多模态的端到端跃迁:SenseNova U1 原生图文交错生成能力与技术应用全景解析
摘要: 商汤科技推出的原生多模态大模型SenseNova U1通过NEO-unify架构实现端到端图文生成,解决了传统模型中文乱码、排版混乱的痛点。测试显示其具备三大核心能力: 高密度图文闭环:精准生成商业图表并反向解析为结构化数据,中文排版达到印刷级清晰度; 物理级视觉重构:材质替换时保持光学反射规律,如镜面不锈钢杯身能真实倒映环境细节; 长上下文图文交织:支持多格漫画等复杂叙事,角色与道具跨帧
多模态的端到端跃迁:SenseNova U1 原生图文交错生成能力与技术应用全景解析
引言:告别多模态大模型的“缝合怪”时代
在文生图领域,准确生成中文字符一直是个痛点。以往使用 Midjourney 或 Stable Diffusion 等模型时,生成的汉字经常出现扭曲、乱码,很难直接用于设计成品。
近期,商汤科技在线上平台开放了原生大模型 SenseNova U1。该模型主打“高密度中文排版”能力,以下是线上平台的使用时的感受:
以下是线上平台实测的硬核表现:
场景一:图文大闭环(高密度图表) 测试高密度图表时,中文标题笔画清晰、无乱码,艺术字体的光影能融入背景。
场景二:推理级视觉重构(物理与时间规律) 在单张 16:9 画布中支持多列网格、线框图标和密集正文,版面空间逻辑合理,无模块重叠。
场景三:原生图文无缝交织(长上下文框架) 输入“智能家居产品功能路线图”等指令,模型能准确输出“智能温控系统”和“传感器矩阵”等专业词汇,图标与文字对齐准确。
场景四:原生图文交错生成(精细排版) 图文混合生成流畅,文字与图像排版同步完成,基本解决了传统模型文字乱码的痛点。
该平台目前免费开放。用户无需配置本地显卡、CUDA 环境或下载几十 GB 的模型权重,直接通过浏览器即可完成海报、产品灵感或数据看板的图文排版。
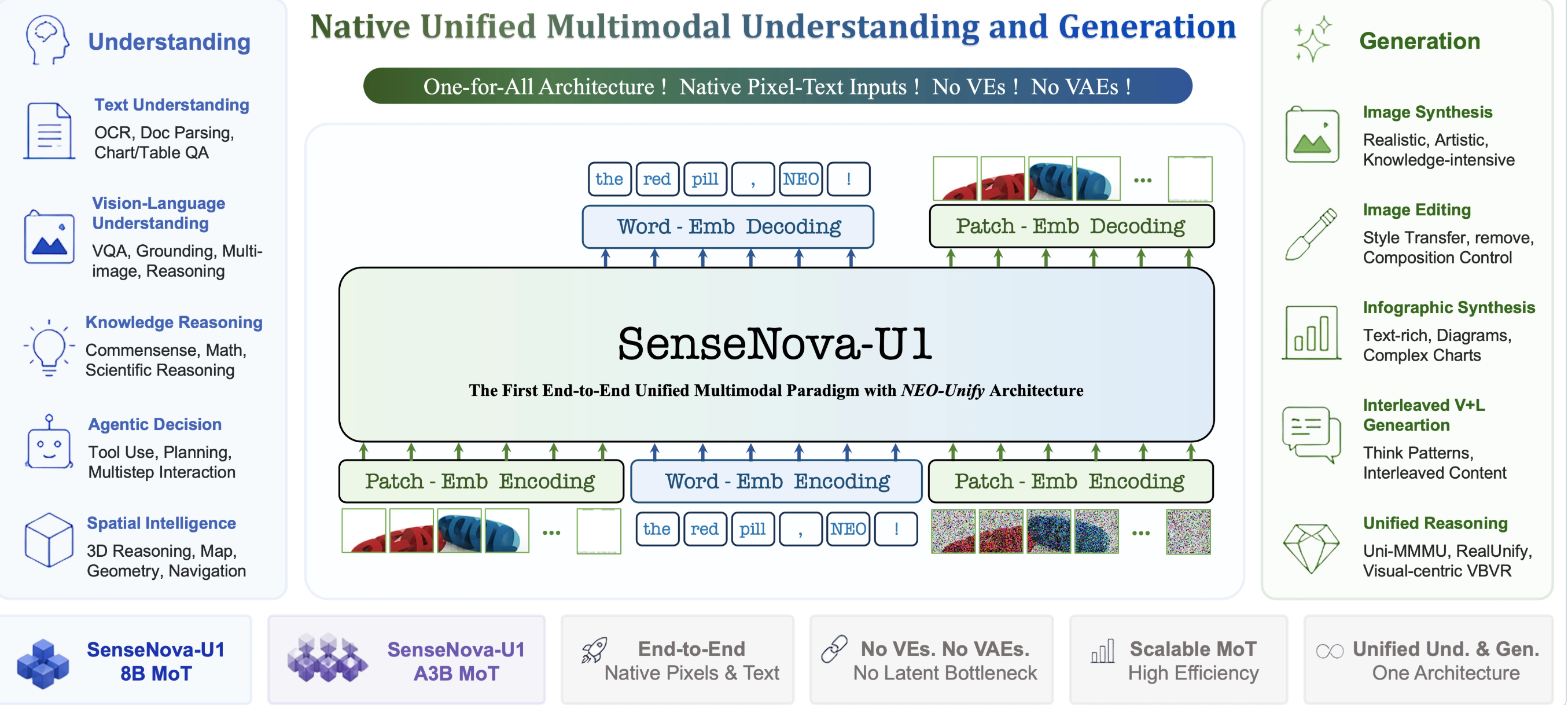
一、 中央核心:NEO-unify 端到端架构
-
真正的一体化架构(NEO-unify): 它彻底踢开了视觉编码器(VE)和变分自编码器(VAE)。文本和图像在模型最底层就是同一种表征,机器不再需要通过“中间商”倒手翻译,理解和生成端到端一步到位。
-
生图界最懂中文排版的“打字机”: 过去 AI 生图最怕写字(尤其是汉字)。U1 拥有强悍的“高密度视觉信息表达”能力,生出来的中文不仅不乱码,而且笔画清晰、横平竖直,能直接做商业级的海报、PPT 和复杂信息图表。
-
能看能想还能执行(Agent 基因): 除了能搞定高精度的 OCR 和图文互生,它还原生支持智能体(Agent)决策。结合配套的 OpenClaw 技能库,它能直接看懂复杂的硬件连线、报错日志,并自动调用本地工具去干活。
二、三大前沿场景极限大考:全方位拷问 SenseNova U1 的“大一统”硬实力
2.1 场景一:图文大闭环(结构化数据与高密度图表的双向无损互转)
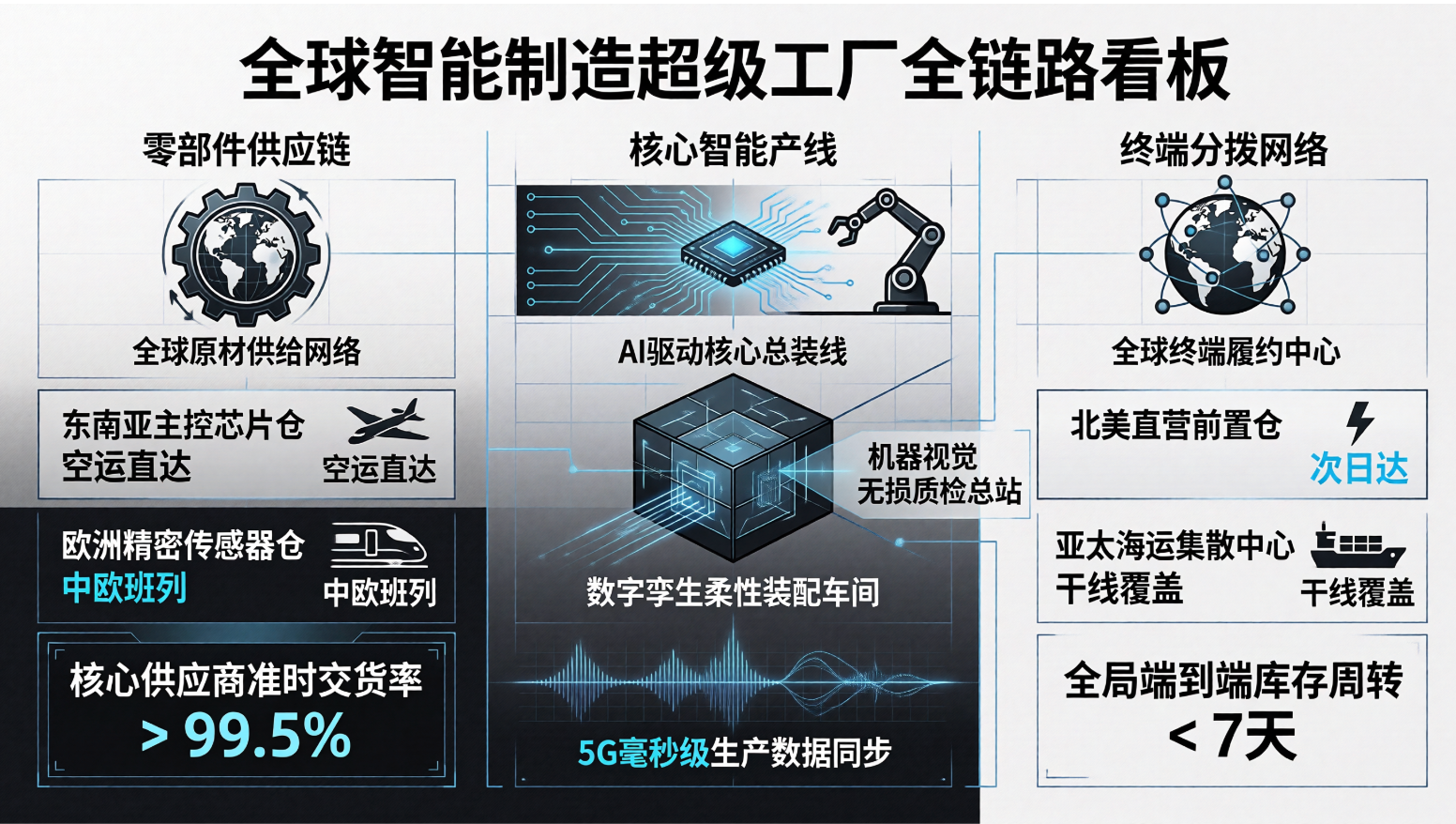
为了测试“高密度图文大闭环”能力,我们选择了一个通用的商业场景进行测试:全球智能制造超级工厂全链路看板
2.1.1 第一环:生成端(像素构建)
首先,向 SenseNova U1 输入这个 Prompt:
这张商业信息图的标题是“全球智能制造超级工厂全链路看板”,采用现代极简的工业科技幻灯片风格,长宽比为 16:9。
整体布局为水平三列网格结构,背景采用干净的哑光纯白底色,带有极淡的浅蓝色科技网格线。
排版要求严谨的视觉层级:主标题使用粗体深炭黑字,正文使用现代无衬线等宽字体,边框使用细炭黑线,核心关键指标使用深邃蓝强调。
画面正上方居中位置,高精度渲染大标题:“全球智能制造超级工厂全链路看板”。标题正下方是副标题:“采购-生产-分拨端到端拓扑”。
画面主体从左到右划分为三个相等的垂直物理区块,区块之间留有充足的负空间:
1. 【左侧区块 - 零部件供应链】:顶部绘制一个带有集装箱与齿轮的极简线框图标,旁边是粗体小标题“全球原材供给网络”。区块内部包含两个包裹在细黑色边框内的独立卡片,分别清晰标注中文:“东南亚主控芯片仓(空运直达)”与“欧洲精密传感器仓(中欧班列)”。卡片下方统一用较小的字体配文:“核心供应商准时交货率 (OTD) > 99.5%”。
2. 【中间区块 - 核心智能产线】:顶部绘制一个带有机械臂与芯片的图标,旁边是粗体小标题“AI 驱动核心总装线”。区块内部包含两个垂直排列的大卡片:上方标注“数字孪生柔性装配车间”;下方标注“机器视觉无损质检总站”。两者之间用带箭头的细实线自上而下连接,并在中央线条旁标注深邃蓝大字:“5G 毫秒级生产数据同步”。
3. 【右侧区块 - 终端分拨网络】:顶部绘制一个带有货运飞机与地球的图标,旁边是粗体小标题“全球终端履约中心”。内部垂直分布着两个浅灰色底色的长方形色块,内部左侧对应圆形打勾标记,右侧分别精准标注文字:“北美直营前置仓(次日达)”与“亚太海运集散中心(干线覆盖)”。最下方配有一行强调文本:“全局端到端库存周转 < 7天”。
画面整体线条极其锐利,所有中文文本、英文缩写和数字必须字形端正、横平竖直,禁止任何拼写模糊或像素揉搓。
- 实测未出现乱码、字形扭曲或构图崩溃。SenseNova U1 遵循了“水平三列网格”的空间划分,其中的工业术语书写清晰,达到了印刷级清晰度。
2.1.2 第二环:理解端(逻辑剥离)
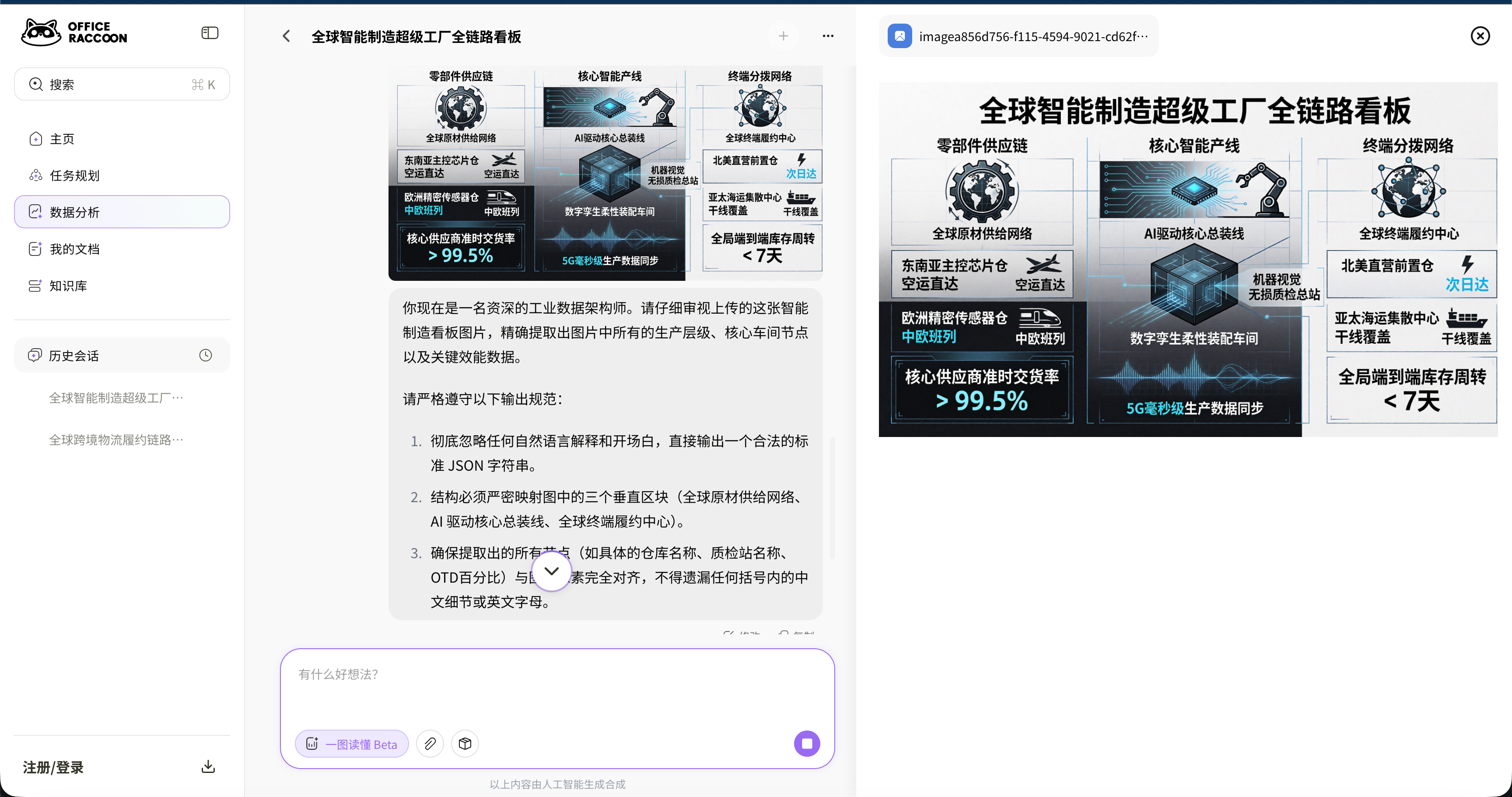
获取 U1 生成的工业看板图片后,清空对话上下文。将图片重新上传至 U1 的视觉理解端,通过以下指令进行信息提取:
你现在是一名资深的工业数据架构师。请仔细审视上传的这张智能制造看板图片,精确提取出图片中所有的生产层级、核心车间节点以及关键效能数据。
请严格遵守以下输出规范:
1. 彻底忽略任何自然语言解释和开场白,直接输出一个合法的标准 JSON 字符串。
2. 结构必须严密映射图中的三个垂直区块(全球原材供给网络、AI 驱动核心总装线、全球终端履约中心)。
3. 确保提取出的所有节点(如具体的仓库名称、质检站名称、OTD百分比)与图像像素完全对齐,不得遗漏任何括号内的中文细节或英文字母。
-
把刚才生成的图直接传回去,不给任何提示,让它反向生成 JSON 数据。
-
结果识别得很准。像
\>99\.5%、5G毫秒级这些角落里的小字都认出来了,没有漏掉。而且图里的左、中、右排版格子,它也能看懂。 -
另外它还会自己做阅读理解,主动把长句子拆成了技术标签和应用范围。
-
以前的生图模型字是乱的,看图也看不懂;现在这个不仅能把中文写对,还能把图里复杂的数据再读回去。以后做 RPA 和自动化时,只要在提示词里定好规则,用它来认图、提取数据完全够用。
{
"全球原材供给网络": {
"东南亚主控芯片仓": {
"运输方式": "空运直达",
"核心供应商准时交货率": ">99.5%"
},
"欧洲精密传感器仓": {
"运输方式": "中欧班列",
"核心供应商准时交货率": ">99.5%"
}
},
"AI驱动核心总装线": {
"机器视觉无损质检总站": {
"检测类型": "无损质检"
},
"数字孪生柔性装配车间": {
"装配类型": "柔性装配"
},
"生产数据同步": {
"技术": "5G毫秒级",
"同步范围": "生产数据"
}
},
"全球终端履约中心": {
"北美直营前置仓": {
"服务时效": "次日达"
},
"亚太海运集散中心": {
"覆盖类型": "干线覆盖"
},
"库存管理": {
"周转周期": "<7天",
"管理范围": "全局端到端"
}
}
}
2.2 场景二:推理级视觉重构(引入物理与时间规律的深度图像编辑)
一般的 AI 修图工具换材质时,只会简单改个颜色或换张贴图,光影反射看起来很不自然。这次我们主要测试:SenseNova U1 换了材质以后,能不能把画面里该有的反光和折射等物理效果做得更自然。
- 基底原图准备

-
一个白色哑光杯身、棕褐色翻盖杯盖的便携式咖啡杯,放在印有卡通小熊和清晰文本“...SUCH GOOD SPIRIT”的蓝色桌垫上,背景是键盘和笔记本。光源清晰,有阴影。
-
【施加逻辑重构 Prompt】
指令:请将杯身的白色哑光材质整体替换为高抛光的镜面不锈钢,并将杯盖的棕褐色材质替换为半透明的琥珀色树脂(Amber Resin)。
要求:请体现出镜面不锈钢杯身对周围环境(蓝色的桌垫小熊图案、文本“...SUCH GOOD SPIRIT”以及键盘键位)的精准、具有透视光学规律的反射(倒影)。同时,请体现出琥珀色树脂杯盖对杯中热咖啡深色液体的折射和光线穿透效果。
像素锁死:桌垫上的卡通小熊图案、文本“...SUCH GOOD SPIRIT”的位置必须像素级保真,背景的键盘和笔记本位置像素级保持不变。光源和整体阴影角度保持一致。

四个地方简单总结
-
光影和材质挺逼真: 不锈钢杯子换成了镜面效果,能照出旁边卡通熊和键盘的倒影。琥珀色的盖子也做出了透明和透光感。
-
能把没露全的字补齐: 原图桌垫上的英文被挡住了一截,只露出
\.\.\.ONE CHILD。AI 自己猜出了整句话 “EVERY CHILD IS SUCH A GOOD SPIRIT”,而且工整地印在了新杯子上。 -
背景: 杯子虽然变了,但后面的键盘和桌垫小熊都没变形,位置也没错。
-
排版: 不仅换了材质,它还顺手把图排成了产品对比海报,连参数都帮着标上去了。
2.3 场景三:原生图文无缝交织(长上下文框架下的多模态流式编排)
请讲一下经典寓言《乌鸦喝水》,但这次请给出出一个极简绘本风的温馨改编版图文故事。这只聪明的乌鸦不满足于扔石头,它用森林里的落叶和树枝组装了一个微型“杠杆抽水机”。在它成功喝到水的那一刻,请原生生成一张治愈系插图:小乌鸦正用叶子卷成的吸管惬意地喝着水,旁边围满了给它鼓掌的森林小动物,画面色调要充满阳光和生机。

主要在以下三点:
-
**字迹: **图里所有的中文标题和总结(比如“聪明的小乌鸦”)都很清晰,没有出现乱码或看不懂的字。
-
角色: 六宫格里乌鸦的样子前后长得一样,它拼装的那台绿色抽水机在每一格里也能对得上,画面没有穿帮。
-
排版: AI 自己排了 2×3 的六宫格,按照口渴、想办法、动手做、到最后喝水和分享的顺序进行,符合提示词的意思。
2.4 场景四:原生图文交错生成能力体验(精细排版)
前面测试了模型在多格分镜上的排版能力,场景四则主要测试它在“复杂顺序步骤”以及“精细排版”上的表现。
这个环节是为了测试大模型在一次输出中,能不能模拟画师的创作过程——从最开始的画骨架、再到丰富线条、最后填充色彩和阴影。这不仅需要模型画同一个角色(比如蜘蛛侠)时保持长相一致,还要求它同步输出每一步对应的教学文字。
ptompt : 生成手绘蜘蛛侠的一系列图案
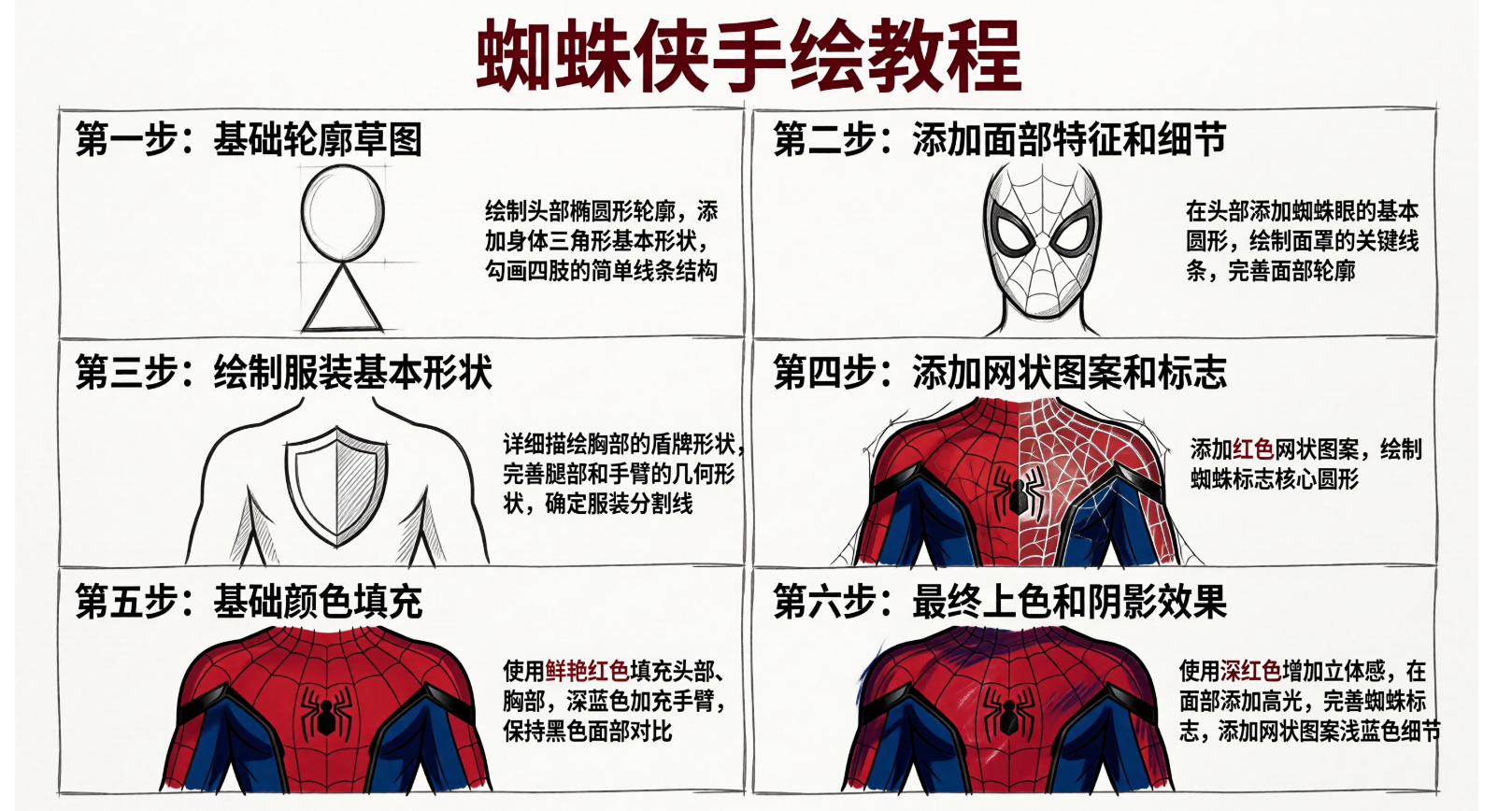
从实际输出的《蜘蛛侠手绘教程》大图来看,大模型在单模型、单链路流程下展现出了令人惊叹的过程流控与空间对齐能力。以下为核心技术亮点解析:
-
步骤逻辑: 画面按照“从简单到复杂”的画画规律进行。第一步是用圆形和三角形画骨架;第二、三步加上脸部和身体轮廓;第四步在没上色的线稿上画上了蜘蛛网图案;最后两步完成了上色和加阴影。整个画画的过程顺序是对的。
-
局部细节: 在连续的几个步骤图里,蜘蛛侠胸前的标志、眼睛的黑色边框比例以及网格线的疏密都对得很齐,没有出现前后长相不一致、标志画歪或位移的情况。
-
排版文字: 图片用了标准的 2×3 六宫格排版。两边的文字说明(比如“绘制头部椭圆形轮廓……”等)和画面的内容正好对应,中文写得工整,字迹清晰,排版看起来挺干净。
三、结语:大模型的多模态终局——从“技术拼凑”走向“端到端原生协同”
测试完这四个核心场景,我们对这个新大模型的能力有了个整体的了解。这四个场景其实代表了模型在不同层面的表现:
-
场景一: 测的是怎么把文字、数据直接变成对齐的图。
-
场景二: 测的是画面动起来、换材质时,光影和空间逻辑合不合理。
-
场景三与场景四: 无论是多格连环画还是手绘教程,测的是长对话下,能不能一直管好剧情和角色的细节,不画崩、不走样。
通过这次全面体验,有三个很直接的感受:
不用再搞“拼凑式”的多模态了
- 以前想做这种功能,得用“大语言模型 + 文生图 API + 前端代码硬拼接”,用起来很别扭。现在单模型自己就能搞定,文本、代码和图像在底层是通的,多模态交互确实自然多了。
排版能力成了新的分水岭
- 以后的技术竞争,可能不单单是比谁画的画质更细腻,而是比模型对整张图版面的掌控力。好的模型得懂怎么自动给图像、代码和文字留出舒服的阅读空间。说白了,排版能力就是多模态下的硬实力。
“前后长相一致”才能真正干活
- 在画连续的图(比如连续的步骤教学)时,主角、机器或者标志不画歪、不频繁变脸,大模型才能真正从一个“好玩的玩具”,变成能用来画工业绘本、做高精度 UI 或者搞商业设计的生产力工具。
技术生态与本地部署
-
源码主仓 (GitHub):
-
(前往获取核心底座代码与本地环境配置指南)
-
权重资产 (Hugging Face):
-
(下载全量多模态模型权重与配置文件)
-
Agent 技能扩展生态:
-
(开箱即用的插件库,赋予智能体高阶的多模态编排能力)
-
您可以直接访问 办公小浣熊官方平台,在功能区内解锁 【一图读懂】 特色模块,免去繁琐的本地部署,即刻秒级生成高颜值视觉排版。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)