。
正确流程:
# Step 1: 初始化(一次性,执行完自动退出)
su -s /bin/bash polarx -c \
"/opt/polardbx_engine/bin/mysqld --defaults-file=/data/polardbx/my.cnf --initialize-insecure --cluster-info='...'"
# Step 2: 验证初始化成功
ls -la /data/polardbx/data/ # 应该看到 ibdata1、mysql 目录等29+个文件
# Step 3: 启动持久服务(mysqld_safe才是守护进程)
su -s /bin/bash polarx -c \
"cd /data/polardbx && /opt/polardbx_engine/bin/mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize"
# Step 4: 验证进程
ps aux | grep mysqld # 应该看到 mysqld 进程
ss -tlnp | grep 3306 # 应该看到 3306 端口监听
经验教训:--initialize-insecure 和 mysqld_safe --daemonize 是两个独立的步骤。 初始化完成后,必须单独执行启动命令才能建立持久服务。很多开发者误以为初始化命令会同时启动服务。
细节五:缺失 libncurses.so.5——RPM安装的隐形依赖
错误场景:集群启动成功,进程和端口都正常。但尝试用 mysql 客户端连接时:
/opt/polardbx_engine/bin/mysql -uroot -h127.0.0.1 -P3306
# 报错:error while loading shared libraries: libncurses.so.5: cannot open shared object file
根本原因:RPM包是在 CentOS 7 / Alibaba Cloud Linux 环境下编译的,依赖 libncurses.so.5。但现代系统默认安装的是 ncurses 6.x,只提供 libncurses.so.6,缺少兼容版本的 .so.5。
解决方案:
# CentOS / RHEL / Alibaba Cloud Linux
yum install -y ncurses-compat-libs
# 验证
ls -la /lib64/libncurses.so.5 # 应该存在
经验教训:RPM安装后,务必检查动态库依赖。 可以通过 ldd /opt/polardbx_engine/bin/mysql | grep "not found" 快速检查缺失的库。
细节六:cluster-info 中的分号截断远程命令
错误场景:通过SSH远程执行初始化命令时,因为 cluster-info 包含分号 ;,导致命令被shell截断:
# 预期执行的命令:
mysqld --initialize-insecure --cluster-info='ip1:3201;ip2:3201;ip3:3201@1'
# 实际执行结果(分号被当作命令分隔符):
mysqld --initialize-insecure --cluster-info='ip1:3201
# ip2:3201 被当作新命令执行,报错:command not found
根本原因:在通过SSH或脚本传递包含特殊字符(分号、引号、美元符号等)的命令时,多层shell的引号解析会导致命令被意外截断或变形。
解决方案——base64编码传递:
# 本地生成初始化脚本
cat > init.sh << 'EOF'
#!/bin/bash
/opt/polardbx_engine/bin/mysqld \
--defaults-file=/data/polardbx/my.cnf \
--initialize-insecure \
--cluster-info="192.168.0.20:3201;192.168.0.19:3201;192.168.0.21:3201@1"
EOF
# base64编码后通过SSH传递(避免引号解析问题)
base64_script=$(base64 -w 0 init.sh)
ssh root@192.168.0.20 \
"echo '$base64_script' | base64 -d > /tmp/init.sh && bash /tmp/init.sh"
经验教训:远程执行包含特殊字符的命令时,使用 base64 编码传递脚本是最可靠的方案。 这完全避免了多层shell引号解析的问题。
细节七:卸载不彻底——进程残留的"幽灵文件"
错误场景:第一次部署失败后执行了标准卸载流程:
mysqladmin shutdown
rm -rf /data/polardbx
rpm -e t-polardbx-engine
看起来干净利落?重新部署时发现磁盘空间不足,但 du -sh / 只统计到18GB,而 df -h 显示已用38GB。消失的20GB去哪了?
排查命令:
# 查看被删除但仍被进程占用的文件
lsof +L1 | grep polarx
# 输出示例:
# mysqld 39258 polarx 3u REG 253,3 12582912 /data/polardbx/data/ibdata1 (deleted)
# mysqld 39258 polarx 4u REG 253,3 50331648 /data/polardbx/data/undo_001 (deleted)
# ... 共约20GB
根本原因:mysqld 进程被 polarx 用户启动,即使数据文件被 rm -rf 删除,只要进程还在运行,文件描述符就继续占用磁盘空间。Linux 中这叫"已删除但仍被打开的文件(deleted-but-open files)"。
正确卸载流程:
# Step 1: 优雅停止服务
mysqladmin -uroot -h127.0.0.1 -P3306 shutdown
# Step 2: 强制终止运行用户的所有残留进程
pkill -9 -u polarx
# Step 3: 验证没有残留占用
lsof +L1 | grep -E 'polardbx|mysqld'
# 如果输出为空,说明空间已释放
# Step 4: 删除数据目录和RPM
rm -rf /data/polardbx
rpm -e t-polardbx-engine
# Step 5: 删除用户(可选)
userdel polarx
# Step 6: 验证磁盘空间释放
df -h
经验教训:卸载时务必终止运行用户(polarx)的所有进程,否则 rm -rf 删掉的只是文件入口,真正的磁盘块仍被进程持有。 建议在卸载脚本中加入 lsof +L1 检查,确认没有残留的已删除文件。
完整部署命令速查表
每台机器都需要执行的命令
# ========== Step 1: 下载并安装RPM ==========
wget -O /tmp/polardbx-engine.rpm "<你的RPM下载链接>"
yum install -y /tmp/polardbx-engine.rpm
# ========== Step 2: 安装客户端依赖 ==========
yum install -y ncurses-compat-libs
# ========== Step 3: 创建用户和数据目录 ==========
useradd -s /sbin/nologin -M polarx
mkdir -p /data/polardbx/data /data/polardbx/tmp
chown -R polarx:polarx /data/polardbx
# ========== Step 4: 生成 my.cnf ==========
# 注意:每台机器的 server_id 不同(1、2、3),其他配置相同
cat > /data/polardbx/my.cnf << 'EOF'
[mysqld]
server_id = 1 # Node2改为2,Node3改为3
datadir = /data/polardbx/data
tmpdir = /data/polardbx/tmp
socket = /data/polardbx/tmp/mysql.sock
log_error = /data/polardbx/data/error.log
port = 3306
# X-Paxos 配置
cluster_id = 1
cluster_info = '192.168.0.20:3201;192.168.0.19:3201;192.168.0.21:3201@1'
# 性能配置(根据内存调整)
innodb_buffer_pool_size = 2G
max_connections = 500
# 日志配置
log_bin = /data/polardbx/data/mysql-bin
binlog_format = ROW
EOF
# ========== Step 5: 初始化数据目录(一次性) ==========
su -s /bin/bash polarx -c \
"/opt/polardbx_engine/bin/mysqld --defaults-file=/data/polardbx/my.cnf --initialize-insecure"
# 验证初始化成功(应该有29+个文件)
ls -la /data/polardbx/data/
# ========== Step 6: 启动服务 ==========
su -s /bin/bash polarx -c \
"cd /data/polardbx && /opt/polardbx_engine/bin/mysqld_safe --defaults-file=/data/polardbx/my.cnf --daemonize"
# 验证进程和端口
ps aux | grep mysqld
ss -tlnp | grep -E '3306|3201'
部署验证:集群状态检查
在所有节点启动后,在 Leader 节点上执行验证:
-- 1. 查看版本
SELECT VERSION();
-- 结果:8.0.32-X-Cluster-8.4.19-20250825
-- 2. 查看本地角色(Leader上执行)
SELECT * FROM INFORMATION_SCHEMA.ALISQL_CLUSTER_LOCAL;
-- 结果:ROLE=Leader, CURRENT_LEADER=192.168.0.20:3201, SERVER_READY_FOR_RW=Yes
-- 3. 查看全局拓扑(Leader上执行)
SELECT * FROM INFORMATION_SCHEMA.ALISQL_CLUSTER_GLOBAL;
-- 结果:3 rows,显示所有节点角色和匹配索引
-- 4. 查看复制健康状态
SELECT * FROM INFORMATION_SCHEMA.ALISQL_CLUSTER_HEALTH;
-- 结果:LOG_DELAY_NUM=0, APPLY_DELAY_NUM=0, APPLY_DELAY_SECONDS=0
-- 5. 写入测试
CREATE DATABASE deploy_test;
USE deploy_test;
CREATE TABLE t1 (id INT PRIMARY KEY, msg VARCHAR(100));
INSERT INTO t1 VALUES (1, 'hello from leader');
-- 6. 在 Follower 节点上验证数据同步
-- 连接到 Node2 或 Node3
SELECT * FROM deploy_test.t1;
-- 结果:(1, hello from leader) ✅
故障切换测试:关闭 Leader(Node1)的 mysqld 进程
-
观察 Node2/Node3 的
ALISQL_CLUSTER_LOCAL,约3秒内新 Leader 产生 -
新 Leader 可正常读写
-
原 Leader 重启后自动作为 Follower 重新加入集群
开发者部署检查清单
在部署前对照检查,避免踩坑:
|
检查项 |
命令/方法 |
预期结果 |
|
节点间网络连通性 |
|
全部通 |
|
共识端口开放 |
|
全部通 |
|
磁盘空间 |
|
剩余 ≥ 10GB |
|
内存 |
|
可用 ≥ 4GB |
|
运行用户 |
|
用户存在 |
|
数据目录权限 |
|
polarx:polarx |
|
RPM依赖 |
|
无输出 |
|
客户端依赖 |
|
文件存在 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)