RAG 不是向量数据库,而是在给大模型建立证据链
RAG 的关键不是“有没有向量数据库”,而是能不能建立一条从用户问题到检索证据、再到可信回答的完整证据链。本文结合 RAG 论文、OpenAI/Anthropic/Microsoft/Elastic/AWS/Google 等资料,以及 LangChain、LlamaIndex、Haystack、RAGFlow、GraphRAG 等开源实践,讲清 RAG 的工程架构、常见误区和最小落地方案。
很多人第一次做 RAG,都会把它理解成一个很简单的流程:
文档切块 → Embedding → 向量数据库 → Top-K 检索 → 拼 Prompt → 大模型回答。
这个流程没有错,但它只说明系统“能检索”,不代表系统“能可靠回答”。
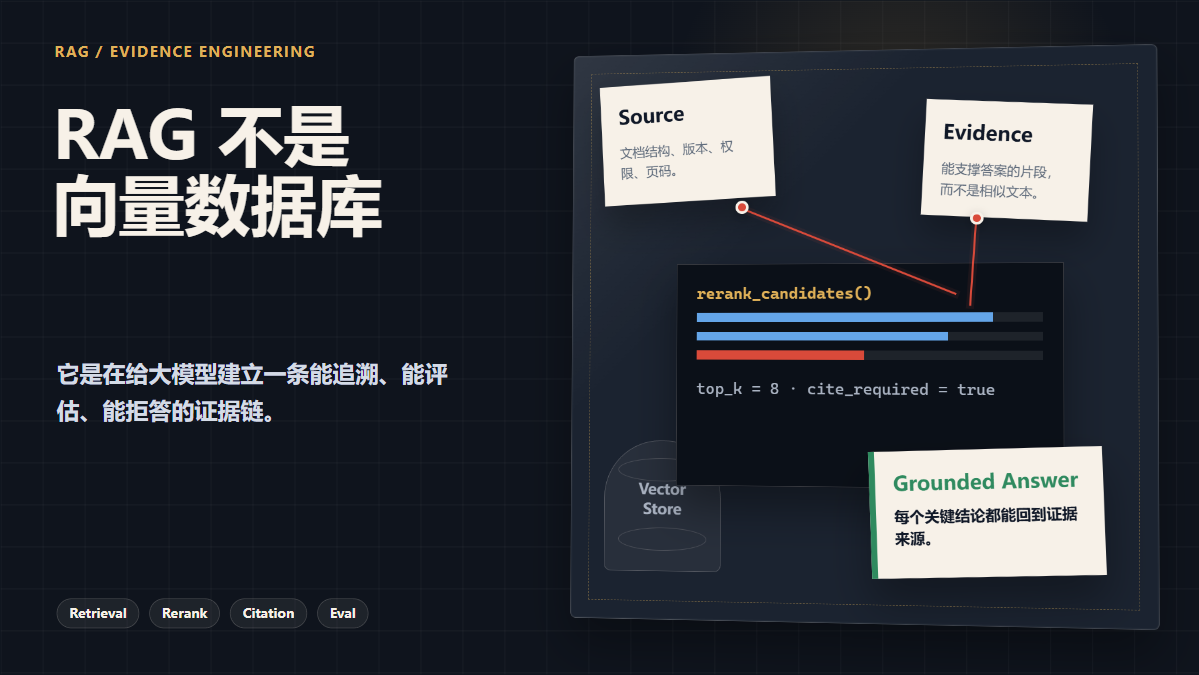
真正可用的 RAG,不是一个向量数据库,而是一条证据链:
问题从哪里来,证据从哪里找,为什么选中这些证据,证据之间有没有冲突,最终答案的每一句话能不能回到来源。
一、为什么接了向量库,答案还是不可靠?
坏 RAG 的问题通常不是模型不会回答,而是证据链在中间断了:
- 文档解析把表格拆坏了,答案需要的字段根本没进库;
- Chunk 切得太碎,“它增长了 3%”这种句子失去了公司、年份、季度;
- 纯向量检索召回了语义像、但事实不对的片段;
- Top-K 太大,把噪声也塞进上下文;
- Prompt 没有要求“资料不足时拒答”,模型开始补脑;
- 没有评测集,系统上线后只能靠用户投诉发现问题。
所以 RAG 的难点不是“怎么把文本变成向量”,而是“怎么让模型回答时拿到正确、完整、可追溯的证据”。

二、RAG 的本质:参数记忆 + 非参数记忆
RAG 这个方向最早在 2020 年的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中系统提出。它的核心思想是:大模型自身的参数是一种“参数记忆”,外部可检索知识库是一种“非参数记忆”。
开发者可以这样理解:
- 模型参数负责语言理解、推理和组织表达;
- 外部检索系统负责提供最新、私有、可追溯的事实;
- 生成结果必须受到检索证据约束。
RAG 和 SFT 微调的区别也在这里:
| 维度 | SFT 微调 | RAG |
|---|---|---|
| 核心目标 | 改变模型行为和任务能力 | 给模型提供外部事实证据 |
| 知识更新 | 通常需要重新训练或增量训练 | 更新知识库即可 |
| 可解释性 | 知识在参数里,不易追溯 | 可以引用来源 |
| 适合场景 | 风格、格式、任务习惯 | 企业知识、文档问答、最新信息 |
一句话概括:
SFT 解决“模型会不会这样做”,RAG 解决“模型有没有可靠资料可查”。
三、完整 RAG 证据链
我更建议把 RAG 拆成两条链路:离线索引链路和在线回答链路。
离线链路负责“证据入库”:
- 数据接入:PDF、Word、PPT、网页、数据库、FAQ、Confluence、Notion;
- 文档解析:正文、标题、表格、图片、页码、层级结构;
- 数据清洗:去重、去噪、修复乱码、保留段落边界;
- Chunk 切分:按语义边界切,不要机械切碎;
- 元数据绑定:来源、时间、作者、产品线、权限、版本;
- 向量化与关键词索引:Embedding + BM25/全文索引;
- 入库:向量库、搜索引擎、图数据库或混合索引。
在线链路负责“证据使用”:
- Query 理解:识别意图、补全上下文、拆分子问题;
- 初筛召回:向量检索、关键词检索、结构化过滤;
- 融合排序:RRF 或加权融合,把多路召回合并;
- Rerank:用更精细的模型重新判断 Query 与 Chunk 的相关性;
- Context Packing:控制 Top-K、去重、排序、压缩;
- Grounded Generation:要求模型基于证据回答,不足就拒答;
- Citation:输出引用来源;
- Evaluation:用数据判断召回、忠实度、答案相关性。

这条链路里,向量数据库只是其中一个组件。把向量数据库等同于 RAG,就像把 MySQL 等同于整个后端系统。
四、Chunk 不是切饼,而是在保留语义现场
Chunk 是 RAG 中影响效果最关键、也最容易被低估的环节。
太小的问题是语义断裂。例如“同比增长 18%。”这句话如果离开公司名、指标名、年份、地区,几乎没有任何证据价值。
太大的问题是噪声过多。一个 2000 token 的 Chunk 里可能只有 80 token 与问题相关,其余内容都会挤占上下文窗口,还可能干扰模型判断。
比较稳的工程策略是:
- FAQ:一个问答对就是一个 Chunk;
- 技术文档:按标题层级、段落和代码块切;
- 长报告:用父子文档策略,小块用于检索,大块用于生成;
- PDF 表格:优先保留行列关系,不要只抽纯文本;
- 代码 RAG:按函数、类、模块和调用关系切,不能按字符硬切;
- 权限场景:每个 Chunk 必须绑定租户、用户组、文档级权限。
Anthropic 在 Contextual Retrieval 里指出,传统 RAG 把文档切成小块时会丢掉上下文。他们的做法是在每个 Chunk 前加一段简短的上下文说明,再做 Embedding 和 BM25 索引。这个思路很适合企业知识库:Chunk 不只是文本片段,它应该知道自己来自哪份文档、哪一节、讨论哪个对象。

五、为什么生产里很少只用纯向量检索?
向量检索擅长“语义相似”,但它不总是擅长“精确命中”。
比如用户问:
TS-999 报错怎么处理?
纯向量检索可能召回很多“报错处理”“故障排查”“错误码说明”的内容,但错过唯一包含 TS-999 的文档。
生产 RAG 通常会走 Hybrid Search:
- Dense Retrieval:向量检索,负责语义相似;
- Sparse Retrieval:BM25/关键词检索,负责精确词、编号、术语;
- Metadata Filter:先按租户、权限、产品、时间过滤;
- RRF 或融合排序:合并多路结果;
- Rerank:把“看起来相关”的结果变成“真的适合回答”的证据。
Elastic 官方文档建议用 RRF 做混合检索排序;Azure AI Search 文档也详细解释了 RRF 如何把多路排序结果融合成一个统一排序。这背后的工程判断很朴素:不要相信单一路径能覆盖所有问题。

六、Rerank 是把“召回结果”变成“可用证据”的关键层
Embedding 检索通常是 Bi-Encoder:Query 编一次,文档编一次,然后算相似度。它快,适合大规模召回,但判断不够细。
Rerank 通常更像 Cross-Encoder:把 Query 和候选 Chunk 放在一起判断相关性。它慢一些,但更准。
一个常见组合是:
向量/BM25 初筛 Top 50
↓
Rerank 精排 Top 5-10
↓
拼入上下文窗口
↓
模型基于证据回答
这里有个取舍:召回越大,覆盖率越高,但延迟和成本上升;Top-K 越大,资料越多,但噪声也越多。不要拍脑袋调参数,应该拿评测集跑。
七、RAG 的 Prompt 不是“请根据资料回答”这么简单
生产里的 RAG Prompt 至少要管住四件事:
- 证据边界:只能使用检索资料,不要把常识和猜测混进去;
- 冲突处理:当资料冲突时,按时间、版本、权威来源排序;
- 引用格式:每个关键结论都要能回到文档、章节或链接;
- 拒答策略:资料不足时明确说明缺少什么,而不是编一个答案。
还要注意间接 Prompt Injection:检索出来的文档和系统 Prompt 共享同一个上下文窗口。如果文档里出现“忽略之前指令”这类内容,模型可能把数据误当指令。LangChain 的 RAG 文档提醒过这个风险,建议把检索内容明确标记为数据,而不是指令。
八、RAG 怎么评估?
RAG 如果没有评测,很容易陷入玄学调参。
| 维度 | 看什么 | 常用指标 |
|---|---|---|
| 检索召回 | 正确证据有没有被找回来 | Recall@K、MRR、nDCG |
| 检索精度 | 找回来的内容是不是噪声太多 | Context Precision |
| 生成忠实度 | 回答是否被证据支持 | Faithfulness / Groundedness |
| 答案相关性 | 是否真正回答了问题 | Answer Relevance |
| 工程指标 | 是否可上线 | 延迟、成本、失败率、缓存命中率 |
LangSmith 的 RAG 评估教程把检索质量、回答质量、Groundedness 分开评估;Google Cloud 的 RAG 文章也强调,不做透明评估会导致“静默失败”:系统看起来能回答,但错误长期没人发现。

九、开源项目和大厂实践的启发
看开源项目和大厂博客,会发现一个趋势:RAG 正在从“向量检索 Demo”变成“上下文基础设施”。
LangChain 把 RAG 放进 Agent/Chain 编排里,强调索引和检索生成是两段流程,同时提醒间接 Prompt Injection 风险。
LlamaIndex 更像数据框架,围绕 Document、Node、Index、Query Engine 建抽象。它的优势是把“数据如何进入 LLM 应用”这件事讲得更系统。
Haystack 强调 Pipeline:Document Store、Retriever、Ranker、Generator 都是可替换组件,更接近传统后端对可组合链路的理解。
RAGFlow 把重点放在 deep document understanding。它的 README 里反复强调复杂格式文档、可解释 Chunk、引用溯源。这说明真实企业场景里,PDF、表格、扫描件、版面结构往往比“向量库选型”更难。
Microsoft GraphRAG 是另一条路线:当问题不只是“找几个相关片段”,而是“理解一堆文档中的实体、关系和全局主题”时,纯文本 Chunk 会吃力。GraphRAG 用图结构承载实体关系,适合全局总结、多跳关系、复杂数据发现。
Uber 的 Enhanced Agentic RAG 也很有参考价值。他们的内部 on-call Copilot 从传统 RAG 演进到 Agentic RAG,引入 LLM-powered agents 做前置和后置步骤,公开文章里提到可接受答案比例相对提升 27%,错误建议相对降低 60%。这说明生产问题往往不是“有没有检索”,而是检索前后的规划、验证、纠错和反馈闭环。
十、最小可落地方案
如果今天从零做一个内部知识库问答,我不会一开始就上 GraphRAG、多 Agent、复杂工作流。
我会先做一个足够扎实的最小闭环:
- 选一个明确场景,比如“内部制度问答”或“产品 FAQ”;
- 整理 50-100 个真实问题,人工标注期望答案和来源文档;
- 文档解析先保守,确保标题、段落、表格和页码不丢;
- Chunk 使用递归切分 + 元数据,FAQ 用 Q-A 对作为 Chunk;
- 检索使用 Hybrid Search:向量 + BM25 + metadata filter;
- 初筛 Top 30-50,再 Rerank 到 Top 5-10;
- Prompt 强制引用来源,资料不足必须拒答;
- 做一个评测脚本,持续看 Recall@K、Groundedness、答案相关性;
- 记录 bad case:没召回、召回错、证据冲突、模型编造;
- 每次只改一个变量:Chunk、Embedding、Top-K、Rerank、Prompt。
总结
RAG 不是向量数据库。
向量数据库只是证据仓库的一种实现,RAG 真正要解决的是:
- 如何把外部知识变成可检索的证据;
- 如何从海量证据里找出正确片段;
- 如何让模型只基于证据回答;
- 如何在资料不足或冲突时不胡说;
- 如何用评测持续证明系统真的变好了。
如果说 Tool Use 是在给 Agent 设计权限边界,Context Engineering 是在管理注意力预算,那么 RAG 就是在给大模型建立证据链。
没有证据链的 RAG,只是把资料塞给模型。
有证据链的 RAG,才是可以上线、可以追责、可以持续优化的知识系统。
参考资料
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS 2020:https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
- OpenAI Retrieval Guide:https://developers.openai.com/api/docs/guides/retrieval
- OpenAI File Search Guide:https://developers.openai.com/api/docs/guides/tools-file-search
- Anthropic Contextual Retrieval:https://www.anthropic.com/engineering/contextual-retrieval
- Elastic Hybrid Search:https://www.elastic.co/docs/solutions/search/hybrid-search/
- Azure AI Search RRF:https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking
- Microsoft GraphRAG:https://github.com/microsoft/graphrag
- RAGFlow:https://github.com/infiniflow/ragflow
- LangChain RAG Docs:https://docs.langchain.com/oss/python/langchain/rag
- LlamaIndex RAG Docs:https://developers.llamaindex.ai/python/framework/understanding/rag/
- Haystack:https://github.com/deepset-ai/haystack
- LangSmith RAG Evaluation:https://docs.langchain.com/langsmith/evaluate-rag-tutorial
- Google Cloud RAG Evaluation Blog:https://cloud.google.com/blog/products/ai-machine-learning/optimizing-rag-retrieval
- Uber Enhanced Agentic RAG:https://www.uber.com/ro/en/blog/enhanced-agentic-rag/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)