CNN更看重Texture还是shape:Stylized ImageNet
《CVPR2019_imagenet-trained cnns are biased towards texture increasing shape bias improves accuracy and robusteness》
实验一、TEXTURE VS SHAPE BIAS IN HUMANS AND IMAGENET-TRAINED CNNS
这个实验为了证明,CNN到底依赖的是Texture 还是shape信息。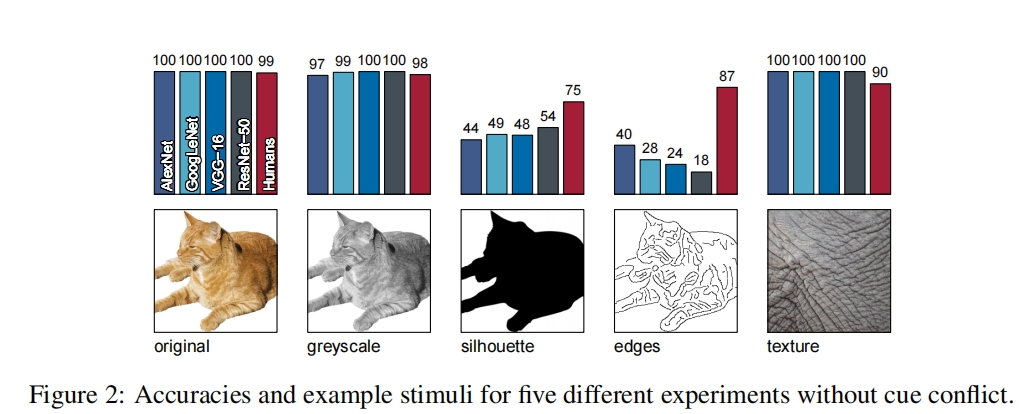
作者通过这样的实验,证明CNN是依赖texture纹理信息的,首先,设置数据集,将纹理、颜色、形状等分离开,上面中的original 是原始自然图像,CNN和人类都能很好的进行分辨;greyscale是灰度图,包含形状、纹理,但是没有颜色信息,CNN和人类依旧很好的区分开;silhouette图片只有目标的形状,没有纹理和颜色,CNN的准确率下降了好的,但是人类却能很好的识别到,对于edges图片也是同样的情况;人类的识别率下降这个说明,人类识别图片,和纹理没有关系。
另外在轮子中,有个实验测试了例如GoogLeNet ,Alexnet等的不同模型的texture bia的程度,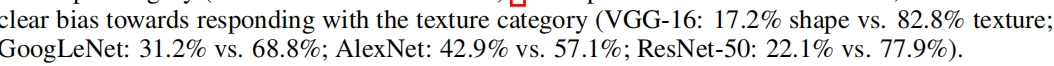
AlexNet shape vs texture 42.9% vs. 57.1%,看到这个结果还是挺惊讶的,因为AlexNet,这个最老,最浅的模型,反而更像人:
- AlexNet只有8层,表达能力远弱于现代CNN,因此它不能特别精细地记忆海量局部纹理组合,高阶的纹理信息统计,因此不得不更多利用细粒度结构,更多依赖低频信息,即它没有能力把纹理学到极致;
- AlexNet是11x11的大的卷积核,而且stride = 4, 这种11x11卷积意味着模糊平滑,然后降采样,所以那些高频的纹理,即图像中变化很快的地方,比如草地纹理,毛发,细条纹等,高频信息被损失,stride=4更严重,因为有些高频纹理,可能只有2~3个像素,stided=4,4个像素保留一个,直接被平滑掉了。AlexNet 输入是224x224,,一下子变成了55x55的特征,细节丢失,只保留大概轮廓;
- 同时AlexNet 网络比较浅,对复杂的texture 建模能力有限。
VGG16 shape vs texture 17.2% 82.8%, texture 偏置最严重
-
VGG里面全是3x3的小卷积堆积,3x3本质上是局部边缘检测器,因为3x3能同时看到中心点,上下左右,对角线,这是最小的二维局部结构感受野,1x1根本看不到邻居。
-
3x3网络连续堆积后,网络逐渐学习局部纹理的层级组合,第一层输入原图后,使用3x3核进行卷积,输出非常像sobel Gabor filter 即方向边缘检测器,例如我们使用垂直边缘检测器,入下图
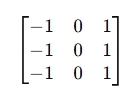
当这个垂直检测器对原图进行卷积后,输出的是,哪里有竖直边缘,第二层的输入已经不是RGB的像素值了,而是边缘1响应图,边缘2响应图,边缘3响应图等,即多通道边缘图,有可能是64个feature map,第二层的卷积核是3x3x64,同时观察多个边缘响应图,而是在检测边缘之间的组合关系,第一层是边,第二层学到的是边的组合。于是整个过程一直在局部patch世界里。 -
CNN很难天然许shape,因为shape 需要远距离结构关系,例如耳朵在头顶,眼睛左右对称,轮子在车下面,但是连续3x3,每次只看局部,所以更容易学到局部统计规律,而不是全局几何结构。
实验二、OVEROMING THE TEXTURE BIAS OF CNNS
-
很多网络结构在ImageNet上的准确率很高,是CNN整合了很多局部纹理特征,而不是看过了全局特征后,得到了类别,ImageNet上局部纹理和类别高度相关,例如,熊,毛皮,大象,灰色皱纹,草地,绿色细纹等,所以即使不知道整体形状,只要收集很多局部纹理统计,也能分类,这个就是CNN的纹理偏置,CNN在ImageNet上找到了纹理和类别这种偏置,于是选择走这种捷径;
-
SIN 是 stylized ImageNet,风格imageNet,它利用风格迁移把图片纹理替换掉,例如,大象的形状保留,把纹理可能变成油画笔触,或者梵高风格,或者马斯克纹理,于是原本“局部纹理”到类别的捷径被破获掉了,只有轮廓,几何结构,部件关系,全局空间布局,也就是形状信息。
-
改实验还提到,在ImageNet上训练的模型,在SIN上的测试结果为16.4%,在SIN上训练的模型,在ImageNet上的测试结果为82.6%。具体详情如下:
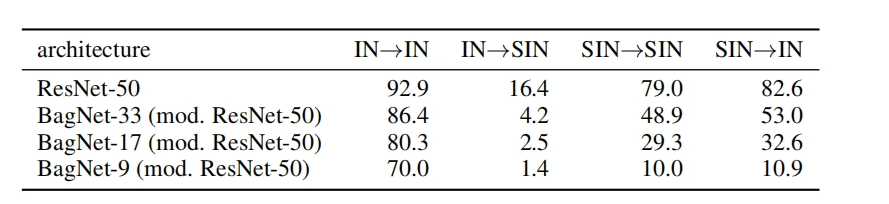
ResNet50在ImageNet训练和测试,得到92.9的准确率,在ImageNet上训练,在SIN上测试,得到16.4的准确率,在SIN上训练和测试,得到79的准确率,在SIN上训练,在ImageNet上测试,得到82.6的准确率。在SIN上训练,SIN迫使网络去学习形状信息,而整个形状信息在ImageNet上去区分类别,也是可行的。而BagNet在看重纹理信息的ImageNet上,训练和测试,效果挺好的,同样ImageNet训练的模型在SIN上崩溃,而SIN上训练的模型可以在一定程度上提升测试结果。 -
BagNet,刻意去限制感受野,普通的CNN,大量使用3X3卷积,stride和stacking,会导致感受野越来越大,最终网络能看到整个物体,长距离结构,全局空间关系,而bagNet,通过把很多3x3卷积改成1x1卷积,因为1x1卷积不扩大感受野,从而将感受野控制在9x9、17x17、33x33,意思是,最终每个输出位置,只能看到9x9输入区域,即一个神经元只依赖9x9patch,无法看到物体整体,长距离关系,全轮廓等。例如,输入狗,普通CNN可能学习头+身体+尾巴的空间关系,而bagNet只会毛发纹理,鼻子局部,耳朵纹理,然后统计这些patch,但是不理解狗的整体形状。
-
BagNet9x9在ImageNet上获得了70%的准确率,而在SIN数据集上,只获得10%的准确率,BagNet在SIN上全面崩溃,因为BagNet根本看不到大范围结构,它只能看到9x9小块,但是SIN已经把局部恩脱离和小区域统计特征破获掉了,于是9x9 patch无法提供类别信息,网络必须把远距离区域组合起来,例如,头在哪里,腿在哪里,身体轮廓如何连接,这种长距离空间关系,BagNet看不到,因此性能直接崩溃。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)