第5讲:部署架构,性能预判与数据设计
本文系统阐述了Gdify平台的架构设计与性能优化策略。主要内容包括:1)当前部署架构采用Nginx+SpringBoot+PostgreSQL+Redis+pgvector组合,明确了各组件职责与请求流转路径;2)预判了系统性能瓶颈,按严重程度排序并给出处理建议;3)设计了从50人到数千人的分阶段扩展路线图;4)制定了详细的数据库性能规范,包括索引设计、大表管理、分页查询等原则;5)梳理了核心数据
上一节课我们定义了代码层次的架构,包括模块怎么分,代码怎么组织,外部调用怎么处理。这一讲,我们进入系统层面,当前怎么部署瓶颈在哪,未来怎么扩展,数据怎么存储。
很多工程师认为,这都是上线前的事情,但是部署架构从第一天就影响了你的设计决策,缓存放在哪里,数据库怎么连接,服务之间怎么通信全部取决于你的部署形态,提前想清楚,不然后面得返工。
当前部署架构
先把当前的部署原貌画出来
Gdify是模块化单体,技术栈spring boot+vue+postgresSql+redis+pgvector。目标50人使用生产环境都可加K8S部署。帮我设计当前阶段的部署架构有哪些组件,请求怎么流转,每个组件之间的职责是什么?


用户请求经Nginx分流,静态资源直接返回,API请求转发给Spring Boot,Spring Boot按需读写PostgresSQL(业务数据)、Redis(缓存会话)、pgvector(向量检索)。K8s只作为部署壳,不引入服务网格和多副本等复杂机制。
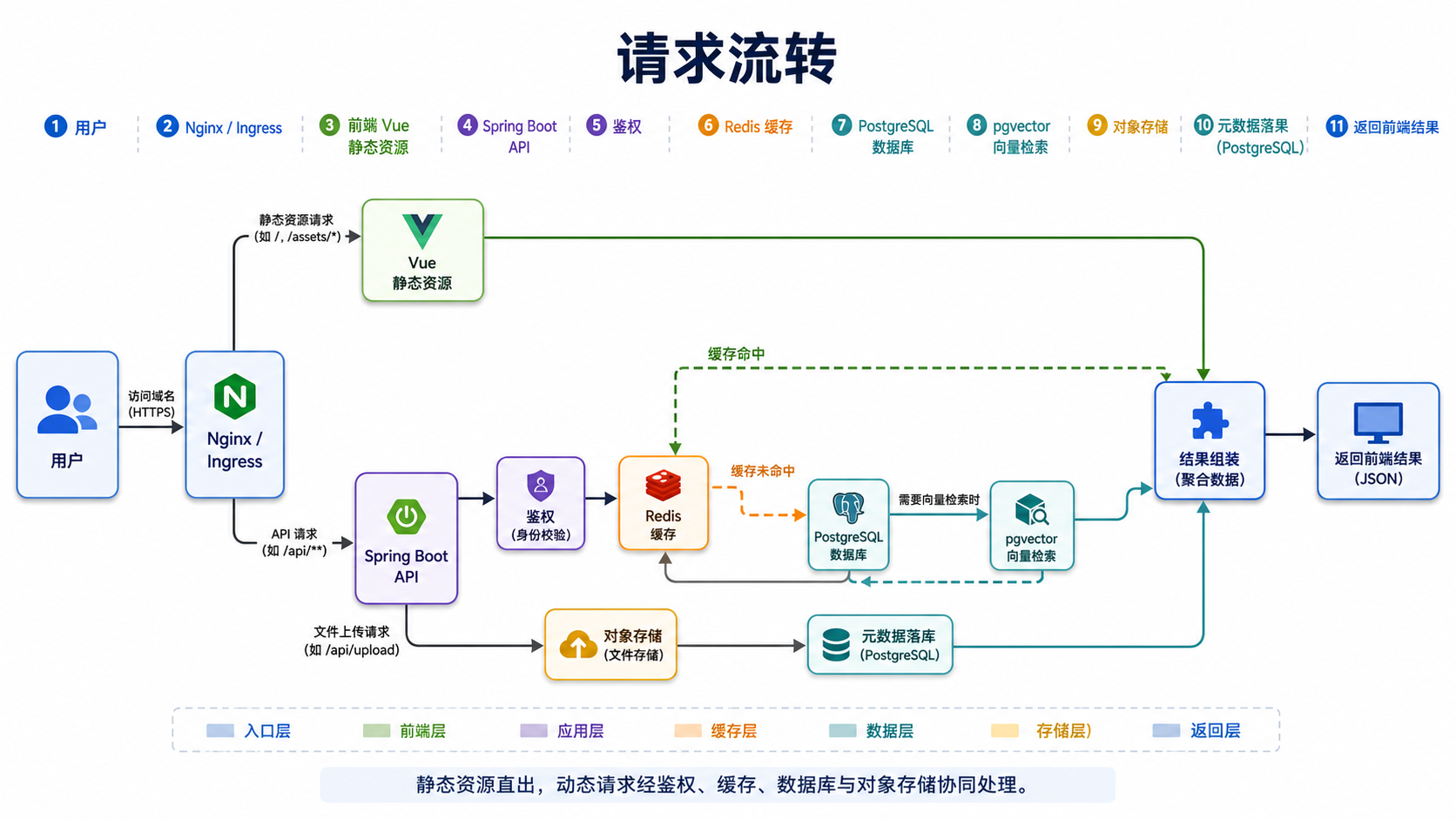
这个架构基本上不错,没有什么大问题,就是我们需要的。
性能瓶颈预判
大部分工程师不会停眼响性能瓶颈,等到出现了问题再救。但是身为架构师,你应该在设计阶段就知道瓶颈可能在哪里。即使一期不做处理,也要心里有数。
让AI编辑器帮我们来分析
基于Hify当前的部署架构(Nginx + Spring Boot + PostgresSQL + Redis + pgvector + 外部LLM API),帮我分析:这个系统的性能瓶颈可能在哪?按严重程度排序,每个瓶颈给出触发条件和一期是否需要处理。

扩展架构
一期50人,如果Gdify做得好,可能要推广到更大范围。架构上不能堵死这条路,但也不能演进过早,过早优化,比性能瓶颈本身的破坏力更大
如果Gdify要从50人扩展到几千人,当前架构需要怎么演进?帮我设计一个分阶段的扩展路径,每一步的触发条件是什么、改什么、不改什么。


这个表就是你的扩展路线图,现在你不需要做任何一步,但是每一步的出发条件改什么难点在哪里,全部写清楚了。
前面模块化单体让微服务拆分成本可控,接口隔离让调用方式可平滑切换,会话存redis让多副本不需要改动代码
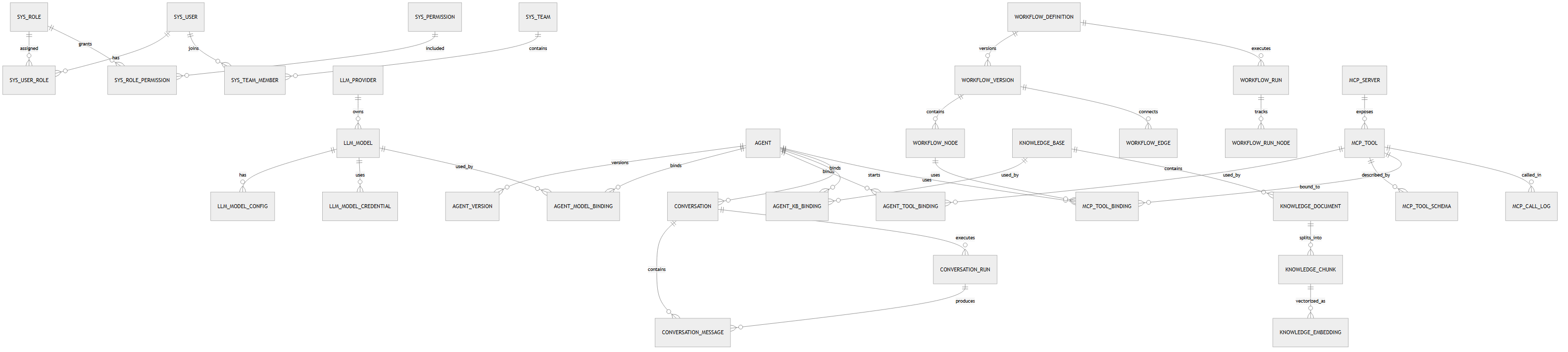
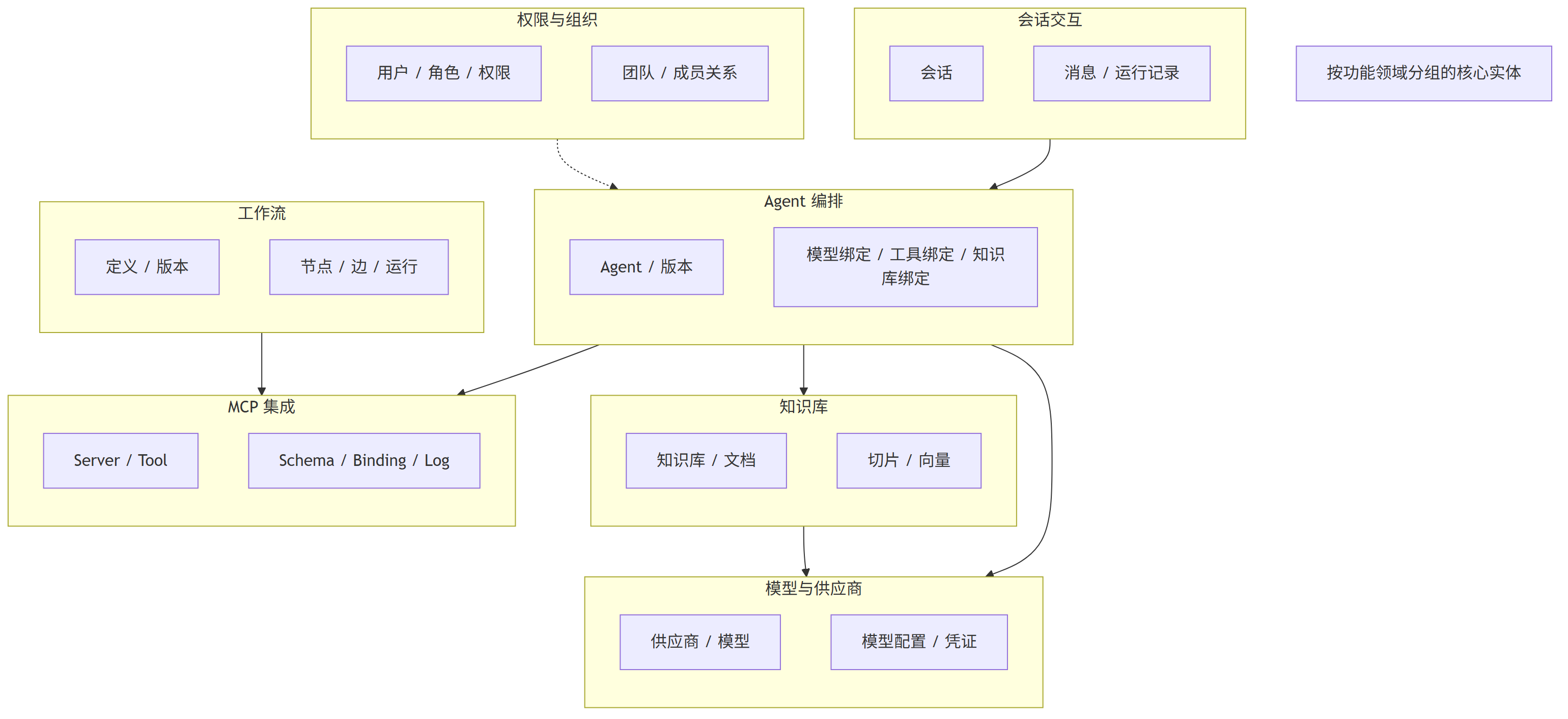
数据模型概览
核心表有哪些关系怎么样?先列出来,具体字段设计等后面每个模块开发再定,现在定太细了,后面一定会改
基于Gdify的功能范围(模型管理,Agent,对话,工作流,知识库,MCP工具),帮我梳理和核心数据表和他们之间的关系,只要表名和关系不展开字段
我们要学会一个点:你要清晰的知道AI能干什么,干什么干得好,而你要做什么。我们跟AI不是敌人,不是竞争者,而是合作者。我们要学会和他一起协作,释放我们自己最大的效率,从而给我们提高更大的现实收益。
数据库性能规范
表结构后面再定,但数据库性能规范,现在就要定,,后面AI编辑器每次建表写查询都要遵循。
Gdify用PostgresSQL+pgvector。帮我定义数据库层面的性能规范,覆盖:索引设计原则,大表预判,和对应策略,分页查询注意事项,通用字段约定。要具体到AI键表时能直接执行
Codex 给了以下的建表规范
数据库性能规范 1. 索引设计原则 只为“已确认的查询模式”建索引,不为未来想象建索引。 默认先用 B-tree,适合等值、范围、排序、唯一约束。 组合索引默认不超过 3 列;列顺序按“等值过滤 -> 范围过滤 -> 排序/去重”排列。 多列索引必须匹配同一条 AND 查询链路,且尽量命中左前缀。 软删除表的热路径索引一律做部分索引:WHERE deleted = 0。 只读/少变表优先做覆盖索引 INCLUDE(...),让列表和详情尽量走索引只读。 生产环境建索引必须优先用 CREATE INDEX CONCURRENTLY。 索引重建优先用 REINDEX CONCURRENTLY。 pgvector 向量索引和业务索引分开建,不要混在同一个索引思路里。 vector 小表可先不建 ANN 索引,先走精确检索;大表再上 HNSW/IVFFlat。 2. 大表预判 判定为大表的标准:> 1000万行,或 日增 > 10万行,或 表+索引 > 20GB,或分页/检索 p95 明显上升。 Gdify 里优先按大表管理的表:conversation_message、conversation_run、workflow_run、workflow_run_node、mcp_call_log、knowledge_chunk、knowledge_embedding。 纯配置类表通常不是大表:agent、llm_model、mcp_server、knowledge_base。 时间序列表优先按月分区。 只有极少数状态值会被查询时,用部分索引,不要造一堆互斥 partial index。 如果按很多不同维度过滤,优先考虑分区,而不是堆很多 partial index。 大表尽量避免硬删和级联删,改成软删 + 异步清理。 向量表和业务主表分离,embedding 单独存。 3. 大表策略 conversation_message、workflow_run_node、mcp_call_log:按 created_at 月分区,热分区保留近 3 到 6 个月,冷分区归档。 knowledge_chunk、knowledge_embedding:先单表 + 索引,超过容量阈值后按 tenant_id 或 knowledge_base_id 评估分区。 audit_log、call_log 类表:只追加不更新,适合时间分区 + 归档。 向量检索表:HNSW 适合更好的召回/查询性能,IVFFlat 适合更快建索引/更省内存。 IVFFlat 建议在有数据后再建;lists 可先按 rows / 1000 起步(百万内),更大规模可按 sqrt(rows)。 查询时 HNSW 用 hnsw.ef_search,IVFFlat 用 ivfflat.probes 做召回/性能平衡。 4. 分页规范 默认用“游标分页 / keyset pagination”,不要把 OFFSET 作为核心接口方案。 只有小列表、低页数后台页面,才允许 LIMIT/OFFSET。 所有分页查询必须有唯一且稳定的排序,推荐 created_at DESC, id DESC。 分页条件要和索引一致,例如:(tenant_id, status, created_at DESC, id DESC)。 高页码深翻页禁止使用 OFFSET。 向量检索不要做传统 offset 翻页,只做 top-k,必要时用游标续查。 如果是过滤 + 向量检索,优先把过滤条件收进 CTE 或分区裁剪里。 5. 通用字段约定 id:bigint,主键,单调递增或雪花型,不用 varchar 当主键。 tenant_id:多租户场景必备;没有租户就不要硬塞。 created_at / updated_at:timestamptz,统一存 UTC。 deleted:软删字段,推荐 0 表示未删除,1 表示已删除。 created_by / updated_by:审计字段,能留就留。 version:乐观锁字段,默认 0。 status:状态字段,尽量用小整数。 sort_no:人工排序字段,只在确实需要时加。 ext / metadata:只放低频扩展信息,别拿来做高频过滤。 表名和字段名统一用 snake_case,业务表尽量用单数名词。 6. AI 直接执行模板 先判断表类型:主数据表 / 关系表 / 日志表 / 向量表 / 工作流运行表。 再判断访问模式:详情 / 列表 / 时间范围 / 状态过滤 / 相似度检索。 然后按下面规则落索引: 主数据表:1 个主键 + 1 到 2 个业务唯一索引。 列表表:(tenant_id, status, created_at DESC, id DESC) 这类复合索引。 软删表:所有热路径索引都加 WHERE deleted = 0。 向量表:单独建 ANN 索引,不和业务字段混在一起。 大表:先定分区,再定索引,最后定归档。 上线建索引用 CONCURRENTLY,不要锁表硬建。 7. 可直接套用的索引模板 CREATE INDEX CONCURRENTLY idx_conversation_tenant_created_id ON conversation (tenant_id, created_at DESC, id DESC) WHERE deleted = 0; CREATE INDEX CONCURRENTLY idx_message_conv_created_id ON conversation_message (conversation_id, created_at ASC, id ASC); CREATE INDEX CONCURRENTLY idx_kb_doc_base_status_created ON knowledge_document (knowledge_base_id, status, created_at DESC, id DESC) WHERE deleted = 0; CREATE INDEX CONCURRENTLY idx_run_tenant_status_created ON workflow_run (tenant_id, status, created_at DESC, id DESC) WHERE deleted = 0; CREATE INDEX CONCURRENTLY idx_embedding_hnsw ON knowledge_embedding USING hnsw (embedding vector_cosine_ops);
写入AGENT.md
Gdify 运行与数据策略补充 本章是 Gdify 当前阶段的默认执行规范。除非明确说明,否则新增代码、数据表、索引和查询都必须遵守。 1. 部署与请求流转 - 当前默认部署形态为 Nginx + Spring Boot + PostgreSQL + Redis + pgvector + 外部 LLM API。 - Nginx 只负责入口治理、HTTPS、静态资源和反向代理,不承载业务逻辑。 - Vue 前端作为静态资源独立部署,API 请求统一转发到 Spring Boot。 - Spring Boot 负责鉴权、业务编排、事务控制、缓存读写、向量检索协调和外部 LLM 调用。 - Redis 负责缓存、会话、限流、热点数据与分布式协调,不作为主数据源。 - PostgreSQL + pgvector 是唯一可信业务数据源,向量数据与业务数据同库管理但职责分离。 - 外部 LLM API 必须被视为慢、贵、不可控的远程依赖,所有调用都要设置超时、重试、熔断和降级。 - 文件类数据优先进入对象存储,数据库只保存元数据和引用地址。 - 面向 K8S 时,应用层必须尽量无状态,状态统一下沉到数据库、缓存和对象存储。 请求流转约定 1. 用户访问域名,先到 Nginx。 2. 静态资源直接返回前端文件。 3. API 请求转发到 Spring Boot。 4. 后端先做鉴权、参数校验和限流判断。 5. 先查 Redis,未命中再查 PostgreSQL。 6. 如涉及知识检索,再走 pgvector 向量查询。 7. 如涉及模型生成,再调用外部 LLM API。 8. 文件上传先写对象存储,再落库元数据。 9. 结果统一由后端组装后返回前端。 2. 核心数据模型 - Gdify 的核心域按 模型 / Agent / 对话 / 工作流 / 知识库 / MCP 六类组织。 - 数据表设计优先围绕“谁拥有数据、谁引用谁”来建模,不按界面拆表。 - 以下为推荐的核心表名与关系,不展开字段。 用户与权限 - sys_user - sys_role - sys_permission - sys_user_role - sys_role_permission - sys_team - sys_team_member 模型管理 - llm_provider - llm_model - llm_model_config - llm_model_credential Agent - agent - agent_version - agent_model_binding - agent_tool_binding - agent_knowledge_binding 对话 - conversation - conversation_message - conversation_run 知识库 - knowledge_base - knowledge_document - knowledge_chunk - knowledge_embedding 工作流 - workflow_definition - workflow_version - workflow_node - workflow_edge - workflow_run - workflow_run_node MCP - mcp_server - mcp_tool - mcp_tool_schema - mcp_tool_binding - mcp_call_log 关键关系约定 - llm_provider 1:N llm_model - llm_model 1:N llm_model_config - llm_model 1:N llm_model_credential - agent 1:N agent_version - agent N:M llm_model 通过 agent_model_binding - agent N:M mcp_tool 通过 agent_tool_binding - agent N:M knowledge_base 通过 agent_knowledge_binding - agent 1:N conversation - conversation 1:N conversation_message - conversation 1:N conversation_run - knowledge_base 1:N knowledge_document - knowledge_document 1:N knowledge_chunk - knowledge_chunk 1:N knowledge_embedding - workflow_definition 1:N workflow_version - workflow_version 1:N workflow_node - workflow_version 1:N workflow_edge - workflow_definition 1:N workflow_run - workflow_run 1:N workflow_run_node - mcp_server 1:N mcp_tool - mcp_tool 1:N mcp_tool_schema - mcp_tool 1:N mcp_call_log 3. 数据库性能规范 3.1 索引设计原则 - 只为明确存在的查询模式建索引,不为未来猜测建索引。 - 默认先用 B-tree,适合等值、范围、排序和唯一约束。 - 组合索引优先控制在 3 列以内,列顺序按“等值过滤 -> 范围过滤 -> 排序”排列。 - 查询中经常带软删除条件的表,热路径索引优先加 WHERE deleted = 0。 - 列表和详情类查询优先做覆盖索引,不要让查询频繁回表。 - 生产环境建索引必须优先使用 CREATE INDEX CONCURRENTLY。 - 索引重建优先使用 REINDEX CONCURRENTLY。 - pgvector 索引要单独设计,不要和业务索引混建思路。 3.2 大表预判与策略 - 满足以下任一条件时,默认按大表处理:> 1000万行、日增 > 10万行、表+索引 > 20GB、分页或检索 p95 明显上升。 - Gdify 中优先按大表管理的表包括:conversation_message、conversation_run、workflow_run、workflow_run_node、mcp_call_log、knowledge_chunk、knowledge_embedding。 - 大表优先考虑按时间分区,时间序列表默认按月分区。 - 日志类、运行轨迹类表只追加不更新,优先做归档和冷数据迁移。 - 高写入、高追加表尽量避免硬删,优先软删 + 异步清理。 - 需要相似度检索的向量表和业务主表分离建模,避免向量数据污染主业务表。 3.3 分页查询注意事项 - 默认使用游标分页 / keyset pagination,不把 OFFSET 作为主分页方案。 - 只有小列表、后台低频页面才允许 LIMIT/OFFSET。 - 所有分页查询必须有稳定且唯一的排序,推荐 created_at DESC, id DESC。 - 深分页禁止使用高 OFFSET。 - 过滤 + 排序必须和索引结构尽量一致,避免全表扫描和临时排序。 - 向量检索只做 top-k,不要做传统意义上的深分页。 3.4 通用字段约定 - id 使用 bigint 主键,不用字符串主键。 - tenant_id 在多租户场景必须保留。 - created_at / updated_at 使用统一时间类型,默认按 UTC 存储。 - deleted 作为软删除标记,0 表示未删除,1 表示已删除。 - created_by / updated_by 用于审计场景,能保留尽量保留。 - version 作为乐观锁字段。 - status 尽量用小整数。 - sort_no 只在确实需要排序控制时添加。 - ext / metadata 只放低频扩展信息,不承担高频过滤职责。 4. AI 生成约束 - AI 生成表、索引、分页 SQL 之前,必须先判断该对象属于哪个业务模块。 - AI 生成代码时必须先判断是“写操作”还是“读操作”。 - AI 生成 DDL 时必须先判断表类型:主数据表、关系表、日志表、向量表、运行表。 - AI 生成索引时必须先判断访问模式:详情、列表、时间范围、状态过滤、相似度检索。 - AI 生成的索引必须匹配真实查询,而不是把所有字段都塞进联合索引。 - AI 生成分页 SQL 时默认禁止 OFFSET 深翻页。 - AI 生成向量表结构时必须单独考虑 embedding 列、向量索引和检索策略。 - AI 生成表结构时如果出现软删除字段,热路径索引必须同步考虑部分索引。 - AI 生成生产环境索引时必须默认使用并发建索引语法。 - AI 生成代码前必须遵守现有模块边界,不允许跨模块直连 Mapper、DO 或 RepositoryImpl。
总结
这一节课我们干了4件事: 设计了当前部署架构,预判了性能瓶颈,规划了扩展路径,定义了数据模型和数据库规范。
其中最有价值的是性能瓶颈预判,大部分工程师不会提前想这个觉得一期跑起来再说。但是你作为架构师,脑子里就需要有一张地图,瓶颈在哪里,什么时候会触发,到时候改什么,有了这张地图,你对系统的掌控力完全不一样。而这张地图不需要你从零开化,让AI编辑器均于你的架构分析,你判断它说的对不对?
另一个值得强调的点就是数据库规范这些内容索引原则分页注意事项大表预判,对有经验的工程师来说是常识,但对AI编辑器来说却不是你不写,它不会自动遵守这些规范在花10分钟内定好。后面每一次建表,每一次查

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)