Conformal CPO:把保形预测嵌入 LLM Agent 编排策略,可证明可靠性 + 30% 成本节省
摘要: 论文《Conformal Constrained Policy Optimization for Cost-Effective LLM Agents》提出将保形预测(conformal prediction)嵌入LLM Agent编排策略,实现可靠性保证与成本优化的平衡。该方法通过Base-Guide双模型协作(如LLaMA-2-7B与GPT-4o),利用强化学习训练策略选择模型响应,同时
Conformal CPO:把保形预测嵌入 LLM Agent 编排策略,可证明可靠性 + 30% 成本节省
论文:Conformal Constrained Policy Optimization for Cost-Effective LLM Agents
arXiv: 2511.11828 |AAAI 2026 推荐
作者:Wenwen Si, Sooyong Jang, Insup Lee, Osbert Bastani(UPenn)
我对这条研究路径的判断
LLM agent 编排(orchestration)是 2025 后半年起来的真问题。一个企业级场景:用户发来一个 multi-hop QA,你有便宜的 LLaMA-2-7B(每次 0.001 cent)和昂贵的 GPT-4o(每次 0.5 cent),怎么决定哪些 query 用便宜模型搞定、哪些必须升级到贵模型?过去做法基本是两类:
- 基于 confidence score 阈值:让模型对自己回答的不确定性打分,超过某个阈值就 escalate。问题是模型自评 confidence 是出名的不准——overconfident 是常态。
- 训一个 RL policy:用强化学习训个 router policy。问题是没有可靠性保证——你跟 user 没法说"我们 95% 概率给你正确答案"。
Conformal CPO(CCPO)这篇做的事是把 conformal prediction 直接嵌进 RL 训练循环——既享有 RL 的灵活性能优化(成本最小化),又享有 conformal prediction 的 distribution-free 可靠性保证(覆盖率 ≥1−α\geq 1-\alpha≥1−α)。这个组合在 ML for Systems 圈早晚会成为标配——任何"决策有 cost、有正确性约束"的场景都能复用。
我自己读完后最直接的感受是——这是一篇会被 follow-up 复制粘贴的方法学论文。conformal prediction × constrained policy optimization 的化学反应被这篇做出来了,后面会有大量"我们把 CCPO 应用到 X 场景"的工作。
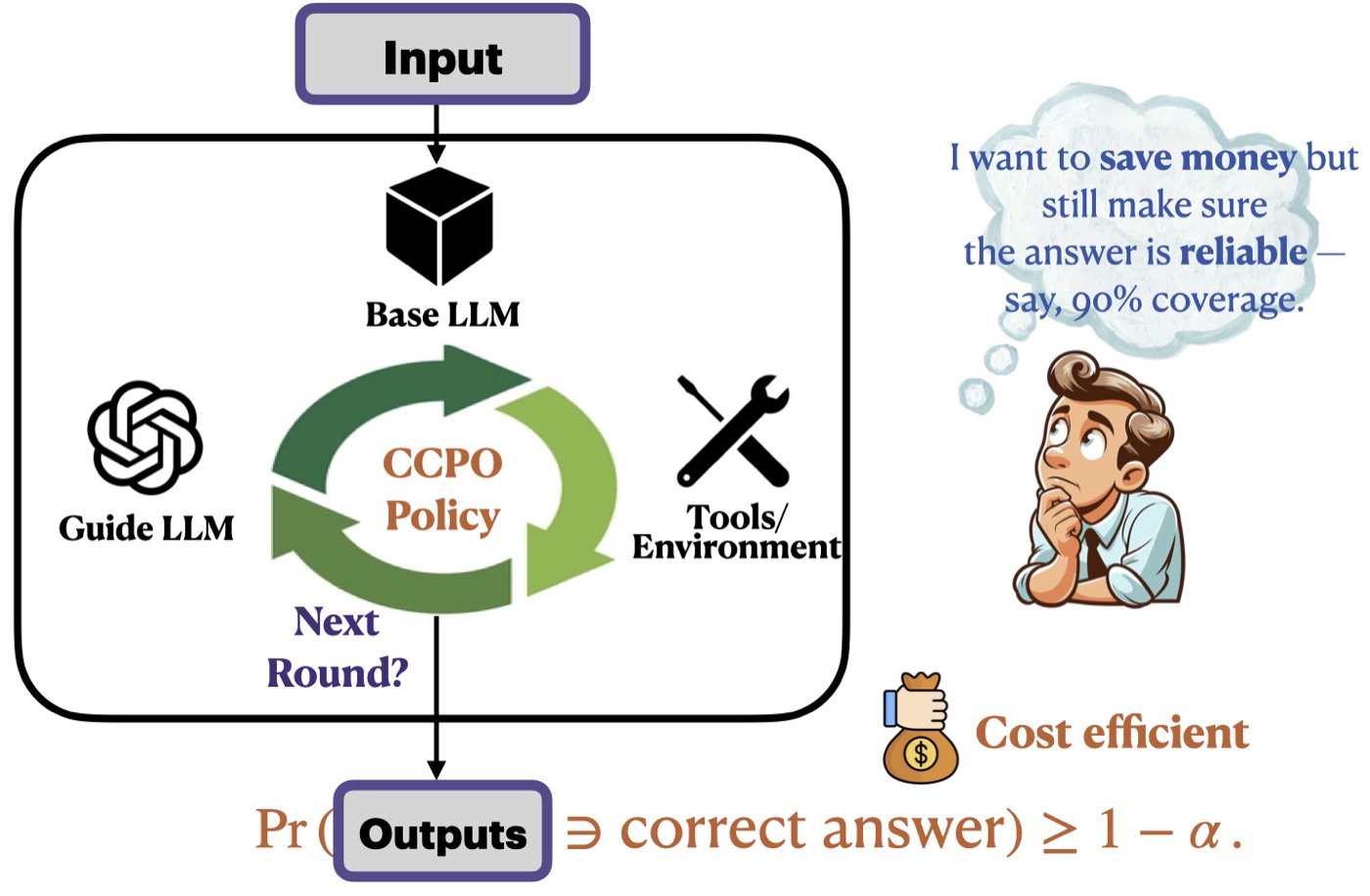
一、问题设定:base + guide 的协作 + conformal 形式化
Base-Guide 编排策略
CCPO 假设两个 agent:
- Base agent(如 LLaMA-2-7B):便宜但弱
- Guide agent(如 GPT-4o):强但贵
每一轮交互的 protocol 是:
- base agent 拿到 question 生成 reasoning trace + answer
- guide agent 评估 base 的输出(注意——只用很少 output token,主要是 input token,所以便宜):判断 base 答案是否正确 + 给一个修正答案
- policy(一个三层 64 维 MLP)观察当前状态,决定下一步动作 at∈Aa_t \in \mathcal{A}at∈A:
base answer:采用 base 的答案,结束guide answer:采用 guide 的修正答案,结束next round:再来一轮
这个 protocol 的工程巧思在第 2 步——guide agent 不做 reasoning,只做 evaluation。这把昂贵 reasoning(每个回答几百 output token)变成了便宜的 input-heavy evaluation。我自己跑过类似 setup,input token 跟 output token 的成本比通常是 1:5 到 1:10,所以这一步省下来的钱很可观。
POMDP 形式化
policy 接收观测 oto_tot(包含 base 的 context、guide 的 judgment、当前轮次、累积 token usage),horizon T=4T=4T=4(论文设的)。要解的问题:
minCE[J(C,Q)+λ∣C(Q)∣] \min_C \mathbb{E}\big[J(C, Q) + \lambda |C(Q)|\big] CminE[J(C,Q)+λ∣C(Q)∣]
s.t.Pr[Y∗∈C(Q)∨Y∗∉Y(Q)]≥1−α \text{s.t.} \quad \Pr\big[Y^* \in C(Q) \vee Y^* \notin \mathcal{Y}(Q)\big] \geq 1 - \alpha s.t.Pr[Y∗∈C(Q)∨Y∗∈/Y(Q)]≥1−α
这里 C:O→2AC: \mathcal{O} \to 2^\mathcal{A}C:O→2A 是 conformal policy(输出动作集合而不是单个动作);Y(Q)\mathcal{Y}(Q)Y(Q) 是所有可能动作序列产生的答案集;α\alphaα 是用户指定的可靠性水平(典型值 0.1,意思是 90% 覆盖率)。
约束读起来有点拗口——含义是"如果存在某个动作序列能产生正确答案,那 conformal policy 输出的答案集 C(Q)C(Q)C(Q) 必须包含正确答案"。这是 conformal prediction 标准的覆盖率保证形式。
二、方法核心:conformal threshold 与 stochastic policy 的联合优化
CCPO 的精髓在于把组合 action space 2A2^\mathcal{A}2A 通过参数化压缩成"score function π\piπ + threshold κ\kappaκ"两个东西的乘积:
Cπ,κ(o)={a∈A:π(a∣o)≥κ} C_{\pi, \kappa}(o) = \{a \in \mathcal{A} : \pi(a \mid o) \geq \kappa\} Cπ,κ(o)={a∈A:π(a∣o)≥κ}
意思是——超过阈值的 action 都进入集合,否则不进。这把 set-valued 决策化简为 pointwise score 比较。同时引入 stochastic conformal policy Sπ,κS_{\pi, \kappa}Sπ,κ——在 conformal set 上均匀采样:
Sπ,κ(a∣o)=1[π(a∣o)≥κ]∑a′1[π(a′∣o)≥κ] S_{\pi, \kappa}(a \mid o) = \frac{\mathbf{1}[\pi(a \mid o) \geq \kappa]}{\sum_{a'} \mathbf{1}[\pi(a' \mid o) \geq \kappa]} Sπ,κ(a∣o)=∑a′1[π(a′∣o)≥κ]1[π(a∣o)≥κ]
这个 stochastic policy 是 RL 训练的 target——每一步交替优化两件事:
Critic 更新(V-trace off-policy 修正)
rollout 用 π\piπ 收集,但目标是 Sπ,κS_{\pi, \kappa}Sπ,κ,存在分布 mismatch。CCPO 借 IMPALA 的 V-trace 做 off-policy 修正,定义截断重要性权重 ρt=min(ρˉ,Sπ,κ/π)\rho_t = \min(\bar\rho, S_{\pi,\kappa}/\pi)ρt=min(ρˉ,Sπ,κ/π)(论文取 ρˉ=1\bar\rho=1ρˉ=1,clip 大权重不 clip 小权重),然后跑 V-trace target:
vt=Vθ(ot)+δtV+ρt(vt+1−Vθ(ot+1)) v_t = V_\theta(o_t) + \delta_t V + \rho_t (v_{t+1} - V_\theta(o_{t+1})) vt=Vθ(ot)+δtV+ρt(vt+1−Vθ(ot+1))
constraint critic VC,ϕV_{C, \phi}VC,ϕ 同样训练,只是把 reward rtr_trt 换成 constraint ct=1[t=tf]⋅1[Y∗∈C(Q)∨Y∗∉Y(Q)]c_t = \mathbf{1}[t = t_f] \cdot \mathbf{1}[Y^* \in C(Q) \vee Y^* \notin \mathcal{Y}(Q)]ct=1[t=tf]⋅1[Y∗∈C(Q)∨Y∗∈/Y(Q)]。
Policy 更新(trust-region with KL ball)
借 CPO 的 trust-region:
minπE[∑tA^tSπ,κ]s.t.JˉCπ,κ≥1−α, DKL(Sπ,κ∥Sk)≤δ \min_\pi \mathbb{E}\Big[\sum_t \hat A^{S_{\pi, \kappa}}_t\Big] \quad \text{s.t.} \quad \bar J_C^{\pi, \kappa} \geq 1 - \alpha, \; D_{\text{KL}}(S_{\pi, \kappa} \| S_k) \leq \delta πminE[t∑A^tSπ,κ]s.t.JˉCπ,κ≥1−α,DKL(Sπ,κ∥Sk)≤δ
其中 JˉCπ,κ\bar J_C^{\pi, \kappa}JˉCπ,κ 是 constraint value 的 upper bound(论文用了一个组合不等式推导出来的 importance-weighted 估计)。这一步和经典 CPO 一样用共轭梯度求解最优拉格朗日乘子和自然梯度方向。
一个 implementation detail——Sπ,κS_{\pi, \kappa}Sπ,κ 里有 indicator function 不可导,CCPO 用 sigmoid softmask 近似:
softmask(a,o;κ)=σ(π(a∣o)−κϵ) \text{softmask}(a, o; \kappa) = \sigma\Big(\frac{\pi(a \mid o) - \kappa}{\epsilon}\Big) softmask(a,o;κ)=σ(ϵπ(a∣o)−κ)
ϵ→0\epsilon \to 0ϵ→0 时 softmask 退化为 indicator。论文用 ϵ=0.01\epsilon = 0.01ϵ=0.01,足够 sharp 但保留可导性。
Threshold κ\kappaκ 校准(在线 conformal)
policy 更新完一轮后,用 Angelopoulos & Bates 2024 的在线 conformal prediction 算法更新阈值:
κk+1=κk+ηk(1−1[Y∗∈Cπ,κ(Q)∨Y∗∉Y(Q)]−α) \kappa_{k+1} = \kappa_k + \eta_k \big(1 - \mathbf{1}[Y^* \in C_{\pi, \kappa}(Q) \vee Y^* \notin \mathcal{Y}(Q)] - \alpha\big) κk+1=κk+ηk(1−1[Y∗∈Cπ,κ(Q)∨Y∗∈/Y(Q)]−α)
这是一个非常优雅的 online learning step——如果当前预测集没覆盖到 ground truth,κ\kappaκ 减小(让集合变大);如果当前预测集覆盖到了,κ\kappaκ 增大(让集合变小、节省成本)。理论上当 ∑tηt=∞\sum_t \eta_t = \infty∑tηt=∞ 且 ∑tηt2<∞\sum_t \eta_t^2 < \infty∑tηt2<∞ 时,i.i.d. 设定下 coverage 渐进收敛到 1−α1-\alpha1−α;adversarial 设定下 long-run coverage error 是 O(T−1/2+ξ)O(T^{-1/2 + \xi})O(T−1/2+ξ)。
CCPO 还做了一个 belt-and-suspenders 设计:训练完 final policy πK\pi_KπK 后,再用传统 batch conformal prediction 在 holdout calibration set 上选最终 κK+1\kappa_{K+1}κK+1,确保即使 policy 没收敛也能保证 coverage。这是工程稳健性思维——理论保证依赖收敛假设,实践上不能赌。
三、主实验:HotpotQA 上 cost 比 CPO online 再降 12-27%
HotpotQA + LLaMA-2-7B + GPT-4o (α=0.1\alpha = 0.1α=0.1)
| Policy | Cost (cents) | Coverage | Avg. Len. | Set Size |
|---|---|---|---|---|
| GPT-4o EXIT(only) | 827.0 | 0.908 | 2.39 | 2.39 |
| LLaMA-2 EXIT | 0.0 | 0.653 | 2.55 | 2.55 |
| GPT-4o-as-policy | 18.65 | 0.780 | 1.20 | 1.00 |
| UALA(uncertainty threshold) | 9.153 | 0.923 | 2.00 | 2.00 |
| CPO(vanilla) | 4.704 | 0.832 | 1.004 | 1.00 |
| CPO batch | 7.835 | 0.905 | 1.70 | 2.19 |
| CPO online | 7.484 | 0.897 | 1.58 | 2.38 |
| CCPO(λ=0\lambda=0λ=0) | 6.552 | 0.902 | 1.34 | 2.35 |
观察:
- GPT-4o EXIT 单独跑 827 cents、coverage 91 个点——参照线。CCPO 用 6.55 cents 拿到几乎相同的 coverage(90.2%),成本降到 0.79 个百分点。这是一个 125 倍的成本节省(注意单位 cents,不是百分比),相当 dramatic。
- CPO online vs CCPO:CCPO 6.552 vs CPO online 7.484,相对降低 12.5%。这是 conformal 嵌入 vs 后处理 conformal 的直接 head-to-head 对比。
- CPO vanilla 的 coverage 只有 0.832 —— 没有 conformal 保证的 RL 拿不到目标 coverage(要求 ≥ 0.9)。这证明了 conformal step 不可省。
- UALA 的 cost 是 CCPO 的 1.4 倍,而且 cover 9.2 个百分点反而高于 CCPO——但 set size 也更大(2.00 vs 2.35 没差很多)。UALA 用固定 threshold 在 uncertainty 上,缺乏 RL 优化空间。
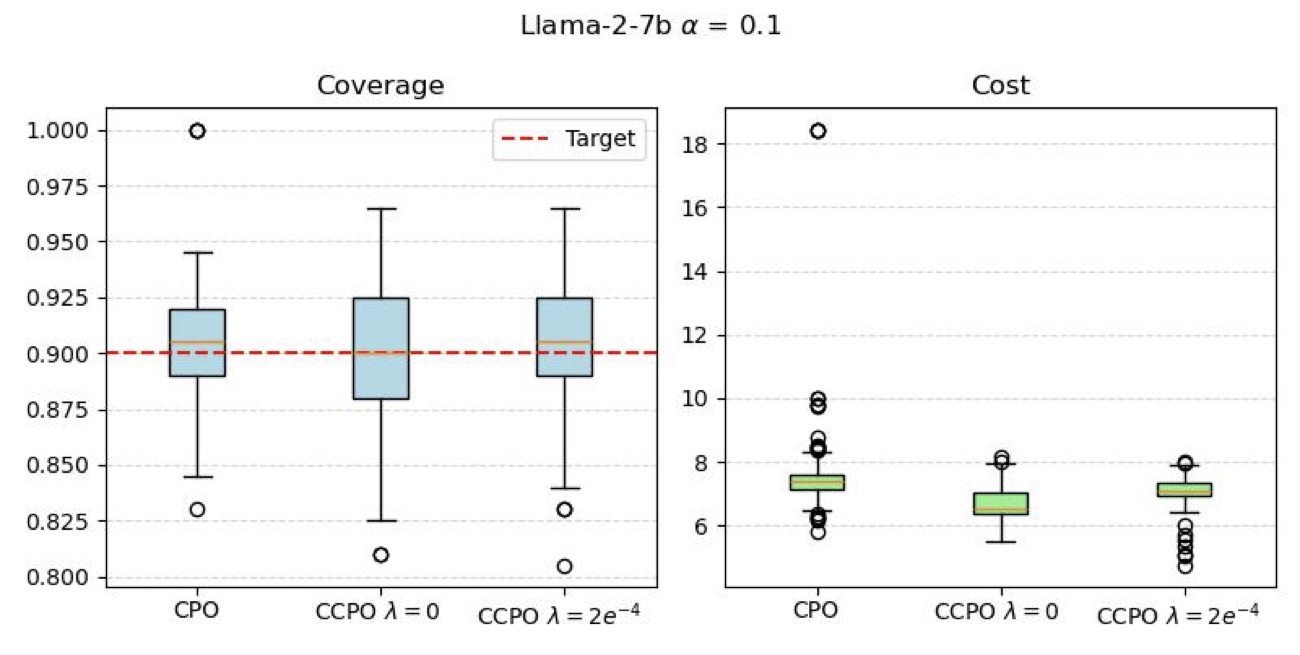
box plot 显示 100 次 random split 上 CCPO 的 cost 中位数明显低于 CPO online/batch,coverage 全部稳定在 0.9 以上。这是 conformal 保证带来的——理论上保证 coverage,实际上稳定性也好。
MMLU + LLaMA-2-7B + GPT-4o (α=0.1\alpha = 0.1α=0.1)
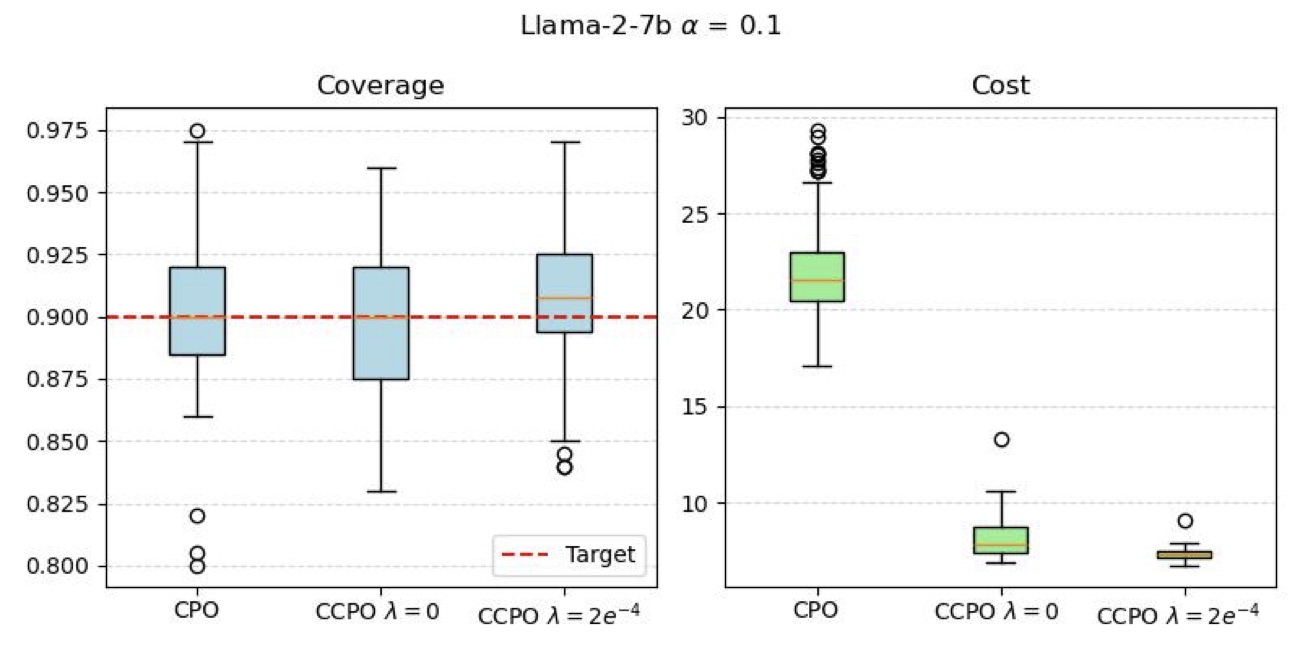
MMLU 这个数据集 base model 表现比 HotpotQA 强(不需要太多 retrieval),CCPO 的优势相对没那么 dramatic 但仍然存在——比 CPO online cost 降低约 27%(论文 Table 8)。这给我一个直觉判断:任务越难(base model 越频繁出错),CCPO 的优势越大——因为 conformal threshold 能更激进地把不确定的 case 路由给 guide。任务太简单时 base 自己就能搞定,编排带来的 marginal value 有限。
LLaMA-3.2-3B + α=0.05\alpha = 0.05α=0.05
LLaMA-3.2-3B 性能比 LLaMA-2-7B 强很多,作者特意把 α\alphaα 调严到 0.05(要求 95% coverage)以避免 trivial baseline。CCPO 在这种更严格设定下仍然能比 CPO online 降本 25% 左右(appendix Table 7)。这条结果说明 CCPO 不是只在某个特定难度下工作——可以适配不同 reliability 要求。
四、几个我特别欣赏的 design choice
1. Stochastic conformal policy 的两层巧思
直接学 conformal policy C:O→2AC: \mathcal{O} \to 2^\mathcal{A}C:O→2A 是组合优化(指数级 action space)。CCPO 通过 π\piπ + κ\kappaκ 把它降成两个标量(score + threshold)的乘积,把 set-prediction 问题压缩成了 score-prediction 问题。这是一个 reduction 的好例子——把难解的搜索空间通过参数化压缩到可学的连续空间。
2. V-trace + softmask 的双重可微化
CCPO 训的是 π\piπ 但要 evaluate Sπ,κS_{\pi, \kappa}Sπ,κ。两个 policy 之间的 ratio 涉及 indicator function 不可导。CCPO 解法是双管齐下:
- V-trace 修正分布 mismatch(截断重要性权重)
- softmask 修正 indicator 不可导(sigmoid 近似)
这两个 trick 加起来让 critic update 和 policy update 都能跑标准的 SGD。从 RL 角度看属于教科书级的 off-policy + 不可微目标的处理。
3. Online + batch 双重校准
虽然 online conformal 有理论 coverage 保证,但依赖 policy 收敛。CCPO 多做一步——训完后用 holdout calibration set 重新跑一次 batch conformal,给 final policy 选最终 κ\kappaκ。这样即使 online 阶段的收敛假设不严格成立,coverage 仍然有保证。这个"训练时 online + 部署时 batch"的双重设计是个很务实的工程选择。
五、几点批判性思考
1. Guide agent 的成本估计可能被低估
CCPO 假设 guide agent 在第 2 步只用 input token、几乎不生成 output token。但 GPT-4o 实际响应一个 evaluation request 会生成几十到上百 token(“yes” 还是 “no” + 修正答案)。这个 output token 的成本累积起来不容忽视。论文里 guide agent 的 cost model 我看下来似乎没有完全细化——如果把 output token 也算进去,CCPO 的成本节省可能略小。
2. Horizon T=4T=4T=4 是个比较激进的选择
对 multi-hop QA 来说 T=4T=4T=4 已经接近上限——超过 4 步通常意味着任务超出 base+guide 协作能力。但对其他场景(比如 SWE-Bench、agentic coding),TTT 经常需要 20+。在长 horizon 下 conformal coverage 保证的 sample efficiency 会变差(covering set size 随 TTT 指数增长上界 2T2T2T),CCPO 的优势可能消失。论文没讨论 TTT 的扩展性,这是个 obvious 的扩展方向。
3. Coverage guarantee 是 marginal 的,不是 conditional 的
conformal prediction 标配的是 marginal coverage——over the random data distribution coverage 是 1−α1-\alpha1−α。但单个 question 上不一定。如果用户给一个特别难的 question(distribution shift 之外),CCPO 没有 per-question 保证。对一些高 stake 场景(医疗、法务)这个区别很关键。论文里没强调这一点,实际部署需要小心。
4. base agent 的"ungivable answer"现象
如果 base agent 完全错(Y∗∉Y(Q)Y^* \notin \mathcal{Y}(Q)Y∗∈/Y(Q)),约束 Y∗∉Y(Q)Y^* \notin \mathcal{Y}(Q)Y∗∈/Y(Q) 这一项在 indicator 里取 1,整个约束 trivially 成立。这意味着 CCPO 对"base 完全无能"的 case 没有惩罚——会让 policy 偷懒不去尝试 escalate。论文用 horizon T=4T=4T=4 部分缓解了这个问题(多轮重试)但没根本解决。如果 base 模型在某类 question 上 systematic 失败,CCPO 会把这些 question 全部交给 guide 但又不计入 coverage 损失——这是个 corner case。
5. 跟 LLM-as-policy 的对比缺乏深入分析
LLM-as-policy(用 GPT-4o 当 router)在 HotpotQA 上 cost 18.65 cents、coverage 0.78。CCPO 6.55 cents、coverage 0.90。CCPO 全方位胜出,但论文没分析 LLM-as-policy 为什么这么差——是 GPT-4o 不擅长输出 routing decision?还是 prompt design 的问题?如果是后者,简单优化 prompt 可能让 LLM-as-policy 也能 cover 0.90,那 CCPO 的优势会被压缩。
六、给从业者的启发
-
任何"模型层叠 + cost-coverage trade-off"的场景都值得套 CCPO。除了 multi-hop QA,明显的应用场景包括:
- 代码生成(先 7B 试一下,不行再 32B 重新生成)
- RAG(先 cheap retriever,结果不 confident 再上 expensive reranker)
- 多模态(先文本模型,搞不定再上 vision-language model)
-
Conformal prediction 不是 black-box add-on,最好嵌入训练循环。CCPO 比"先训 RL 再后处理 conformal"(CPO online/batch)省 12-27% 成本,差距来自 RL 在训练时就感知到 conformal threshold 而做的策略调整。
-
threshold 校准用在线 + 离线双保险。理论保证依赖收敛,工程上不能赌。
-
Output set 的 size 也是 trade-off 维度。CCPO 默认 λ=0\lambda=0λ=0(不惩罚 set size),但论文也跑了 λ>0\lambda > 0λ>0 版本,coverage 不变的情况下 set size 从 2.35 降到 2.22(HotpotQA)。生产环境上根据 user UX 要求选合适的 λ\lambdaλ。
-
对 base + guide 比例敏感。CCPO 的 cost 节省高度依赖 base/guide 成本比。如果 guide 只比 base 贵 2 倍(不是 100 倍),CCPO 的相对优势会变小。在选 base/guide 组合时尽量拉大成本差。
七、跟前几篇推荐论文的串联
- DEPO(arXiv 2511.15392) 给 LLM agent 加 dual-efficiency 偏好优化(token + step)
- LLMdoctor(arXiv 2601.10416) 用小 doctor 模型在 token 级 guide 大 patient 模型
- CCPO(本文) 用 conformal RL 优化 LLM agent 编排,cost vs coverage 双约束
三篇有一个共同主题——小模型加大模型协作是 2026 阶段 LLM agent 工程化的主旋律。DEPO 在偏好层面做 efficiency;LLMdoctor 在 token 层面做 alignment;CCPO 在 system 层面做 routing。它们是同一个工程化范式的三个维度,未来一两年应该会出现把三者揉在一起的 unified framework。
八、收尾:理论保证 × 工程实用的甜蜜点
写到这里我意识到 CCPO 这篇的真正价值是——它在"distribution-free 理论保证"和"实际工程性能"之间找到了一个甜蜜点。Conformal prediction 在统计圈是个被广泛接受的、有严格 coverage 保证的方法;CPO 在 RL 圈是有 trust-region 收敛保证的 constrained policy optimization。CCPO 把这两个 well-studied 工具揉在一起,得到一个既有保证又能跑 SOTA 性能的方法。
我把它列入"工业落地候选"——任何一个有 reliability 要求 + 多模型成本权衡的 production system,都值得评估 CCPO 范式。比起那些"work for now but no guarantee"的 RL agent,CCPO 给 PM 一个能写进 SLA 的 coverage 数字,这是签合同时的关键 leverage。
最后一个个人观察——AAAI 2026 这一波 cost-aware agent 方向的论文密度很高。除了 CCPO 还有 frugal LLM、cascade routing、auto-prompt-LM 一系列工作。这意味着工业界对成本控制的需求开始反哺学术界。我建议做 LLM 系统优化的同行同时关注这几条线,未来一年 cost-aware orchestration 应该会从"别人怎么做"变成"我们必须做"。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)