我爱你们那迷人的边界感!——ClaudeCode如何做Harness(工具篇1)

你好,我是司沐。
从CC源码泄露到现在,已经差不多有两个月的时间了。Github上从原始代码到重写项目,再到出教程,已经积累了许多很不错的仓库。
由于我自己目前的主要工作就是Agent Harness,所以过去的两个月里也将CC的代码翻来覆去反复读。在这个过程中,我发现目前许多对CC代码与设计的解析,看起来好像并非出自一个Agent工程师之手,而更像是一个转行到Agent,但同时保留了一些老行业思维的人,与并不是很懂Agent的AI一起协作出来的。当然有许多可圈可点的地方,但总归少了点意思,并不能聚焦到CC真正的核心设计上。
所以,我计划在CC源码泄露已经过了两个月之后的当下,重新整理并发出一份我自己对CC中Harness工程设计的理解。
这个系列大概会出10篇左右,涵盖工具设计,上下文压缩策略,提示词编排策略,记忆策略,数据实体分层结构等等内容。
希望对读到文章的你有帮助。
本文详细介绍七个最基础的操作工具:Read、Write、Edit、Glob、Grep、Bash、PowerShell。每个工具先讲参数和行为,再讲设计取舍——为什么这样设计、解决了什么问题、预防了什么风险。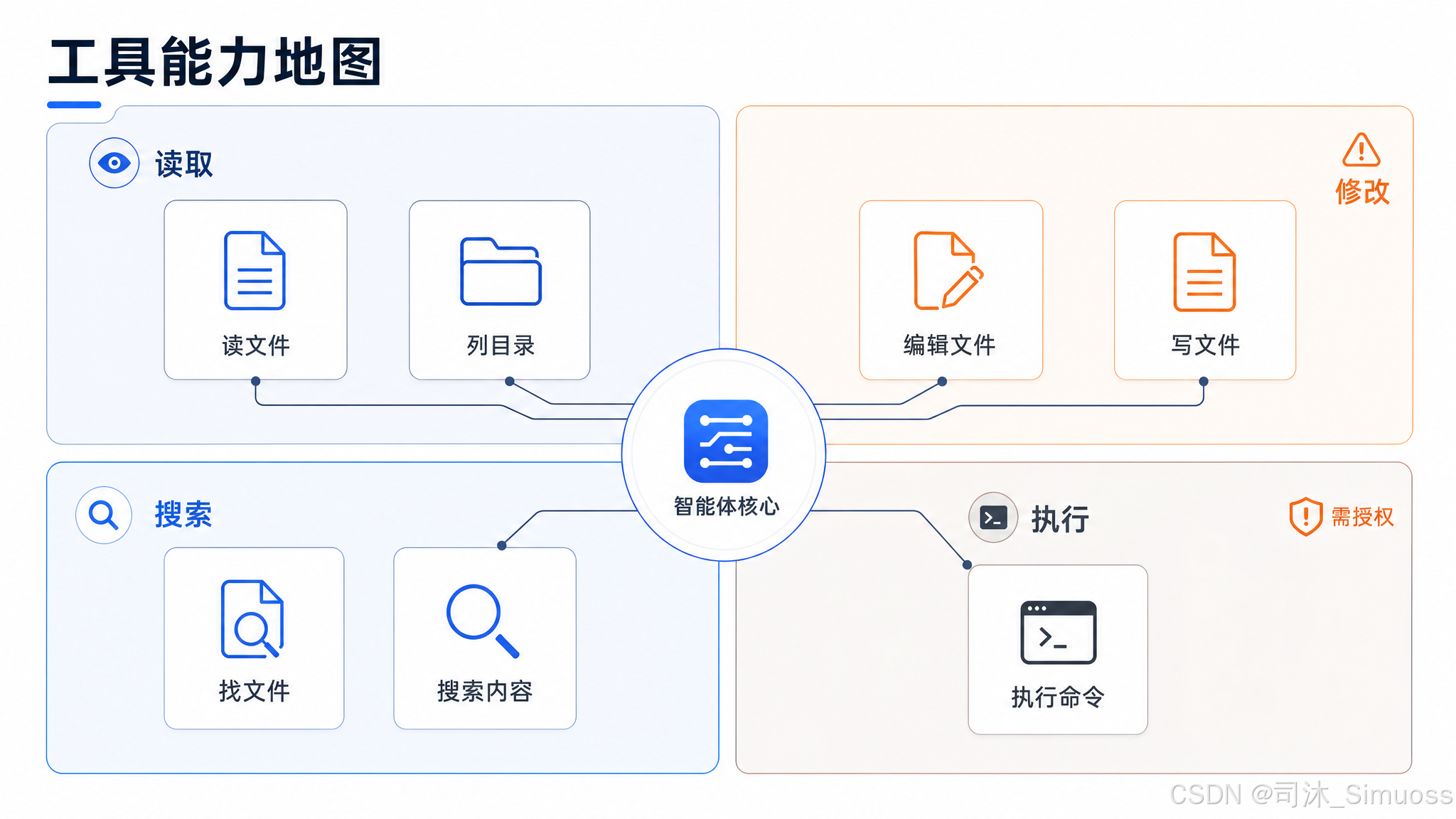
Read(读取文件)
参数
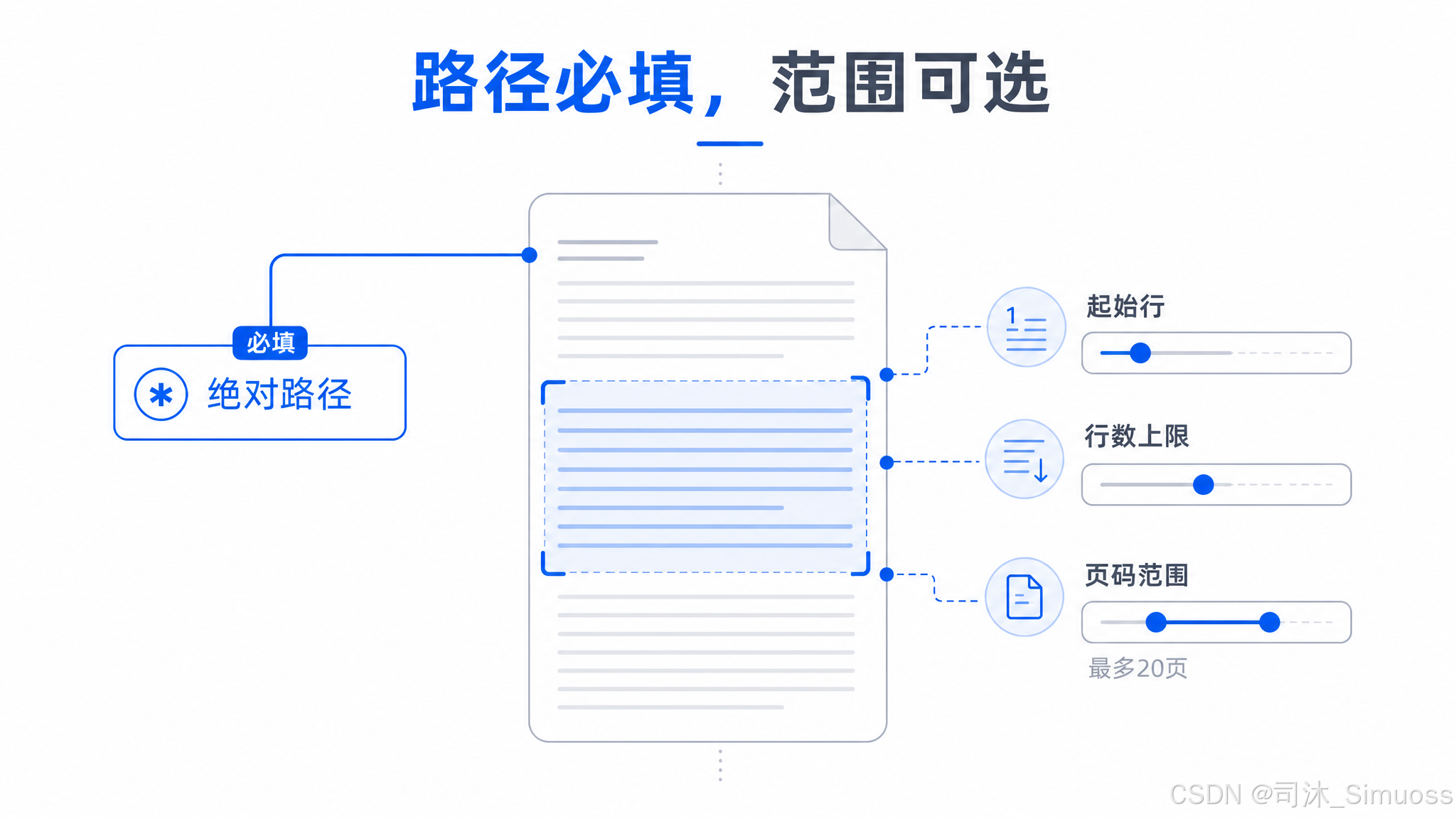
必填:文件路径(必须是绝对路径)。
可选:
offset:从第几行开始读,1 起算,默认 1。传 0 与传 1 效果相同,都从文件第一行开始——这是个历史兼容的边界情况,不是两种不同行为。limit:最多读多少行。不填时读到文件末尾(受字节/token 上限约束)。pages:仅 PDF 有效,格式如"1-5"或"3",单次最多 20 页。
两道大小门槛
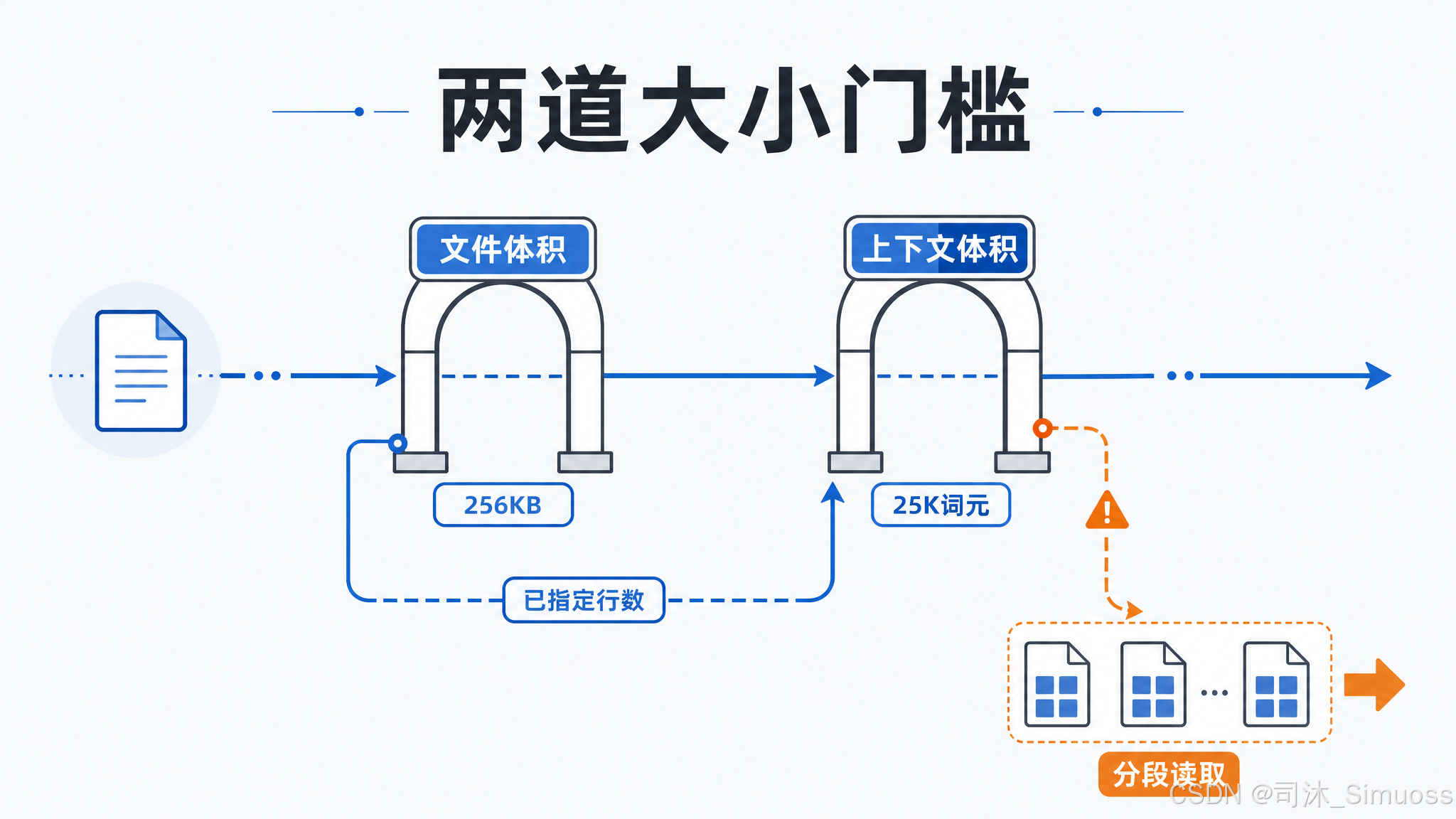
字节门槛(256 KB):针对整个文件的大小,用一次 stat 调用判断,不实际读取内容。超出时在读取前就抛错。有一个重要的特殊情况:如果调用方提供了 limit 参数(指定读多少行),字节门槛不生效——系统认为你已经在做分段读取了,字节门槛只对"读整文件"的情况拦截。
这个设计在代码注释里有明确说明,且有历史背景:团队曾测试过"超限时截断而非报错"的方案(2026 年 3 月),结果工具报错率下降了但平均 token 消耗上升了——截断路径每次都生成约 25,000 token 的内容,而报错路径只生成约 100 字节的错误消息。所以最终保留了报错行为。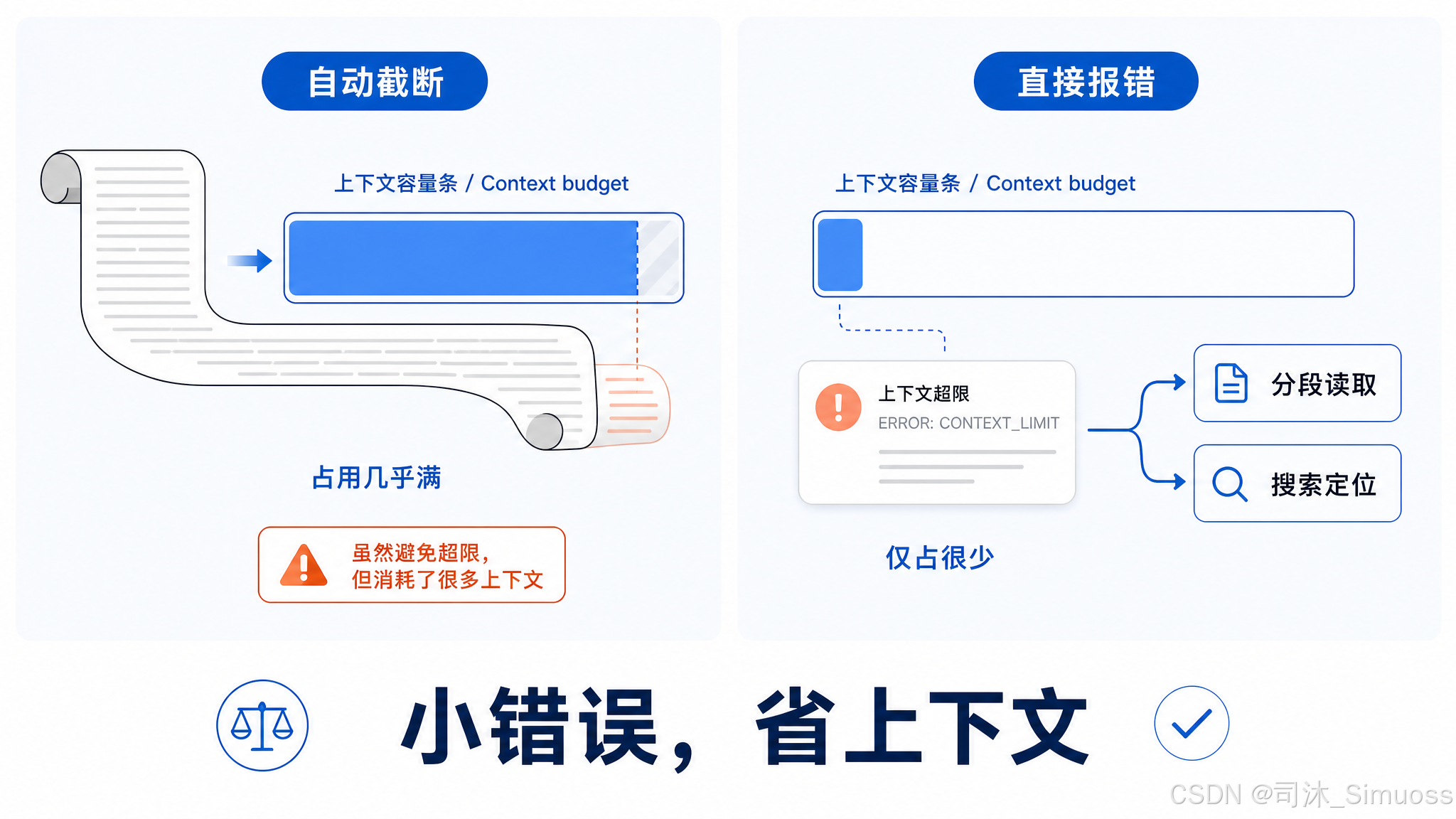
token 门槛(25,000 token):针对实际读出来的内容大小,在读取完成后判断。先做粗略估算(基于文件扩展名的启发式算法),如果估算值超过上限的 1/4 才做精确的 API token 计数;如果精确值超上限,则抛错。
token 超出时返回:
File content (N tokens) exceeds maximum allowed tokens (25000). Use offset and limit parameters to read specific portions of the file, or search for specific content instead of reading the whole file.
两道门槛都可以通过环境变量或 GrowthBook feature flag 调整,会话内固定,不随 flag 动态刷新。
默认每次最多读 2,000 行

文档里明确写了这个默认上限(MAX_LINES_TO_READ = 2000)。这是 prompt 里告知模型的行为约束,鼓励模型主动用 offset/limit 分段读取大文件,而不是一口气请求全部。
去重:文件没变就不重传
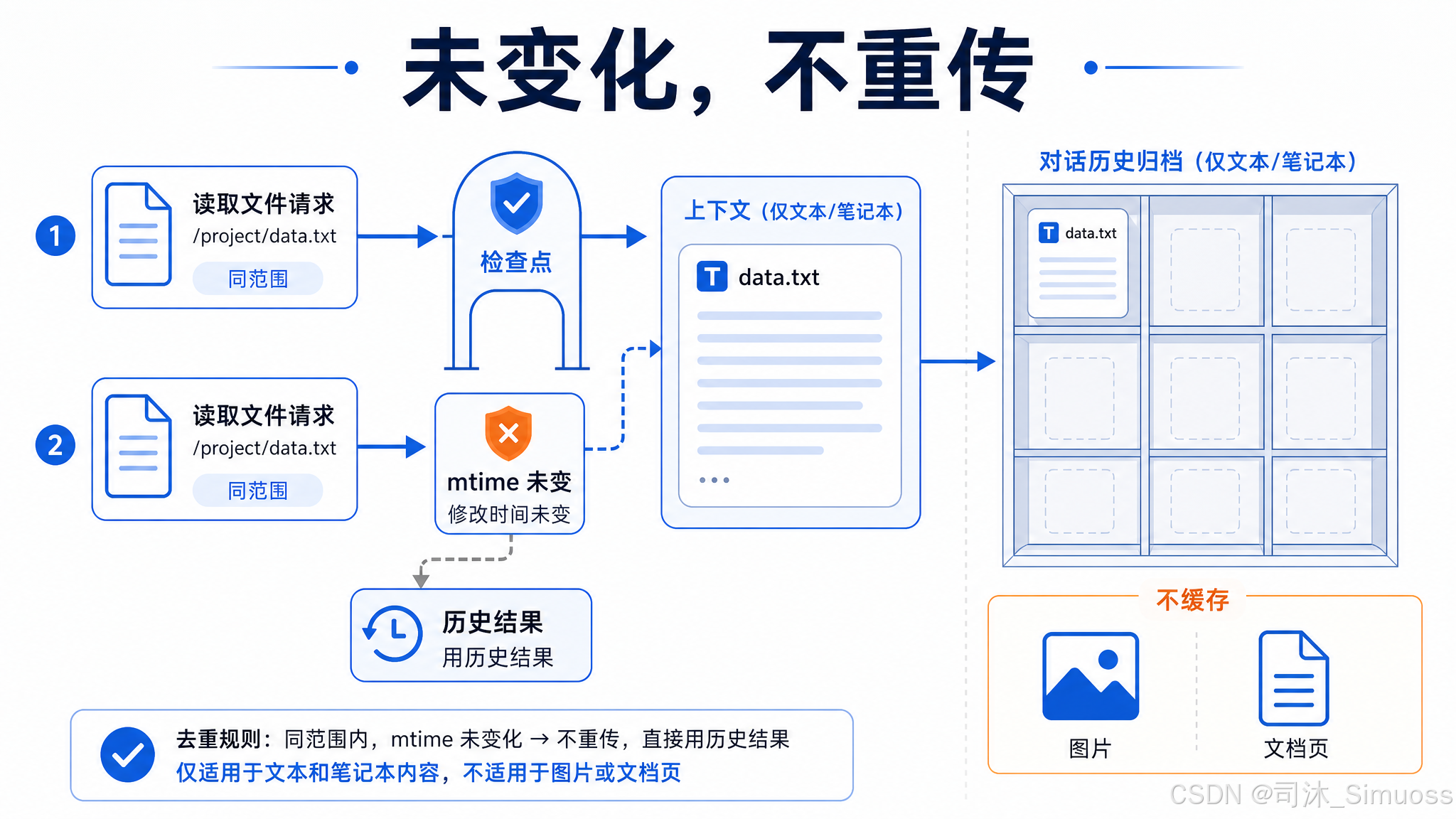
如果同一个文件的同一个范围已经读过,且磁盘上的 mtime 没有变化,Read 工具不重新传输内容,而是返回一个固定的提示字符串:
File unchanged since last read. The content from the earlier Read tool_result in this conversation is still current — refer to that instead of re-reading.
这条字符串出现在 tool_result 里,让模型知道去对话历史里找之前的读取结果,而不是期待新内容。去重只对文本和 notebook 有效,图像和 PDF 不缓存。
文件不存在时
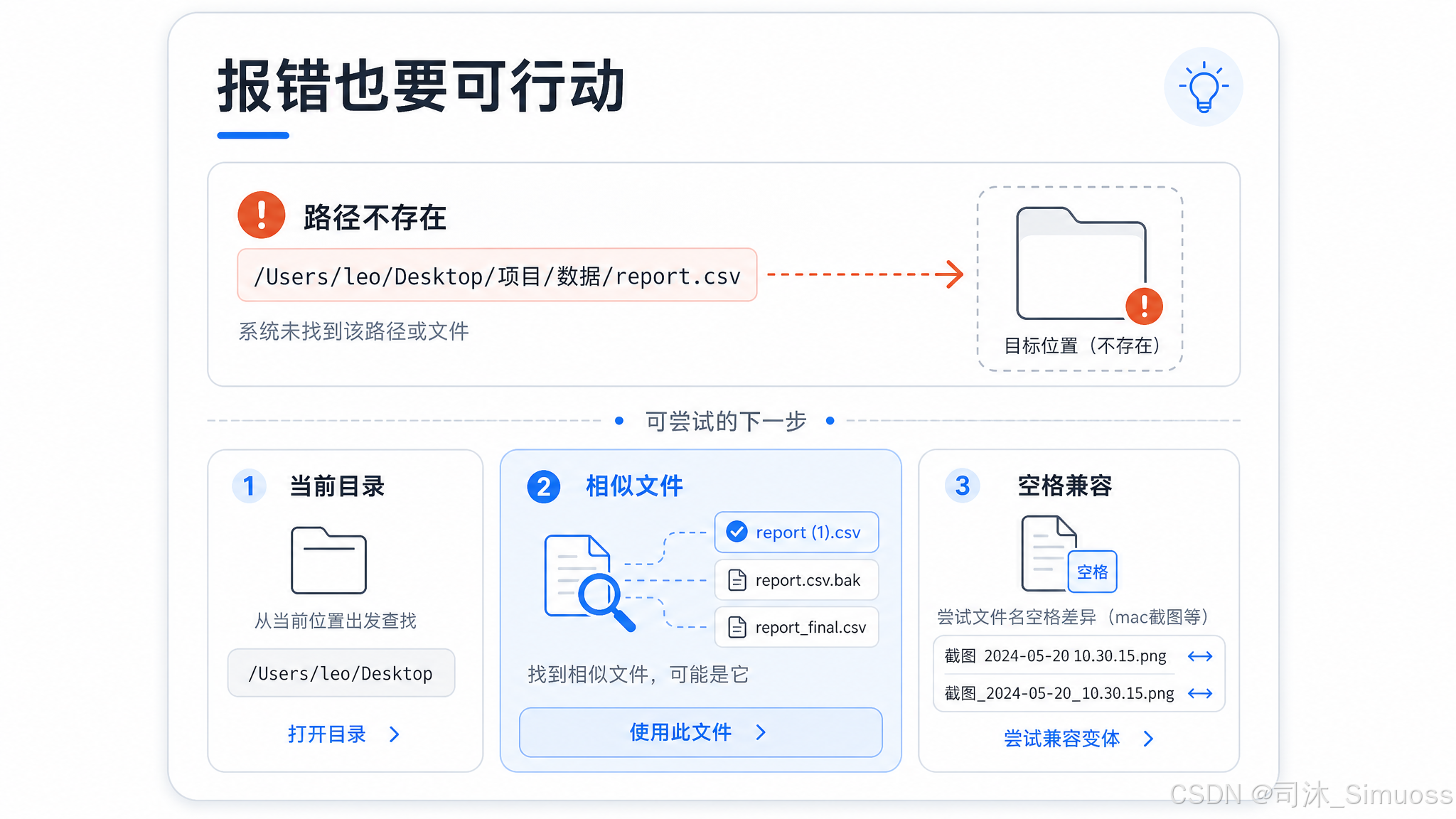
返回错误并附带当前工作目录,尝试给出"你是不是想找这个?"的建议:
File does not exist. Current working directory: /path/to/cwd. Did you mean /path/to/similar-file?
在 macOS 上有个额外处理:截图文件名里 AM/PM 前的空格可能是普通空格或窄不换行空格(U+202F),两种 macOS 版本行为不同。如果路径不存在,系统自动换用另一种空格字符再试一次。
不同类型文件的处理
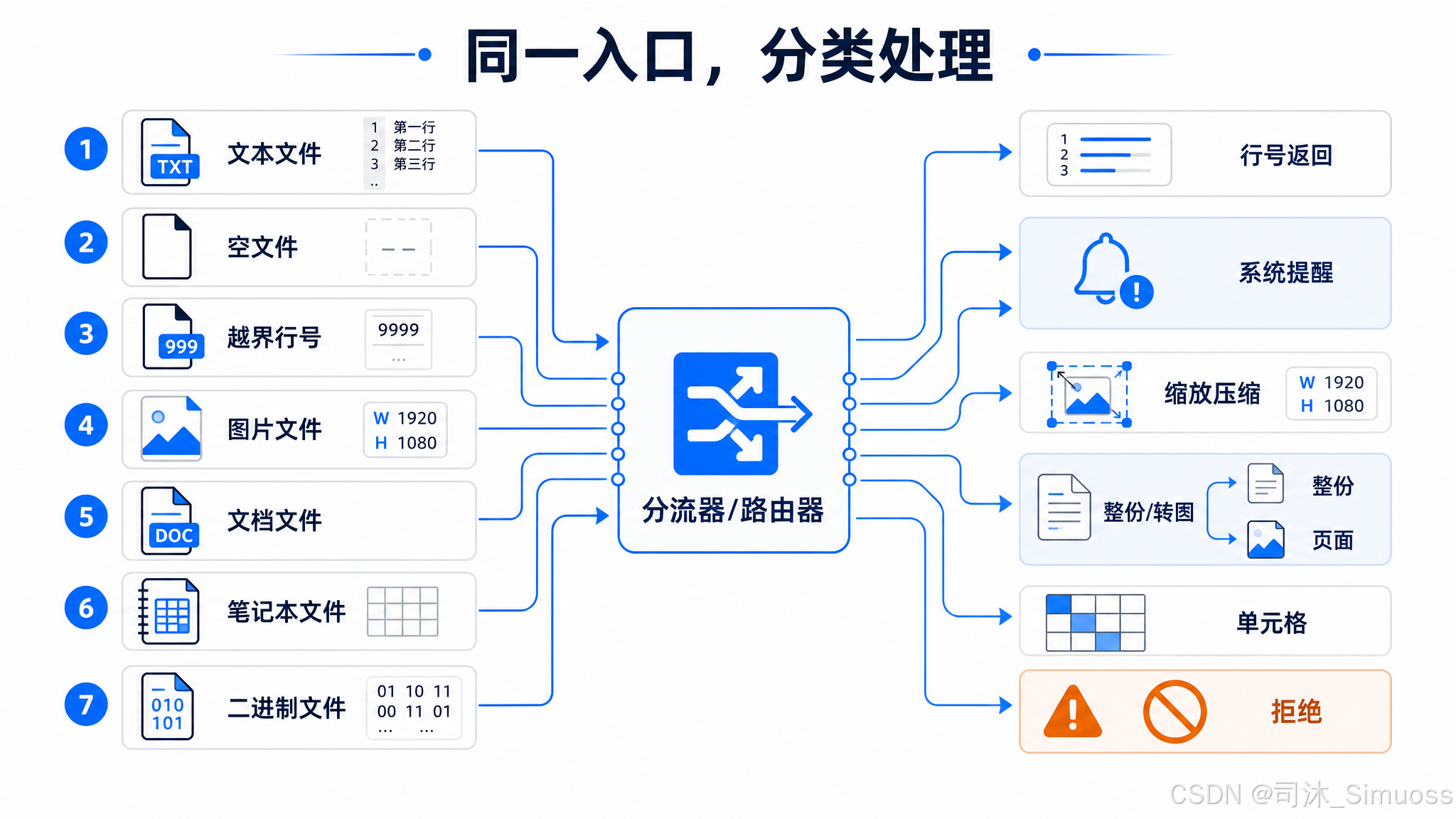
文本:带行号前缀返回,格式 行号→内容(行号右对齐 6 位)。除了少数特定模型,所有文本文件结尾都附加一段安全提示,提醒模型如果内容看起来像恶意软件,可以分析但不能改进它。
空文件或 offset 超出范围:不报错,而是通过 <system-reminder> 包裹的警告信息告知:
- 文件为空:
Warning: the file exists but the contents are empty. - offset 超过文件行数:
Warning: the file exists but is shorter than the provided offset (N). The file has M lines.
图像(png/jpg/jpeg/gif/webp):读入内存后先做标准 resize(保持比例缩小),估算 token 数,如果超过 25,000 token 则做更激进的压缩。压缩失败时最后兜底:强制缩到 400×400 像素,JPEG 质量 20。读取成功后额外注入一条包含宽高信息的附加消息,供模型做坐标定位用。
PDF:模型支持且文件小于约 3 MB 时,整文件作为 document block 传输。否则用 poppler 工具把各页提取为图片传输。不支持 PDF 的模型会收到错误提示和安装 poppler 的方法。
Jupyter Notebook(.ipynb):解析全部 cells(代码、文本、输出)返回。大小超过字节上限时,提示用 Bash + jq 分片读取,附带具体的 jq 命令示例。
二进制文件:在参数校验阶段直接拒绝,不做任何读取:
This tool cannot read binary files. The file appears to be a binary .exe file. Please use appropriate tools for binary file analysis.
危险设备文件:/dev/zero、/dev/random、/dev/urandom、/dev/full、/dev/stdin、/dev/tty、/dev/console、/dev/stdout、/dev/stderr,以及 /dev/fd/0-2、/proc/*/fd/0-2,在校验阶段全部拦截:
Cannot read 'file_path': this device file would block or produce infinite output.
这些路径要么会产生无限输出(/dev/zero),要么会阻塞等待输入(/dev/tty),不拦截就会把进程挂死。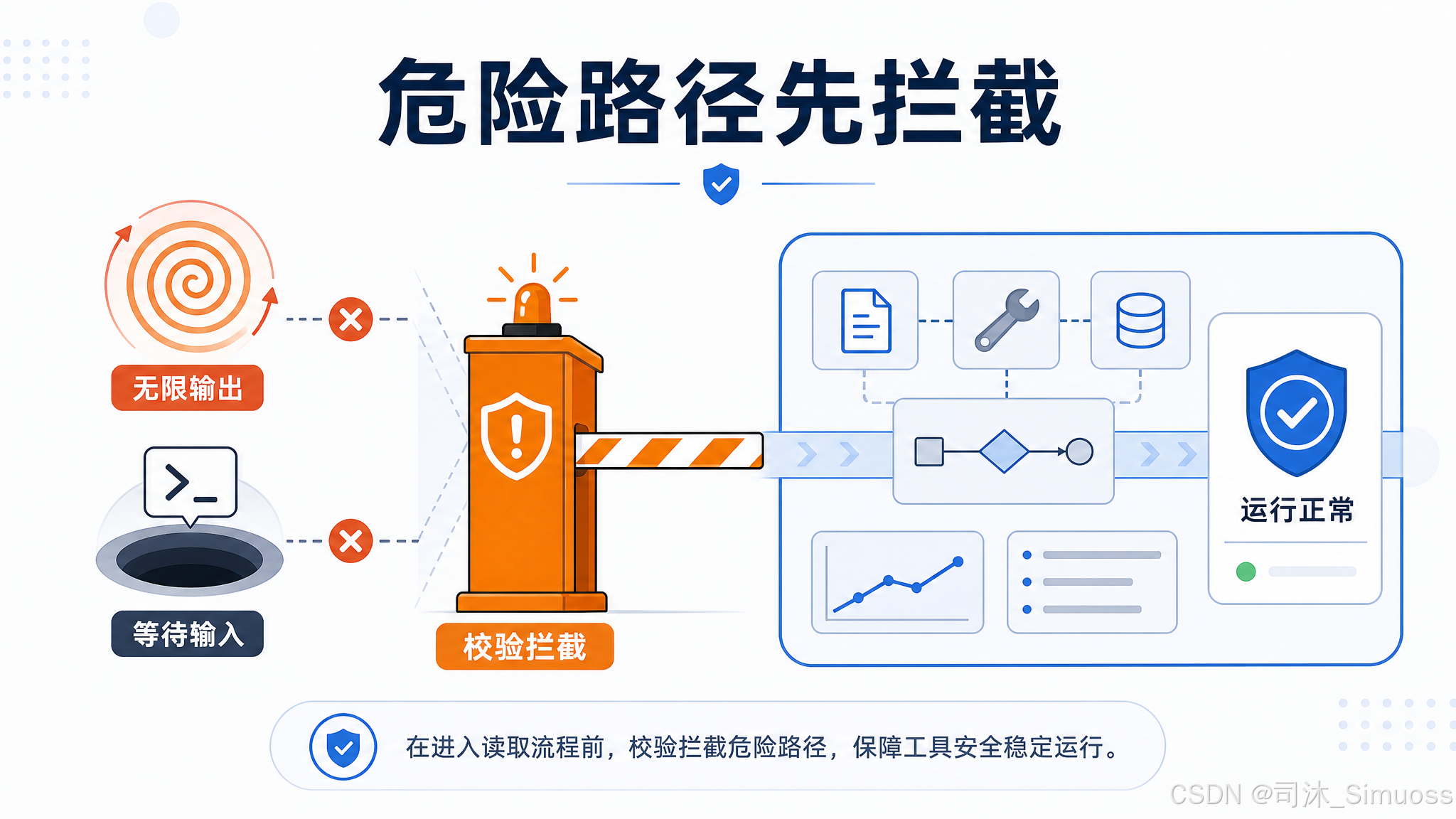
Write(写入文件)
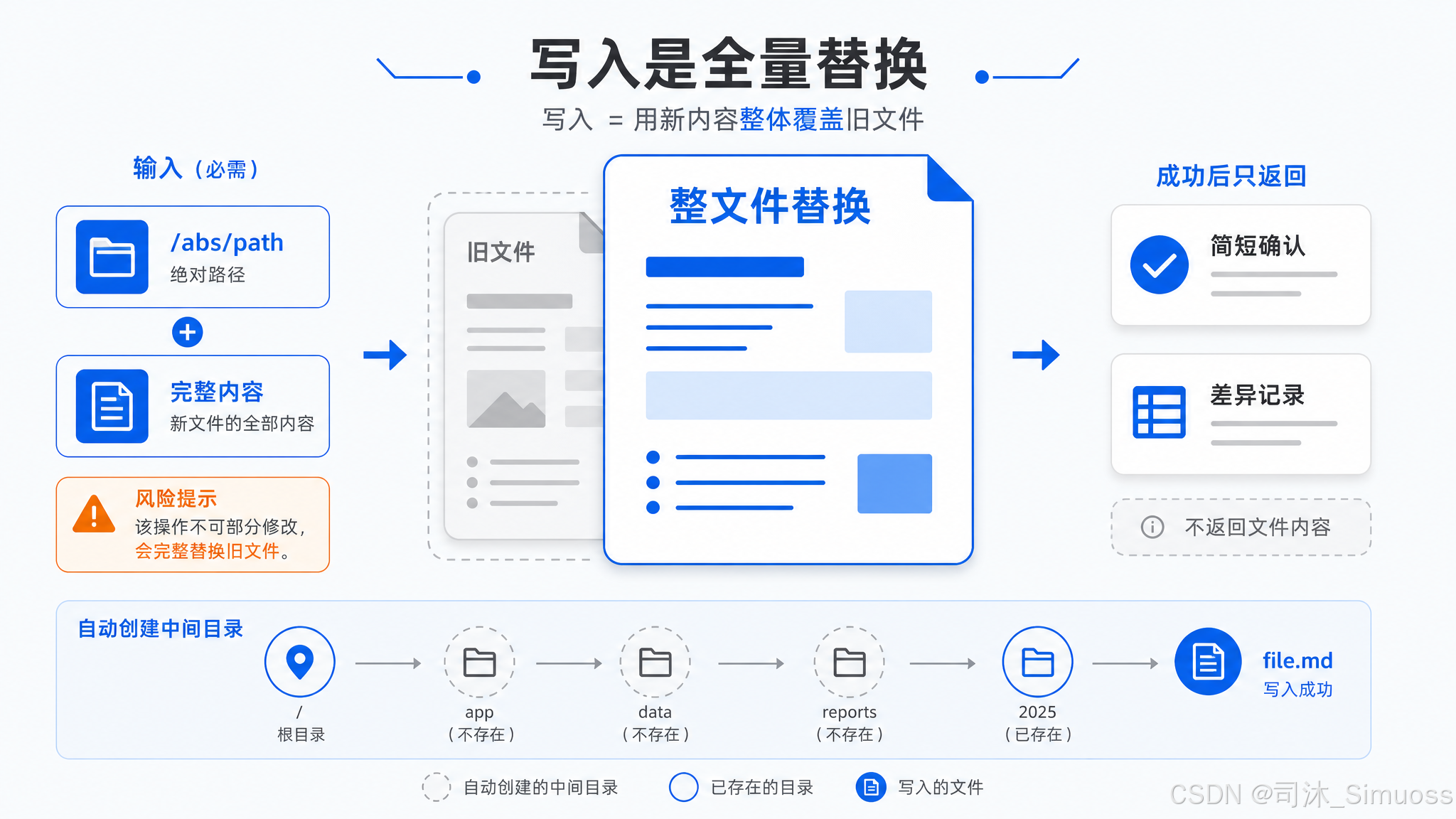
参数
必填:文件路径(绝对路径)、文件内容。仅这两个,没有其他选项。
返回:成功时只返回一句简短确认,不原样返回内容:
- 新建文件:
File created successfully at: /path/to/file - 更新文件:
The file /path/to/file has been updated successfully.
同时附带结构化的 diff patch,供 UI 展示变更记录。
写入前自动创建所有必要的中间目录,不需要提前建目录。
四层拒绝检查(按顺序)
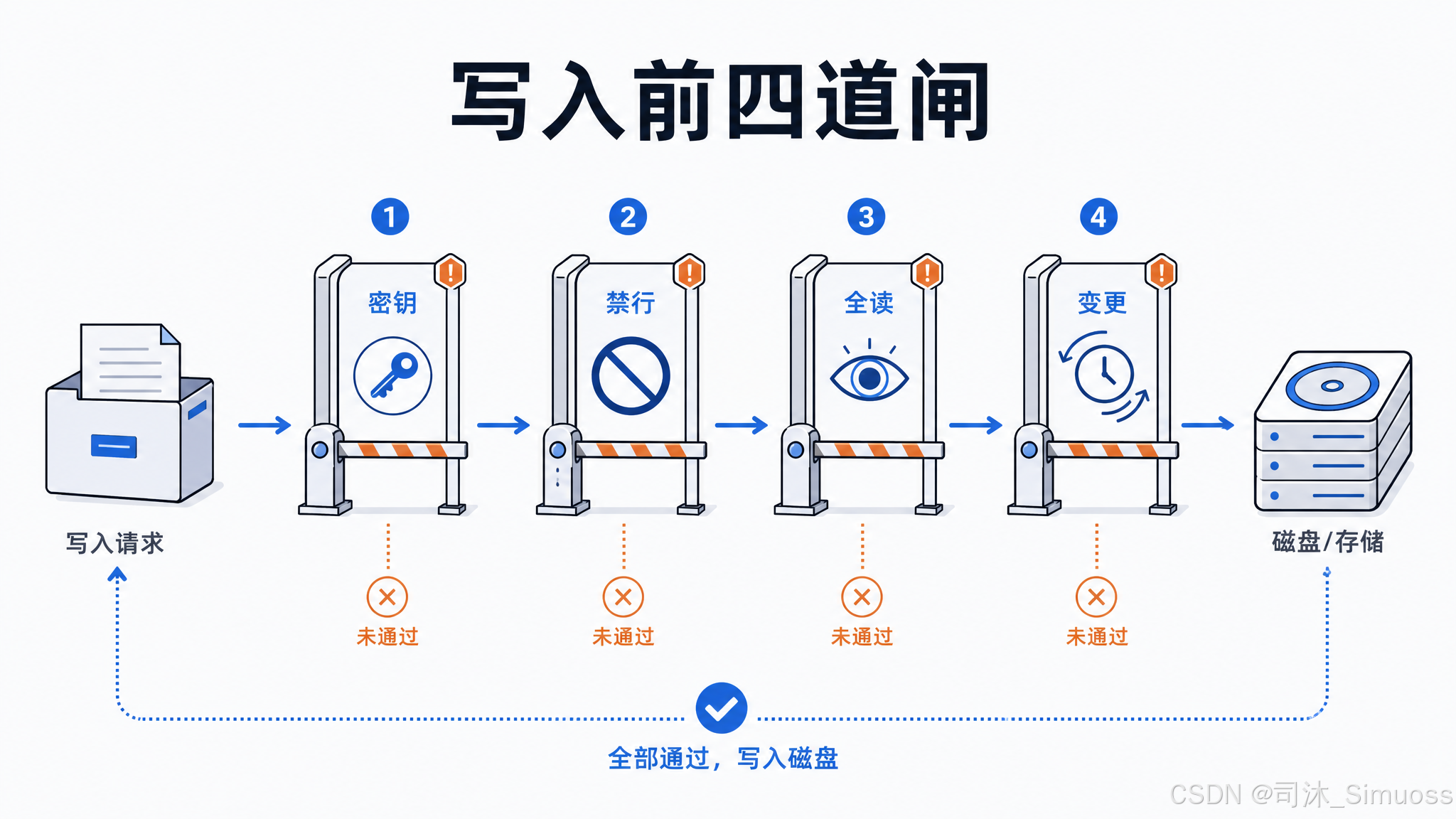
第一层:密钥泄露检测:若写入内容被检测为包含 token、密钥等敏感信息且目标是团队共享记忆文件,直接拒绝。
第二层:路径 deny 规则:目标路径匹配管理员配置的禁止规则时:
File is in a directory that is denied by your permission settings.
第三层:从未完整读过:没有读取记录,或上次读取时用了 offset/limit(只看了部分内容),拒绝:
File has not been read yet. Read it first before writing to it.
这里"分段读不算读过"是刻意的设计:模型在只看了文件局部的情况下,不应该用 Write 把整个文件覆盖。
第四层:读后被其他进程修改:文件的磁盘 mtime 比上次读取时间戳更新,说明 linter、格式化工具或用户在模型读完后改了文件:
File has been modified since read, either by the user or by a linter. Read it again before attempting to write it.
上面四层在参数校验阶段完成,还没有尝试写入。
写入前的最后一道:在真正写入磁盘之前,重新读一次 mtime 再比对一遍,防范校验和写入之间极短时间窗口里发生的并发修改。Windows 上有额外兜底:云同步、杀毒软件可能在不改内容的情况下更新 mtime。如果是完整读取(没有 offset/limit),在 mtime 不一致时再对比一次文件内容,内容相同则放行,避免误判:
File has been unexpectedly modified. Read it again before attempting to write it.
强制 LF 换行
Write 总是用 LF 写入,即使原文件是 CRLF。理由:Write 是全量替换,如果继承旧文件的换行符,当原文件是 CRLF 时,新内容就会变成 CRLF,可能悄悄破坏 Linux/macOS 上的 shell 脚本。强制 LF 让结果可预期。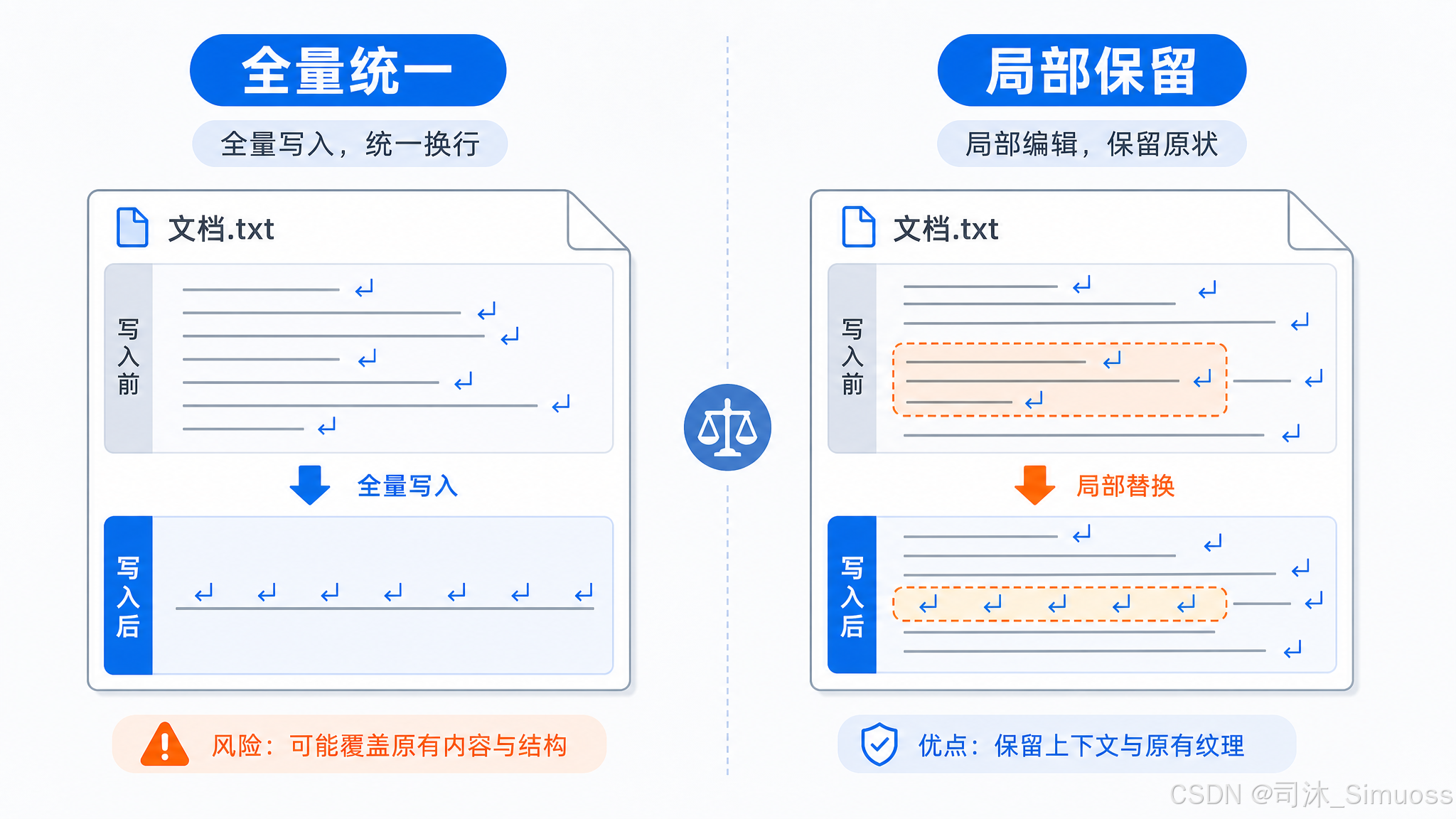
这与 Edit 的行为刻意相反——Edit 做局部修改,保留文件原有换行策略。
写入后的通知链
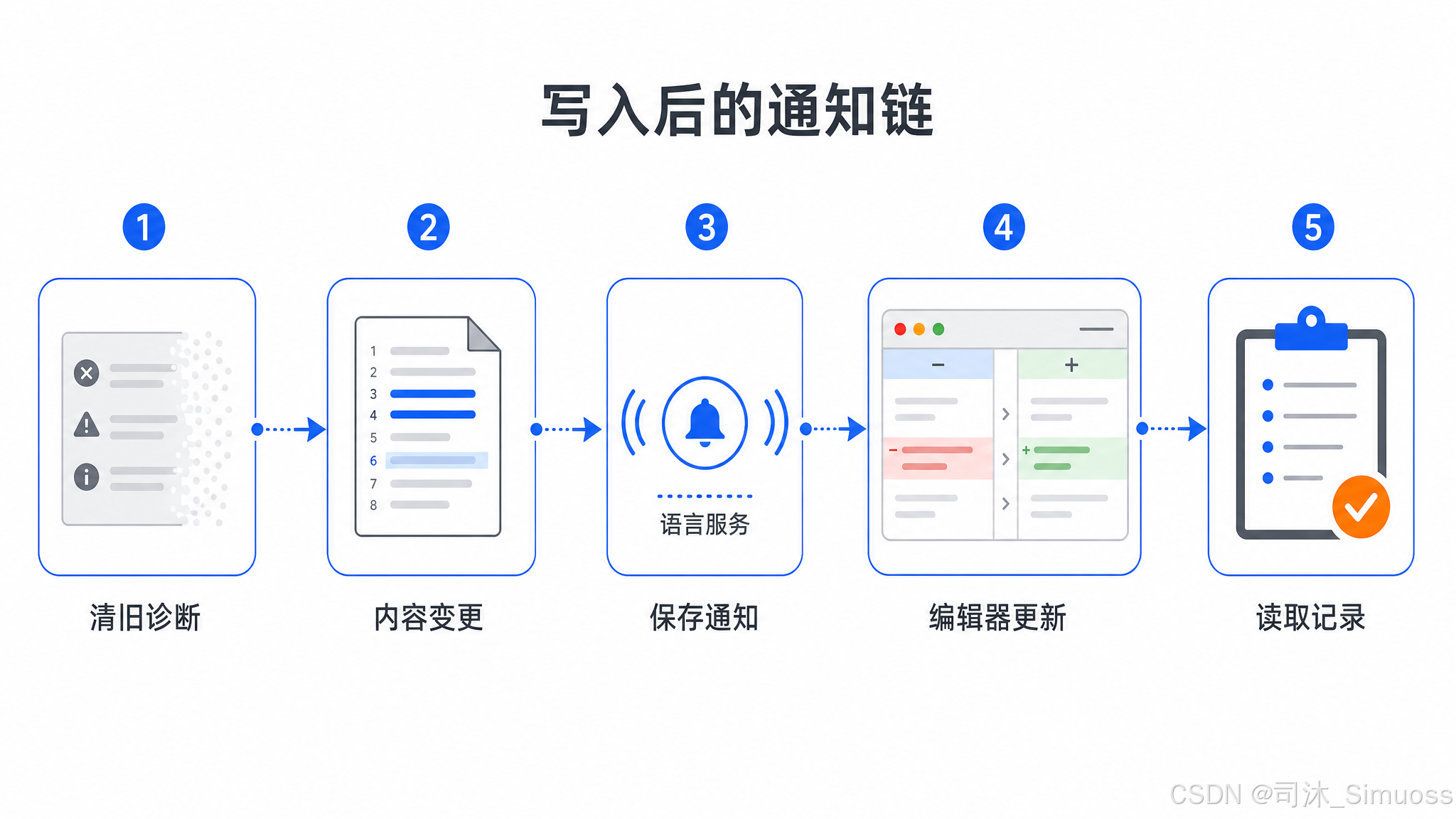
写入成功后,系统依次做:
- 清除 LSP 服务器里这个文件的旧诊断结果
- 通知 LSP 服务器文件内容已变更(触发重新分析)
- 通知 LSP 服务器文件已保存(触发 TypeScript Server 等生成新诊断)
- 通知 VS Code MCP 客户端文件已更新(用于 diff view)
- 更新读取记录(新的 mtime 和内容,供下次写入时的一致性检查用)
Edit(局部编辑)
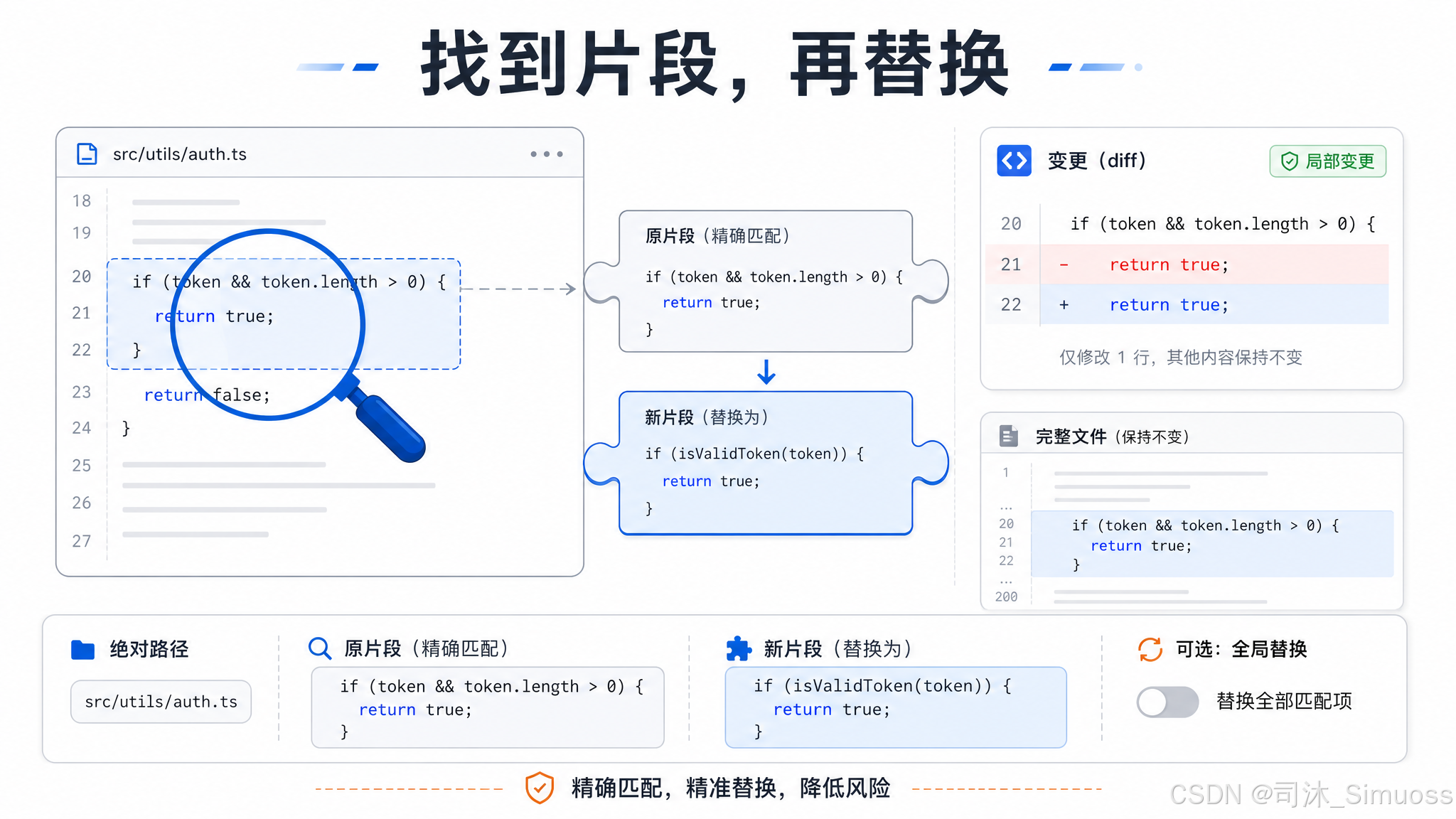
参数
必填:文件路径、old_string(要替换的原文)、new_string(替换成什么)。
可选:replace_all,默认 false。
返回:成功时返回 diff patch,以及原文件完整内容(用于 UI 展示):
- 单处替换:
The file /path/to/file has been updated successfully. - 全部替换:
The file /path/to/file has been updated. All occurrences were successfully replaced. - 用户修改了模型提议的内容:末尾附加
The user modified your proposed changes before accepting them.
九种拒绝情况
参数校验阶段按顺序检查,任何一种命中就拒绝:
errorCode 0:new_string 包含敏感信息且目标是团队记忆文件(同 Write 的密钥检测)
errorCode 1:old_string 和 new_string 完全一样:
No changes to make: old_string and new_string are exactly the same.
errorCode 2:路径被 deny 规则拦截:
File is in a directory that is denied by your permission settings.
errorCode 3:old_string 为空但文件已存在且有内容(试图用 Edit 当 Write 用):
Cannot create new file - file already exists.
errorCode 4:文件不存在(old_string 非空时),附带相似路径建议。
errorCode 5:Jupyter Notebook 文件,Edit 不支持,需用专门工具:
File is a Jupyter Notebook. Use the NotebookEdit to edit this file.
errorCode 6:文件从未完整读过(同 Write 的第三层检查):
File has not been read yet. Read it first before writing to it.
errorCode 7:读后被其他进程修改(同 Write 的第四层检查):
File has been modified since read, either by the user or by a linter. Read it again before attempting to write it.
errorCode 8:old_string 在文件中根本找不到:
String to replace not found in file.\nString: [old_string的内容]
errorCode 9:找到多处匹配但 replace_all 为 false:
Found N matches of the string to replace, but replace_all is false. To replace all occurrences, set replace_all to true. To replace only one occurrence, please provide more context to uniquely identify the instance.\nString: [old_string的内容]
errorCode 10:文件超过 1 GiB:
File is too large to edit (N GB). Maximum editable file size is 1.00 GiB.
引号归一化
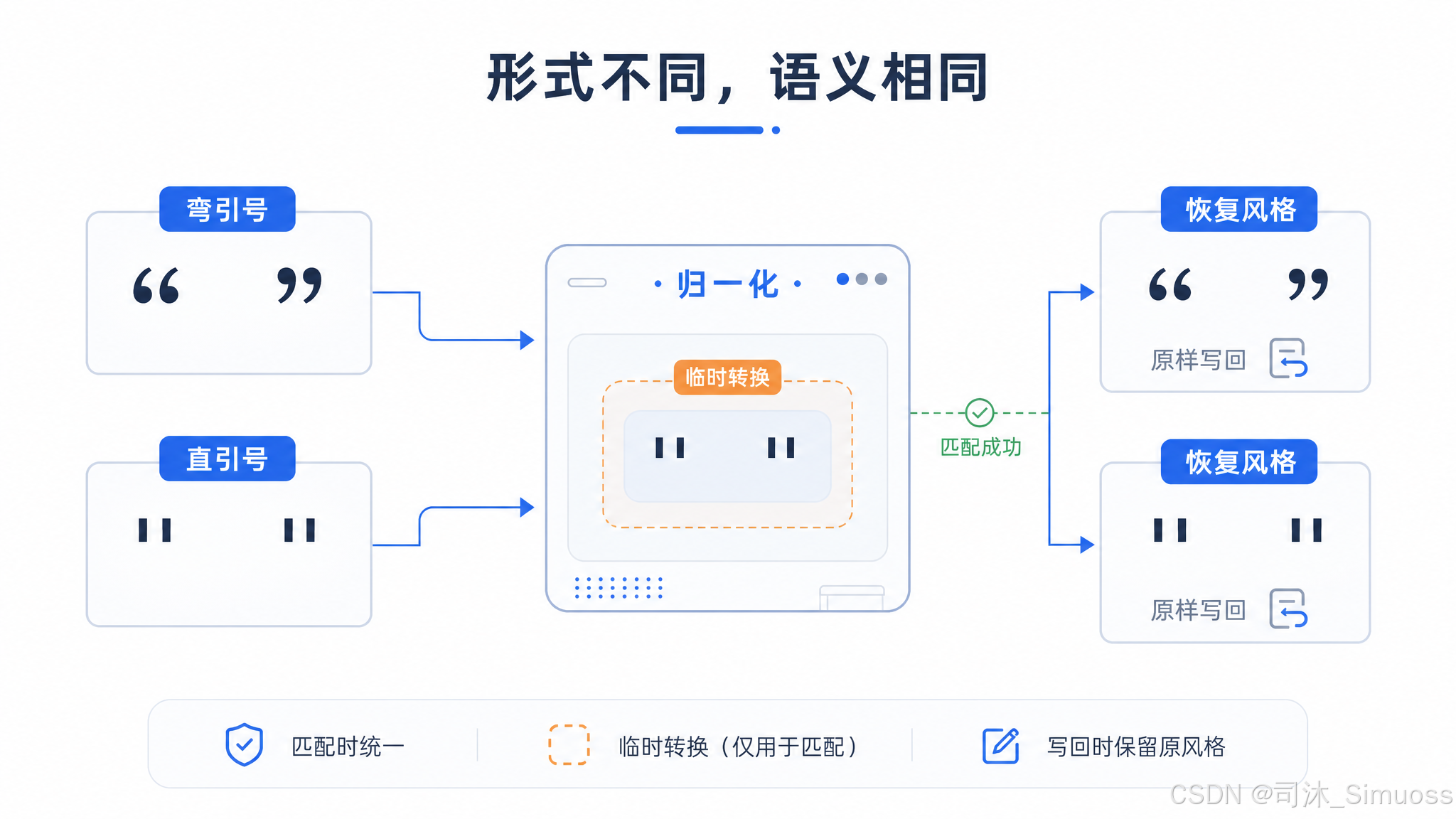
精确匹配失败后,系统做第二次尝试:把 old_string 和文件内容里的弯引号(" " ' ')全部归一化成直引号再匹配。匹配成功后,写入时把 new_string 里的直引号恢复为文件原有的弯引号风格。这样模型生成的直引号可以匹配排版软件生成的弯引号文档。
编码检测
读取文件时检查前两个字节:如果是 0xFF 0xFE,识别为 UTF-16LE 编码,否则按 UTF-8 处理。这覆盖了 Windows 上常见的 UTF-16LE 文件(如某些配置文件)。
保留换行符风格
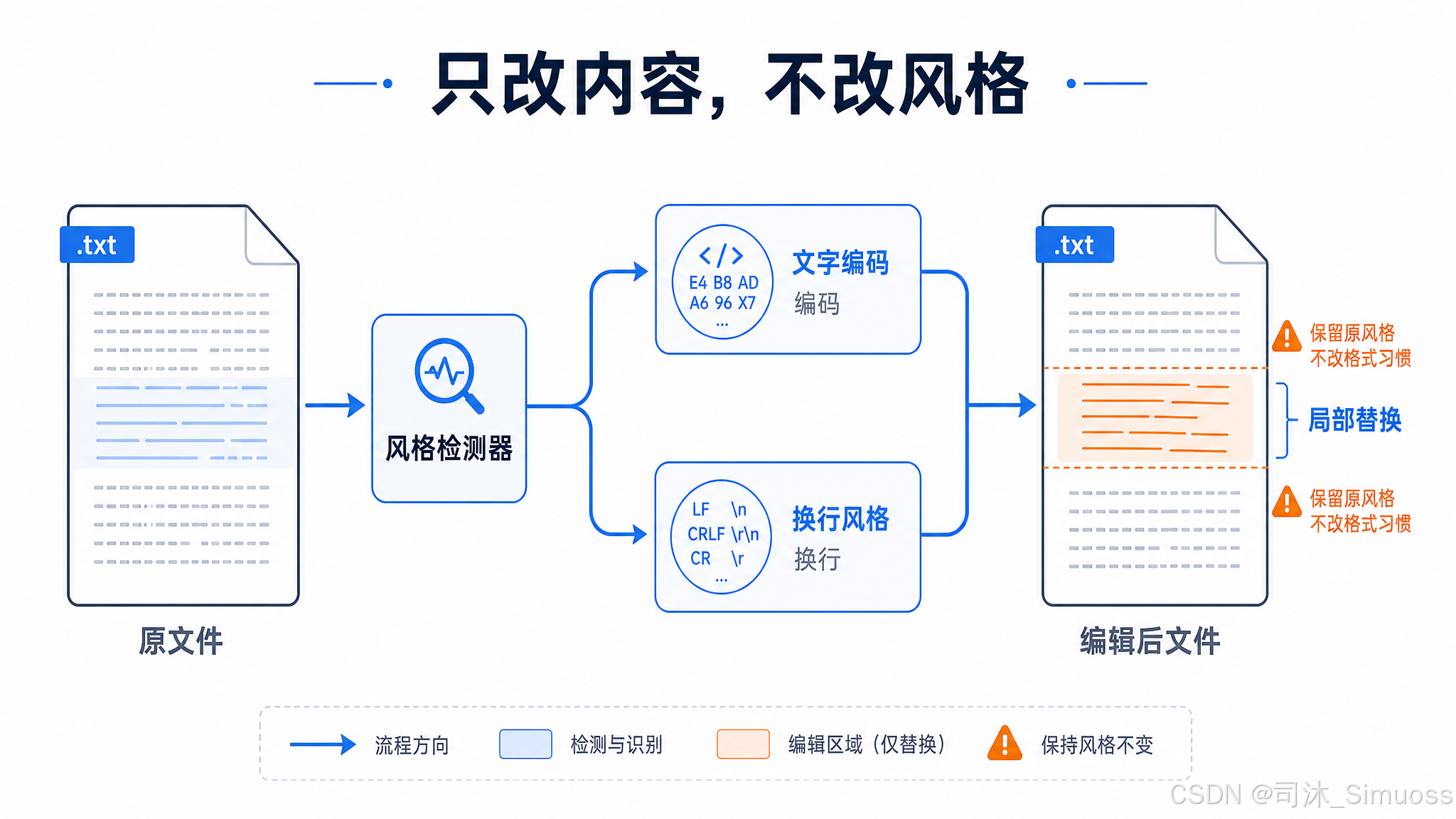
写入时按原文件检测到的换行符(CRLF 或 LF)保持一致,不强制转换。局部编辑不应改变整个文件的风格。
创建新文件
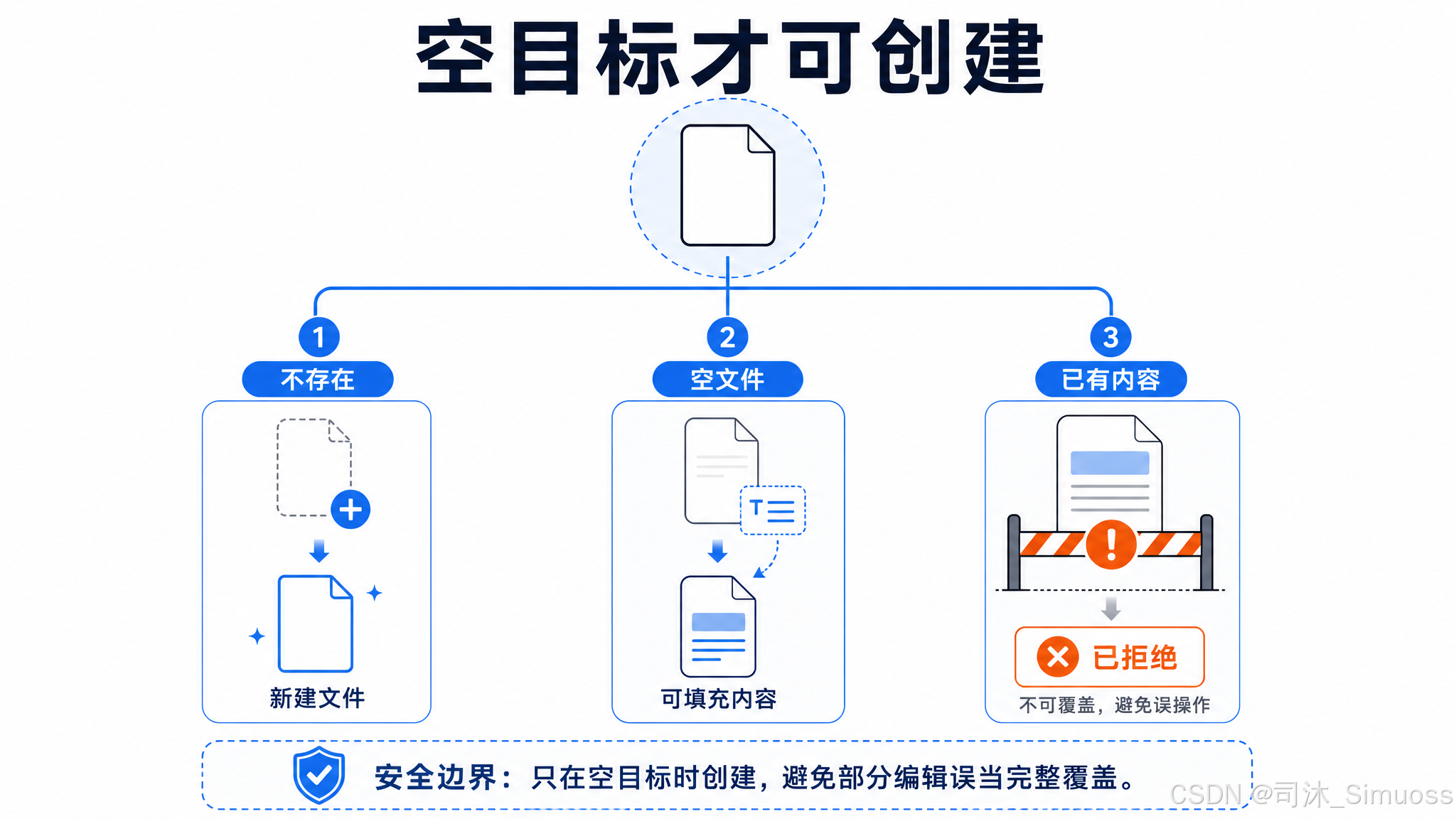
old_string 为空且文件不存在:创建文件,内容为 new_string。
old_string 为空且文件存在但为空:用 new_string 填充空文件。
old_string 为空且文件存在且有内容:拒绝(errorCode 3)。
写入后同样触发 LSP 通知链
与 Write 完全相同:清旧诊断 → didChange → didSave → VS Code 通知 → 更新读取记录。
Glob(列出文件)
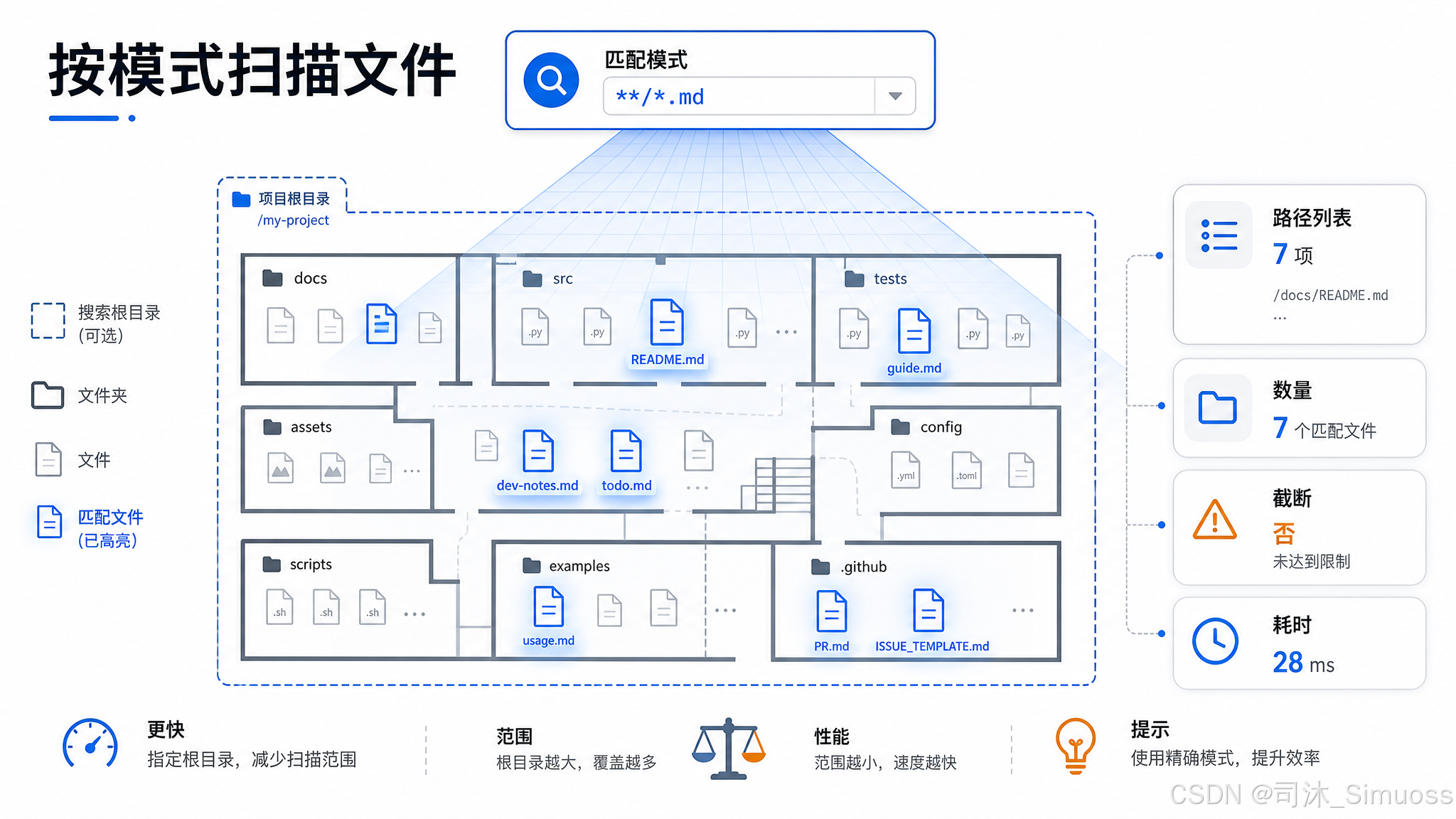
参数
必填:pattern,glob 模式(如 **/*.ts、src/{a,b}/**)。
可选:path,搜索根目录,省略时用当前工作目录。
返回:
{
filenames: string[], // 相对于 cwd 的路径列表
numFiles: number,
truncated: boolean,
durationMs: number
}
底层是 ripgrep
Glob 调用 rg --files 加上 --glob <pattern> 和 --sort=modified。这不是 Node.js 原生的 glob 实现,用 ripgrep 的好处是:速度快、与 Grep 使用同一套 ignore 规则,行为一致。
默认行为:显示隐藏文件,不遵守 gitignore
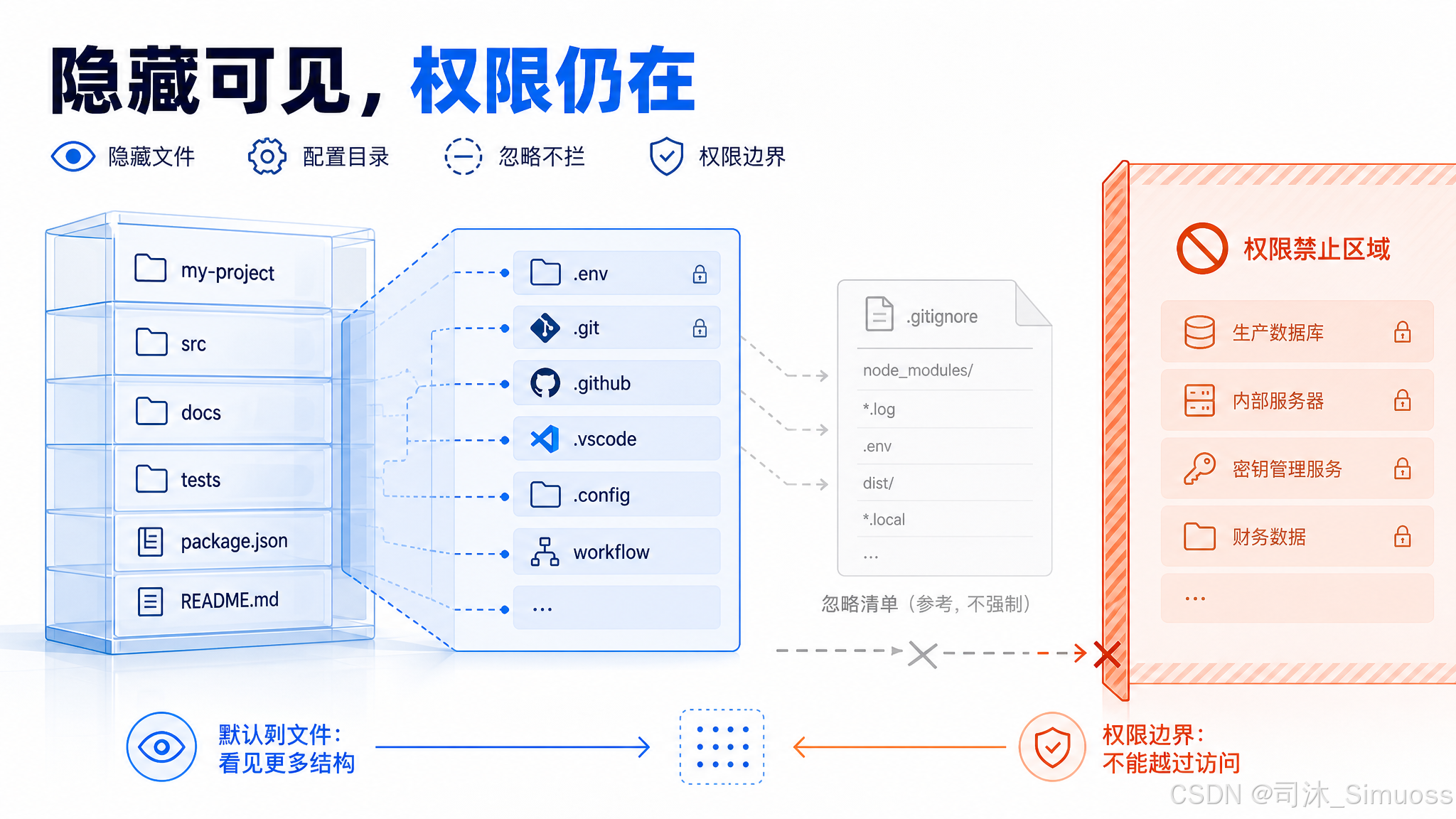
Glob 默认传 --hidden(显示 . 开头的文件)且不传 --no-ignore(不强制遵守 .gitignore)。这与命令行 glob 的直觉相反,但在代码分析场景合理:模型需要能看到 .github/、.env 等目录,gitignore 是给构建工具用的,不是给代码分析用的。
权限系统的 deny 规则仍然生效,它们被转成 ripgrep 的 --glob !... 排除参数。
结果数量上限
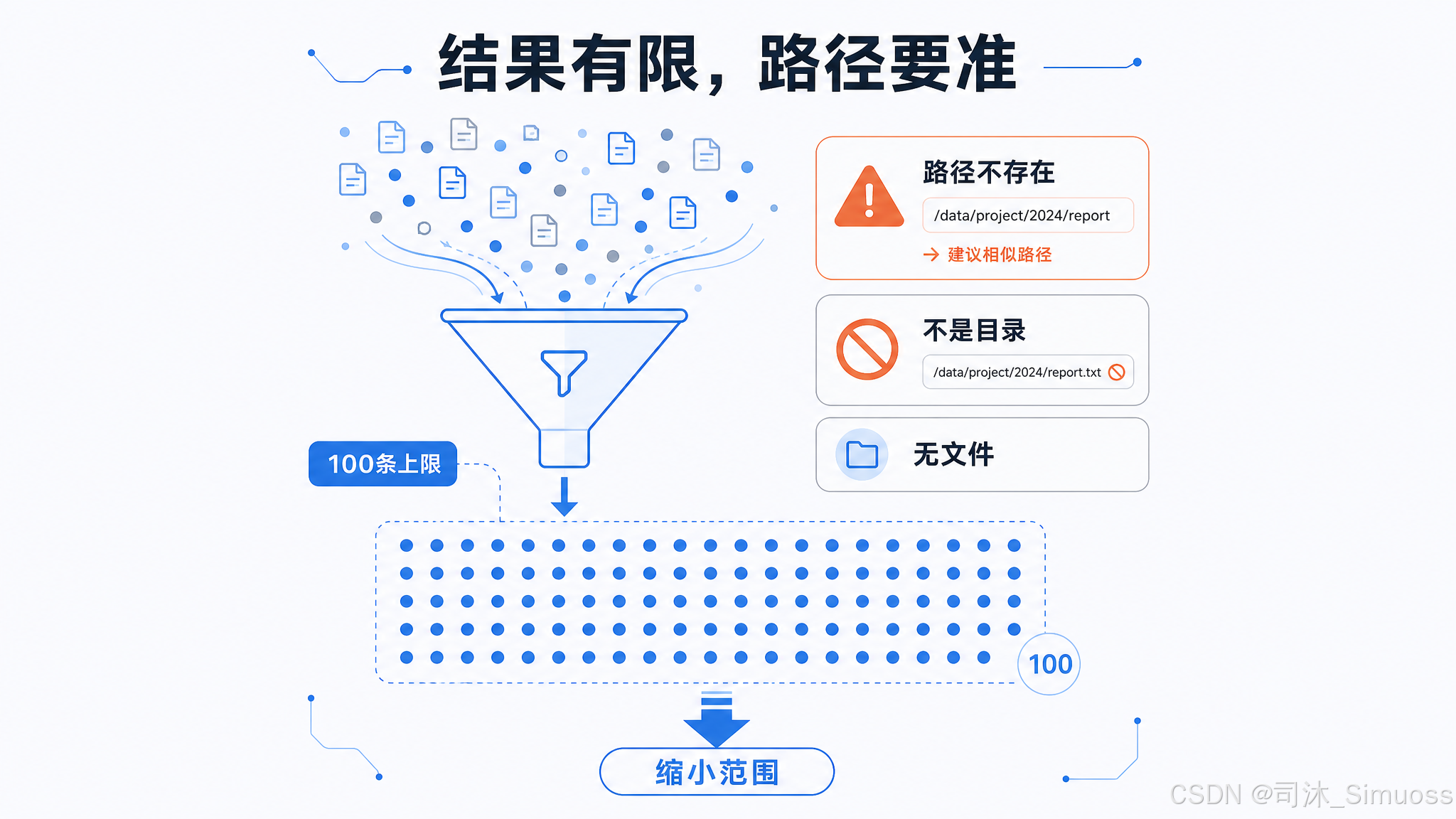
默认 100 条,可通过上下文配置调整。超出时在结果末尾追加:
(Results are truncated. Consider using a more specific path or pattern.)
没有匹配时返回:No files found
path 参数校验
如果传了 path:
- 目录不存在:errorCode 1,同样附带相似路径建议
- 路径存在但不是目录:errorCode 2,
Path is not a directory: /path
结果排序与相对化
结果按修改时间从新到旧排序(--sort=modified)。测试环境下按路径名字符串排序,保证测试结果确定性。所有路径相对化到 cwd,减少 token 消耗。
Grep(搜索文件内容)
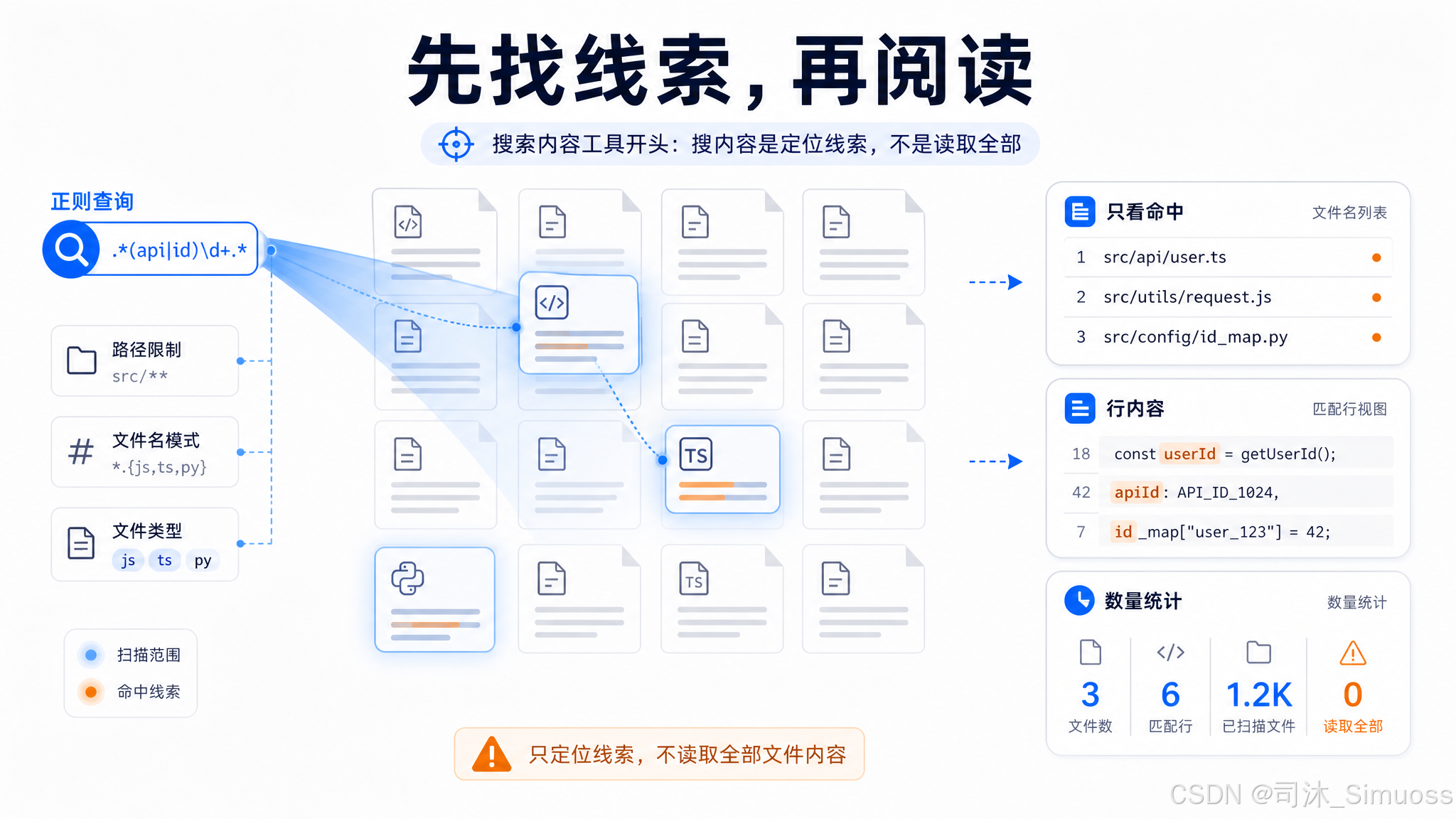
参数
必填:pattern(正则表达式)。
常用可选:
path:搜索目录或文件,省略时用 cwdglob:文件名过滤(如*.ts,支持逗号分隔多个,支持{a,b}brace 展开)type:文件类型(如js、py),比 glob 更高效output_mode:files_with_matches(默认,只返回文件名)、content(返回匹配行内容)、count(统计每文件匹配数)-i:大小写不敏感-n:在 content 模式下显示行号(content 模式默认开启)-A/-B/-C或context:匹配行前后上下文行数multiline:多行模式,.可匹配换行符head_limit:结果条数上限,默认 250,传 0 表示不限offset:跳过前 N 条结果,配合head_limit分页
防止结果爆炸的两道机制
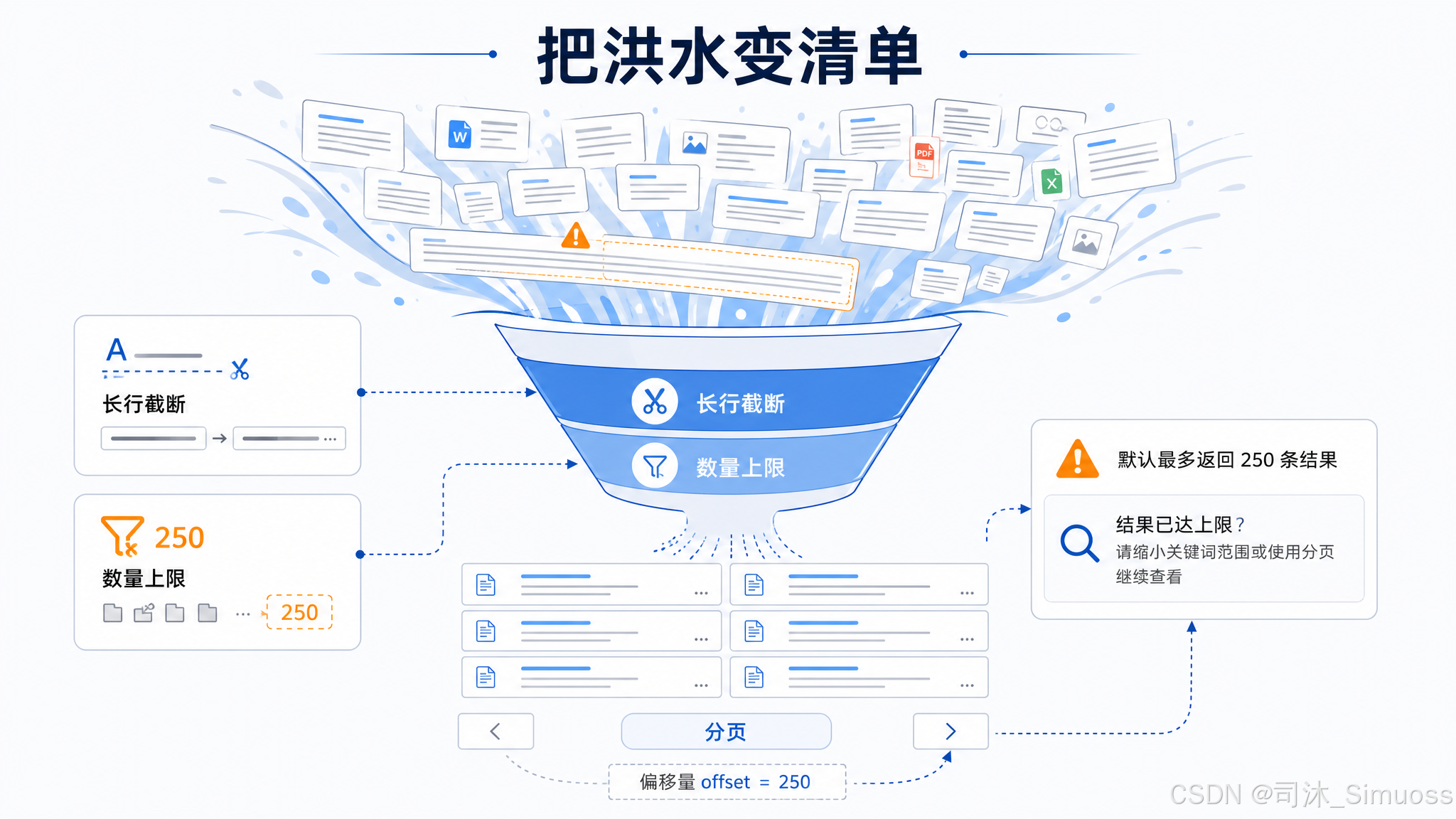
--max-columns 500:每行内容超过 500 个字符的部分被裁掉,并附上截断说明。这主要针对 minified JavaScript 和 base64 数据——这类行可能有几十 KB,对搜索结果毫无价值。
head_limit(默认 250):最多保留 250 条结果。当截断发生时,模型侧 tool_result 末尾会有分页信息:
[Showing results with pagination = limit: 250]
模型可以用 offset 参数翻页,或缩小搜索范围。
代码注释里说明了 250 这个默认值的选取逻辑:没有限制的 content 模式搜索可能撑满约 20KB 的落盘阈值,在搜索密集的会话里可能用掉 6,000~24,000 token。250 在"够用于探索"和"不撑爆上下文"之间取得平衡。
自动排除 VCS 目录
.git、.svn、.hg、.bzr、.jj、.sl 这六个版本控制目录被硬编码排除,不走用户配置。
超时返回错误,而非空结果
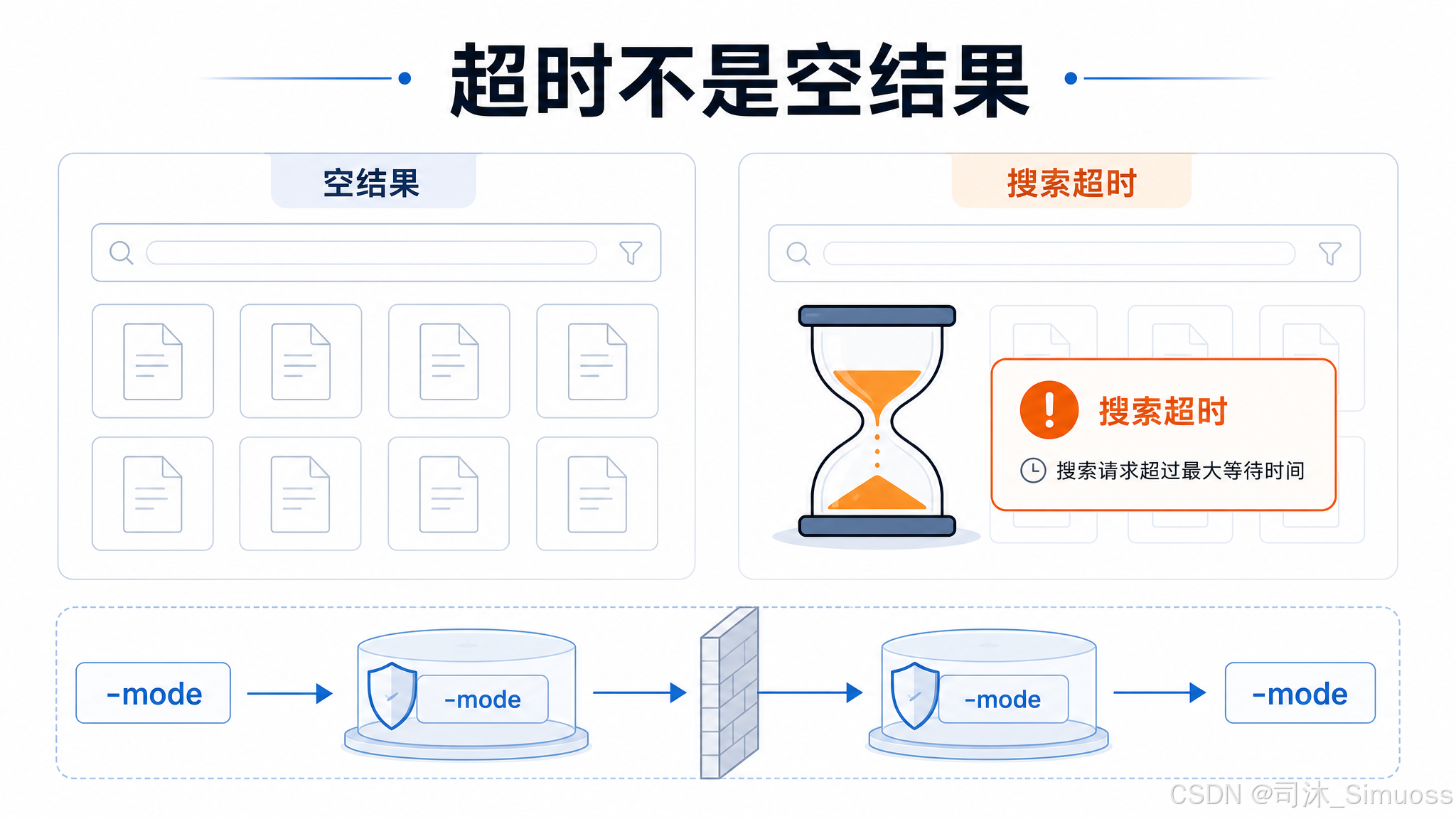
Grep 底层 ripgrep 有超时限制(默认 20 秒,WSL 环境 60 秒)。超时时抛出 RipgrepTimeoutError 类型的错误,不是返回空结果。这个设计防止模型误以为"搜索结果为空"——空结果和超时是完全不同的两件事。
模式以 - 开头时的特殊处理
如果搜索模式以 - 开头(如 -foo),直接传给 ripgrep 会被解析为命令行参数。系统自动改为 -e 模式 的形式传递,避免出错。
结果格式与相对化
files_with_matches 模式:结果按 mtime 排序(测试环境按文件名),所有路径相对化到 cwd。
content 模式:每行格式为 相对路径:行号:内容,路径已相对化。
工具结果大小上限 20,000 字符(比 Read/Write/Edit 的 100,000 更严格),因为搜索结果天然是多文件多行格式,token 消耗更大。
Bash(执行命令)
参数
必填:command(命令字符串)。
可选:
timeout:超时毫秒数,默认 120,000ms(2 分钟),上限 600,000ms(10 分钟)。两者都可通过环境变量BASH_DEFAULT_TIMEOUT_MS/BASH_MAX_TIMEOUT_MS调整。description:对命令的说明,展示给用户,不影响执行。run_in_background:后台运行,工具调用立刻返回任务 ID 和输出文件路径。
Shell 和工作目录
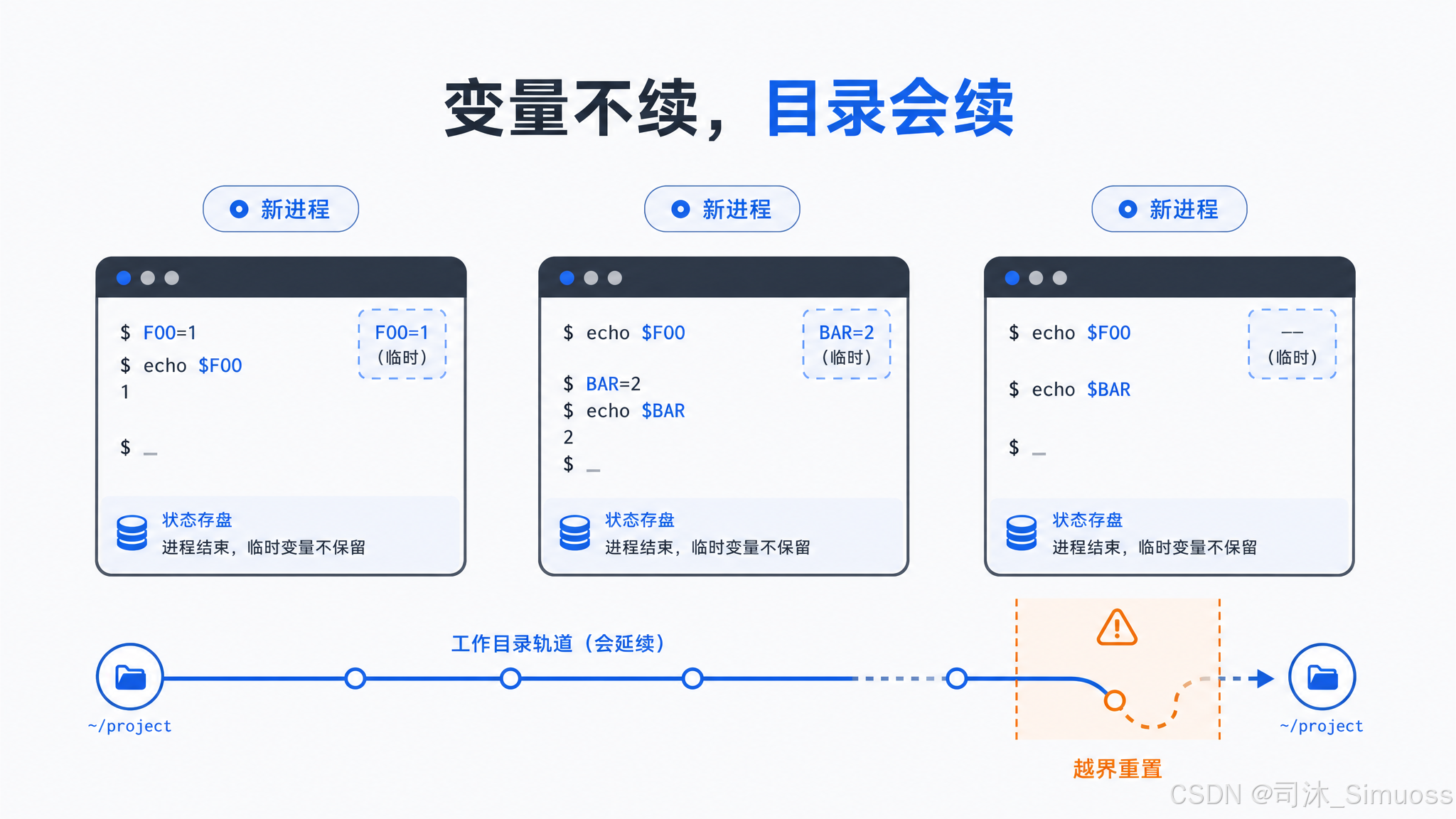
每条命令启动一个新的 shell 进程(bash 或 zsh,可用 CLAUDE_CODE_SHELL 指定),不保持持久 shell 会话。这意味着每条命令的 shell 变量都是全新的——上一条 export FOO=bar,下一条命令里没有 $FOO。
工作目录是个例外:cd 命令会把新路径写到一个状态文件里,下一条命令的进程从这里读取起始目录。如果当前目录漂移到了允许的工作路径之外,系统自动重置回最初的目录,并在 stderr 里附加:
Shell cwd was reset to /original/path
stdout 和 stderr 合并
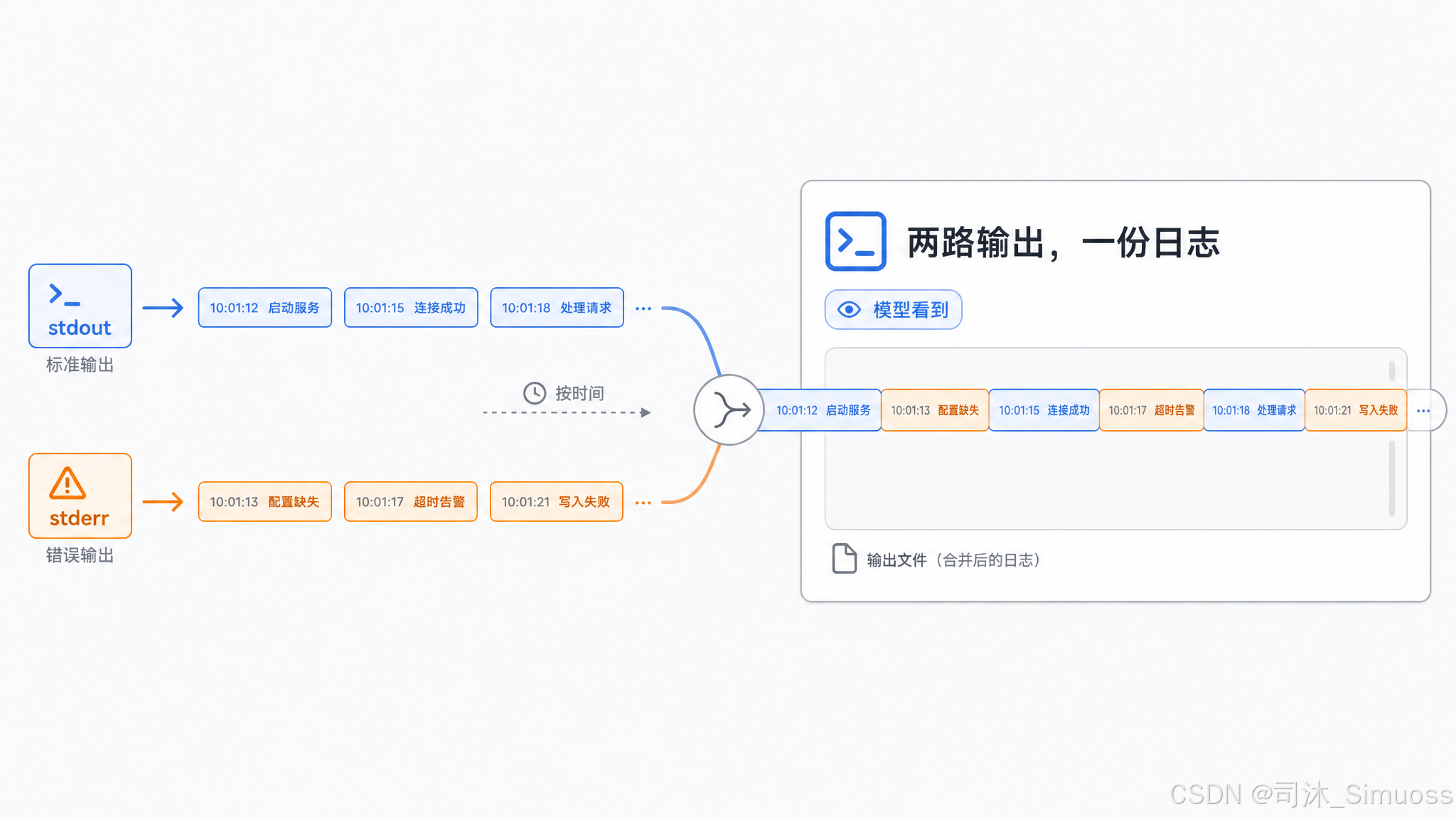
命令的 stdout 和 stderr 指向同一个输出文件,按时间顺序交错在一起。模型看到的是一份合并的完整输出。这和在终端直接运行命令看到的效果相同,符合直觉。
输出截断格式
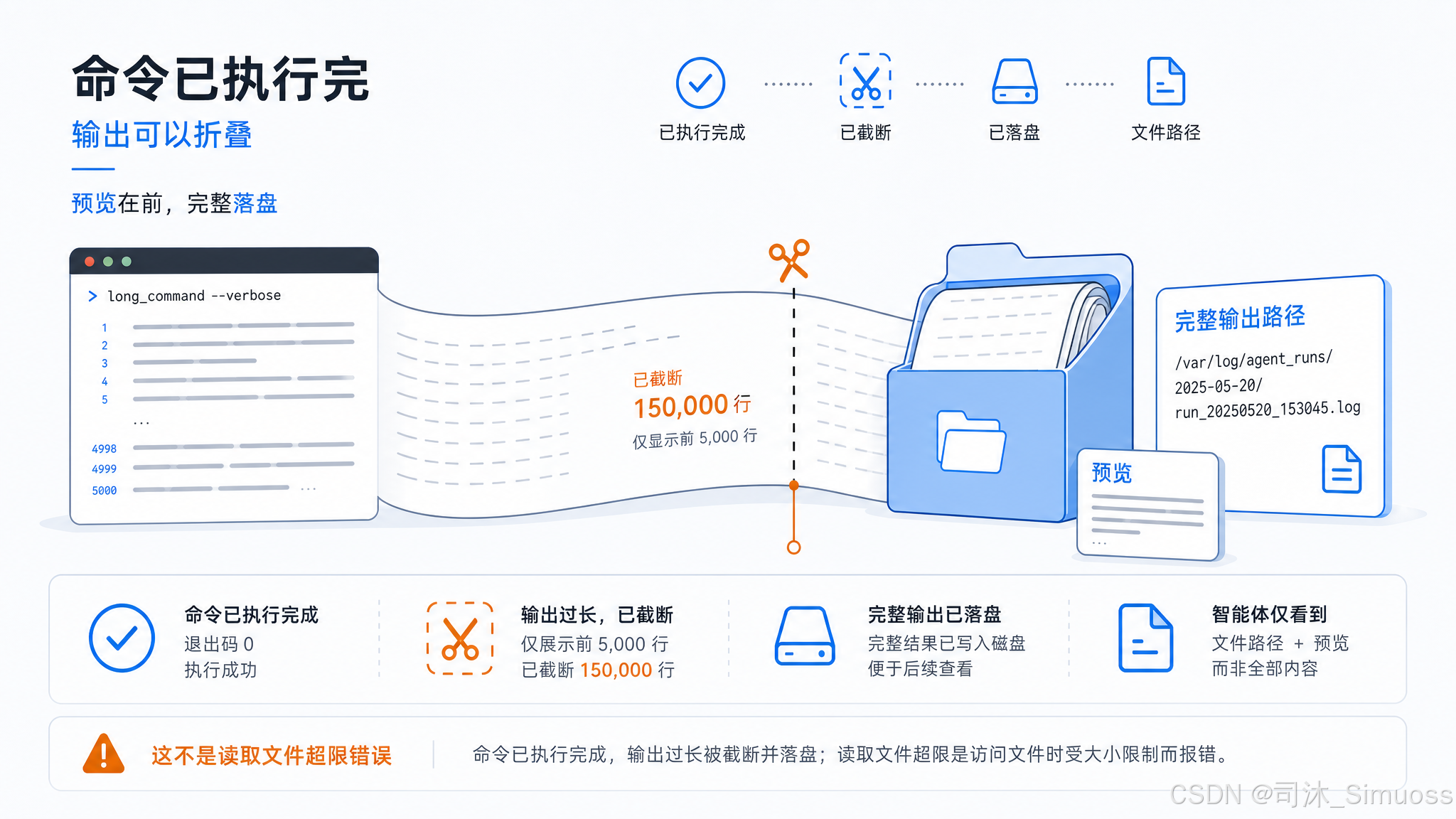
命令输出超过 getMaxOutputLength()(默认 30,000 字符,上限 150,000,由 BASH_MAX_OUTPUT_LENGTH 控制)时,保留前半部分,后面附上:
... [N lines truncated] ...
其中 N 是被截掉的行数。这与文件读取的"报错而非截断"策略不同——命令已经执行完了,截断已有输出是合理的降级。
超大输出(超过截断上限且落盘):完整内容写到磁盘,模型看到的工具结果替换为文件路径加前 2,000 字节预览。
图像输出的自动识别
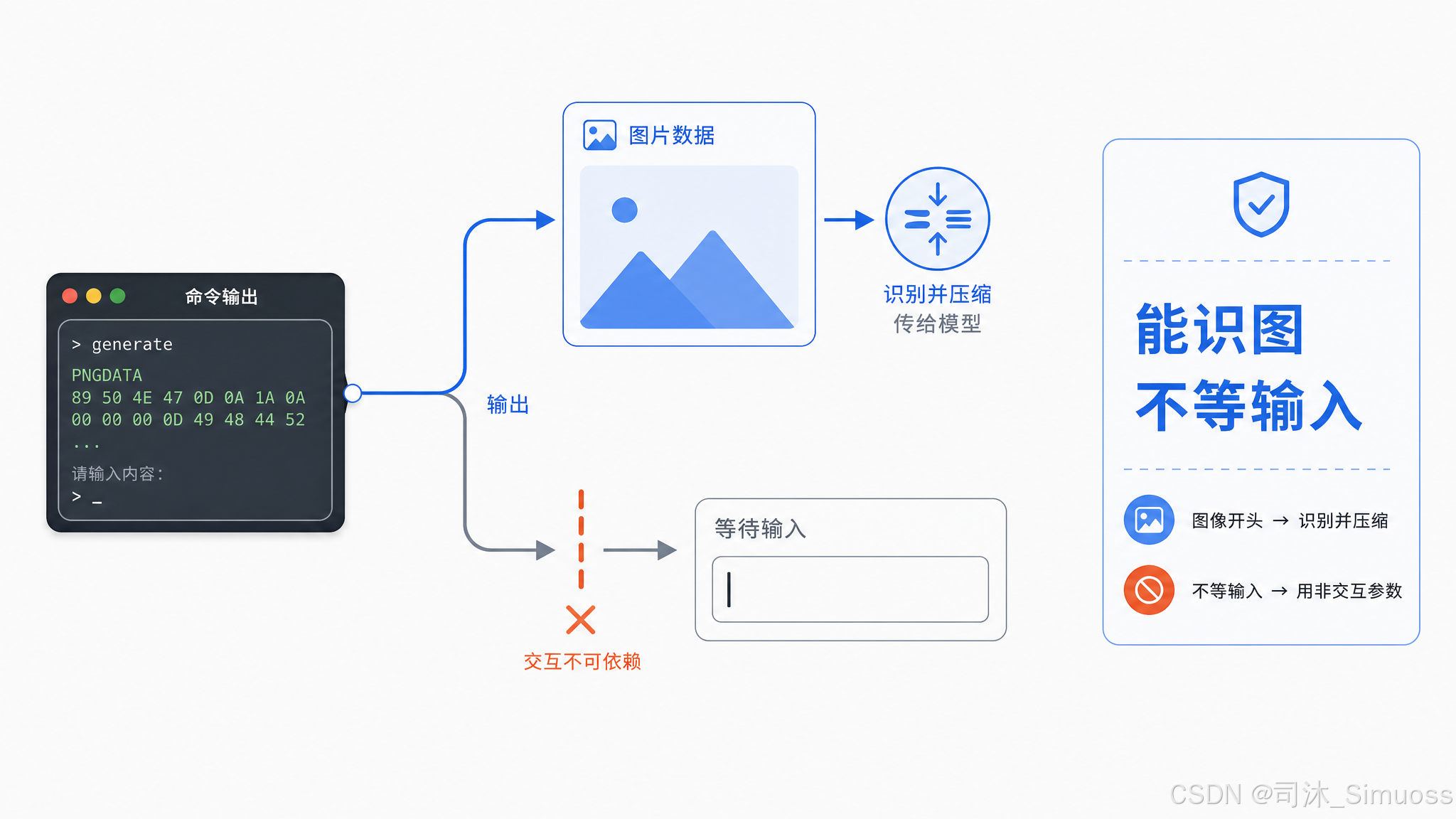
如果 stdout 以 data:image/...;base64, 开头,工具自动把内容识别为图像 data URI,构造成图像 block 传给模型,而不是作为文本字符串。图像在传输前会做 resize 和压缩处理,防止超大图像被 API 拒绝。
交互式命令
命令的 stdin 连接到 /dev/null,任何等待用户输入的命令会立刻收到 EOF 或者卡住直到超时。系统提示里会告知模型这个限制,鼓励用 -y、--non-interactive 等标志或其他方式代替。
后台与自动转后台
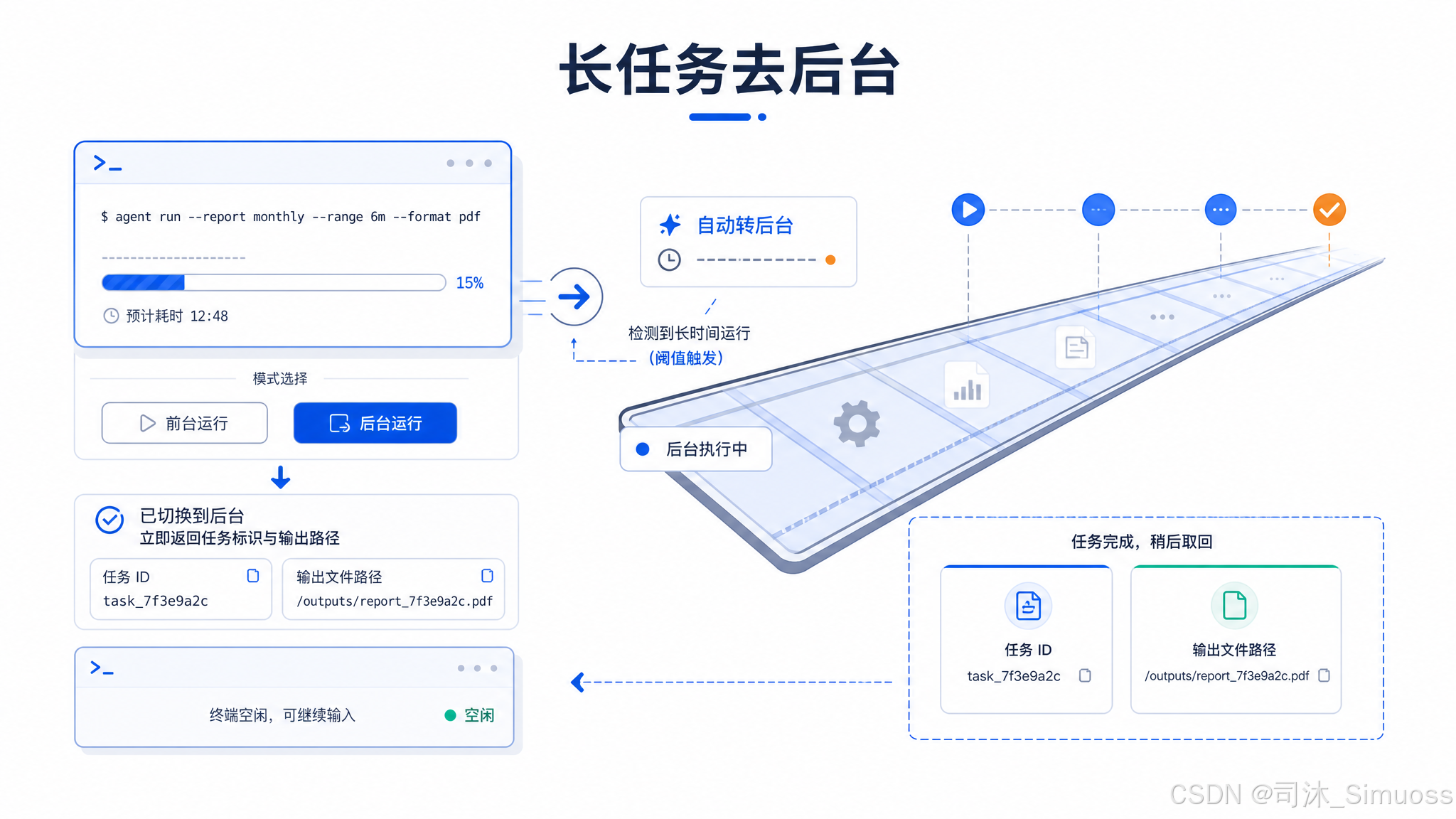
run_in_background: true 时立刻返回,子进程在后台持续运行,最终通过任务通知告知父 Agent 结果。
某些模式下(如 assistant 模式),如果一条命令超过 15 秒仍未完成,系统自动把前台任务转为后台,返回已启动的通知,防止前台界面长时间阻塞。
PowerShell(Windows 命令执行)
与 Bash 的关系
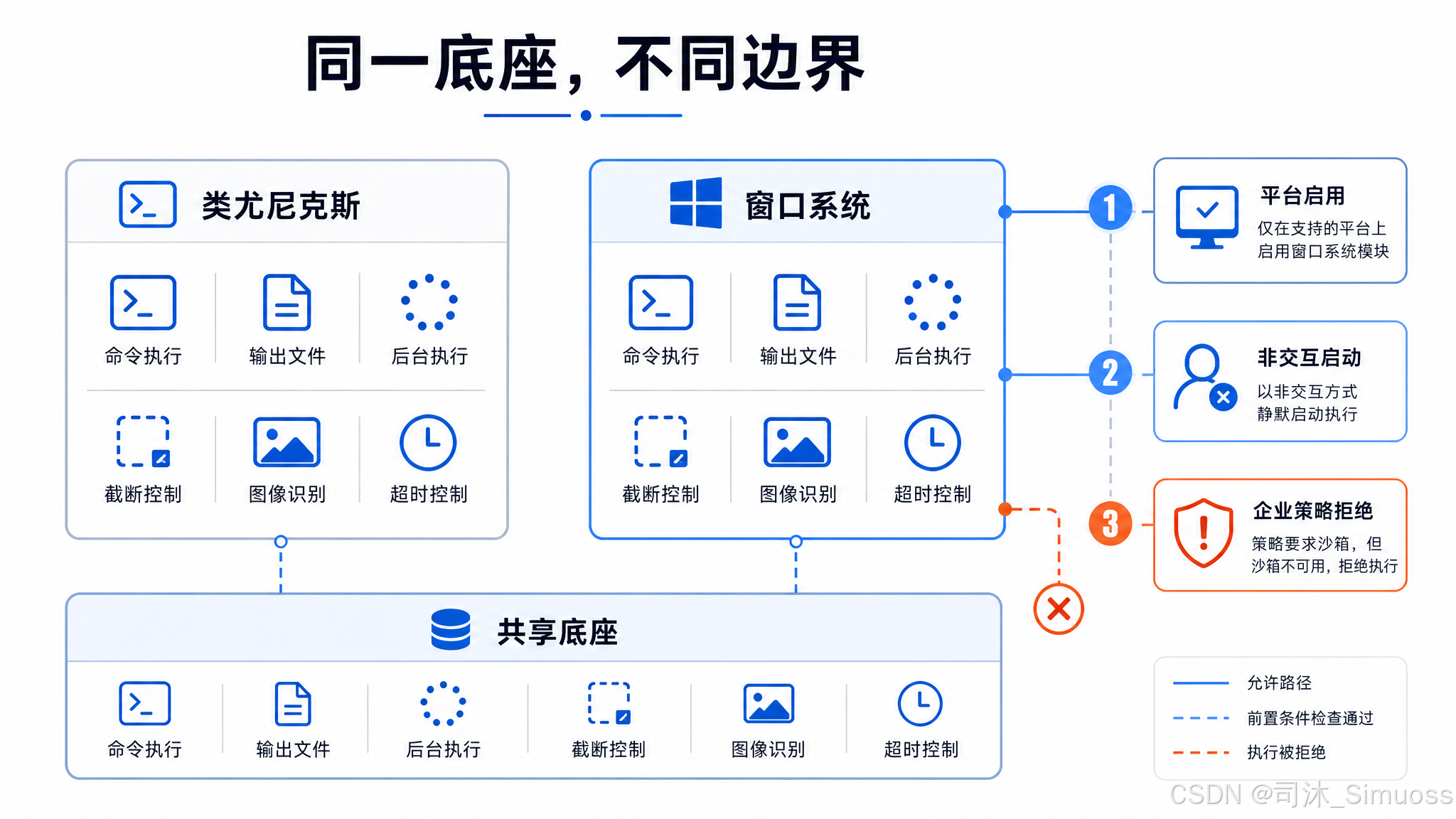
PowerShell 工具是 Bash 在 Windows 上的对应版本,共用同一套底层基础设施:输出文件模式、大输出落盘预览、后台执行、内存截断(同样的上限)、图像输出识别、输出截断格式(... [N lines truncated] ...)。
超时默认值(2 分钟)和上限(10 分钟)、输出字符上限(30,000)均与 Bash 一致。
主要差异
可用性:PowerShell 工具只在 Windows 上启用(运行时检查平台),且对外部用户默认关闭,需要明确设置环境变量才能使用。
超时上限的强制执行:PowerShell 工具在传入超时时明确做 Math.min(timeout, maxTimeout) 截断,确保不会超过上限。Bash 工具在这一层没有同样的强制截断(依赖 shell 层面的 30 分钟超时作为保底)。
启动参数:以 -NoProfile -NonInteractive 启动,抑制交互提示和 profile 脚本。执行策略(ExecutionPolicy)不在代码里强制设置,由本机 PowerShell 配置决定。
沙箱与企业策略:Windows 上沙箱机制不可用。如果企业策略要求必须在沙箱里运行且禁止在沙箱外执行,PowerShell 工具整体拒绝使用,返回固定的策略拒绝说明。这防止在受限环境下绕过安全配置。
跨工具共同设计
统一的权限层
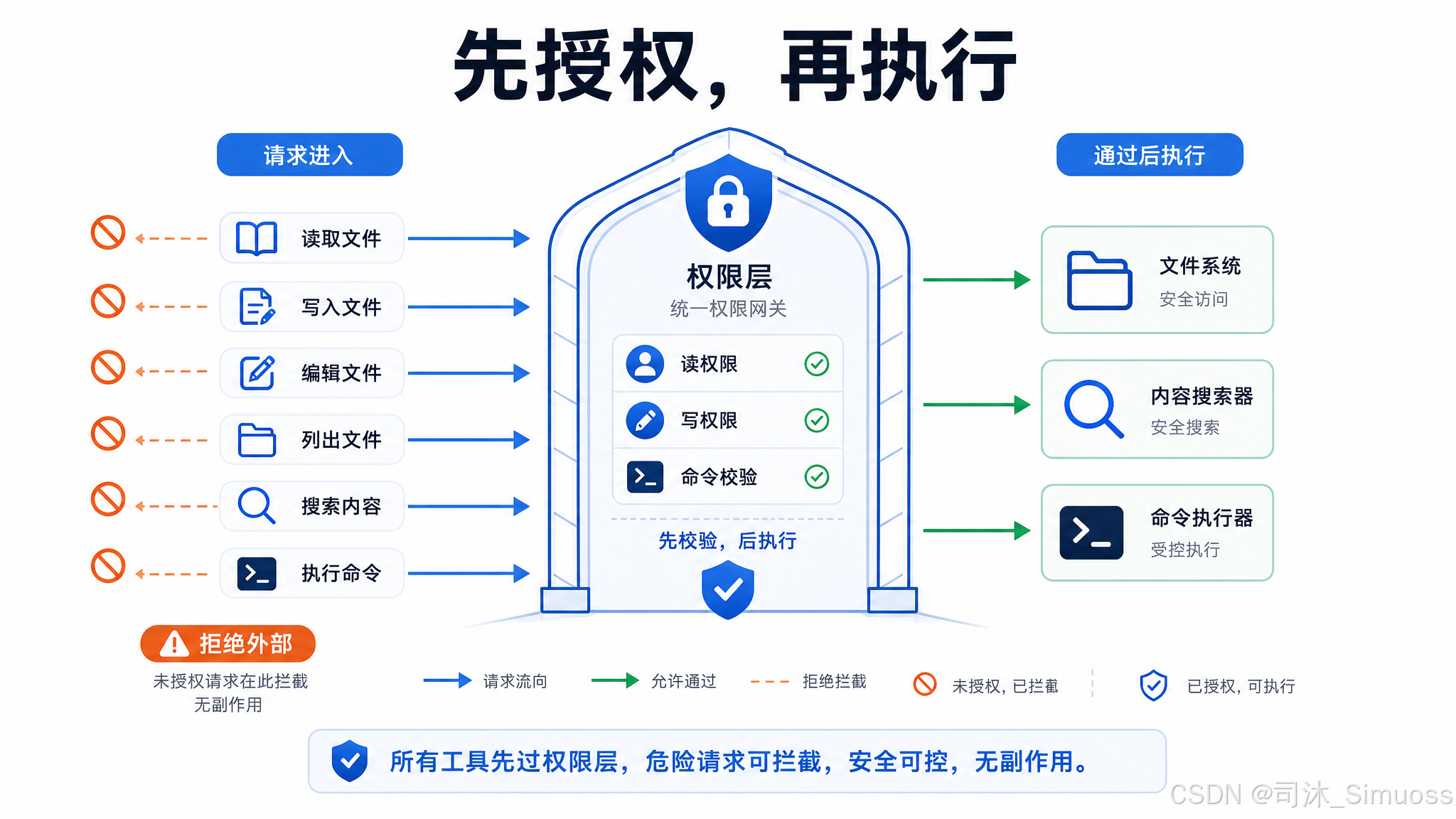
所有工具在参数校验阶段都先过一道权限检查(读类工具检查读权限,写类工具检查写权限,Bash 有额外的命令级校验)。这层检查在工具实际执行之前发生,可以在不产生任何副作用的情况下拒绝请求。
UNC 路径的安全跳过
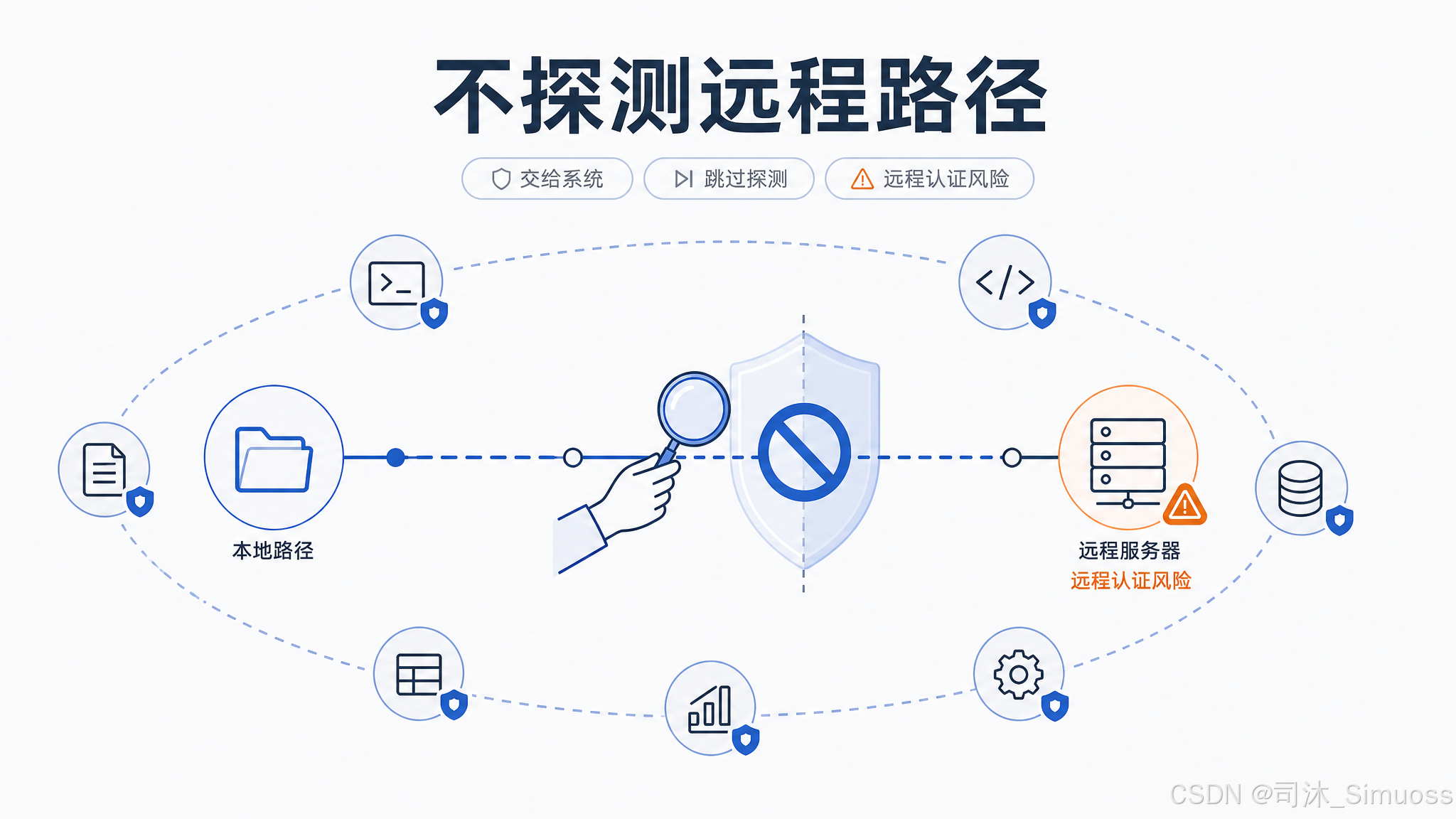
Windows 的 UNC 路径(\\server\share 或 //server/share)在路径校验阶段跳过所有文件系统操作(stat、existsSync 等),把真实访问控制交给操作系统处理。原因:对 UNC 路径做 stat 可能触发 Windows 的 SMB 认证流程,潜在泄露 NTLM 凭据给恶意服务器。
所有七个工具(包括 Glob、Grep)都实现了这个跳过逻辑。
工具结果大小与落盘
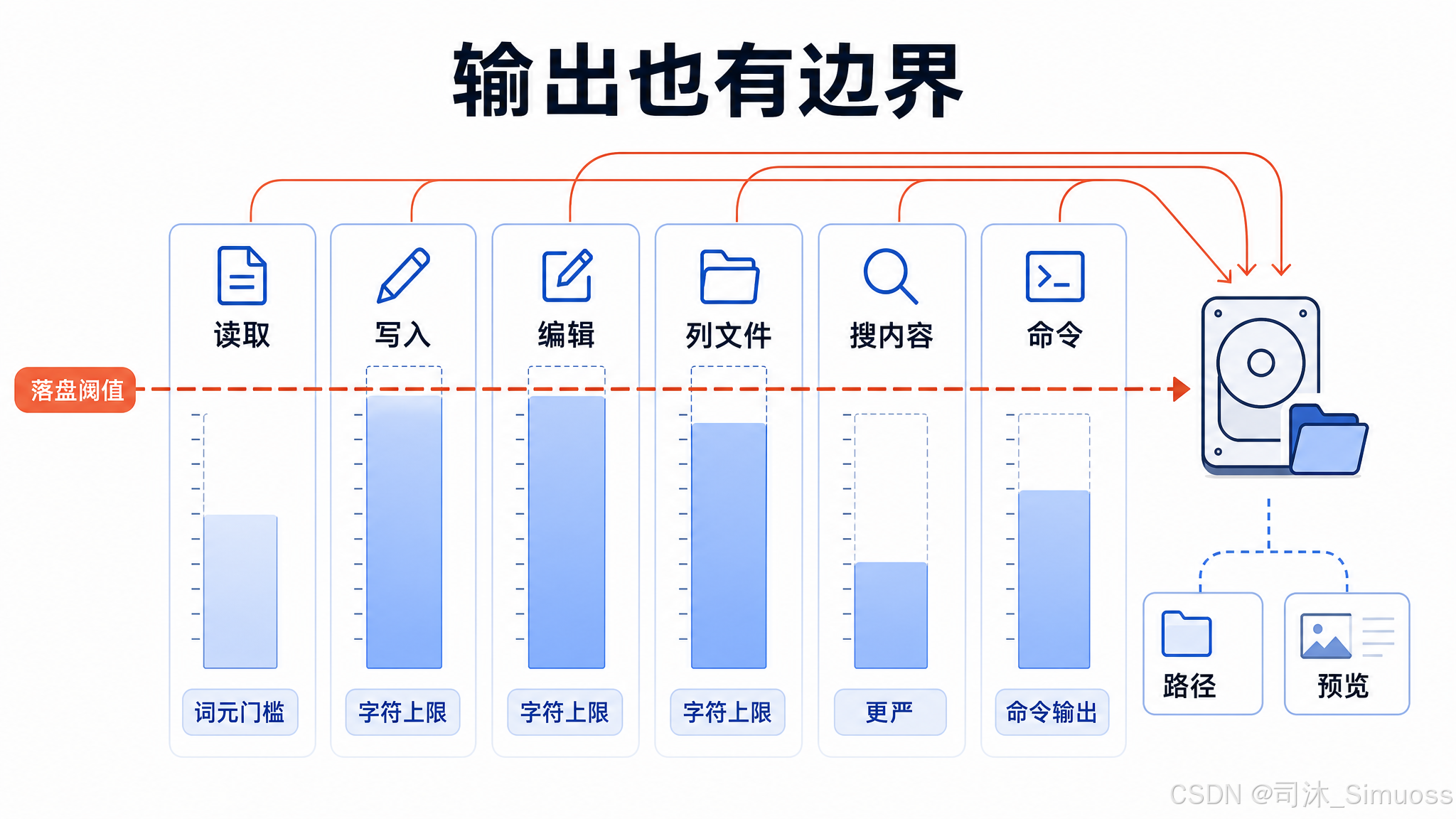
各工具的工具结果都有大小上限:Read 无上限(由 token 门槛控制),Write/Edit 100,000 字符,Glob 100,000 字符,Grep 20,000 字符,Bash/PowerShell 由 getMaxOutputLength() 控制。
全局还有一道 50,000 字符的落盘阈值——任何工具结果超过这个大小,完整内容写到磁盘,模型侧看到路径加预览。
Glob 和 Grep 共用 ripgrep
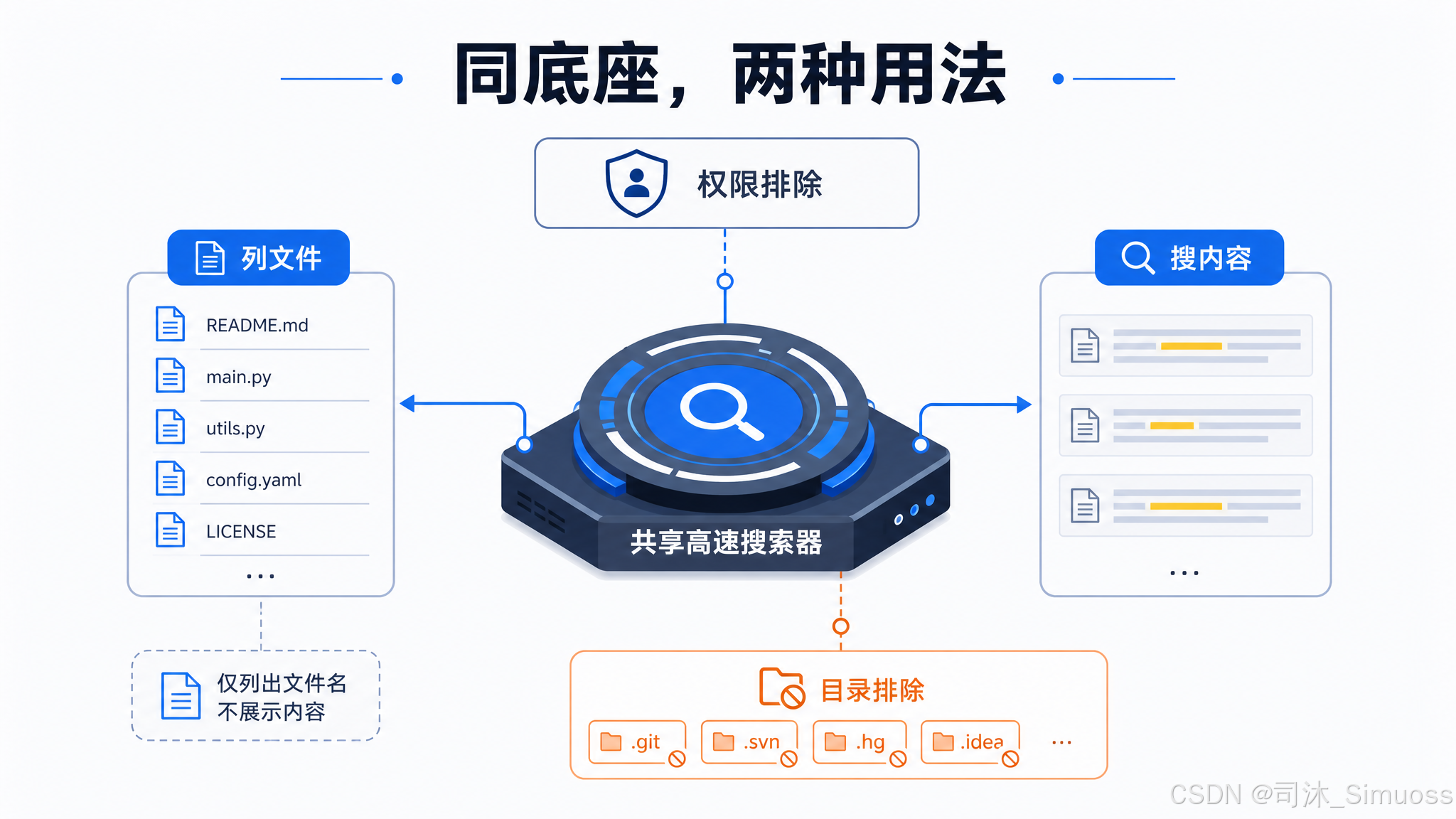
两者都调用 ripgrep,共享同一套 ignore 规则逻辑(将权限系统的 deny 模式转成 ripgrep 的 --glob !... 排除参数)。不同之处:Glob 用 --files(枚举文件名),Grep 用标准搜索模式;Glob 默认不排除 VCS 目录,Grep 硬编码排除 .git 等六个目录。
Read、Write、Edit 共享读取状态
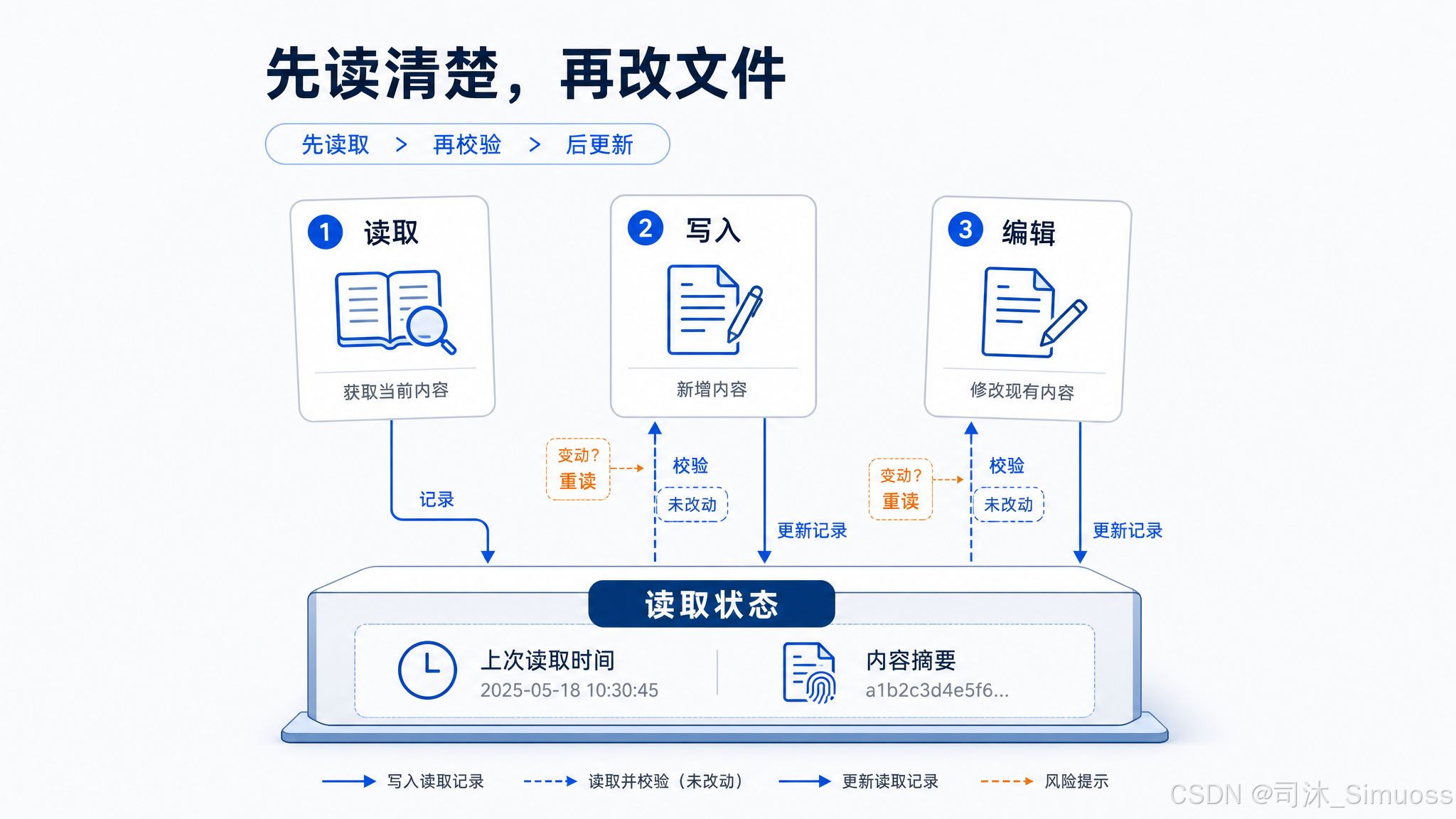
三个工具共用一个 readFileState(以路径为 key 的 Map),记录每个文件的上次读取时间戳和内容。Read 写入这个状态,Write 和 Edit 读取并验证,再写入新的状态。这是覆盖保护机制的底层数据结构,所有文件写操作都必须经过它的校验。
如果您认为内容不错,还可以订阅本合集,更快获取后续更新。
还可以加入矢量起源Agent交流群,与大家一起讨论~


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)