大力出奇迹的背后:OpenAI找到了炼丹的物理定律
幂律说的是这么回事:当你把某个变量乘以 k 倍,结果会以 k 的某个固定次方的比例变化。用公式写就是 L ∝ x^{-α}。翻译成人话:你每把参数量翻10倍,loss 就会下降一个可预测的固定比例。不是一个大概的趋势,而是一条在对数坐标上近乎完美的直线。这意味着什么?意味着你可以提前预测一个更大的模型会有多好。在它还没训练完之前,你就知道结果。这对于一个动辄花几百万美元训练模型的公司来说,价值不言


如果你从2020年开始关注大模型,你一定听过一句话:「大力出奇迹」。把模型做大、数据做多、算力堆够,效果就是会变好。这句话听起来像玄学,但 OpenAI 在2020年发了一篇论文,告诉全世界:这不是玄学,这是物理学。
这就是今天要聊的 Scaling Laws for Neural Language Models,Jared Kaplan 领衔,OpenAI 出品。这篇论文发现了一条简洁到令人震惊的规律——模型的 loss 和三个因素之间,遵循精确的幂律(power law)关系。
什么是幂律?为什么它重要?
幂律说的是这么回事:当你把某个变量乘以 k 倍,结果会以 k 的某个固定次方的比例变化。用公式写就是 L ∝ x^{-α}。
翻译成人话:你每把参数量翻10倍,loss 就会下降一个可预测的固定比例。不是一个大概的趋势,而是一条在对数坐标上近乎完美的直线。
这意味着什么?意味着你可以提前预测一个更大的模型会有多好。在它还没训练完之前,你就知道结果。这对于一个动辄花几百万美元训练模型的公司来说,价值不言而喻。
三个变量,三条曲线
论文的核心发现是,语言模型的 cross-entropy loss 受三个因素影响,而且每个都独立地服从幂律:
第一,模型参数量(N)。参数越多,loss 越低。这条曲线非常平滑,几乎没有噪声。你可以想象成一条从左上到右下的完美直线(对数坐标下)。
第二,数据集大小(D)。训练数据越多,loss 也越低,同样遵循幂律。更多数据的效果是高度可预测的。
第三,计算量(C)。你总共花了多少 FLOPs,跟最终 loss 之间也是幂律关系。花更多的钱(算力),得到更好的模型,而且好多少是可以算出来的。
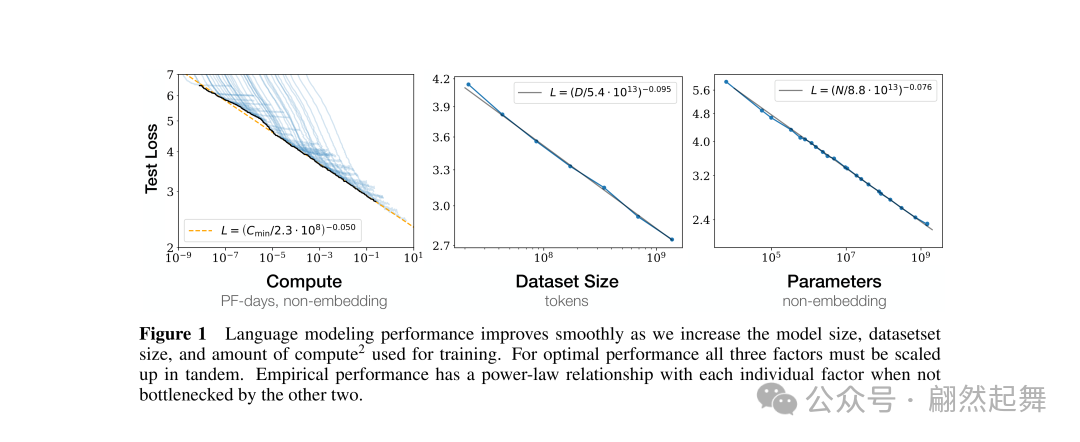
loss 随参数量、数据量、计算量的幂律变化曲线,在对数坐标下呈现出惊人的线性关系(来源:原论文Figure 1)
最反直觉的发现:架构不重要
这篇论文里最让人意外的结论之一:模型的架构细节,远没有你想的那么重要。
层数、宽度、注意力头数、残差连接的方式——这些我们在论文里吵来吵去的设计选择,在大尺度上几乎被「参数总量」这一个数字吸收了。两个参数量相同的模型,只要架构不脱离合理范围,不管内部具体怎么设计,最终的 loss 差不多。
打个比方:你盖一栋楼,是用红砖还是灰砖,窗户开圆的还是方的,这些「架构」选择对楼的高度影响不大。真正决定楼有多高的,是你用了多少材料(参数量)。
这个发现直接给了整个领域一记重锤——别折腾架构了,堆参数就完了。
大模型 vs 长训练:怎么选?
论文的另一个关键结论同样有实用价值:在固定算力预算下,训练一个更大的模型,比把小模型训练更久要划算得多。
具体来说,如果你的预算是固定的,想要最好的效果,正确的策略是:增大模型参数量,同时减少训练步数(early stop)。一个10倍大的模型训练到收敛前的某个时间点,效果会好于把原来那个小模型训练10倍长的时间。
这个发现直接影响了后来 GPT-3 的设计决策——超大模型,适度的训练时长。而不是搞一个小模型,训练到天荒地老。
幂律的阴暗面
幂律虽然简洁优美,但它也藏着一个让人焦虑的事实:边际收益递减。
因为 loss 的下降是 x 的负指数,所以你每次想获得同样幅度的 loss 提升,需要的投入是指数级增长的。从 1B 到 10B 参数,loss 可能降了 0.1;但从 10B 到 100B,同样的 0.1 降幅可能需要更多的资源。
换句话说,前 80 分的提升花 20 块钱,后 20 分的提升可能要花 80 块。这就解释了为什么顶级模型的训练成本从百万美元飙升到上亿美元——想要那最后几个百分点的提升,代价是惊人的。
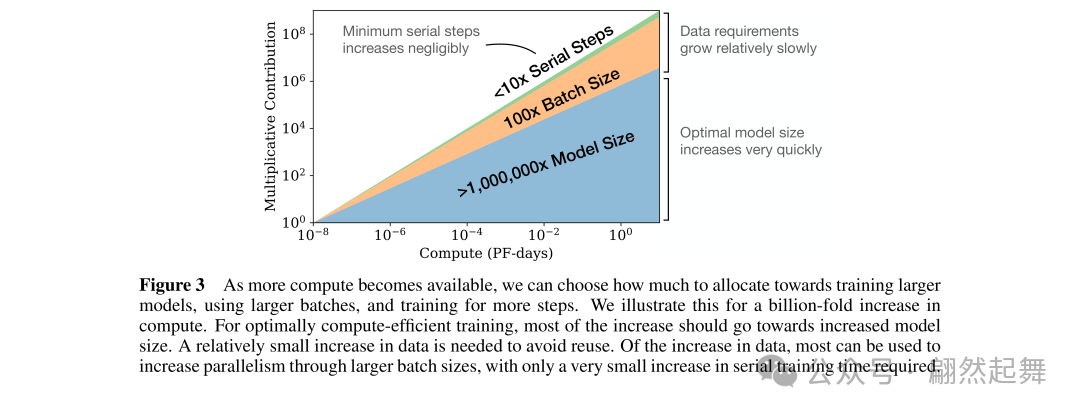
在固定计算预算下,参数量与训练步数的最优分配关系(来源:原论文Figure 3)
为什么这篇论文改变了一切?
Scaling Laws 的意义远不止学术发现。它实际上成了大模型军备竞赛的理论基石。
在它之前,做大模型是一种赌注——谁知道堆参数是不是真的有用?在它之后,做大模型变成了一种可预测的投资。你花多少钱,就能预期得到多好的模型。这让 Google、Meta、百度、字节这些公司敢于砸几十上百亿美元去训练下一代模型。
回头看,Scaling Laws 几乎预言了后来发生的一切:GPT-3 的 1750 亿参数、PaLM 的 5400 亿参数、GPT-4 的(据传)万亿级参数。每一步都在验证 Kaplan 画出的那条直线。
做工程的我们都知道,一个领域从「靠经验」走向「有理论指导」,意味着什么。Scaling Laws 就是把大模型训练从炼丹术变成了工程学。你不用再靠直觉决定模型多大,而是拿公式算出来。
当然,后来 Chinchilla 的研究者发现 OpenAI 对数据量的幂律指数估计偏保守了——数据其实比 Scaling Laws 原文认为的更重要。但那是另一篇论文的故事了。
论文链接:https://arxiv.org/abs/2001.08361
kk的大模型论文学习笔记 · 第6篇 · Scaling Laws

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)