从 Prompt 到 Skills:把论文复现、数据清洗和代码规范写进 AI
**摘要:**本文探讨如何将科研项目中的复现规范、数据清洗规则和代码标准转化为AI可执行的Skills,以提升研究效率。针对经管社科研究者常遇到的AI重复犯错问题(如路径错误、输出混乱),作者提出使用ClaudeCode的SKILL.md机制,将项目目录结构、数据处理流程、写作规范等固化为可复用规则。相比临时Prompt,Skills能实现长期记忆,使AI从"临时工"转变为理解
作者: 连小白 (连享会)
邮箱: lianxhcn@163.com
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
- Title: 从 Prompt 到 Skills:把论文复现、数据清洗和代码规范写进 AI
- Keywords: Claude Code, Skills, SKILL.md, AI Agent, 科研工作流, 论文复现, Stata, Python, Quarto
- 提要:从 Prompt 到 Skills,关键不是让 AI 回答得更长,而是把论文复现、数据清洗、代码规范和写作要求沉淀为可复用规则。本文面向经管和社会科学研究者,介绍如何用 Claude Code Skills 固化项目目录、路径、输出和复现要求,让 AI 从临时助手逐渐变成更熟悉项目规则的研究协作者。
编者按:很多研究者已经开始用 AI 写代码、清洗数据、修改论文、检查复现包。但一个常见问题是:AI 每次都像第一次接触你的项目,路径规则、数据规则、输出规则和写作规范都要反复解释。本文讨论如何借助 Claude Code Skills,把这些重复出现的项目规范沉淀为 AI 可以长期调用的工作流规则。
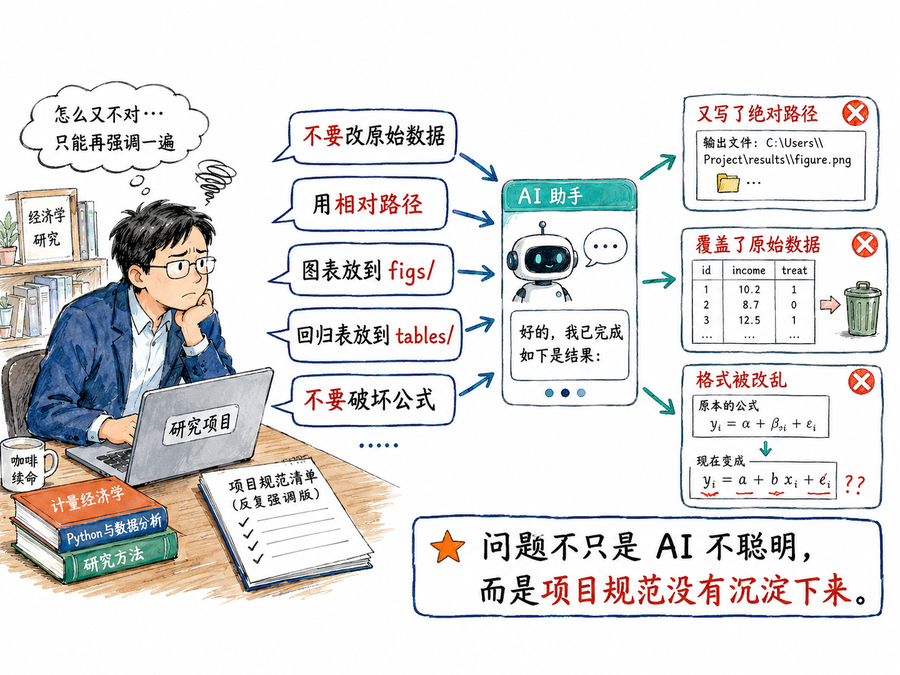
1. AI 不是不听话,而是不知道项目规则
很多研究者使用 AI 的体验,并不是「AI 完全不会」,而是「它每次都像第一次接触我的项目」。
你明明提醒过它不要修改原始数据,它下一次还是可能动了 data_raw/;你强调过要使用相对路径,它又写出一个只在你电脑上能运行的本地路径;你要求回归表放进 tables/、图片放进 figs/,它这次记住了,下次又忘了;你让它修改 Quarto 文稿,它可能顺手把公式、脚注和交叉引用改乱。
这些问题表面上是 AI 不稳定,深层看却是研究项目没有形成 AI 可以读取的工作规则。
过去,我们把项目规范写给人看:写在 README 里,写在课题组文档里,写在老师给学生的注意事项里。这样做当然有用,但它默认读者是人。人可以理解上下文,可以根据经验判断哪些文件不能动,哪些输出只是中间结果,哪些表格才是论文最终结果。
可是,当 AI 开始参与数据清洗、代码生成、论文修改和复现检查时,只让人看懂规范已经不够了。我们还需要让 AI 也能看懂,并在相关任务中自动遵守。
这就带来一个新的问题:研究项目的规范,能不能从「写给人看的说明」变成「AI 可以执行的工作流」?
Claude Code Skills 正是为这个问题提供了一种思路。它不是让我们写更长的 Prompt,而是把那些反复解释给 AI 的要求,写成可以被自动调用的 SKILL.md。换句话说,它不是在解决「这一次该怎么问 AI」,而是在解决「以后遇到类似任务,AI 应该默认按什么规则做」。
对经管类和社会科学研究者来说,这个转变很重要。我们的很多工作并不是一次性的:一篇论文要反复清洗数据、调整变量、跑回归、导出表格、画图、写附录、准备复现包;一门课程要反复生成讲义、代码、案例和作业;一个课题组要长期维护目录结构、变量命名、数据版本和输出规范。
如果这些规则只能靠每次 Prompt 临时提醒,AI 就始终像一个临时工。如果这些规则被写成 Skills,它才有机会逐渐成为一个理解项目工作流的协作者。
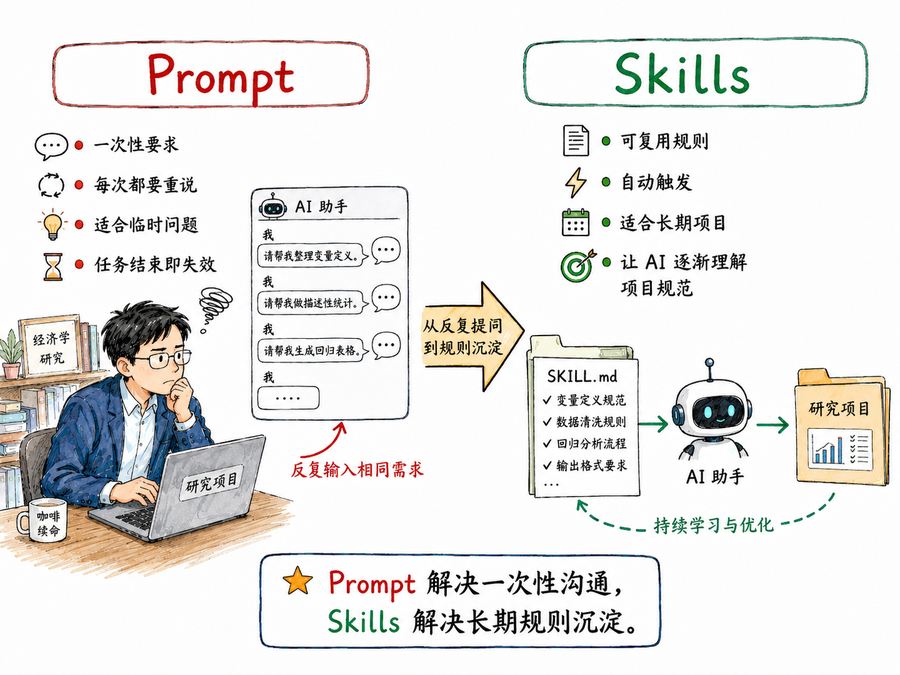
2. Prompt 适合临时沟通,Skills 适合长期记忆
我们最熟悉的是 Prompt。
Prompt 适合解决临时问题。例如:
请帮我写一段 Stata 代码,读取
auto.dta,做一个回归,并导出结果表。
这个要求很具体,AI 通常可以完成。
但问题在于,很多研究规则并不是一次性要求,而是长期约束。比如:
-
不要修改原始数据;
-
不要写本地绝对路径;
-
数据清洗、变量构造、回归分析要分开;
-
回归表输出到
tables/; -
图形输出到
figs/; -
每次修改代码后说明改了哪些文件;
-
Quarto 公式不要被错误拆行;
-
Stata 代码要写清楚注释,便于教学和复现。
这些内容如果每次都写进 Prompt,就会非常低效。更重要的是,它们本来就不是临时偏好,而是项目规范。
可以用一句话概括:
Prompt 解决的是「这一次怎么做」;Skills 解决的是「以后遇到这类任务都应该怎么做」。
Anthropic 对 Agent Skills 的说明中,将 Skills 描述为由文件和文件夹组成的模块化机制,用来为 agent 提供程序性知识和组织上下文;Claude Code 文档也把 Skills 放在扩展 Claude 能力的工具体系中,用于创建、管理和共享可复用能力。(Anthropic)
换成研究者更熟悉的话说,Skill 就像写给 AI 的「项目工作手册」。它通常放在 .claude/skills/ 目录下,每个 Skill 对应一类任务。Claude 可以根据任务内容判断是否需要调用相关 Skill,也可以在用户明确点名时调用。
普通文档和 Skills 的差别,可以这样理解:
| 维度 | 普通说明文档 | Claude Code Skills |
|---|---|---|
| 主要读者 | 人 | AI Agent |
| 使用方式 | 人主动打开查看 | Claude 根据任务判断是否调用 |
| 生效时机 | 出错后再查 | 生成前先约束 |
| 典型内容 | 项目说明、操作指南 | 任务规则、触发场景、正反示例 |
| 适用场景 | 说明项目 | 约束 AI 执行项目任务 |
这里的关键不是技术文件本身,而是协作方式的改变。
过去,我们把每一次任务都当作新的对话:这次请你写回归代码,这次请你清洗数据,这次请你检查复现包。于是,路径规则、输出规则、数据保护规则、文件命名规则都要反复解释。
Skills 把这种临时沟通改成了长期规则。只要任务触发了对应 Skill,Claude 就会先读取相关规范,再开始行动。
这不保证 AI 永远不犯错,但可以显著减少那些反复出现、低级而耗时的错误。
需要先说明一点:本文主要以 Claude Code Skills 为例,讨论如何把论文复现、数据清洗和代码规范写成 AI 可以调用的项目规则。严格来说,SKILL.md、.claude/skills/ 目录和自动触发机制,是 Claude Code / Anthropic 生态中的原生设计。Claude Code 官方文档也明确提到,当你反复粘贴同一套说明、检查清单或多步骤流程时,就可以考虑把它写成 Skill。
但本文真正想强调的,不只是 Claude Code 的某个功能,而是一个更通用的工作方式:把反复解释给 AI 的项目规则,沉淀为可复用、可加载、可更新的上下文。至于 ChatGPT、Kimi、DeepSeek、豆包等工具如何实现类似效果,我们会在另一篇推文「没有 Claude Code,如何实现 Skills?ChatGPT、Kimi、DeepSeek、豆包的替代方案」中专门讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)