AI Agent 长期记忆架构实战:Mem0 + LangGraph + Neo4j,让 Agent 真正记住你
RAG解决检索,但Agent需要记忆。本文从记忆分层架构、Mem0集成、Neo4j图记忆、LangGraph持久化四个维度,提供Agent长期记忆的完整实战方案。包含Mem0+LangGraph可运行代码和图记忆查询示例。
上下文窗口 200K 了,为什么 Agent 还是"记不住"?
2026 年,Claude Opus 4.7 的上下文窗口到了 1M token,GPT-5.5 也到了 256K。看起来 Agent 可以一口气读完几十本书。
但上下文窗口大 ≠ 有记忆。每次新会话,Agent 还是失忆的。它不记得上次聊了什么、你的偏好是什么、上次的决策结果如何。
Agent 记忆的真正挑战不是"能塞多少 token",而是跨会话持久化、结构化检索、图关系推理。

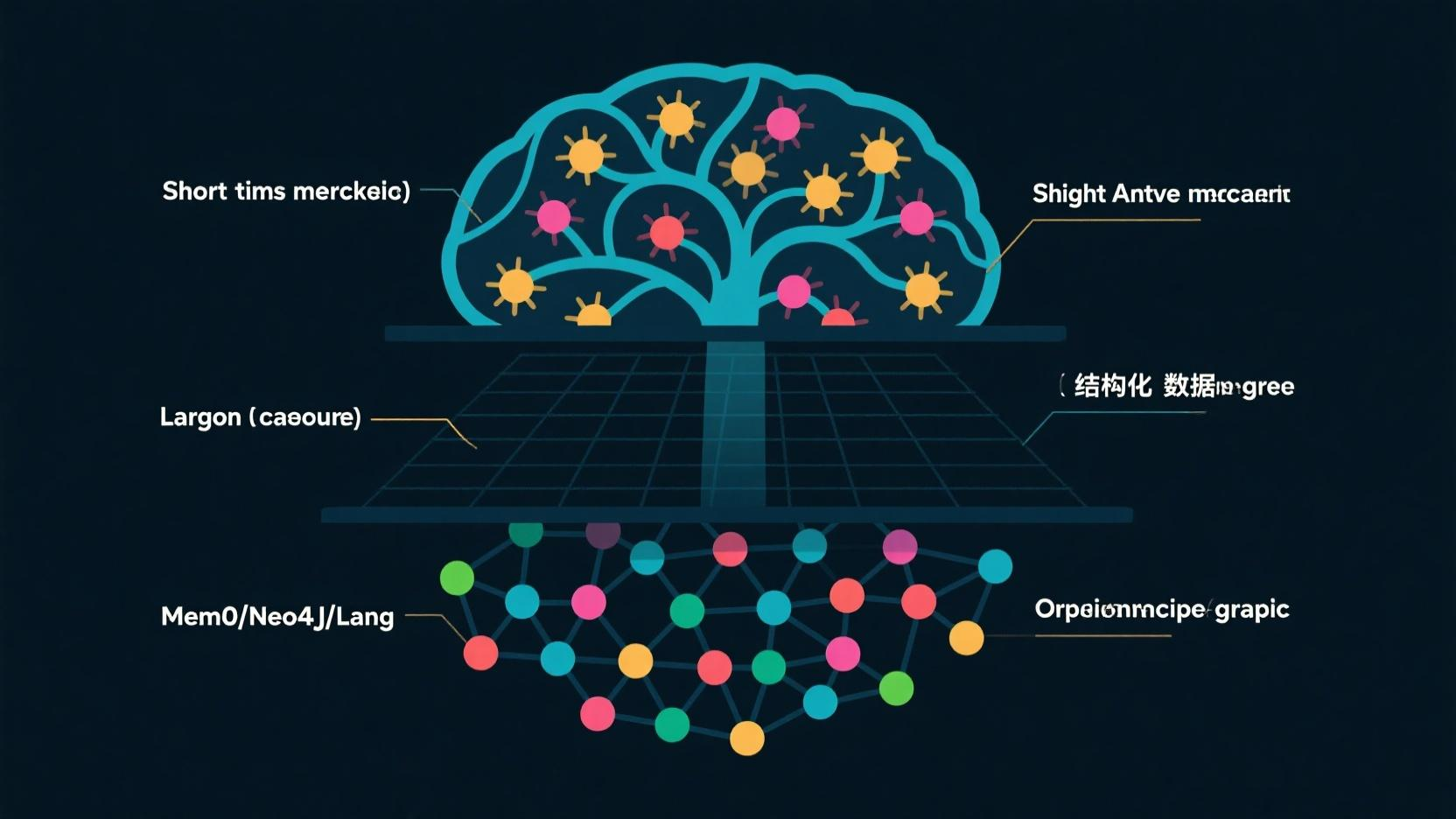
记忆三层架构:不是所有记忆都要进向量库
我曾在 Agent 企业落地那篇文章里简单提过这个分层,这里展开实战。
| 层级 | 存储 | 生命周期 | 典型数据 | 技术方案 |
|---|---|---|---|---|
| 工作记忆 | 上下文窗口 | 单次会话 | 当前对话、中间推理步骤 | LLM Context |
| 短期记忆 | 会话存储 | 数小时-数天 | 当前任务上下文、临时偏好 | Redis / LangGraph Checkpoint |
| 长期记忆 | 持久化存储 | 永久 | 用户画像、历史决策、知识积累 | Mem0 / Neo4j / SQL |
关键原则:不同记忆类型用不同存储,不要全灌进向量库。
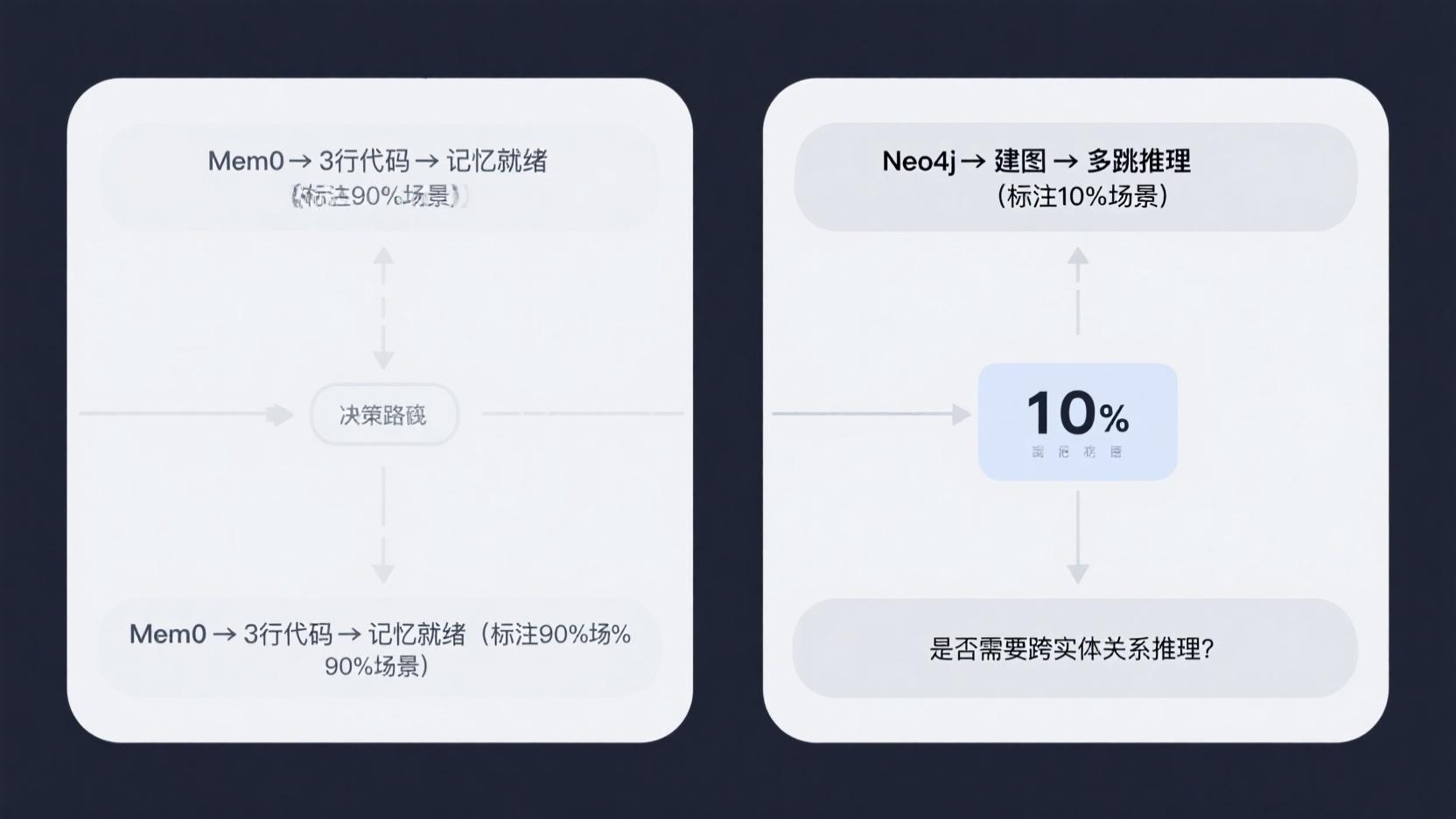
方案一:Mem0 —— 开箱即用的 Agent 记忆层
Mem0 是 2026 年最火的 Agent 记忆中间件。它自动做三件事:记忆提取、存储、检索。你只需要几行代码:
from mem0 import Memory
from openai import OpenAI
client = OpenAI()
memory = Memory()
# ── 1. 记忆自动提取与存储 ──
# Mem0 从对话中自动识别值得记住的信息
conversation = [
{"role": "user", "content": "我叫张三,是后端工程师,团队用Go和PostgreSQL"},
{"role": "assistant", "content": "好的张三,我记住了你的技术栈。"},
{"role": "user", "content": "我们项目是微服务架构,有12个服务,用的是gRPC通信"},
]
# Mem0 自动提取结构化记忆
for msg in conversation:
memory.add(msg["content"], user_id="zhangsan")
# ── 2. 记忆检索 ──
# Agent 收到新请求时,先检索相关记忆
relevant_memories = memory.search(
"用什么技术栈做API网关?",
user_id="zhangsan",
limit=5
)
for mem in relevant_memories:
print(f"[{mem['memory']}] (score: {mem['score']:.2f})")
# 输出:
# [张三使用Go和PostgreSQL] (score: 0.89)
# [项目是微服务架构,12个服务,gRPC通信] (score: 0.82)
# ── 3. 注入记忆到 Agent Prompt ──
memory_context = "\n".join(
f"- {m['memory']}" for m in relevant_memories
)
response = client.chat.completions.create(
model="gpt-5.1",
messages=[
{"role": "system", "content": f"用户背景信息:\n{memory_context}"},
{"role": "user", "content": "推荐一个适合我们项目的API网关方案"}
]
)
# Agent 自动推荐与 Go 生态兼容、适合 gRPC 微服务架构的网关
方案二:图记忆 —— Neo4j 存储实体关系
向量检索能找"相似",但找不到"张三负责哪些项目 → 这些项目用了什么技术栈 → 有哪些类似项目 → 谁在维护"。这种跨实体多跳推理需要图记忆。
from langgraph.store.memory import InMemoryStore
from langgraph.store.base import Item
import neo4j
# ── 构建图记忆 ──
driver = neo4j.GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
def store_entity_relationship(entity1, relation, entity2, properties=None):
"""在 Neo4j 中存储实体关系"""
with driver.session() as session:
session.run(
"""
MERGE (a:Entity {name: $e1})
MERGE (b:Entity {name: $e2})
MERGE (a)-[r:%s]->(b)
SET r = $props
""" % relation.replace(" ", "_"),
e1=entity1, e2=entity2,
props=properties or {}
)
# Agent 从对话中提取实体 → 自动建图
store_entity_relationship("张三", "负责", "用户服务")
store_entity_relationship("张三", "擅长", "Go", {"level": "expert"})
store_entity_relationship("用户服务", "使用", "PostgreSQL")
store_entity_relationship("用户服务", "调用", "订单服务", {"protocol": "gRPC"})
store_entity_relationship("李四", "负责", "订单服务")
store_entity_relationship("李四", "擅长", "Rust")
# ── 图查询:多跳推理 ──
def find_relevant_context(query_entity: str, hops: int = 2):
"""围绕实体展开N跳图搜索"""
with driver.session() as session:
result = session.run(
"""
MATCH (a:Entity {name: $name})-[*1..%d]-(related:Entity)
RETURN DISTINCT related.name as entity, labels(related) as type
LIMIT 20
""" % hops,
name=query_entity
)
return [{"entity": r["entity"], "type": r["type"]} for r in result]
# 问"用户服务挂了影响谁?" → 图搜索发现 → 张三负责 → 订单服务受影响 → 李四负责
context = find_relevant_context("用户服务", hops=2)
# [{"entity": "张三", "type": ["Entity"]}, {"entity": "订单服务", "type": ["Entity"]},
# {"entity": "李四", "type": ["Entity"]}, {"entity": "Go", "type": ["Entity"]}]
方案三:LangGraph + Mem0 集成——生产级记忆 Agent
单个技术用起来简单,但生产环境需要把记忆集成到 Agent 工作流中:
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from mem0 import Memory
from typing import TypedDict
memory_client = Memory()
class AgentState(TypedDict):
user_id: str
query: str
memories: list
response: str
def retrieve_memory(state: AgentState) -> AgentState:
"""节点1: 检索相关记忆"""
memories = memory_client.search(
state["query"],
user_id=state["user_id"],
limit=5
)
state["memories"] = [m["memory"] for m in memories]
return state
def generate_response(state: AgentState) -> AgentState:
"""节点2: 基于记忆生成回复"""
memory_context = "\n".join(f"- {m}" for m in state["memories"])
response = client.chat.completions.create(
model="gpt-5.1",
messages=[
{"role": "system", "content": f"你是技术顾问。已知用户背景:\n{memory_context}"},
{"role": "user", "content": state["query"]}
]
)
state["response"] = response.choices[0].message.content
return state
def store_memory(state: AgentState) -> AgentState:
"""节点3: 从本轮对话提取新记忆"""
memory_client.add(
f"Q: {state['query']}\nA: {state['response']}",
user_id=state["user_id"]
)
return state
# ── 构建带记忆的 Agent ──
workflow = StateGraph(AgentState)
workflow.add_node("retrieve", retrieve_memory)
workflow.add_node("generate", generate_response)
workflow.add_node("store", store_memory)
workflow.add_edge("retrieve", "generate")
workflow.add_edge("generate", "store")
workflow.add_edge("store", END)
workflow.set_entry_point("retrieve")
# LangGraph Checkpoint = 会话级短期记忆 + 跨会话持久化
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer)
# 使用
result = app.invoke(
{"user_id": "zhangsan", "query": "帮我优化用户服务的数据库查询"},
config={"configurable": {"thread_id": "session_001"}} # 同一thread_id共享上下文
)
图记忆 vs 向量记忆:选型边界
| 场景 | 向量记忆 (Mem0) | 图记忆 (Neo4j) |
|---|---|---|
| "用户喜欢什么" | ✅ 语义检索 | ❌ 过度设计 |
| "张三和李四有什么共同点" | ❌ 无法推理 | ✅ 图遍历 |
| "这个决策的历史上下文" | ✅ 时间线检索 | ⚠️ 需加时间戳属性 |
| "谁负责的模块受这个变更影响" | ❌ | ✅ 多跳推理 |
| 实现复杂度 | ⭐ 低 | ⭐⭐⭐ 高 |
实战建议:先用 Mem0 快速上线(90% 场景够用),当出现"需要跨实体推理"的需求时再引入 Neo4j。
小结
2026 年,Agent 的记忆问题已经从"能不能记住"变成了"记住什么、怎么检索、不同记忆用什么存储"。
三层记忆架构的核心:上下文窗口做工作记忆 → Mem0 做长期语义记忆 → Neo4j 做图关系记忆。三者各司其职,别让一个工具打三份工。
下一篇预告:Agent 记忆系统进阶——记忆冲突消解、遗忘策略、隐私合规。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)