ICLR 2026|Next-ToBE:让“自信而短视“的大模型看得更远、推理更准
华东师范大学与复旦大学团队在ICLR 2026论文《Next-ToBE》中提出了一种创新的大语言模型训练方法。研究发现,当前模型预测分布中已隐含未来token信息,但标准next-token训练目标未能充分利用这一前瞻能力。Next-ToBE通过将单点one-hot标签扩展为覆盖未来窗口的软目标分布,在不改变模型结构的情况下激活了模型的潜在前瞻能力。实验表明,该方法在数学推理、代码生成等任务上显著

论文标题:Next-ToBE: Probabilistic Next Token-Bag Exploitation for Activating Anticipatory Capacity in LLMs
论文链接:https://openreview.net/pdf?id=T8IJojfaOh
如果让一个人一边说话一边思考,他通常不会真的只盯着"下一个字"。
在真正开口之前,人往往已经在脑中预铺了后面几步:下一句如何衔接,整体逻辑是否闭合,最后的结论会不会偏离原意。
但现有大语言模型的主流训练目标,仍然是标准的 next-token prediction(NTP):在每一步只学习"下一个 token 是什么"。这一目标足以支撑高质量的通用文本生成,却在数学推理、代码生成、多步决策等依赖长程规划的场景中暴露出明显局限——局部流畅,整体却容易偏离航向。
一个值得追问的问题是:
如果训练目标始终只优化"下一个 token",是否也在无形中限制了模型对更远未来的建模能力?
围绕这一问题,华东师范大学与复旦大学的研究团队在 ICLR 2026 论文《Next-ToBE: Probabilistic Next Token-Bag Exploitation for Activating Anticipatory Capacity in LLMs》中给出了系统性的回答。
作者发现,LLM 在当前时刻的预测分布中,其实已经包含了一部分对未来若干 token 的信息。问题不在于模型缺乏前瞻能力,而在于标准训练目标没有充分利用它。
基于这一观察,论文提出 Next-ToBE:不增加预测头、不修改模型结构,仅通过调整训练时的目标分布,把单一的 one-hot 标签替换为覆盖未来窗口的软目标分布,从而更充分地激活模型已有的前瞻能力。
当前预测里,其实已经藏着未来
为衡量模型是否会在当前时刻"提前看到"后续内容,论文提出了 Future-tokens Hit Rate(FtHR) 指标,用于刻画当前预测分布对未来 token 的覆盖情况。
实验发现,即便模型只接受标准的next-token训练,当前时刻的输出分布中也已经覆盖了相当一部分未来token;与此同时,一个未来token在当前分布中的排名越靠前,它在后续生成中被正确输出的概率也越高。
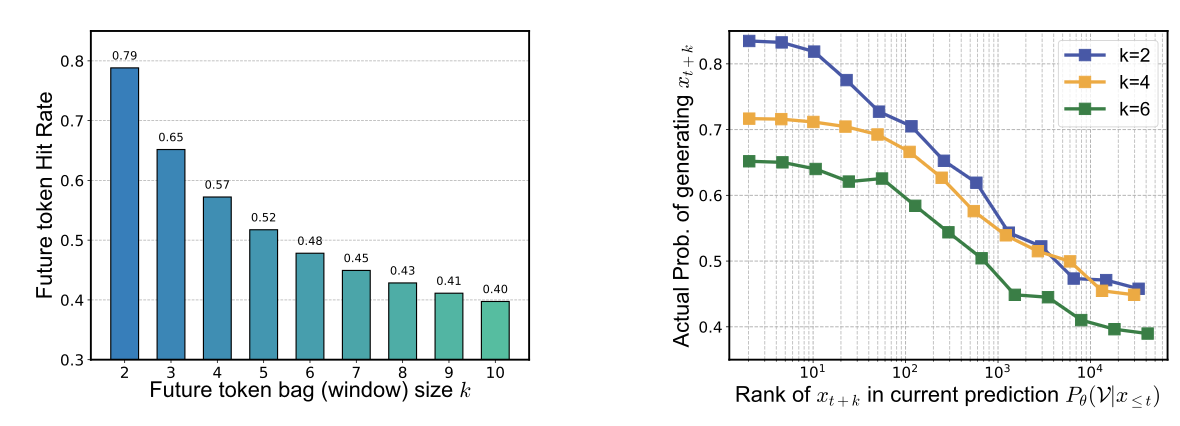
图 1:左)当前一步的输出分布也已经覆盖了相当比例的未来 token;右)未来 token 在当前预测中的排名越高,后续被正确生成的概率越大。
这说明,所谓前瞻能力并不是一个抽象概念,而是与模型后续生成质量存在可测的关联。Next-ToBE 正是从这里切入,既然模型已经具备一定的"向前看"能力,训练目标就不应只围绕当前一步展开。
Next-ToBE 是怎么把前瞻能力变成训练收益的
Next-ToBE 与 MTP(Multi-token Prediction)这类通过增加预测头来预测多个未来 token 的方法有本质区别。它不改变模型结构,而是直接改造训练目标。
具体来说,传统 NTP 在每一步只用"下一个 token"的 one-hot 标签做监督;而 Next-ToBE 则在保留这一主目标的同时,引入未来窗口内其余 token 构成一个软目标分布。换言之,模型不仅要学习"当前时刻最应该输出什么",还会被鼓励对后续若干步形成更合理、更稳定的概率分配。
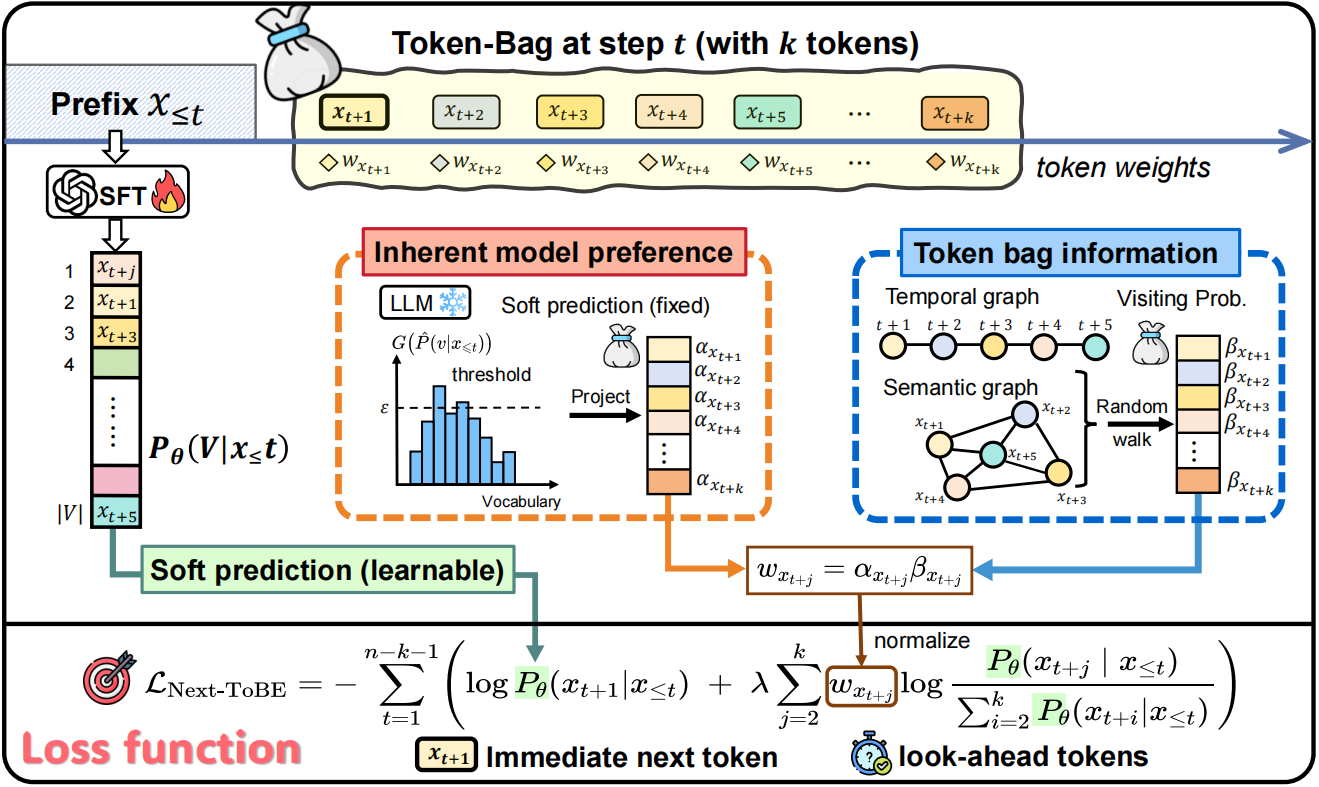
图 2:Next-ToBE 总体架构。
损失函数由"下一 token"主项与未来窗口 token 软目标项组成;后者的权重由模型自身的前瞻偏好和 token 间的时间-语义关系共同决定。
需要强调的是,下一个 token 仍然是训练的核心目标。Next-ToBE 把预测下一个 token 作为损失的主项保留下来,再在此基础上引入未来窗口内 k-1 个 token 作为辅助监督,并通过权重系数 λ 来平衡主目标与辅助目标。
这样的设计既保留了局部生成的稳定性,也增强了模型对更远程内容的感知能力。
更关键的是,这些未来 token 并不是被平均纳入目标分布,而是会被区别加权。权重主要来自两类信息:
- • 模型自身的先验偏好:如果模型本身对未来 token 赋予高的预测概率,那么它更值得被保留到监督信号中;
- • token 间的时间与语义关系:距离当前时刻更近、与上下文语义关联更强的未来 token,会获得更高权重。
这种设计的核心目的,是使辅助监督尽可能贴合模型已经具备的潜在前瞻结构,而不是机械地将未来所有 token 一视同仁地纳入训练目标。
因此,Next-ToBE 改变的不是模型结构,而是监督方式:它让模型在学习"下一个 token"的同时,也被鼓励对后续几步建立更平滑、更一致的概率预期。
打个比方,MTP 更像是"为模型增设多个预测头,以分别负责不同未来位置的输出";而 Next-ToBE 更像是"让模型在开口之前,先把后文想得更完整一些"。
前瞻能力,能否转化为推理收益?
实验主要围绕三个问题展开:
- • Next-ToBE 是否真的增强了模型对未来 token 的感知?
- • 这种前瞻能力能否转化为更准确的后续生成?
- • 这种变化最终会不会体现到复杂推理任务上?
对前两个问题,图 3 给出了直接证据。经过微调后,模型前瞻能力(FtHR)得到显著提升。
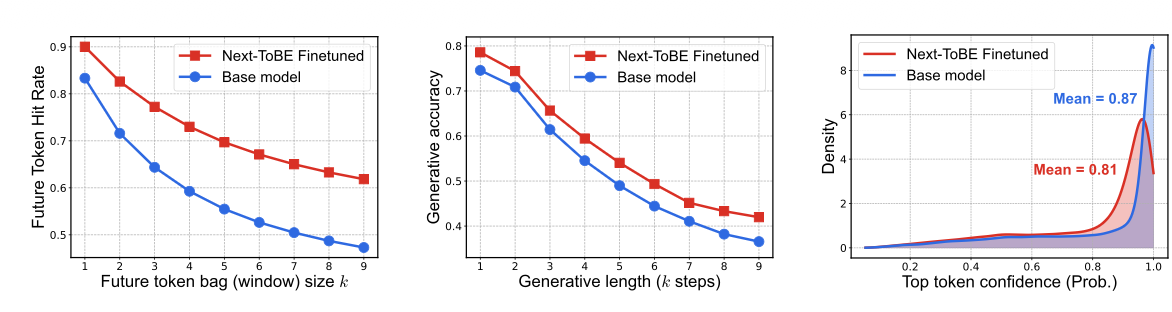
图 3:经 Next-ToBE 微调后,(a)未来 token 命中率显著提升;(b)自回归下未来 k 步生成准确率同步上升;(c)下一 token 置信度略有下降,即模型变得不那么
更重要的是,这种前瞻能力并不只停留在分析指标上,而是落实到了下游任务表现。论文在 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B 和 Llama3.1-8B-Instruct 三个基座模型上,评测了数学推理、代码生成和常识推理三类任务;在共 36 组对比中,Next-ToBE 有 35 组取得了最佳结果。
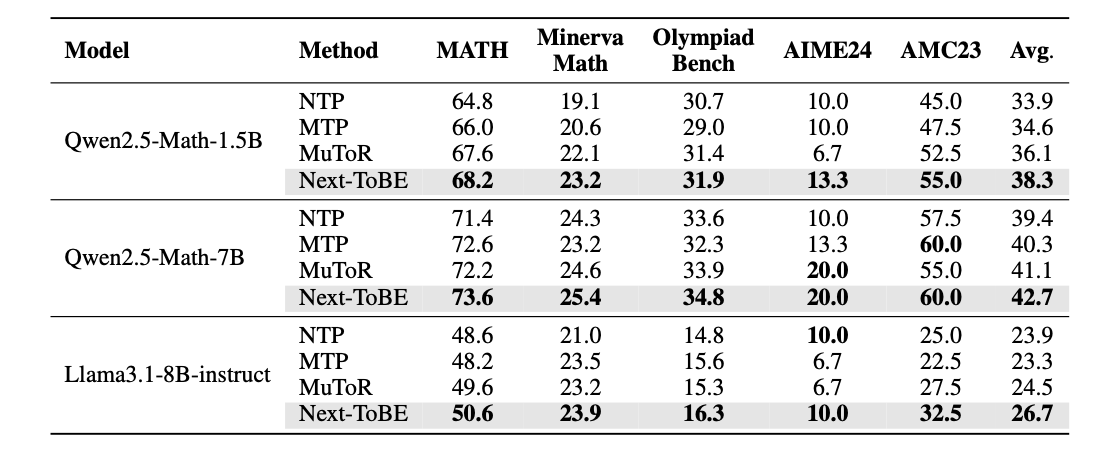
表 1:数学推理上的对比,Next-ToBE 在三个基座上均取得最高平均分。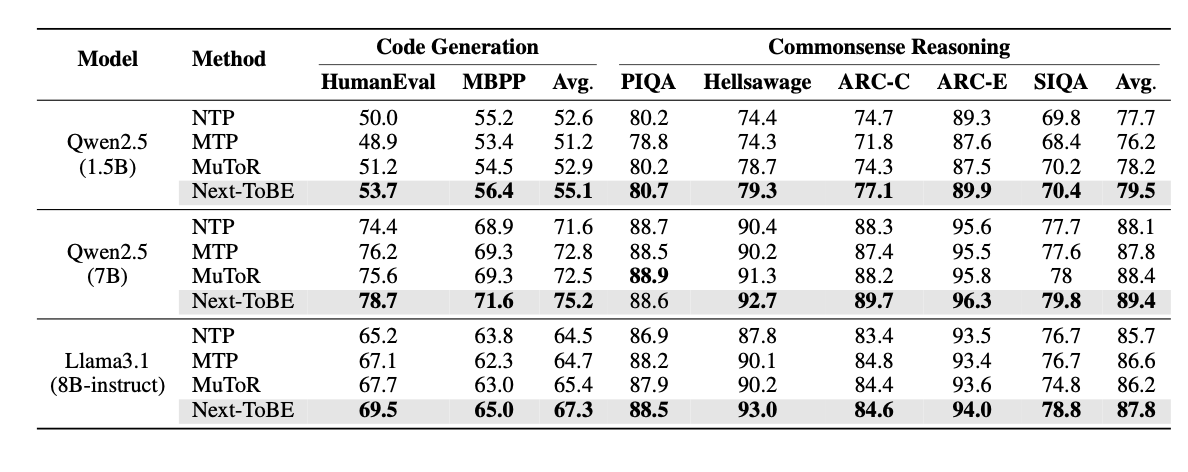
表 2:代码生成与常识推理结果。
论文还观察到一个很有意思的现象:随着 λ 增大,也就是让模型更倾向于未来 token,模型对下一 token 的置信度会持续下降;但任务准确率并不会同步下降,而是呈现出先升后降的倒 U 型趋势。
这说明,长程推理能力的提升,并不一定来自更高的局部确定性。相反,当模型不再把概率质量过度集中在当前一步,而是为后续几步保留更多可能性时,反而更有利于数学推理和代码生成这类需要整体规划的任务。
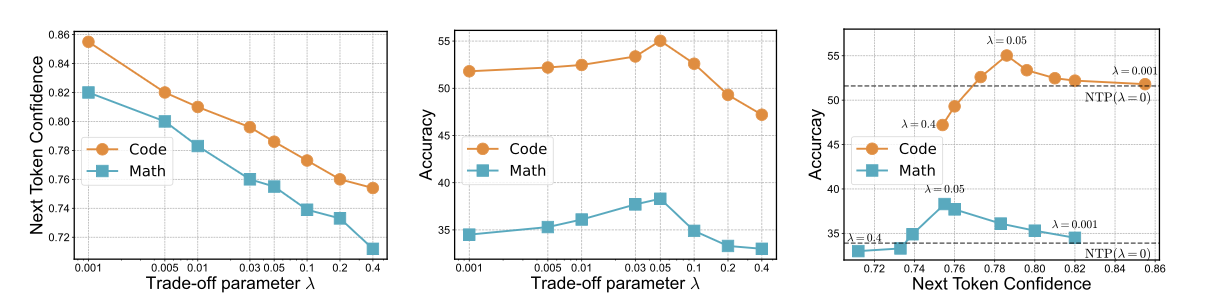
图 4:λ 越大,下一 token 置信度越低(左);但推理准确率随 λ、置信度呈先升后降(中、右)
不仅是微调:从零开始也能长出前瞻能力:作者还验证了 Next-ToBE 在预训练场景下的有效性,这说明前瞻能力并非大模型预训练后的偶然产物,而是可以被训练目标主动"塑造"出来的。

表 3:GPT-2(124M)在 WikiText-103 上从零预训练,Next-ToBE 相对 NTP / MTP 在 FtHR 与 HellaSwag 准确率上均有提升(PPL 略高,是用局部确定性换长程感知的预期结果)。
不只是有效,还更轻:除了效果,Next-ToBE 在训练开销上也有优势。与代表性的 MTP 类方法相比,它在显存占用上最多可降低 68%,训练时间最多可减少 15%,同时性能更优。
这意味着,Next-ToBE 在保留单头 NTP 简洁性的前提下,也能有效地利用了模型原本就存在的前瞻信息。
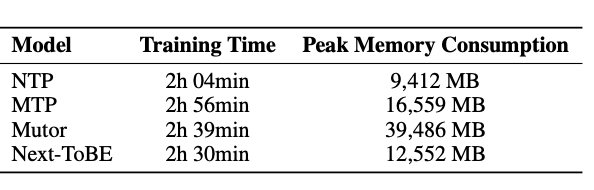
表 4:在 Qwen2.5-Math-1.5B 上的训练时间与峰值显存对比。
写在最后
我们常把大模型的推理不稳归结为"它不会想"。Next-ToBE 提供了另一种视角:模型未必没有前瞻能力,只是被一个过于短视的训练目标长期束缚住了。
这项工作没有用更复杂的结构去拉长模型视野,而是回到训练目标本身,把原本就藏在当前预测里的未来信息重新利用起来,让模型在每一步里,都为后面几步做更多的准备。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)