Agent上下文工程完全指南
本文探讨如何在有限上下文窗口中高效管理信息。核心内容包括:1) 精准设计System Prompt、工具定义和状态注入;2) 采用滑动窗口、渐进摘要等策略优化窗口管理;3) 实现四种记忆形态(上下文/外部/参数/工作区)的协同;4) 多智能体协作时的上下文传递机制;5) 通过Token用量、信息命中率等指标评估优化。文章提出三条设计原则:即时注入、结构化压缩和可观测性,强调需在完整性/精简性、实时
Agent 上下文工程完全指南
上下文工程到底应该怎么做,这篇文章带大家一起探究。
核心问题只有一个:在有限的 context window 内,放置恰好足够的信息。
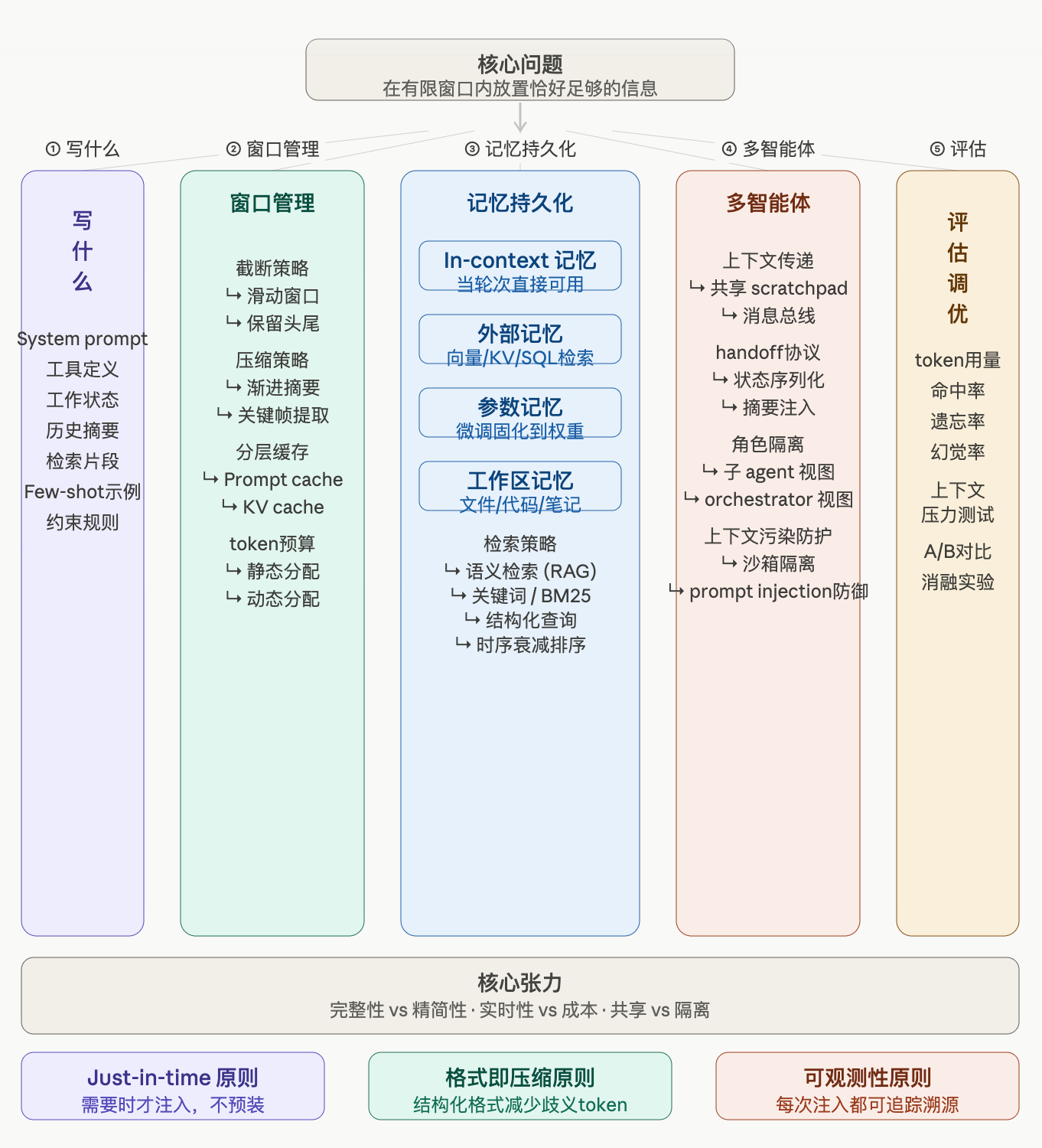
一、写什么进上下文
内容层——决定"放什么进去"。
System Prompt 设计
不只是角色描述,而是 agent 的"操作系统"。包含身份、行为规范、输出格式、边界条件、异常处理逻辑。写得越精准,模型浪费在歧义消解上的推理就越少。
工具定义
工具 schema 的字段名、描述文字、参数类型,直接影响模型选择和调用工具的准确率。描述模糊的工具会导致错误调用或冗余调用。
状态注入
把当前任务进度(已完成哪些步骤、当前卡在哪里、还剩什么目标)以结构化方式写入。常见格式是 JSON 状态块或 Markdown checklist。
按需注入
检索片段(RAG 结果)、Few-shot 示例、约束规则——需要时才注入,不预装。这就是 just-in-time 原则的精髓。
二、窗口管理
截断策略
- 滑动窗口:丢弃最早的消息
- 保留头尾:首轮 system prompt + 近期消息,适合长任务
- 重要性打分:选择性保留关键轮次
压缩策略
- 渐进摘要(Progressive Summarization):每轮末尾把历史对话压成摘要,下一轮只带摘要
- 关键帧提取:只保留"决策节点"和"状态变更点",丢弃过程性闲聊
分层缓存
- Prompt Cache:把不变的 system prompt 缓存,避免每轮重复计费
- KV Cache:推理层减少重复计算
Token 预算管理
规划阶段需要更多推理空间,执行阶段需要更多工具调用空间,按任务类型动态分配,不能一刀切。
三、记忆持久化
Agent 的"记忆"有四种形态:
| 类型 | 机制 | 适用场景 |
|---|---|---|
| In-context 记忆 | 直接放在当前窗口 | 短任务、即时信息 |
| 外部记忆 | 向量库 / KV / SQL 检索回填 | 长期知识、跨会话 |
| 参数记忆 | 微调固化到模型权重 | 领域专业知识 |
| 工作区记忆 | 文件 / 代码 / 笔记本 | 复杂任务的中间产物 |
检索策略
- 语义检索(RAG):适合非结构化知识
- BM25 关键词匹配:适合精确术语
- 结构化查询(SQL / 图查询):适合关系型数据
- 时序衰减排序:优先返回近期相关记忆,防止陈旧信息污染判断
四、多智能体上下文传递
上下文传递模式
- 共享 Scratchpad:所有 agent 读写同一个状态文件,适合紧耦合协作
- 消息总线(事件队列):agent 异步传递结构化消息,适合松耦合流水线
Handoff 协议
序列化当前完整状态交给下一个 agent,还是只注入摘要——直接影响下游 agent 的理解质量。
角色隔离
子 agent 只看到与自己任务相关的上下文切片,orchestrator 保留全局视图。既节省 token,也防止信息泄露和角色混淆。
Prompt Injection 防御
从网页、文件、数据库读入的内容可能夹带伪造指令,注入上下文前必须做沙箱化清洗。
五、评估与调优
上下文工程是实验科学,必须有度量才能优化。
核心指标
- Token 用量:直接影响成本
- 关键信息命中率:检索的内容有没有真正被用上
- 任务遗忘率:agent 是否丢失了重要的历史决策
- 幻觉率:上下文不足时模型是否开始编造
测试方法
- 上下文压力测试:在极长任务、极多工具场景下观察 agent 行为是否退化
- 消融实验:逐一去掉某类注入内容,观察任务成功率变化,精确定位哪些内容真正有价值
- A/B 对比:不同上下文构建策略的横向对比
三条底层设计原则
① Just-in-time 原则
不要预装所有信息,只在需要时注入,保持窗口干净。
② 格式即压缩原则
结构化输出(JSON、Markdown 表格)本身就是一种压缩,减少歧义 token。
③ 可观测性原则
每次往上下文注入什么,必须可追踪、可审计。否则调试和优化无从下手。
核心张力
在实践中永远要平衡三组张力:
- 完整性 vs 精简性:信息越全越好,但窗口有限
- 实时性 vs 成本:每轮重新检索最准,但推理成本高
- 共享 vs 隔离:多 agent 共享上下文协作更顺畅,但安全边界模糊
上下文工程没有银弹,只有针对具体任务的最优解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)