大语言模型后训练全解析
本文系统阐述了大语言模型(LLM)从基础模型到AI助手的后训练流程,重点解析了SFT、DPO和GRPO三阶段技术。SFT通过指令-回答样本训练模型遵循指令;DPO利用偏好对优化回答质量;GRPO通过强化学习提升推理能力。文章对比了不同训练方法的优劣,强调数据集质量的重要性,并指出RL阶段虽能显著提升性能但需较高算力支持。后训练技术经历了从SFT到DPO再到RL的演进,当前开源工具已使完整流程对开发
本文系统阐述了大语言模型(LLM)从预训练基础模型到对齐人类需求的 AI 助手的核心后训练流程,明确了后训练与传统微调的区别,拆解了 SFT、DPO、GRPO 三个核心阶段的原理、实现与实践要点,并梳理了后训练技术的发展历程与落地考量。
一、什么是后训练(Post-Training)
1.1 核心概念
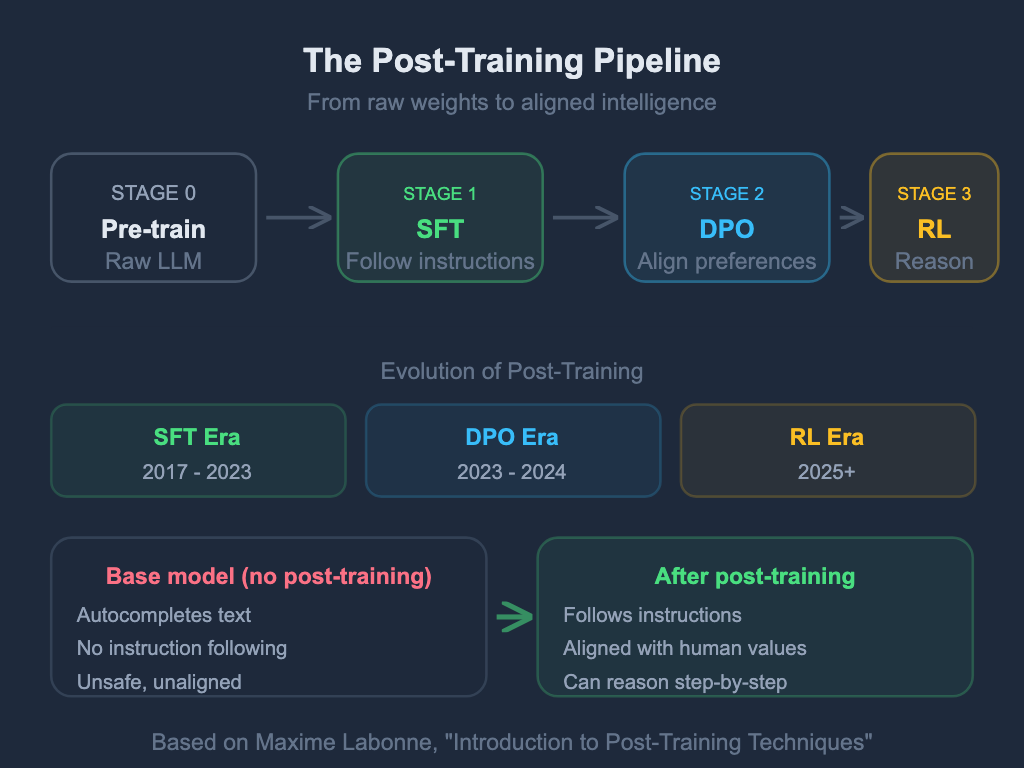
当Meta发布Llama或Mistral发布其模型时,通常会提供两个版本:基础模型(Base Model) 和指令模型(Instruct Model)。基础模型是预训练的直接产物,只能进行文本自动补全,无法遵循指令、回答问题或进行对话。指令模型则具备所有这些能力。两者的关键区别就在于后训练——一组在预训练之后应用的技术,将文本补全引擎转变为AI助手。
如果预训练好比让一个人阅读大量书籍,那么后训练就是教他如何就所读内容进行对话。
1.2 后训练与微调的区别
这两个概念虽然重叠,但并非同一回事。
后训练 vs 微调对比
|
维度 |
后训练 |
微调 |
|
目标 |
通用型助手 |
特定任务专家 |
|
数据规模 |
100万+样本 |
1万-100万样本 |
|
执行者 |
模型提供商(Meta、Mistral等) |
最终用户和企业 |
|
输出 |
指令/对话模型 |
领域适配模型 |
|
技术组合 |
SFT + DPO + RL |
通常仅SFT |
后训练是将Llama变成Llama-Instruct的过程;微调则是将Llama-Instruct变成自定义产品助手的过程。两者使用相同的底层方法(尤其是SFT),但规模和目的不同。
二、三阶段流水线概览
现代后训练遵循一个三阶段流水线,每个阶段建立在前一个阶段之上:
基础模型 → SFT → DPO → GRPO → 对齐模型
(自动补全) (遵循指令) (偏好优质回答) (逐步推理)三、第一阶段:监督微调(Supervised Fine-Tuning, SFT)
3.1 核心作用
SFT是最直观的阶段:向模型展示数千对"指令-回答"样本,训练它生成类似的输出。例如,对基础模型输入"法国的首都是什么?",它可能会续写为"德国的首都是什么?什么是……"——它是在自动补全,而非在回答问题。经过SFT后,它才会回答:"法国的首都是巴黎。"
SFT教授三项核心能力:
- 指令遵循:理解用户所问的内容
- 格式合规:以期望的结构(对话、JSON、代码)进行回复
- 知识激活:将预训练中获得的相关知识调取出来
3.2 三种训练方法
运行SFT有三种方式,各有权衡:
SFT训练方法对比
|
方法 |
质量 |
显存需求 |
速度 |
适用场景 |
|
全量微调 |
最佳 |
极高(2倍模型) |
慢 |
拥有多块A100时 |
|
LoRA |
接近全量 |
高(1倍模型 + 5%) |
快 |
大多数团队的默认选择 |
|
QLoRA |
良好(轻微下降) |
低(0.25倍模型) |
中等 |
消费级GPU、原型开发 |
LoRA(低秩适配) 是大多数实际工作的标准方法。它冻结基础模型权重,只训练小型适配器矩阵(约占模型总参数的2%),以极小的计算开销达到接近全量微调的质量。
QLoRA 更进一步,将基础模型量化为4位精度,显存需求降低至原来的四分之一。代价是质量有轻微下降——适合实验和原型开发,但生产环境通常仍用LoRA或全量微调。
3.3 关键训练参数
SFT阶段最关键的训练参数:
- 学习率:1e-5 到 5e-5(过高会导致灾难性遗忘,过低则无有效学习)
- 训练轮数(Epochs):3-5轮(并非越多越好,模型在小数据集上会快速过拟合)
- 批次大小(Batch Size):8-16(更大批次可使梯度更平滑,但需要更多显存)
- 最大序列长度:2048-8192 tokens(越长上下文越丰富,但训练速度越慢)
- 优化器:带权重衰减0.01的AdamW
3.4 数据集质量重于规模
文章特别强调:数据集的质量远比规模重要。一个优秀的SFT数据集需具备三大支柱:
- 准确性:每条回答都必须正确。一条错误回答就可能教会模型产生幻觉。
- 多样性:覆盖全部任务类型——问答、推理、编程、数学、创意写作。
- 复杂性:包含多步推理,而不仅仅是简单的事实回忆。
一个精心策划的5万条高质量样本,性能始终优于50万条充满噪声的样本。
四、第二阶段:直接偏好优化(Direct Preference Optimization, DPO)
4.1 核心机制
SFT教会模型生成合理回答,DPO则教会模型在存在多个有效回答时哪个更好。DPO使用偏好对(Preference Pairs) 进行工作——对每个提示词,提供一个"被选中的"(好的)回答和一个"被拒绝的"(差的)回答。训练目标是在概率上拉开选中回答与被拒绝回答之间的差距,模型不光学到了该说什么,还学到了不该说什么。
SFT与DPO的教学逻辑对比
|
SFT |
DPO |
|
|
教学方式 |
"对这类问题,你应该这样回答" |
"这两个回答之间,这个更好,因为……" |
|
局限 |
无法区分"够好"与"优秀"的回答 |
—— |
SFT存在能力上限——它教会模型模仿训练数据,但无法区分"够好"的回答和"优秀"的回答。DPO加入了质量信号,将模型推向其能力范围的更优一端。
4.2 策略漂移问题与解决方案
DPO有一个重要陷阱:策略漂移。如果偏好数据是由另一个模型(如GPT-4)生成的,那么该模型的回答风格与你的模型之间存在不匹配,训练信号会变得充满噪声。解决方案是在线策略数据生成(on-policy data generation):使用你自己的模型生成回答,再由LLM评审团进行排序,最佳为Chosen、最差为Rejected,然后用DPO进行训练。这创建了更紧密的反馈闭环——模型从自身错误中学习,而非从另一模型的输出中学习。
4.3 最新DPO改进技巧
文章中提到的前沿改进技术包括:
- 长度归一化:防止模型学到"越长越好取悦用户"的偏好
- 锚定偏好优化:添加参考锚点以稳定训练过程
- 精炼选中回答:训练前使用更强模型打磨"被选中"的回答
- 基于评分标准的评分:按特定维度(准确性、帮助性、安全性)评分,而非简单的二元好坏判断
五、第三阶段:强化学习(Group Relative Policy Optimization, GRPO)
5.1 GRPO工作原理
这是最新、也最强大的阶段。SFT教模仿,DPO教偏好,RL则教模型推理——去尝试多种思路,并学习哪些思维模式能导向正确答案。
GRPO(组相对策略优化) 由DeepSeek提出,并驱动了DeepSeek-R1等模型。与需要单独"评论家模型"的传统RL方法(PPO)不同,GRPO更为简洁:
- 给定一个提示词,采样一组回答(例如8个输出)
- 用奖励函数为每个回答打分
- 在组内归一化分数,计算每个回答的相对优势
- 更新模型,使其生成更多高分回答、更少低分回答
核心洞见在于:通过在一组回答内部进行比较,GRPO不需要知道每个回答的绝对价值——它只需要知道这批回答中哪个相对更好。
5.2 奖励函数设计
奖励函数是驱动学习的核心,分为两类:
|
类型 |
示例 |
特点 |
|
基于规则的奖励 |
数学答案是否匹配正确答案?代码是否通过测试用例?格式是否符合要求? |
易于实现,信号明确无歧义 |
|
基于模型的奖励 |
使用另一个LLM评判回答质量 |
更灵活通用,但引入了另一个模型的偏见 |
对于大多数实际应用,基于规则的奖励效果最好,因为它们给出的是无歧义的信号。这也解释了为何RL在数学和编程任务上最为成功——奖励是二元的(正确或错误)。
5.3 RL为何至关重要
RL赋予了DeepSeek-R1、OpenAI o1等模型推理能力。模型在此阶段学会了:
- 将问题拆解为多个步骤
- 尝试多种解题思路
- 验证自身的工作
- 当某条路径行不通时回退重试
这种涌现行为无法从SFT获得——那需要数百万条完美的思维链示例;也无法从DPO获得——偏好对无法很好地捕捉推理过程。RL让模型通过试错自行发现推理策略。
六、后训练的三个发展阶段
后训练技术经历了快速演进:
|
阶段 |
时间 |
核心特征 |
代表模型 |
|
SFT时代 |
2017-2023 |
从Transformer论文和InstructGPT的RLHF起步,聚焦于让模型至少能遵循指令 |
GPT-3.5、早期ChatGPT |
|
DPO时代 |
2023-2024 |
DPO通过消除独立的奖励模型,降低了RLHF的复杂性;对齐变得对小型团队也可行 |
Zephyr、Intel NeuralChat、早期Llama微调版本 |
|
RL时代 |
2025+ |
DeepSeek-R1证明纯RL可产生突破性推理能力,GRPO成为标准 |
DeepSeek-R1、QwQ、Kimi k1.5 |
七、实用工具与资源需求
7.1 工具推荐
后训练工具链对比
|
工具 |
最适用于 |
复杂度 |
|
Unsloth |
SFT和DPO,新手友好 |
低 |
|
TRL(Hugging Face) |
完整流程(含GRPO) |
中 |
|
OpenRLHF |
大规模分布式RL |
高 |
|
torchtune(PyTorch) |
原生PyTorch的SFT |
中 |
对大多数团队而言,Unsloth处理SFT/DPO,TRL处理GRPO,即可覆盖完整流程。
7.2 资源需求
各阶段成本对比
|
阶段 |
算力需求 |
数据需求 |
典型耗时 |
|
SFT |
1 GPU,数小时 |
1万-10万样本 |
3-8小时 |
|
DPO |
1-2 GPU,数小时 |
1万-5万偏好对 |
4-12小时 |
|
GRPO |
4-8+ GPU,数天 |
提示词 + 奖励函数 |
1-7天 |
SFT对任何拥有一块GPU的人都触手可及;DPO增加了中等成本;RL则需要严肃的基础设施——这也是它主要由大型实验室和资金充足的团队来完成的原因。
7.3 何时需要后训练 vs 微调
大多数开发者无需运行完整的后训练流程。决策路径如下:
- 从指令模型开始——已有人为你完成了后训练
- 先尝试RAG——在推理时注入领域知识
- 如需要特定语气/领域格式化/一致的行为模式,用SFT微调
- 如模型生成尚可但质量缺乏一致性,考虑DPO
- 仅在有明确奖励信号(代码正确性、数学准确性)且有充足算力时考虑RL
八、优劣势分析
8.1 优势
- 转变能力:基础模型对终端用户几乎无用,后训练使其变得实用
- 阶段可组合:每个阶段解决不同的弱点,可在任意阶段停止
- SFT易于获取:任何拥有GPU和优质数据的人都能在数小时内微调模型
- RL解锁推理:这些能力无法仅通过模仿来教授
- 开源工具齐全:Unsloth、TRL等使完整流程对所有人开放
8.2 劣势
- 数据质量决定一切:糟糕的训练数据只会让模型变得更差而非更好
- 灾难性遗忘:过于激进的训练可能破坏预训练阶段获得的知识
- RL成本高昂:完整的GRPO需要多GPU环境和数天的算力投入
- 对齐税:安全训练可能降低模型的原始能力(模型变得更谨慎)
- 评估困难:与预训练损失不同,后训练的质量评估是主观的且依赖于具体任务
- 策略漂移:使用离线数据进行的DPO会产生不可靠的结果
九、核心要点总结
- 后训练是连接原始语言模型和实用AI助手之间的桥梁
- 三阶段流程:SFT(学习遵循指令)→ DPO(学习偏好更优回答)→ RL(学习推理)
- 从指令模型开始——除非你有特定需求,否则不要重复造轮子
- SFT是商业微调最实用的阶段,推荐配合LoRA使用
- RL是前沿领域——它如何构建出最好的推理模型,但需要海量资源
- 数据集质量永远优先于数量

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)