【ReACT 设计模式】(思考 - 行动 - 观察)
摘要(148字): ReAct是一种结合推理(Reasoning)与行动(Acting)的智能体模式,通过思考→行动→观察的循环处理复杂任务。典型流程:1)思考问题并规划行动;2)调用工具执行;3)获取结果并评估。若信息不足则循环,直至输出最终答案(如查询股价需先搜索再返回结果)。其优势在于提升准确性(整合外部数据)和可解释性(透明推理过程),适用于代码生成、数据分析等需多步交互的场景。例如代码重
ReAct 是一种将 推理(Reasoning)与 行动(Acting)相结合的智能体(Agent)设计模式,常见于大语言模型(LLM)应用开发(如 LangChain、AutoGPT)。
小知识: ReAct 模式下一次只能生成一个 Action 行动,无法基于 Thought 思考生成多个 Action 行动 同时执行。
— — 循环机制限制: 流程是:解析 → 执行 → 拿到结果 → 下一轮。如果一次生成两个 Action 行动,解析和执行都会乱套。
它的核心思想是让模型在解决复杂任务时交替进行:
- 思考(Thought):分析用户问题与当前信息(循环记录),规划下一步。
- 行动(Action):
调用外部工具(如搜索、计算器、API)LLM 生成一个动作指令,指明需要调用的工具名和参数;由系统代码真正执行调用。 - 观察(Observation):接收工具返回的结果。
推理 (Reason) → 行动 (Act) → 观察 (Observe) → 重复推理
| 步骤 | 名称 | 核心职责 | 功能描述 | |
|---|---|---|---|---|
| 1 | Thought 思考 | 规划 | 分析用户问题与当前信息(循环记录),决定下一步要调用哪个工具,以及传入什么参数。 | |
| 2 | Action 行动 | 执行 | 调用工具(LLM 生成一个动作指令,指明需要调用的工具名和参数;由系统代码真正执行调用。(如搜索、计算)) | |
| 3 | Observation 观察 | 接收 | 获取工具返回结果,作为下一轮思考的事实依据 | |
| 4 | Thought 思考(评估) | 判断决策 | (循环的关键) 评估 Observation 提供的信息是否足以回答用户问题。 • 如果不够:决定新的 Action行动,返回步骤2继续循环。• 如果足够:整理最终答案,准备结束。 | |
| 5 | Answer 回答 | 输出 | 向用户输出最终答案 |
典型流程示例(用户问:“今天XX公司股价是多少?”):
- Thought 思考:我需要查找今天的股价。 # 思考用户问题,制定行动方案
- Action 行动:Search[XX公司 股价 2026-04-21] # 调用工具
- Observation 观察:收盘价 125.30 元 # 获取工具返回的原始结果,作为下一步推理的依据
- Thought 思考(评估):已获得答案。 # 评估当前积累的观察结果是否足以回答用户问题。若信息不足,指定下一步行动任务 返回第2步循环执行。
- Answer 回答:XX公司今日收盘价为 125.30 元。 # 向用户输出最终答案
ReAct 的核心循环是:
行动 → 观察 → 思考(评估)。若信息不足则继续行动,直至积累的信息足以回答用户问题,最后输出答案。
优势:
- 提高事实准确性(结合外部数据)
- 增强可解释性(推理过程可见)
- 处理需要多步交互的复杂任务
典型应用:代码生成、生成文档、数据分析、自动化操作等。
Trae 内置的 ReACT 模式回答用户问题
用户问题:重构这个函数并添加错误处理
Trae 内部执行流程:
- Thought(思考):需要先读取当前代码 → Action(行动):读取文件
- Observation(观察):获得代码内容
- Thought(思考/评估):需要理解函数逻辑 → Action(行动):分析依赖
- Observation(观察):发现有3个依赖函数
- Thought(思考/评估):信息充足,可以开始重构 → Action(行动):生成新代码
- Answer(回答):输出重构后的代码
ReAct Agent 核心技术 - 三点总结
1. 停止关键词 Stop Sequence
技术手段,设置停止提示词 拦截模型自动续写,杜绝幻觉编造工具返回结果,保证工具调用交由程序真实执行。
2. 示例提示词(Few-shot)
通过提供示例,规范模型的输出格式、思考逻辑与工具调用写法,确保模型遵循固定的输出范式,避免生成随意或错误的内容。
3. 推理+行动 循环设计模式
Thought思考判断 → Action工具调用 → Observation观测反馈,往复闭环完成任务决策。
通俗串联逻辑
靠提示词教会模型怎么思考、怎么输出调用指令;
靠停止词卡死边界,不让模型瞎编答案;
整体用推理行动循环模式反复迭代,一步步解决复杂问题。
手写 ReAct 伪代码
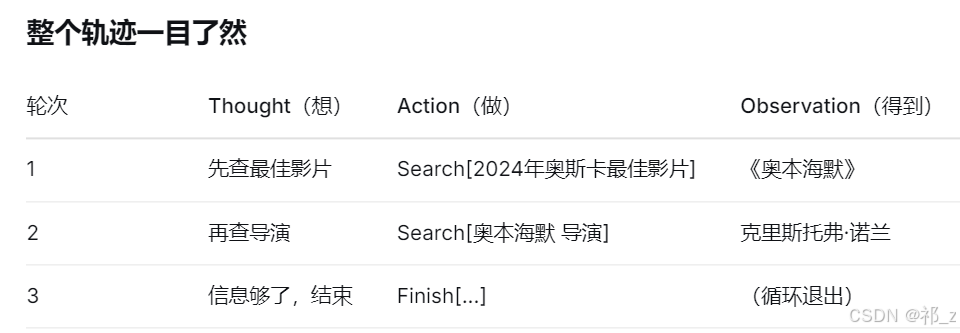
用户问题:“2024年奥斯卡最佳影片是什么?作者是谁?”
# 手写 ReAct Agent 核心循环 (纯 Python 示意)
def run_react_agent(question, tools, llm, max_steps=5):
# 1. 构建初始 prompt (包含工具描述、示例、用户问题)
prompt = build_prompt(tools, question)
# 循环最新5次,避免死循环
for i in range(max_steps):
# 2. 调用 LLM 生成 Thought思考 和 Action行动(需要调用的工具及参数)
# - Thought 思考: 用户想知道2024年奥斯卡最佳影片,我需要先搜索最佳影片是什么。
# - Action 行动: Search[2024年奥斯卡最佳影片]
response = llm(prompt)
# 3. 手动解析 LLM 输出的字符串
# action = "Search"(需要调用的工具方法)
# action_input = "2024年奥斯卡最佳影片"(参数)
action, action_input = parse_action(response)
# 4. 判断是否结束
if action == "Finish":
return action_input
# 5. 手动分发并执行工具
if action == "Search":
observation = search_tool(action_input)
elif action == "Calculate":
observation = calc_tool(action_input)
else:
observation = "未知工具"
# 6. 拼接 Observation,进入下一轮循环
prompt += f"\nObservation: {observation}\n"
return "达到最大步数,任务失败"
执行轨迹说明:
----- 初始化 ------
prompt = build_prompt(tools, question)
# prompt 现在是:工具说明 + 示例 + 用户问题
----- 第 1 轮循环 (i=0) ------
# 步骤2:调用 LLM
response = llm(prompt)
# response 输出:
# Thought 思考: 用户想知道2024年奥斯卡最佳影片,我需要先搜索最佳影片是什么。
# Action 行动: Search[2024年奥斯卡最佳影片]
# 步骤3:解析
action, action_input = parse_action(response)
# action 行动 = "Search"
# action_input 参数 = "2024年奥斯卡最佳影片"
# 步骤4:判断结束?不是Finish,继续
# 步骤5:分发执行
if action == "Search":
observation = search_tool("2024年奥斯卡最佳影片")
# observation 观察 = "《奥本海默》"
# 步骤6:拼接
prompt += f"\nObservation: {observation}\n"
# prompt 现在追加了:Observation: 《奥本海默》
-------- 第 2 轮循环 (i=1) --------
# 步骤2:LLM 看到完整的 prompt(包含上一轮的 Observation)
response = llm(prompt)
# response 输出:
# Thought 思考: 最佳影片是《奥本海默》,现在需要查它的导演是谁。
# Action 行动: Search[奥本海默 导演]
# 步骤3:解析
action, action_input = parse_action(response)
# action 行动 = "Search"
# action_input 参数 = "奥本海默 导演"
# 步骤5:执行
observation = search_tool("奥本海默 导演")
# observation 观察 = "克里斯托弗·诺兰"
# 步骤6:拼接
prompt += f"\nObservation: {observation}\n"
# prompt 追加:Observation: 克里斯托弗·诺兰
--------- 第 3 轮循环 (i=2) ---------
# 步骤2:LLM 判断信息足够
response = llm(prompt)
# response 输出:
# Thought 思考: 最佳影片是《奥本海默》,导演是诺兰,信息足够了。
# Action 行动: Finish[2024年奥斯卡最佳影片是《奥本海默》,导演是克里斯托弗·诺兰。]
# 步骤3:解析
action, action_input = parse_action(response)
# action 行动 = "Finish"
# action_input 参数 = "2024年奥斯卡最佳影片是《奥本海默》,导演是克里斯托弗·诺兰。"
# 步骤4:命中 Finish
if action == "Finish":
return action_input # 循环结束,返回最终答案给用户
Q&A
- 什么是ReAct:把推理和行动交错在一起。让模型能一边思考一边调用外部工具,并根据工具返回的事实修正自己的推理。
- 仅推理:只靠模型内部知识一步步推理,容易产生幻觉,也无法获取最新信息。
- 仅行动:模型只机械输出动作,缺乏高层次的规划、反思和推理,容易在复杂任务中跑偏。
- ReAct:推理帮助模型制定合理的行动计划、处理观察结果、动态调整;行动则把推理“接地气”,从外部世界拉回事实。两者互补。
-
ReAct 的 prompt 长什么样?这个我没太明白
-
如何在工程上实现一个简单的 ReAct Agent?
- 利用框架-langchain的create_agent、LlamaIndex等。
- 核心是一个 while 循环:解析模型输出 → 如果是动作则调用工具(if判断或动态反射执行方法) → 拼接观察 → 再次推理,直到触发结束条件。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)