【MiniGPT-4论文阅读】:用一个线性层解锁大语言模型的视觉超能力
MiniGPT-4是多模态大模型发展史上的一个里程碑式的工作。多模态大模型的能力上限,是由语言模型决定的。简单就是美:有时候最简单的架构反而能取得最好的效果数据质量 > 数据数量:3500条高质量数据带来的提升,超过了500万条低质量数据站在巨人的肩膀上:充分利用已经训练好的单模态模型,可以大大降低多模态模型的训练成本MiniGPT-4的开源也极大地推动了多模态大模型的研究和应用。现在,任何人都可
论文信息
- 标题:MINIGPT-4: ENHANCING VISION-LANGUAGE UNDERSTANDING WITH ADVANCED LARGE LANGUAGE MODELS
- 会议:arXiv预印本 (2023)
- 单位:阿卜杜拉国王科技大学(KAUST)
- 代码:https://minigpt-4.github.io
- 论文:https://arxiv.org/pdf/2304.10592.pdf
引言:当GPT-4的魔法被开源破解
2023年3月,OpenAI发布的GPT-4震惊了全世界。它不仅能看懂图片,还能根据你的手绘草图生成完整的HTML网站,能解释网络迷因的笑点,甚至能根据一张食物照片教你怎么做菜。但遗憾的是,GPT-4的技术细节完全是个黑盒,没人知道它是怎么做到的。
就在大家都以为只有OpenAI这样的巨头才能做出这么强大的多模态模型时,来自KAUST的研究团队带来了一个重磅炸弹:MiniGPT-4。他们只用了一个线性投影层,就把开源的BLIP-2视觉编码器和Vicuna大语言模型连接起来,竟然复现了GPT-4展示的几乎所有高级多模态能力!
更让人震惊的是,整个训练过程只需要:
- 第一阶段:在4张A100上训练10小时,对齐视觉和语言特征
- 第二阶段:在1张A100上训练7分钟,让生成的语言更自然
这篇论文告诉我们一个颠覆认知的事实:多模态大模型的能力上限,其实是由语言模型决定的。只要你有一个足够强的语言模型,哪怕只用最简单的方式把视觉信息喂给它,它就能展现出惊人的视觉理解和生成能力。
一、MiniGPT-4架构:简单到离谱,强大到可怕
MiniGPT-4的架构简单到让人不敢相信,它只有三个部分:一个冻结的视觉编码器、一个可训练的线性投影层和一个冻结的大语言模型。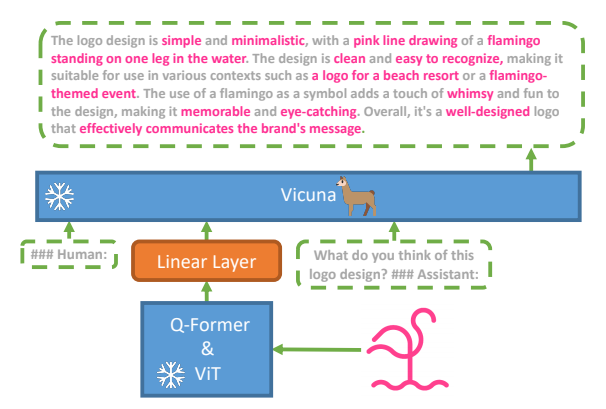
图片1:MiniGPT-4网络架构
出处:论文图1
1.1 视觉编码器
MiniGPT-4直接复用了BLIP-2的视觉模块,它由两部分组成:
- ViT-G/14:来自EVA-CLIP的视觉Transformer,是当时最强的开源视觉编码器之一
- Q-Former:BLIP-2提出的查询转换器,能从视觉特征中提取出最有用的信息,压缩成固定长度的token序列
对于一张输入图片XvX_vXv,视觉编码器会输出一个视觉特征序列ZvZ_vZv:
Zv=g(Xv)Z_v = g(X_v)Zv=g(Xv)
- ZvZ_vZv:视觉特征序列,形状为(N,D)(N, D)(N,D),其中NNN是token数量,DDD是特征维度
- g(⋅)g(\cdot)g(⋅):视觉编码器函数(ViT-G/14 + Q-Former)
- XvX_vXv:输入图片,形状为(3,H,W)(3, H, W)(3,H,W)
1.2 线性投影层
这是整个模型中唯一需要训练的部分!它的作用是把视觉特征转换成语言模型能理解的格式:
Hv=W⋅ZvH_v = W \cdot Z_vHv=W⋅Zv
- HvH_vHv:投影后的视觉token序列,形状为(N,d)(N, d)(N,d),其中ddd是语言模型的词嵌入维度
- WWW:可训练的线性投影矩阵,形状为(D,d)(D, d)(D,d)
- ZvZ_vZv:视觉编码器输出的特征序列
通俗解释:这就像一个翻译官,把视觉编码器说的"视觉语言"翻译成Vicuna能听懂的"自然语言"。虽然只有一个线性层,但它已经足够完成这个翻译任务了。
1.3 大语言模型
MiniGPT-4使用了Vicuna作为语言解码器,它是基于LLaMA微调的开源聊天机器人,在GPT-4的评估中达到了ChatGPT 90%的水平。
投影后的视觉tokenHvH_vHv会被包装成特殊的格式<Img><ImageFeature></Img>,然后插入到用户的指令中,一起输入到Vicuna里。Vicuna会自回归地生成回答,就像它平时和人类聊天一样。
二、两阶段训练策略:先对齐,再润色
MiniGPT-4采用了两阶段的训练策略,完美解决了视觉-语言对齐和自然语言生成的问题。
2.1 第一阶段:大规模预训练对齐
在这个阶段,作者们使用了三个大规模的图文对数据集:
- Conceptual Captions (CC):330万条
- SBU Captions:100万条
- LAION:部分子集
总共大约500万条图文对。训练时,视觉编码器和语言模型都保持冻结,只训练线性投影层WWW。
训练目标是让语言模型根据视觉特征生成对应的图片标题:
L=−∑i=1Llogp(xi∣Hv,x<i)\mathcal{L} = -\sum_{i=1}^{L} \log p(x_i | H_v, x_{<i})L=−i=1∑Llogp(xi∣Hv,x<i)
- L\mathcal{L}L:交叉熵损失
- xix_ixi:标题的第iii个token
- x<ix_{<i}x<i:第iii个token之前的所有token
- HvH_vHv:投影后的视觉特征序列
问题来了:第一阶段训练完成后,模型虽然能理解图片内容,但生成的语言非常糟糕——经常重复、碎片化、不连贯,根本没法用来聊天。
这是为什么呢?因为训练用的图文对都是非常简短的标题,比如"一只狗在草地上跑",这种语言风格和人类自然对话的风格完全不同。语言模型虽然学会了把视觉特征和这些短标题对应起来,但还没学会用自然的人类语言来描述图片。
2.2 第二阶段:高质量微调润色
为了解决这个问题,作者们提出了一个天才的解决方案:自己造一个高质量的详细描述数据集。
数据收集过程
- 自动生成:用第一阶段训练好的模型,给5000张随机图片生成详细描述。为了让描述更长,他们设计了专门的prompt,如果生成的描述少于80个token,就继续让模型续写。
- ChatGPT修正:把生成的描述发给ChatGPT,让它修正错误、删除重复、补全不完整的句子。
- 人工筛选:最后人工检查,去掉质量不好的样本,最终得到了3500条高质量的详细描述数据。
微调过程
用这3500条数据,按照Vicuna的对话模板进行微调:
###Human: <Img><ImageFeature></Img>描述这张图片的详细内容。###Assistant: 这张图片展示了...
微调时,仍然只训练线性投影层,只需要400步,在1张A100上大约7分钟就能完成!
表格1:第二阶段微调前后的失败率对比
| 任务 | 微调前失败率 | 微调后失败率 |
|---|---|---|
| 详细描述生成 | 35% | 2% |
| 诗歌创作 | 32% | 1% |
| 出处:论文表3 |
分析:仅仅7分钟的微调,就把生成失败率从30%以上降到了2%以下!这说明第二阶段的作用不是让模型学会新的视觉知识,而是让它学会用人类能听懂的方式把已经学会的知识表达出来。
三、实验结果:7分钟的奇迹
MiniGPT-4在各种任务上都展现出了惊人的能力,很多方面甚至接近了GPT-4的水平。
3.1 高级多模态能力评估
作者们收集了100张图片,分成4个任务,让人类评估模型的表现:
- 迷因解释:解释为什么这个迷因好笑
- 菜谱生成:根据食物照片生成详细的菜谱
- 广告创作:根据产品图片写一个吸引人的广告
- 诗歌创作:根据图片写一首优美的诗
表格2:高级能力评估结果
| 模型 | 迷因解释 | 菜谱生成 | 广告创作 | 诗歌创作 | 平均 |
|---|---|---|---|---|---|
| BLIP-2 | 0/25 | 4/25 | 1/25 | 0/25 | 5/100 |
| MiniGPT-4 | 8/25 | 18/25 | 19/25 | 20/25 | 65/100 |
| 出处:论文表1 |
分析:BLIP-2在这些高级任务上几乎完全失败,而MiniGPT-4的平均成功率达到了65%!特别是在广告创作和诗歌创作上,成功率超过了75%。这说明强语言模型带来的组合泛化能力是BLIP-2使用的Flan-T5完全无法比拟的。
3.2 COCO字幕评估
在传统的COCO字幕任务上,MiniGPT-4也表现出色。作者们用ChatGPT作为评委,评估生成的字幕是否覆盖了所有真实字幕中的物体和关系。
表格3:COCO字幕评估结果
| 模型 | 正确率 |
|---|---|
| BLIP-2 | 27.5% |
| MiniGPT-4 | 66.2% |
| 出处:论文表2 |
分析:MiniGPT-4的正确率是BLIP-2的2.4倍!这说明它能更全面、更准确地描述图片内容。
3.3 架构消融实验
作者们还做了消融实验,验证了"一个线性层就足够"的结论。
表格4:架构消融实验结果
| 模型变体 | AOK-VQA | GQA |
|---|---|---|
| 原始MiniGPT-4 | 58.2 | 32.2 |
| 去掉Q-Former | 56.9 | 33.4 |
| 用3个线性层代替1个 | 49.7 | 31.0 |
| 微调Q-Former | 52.1 | 28.0 |
| 出处:论文表4 |
分析:
- 去掉Q-Former后,性能几乎没有下降!这说明Q-Former在这个架构里并不是必须的
- 用更多的线性层反而会降低性能
- 微调Q-Former也会导致性能下降
这再次证明了:最简单的架构往往是最好的。在有强语言模型的情况下,复杂的对齐模块不仅没有必要,反而会引入噪声。
3.4 幻觉问题评估
和所有大语言模型一样,MiniGPT-4也有幻觉问题,会生成图片中不存在的东西。作者们用CHAIR指标评估了幻觉率。
表格5:幻觉评估结果
| 模型 | CHAIR_i | 平均生成长度 |
|---|---|---|
| BLIP-2 | 1.3 | 6.5 |
| MiniGPT-4(短) | 7.2 | 28.8 |
| MiniGPT-4(长) | 9.6 | 175 |
| 出处:论文表5 |
分析:生成的内容越长,幻觉率越高。这是因为语言模型在生成长文本时,会更多地依赖自己的内部知识,而不是输入的视觉信息。
四、核心代码实现
下面是MiniGPT-4的核心代码实现,包括模型架构和前向传播过程:
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModelForCausalLM
from lavis.models import load_model_and_preprocess
class MiniGPT4(nn.Module):
def __init__(
self,
vision_model_name="blip2_vicuna_instruct",
vision_model_type="vicuna7b",
language_model_name="lmsys/vicuna-7b-v1.5",
freeze_vision=True,
freeze_language=True
):
super().__init__()
# 加载BLIP-2的视觉编码器和Q-Former
self.visual_model, self.vis_processors, _ = load_model_and_preprocess(
name=vision_model_name,
model_type=vision_model_type,
is_eval=True,
device="cpu"
)
# 线性投影层:将Q-Former输出的视觉特征映射到Vicuna的词嵌入维度
self.vision_proj = nn.Linear(
self.visual_model.Qformer.config.hidden_size,
AutoModelForCausalLM.from_pretrained(language_model_name).config.hidden_size
)
# 加载Vicuna语言模型和分词器
self.tokenizer = AutoTokenizer.from_pretrained(language_model_name)
self.language_model = AutoModelForCausalLM.from_pretrained(
language_model_name,
torch_dtype=torch.float16
)
# 冻结视觉和语言模型参数
if freeze_vision:
for param in self.visual_model.parameters():
param.requires_grad = False
if freeze_language:
for param in self.language_model.parameters():
param.requires_grad = False
# 特殊token
self.img_token = "<Img>"
self.img_end_token = "</Img>"
self.img_token_id = self.tokenizer.convert_tokens_to_ids(self.img_token)
self.img_end_token_id = self.tokenizer.convert_tokens_to_ids(self.img_end_token)
# 添加特殊token到分词器
if self.img_token_id == self.tokenizer.unk_token_id:
self.tokenizer.add_tokens([self.img_token, self.img_end_token])
self.language_model.resize_token_embeddings(len(self.tokenizer))
self.img_token_id = self.tokenizer.convert_tokens_to_ids(self.img_token)
self.img_end_token_id = self.tokenizer.convert_tokens_to_ids(self.img_end_token)
def encode_images(self, images):
"""编码图像为视觉特征"""
# 预处理图像
images = self.vis_processors["eval"](images).unsqueeze(0).to(
device=self.visual_model.device,
dtype=self.visual_model.dtype
)
# 提取Q-Former输出的视觉特征
with torch.no_grad():
# 调用BLIP-2的内部方法获取Q-Former输出
image_embeds = self.visual_model.ln_vision(self.visual_model.visual_encoder(images))
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image_embeds.device)
query_tokens = self.visual_model.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.visual_model.Qformer(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True
)
image_features = query_output.last_hidden_state
# 投影到语言模型维度
image_embeds = self.vision_proj(image_features)
return image_embeds
def prepare_inputs(self, conversations, images=None):
"""准备模型输入"""
input_ids = []
attention_masks = []
labels = []
for conv in conversations:
# 构建Vicuna格式的提示词
prompt = ""
for turn in conv:
if turn["role"] == "user":
prompt += f"###Human: {turn['content']} "
elif turn["role"] == "assistant":
prompt += f"###Assistant: {turn['content']}</s>"
# 分词
encoded = self.tokenizer(
prompt,
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=2048
)
input_ids.append(encoded["input_ids"])
attention_masks.append(encoded["attention_mask"])
# 构建标签:只计算assistant回答部分的损失
label = encoded["input_ids"].clone()
# 找到所有###Human:的位置
human_positions = (label == self.tokenizer.encode("###Human:", add_special_tokens=False)[0]).nonzero()
for pos in human_positions:
start = pos[1] + len("###Human:")
# 找到下一个###Assistant:的位置
assistant_pos = (label[0, start:] == self.tokenizer.encode("###Assistant:", add_special_tokens=False)[0]).nonzero()
if len(assistant_pos) > 0:
end = start + assistant_pos[0][1] + len("###Assistant:")
# 将Human部分的标签设为-100(忽略)
label[0, :end] = -100
labels.append(label)
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.cat(labels, dim=0)
return input_ids, attention_masks, labels
def forward(self, input_ids, attention_mask, labels=None, images=None):
"""前向传播"""
# 获取词嵌入
inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
# 如果有图像,替换<Img>和</Img>之间的token为视觉特征
if images is not None:
image_embeds = self.encode_images(images)
# 找到所有<Img>和</Img> token的位置
img_start_positions = (input_ids == self.img_token_id).nonzero()
img_end_positions = (input_ids == self.img_end_token_id).nonzero()
for i, (start_pos, end_pos) in enumerate(zip(img_start_positions, img_end_positions)):
batch_idx, start_idx = start_pos
_, end_idx = end_pos
# 替换为对应的视觉特征
inputs_embeds[batch_idx, start_idx+1:end_idx, :] = image_embeds[i]
# 前向传播
outputs = self.language_model(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
labels=labels
)
return outputs
def generate(self, input_ids, attention_mask, images=None, **kwargs):
"""生成回答"""
# 获取词嵌入
inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
# 如果有图像,替换<Img>和</Img>之间的token为视觉特征
if images is not None:
image_embeds = self.encode_images(images)
# 找到所有<Img>和</Img> token的位置
img_start_positions = (input_ids == self.img_token_id).nonzero()
img_end_positions = (input_ids == self.img_end_token_id).nonzero()
for i, (start_pos, end_pos) in enumerate(zip(img_start_positions, img_end_positions)):
batch_idx, start_idx = start_pos
_, end_idx = end_pos
# 替换为对应的视觉特征
inputs_embeds[batch_idx, start_idx+1:end_idx, :] = image_embeds[i]
# 生成回答
outputs = self.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
**kwargs
)
return outputs
# 使用示例
if __name__ == "__main__":
# 加载模型
model = MiniGPT4()
# 准备输入
conversations = [
[
{"role": "user", "content": "<Img><ImageFeature></Img> 帮我为这个产品写一个广告文案"}
]
]
# 加载图片
from PIL import Image
image = Image.open("toucan_lamp.jpg")
# 准备输入
input_ids, attention_mask, _ = model.prepare_inputs(conversations, images=[image])
# 生成回答
outputs = model.generate(
input_ids,
attention_mask,
images=[image],
max_new_tokens=200,
temperature=0.7
)
# 解码回答
print(model.tokenizer.decode(outputs[0], skip_special_tokens=True))
五、MiniGPT-4的神奇能力展示
MiniGPT-4展现出了很多令人惊叹的 emergent 能力,这些能力在之前的开源多模态模型中从未出现过。
5.1 解释网络迷因
MiniGPT-4能看懂网络迷因,理解其中的幽默之处。
表格6:周一狗迷因解释对比
| 模型 | 回答 |
|---|---|
| 用户 | 解释一下这个迷因为什么好笑? |
| BLIP-2 | 一只狗躺在地板上,上面写着"周一,就是周一"。 |
| MiniGPT-4 | 这个迷因好笑是因为它展示了一只狗趴在地板上,头靠在爪子上,看起来又累又困。上面的文字"周一,就是周一"增加了幽默感,它暗示这只狗的感受和很多人在周一的感受一样——周一通常被认为是一周中最可怕的一天。这个迷因很有共鸣,也很有趣,因此在互联网上很受欢迎。 |
| 出处:论文图4a |
5.2 根据手绘草图生成HTML网站
MiniGPT-4能看懂你的手绘草图,然后生成完整的HTML/JS代码,实现一个可交互的网站!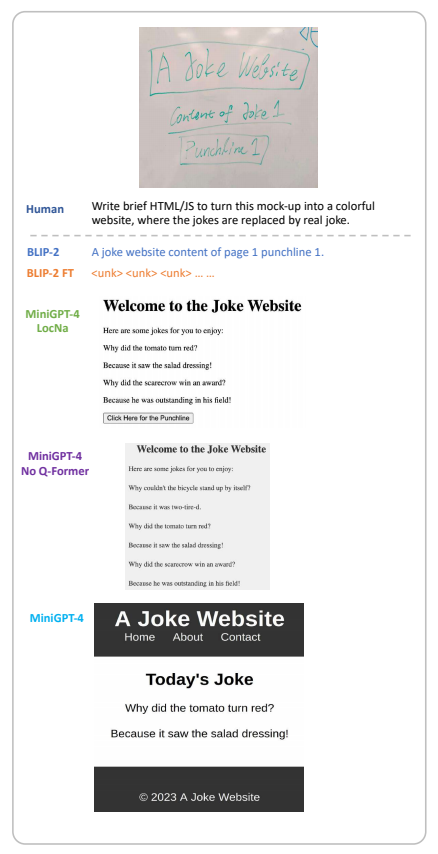
图片2:根据手绘草图生成HTML网站
出处:论文图4b
5.3 根据食物照片生成菜谱
给MiniGPT-4看一张龙虾的照片,它能立刻给你生成一份详细的烤龙虾菜谱!
表格7:烤龙虾菜谱生成
| 模型 | 回答 |
|---|---|
| 用户 | 我应该怎么做这个菜? |
| BLIP-2 | 预热烤箱到400华氏度,在烤盘上铺上羊皮纸。 |
| MiniGPT-4 | 要做这道菜,你需要以下食材: * 4只大龙虾 * 2汤匙橄榄油 * 2瓣大蒜,切碎 * 1茶匙干百里香 * 1茶匙干牛至 * 1/2茶匙辣椒粉 * 盐和胡椒粉,适量 * 4个柠檬角,用于上菜 步骤: 1. 预热烤箱到400°F(200°C)。 2. 在一个大烤盘中,将龙虾与橄榄油、大蒜、百里香、牛至、辣椒粉、盐和胡椒粉拌匀。 3. 将龙虾放入预热的烤箱中烤20-25分钟,直到完全熟透。 4. 从烤箱中取出龙虾,让它们冷却几分钟。 5. 配上柠檬角一起上桌。 |
| 出处:论文图11 |
5.4 其他神奇能力
- 写广告文案:给它看一张巨嘴鸟台灯的照片,它能写出一段吸引人的广告
- 写诗歌:给它看一张夕阳下男人和狗的照片,它能写出一首感人的诗
- 电影介绍:给它看《教父》的海报,它能详细介绍这部电影的剧情和演员
- 植物诊断:给它看一张有斑点的植物叶子照片,它能诊断出是真菌感染,并给出治疗方案
六、局限性与未来方向
虽然MiniGPT-4已经非常强大,但它仍然有一些明显的局限性:
6.1 幻觉问题
MiniGPT-4经常会生成图片中不存在的东西。比如给它看一张没有桌布的餐厅照片,它可能会说"桌子上铺着白色的桌布"。生成的内容越长,幻觉问题越严重。
6.2 空间理解能力差
MiniGPT-4对空间位置的理解很弱,经常分不清左右、上下。比如给它看一张窗户在左边的照片,它可能会说"窗户在照片的右边"。
6.3 传统VQA任务表现一般
在传统的VQA数据集如AOK-VQA和GQA上,MiniGPT-4的表现不如BLIP-2。这是因为BLIP-2专门在这些数据集上进行了大量的训练,而MiniGPT-4的训练目标是通用的视觉对话,而不是特定的VQA任务。
未来的研究方向包括:
- 解决幻觉问题,让生成的内容更准确
- 提升空间理解能力
- 支持多轮对话和上下文学习
- 结合工具使用能力,让MiniGPT-4能调用外部工具来解决更复杂的问题
总结
MiniGPT-4是多模态大模型发展史上的一个里程碑式的工作。它用最简单的架构和最少的训练成本,证明了一个颠覆认知的结论:多模态大模型的能力上限,是由语言模型决定的。
MiniGPT-4的成功告诉我们:
- 简单就是美:有时候最简单的架构反而能取得最好的效果
- 数据质量 > 数据数量:3500条高质量数据带来的提升,超过了500万条低质量数据
- 站在巨人的肩膀上:充分利用已经训练好的单模态模型,可以大大降低多模态模型的训练成本
MiniGPT-4的开源也极大地推动了多模态大模型的研究和应用。现在,任何人都可以在自己的电脑上运行一个强大的视觉助手,这为很多新的应用场景打开了大门。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)