SDK Harness架构 :DeepAgent 基于LangGraph的生产级Super Agent驾驭层实现
SDK Harness架构 :DeepAent 基于LangGraph的生产级Super Agent驾驭层实现
尼恩说在前面
在45岁老架构师尼恩的读者交流群(50+人)里,最近不少小伙伴拿到了阿里、滴滴、极兔、有赞、希音、百度、字节、网易、美团这些一线大厂的面试入场券,恭喜各位!
前两天就有个小伙伴面腾讯, 问到 **“ 听说过Harness Agent 吗?你们怎么实现 Harness Agent 的? ”**的场景题 ,小伙伴没有一点概念,导致面试挂了。
小伙伴 没有看过系统化的 答案,回答也不全面 ,so, 面试官不满意 , 面试挂了。
小伙伴找尼恩复盘, 求助尼恩。
通过这个 文章, 这里 尼恩给大家做一下 系统化、体系化的梳理,写一个系列的文章组成 尼恩编著 《Harness 架构与源码 学习圣经》 深入剖析 Harness AI 平台级 架构的 架构思维与 核心源码,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
同时,也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
尼恩编著 《Harness 架构与源码 学习圣经》
第一章: 什么是 Harness架构?2026年AI核心范式解析 : Harness架构与Agent工程化
具体文章: 54k+Star 爆火!AI 框架 新王者 Harness Agent 来了!尼恩 来一次Harness穿透式解读
第二章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑
具体文章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑
第三章: DeerFlow 源码 14层Middleware 源码解析 ,又一个 “洋葱责任链模式” 架构思维 的 经典案例
具体文章: DeerFlow 源码 14层Middleware 源码解析 ,又一个 “洋葱责任链模式” 架构思维 的 经典案例
第四章: LangChain 超底层 四大设计模式 Design Patterns ,架构师 的 必备 内功,毒打面试官
具体文章: LangChain 超底层 四大设计模式 Design Patterns ,架构师 的 必备 内功,毒打面试官
第五章:Harness宏观架构:基于 PPAF 思维 & REPL 思维,完成 Lead-Agent和Sub-Agent深度拆解
具体文章: 第五章:Harness宏观架构:基于 PPAF 思维 & REPL 思维,完成 Lead-Agent和Sub-Agent深度拆解
第六章:Harness宏观架构:DeerFlow 2.0 断点续跑机制 架构设计与实现
具体文章: Harness宏观架构:DeerFlow 2.0 断点续跑机制 架构设计与实现
第七章: Harness 平台实战: 用 DeerFlow 构建 一个企业自己的 Manus 平台( 企业长任务智能体平台)
具体文章: Harness 平台实战: 用 DeerFlow 构建 一个企业自己的 Manus 平台( 企业长任务智能体平台)
第八章: Harness 超牛逼的 三级记忆架构 :字节 Deerflow 上下文+历史分层+事实列表 ! 落地价值 逆天!!
具体文章: Harness 超牛逼的 三级记忆架构 上下文+历史分层+事实列表 ! 落地价值 逆天!!
第九章: Harness 顶级架构:DeerFlow 2.0 沙盒 Sandbox 架构设计、Sandbox 源码深度解析(史上最深 、价值 逆天)
具体文章: Harness 顶级架构:DeerFlow 2.0 沙盒 Sandbox 架构设计、Sandbox 源码深度解析(史上最深 、价值 逆天)
第10章: 顶奢RAG架构之, 必不可少的 RAG评估体系:7大核心指标落地优化,让RAG从Demo走向生产
【RAG评估、RAG度量指标】顶奢RAG架构之, 必不可少的 RAG评估体系:7大核心指标落地优化,让RAG从Demo走向生产 full - 技术自由圈
第11章:Harness架构 :字节 Deerflow 基于LangGraph的生产级Super Agent驾驭层实现 / DeerFlow 2.0 的 lead_agent 任务总调度 架构设计与实现解析
Harness架构 : DeerFlow 2.0 的 lead_agent 任务总调度 架构设计与实现解析
第十二章: Harness 具体应用:AI编程王炸组合:顶级三剑客 OpenSpec 定方向,Superpowers定纪律,Harness定协同
顶级三剑客 OpenSpec 定方向,Superpowers定纪律,Harness定协同
第十三章: Harness 架构哲学和思维:架构思维、架构哲学、设计模式 大拆解、大总结、大提炼
Harness 架构哲学和思维:架构思维、架构哲学、设计模式 大拆解、大总结、大提炼
本文
第十四章: 架构哲学和思维: Harness /ReAct /PlanExec /Reflect /混合范式 的 区别
架构哲学和思维: Harness /ReAct /PlanExec /Reflect /混合范式 的 区别
第十五章: Harness 底层知识: MCP与FC的10大差别?Harness 怎么 用MCP与FC?
Harness 底层知识: MCP与FC的10大差别?Harness 怎么 用MCP与FC?
第16章: 架构天花板 : 字节 Deerflow 基于LangGraph的生产级 Harness 执行层 Sub-Agent 深度拆解
架构天花板 :基于LangGraph的生产级 Harness 执行层 Sub-Agent 深度拆解
第17章: Harness SDK 架构 :DeepAgent 基于LangGraph的生产级Super Agent驾驭层实现
本文
第18章:Harness架构 核心一:断点续跑机制 的 架构设计 与底层源码分析 .
具体文章: 尼恩还在写, 本周发布
第19章:Harness架构 核心二: XXX
具体文章: 尼恩还在写,后续发布
估计有 10章以上,具体请关注技术自由圈。

DeepAgents的Super-Agent 全局调度中枢
SDK Harness架构 :基于LangGraph的生产级Super Agent驾驭层实现 / DeepAgent 的 lead_agent 任务总调度 架构设计与实现解析
尼恩先问一句:做过 Agent项目的CTO、架构师们,你们是不是也踩过这样的坑?
Agent Demo 阶段, MVP版本 跑起来贼溜: 工具调用丝滑、子Agent分工明确,拍着胸脯跟老板说“能上线”;
结果一到生产环境,直接翻车——工具调用乱套,A工具干了B工具的活;子Agent并行跑起来,中间结果互相污染,排查日志查得头皮发麻;更要命的是,换个模型厂商,整个业务层代码全要改,加班到凌晨还搞不定。
尼恩有个cto 级的vip,带团队做智能运维Agent, 就狠狠栽过这跟头。
当时 堆了8个工具、3个子Agent,Demo阶段号称“全自动化运维”,结果上线3天,因为没有统一调度,子Agent嵌套调用导致内存泄漏,直接把服务器搞崩了,损失几十万。
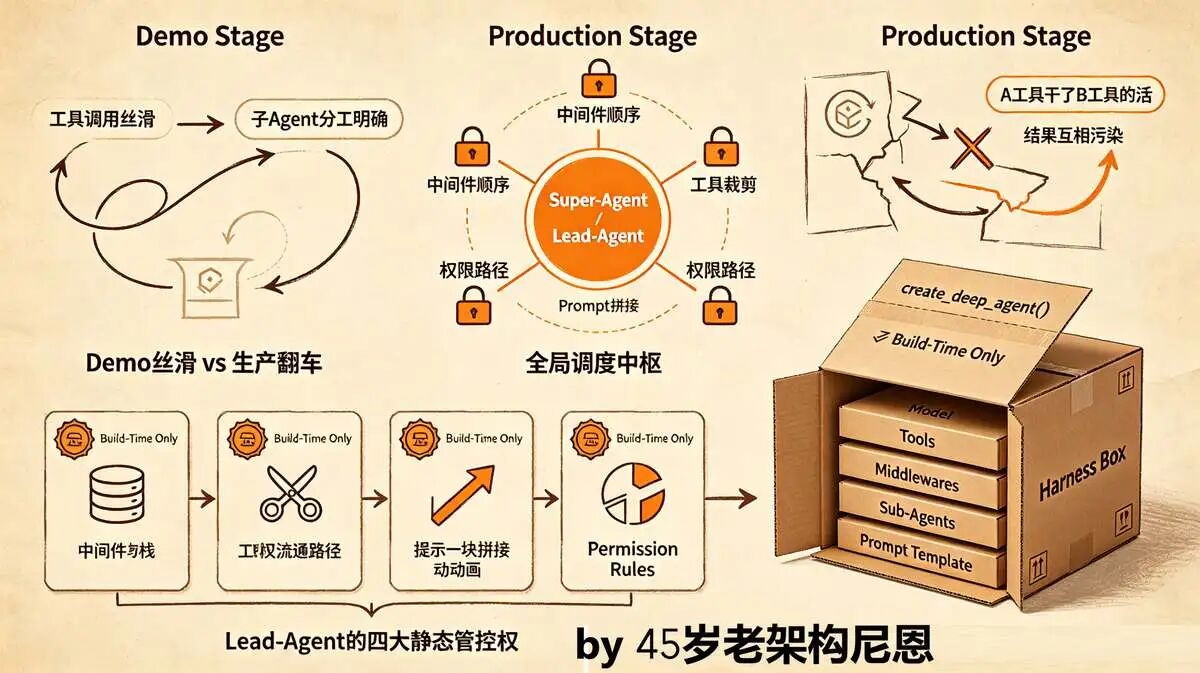
到底哪里出了问题?
不是工具太多。不是子 Agent 太多。
er 是**缺了一个能管住全局的主 Agent,一个在跑起来之前就把所有规则定死的调度中枢。**这就是 Super-Agent 、或者 Lead-Agent。
研究DeepAgents的lead-Agent, 大家一定会有巨大收获:多Agent生产翻车,从来不是工具不够多、模型不够强,而是缺了一个“全局调度中枢”,缺了一套“构建期定死规则、运行期只做执行”的lead-Agent 架构逻辑。
lead-Agent 干了啥:
-
中间件排什么顺序?
-
工具该不该裁?
-
权限规则怎么走?
-
Prompt 按什么顺序拼?
这些都要在构建期一次性定死,不能在运行期改。
DeepAgents 就是这套 Harness 思路的完整落地。 Super-Agent 是它的核心产品,create_deep_agent 是创建 Super-Agent 的唯一入口。
一整套从模型到工具、从中间件到子 Agent、从 Prompt 到权限的全局组装,全塞在这一个函数里。
接下来,尼恩带大家顺着 create_deep_agent,看它怎么从参数一路装到封箱。
一、先搞懂 Super-Agent:DeepAgents 的全局调度中枢
先把这个概念说清楚。
因为"Super-Agent"这名字容易让人误会, 它不是"比普通 Agent 更强"的意思,更不是模型更大、工具更多、Prompt 更长的 Agent。
Super-Agent 是 DeepAgents 的主 Agent,是全局调度中枢。 在 DeepAgents 的多 Agent 体系里,它是唯一的老大。
子 Agent 归它分派,中间件归它编排,工具调用归它决策。它自己就是那个跑在用户面前的 Agent,只不过它底下还管着一群随时待命的子 Agent。
那它和普通 Agent 到底差在哪?
差在它是"先装好再跑"的。
普通 Agent 可能边跑边拼配置,Super-Agent 是 create_deep_agent 这条装配流水线把模型、工具、中间件、子 Agent、权限规则全装好封死后,才交出去跑的。
装好之后,图结构不可变。只能 .invoke() / .stream(),不能改任何东西。
打个比方:Super-Agent 是一辆整车,create_deep_agent 是造它的生产线。生产线负责把发动机(模型)、方向盘(工具)、安全气囊(中间件)、车载导航(子 Agent)全装好、全锁死,然后交钥匙。车开起来之后,你不能边开边换发动机。
子 Agent 归 Super-Agent 分派,中间件归Super-Agent 编排。
Super-Agent / leader-Agent 自己就是那个跑在用户面前的 Agent,只不过它底下还管着一群随时待命的子 Agent。
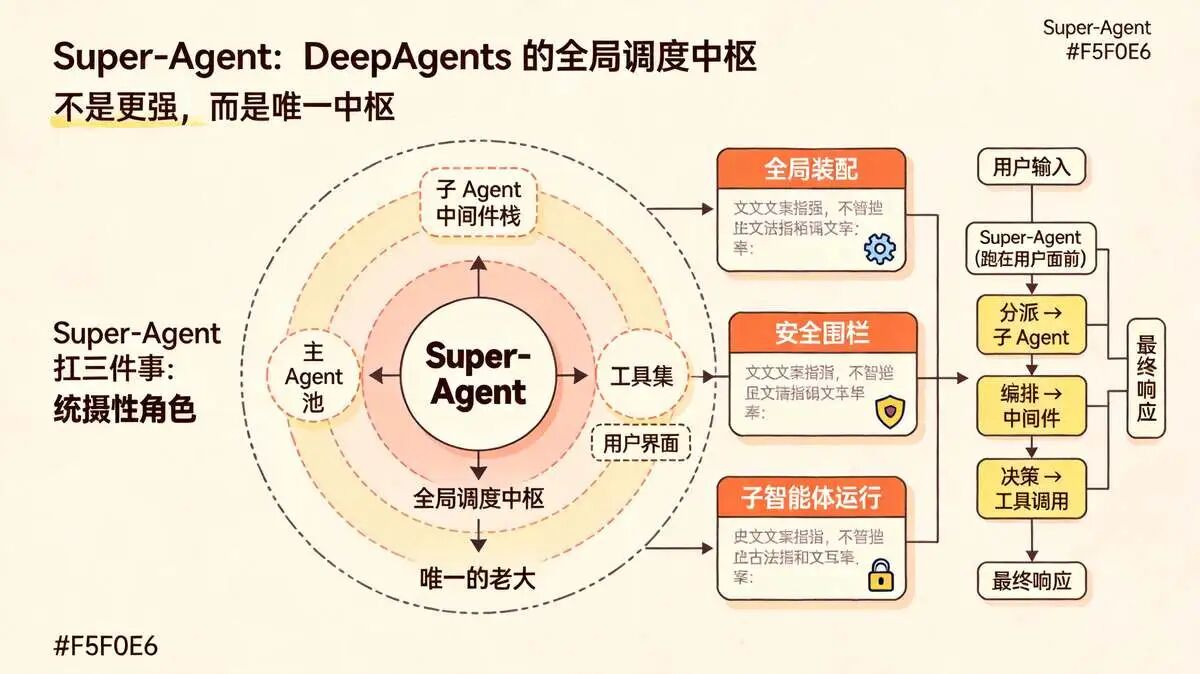
具体来说,Super-Agent 扛三件事:
(1) 全局装配:接用户需求,拆任务,分给子 Agent 去并行跑,最后汇总结果
(2) 安全围栏:上下文截断、工具过滤、权限拦截、子 Agent 隔离。这些安全能力不是外挂插件,是生产线装车时就嵌进去的
(3) 子智能体运行:构建期走完装配流水线后,图结构冻结,运行时只能执行不能篡改
Super-Agent 的分层架构思维
create_deep_agent函数 ,把模型、工具、中间件、子Agent、权限规则,所有“零部件”在构建期全部装配好、封死,等到运行期,你只能调用(invoke/stream),想改图编排结构, 门都没有!
这里就藏着第一个经典架构思维——分层架构思维,也是尼恩当年踩坑后最想复盘的点。
Super-Agent把整个Agent的生命周期,清晰地分成了“构建期”和“运行期”两层,彻底解耦:
(1) 构建期:负责“编译配置”——选什么模型、排什么中间件、定什么权限,所有决策都在这一步定死,相当于“生产线装整车”;
(2) 运行期:负责“执行配置”——调用工具、处理任务、返回结果,只做执行,不做任何决策,相当于“开整车”,不能边开边换零件。
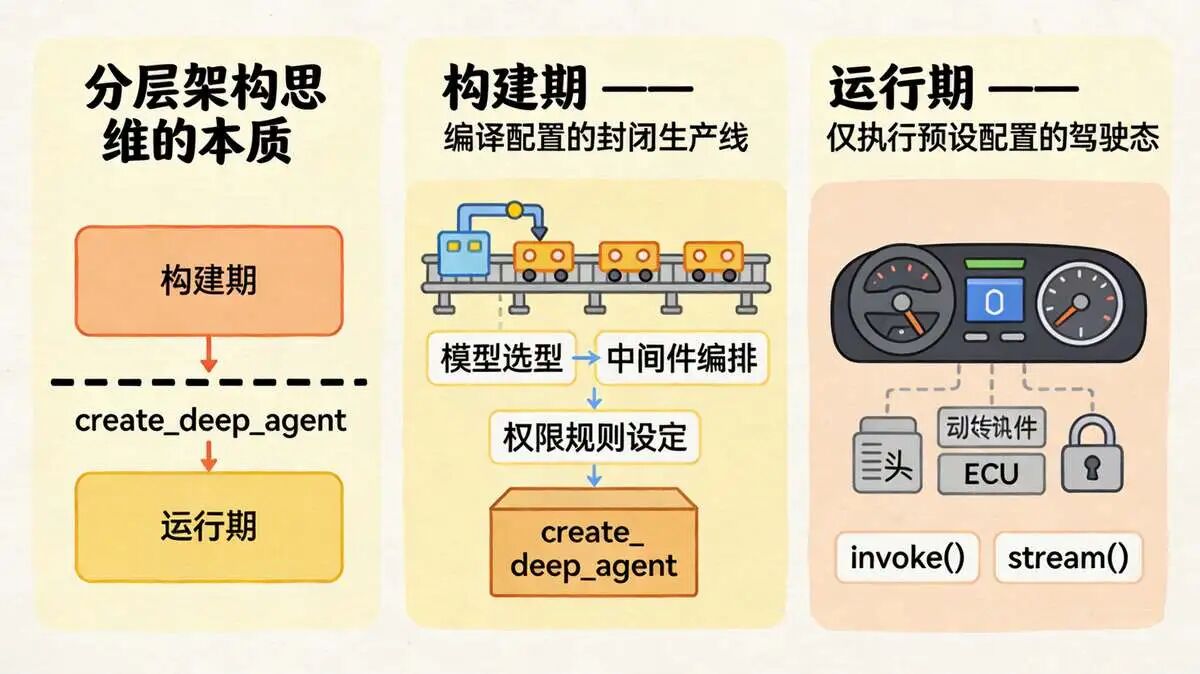
create_deep_agent:Super-Agent 的唯一入口
好,概念说清了。下一个问题:在 DeepAgents 里,怎么造一个 Super-Agent?
Super-Agent 的生命周期,就两个阶段。
构建期把该定的全定死。模型选谁、中间件排什么顺序、工具该不该裁、Prompt 怎么拼,一次性做完。create_deep_agent() 是这个阶段的唯一入口,它一调,到 return 的那一刻,所有决策都冻住了。
运行期只负责跑。拿到 CompiledStateGraph,调 .invoke() / .stream(),图结构碰都不能碰。
说白了,构建期是装车,运行期是开车。装车时装错了,开起来必翻。
先看create_deep_agent()源码。该方法的十七个参数,全塞在一个函数签名里:
# 真实源码:libs/deepagents/deepagents/graph.py
def create_deep_agent( # noqa: C901, PLR0912, PLR0915
model: str | BaseChatModel | None = None,
tools: Sequence[BaseTool | Callable | dict[str, Any]] | None = None,
*,
system_prompt: str | SystemMessage | None = None,
middleware: Sequence[AgentMiddleware] = (),
subagents: Sequence[SubAgent | CompiledSubAgent | AsyncSubAgent] | None = None,
skills: list[str] | None = None,
memory: list[str] | None = None,
permissions: list[FilesystemPermission] | None = None,
backend: BackendProtocol | BackendFactory | None = None,
interrupt_on: dict[str, bool | InterruptOnConfig] | None = None,
checkpointer: Checkpointer | None = None,
store: BaseStore | None = None,
debug: bool = False,
name: str | None = None,
cache: BaseCache | None = None,
) -> CompiledStateGraph:
源码中声明了三个 noqa 抑制:C901、PLR0912、PLR0915。
翻译成人话:这函数太复杂了,复杂到代码检查工具都觉得不对劲。但框架作者没选择把它拆散,而是把复杂度全集中到这一个入口里。公有 API 只有一个。
graph.py 里所有内部函数都以 _ 前缀命名,_build_default_model、_apply_excluded_middleware,全是流水线内部的工位,不暴露。
这和微服务对外暴露单一端口、内部随意重构是同一套逻辑。入口集中,内部自由。
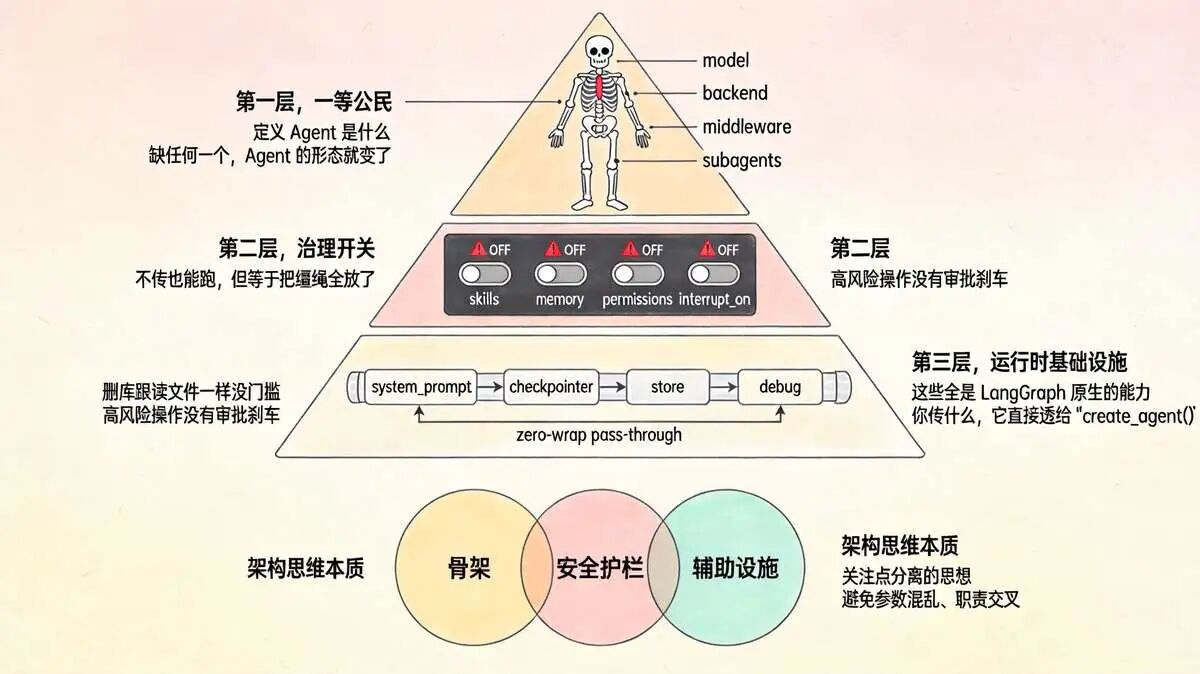
十七个参数分三层,每层管不同的事
十七个参数看着多,但尼恩把它们捋了一下,其实就三层。每层管不同的事:
第一层,一等公民。 model、backend、middleware、subagents 这四个,定义了 Agent 是什么。
用什么模型推理、文件落在哪、横切逻辑怎么搞、子 Agent 委派给谁。缺任何一个,Agent 的形态就变了。
第二层,治理开关。 skills、memory、permissions、interrupt_on 这四个,控制 Agent 被管到多紧。
不传也能跑,但等于把缰绳全放了。
skills不设,技能只能靠 Prompt 硬塞,回回手写。memory不开,每次对话从零开始,记不住任何东西。permissions不配,read_file和rm -rf同级权限,删库跟读文件一样没门槛。interrupt_on不挂,高风险操作没有审批刹车。
第三层,运行时基础设施。 system_prompt 是用户自定义指令,checkpointer 管会话持久化,store 做跨会话的长期存储,debug 开调试日志。
这些全是 LangGraph 原生的能力,DeepAgents 不包装,不重命名,不藏参数。你传什么,它直接透给 create_agent()。
三层合在一起,就是 之前 Harness 工程方案里说的六大闭环:行为闭环靠 middleware,状态闭环靠 checkpointer,经验闭环靠 skills + memory,行动闭环靠 permissions,输入闭环靠 interrupt_on,质量闭环靠 metadata。全部在构建期锁死。
这里涉及的架构思维 关注点分离的思想
把 Agent 的 “骨架”(核心参数)、“安全护栏”(治理参数)、“辅助设施”(运行参数)分开管理,避免参数混乱、职责交叉 。
* 这个符号的含义
有个细节很容易被扫过去:tools 参数后面那个孤零零的 *。
这符号是 Python 的 keyword-only 分隔符。意思很重:它右边的所有参数,调用时必须写出名字。
所以你写不出 create_deep_agent(model, tools, "my prompt"),必须老老实实写 create_deep_agent(model, tools, system_prompt="my prompt")。
尼恩觉得这是整条流水线最精髓的设计。普通框架关心"参数够不够",Harness 关心"参数意图清不清晰"。每条参数在调用点都带名字,不可误读。
这是代码级的确定性约束。
零配置就能跑
model=None 不报错。框架自己补一个 ChatAnthropic(model_name="claude-sonnet-4-6")。
backend 不传,那就走 StateBackend()。设个 ANTHROPIC_API_KEY,其他啥都不用配,Agent 就能跑起来。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
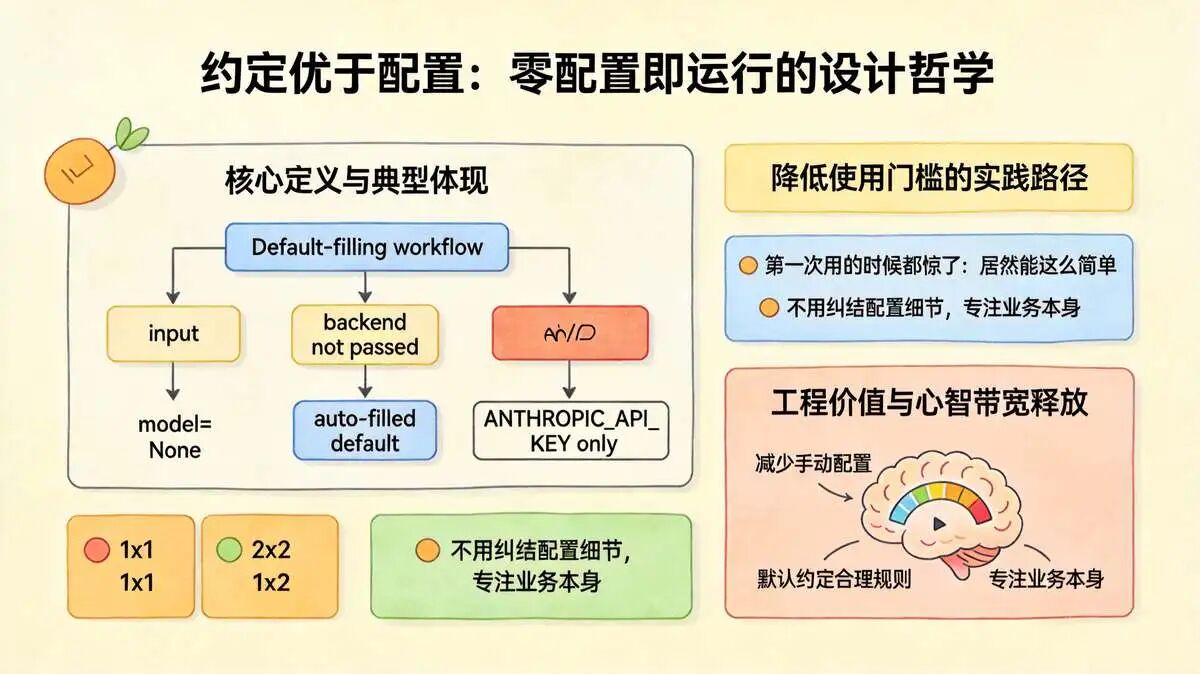
隐含设计理念: 约定优于配置(Convention over Configuration)
“零配置就能跑” 的设计的是典型体现:model=None、backend 不传时,框架自动补默认值,不用开发者手动配置,只需要设个 ANTHROPIC_API_KEY 就能运行。
这是生产级框架的实用设计,核心是 “减少手动配置,默认约定合理规则”,降低使用门槛,
尼恩提到 “第一次用的时候都惊了:居然能这么简单”,就是被这种设计打动 —— 不用纠结配置细节,专注业务本身。
最后一步:LangChain Agent 创建
装配流水线走完,调 create_agent(...),把模型、工具、中间件、system_prompt 全打进去:
# 真实源码:libs/deepagents/deepagents/graph.py
return create_agent(
model, system_prompt=final_system_prompt, tools=_tools,
middleware=deepagent_middleware, ...
).with_config({
"recursion_limit": 9_999,
"metadata": {
"ls_integration": "deepagents",
"versions": {"deepagents": __version__},
},
})
这一步就是创建了 Super-Agent 实例,之后只能 .invoke() / .stream(),图结构碰都不能碰。
说白了,create_deep_agent 不推理,不调模型,不跑业务逻辑。它就是一条流水线。把车装好,锁死,交钥匙。
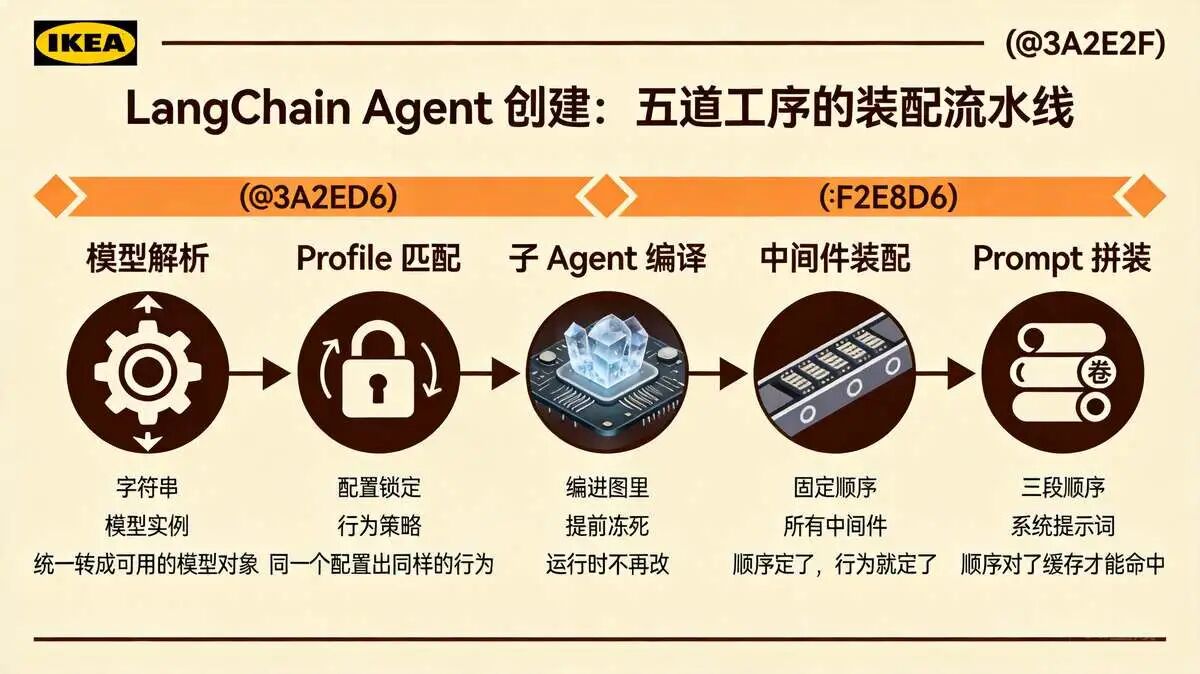
那这条流水线到底串了哪些工序?具体来说,五道:
(1) 模型解析:不管你传字符串还是模型实例,统一转成可用的模型对象
(2) Profile 匹配:根据配置锁定行为策略,同一个配置出同样的行为
(3) 子 Agent 编译:把子 Agent 也编进图里,提前冻死,运行时不再改
(4) 中间件装配:按固定顺序装好所有中间件,顺序定了,行为就定了
(5) Prompt 拼装:把系统提示词按三段顺序拼好,顺序对了缓存才能命中
下面一道一道拆开看。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
二、工序一:模型解析,统一模型入口,换模型不污染业务层
你可能觉得"统一模型入口"这种事太基础,不值一提。
但尼恩翻过不少生产级代码库,模型实例化逻辑散落三四处是常态。
这道工序解决的,就是这个脏活。
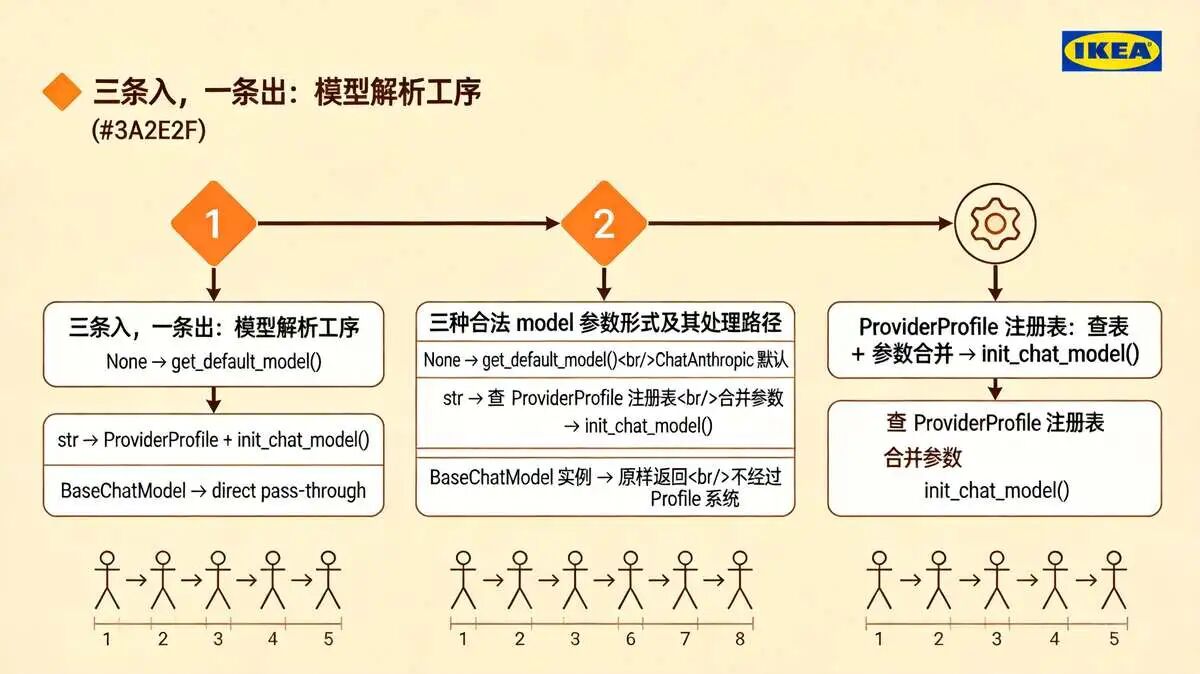
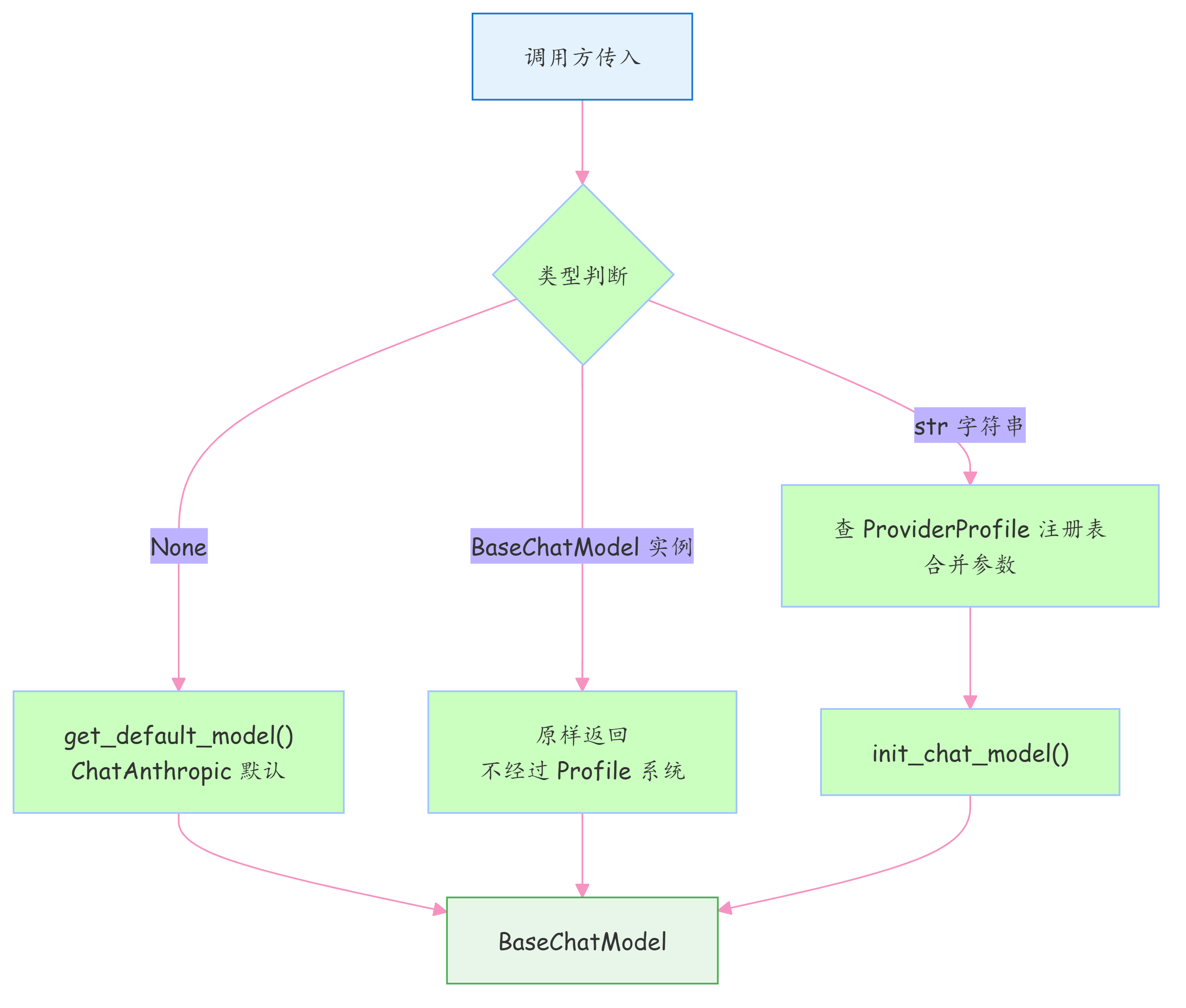
model 参数能接三种形式:None、str 字符串、BaseChatModel 实例。
三种形式,背后是三条完全不同的处理路径。但对外,只有一种输出。
翻译成人话:
(1) 不传 model:框架自己补一个默认的 ChatAnthropic(model_name="claude-sonnet-4-6")。设个 ANTHROPIC_API_KEY 就能跑,约定优于配置
(2) 传字符串:比如 "claude-sonnet-4-6",先查 ProviderProfile 注册表合并参数,再调 init_chat_model() 实例化。这是最复杂的一条路径
(3) 传现成实例:你传什么它用什么,原样返回,不经过任何 Profile 系统
三条入,一条出。后续所有工序只认 BaseChatModel,不关心它是怎么来的。
三、工序二 HarnessProfile——管行为策略,不与模型配置耦合
模型知道用哪个了。
但光知道用哪个不够,还得告诉它"怎么跑"。
用什么 Prompt、禁哪些工具、注入哪些中间件,这些都属于行为策略。
DeepAgents 用 HarnessProfile 来管这一层。
每个模型名可以注册一个 Profile,声明该模型专属的行为边界。
构建流程可以根据模型名查注册表,找到匹配的 Profile,提取 Prompt、工具排除列表、中间件注入等配置。
为什么是两组 Profile,不是一组
有人可能会想:把 ProviderProfile 和 HarnessProfile 合在一起不行吗?少一组注册表,少一层概念。
不行。因为两者变动的触发条件完全不同。
换模型时你只关心模型怎么构建,不管行为策略。调行为时你只关心 Agent 怎么跑,不管模型参数。
两组 Profile 各管各的:换模型只动 ProviderProfile,调行为只动 HarnessProfile,改一个不影响另一个。
这和 Harness 工程方案里 Config 分层加载是同一套逻辑。
配置系统不是读个 YAML 那么简单,它决定 Agent 的行为边界——能用哪个模型、能调用哪些工具、Token 预算是多少、是否需要审批。
四、工序三 : Sub-Agent治理,单层委派与隔离机制
多 Agent 系统最怕什么?子任务互相污染,一个崩了拖垮全局。
Harness 工程里拆过 Multi-Agent Delegation 的三大内核:任务拆解与委派、隔离与独立生命周期、状态追踪与弹性容错。
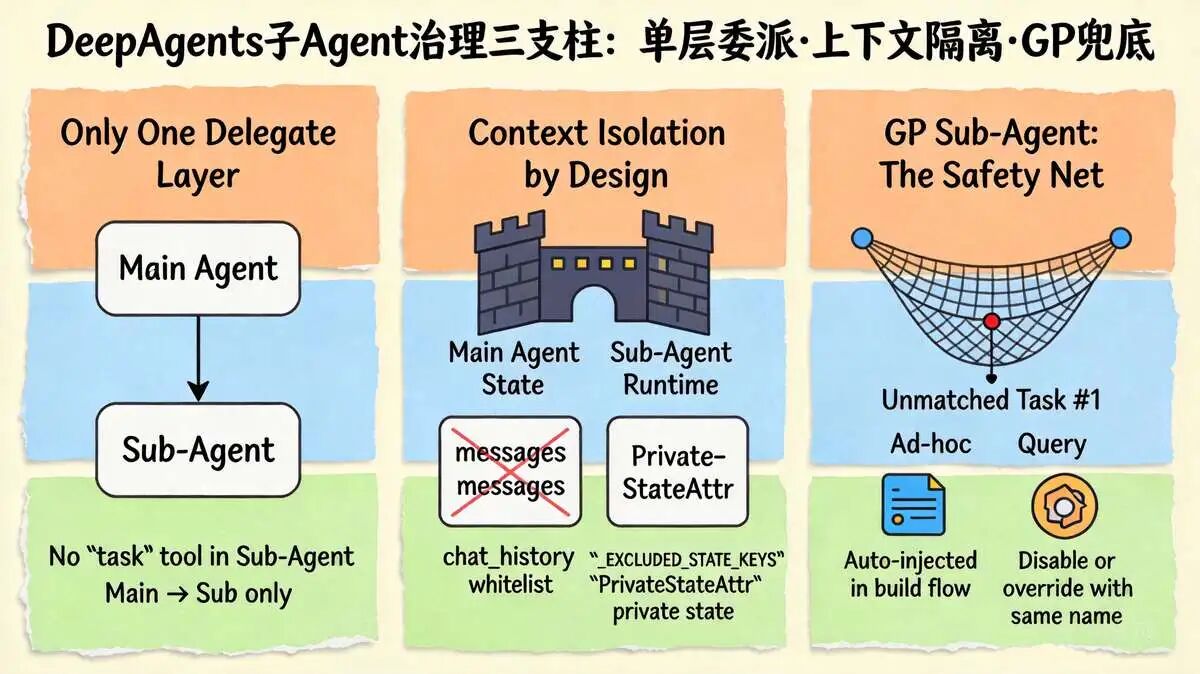
DeepAgents 的子 Agent 治理就是这三个内核在构建期的落地。下面先讲架构设计,再看源码怎么实现。
架构决策一:单层委派,不是级联嵌套
主 Agent 把子任务分给子 Agent,子 Agent 能不能再把活拆开,丢给孙子 Agent?
DeepAgents 的答案是:不行。Sub-Agent 的 task 工具被直接移除。整个体系只有"主 Agent → 子 Agent"这一层委派关系。
为什么要这么设计?尼恩以前跟团队折腾过递归嵌套的方案,深度一失控就是灾难。上下文窗口被套娃撑爆,内存泄漏查得人头秃。一个子 Agent 卡死,它下面的孙子、曾孙全跟着卡死,排查的时候看日志就像看蜂窝。
单层委派的本质不是约束,是保命。 Super-Agent 和 Sub-Agent 之间只有一层,资源消耗可控,调试路径直线。对主 Agent 来说,调 task 跟调 read_file 没区别,统一的工具调用接口,不搞特殊通道。
架构决策二:上下文隔离,各跑各的
每个子 Agent 启动时只拿到一条 HumanMessage,内容就是 task 工具传进来的任务描述。
主 Agent 的完整对话历史、其他子任务的中间产出、用户最初的聊天上下文,全被挡在门外。
怎么做到的?两道机制。
_EXCLUDED_STATE_KEYS白名单规定哪些主 Agent 状态不能传给子 Agent。PrivateStateAttr允许子 Agent 拥有主 Agent 不可见的私有状态。- 两边隔离,一个崩了不会拖垮另一个。
隔离听上去像信息丢失,其实恰恰相反。让子 Agent 去搜 Python 异步最佳实践,它真需要知道用户之前问没问过天气,或者另一个子 Agent 在不在编译代码吗?不需要。这些杂音只会挤占上下文窗口,冲淡核心指令。
这就逼着 Lead Agent 给子 Agent 的任务 prompt 必须自包含:不依赖历史对话,不依赖其他子任务产出,不依赖之前聊过什么。
要做什么、有什么约束、格式怎么要求、参考什么规则,一次性全塞进一条 prompt 里。
架构决策三:GP Sub-Agent 兜底,不让任何任务裸奔
生产环境总有杂活是现有专业子 Agent 不匹配的,有一默认的通用子 Agent,消化这些杂项任务。
这些活儿堆在主 Agent 的上下文里硬扛,工具越调越多,上下文越来越脏,最后不是 Token 耗尽就是死循环。
所以 DeepAgents 在构建流程里自动塞了一个 通用Sub-Agent(General Purpose),专门消化这些杂项任务。
调用方可以显式关掉,也可以自己定义一个同名子 Agent 覆盖默认。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
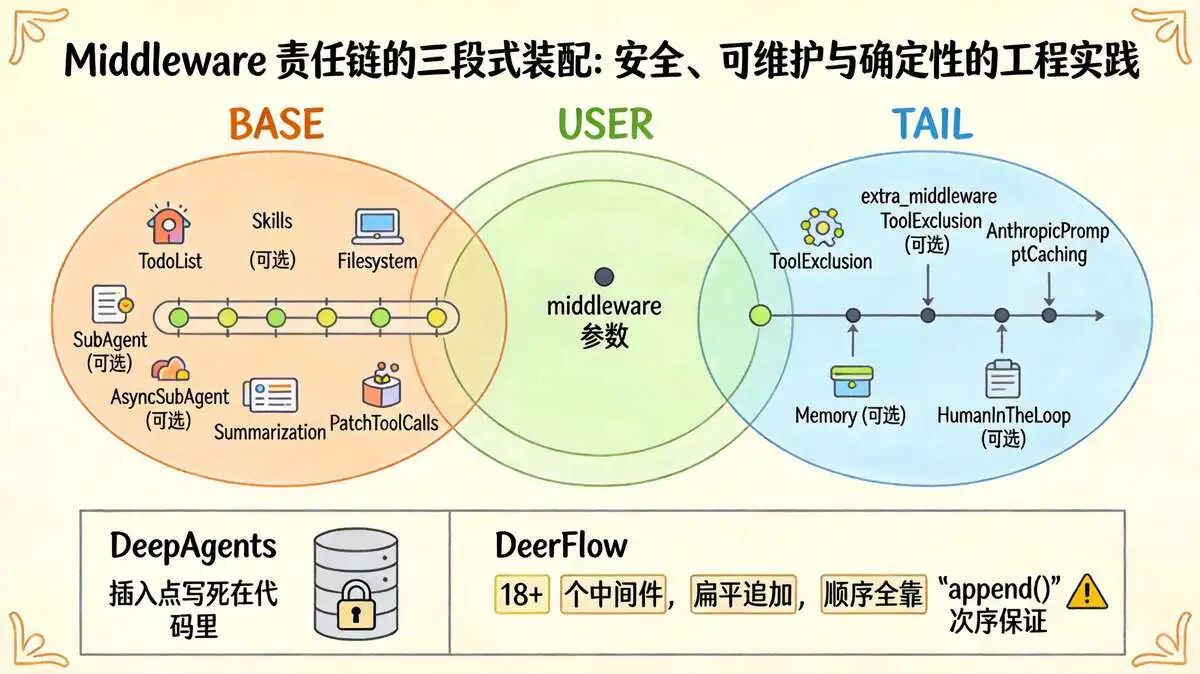
五、工序四:middleware 责任链的 三段式装配
这是 AI Agent 构建流程中最核心、容错率最低的关键工序。
中间件的执行顺序绝非随意编排,一旦顺序错乱,会直接引发缓存雪崩、权限绕过、审批失效等生产级严重故障。
先明确核心概念:
Agent Loop 每一轮执行「模型推理→工具调用→结果回传」,如同一条标准化流水线;中间件就是流水线上的固定工位,负责拦截请求 / 响应,完成上下文注入、工具裁剪、权限校验等治理逻辑,再传递给下一个节点。
所有中间件串联成管道,执行顺序直接决定治理逻辑的生效顺序。
middleware 是 Langgraph 洋葱模式责任链
langchain_core.runnables.middleware 是 LangChain 实现洋葱模式责任链的核心,替代了早期 AgentMiddleware,为模型、Agent、链式任务提供统一的拦截增强能力。
1. 标准执行流程
用户输入 → 中间件栈 → AI模型 → 响应输出
2 中间件四大拦截节点
中间件可在 Agent 生命周期的四个关键阶段介入:
before_model:模型调用前执行,用于输入预处理、文本格式化;wrap_model_call:包裹模型调用,动态修改工具列表、模型参数;wrap_tool_call:拦截工具调用,实现权限校验、参数合法性检查;after_model:模型返回后执行,用于输出校验、安全过滤。
3 多中间件执行顺序(洋葱模式:先进后出)
# 定义三个中间件
agent = create_agent(
model="gpt-4o",
middleware=[middleware1, middleware2, middleware3],
tools=[...]
)
完整执行顺序:
(1) 启动前:middleware1 → 2 → 3 执行before_agent()
(2) 调模前:middleware1 → 2 → 3 执行before_model()
(3) 调用模型:1→2→3 嵌套执行wrap_model_call(),最终调用模型
(4) 调模后:3 → 2 → 1 逆序执行after_model()
(5) 结束后:3 → 2 → 1 逆序执行after_agent()
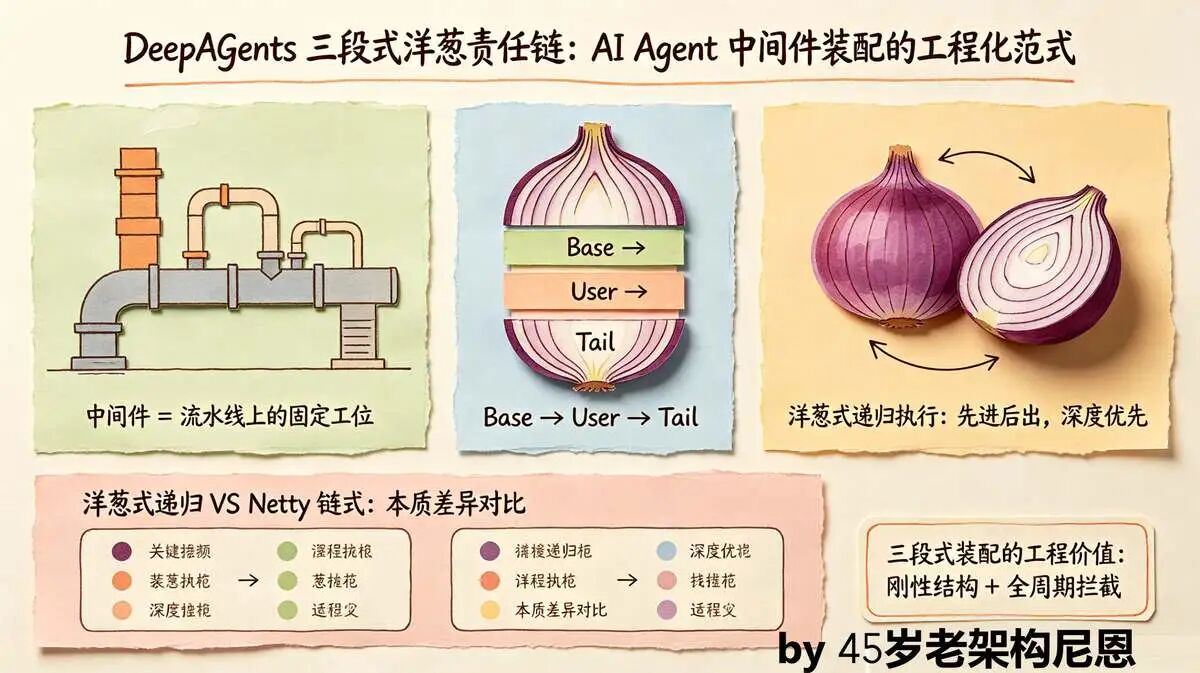
DeepAgents 设计:三段式装配 + 洋葱式递归
DeepAgents 结合三段刚性结构与洋葱递归执行,兼顾稳定性与拦截能力:
三段式装配伪代码
def process_request(request):
# 1. Base段:框架基础治理(最先执行)
for middleware in base_middlewares:
request = middleware.process(request)
# 2. User段:用户自定义逻辑(中间执行)
for middleware in user_middlewares:
request = middleware.process(request)
# 3. Tail段:缓存、记忆、审批(最后执行)
for middleware in tail_middlewares:
request = middleware.process(request)
# 核心Agent逻辑
return core_agent_process(request)
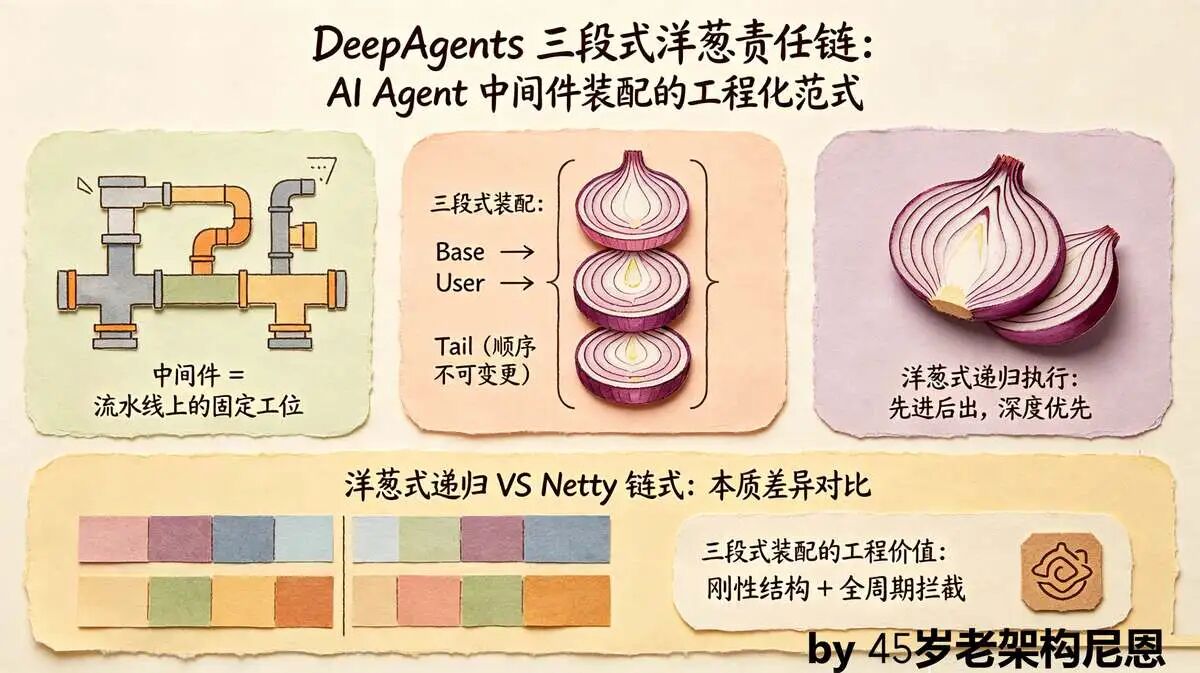
DeepAgents 三段式装配:职责与执行流程
DeepAgents 将中间件强制划分为Base 基础段、User 自定义段、Tail 收尾段,三段顺序不可变更,每一段各司其职:
三段核心职责
(1) Base 段(框架内置,必选)
框架底层治理中间件,包含 TodoList、文件系统、子代理、摘要、工具调用补丁等,是 Agent 运行的基础能力。
(2) User 段(用户自定义,可选)
调用方通过参数传入的个性化中间件,用于业务定制化逻辑,插入位置固定在 Base 与 Tail 之间。
(3) Tail 段(框架内置,必选)
最终治理中间件,负责缓存、记忆、人工审批等收尾逻辑,是请求处理的最后一道关卡。
洋葱式递归 VS Netty 链式
| 特性 | 洋葱式递归责任链 | Netty 链式责任链 |
|---|---|---|
| 处理逻辑 | 深度优先递归,先进后出 | 线性传递,先进先出 |
| 执行顺序 | 请求:A→B→C→处理→C→B→A(逆序收尾) | 请求:A→B→C→处理(无逆序) |
| 代码实现 | 递归 + next () 传递 | 线性遍历 + 显式调用下一个处理器 |
| 代表框架 | Koa、Express、LangChain | Netty、Spring AOP |
| 适用场景 | Web 中间件、Agent 拦截器 | 网络协议栈、数据流处理 |
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
六、工序五: 提示词工程 Prompt 三段拼装
很多人将 Prompt 组装简单视为字符串拼接,顺序似乎无关紧要。
但在 Harness 这类追求性能与成本优化的架构中,Prompt 的组装逻辑直接决定了 Claude 等大模型 Prompt Cache 的命中率——逻辑错了,Token 消耗和响应延迟会显著增加。
核心理念:动静态内容必须分离
优化缓存的核心前提是保持 system prompt的完全静态。
Claude 等大模型 的 Prompt Cache 机制基于 system prompt的哈希值。只要它不变,缓存就能命中,后续计算成本大幅降低。
因此,任何动态的、每次请求都可能变化的内容,绝不能混入 system prompt。
这引出了 Harness 架构中 Prompt 组装的黄金法则:静态行为定义归于 System Prompt,动态任务指令归于 User Message。
静态 System Prompt 的构建:BASE + SUFFIX
最终的 system prompt由两部分静态内容构成:
| 段 | 内容 | 性质 | 目的与说明 |
|---|---|---|---|
| BASE | SDK 行为纪律 | 静态核心 | 定义智能体的核心行为范式,在应用构建期确定后冻结不变。 |
| SUFFIX | 模型调优后缀 | 静态调优 | 提供最终的行为调优指令,置于末尾以最大化效力。 |
顺序固定为 BASE → SUFFIX。 这个顺序基于两个原因:
(1) 缓存稳定性:BASE作为恒定前缀,确保了 system prompt哈希值的稳定性,是缓存命中的基石。
(2) 指令效力:研究表明,模型对 system prompt末尾的内容关注度最高。将最重要的调优指令(SUFFIX)放在最接近后续对话历史的位置,能使其发挥最大效力。
其中,BASE段定义了四条不可篡改的工程纪律,将开发共识编译为底层契约:
| 纪律 | 核心含义 |
|---|---|
| 核心行为 | 回应简洁直接;遇歧义先澄清;对“怎么做”类问题,遵循“先解释后执行”。 |
| 专业客观 | 准确性优先;敢于并礼貌地纠正错误;避免不必要的情感化表达。 |
| 任务流控制 | 遵循“理解→实现→验证”流程;长任务拆分迭代;失败时先分析原因再重试;仅在真实阻塞时移交人类。 |
| 进度同步 | 执行长任务时必须主动同步进度(已完成什么、下一步做什么)。 |
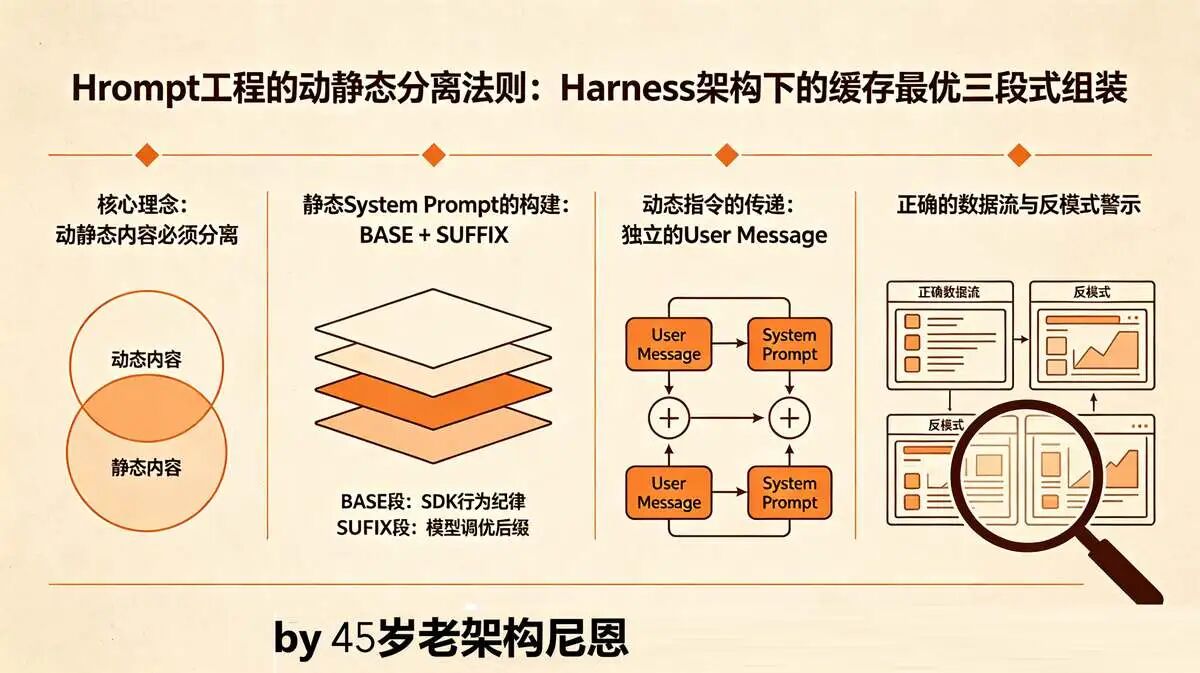
动态指令的传递:独立的 User Message
每次请求中变化的用户指令、上下文或具体问题,应作为独立的 user message 发送。
这对应了原文中“USER”段的概念,但它的正确位置不是在 system prompt里,而是在其之后。
正确的数据流结构如下:
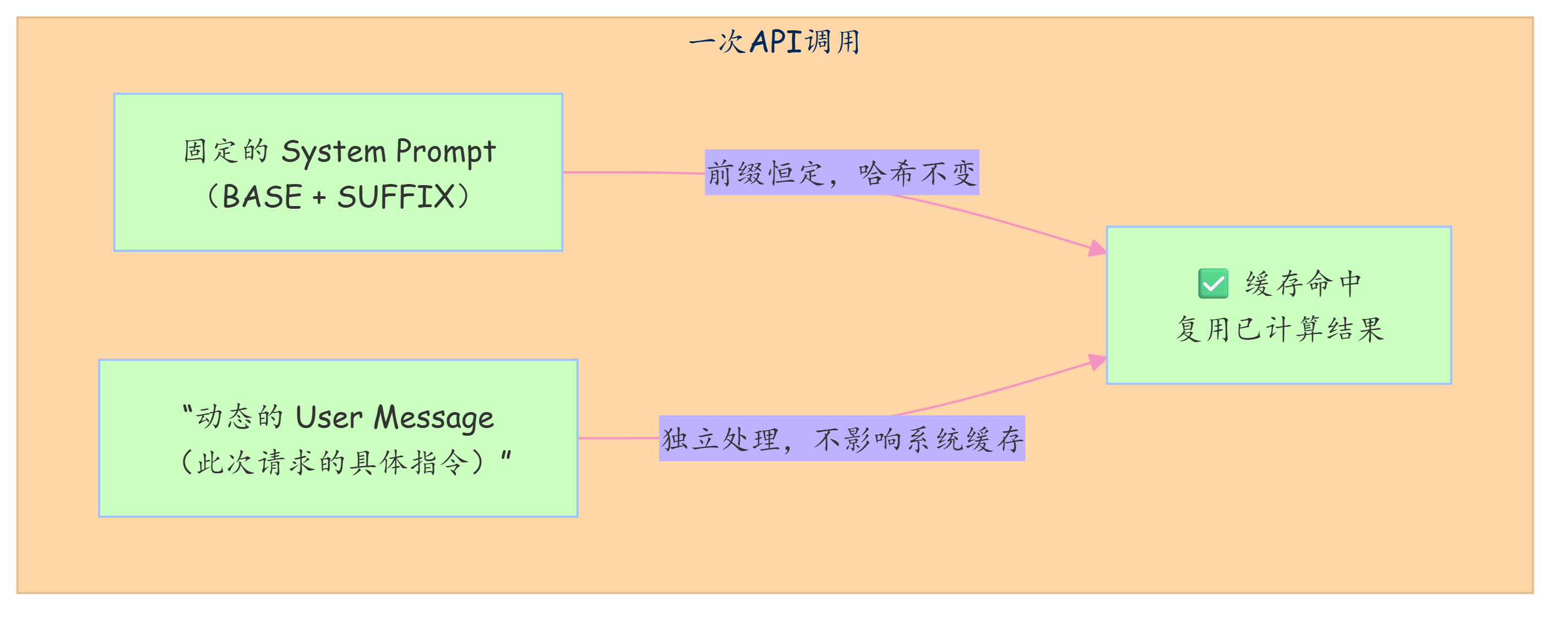
正确的 Prompt 工程不是简单的三段拼装,而是严谨的动静态分离。
将静态的行为契约(BASE+SUFFIX)固化到 system prompt中以最大化缓存效益,同时将动态的任务指令(USER)通过 user message传递以实现灵活性,是兼顾性能、成本与控制力的唯一正确路径。
任何将动态内容前置到 system prompt的方案,都会直接破坏缓存机制,导致目标与结果的背离。
七、创建 Super-Agent:LangGraph接管运行期
前面五道工序,模型选好了、中间件排好了、工具裁好了、Prompt 拼好了。
但这些都是散件,还没锁死。
最后一步:调 create_agent(),把所有散件锁进一个不可变的 CompiledStateGraph 里。
# 真实源码:libs/deepagents/deepagents/graph.py
return create_agent(
model, system_prompt=final_system_prompt, tools=_tools,
middleware=deepagent_middleware, ...
).with_config({
"recursion_limit": 9_999,
"metadata": {
"ls_integration": "deepagents",
"versions": {"deepagents": __version__},
},
})
这一调用完,构建期就彻底结束了。之前所有决策全部冻住——中间件顺序不可改、工具列表不可改、权限规则不可改、Profile 快照不可改。
之后就是 LangGraph 运行时接管:Agent Loop、工具调度、状态更新、流式输出,DeepAgents 不再介入。
有人看到 recursion_limit: 9999 会问:这么大的数字,不是放任模型无限循环吗?
不是。9999 只是兜底的硬上限,防止极端情况下的死循环把进程卡死。
真正的循环退出不靠这个数字,靠中间件按业务逻辑控制:
SummarizationMiddleware在上下文快溢出时触发摘要压缩,把对话缩短;PatchToolCallsMiddleware检测到无效工具调用直接截断,不让模型在死胡同里绕。
交付这一刻,Harness 工程方案里的六大闭环同时落地。
前面各道工序已经把状态闭环、行动闭环、经验闭环锁死了,交付点最后闭合行为闭环、输入闭环和质量闭环。
八、小结:构建期定死一切决策
Super-Agent 的设计理念就一句话:构建期把所有决策定死,运行期不许改。
五道工序就是五次决策:
- 模型选哪个,构建期定
- Prompt 拼什么、工具裁哪些、中间件排什么顺序,构建期定
- 子 Agent 能看什么、能干什么,构建期定
最后交给 LangGraph,运行期只剩一条确定性链路在跑。
分层架构、依赖倒置两大经典思维,贯穿始终;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)