端侧NPU语音Agent实战:Embedding召回+Qwen2.5-0.5B意图识别,MTK 9TOPS整体延迟1s
本文探讨了在端侧设备上实现语音意图解析的两种方案:纯LLM方案与Embedding召回+LLM组合方案。通过实际工程验证,揭示了在NPU硬件受限环境下(如9 TOPS算力、0.5B-4B小模型),Embedding的核心价值并非工具检索,而是通过预过滤大幅降低输入LLM的token数量——这对端侧延迟控制至关重要。实测数据显示,组合方案通过CPU跑轻量Embedding(100ms)换取LLM阶段
端侧语音意图解析:Embedding 召回 + LLM,还是纯 LLM?——一次真实的工程取舍
本文记录我在受限 NPU 硬件上落地"语音 → 意图 → 可执行指令"全链路时,对意图解析模块的两套方案做的取舍。结论先放这:在端侧,Embedding 召回的价值不是"找工具",而是把喂给 LLM 的 token 压下来——而 token 数恰恰是 NPU 上 LLM 延迟的主要瓶颈。
0. 这篇文章在解决什么问题
现在"端侧 AI Agent / on-device function calling"很热。大家都想要这样一个东西:
用户对着设备说一句话 → 设备本地识别意图、填好参数 → 生成一条可执行指令(function call / MCP 指令)去驱动应用。
云端做这件事很容易,丢给 GPT/Claude 一把工具 + 一段话,它直接给你 function call。但端侧不一样:你的算力是一块 NPU(BM1684X / MTK NeuroPilot / RK3576 这类),内存有限,LLM 只能跑 0.6B~4B 的小模型,而且延迟对体验极其敏感——用户说完话到设备响应,超过 1.5 秒就开始"感觉卡"。
意图解析模块,就是这条链路里最吃 LLM、最容易成为瓶颈的一环。我对它设计了两套方案,实测后选了其中一套。下面讲清楚为什么。
1. 整条链路长什么样
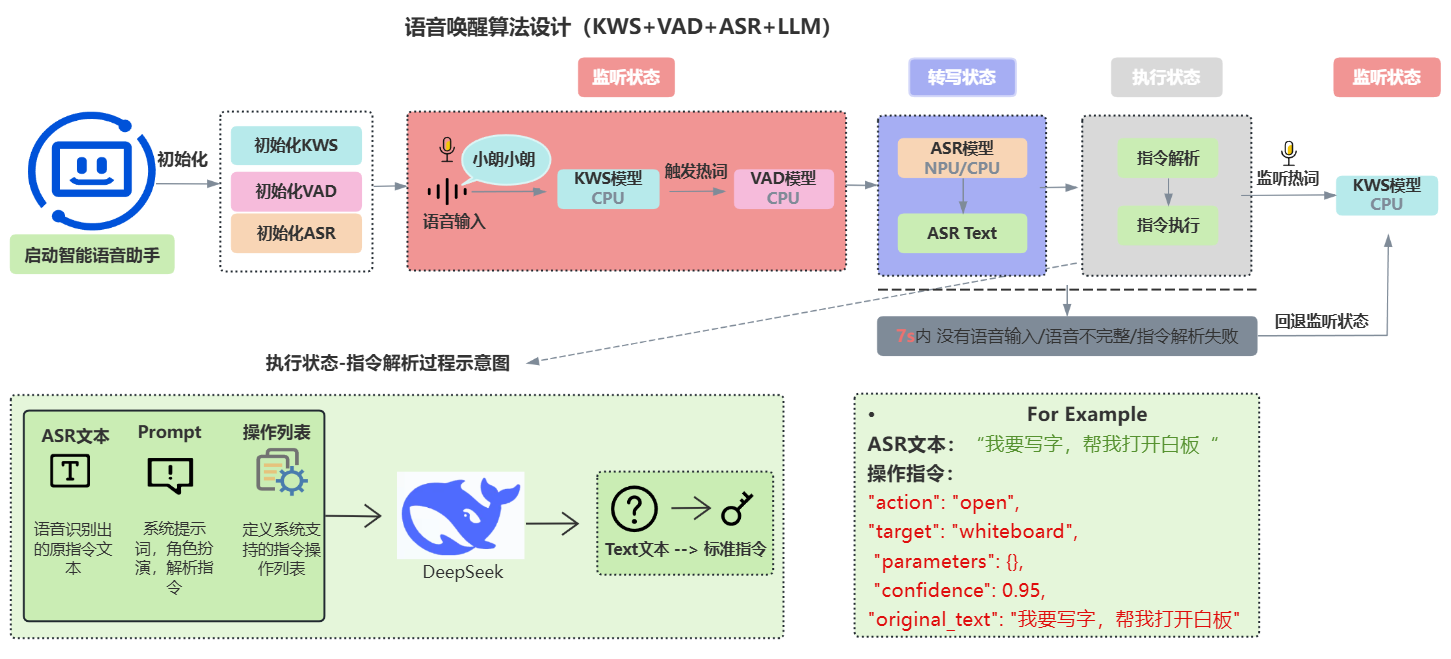 先交代上下文。完整的语音助手是一个状态机:
先交代上下文。完整的语音助手是一个状态机:
启动 → 初始化(KWS / VAD / ASR)
→ 【监听态】KWS 热词唤醒("小朗小朗")→ VAD 检测语音起止
→ 【转写态】ASR 出文本(NPU/CPU)
→ 【执行态】意图解析 → 指令执行
→ 7s 内无语音/语音不完整/解析失败 → 回退监听态
本文聚焦的是"执行态"里的第一步:ASR 文本 → 可执行指令。
输入是一段 ASR 文本,比如:
“帮我打开白板,我想用马克笔写字,笔迹大小调整到 12”
期望输出是一组可执行的结构化指令:
[
{"tool": "open_whiteboard"},
{"tool": "set_pen", "params": {"type": "marker", "size": 12}}
]
注意这里有两个动作、还有参数(笔类型、笔迹大小),这正是难点。
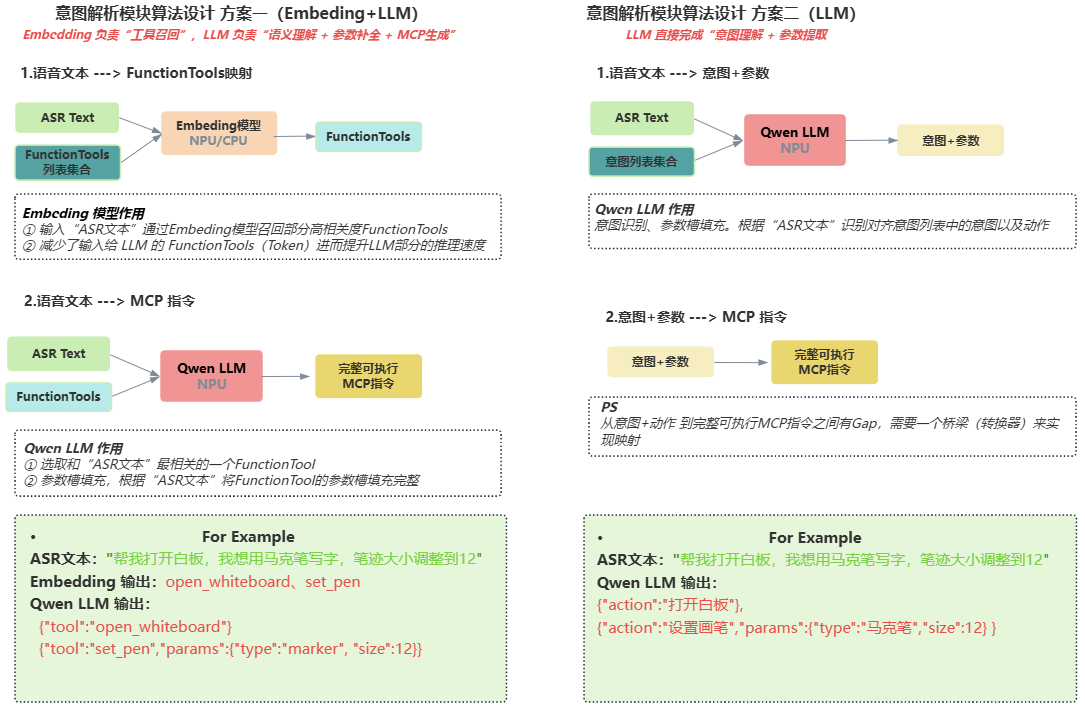
2. 方案二:纯 LLM 一步到位(看着最香,其实有隐藏成本)
最直觉的做法:把"意图列表"和 ASR 文本一起塞给 LLM,让它一步出意图 + 参数。
ASR Text + 意图列表集合 ──► Qwen LLM (NPU) ──► 意图 + 参数
输出类似:
{"action": "打开白板"}
{"action": "设置画笔", "params": {"type": "马克笔", "size": 12}}
看起来很干净。但我落地时发现一个绕不过去的 Gap:
从"意图 + 动作"到"完整可执行的 MCP 指令"之间,还差一个桥接转换器。
LLM 吐出来的 {"action": "设置画笔"} 不是系统能直接执行的东西。系统认的是 set_pen 这个 tool 名、认的是 type: "marker" 这个枚举值——而不是中文的"马克笔"。于是你还得在 LLM 后面再写一层映射:中文动作名 → tool 名、中文参数值 → 系统枚举值。
这层映射本身不难,但它意味着:
- LLM 的输出空间是"自由文本",不可控。今天它说"设置画笔",明天可能说"调整笔",你的映射表永远在追着补。
- 想让它稳定输出,就得在 prompt 里把所有工具、所有参数枚举都写进去 → prompt 变长 → token 变多。
这个 token 问题,就是端侧的命门。
3. 方案一:Embedding 召回 + LLM(我最终选的)
方案一把意图解析拆成两步:
第一步:工具召回(Embedding 模型,跑 CPU)
ASR Text + FunctionTools 列表集合 ──► Embedding 模型 ──► 召回 Top-K 相关 FunctionTools
我这里用的是中文场景常见的轻量 embedding(m3e / text2vec 这一类),模型小、可以放在 CPU 上跑,不占 NPU——而 NPU 要留给后面的 LLM。Embedding 模型在这里干两件事:
- 输入 ASR 文本,通过向量相似度从完整工具库里召回最相关的几个 FunctionTools。
- 减少输入给 LLM 的 FunctionTools(token),从而提升 LLM 部分的推理速度。
第二步:参数槽填充 + 指令生成(Qwen LLM,NPU)
ASR Text + 召回的 FunctionTools ──► Qwen LLM (NPU) ──► 完整可执行 MCP 指令
这一步的 LLM 我用的是 LoRA 微调过的 Qwen2.5-0.5B,跑在一颗 9 TOPS 的 MTK NPU 上,实测 prefill ~600 token/s、decode ~45 token/s。选 0.5B 而不是更大的模型,正是因为它配合上一步的 token 压缩,延迟刚好能压进预算;而 LoRA 微调补回了小模型在"工具选择 + 参数槽填充"这个窄任务上的准确率——窄任务正是小模型 + 微调最划算的地方。
LLM 在这里只做两件被严格约束的事:
- 从召回的(已经很少的)几个 FunctionTool 里,选出和 ASR 文本最相关的。
- 参数槽填充——根据 ASR 文本把这个 FunctionTool 的参数填完整。
因为喂进去的工具定义本身就携带了精确的 tool 名和参数 schema,LLM 直接输出:
{"tool": "open_whiteboard"}
{"tool": "set_pen", "params": {"type": "marker", "size": 12}}
不再需要那层中文→枚举的桥接转换器——Gap 消失了。
4. 核心权衡:为什么端侧值得多加一个 Embedding 模型?
表面看,方案一比方案二多了一个模型(Embedding),更复杂。在云端我大概率会选方案二,因为云端 token 几乎不要钱、上下文窗口巨大。
但端侧的成本结构完全不同:
| 维度 | 端侧的真实约束 |
|---|---|
| LLM 延迟 | 由 prefill 的 token 数 + decode 的 token 数共同决定,prefill 几乎和输入 token 数成正比 |
| 工具数量 | 一个真实产品的工具库可能有几十上百个,全塞进 prompt → 输入 token 爆炸 |
| 模型大小 | 端侧 LLM 只有 0.6B~4B,长上下文下既慢又容易乱 |
| 输出可控性 | 工具越多、prompt 越杂,小模型越容易输出错工具名/错参数 |
关键洞察:Embedding 召回的真正价值,不是"帮 LLM 找工具",而是"把喂给 LLM 的 token 数从’整个工具库’压到’Top-K 几个’"。
而 token 数,正是 NPU 上 LLM 延迟的主要瓶颈。
举个直观的例子:我的工具库是几十个工具的量级,每个工具的定义(名字 + 描述 + 参数 schema)平均下来几十个 token,全部塞进 prompt 就是数千 token 的输入。Embedding 召回 Top-K(我取个位数)之后,实际喂给 LLM 的工具定义只剩几百 token。对一个跑在 NPU 上的 0.6B~4B 小模型,prefill 阶段处理几千 token 和几百 token,延迟差距是肉眼可见的。
而且这个差距会随工具库增长而放大:工具越多,纯 LLM 方案的 prompt 越长、越慢、小模型越容易选错;而 Embedding 召回方案喂给 LLM 的 token 数几乎不变(始终是 Top-K)。工具库越大,方案一的优势越明显。
代价是多加一个 Embedding 模型。但它小、快、跑在 CPU 上不抢 NPU,而且它自己的延迟远小于它为 LLM 省下来的延迟。这是一笔稳赚的交易。
5. 实测:整套链路在 9 TOPS NPU 上跑到 ~1s
光讲道理不够,上数字。下面是方案一在一颗 9 TOPS 的 MTK NPU 上的实测端到端延迟拆解(ASR 用流式中英双语 zipformer,LLM 用 LoRA 微调的 Qwen2.5-0.5B):
| 阶段 | 模型 | 实测延迟 |
|---|---|---|
| ASR(语音转文本) | zipformer 流式中英双语 | ~300 ms |
| Embedding 召回 | m3e/text2vec 系(CPU) | ~100 ms |
| LLM 意图解析 + 槽填充 | Qwen2.5-0.5B LoRA(NPU) | ~600 ms |
| MCP 指令生成 | 桥接/模板 | 10~50 ms |
| 整体系统延迟 | ~1 s |
对比方案二(纯 LLM):它省掉了 Embedding 那 100ms,但省不掉 LLM 的延迟,反而会拉长它——因为没有召回压 token,整个工具库都要塞进 prompt,prefill 阶段要处理的 token 多出一截。在我的工具库规模下,方案二的 ASR + LLM 至少也是 900ms 起步(300 + 600),而且这个 600ms 会随工具库增大而上涨。方案一多花的那 100ms embedding,买来的是 LLM 延迟的可控和稳定。
几个值得说的点:
- prefill 600 token/s、decode 45 token/s 是这颗 9 TOPS NPU 上 0.5B 模型的实测吞吐。正因为 decode 不快,我才要在输入端把 token 压到极致——能省的延迟主要在 prefill 和"少生成几个 token"上。
- ~1s 的整体延迟,是端侧语音交互"无感"的关键门槛。超过 1.5s,用户就会觉得设备"反应慢"。方案一压进 1s,体验上是过线的。
6. 一个容易被忽略的坑:别用 LLM 自报的 confidence 去 gate 动作
链路里有个细节我想单独拎出来提醒:有些设计会让 LLM 在输出里附一个置信度,比如:
{"action": "open", "target": "whiteboard", "confidence": 0.95, "original_text": "..."}
然后用这个 confidence 去决定要不要执行动作。
慎用。 LLM 自评的置信度通常没有经过校准(uncalibrated)——它说 0.95 不代表真有 95% 的概率对。拿一个没校准的数去 gate “要不要真的打开白板/执行操作”,风险不小。
更可靠的 gate 信号是:
- ASR 的声学置信度 / VAD 是否检测到完整语音段;
- Embedding 召回的 Top-1 相似度分数(这个是有物理意义的几何距离);
- 参数是否填全(槽位完整性校验);
- 真不确定时,走一轮"你是想…吗?"的确认反问。
把"是否执行"的决策权交给这些更可信的信号,而不是 LLM 的一句自我感觉良好。
7. 小结:端侧不是把云端方案缩小,而是换一套成本模型
如果只记一句话:
云端选纯 LLM,因为 token 不要钱;端侧选 Embedding 召回 + LLM,因为 token 就是延迟。
意图解析这一环的设计,本质上是在回答一个问题:你的瓶颈资源是什么? 云端是开发效率,端侧是每一个 token 的推理时间。同一个功能,瓶颈不同,最优架构就完全不同。
这也是我做端侧语音 Agent 这段时间最大的体会:端侧工程的难点很少在"模型能不能跑",而在"在给定的硬件预算下,怎么把整条链路的延迟、内存、可控性配平。"
我在 BM1684X / MTK NeuroPilot / RK 等端侧 NPU 上落地过 Whisper、SenseVoice、ChatTTS、Qwen 等模型的移植与全链路语音 Agent。这个系列会陆续把这些工程实践写出来,如果你也在受限硬件上做端侧 AI,欢迎在评论区交流。
GitHub:https://github.com/superLin006

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)