大模型微调
本文介绍了大语言模型的两种微调方法:全参数微调和参数高效微调(PEFT)。全参数微调更新所有参数但资源消耗大,而PEFT方法如LoRA和QLoRA通过低秩分解和量化技术显著降低计算成本。重点阐述了LoRA的原理,通过分解增量矩阵为低秩乘积,仅训练少量参数;QLoRA进一步引入4-bit量化和分页优化器,使微调可在消费级GPU上运行。最后介绍了LLaMA-Factory工具的使用方法,包括安装依赖和
第 1 章 微调方法选择
根据是否更新模型全部参数,监督微调(SFT)的方法可分为两类:
- 全参数微调(Full Fine-tuning)
- 参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
**1.1 **全参数微调
全参数微调是一种在微调过程中更新模型全部参数的方法。它能最大限度地适配目标任务,通常获得最优性能。
但由于大语言模型参数量庞大(数十亿至数千亿),全参数微调对显存、算力和训练时间要求极高,单设备通常无法承载模型参数、优化器状态与激活值,必须依赖分布式训练技术才能实施。
因此,全参数微调适用于资源充足、对性能要求严苛、且拥有高质量标注数据的场景。在实际应用中,常作为参数高效微调无法满足需求时的高成本备选方案。
1.2 参数高效微调
**1.2.1 **概述
参数高效微调(Parameter-Efficient Fine-tuning, PEFT)是一系列微调方法,其核心思想是仅更新少量参数或引入少量可训练模块,在显著降低资源消耗的同时,高效适配目标任务。目前,最先进的PEFT方法已经能实现与全参微调相当的性能。
PEFT 的兴起可追溯至 2019 年前后。当时以 BERT、GPT-2 为代表的预训练模型规模迅速扩大,传统全参数微调的资源成本逐渐难以承受。伴随模型规模持续膨胀,这种矛盾愈发凸显,由此推动了 PEFT 技术的快速发展,形成了包括 Prompt Tuning、Prefix Tuning、P-Tuning、Adapter、LoRA 等多条技术路线,如下图所示:
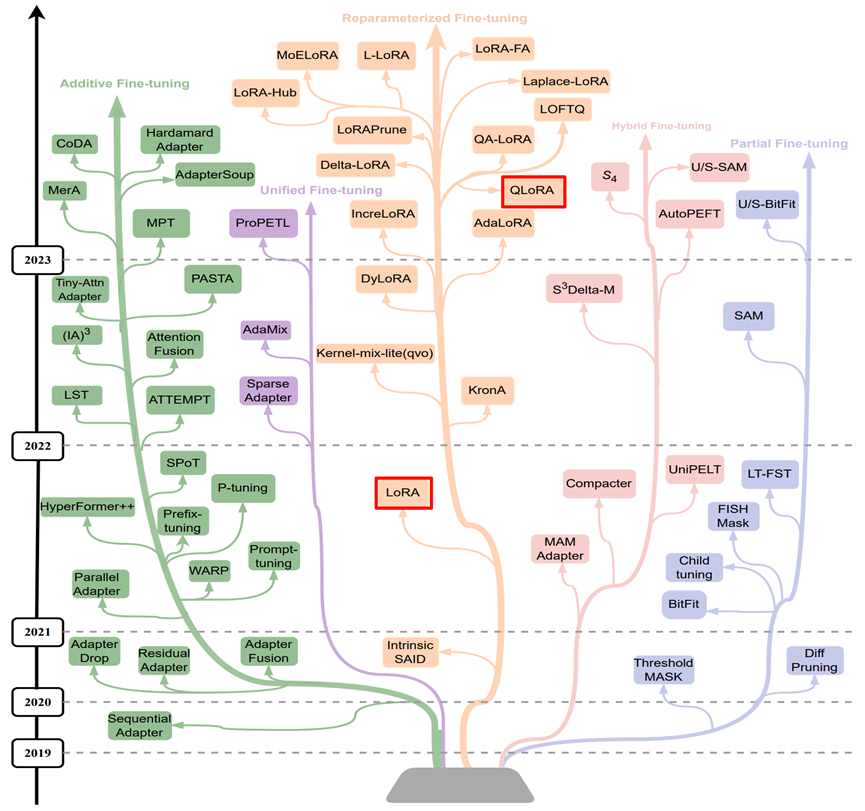
在众多方法中,LoRA(Low-Rank Adaptation)因其结构简洁、训练高效、稳定,已成为当前大语言模型监督微调(SFT)的主流选择;其量化版本 QLoRA (Quantized Low-Rank Adaptation)进一步融合量化技术,将微调门槛降至消费级 GPU 也可运行的水平。相比之下,其他 PEFT 方法因在效率、稳定性或通用性等方面存在局限,已逐渐边缘化。
**1.2.2 **LoRA
**1)**概述
LoRA(Low-Rank Adaptation)是一种高效且广泛使用的参数高效微调方法,由微软研究院于 2021 年提出。因其训练成本低、适配能力强、推理无额外开销等优势,已成为当前大语言模型监督微调(SFT)中最广泛使用的技术。
**2)**原理
在传统的全参数微调(Full Fine-tuning)中,模型中的某个参数矩阵会在训练过程中被更新为W_0:
W = W 0 + Δ W W=W_0+ΔW W=W0+ΔW
其中ΔW是微调阶段需要学习的完整增量矩阵。
LoRA 的作者在实践中观察到:ΔW 往往具有低秩结构,也就是说它的有效自由度远低于其表面维度。基于这一关键现象,LoRA 将 ΔW 近似分解为两个低秩矩阵的乘积:
Δ W ≈ A B , A ∈ R d × r , B ∈ R r × k ΔW≈AB,A \in R^{d\times r},B \in R^{r\times k} ΔW≈AB,A∈Rd×r,B∈Rr×k
其中 r << min(d,k) ,通常取 4、8 或 16 等远小于原始维度的数值。这样,微调后的权重矩阵可写为:
W = W 0 + A B W=W_0+AB W=W0+AB
如下图所示:
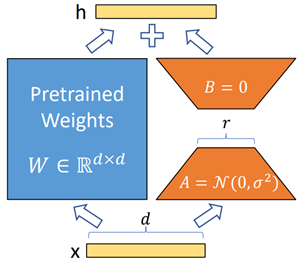
在训练过程中,LoRA 完全冻结原始权重 W_0 ,仅对新增的低秩矩阵 A 和 B 进行优化。这大幅减少了需要更新的参数量,同时也避免了对大规模模型权重的直接修改,使微调过程更加轻量、高效。
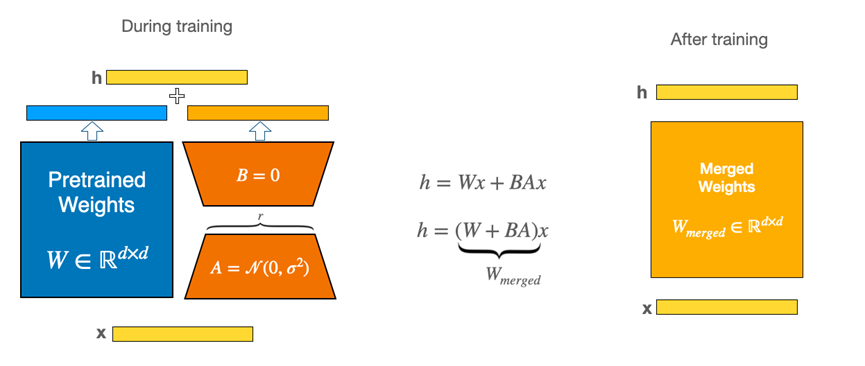
在推理阶段,低秩增量可以无缝合并回原始权重 W_0 中,不会引入额外的计算复杂度,因此 LoRA 的高效性不仅体现在训练中,也体现在推理过程中。如下图所示:
由于秩 r 很小,LoRA 的参数开销和计算成本都极低。例如,对 d=k=4096 的权重矩阵进行全参数更新需要约 16M 个参数,而采用 LoRA(如 r=8)时,仅需:
4096 × 8 + 8 × 4096 = 65536 4096\times 8+8\times 4096=65536 4096×8+8×4096=65536
个参数,占原始权重的仅约 0.4%。这种数量级的压缩使得在有限资源下微调大模型成为可能,也使得在多个任务之间共享底层模型、仅保存轻量级 LoRA 适配器成为现实。
**1.2.3 QloRA
**1)**概述
QLoRA(Quantized Low-Rank Adaptation)是 LoRA 的量化增强版本,由华盛顿大学和微软研究院于 2023 年提出。QLoRA 在 LoRA 的基础上引入 4-bit 量化技术,在几乎不损失性能的前提下,将大语言模型微调的硬件门槛大幅降低,使得数十亿参数级别的模型可在单张消费级 GPU(如 RTX 3090/4090)上完成高效微调。
**2)**原理
QLoRA 的核心思想是:先对预训练模型权重进行 4-bit 量化以压缩显存占用,再在其上应用 LoRA 进行参数高效微调。
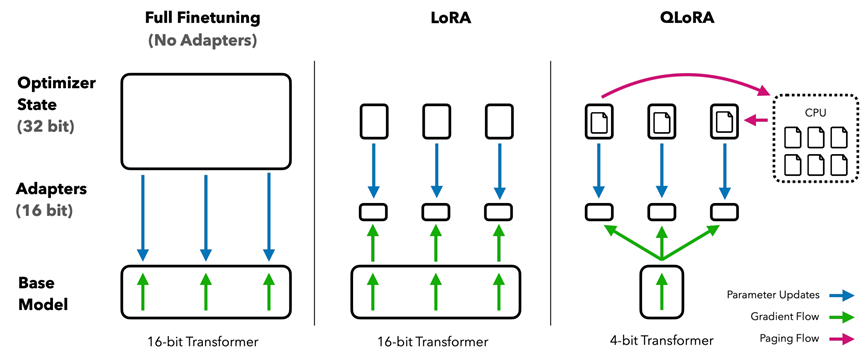
整个流程包含三个关键技术组件:
(1)4-bit NormalFloat(NF4)量化
量化(Quantization)是一种通过降低数值精度(例如从 16-bit 降至 4-bit)来压缩模型、节省显存的技术。传统 4-bit 量化通常采用如下流程:
-
使用权重的最大绝对值(absmax)将权重归一化到区间 [-1 , 1] ; -
将该区间均匀划分为 2^4=16 个等距格点; -
每个权重被映射到最近的格点,并以对应的 4-bit 索引存储。
具体如下图所示:

然而,大语言模型的权重分布并非均匀,而是近似服从标准正态分布(均值为 0,方差为 1)。在这种分布下,传统均匀量化存在明显缺陷:
-
在权重密集的 0 附近,格点相对不足,导致量化误差较大;
-
在权重稀疏的两端,格点又相对冗余,造成信息利用率低下。
为解决这一问题,QLoRA 提出了 4-bit NormalFloat(NF4)量化,专为标准正态分布设计:
-
将标准正态分布按累积概率均分为 16 个等概率区间;
-
每个区间选取其中位数作为该区间的量化代表值。
这样得到的量化格点在 0 附近更密集,在两端更稀疏,与权重的实际分布高度匹配,从而显著降低量化误差。
(2)双重量化(Double Quantization)
在权重量化过程中,为了保证精度,通常的做法是让每 64 个权重共享一个 32-bit 的缩放因子(Absmax)。虽然这种方法能有效控制量化误差,但这些大量的缩放因子自身也会带来显著的存储开销。
为缓解这一问题,QLoRA 提出了“双重量化”:不仅对模型权重量化,更对这些高精度的缩放因子进行二次量化。其实现方式是,将缩放因子以 256 个为一组,使用 8-bit 数据类型进行二次量化。如此一来,量化所需的辅助存储空间得以大幅减少。
(3)分页优化器(Paged Optimizers)
在微调过程中,优化器状态(如 Adam 的一阶矩、二阶矩)往往比模型权重本身更占显存。即使使用 LoRA 或 QLoRA,大量优化器状态仍可能导致显存不足,尤其是在消费级 GPU 上。
为解决这一瓶颈,QLoRA 使用了**分页优化器(Paged Optimizer)技术,使优化器状态能够按需加载、按需卸载,从而更加高效地利用显存。
其核心思路是:
-
将优化器状态拆分为多个小块(pages);
-
仅在需要更新某层时,临时把对应 page 载入到显存;
-
更新完成后立即将该 page 写回内存,并从显存中释放;
借助分页机制,显存只需容纳当前正在使用的优化器状态,显存占用随之显著降低。这一技术让大型模型的 QLoRA 微调能够在更低显存环境下高效运行,并最大化消费级 GPU 的可用算力。
**第 2 章 **微调实操
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
**2.1 **安装LLaMA-Factory
**1)**下载源码
使用git下载:
git clone https://github.com/hiyouga/LLaMA-Factory.git
autodl内置代理加速:https://www.autodl.com/docs/network_turbo/
配置代理加速:
source /etc/network_turbo
取消代理加速:
unset http_proxy && unset https_proxy
**2)**安装依赖
使用UV,创建一个python 3.12环境:
uv venv --python 3.12
激活环境:
source .venv/bin/activate
安装依赖:
uv pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装成功:
llamafactory-cli version
2.2 启动LLaMA-Factory
启动webui:
llamafactory-cli webui
不占用前台的方式启动:
nohup llamafactory-cliwebui >llama_factory.log 2>&1 &
看到“Running on local URL: http://0.0.0.0:7860”即启动成功。
如果使用autodl服务器启动,本地电脑访问需开启SSH隧道,在本地电脑执行:
ssh -CNg-L7860:127.0.0.1:7860root@connect.nmb2.seetacloud.com-p16652
也可以使用AutoDL提供的图形化界面工具配置代理隧道:
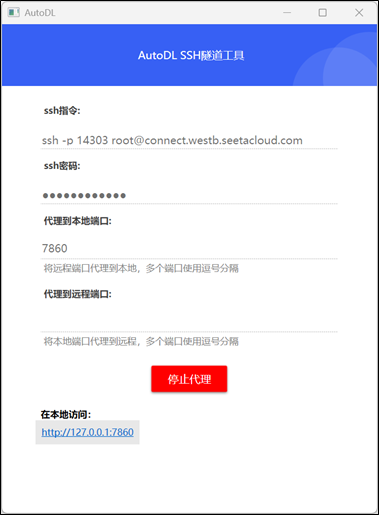
浏览器打开http://localhost:7860/
2.3 准备模型
在使用LLaMA-Factory进行微调时,可以通过LLaMA-Factory在训练时下载模型,也可以提前将模型下载好之后,配置本地路径,直接使用本地的模型。
通过ModelScope下载Qwen3-0.6B模型至model/Qwen3-0.6B路径下,命令如下:
model scope download--modelQwen/Qwen3-0.6B--local_dirmodel/Qwen3-0.6B
**2.4 **准备数据集
LLaMA-Factory目前支持 Alpaca 格式和 ShareGPT 格式的数据集。我们自己整理好格式的数据需要添加到数据集信息中。
**1)**处理数据格式
首先先将课程资料中的数据,上传至LLaMa-Factory目录中。
在LLaMa-Factory目录下,使用以下脚本,将数据整理成LLaMa-Factory所需要的格式,并保存至data/keywords_data_sharegpt.jsonl中。
from datasets import load_dataset
def convert_to_qwen_format(examples):
conversations = []
# 遍历每个对话样本,注意开启batch时,会自动套一层list
for conv_list in examples["conversation"]:
# 重建符合Qwen3标准的消息结构
for conv in conv_list:
conversations.append([
{"role": "user", "content": conv['human'].strip()},
{"role": "assistant", "content": conv['assistant'].strip()}
])
return {"messages": conversations}
if __name__ == '__main__':
dataset = load_dataset("json", data_files="data/keywords_data_train.jsonl", split="train")
# 格式化数据为 Chatgpt 格式
dataset = dataset.map(
convert_to_qwen_format,
batched=True,
remove_columns=dataset.column_names
)
dataset.to_json("data/keywords_data_sharegpt.jsonl",force_ascii=False)
**2)**添加数据集
修改dataset_info.json文件,添加数据集信息
"keywords_extract": {
"file_name": "keywords_data_sharegpt.jsonl",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
在web ui上就可以看到数据集,选中后,可以在页面预览数据。

2.5 使用LoRA进行微调
**1)**配置模型
配置前面已经下载好的模型,模型名称选择Custom,模型路径配置本地路径即可:

**2)**配置使用LoRA
在微调方法栏,配置使用lora,即可启用LoRA微调

**3)**配置训练轮数和最大样本数
配置训练总轮数以及每个数据集最多使用的样本数。
在不设置最大样本数时,每个 epoch 会遍历完整训练集,因此理论训练样本量约为训练集样本数×训练轮数。
在设置最大样本数后,训练前会先将可用训练样本限制到该数量以内,因此理论训练样本量约为 min(训练集样本数, 最大样本数) ×训练轮数。

**4)**配置保存位置
设置输出目录,后续训练过程中的检查点以及其他相关数据,都会保存至该目录当中去。

**2.6 **模型权重导出
通过LLaMA-Factory,可将训练好后得到的LoRA适配器参数和基座模型参数进行合并导出:
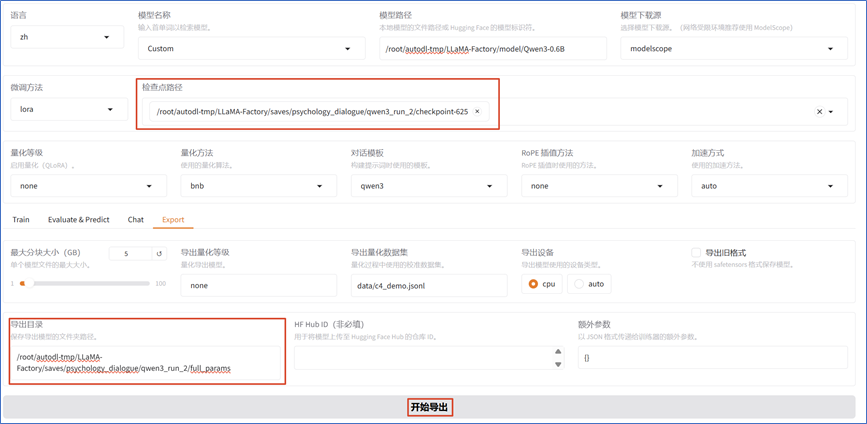
**第 3 章 **模型部署
在实际生产环境下,微调之后的模型,需要经过部署之后,才能使用。部署的本质就是将模型转换成可通过HTTP调用的服务,本章介绍如何使用vLLM对大模型进行部署以及如何在实际代码当中进行调用。
3.1 vLLM模型部署
**3.1.1 **简介
vLLM 是一个面向大语言模型推理的高性能推理框架,专为大规模并发请求优化,底层基于PyTorch 构建。
vLLM项目主页:https://docs.vllm.ai/en/latest/index.html
Github开源地址:https://github.com/vllm-project/vllm
从各种基准测试数据来看,同等配置下,使用 vLLM 框架与 Transformer 等传统推理库相比,其吞吐量可以提高一个数量级,这归功于以下几个特性:
-
高级 GPU 优化:利用 CUDA 和 PyTorch 最大限度地提高 GPU 利用率,从而实现更快的推理速度。
-
高级内存管理:通过PagedAttention算法实现对显存的高效管理,减少内存浪费,从而优化大模型的运行效率。
-
批处理功能:支持连续批处理和异步处理,从而提高多个并发请求的吞吐量。
-
安全特性:内置 API 密钥支持和适当的请求验证,不像其他完全跳过身份验证的框架。
-
易用性:支持多种流行的大型语言模型,并兼容 OpenAI 的 API 服务器。
3.1.2 安装
环境要求:
-
OS: Linux
-
Python: 3.9 – 3.12
创建并激活vllm环境
uv venv --python3.12
安装vllm
uv pip install vllm-ihttps://pypi.tuna.tsinghua.edu.cn/simple
查看安装信息
uv pip show vllm
3.1.3 启动
此处使用vllm将前面经过微调后的模型进行部署操作,首先需要将原模型目录和微调后的模型目录都拷贝到vllm_dir目录下(按照个人实际操作过程中的目录结构调整)。
启动命令:
vllm serve /root/autodl-tmp/vllm_dir/Qwen3-0.6B-sft-lora \
--served-model-name Qwen3-0.6B-sft-lora \
--tokenizer /root/autodl-tmp/vllm_dir/Qwen3-0.6B \
--max-model-len 32768
注意:小写的k,单位是1000;大写的K,单位是1024
正式运行应后台运行:
nohup vllm serve /root/autodl-tmp/vllm_dir/Qwen3-0.6B-sft-lora \
--served-model-name Qwen3-0.6B-sft-lora \
--tokenizer /root/autodl-tmp/vllm_dir/Qwen3-0.6B \
--max-model-len 32K \
> vllm.log 2>&1 &
3.1.4 调用
**1)**快速测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-0.6B-sft-lora",
"messages": [
{"role": "user", "content": "抽取出下文中的关键词:\n目的分析结节性甲状腺肿(NG)合并甲状腺微小癌(TMC)的超声声像图特点,以提高 TMC 的术前超声检出率.资料与方法回顾性分析经手术病理证实的64例 NG 合并 TMC 的超声声像图表现,并以同病例邻近癌灶且直径≤1cm 的 NG 结节作为对照.结果 TMC 与 NG 结节在形态、边界、回声强度、声晕、微小钙化、囊性变与血流分布等方面差异有统计学意义(P <0.01),回声均匀程度差异无统计学意义(P >0.05).颈部淋巴结肿大超声检出率为89.47%(17/19).结论 TMC 具有与 NG 结节不同的声像图特点,TMC 的灰阶超声特点为低回声、无声晕、有微小钙化、无囊性变等,彩色多普勒超声显示病灶内部血流信号丰富或无血流,周边少或无血流信号.在 NG 检查中重点观察≤1cm 的低回声结节,以及早发现 TMC. "}
]
}'
**2)代码调用(openai库)
安装openai库
uv pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
测试代码
from openai import OpenAI
# 连接本地
client = OpenAI(
base_url="http://localhost:8000/v1/",
api_key="none" # 占位符,可忽略
)
# 多轮对话
response = client.chat.completions.create(
model="Qwen3-0.6B-sft-lora", # 指定模型,必须与启动vllm时指定的名字一致
messages=[
{"role": "user", "content": "抽取出下文中的关键词:\n目的分析结节性甲状腺肿(NG)合并甲状腺微小癌(TMC)的超声声像图特点,以提高 TMC 的术前超声检出率.资料与方法回顾性分析经手术病理证实的64例 NG 合并 TMC 的超声声像图表现,并以同病例邻近癌灶且直径≤1cm 的 NG 结节作为对照.结果 TMC 与 NG 结节在形态、边界、回声强度、声晕、微小钙化、囊性变与血流分布等方面差异有统计学意义(P <0.01),回声均匀程度差异无统计学意义(P >0.05).颈部淋巴结肿大超声检出率为89.47%(17/19).结论 TMC 具有与 NG 结节不同的声像图特点,TMC 的灰阶超声特点为低回声、无声晕、有微小钙化、无囊性变等,彩色多普勒超声显示病灶内部血流信号丰富或无血流,周边少或无血流信号.在 NG 检查中重点观察≤1cm 的低回声结节,以及早发现 TMC. "}
],
extra_body={
"chat_template_kwargs": {"enable_thinking": False} # 关键参数
}
)
# print(response)
print(response.choices[0].message.content)
**3)**Langchain调用
安装langchain库
uv pip install langchain-core langchain-openai -i https://pypi.tuna.tsinghua.edu.cn/simple
测试代码
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
llm = ChatOpenAI(
model="Qwen3-0.6B-sft-lora",
base_url="http://localhost:8000/v1/",
api_key="none",
temperature=0)
# 构建消息(支持多角色)
messages = [
HumanMessage(content="抽取出下文中的关键词:\n目的分析结节性甲状腺肿(NG)合并甲状腺微小癌(TMC)的超声声像图特点,以提高 TMC 的术前超声检出率.资料与方法回顾性分析经手术病理证实的64例 NG 合并 TMC 的超声声像图表现,并以同病例邻近癌灶且直径≤1cm 的 NG 结节作为对照.结果 TMC 与 NG 结节在形态、边界、回声强度、声晕、微小钙化、囊性变与血流分布等方面差异有统计学意义(P <0.01),回声均匀程度差异无统计学意义(P >0.05).颈部淋巴结肿大超声检出率为89.47%(17/19).结论 TMC 具有与 NG 结节不同的声像图特点,TMC 的灰阶超声特点为低回声、无声晕、有微小钙化、无囊性变等,彩色多普勒超声显示病灶内部血流信号丰富或无血流,周边少或无血流信号.在 NG 检查中重点观察≤1cm 的低回声结节,以及早发现 TMC. ")
]
# 调用模型获取响应
response = llm.invoke(messages)
print(response.content)
第 1 章 微调方法选择
根据是否更新模型全部参数,监督微调(SFT)的方法可分为两类:
- 全参数微调(Full Fine-tuning)
- 参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
**1.1 **全参数微调
全参数微调是一种在微调过程中更新模型全部参数的方法。它能最大限度地适配目标任务,通常获得最优性能。
但由于大语言模型参数量庞大(数十亿至数千亿),全参数微调对显存、算力和训练时间要求极高,单设备通常无法承载模型参数、优化器状态与激活值,必须依赖分布式训练技术才能实施。
因此,全参数微调适用于资源充足、对性能要求严苛、且拥有高质量标注数据的场景。在实际应用中,常作为参数高效微调无法满足需求时的高成本备选方案。
1.2 参数高效微调
**1.2.1 **概述
参数高效微调(Parameter-Efficient Fine-tuning, PEFT)是一系列微调方法,其核心思想是仅更新少量参数或引入少量可训练模块,在显著降低资源消耗的同时,高效适配目标任务。目前,最先进的PEFT方法已经能实现与全参微调相当的性能。
PEFT 的兴起可追溯至 2019 年前后。当时以 BERT、GPT-2 为代表的预训练模型规模迅速扩大,传统全参数微调的资源成本逐渐难以承受。伴随模型规模持续膨胀,这种矛盾愈发凸显,由此推动了 PEFT 技术的快速发展,形成了包括 Prompt Tuning、Prefix Tuning、P-Tuning、Adapter、LoRA 等多条技术路线,如下图所示:
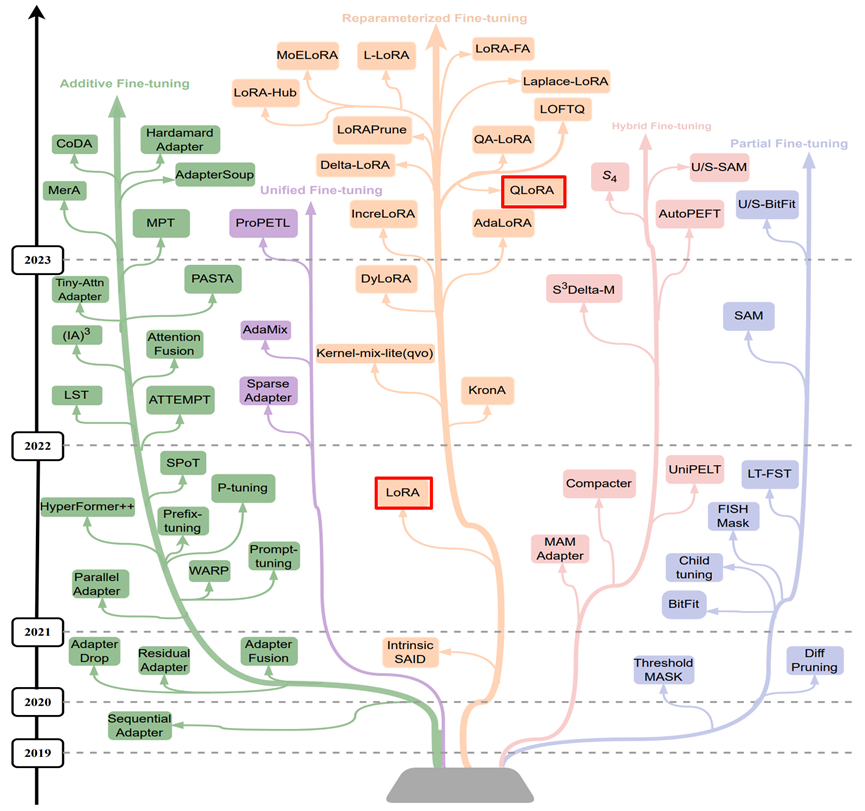
在众多方法中,LoRA(Low-Rank Adaptation)因其结构简洁、训练高效、稳定,已成为当前大语言模型监督微调(SFT)的主流选择;其量化版本 QLoRA (Quantized Low-Rank Adaptation)进一步融合量化技术,将微调门槛降至消费级 GPU 也可运行的水平。相比之下,其他 PEFT 方法因在效率、稳定性或通用性等方面存在局限,已逐渐边缘化。
**1.2.2 **LoRA
**1)**概述
LoRA(Low-Rank Adaptation)是一种高效且广泛使用的参数高效微调方法,由微软研究院于 2021 年提出。因其训练成本低、适配能力强、推理无额外开销等优势,已成为当前大语言模型监督微调(SFT)中最广泛使用的技术。
**2)**原理
在传统的全参数微调(Full Fine-tuning)中,模型中的某个参数矩阵会在训练过程中被更新为W_0:
W = W 0 + Δ W W=W_0+ΔW W=W0+ΔW
其中ΔW是微调阶段需要学习的完整增量矩阵。
LoRA 的作者在实践中观察到:ΔW 往往具有低秩结构,也就是说它的有效自由度远低于其表面维度。基于这一关键现象,LoRA 将 ΔW 近似分解为两个低秩矩阵的乘积:
Δ W ≈ A B , A ∈ R d × r , B ∈ R r × k ΔW≈AB,A \in R^{d\times r},B \in R^{r\times k} ΔW≈AB,A∈Rd×r,B∈Rr×k
其中 r << min(d,k) ,通常取 4、8 或 16 等远小于原始维度的数值。这样,微调后的权重矩阵可写为:
W = W 0 + A B W=W_0+AB W=W0+AB
如下图所示:
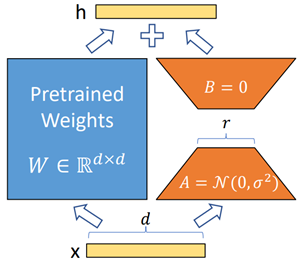
在训练过程中,LoRA 完全冻结原始权重 W_0 ,仅对新增的低秩矩阵 A 和 B 进行优化。这大幅减少了需要更新的参数量,同时也避免了对大规模模型权重的直接修改,使微调过程更加轻量、高效。
在推理阶段,低秩增量可以无缝合并回原始权重 W_0 中,不会引入额外的计算复杂度,因此 LoRA 的高效性不仅体现在训练中,也体现在推理过程中。如下图所示:
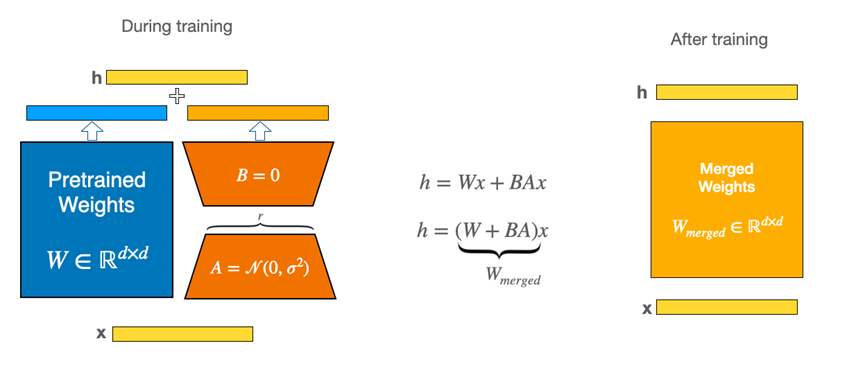
由于秩 r 很小,LoRA 的参数开销和计算成本都极低。例如,对 d=k=4096 的权重矩阵进行全参数更新需要约 16M 个参数,而采用 LoRA(如 r=8)时,仅需:
4096 × 8 + 8 × 4096 = 65536 4096\times 8+8\times 4096=65536 4096×8+8×4096=65536
个参数,占原始权重的仅约 0.4%。这种数量级的压缩使得在有限资源下微调大模型成为可能,也使得在多个任务之间共享底层模型、仅保存轻量级 LoRA 适配器成为现实。
**1.2.3 QloRA
**1)**概述
QLoRA(Quantized Low-Rank Adaptation)是 LoRA 的量化增强版本,由华盛顿大学和微软研究院于 2023 年提出。QLoRA 在 LoRA 的基础上引入 4-bit 量化技术,在几乎不损失性能的前提下,将大语言模型微调的硬件门槛大幅降低,使得数十亿参数级别的模型可在单张消费级 GPU(如 RTX 3090/4090)上完成高效微调。
**2)**原理
QLoRA 的核心思想是:先对预训练模型权重进行 4-bit 量化以压缩显存占用,再在其上应用 LoRA 进行参数高效微调。
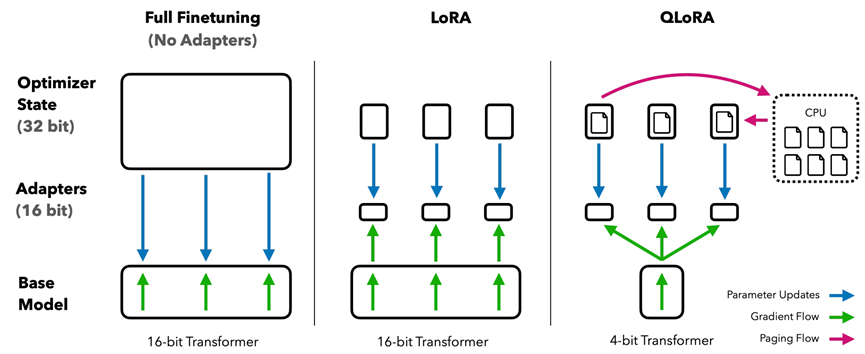
整个流程包含三个关键技术组件:
(1)4-bit NormalFloat(NF4)量化
量化(Quantization)是一种通过降低数值精度(例如从 16-bit 降至 4-bit)来压缩模型、节省显存的技术。传统 4-bit 量化通常采用如下流程:
-
使用权重的最大绝对值(absmax)将权重归一化到区间 [-1 , 1] ; -
将该区间均匀划分为 2^4=16 个等距格点; -
每个权重被映射到最近的格点,并以对应的 4-bit 索引存储。
具体如下图所示:

然而,大语言模型的权重分布并非均匀,而是近似服从标准正态分布(均值为 0,方差为 1)。在这种分布下,传统均匀量化存在明显缺陷:
-
在权重密集的 0 附近,格点相对不足,导致量化误差较大;
-
在权重稀疏的两端,格点又相对冗余,造成信息利用率低下。
为解决这一问题,QLoRA 提出了 4-bit NormalFloat(NF4)量化,专为标准正态分布设计:
-
将标准正态分布按累积概率均分为 16 个等概率区间;
-
每个区间选取其中位数作为该区间的量化代表值。
这样得到的量化格点在 0 附近更密集,在两端更稀疏,与权重的实际分布高度匹配,从而显著降低量化误差。
(2)双重量化(Double Quantization)
在权重量化过程中,为了保证精度,通常的做法是让每 64 个权重共享一个 32-bit 的缩放因子(Absmax)。虽然这种方法能有效控制量化误差,但这些大量的缩放因子自身也会带来显著的存储开销。
为缓解这一问题,QLoRA 提出了“双重量化”:不仅对模型权重量化,更对这些高精度的缩放因子进行二次量化。其实现方式是,将缩放因子以 256 个为一组,使用 8-bit 数据类型进行二次量化。如此一来,量化所需的辅助存储空间得以大幅减少。
(3)分页优化器(Paged Optimizers)
在微调过程中,优化器状态(如 Adam 的一阶矩、二阶矩)往往比模型权重本身更占显存。即使使用 LoRA 或 QLoRA,大量优化器状态仍可能导致显存不足,尤其是在消费级 GPU 上。
为解决这一瓶颈,QLoRA 使用了**分页优化器(Paged Optimizer)技术,使优化器状态能够按需加载、按需卸载,从而更加高效地利用显存。
其核心思路是:
-
将优化器状态拆分为多个小块(pages);
-
仅在需要更新某层时,临时把对应 page 载入到显存;
-
更新完成后立即将该 page 写回内存,并从显存中释放;
借助分页机制,显存只需容纳当前正在使用的优化器状态,显存占用随之显著降低。这一技术让大型模型的 QLoRA 微调能够在更低显存环境下高效运行,并最大化消费级 GPU 的可用算力。
**第 2 章 **微调实操
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
**2.1 **安装LLaMA-Factory
**1)**下载源码
使用git下载:
git clone https://github.com/hiyouga/LLaMA-Factory.git
autodl内置代理加速:https://www.autodl.com/docs/network_turbo/
配置代理加速:
source /etc/network_turbo
取消代理加速:
unset http_proxy && unset https_proxy
**2)**安装依赖
使用UV,创建一个python 3.12环境:
uv venv --python 3.12
激活环境:
source .venv/bin/activate
安装依赖:
uv pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装成功:
llamafactory-cli version
2.2 启动LLaMA-Factory
启动webui:
llamafactory-cli webui
不占用前台的方式启动:
nohup llamafactory-cliwebui >llama_factory.log 2>&1 &
看到“Running on local URL: http://0.0.0.0:7860”即启动成功。
如果使用autodl服务器启动,本地电脑访问需开启SSH隧道,在本地电脑执行:
ssh -CNg-L7860:127.0.0.1:7860root@connect.nmb2.seetacloud.com-p16652
也可以使用AutoDL提供的图形化界面工具配置代理隧道:
浏览器打开http://localhost:7860/
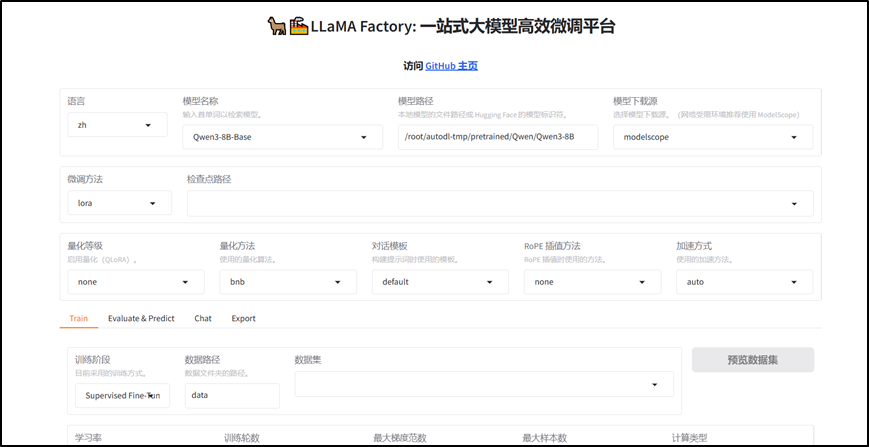
2.3 准备模型
在使用LLaMA-Factory进行微调时,可以通过LLaMA-Factory在训练时下载模型,也可以提前将模型下载好之后,配置本地路径,直接使用本地的模型。
通过ModelScope下载Qwen3-0.6B模型至model/Qwen3-0.6B路径下,命令如下:
model scope download--modelQwen/Qwen3-0.6B--local_dirmodel/Qwen3-0.6B
**2.4 **准备数据集
LLaMA-Factory目前支持 Alpaca 格式和 ShareGPT 格式的数据集。我们自己整理好格式的数据需要添加到数据集信息中。
**1)**处理数据格式
首先先将课程资料中的数据,上传至LLaMa-Factory目录中。
在LLaMa-Factory目录下,使用以下脚本,将数据整理成LLaMa-Factory所需要的格式,并保存至data/keywords_data_sharegpt.jsonl中。
from datasets import load_dataset
def convert_to_qwen_format(examples):
conversations = []
# 遍历每个对话样本,注意开启batch时,会自动套一层list
for conv_list in examples["conversation"]:
# 重建符合Qwen3标准的消息结构
for conv in conv_list:
conversations.append([
{"role": "user", "content": conv['human'].strip()},
{"role": "assistant", "content": conv['assistant'].strip()}
])
return {"messages": conversations}
if __name__ == '__main__':
dataset = load_dataset("json", data_files="data/keywords_data_train.jsonl", split="train")
# 格式化数据为 Chatgpt 格式
dataset = dataset.map(
convert_to_qwen_format,
batched=True,
remove_columns=dataset.column_names
)
dataset.to_json("data/keywords_data_sharegpt.jsonl",force_ascii=False)
**2)**添加数据集
修改dataset_info.json文件,添加数据集信息
"keywords_extract": {
"file_name": "keywords_data_sharegpt.jsonl",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
在web ui上就可以看到数据集,选中后,可以在页面预览数据。

2.5 使用LoRA进行微调
**1)**配置模型
配置前面已经下载好的模型,模型名称选择Custom,模型路径配置本地路径即可:

**2)**配置使用LoRA
在微调方法栏,配置使用lora,即可启用LoRA微调

**3)**配置训练轮数和最大样本数
配置训练总轮数以及每个数据集最多使用的样本数。
在不设置最大样本数时,每个 epoch 会遍历完整训练集,因此理论训练样本量约为训练集样本数×训练轮数。
在设置最大样本数后,训练前会先将可用训练样本限制到该数量以内,因此理论训练样本量约为 min(训练集样本数, 最大样本数) ×训练轮数。

**4)**配置保存位置
设置输出目录,后续训练过程中的检查点以及其他相关数据,都会保存至该目录当中去。

**2.6 **模型权重导出
通过LLaMA-Factory,可将训练好后得到的LoRA适配器参数和基座模型参数进行合并导出:
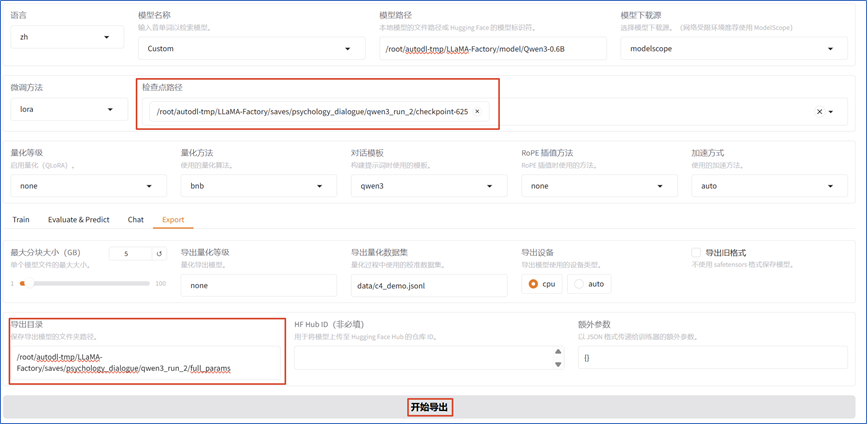
**第 3 章 **模型部署
在实际生产环境下,微调之后的模型,需要经过部署之后,才能使用。部署的本质就是将模型转换成可通过HTTP调用的服务,本章介绍如何使用vLLM对大模型进行部署以及如何在实际代码当中进行调用。
3.1 vLLM模型部署
**3.1.1 **简介
vLLM 是一个面向大语言模型推理的高性能推理框架,专为大规模并发请求优化,底层基于PyTorch 构建。
vLLM项目主页:https://docs.vllm.ai/en/latest/index.html
Github开源地址:https://github.com/vllm-project/vllm
从各种基准测试数据来看,同等配置下,使用 vLLM 框架与 Transformer 等传统推理库相比,其吞吐量可以提高一个数量级,这归功于以下几个特性:
-
高级 GPU 优化:利用 CUDA 和 PyTorch 最大限度地提高 GPU 利用率,从而实现更快的推理速度。
-
高级内存管理:通过PagedAttention算法实现对显存的高效管理,减少内存浪费,从而优化大模型的运行效率。
-
批处理功能:支持连续批处理和异步处理,从而提高多个并发请求的吞吐量。
-
安全特性:内置 API 密钥支持和适当的请求验证,不像其他完全跳过身份验证的框架。
-
易用性:支持多种流行的大型语言模型,并兼容 OpenAI 的 API 服务器。
3.1.2 安装
环境要求:
-
OS: Linux
-
Python: 3.9 – 3.12
创建并激活vllm环境
uv venv --python3.12
安装vllm
uv pip install vllm-ihttps://pypi.tuna.tsinghua.edu.cn/simple
查看安装信息
uv pip show vllm
3.1.3 启动
此处使用vllm将前面经过微调后的模型进行部署操作,首先需要将原模型目录和微调后的模型目录都拷贝到vllm_dir目录下(按照个人实际操作过程中的目录结构调整)。
启动命令:
vllm serve /root/autodl-tmp/vllm_dir/Qwen3-0.6B-sft-lora \
--served-model-name Qwen3-0.6B-sft-lora \
--tokenizer /root/autodl-tmp/vllm_dir/Qwen3-0.6B \
--max-model-len 32768
注意:小写的k,单位是1000;大写的K,单位是1024
正式运行应后台运行:
nohup vllm serve /root/autodl-tmp/vllm_dir/Qwen3-0.6B-sft-lora \
--served-model-name Qwen3-0.6B-sft-lora \
--tokenizer /root/autodl-tmp/vllm_dir/Qwen3-0.6B \
--max-model-len 32K \
> vllm.log 2>&1 &
3.1.4 调用
**1)**快速测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-0.6B-sft-lora",
"messages": [
{"role": "user", "content": "抽取出下文中的关键词:\n目的分析结节性甲状腺肿(NG)合并甲状腺微小癌(TMC)的超声声像图特点,以提高 TMC 的术前超声检出率.资料与方法回顾性分析经手术病理证实的64例 NG 合并 TMC 的超声声像图表现,并以同病例邻近癌灶且直径≤1cm 的 NG 结节作为对照.结果 TMC 与 NG 结节在形态、边界、回声强度、声晕、微小钙化、囊性变与血流分布等方面差异有统计学意义(P <0.01),回声均匀程度差异无统计学意义(P >0.05).颈部淋巴结肿大超声检出率为89.47%(17/19).结论 TMC 具有与 NG 结节不同的声像图特点,TMC 的灰阶超声特点为低回声、无声晕、有微小钙化、无囊性变等,彩色多普勒超声显示病灶内部血流信号丰富或无血流,周边少或无血流信号.在 NG 检查中重点观察≤1cm 的低回声结节,以及早发现 TMC. "}
]
}'
**2)代码调用(openai库)
安装openai库
uv pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
测试代码
from openai import OpenAI
# 连接本地
client = OpenAI(
base_url="http://localhost:8000/v1/",
api_key="none" # 占位符,可忽略
)
# 多轮对话
response = client.chat.completions.create(
model="Qwen3-0.6B-sft-lora", # 指定模型,必须与启动vllm时指定的名字一致
messages=[
{"role": "user", "content": "抽取出下文中的关键词:\n目的分析结节性甲状腺肿(NG)合并甲状腺微小癌(TMC)的超声声像图特点,以提高 TMC 的术前超声检出率.资料与方法回顾性分析经手术病理证实的64例 NG 合并 TMC 的超声声像图表现,并以同病例邻近癌灶且直径≤1cm 的 NG 结节作为对照.结果 TMC 与 NG 结节在形态、边界、回声强度、声晕、微小钙化、囊性变与血流分布等方面差异有统计学意义(P <0.01),回声均匀程度差异无统计学意义(P >0.05).颈部淋巴结肿大超声检出率为89.47%(17/19).结论 TMC 具有与 NG 结节不同的声像图特点,TMC 的灰阶超声特点为低回声、无声晕、有微小钙化、无囊性变等,彩色多普勒超声显示病灶内部血流信号丰富或无血流,周边少或无血流信号.在 NG 检查中重点观察≤1cm 的低回声结节,以及早发现 TMC. "}
],
extra_body={
"chat_template_kwargs": {"enable_thinking": False} # 关键参数
}
)
# print(response)
print(response.choices[0].message.content)
**3)**Langchain调用
安装langchain库
uv pip install langchain-core langchain-openai -i https://pypi.tuna.tsinghua.edu.cn/simple
测试代码
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
llm = ChatOpenAI(
model="Qwen3-0.6B-sft-lora",
base_url="http://localhost:8000/v1/",
api_key="none",
temperature=0)
# 构建消息(支持多角色)
messages = [
HumanMessage(content="抽取出下文中的关键词:\n目的分析结节性甲状腺肿(NG)合并甲状腺微小癌(TMC)的超声声像图特点,以提高 TMC 的术前超声检出率.资料与方法回顾性分析经手术病理证实的64例 NG 合并 TMC 的超声声像图表现,并以同病例邻近癌灶且直径≤1cm 的 NG 结节作为对照.结果 TMC 与 NG 结节在形态、边界、回声强度、声晕、微小钙化、囊性变与血流分布等方面差异有统计学意义(P <0.01),回声均匀程度差异无统计学意义(P >0.05).颈部淋巴结肿大超声检出率为89.47%(17/19).结论 TMC 具有与 NG 结节不同的声像图特点,TMC 的灰阶超声特点为低回声、无声晕、有微小钙化、无囊性变等,彩色多普勒超声显示病灶内部血流信号丰富或无血流,周边少或无血流信号.在 NG 检查中重点观察≤1cm 的低回声结节,以及早发现 TMC. ")
]
# 调用模型获取响应
response = llm.invoke(messages)
print(response.content)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)