LangChain大模型应用开发框架详解:从入门到实战,构建智能体与私有知识库
LangChain是一个开源的大模型应用开发框架,旨在将大语言模型(LLM)从简单的聊天功能扩展为可落地的工程化应用。它通过六大核心模块(模型层、提示词工程层、记忆层、链层、数据连接层和智能体层)解决了LLM的幻觉、知识截止等问题,支持RAG检索增强生成和Agent智能体技术。LangChain可快速搭建知识库问答、自动化工作流等应用,支持云端和本地模型调用,具有组件齐全、生态完善等优点,但也存在
LangChain是一个开源大模型应用开发框架,旨在将大语言模型(LLM)从简单的聊天能力封装成可落地的工程化应用。它通过六大核心模块——模型层、提示词工程层、记忆层、链层、数据连接层和智能体层,解决了LLM的幻觉、知识截止、上下文限制等问题。文章详细介绍了LangChain的工作流程、核心技术(如RAG检索增强生成和Agent智能体)、生态组件以及典型应用场景,并通过实例展示了如何使用LangChain结合Ollama本地模型搭建私有知识库问答系统。此外,还探讨了如何通过提示词工程、RAG检索增强和模型微调三层改造方法来适应自身需求构建智能体。
本文包括以下内容:
Q1:什么是LangChain
Q2:LangChain工作全流程
Q3:如何改造LLM以适应自身需求构建智能体
Q4:langchain与ollama的关系是什么
Q5:具体如何使用langchain
Q1:什么是LangChain
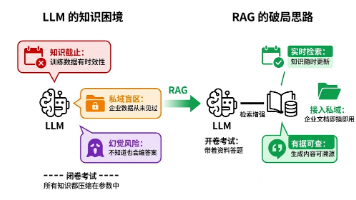
LangChain 是2022年底推出的开源大模型应用开发框架,由 Harrison Chase 开发,基于 Python/JavaScript,核心定位是把大语言模型(LLM)从单纯聊天能力,封装成可落地的工程化应用,解决大模型幻觉、无外部知识、无法调用工具、上下文有限、无法串联复杂任务等问题。下图是llm以及rag应用过程。
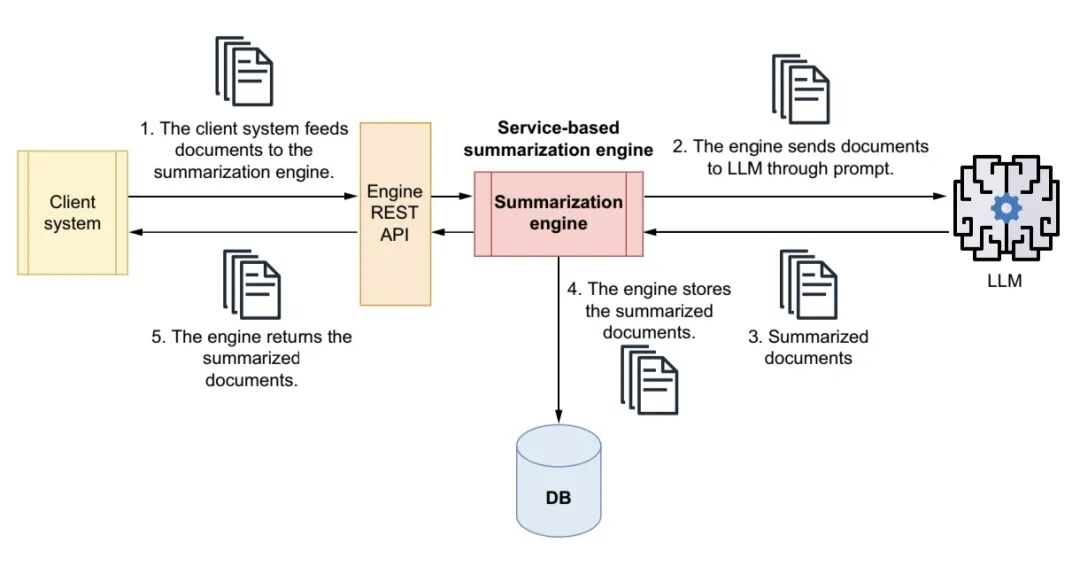
图1 LLM应用过程
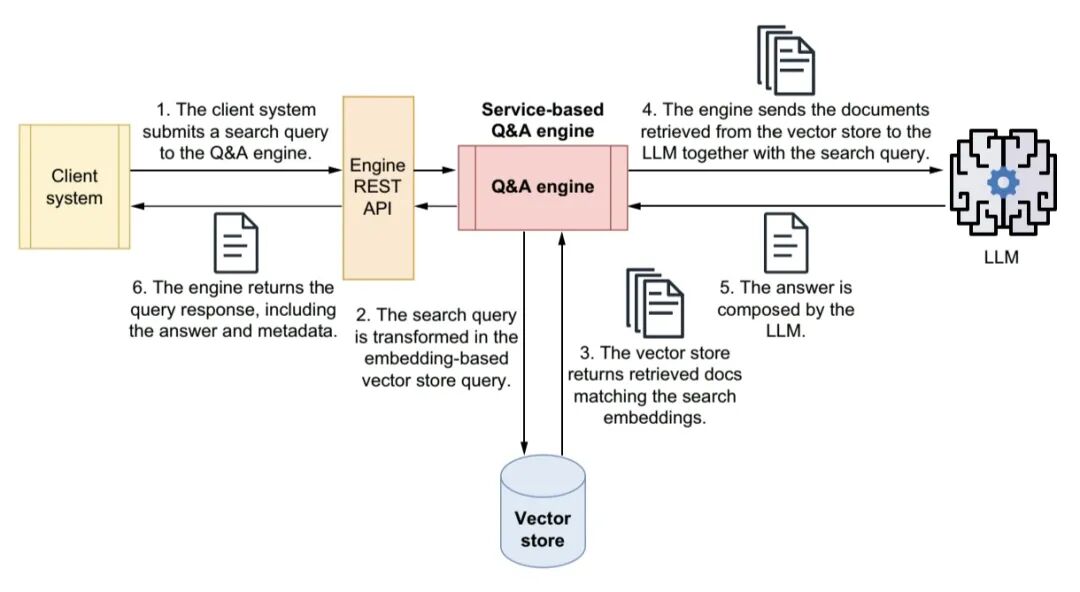
图2 检索增强生成(RAG)过程
一、概述
(一)大模型llm的缺点
- 知识截止时间固定,不能用私有数据、实时数据
- 上下文长度有限,不能直接读长文档、海量知识库
- 没有记忆,多轮对话容易遗忘上下文
- 不会调用外部工具,比如搜索、数据库、API、计算器等
- 无法自动规划多步骤复杂任务
- 提示词管理混乱,难维护
(二)LangChain 作用
能够提供标准化组件,让开发者不用从零写底层逻辑,可以快速搭建RAG知识库、Agent智能体、对话机器人、自动化工作流、数据分析助手等。
二、LangChain整体架构
LangChain 所有功能主要包括六大核心模块:
- Models(模型层:统一调用各类大模型)
提供统一接口,屏蔽不同厂商 API 差异,一行代码便可切换模型。
- 云端模型:OpenAI、通义千问、文心一言、字节豆包、Anthropic等
- 本地开源模型:Llama、Qwen、GLM、通过 Ollama / vLLM 调用等
- 支持:聊天模型 ChatModel、嵌入模型 Embeddings(做向量检索)
- Prompts(提示词工程层)
标准化管理提示词,解决硬编码问题。
- PromptTemplate:模板化提示词,动态插入变量
- FewShotPromptTemplate:少样本提示
- 输出解析器 OutputParser:强制大模型输出 JSON、列表、指定格式,方便程序解析
- Memory(记忆层:让AI记住历史)
给对话增加上下文存储,支持多轮连续对话。
- ConversationBufferMemory:完整保存所有对话
- SummaryMemory:自动总结历史,节省 token
- VectorStoreMemory:向量形式记忆,支持长期记忆
- 支持持久化:存入 Redis、数据库、文件
-
Chains(链:串联多个步骤,实现流水线任务)
LangChain 最核心组件,把多个组件按顺序执行,形成工作流。
常见内置链:
☆LLMChain:最简单,提示词 + 模型 + 输出解析
☆RetrievalQA:RAG核心链,文档检索 → 传给大模型回答
☆SequentialChain:顺序执行多步任务(翻译→总结→改写)
☆RouterChain:路由分发,根据问题类型调用不同模型/工具 -
Data Connection(数据连接层:对接私有数据)
实现大模型读取私有文档、外部数据,是 RAG 的基础。
★Document Loaders:文档加载器,可以加载PDF、Word、Excel、网页、数据库、CSV等
★Text Splitters:文本分割器,可以按字符、语义、递归分割,适配向量库
★Embeddings:文本向量化
★Vector Stores:向量数据库,如Chroma、FAISS、PGVector、Milvus、Redis等
★Retrievers:检索器,从向量库召回最相关内容 -
Agents(智能体层:自主决策、自动调用工具)
LangChain 最高级功能,让 AI 自己思考:
我要完成什么任务 → 需要哪些工具 → 调用顺序 → 整理结果
支持工具:联网搜索、计算器、代码解释器、数据库查询、API调用、文件读写
主流 Agent:
- ReAct Agent:推理+行动,最经典
- Plan-and-Solve:先规划再执行
- OpenAI Function Agent:基于函数调用
三、核心技术
-
RAG 检索增强生成
具体流程:
私有文档 → 加载 → 分割 → 向量化存入向量库 → 用户提问 → 问题向量化 → 检索相似片段 → 拼接提示词给大模型 → 输出回答
能够解决:大模型幻觉、不能用内部资料问题。 -
Agent 智能体
让大模型脱离固定流程,自主决策、调用工具、循环执行,适合复杂任务。如查天气+查股票+做数据分析+生成报告,自动完成。
四、LangChain 生态 & 配套组件
- LangSmith:LangChain 官方调试、监控、日志、评估平台,可视化链执行过程
- LangServe:把 LangChain 应用快速部署成 API 服务
- LangGraph:最新核心扩展,实现有状态、循环、分支的复杂 Agent(支持多轮迭代、工具调用循环)
五、版本区别:LangChain v0.1 / v0.2 / v0.3
旧版组件耦合重,代码混乱;新版(v0.2+):- 架构重构,更模块化。新版支持 LCEL(LangChain Expression Language),声明式链式编程,可读性极强,更适配 LangGraph,Agent 能力大幅增强,官方主推 LCEL + LangGraph 开发模式。
六、典型应用场景
现在langchain在企业应用较多,其他办公自动化方面也有所涉及,具体包括:
- 企业内部知识库问答、客服机器人
- 文档智能分析:PDF/合同/论文总结、翻译、提取信息
- 个人知识库、本地私有AI
- 自动化办公:自动写周报、邮件、数据分析
- 复杂智能体:联网搜索助手、代码助手、科研助手
- 多模态应用:图文问答、语音对话
七、优缺点
(一)优点
- 组件齐全,开箱即用,大幅降低LLM应用开发门槛
- 模型无关,可快速切换云端/本地模型
- 支持向量库、记忆、Agent、工作流,覆盖90%应用场景
- 生态完善,社区活跃,文档丰富
(二)缺点
- 过度封装,底层原理不透明,调试较难
- 早期版本性能一般,token消耗偏高
- 复杂Agent稳定性依赖大模型本身能力
- 大规模生产环境需要深度二次开发优化
八、与同类框架对比
- LlamaIndex:侧重文档检索、RAG,数据处理更强;Agent较弱
- Haystack:侧重检索引擎,适合大规模知识库
- LangChain:全能型,链+Agent+RAG 均衡最强,最通用
九、开发流程总结
- 选择模型(OpenAI/豆包/本地模型)
- 加载私有数据 → 分割 → 存入向量库
- 构建检索链 RAGChain 或 Agent
- 调试优化提示词、检索参数
- 用 LangServe 部署为 API
- LangSmith 监控日志
Q2:LangChain工作全流程
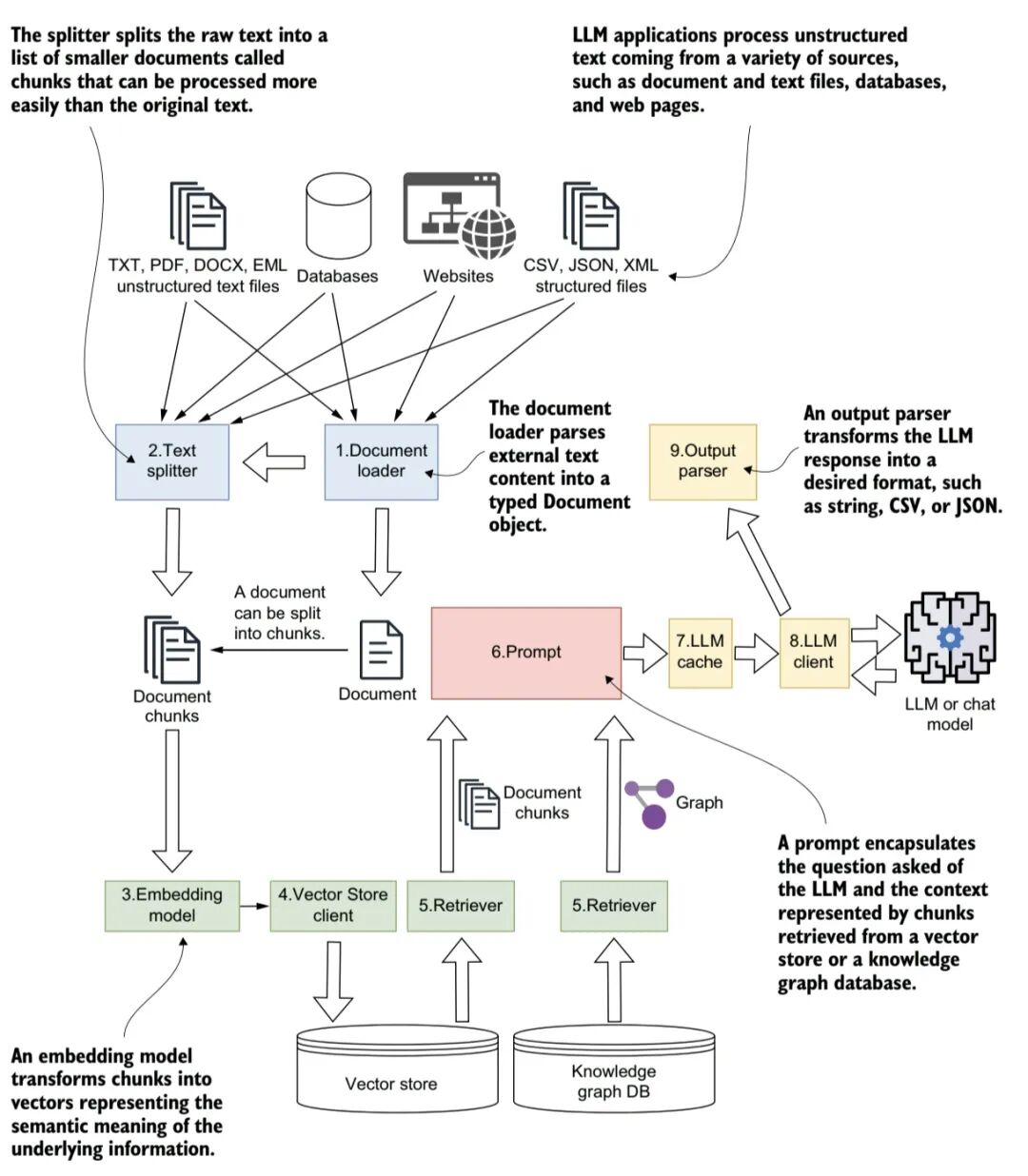
图3 LangChain工作全流程
LangChain本质是:将外部私有数据加工为可被大模型使用的知识 → 用户提问时精准召回相关知识 → 结合问题生成规范回答。
全链路顺序:
数据源 → 文档加载 → 文本分割 → 嵌入向量化 → 向量/图谱存储 → 检索召回 → 提示词构建 → 缓存校验 → LLM调用 → 输出解析
一、第一阶段:离线构建知识库(一次性预处理)
-
Document Loader 文档加载器
数据来源:TXT/PDF/DOCX、数据库、网页、CSV/JSON/XML 等异构数据
LangChain 动作:解析各类格式文件,统一转为框架标准 Document 对象(包含文本内容+元数据)
核心目的:屏蔽文件格式差异,让大模型能读取外部私有数据 -
Text Splitter 文本分割器
输入:完整长文档
LangChain 动作:把超长文本切分成小的文本块 chunks原因:LLM 有上下文长度限制,长文本无法直接输入;小块文本检索更精准
输出:多个短粒度 Document chunks -
Embedding Model 嵌入模型
输入:分割后的文本块
LangChain 动作:将自然语言文本,转为高维语义向量,语义相近的文本向量距离更近 核心:把文字变成计算机可计算的语义信息 -
Vector Store / Knowledge Graph DB 存储
向量库:存储文本向量+原始文本,建立相似度索引,用于快速检索
知识图谱库:存储实体、关系,用于复杂逻辑推理类检索
输出:持久化的私有知识库,等待后续调用到此,离线准备完成,之后进入用户在线问答流程。
二、第二阶段:在线问答推理流程(用户触发)
-
Retriever 检索器(RAG核心)
输入:用户的提问
两条检索路径:一是向量检索:问题转向量 → 在向量库中匹配,召回语义最相似的文本块
;二是知识图谱检索:解析问题中的实体关系 → 从图谱库召回结构化上下文
核心价值:只把和问题相关的信息给大模型,解决幻觉、知识过时、私有知识无法使用的问题
输出:问答所需的参考上下文 -
Prompt 提示词
输入:用户问题 + 检索召回的上下文
LangChain 动作:把系统指令、参考资料、用户问题拼接成完整提示词
模板示例: 基于{上下文},回答{用户问题},禁止编造信息
作用:约束大模型回答的方向、格式、准确性 -
LLM Cache 大模型缓存
输入:构建完成的完整 Prompt
动作:检查是否有相同问题的历史缓存结果命中缓存:直接返回结果,不调用大模型
未命中:进入下一步
目的:降低调用成本、提升响应速度 -
LLM Client 大模型客户端
输入:最终提示词
LangChain 动作:统一对接各类大模型(OpenAI、豆包、通义千问、本地开源模型),屏蔽API差异,调用LLM生成回答
输出:大模型返回的原始文本 -
Output Parser 输出解析器
输入:LLM 原始自由文本
LangChain 动作:将结果转为字符串、JSON、CSV等结构化格式作用:标准化输出,方便对接前端、业务系统
三、全流程闭环总结
- 上游数据层:多源异构数据输入
- 数据处理层:加载 → 分割 → 向量化 → 存储,完成知识库构建
- 检索匹配层:用户提问 → 检索召回相关上下文
- LLM生成层:提示词构建 → 缓存校验 → 调用大模型
- 输出格式化层:解析输出,返回标准化答案
四、对应 LangChain 六大核心模块映射
1.文档加载/分割/向量存储 → Data Connection 数据连接模块
2.提示词构建 → Prompts 提示词模块
3.检索+LLM调用 → Chains 链模块(核心为 RetrievalQAChain)
4.缓存/上下文记忆 → Memory 记忆模块
5.统一模型调用 → Models 模型模块
6.扩展工具调用 → Agents 智能体模块
Q3:如何改造LLM以适应自身需求构建智能体
langchain在构建智能体时,需要用到大模型,目前市面上国内外的大模型功能各异,要想找到适用于自身需要的大模型,主要考虑以下三方面:
提示词工程 → RAG检索增强 → 模型微调
一、提示词工程(Prompt Engineering)
LangChain 智能体第一层改造,不改动模型本身,通过 LangChain 封装提示词,规范智能体行为。
-
角色与指令 Prompt
用 SystemMessage 定义智能体身份、行为规则、回答风格、禁止行为。
-
智能体思考模板(Agent Prompt)
自定义 ReAct / Plan-and-Solve 提示词,强制模型按步骤思考、调用工具、输出格式统一。
-
Few‑Shot 少样本示例
在 Prompt 里加入任务样例,让智能体模仿你的业务逻辑。
-
记忆模块约束
配合ConversationBufferMemory /
SummaryMemory用提示词控制上下文总结、历史对话复用。
适用场景主要包括:通用智能体、简单工具调用、格式规范、语气统一;成本最低,直接在 LangChain 里配置即可,无需训练。
优点是能够快速落地、零算力、调试灵活;缺点是私有知识不足,复杂推理/垂直领域稳定性差。
二、检索增强生成 RAG
LangChain 智能体第二层改造,给智能体接入私有知识库,解决幻觉、私有数据问答,不微调模型。
(一)LangChain 完整改造链路
-
文档加载与切片: DocumentLoader → RecursiveCharacterTextSplitter
-
向量化:OpenAIEmbeddings / BGEEmbeddings
-
向量库存储:Chroma、FAISS、PGVector
-
检索链: RetrievalQA / ConversationalRetrievalChain
-
接入智能体:把 RAG 作为自定义工具注入 Agent,实现:用户提问 → 智能体判断是否查私有知识库 → 检索 → 生成回答
(二)核心价值
-
智能体具备私有行业知识、企业文档、业务手册问答能力
-
避免模型幻觉,信息来源可控
-
可实时更新知识库,不用重训模型
(三)典型架构
Agent → Tools(RAG工具+其他工具) → LLM
三、模型微调 Fine‑tuning
LangChain 智能体第三层深度改造,底层改变模型能力,适配垂直领域、专属话术、复杂任务逻辑
(一)微调后在 LangChain 中如何使用
-
微调方式优先:LoRA 低秩微调(轻量、低成本)
-
微调方向:- 垂直领域问答
-
工具调用格式对齐
-
智能体推理逻辑优化
-
行业术语、输出风格定制
- LangChain 接入:
把微调后的模型,通过 ChatOpenAI / HuggingFacePipeline 接入 LangChain,替换基座模型。
(二)适用场景
-
专业领域智能体(科研、工业、医疗、无人系统、政务等)
-
工具调用频繁、逻辑复杂、通用模型不稳定
-
需要固定话术、固定推理范式
(三)优缺点
优点:智能体深度定制,推理更稳、幻觉更少、垂直能力极强
缺点:需要标注数据、算力成本、部署复杂
四、LangChain 智能体三层改造最佳实践
提示词工程 + LangChain Agent + 内置工具
(一)企业项目版
提示词工程 + RAG检索增强 + LangChain Agent + 自定义工具链
(二)专业深度版
微调基座模型 + 提示词工程 + RAG + 多智能体协作 + 记忆模块
五、总结
-
提示词:规范智能体怎么说话、怎么思考、怎么调用工具
-
RAG:给智能体喂私有知识,解决不知道、幻觉问题
-
微调:改造模型底层,让智能体天生适配你的业务
Q4:langchain与ollama的关系是什么
Ollama 负责本地跑大模型,LangChain 负责给大模型搭应用流程;二者是底层模型以及上层应用框架的上下游配合关系。
一、两者分别是什么
-
Ollama
本质:本地大模型运行工具
作用:一键在电脑/服务器上下载、运行、管理开源大模型(Llama3、Qwen、GLM、Mistral 等),提供本地 API 接口
解决:不用云服务、本地私有化部署大模型,数据不出本地
-
LangChain
本质:大模型应用开发框架
作用:搭建完整RAG、Agent、知识库、对话链(就是你前面那张全流程图),把模型、文档、向量库、检索、提示词串成应用
解决:大模型只是会聊天,LangChain 让它能读文档、查知识库、做复杂任务
二、二者关系
- 层级关系:Ollama 是底层,LangChain 是上层 ,以汽车为例:
-
Ollama = 发动机(大模型本体)
-
LangChain = 整车系统(车身、方向盘、导航、传感器、工作流程)
-
调用关系:LangChain 通过 API 调用 Ollama
-
你用 Ollama 在本地启动一个模型(如 qwen:7b)
-
Ollama 开启本地接口: http://localhost:11434
-
LangChain 直接调用这个接口,把 Ollama 当作本地版LLM客户端
-
LangChain 负责文档加载、切分、向量库、检索、提示词、输出解析;Ollama 只负责生成回答
-
互补关系
-
Ollama:只管跑模型、推理,没有知识库、检索、工作流能力
-
LangChain:不自带模型,可以对接 OpenAI、豆包、通义千问,也可以对接 Ollama 本地模型
三、结合 LangChain 流程图
直接对应图中第8步 LLM client(大模型客户端):
-
云模型: ChatOpenAI 、 ChatTongyi
-
本地模型:Ollama
完整本地私有化RAG全流程(Ollama+LangChain):
文档加载→切分→向量库→检索→Prompt→LangChain调用Ollama本地模型→输出解析
四、通俗举例理解
-
Ollama:把开源大模型装到个人电脑里,让它能说话
-
LangChain:给这个本地模型接上PDF、专利、代码库,做成私人智能助手
没有 LangChain:Ollama 只能单纯聊天,不会读你的私有文档
没有 Ollama:LangChain 只能用云端大模型,无法本地私有化
二者结合后,可以实现纯本地化智能助手
五、实战落地的标准搭配
-
Ollama 本地部署:通义千问/Qwen、Llama3 等开源模型
-
LangChain 搭建RAG:接入论文、D‑H运动学、ROS2、Python代码、技术手册
-
实现:本地私有知识库问答,数据部署于本地
Q5:具体如何使用langchain
结合前面的 LangChain 全流程架构,具体使用过程包括:
文档加载 → 文本分割 → 嵌入向量化 → 向量库 → 检索 → Prompt → 调用模型 → 输出
一、第一步:环境安装
- 安装依赖库
pip install langchain langchain-ollama langchain-chroma langchain-text-splitters pypdf
-
langchain :核心框架
-
langchain-ollama :对接本地 Ollama 模型
-
langchain-chroma :轻量向量数据库
-
pypdf :读取PDF文档
- 提前启动 Ollama(本地模型)
(1)安装 Ollama 后,终端运行:
ollama pull qwen:7b
ollama run qwen:7b
(2)保持 Ollama 服务开启(默认接口 http://localhost:11434 )
二、场景1:最简单对话
直接调用本地 Ollama 模型,实现基础对话
python代码:
from langchain_ollama import ChatOllama
1. 绑定本地Ollama模型(流程图 8.LLM Client)
llm = ChatOllama(model=“qwen:7b”, temperature=0.1)
2. 提示词(流程图 6.Prompt)
res = llm.invoke(“用通俗语言解释什么是D‑H参数”)
print(res.content)
三、场景2:搭建完整RAG私有知识库
功能:上传PDF文档 → 本地向量库存储 → 提问时检索文档回答
python 代码
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_chroma import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
====================== 1. 加载文档(流程图 1.Document Loader) ======================
loader = PyPDFLoader(“你的文档.pdf”) # 替换成你的PDF文件
docs = loader.load()
====================== 2. 文本分割(流程图 2.Text Splitter) ======================
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 文本块大小
chunk_overlap=100 # 块之间重叠,防止信息丢失
)
splits = text_splitter.split_documents(docs)
====================== 3. 嵌入模型(流程图 3.Embedding Model) ======================
embeddings = OllamaEmbeddings(model=“qwen:7b”)
====================== 4. 向量库存储(流程图 4.Vector Store) ======================
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=“./chroma_db” # 向量库本地持久化
)
====================== 5. 检索器(流程图 5.Retriever) ======================
retriever = vectorstore.as_retriever(search_kwargs={“k”: 3}) # 召回3个最相关片段
====================== 6. 提示词(流程图 6.Prompt) ======================
prompt_template = “”"
你是专业技术助手,严格基于以下参考资料回答问题,禁止编造内容。
参考资料:{context}
用户问题:{question}
“”"
PROMPT = PromptTemplate(
template=prompt_template,
input_variables=[“context”, “question”]
)
====================== 7. 绑定本地模型(流程图 8.LLM Client) ======================
llm = ChatOllama(model=“qwen:7b”, temperature=0.1)
====================== 8. 构建RAG链,执行问答 ======================
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={“prompt”: PROMPT}
)
提问测试
result = qa_chain.invoke({“query”: “文档中关于机器人运动学的核心内容是什么?”})
print(result[“result”])
四、对应流程图,每一步在代码里的映射
-
Document Loader → PyPDFLoader 读取PDF
-
Text Splitter → RecursiveCharacterTextSplitter 切块
-
Embedding Model → OllamaEmbeddings 向量化
-
Vector Store → Chroma 向量数据库
-
Retriever → vectorstore.as_retriever 检索
-
Prompt → PromptTemplate 提示词模板
-
LLM Client → ChatOllama 调用本地模型
-
Output Parser → LangChain默认输出解析,直接返回文本
五、进阶:用 LCEL 链式写法
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
构建RAG链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| PROMPT
| llm
| StrOutputParser()
)
提问
res = rag_chain.invoke(“你的问题”)
print(res)
六、关键使用逻辑总结
-
LangChain不自带大模型,必须对接 Ollama/OpenAI/豆包等模型
-
RAG是LangChain最核心用法,完整实现私有知识库问答
-
结合Ollama = 100%本地私有化部署,数据不泄露
-
开发顺序:提示词 → 基础对话 → RAG知识库 → Agent智能体
七、机器人项目的直接用法
-
把论文、专利、D‑H参数、ROS2手册、Python代码做成PDF
-
用上面代码搭建本地RAG
-
实现本地私有机器人技术问答助手
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献740条内容
已为社区贡献740条内容

所有评论(0)