NeurIPS 2025 (ML4PS) | RPI Ling Yue(岳凌)、Shaowu Pan(潘韶武)等:FoamGPT:基于微调大语言模型的OpenFOAM计算流体力学仿真自动化
FoamGPT从数据提取、监督微调到通过Foam-Agent智能体框架落地执行,形成了一条完整的技术闭环。研究结果表明,专业领域数据的质量与对齐程度,对提升大模型在CFD任务中的实用能力具有较大影响,在本评测集的对比条件下,其效果更为明显。该工作有望降低CFD仿真对非流体专业研究人员的使用门槛,同时也为科学仿真自动化领域的后续研究提供了可复用的数据与微调代码基础。相关数据集与训练代码已完整开源,供
FoamGPT:基于微调大语言模型的OpenFOAM计算流体力学仿真自动化
FoamGPT: Fine-Tuning Large Language Model for Agentic Automation of CFD Simulations with OpenFOAM
Ling Yue(岳凌)1, Peijing Xu1, Tingwen Zhang1, Nithin Somasekharan1, Shaowu Pan(潘韶武)1,*
1.Rensselaer Polytechnic Institute, Troy, NY 12180, USA

引用格式:
Yue L, Xu P, Zhang T, et al. FoamGPT: Fine-Tuning Large Language Model for Agentic Automation of CFD Simulations with OpenFOAM[J]. NeurIPS 2025 (ML4PS).
导读:
本文针对CFD仿真自动化中数据稀缺、物理多样性不足的问题,构建了首个包含202组OpenFOAM案例的高质量自然语言-配置对齐数据集,覆盖多种几何形态与物理规范。基于该数据集,研究团队通过LoRA对Qwen2.5-7B进行微调,得到FoamGPT模型,在CFDLLMBench基准测试中以22.73%的执行成功率超越AutoCFD(20.91%),而后者所用训练数据量约为本文的150倍。在本文的对比实验条件下,结果初步表明,专业领域内的高质量对齐数据对提升大模型CFD配置生成能力的效果,优于以数据规模为导向的通用语料训练,但其在更广泛场景下的适用性有待进一步验证。
1. 研究背景
计算流体力学(Computational Fluid Dynamics, CFD)在航空航天、绿色能源等众多工程领域有着广泛应用,OpenFOAM 作为其中使用者最多的开源平台,积累了大量官方案例与求解器配置规范。然而,该平台基于文本命令行的配置工作流语法复杂、约束严格,对流体力学背景以外的研究人员构成较高的使用门槛。
随着大语言模型(LLM)在通用代码生成方面能力的提升,研究者希望借助自然语言描述替代繁琐的手动配置输入。但在CFD领域,这一方向长期受制于高质量训练数据的匮乏。以AutoCFD的先驱工作NL2FOAM为例,其训练集仅涵盖16个简单场景,导致微调后的模型泛化能力有限,在面对复杂热多相或刚体运动耦合等真实仿真需求时表现不稳定。构建一个覆盖多样物理场景、与物理语义对齐的专用数据集,是推动该方向发展的必要前提。
2. 方法论:三阶段数据流水线与模型微调
本文的核心贡献在于一套完整的结构化数据提取与对齐流水线,系统地将202个OpenFOAM官方校准案例(涵盖多种湍流模型结构与网格动态机制)转化为自然语言描述与配置文件的对应训练样本。
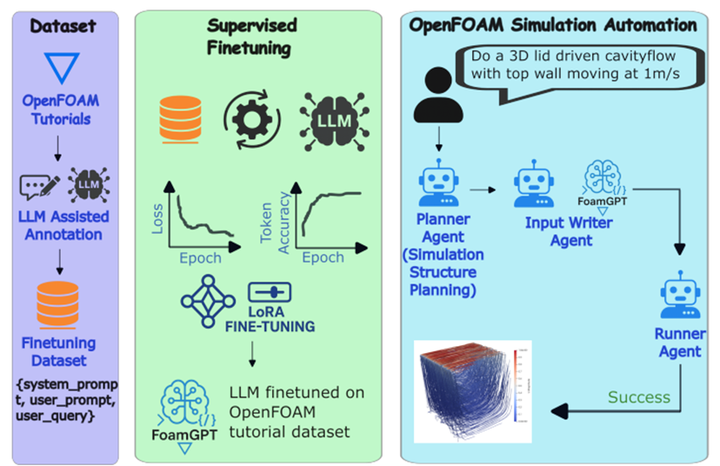
整个数据处理流程分为三个阶段:
(1)解析阶段(Parsing Phase):系统自动遍历OpenFOAM案例目录,过滤冗余注释,提取每个案例所依赖的求解器类型(Solver)、仿真域坐标系等关键元数据,形成结构化骨架信息。
(2)逆向合成阶段(Reverse Synthesizing):针对”只有答案、没有题目”的数据特点,研究团队调用前沿推理模型(本文采用Claude Sonnet架构)作为教师模型,从专业配置文件中逆推工程师在实际求解时可能提出的自然语言需求描述(User Query)。所有生成结果经人工研究员核验,确保语义准确、无歧义。
(3)提示词重写阶段(Instruction Prompting):针对大模型在多智能体框架中的实际调用场景,将用户需求与动态提取的物理条件参数联合输入,并明确指定当前待生成的配置模块。在此基础上,研究团队采用LoRA低秩自适应技术对基础模型进行监督微调,在保留通用语言能力的同时,使模型掌握OpenFOAM字典键值语法,最终得到FoamGPT。
3. 实验结果与分析
研究者在CFDLLMBench评估平台上对模型进行测试,该平台包含110个独立仿真场景,覆盖化学反应、相变、多相耦合等11类物理问题。为保证测试条件单一,评估过程中关闭了多智能体工作流中的错误检测与修复组件,直接衡量模型在”一次生成即可执行”意义下的执行成功率(Execution Success Rate)。
测试结果显示:未经微调的Qwen2.5-7B基础模型执行成功率为0.00%;经本文约200条数据微调后的FoamGPT,执行成功率达到22.73%。作为对比,AutoCFD使用了约30,000条原始非规范语料(约为本文训练数据量的150倍),并借助辅助模型对输出格式进行后处理纠错,最终执行成功率为20.91%,仍低于FoamGPT。
这一结果说明,在专业CFD配置生成任务中,在本评测集上,高质量、专业对齐的少量数据的微调效果,优于以数据规模为主的通用语料训练。
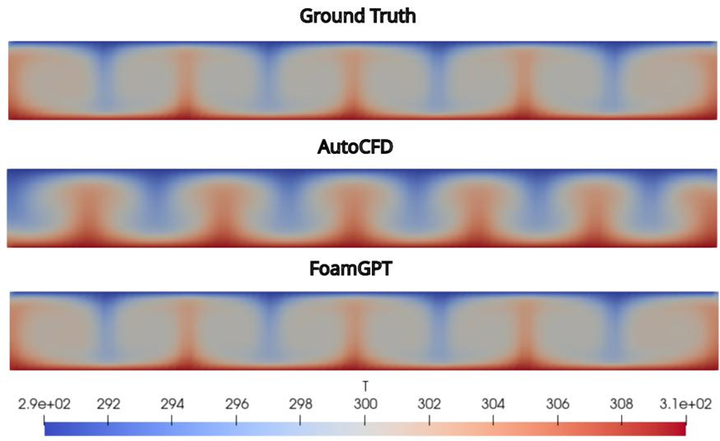
此外,本文数据集表现出一定的通用性:无论是基于Llama 3.1的8B参数模型,还是通过API调用的GPT-4.1 Mini,经本流程数据微调后,执行成功率均有不同程度的提升,部分基座模型在所测试条件下接近40%,初步表明该数据集在不同基座模型上具备一定的迁移性。下图中热交换案例直观展示了两者的配置质量差异:
总结
FoamGPT从数据提取、监督微调到通过Foam-Agent智能体框架落地执行,形成了一条完整的技术闭环。研究结果表明,专业领域数据的质量与对齐程度,对提升大模型在CFD任务中的实用能力具有较大影响,在本评测集的对比条件下,其效果更为明显。该工作有望降低CFD仿真对非流体专业研究人员的使用门槛,同时也为科学仿真自动化领域的后续研究提供了可复用的数据与微调代码基础。相关数据集与训练代码已完整开源,供社区进一步探索与扩展。
公众号原文链接(附论文资源):
https://mp.weixin.qq.com/s/b-xdDkxth_gO4KyAJ3QycA
注:文章由原作者投稿分享,向本公众号授权发布。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)