一文读懂 Agent Skill 编写和使用
什么是 Agent SKILL?
Skill 可以理解为专业技能的一系列文本表示。
比如一个程序员,就需要具备设计架构,编写代码,调试 bug 的配套技能。
提示词和 SKILL 分不清楚,为什么要这么多事?
| 概念 | 类比 | 作用 |
|---|---|---|
| Prompt | 临时任务说明 | 临时交流,告诉 AI 这一次怎么做 |
| SKILL | 操作手册 / 固定流程 | 使用更专业的流程,告诉 AI 以后遇到这类任务都怎么做 |
一个例子是:
Prompt —— 像你去餐厅点菜:
“我要一份番茄牛肉面,少辣,多加葱。”
Skill —— 像餐厅后厨的一整套出餐流程:
“接单 → 准备食材 → 煮面 → 炒汤底 → 控制火候 → 摆盘 → 检查口味 → 出餐。”
Prompt 是“这次怎么做”;Skill 是“以后遇到这类任务都按什么规范做”。
所以对于专业的任务,更推荐用 SKILL 完成。
今天的目的是生成一张下面这样的海报。

Skill 编写
以 CLAUDE CODE 的 Agent Skill 规范包括:
- 开发流程:SKILL.md
- 参考文档:references
- 开发工具:scripts
- 静态资源:assets
每个 SKILL 必须要有 SKILL.md 文件,其他为可选。
一个完整的技能是一个文件夹
.claude/skills/my_skill
|---SKILL.md # 主文件 (必选)
|---references/ # 附加文档
|---scripts/ # 可执行脚本
|---assets / # 静态文件
每个 SKILL 必须在路径 .claude/skills/ 下,才会被检测到。
建议目录是
- Windows
C:\Users\baimo\.claude\skills - Linux
~/.claude\skills
一个示例
---
name: creative-poster
description: 为用户生成具有吉卜力动画气质的插画创意与图片。当用户说要做某种插画(人物、场景、海报、头像、封面、故事分镜等)时,你需要先询问用户是否需要生成图片;如果需要,则将创意转化为图片生成提示词并调用生成图片流程;如果不需要,则直接输出完整插画创意描述。
---
# creative-poster 为用户生成具有吉卜力动画气质的插画创意方案或图片
## 风格核心元素
- 风格参考:吉卜力动画气质
- 整体气质:温暖、治愈、童话感、生活感、自然感、轻幻想
- 画面感觉:手绘动画感、细腻背景、柔和光线、电影分镜感
- 常见题材:乡村、森林、小镇、天空、列车、海边、猫、少女、少年、日常奇遇
## 你的任务
当用户说要做某种插画、头像、海报、封面、壁纸、分镜图片或视觉物料时,你需要输出这个物料的吉卜力动画气质插画创意描述或图片。
元信息
元信息是 SKILL 关键组成,可以极大的减少 AI token 消耗量。对于 AI 来说,用户的需求,先要查找是否有对应的 SKILL 是否符合要求,如果有则优先调用 SKILL 完成。
AI 查询 SKILL 不会遍历 SKILL 的所有内容,只读取元信息,也就是 name 和 description。因此,元信息必须要精简且准确,提高 AI 查找 SKILL 的命中率。
包括
- name
- description
---
name: creative-poster
description: 为用户生成具有吉卜力动画气质的插画创意与图片。当用户说要做某种插画(人物、场景、海报、头像、封面、故事分镜等)时,你需要先询问用户是否需要生成图片;如果需要,则将创意转化为图片生成提示词并调用生成图片流程;如果不需要,则直接输出完整插画创意描述。
---
指令
这里的内容不止提示词,同时还包括了代码,任务目标,任务结果
## 你的任务
当用户说要做某种插画、头像、海报、封面、壁纸、分镜图片或视觉物料时,你需要输出这个物料的吉卜力动画气质插画创意描述或图片。
按以下步骤顺序执行:
1. 使用 `AskUserQuestion` 询问用户:是否需要生成图片?
- 如果否:直接输出完整的插画创意描述、构图方案和绘图提示词,结束流程。
- 如果是:继续步骤 2。
2. 确认输出路径:使用 `AskUserQuestion` 询问用户输出路径。
- 如果用户指定了路径,则使用用户指定路径。
- 如果未指定,默认路径为 `./images`。
3. 调用图片生成脚本 `.claude/skills/creative-poster/generate_image.py`,传入最终图片提示词。
- 如果用户提供了参考图、角色图、品牌图、草图或背景素材,将 `assets` 下的图片资源也作为参数传入。
4. 生成完成后,返回图片保存路径和简短说明。
脚本
这里的脚本是用来辅助提示词生成图片内容。
你不需要理解脚本内容,只需要放到 scripts 中等待调用即可。
其中需要安装的包,Agent 会帮你自动安装。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
调用 Google Gemini Nano Banana Pro (gemini-3-pro-image-preview) API 生成图片,支持参考图输入。
依赖:
- Python 3.8+
- google-genai (pip install google-genai)
- Pillow (pip install Pillow)
"""
import argparse
import json
import os
import re
import sys
import time
from pathlib import Path
from typing import List, Optional
DEFAULT_MODEL = "gemini-3-pro-image-preview"
DEFAULT_ASPECT_RATIO = "1:1"
DEFAULT_RESOLUTION = "1K"
VALID_ASPECT_RATIOS = {
"1:1", "1:4", "1:8", "2:3", "3:2", "3:4",
"4:1", "4:3", "4:5", "5:4", "8:1", "9:16", "16:9", "21:9",
}
# 512 仅 gemini-3.1-flash-image-preview 支持,Pro 模型最低 1K
VALID_RESOLUTIONS = {"1K", "2K", "4K"}
VALID_TYPES = {
"illustration",
"character",
"scene",
"poster",
"cover",
"avatar",
"wallpaper",
"storyboard",
"social",
"banner",
}
def eprint(*args, **kwargs):
print(*args, file=sys.stderr, **kwargs)
def read_api_key(cli_key: Optional[str]) -> str:
api_key = cli_key or os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError(
"未提供 API Key。请使用 --api-key 传入,或先设置环境变量 GEMINI_API_KEY。"
)
return api_key
def slugify(text: str, max_len: int = 40) -> str:
text = re.sub(r"[^A-Za-z0-9\u4e00-\u9fff]+", "_", text).strip("_")
if not text:
return "image"
return text[:max_len]
def ensure_output_path(output: str, material_type: str, prompt: str) -> Path:
output_path = Path(output)
if output_path.suffix.lower() in {".png", ".jpg", ".jpeg", ".webp"}:
output_path.parent.mkdir(parents=True, exist_ok=True)
return output_path
output_path.mkdir(parents=True, exist_ok=True)
stem = f"gemini_{material_type}_{slugify(prompt, 30)}_{time.strftime('%Y%m%d_%H%M%S')}"
return output_path / f"{stem}.png"
def build_text_prompt(user_prompt: str, material_type: str) -> str:
material_hint = {
"illustration": "Create a detailed illustration",
"character": "Create a character-focused illustration",
"scene": "Create an environmental scene illustration",
"poster": "Create a poster-style illustration with strong composition",
"cover": "Create a cover image with strong focal point and clean layout",
"avatar": "Create an avatar / portrait illustration",
"wallpaper": "Create a wallpaper-style wide composition",
"storyboard": "Create a storyboard-like cinematic frame",
"social": "Create a social-media visual illustration",
"banner": "Create a banner-style wide illustration",
}.get(material_type, "Create an illustration")
return f"{material_hint}. {user_prompt}".strip()
def load_reference_images(assets: List[str]):
"""加载参考图为 PIL Image 对象列表。"""
from PIL import Image
images = []
for path in assets:
p = Path(path)
if not p.exists():
raise FileNotFoundError(f"参考图不存在: {path}")
images.append(Image.open(str(p)))
return images
def generate_image(
prompt: str,
material_type: str,
aspect_ratio: str,
resolution: str,
assets: Optional[List[str]],
api_key: str,
model: str = DEFAULT_MODEL,
):
"""调用 Gemini API 生成图片,返回 PIL Image 对象。"""
from google import genai
from google.genai import types
client = genai.Client(api_key=api_key)
text_prompt = build_text_prompt(prompt, material_type)
contents = [text_prompt]
if assets:
contents.extend(load_reference_images(assets))
response = client.models.generate_content(
model=model,
contents=contents,
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio=aspect_ratio,
image_size=resolution,
),
),
)
for part in response.parts:
image = part.as_image()
if image is not None:
return image
raise RuntimeError("API 未返回图片数据。请检查 prompt 是否触发内容过滤。")
def save_image(image, out_path: Path) -> Path:
image.save(str(out_path))
return out_path
def summarize_args(args: argparse.Namespace):
eprint("[INFO] 生成参数:")
eprint(f" - type: {args.type}")
eprint(f" - aspect-ratio: {args.aspect_ratio}")
eprint(f" - resolution: {args.resolution}")
eprint(f" - output: {args.output}")
eprint(f" - model: {args.model}")
eprint(f" - assets: {args.assets if args.assets else 'None'}")
def main():
parser = argparse.ArgumentParser(
description="调用 Google Gemini Nano Banana Pro (gemini-3-pro-image-preview) 生成图片"
)
parser.add_argument("prompt", help="具体需求描述 / 生图提示词")
parser.add_argument("-t", "--type", dest="type", default="illustration",
help=f"物料类型,支持:{', '.join(sorted(VALID_TYPES))}")
parser.add_argument("-o", "--output", default="./images",
help="输出路径。可以是目录,也可以是完整文件路径(如 ./images/out.png)")
parser.add_argument("--assets", nargs="*", default=None,
help="参考图片路径列表(最多 14 张),例如 --assets assets/a.png assets/b.png")
parser.add_argument("--aspect-ratio", default=DEFAULT_ASPECT_RATIO,
choices=sorted(VALID_ASPECT_RATIOS),
help=f"图片宽高比,默认 {DEFAULT_ASPECT_RATIO}")
parser.add_argument("--resolution", default=DEFAULT_RESOLUTION,
choices=sorted(VALID_RESOLUTIONS),
help=f"图片分辨率,支持 1K / 2K / 4K,默认 {DEFAULT_RESOLUTION}")
parser.add_argument("--model", default=DEFAULT_MODEL,
help=f"模型名称,默认 {DEFAULT_MODEL}")
parser.add_argument("--api-key", default=None,
help="Gemini API Key;如果不传则从环境变量 GEMINI_API_KEY 读取")
args = parser.parse_args()
if args.type not in VALID_TYPES:
raise ValueError(f"不支持的物料类型: {args.type}\n支持类型:{', '.join(sorted(VALID_TYPES))}")
api_key = read_api_key(args.api_key)
out_path = ensure_output_path(args.output, args.type, args.prompt)
summarize_args(args)
eprint("[INFO] 正在调用 Gemini API 生成图片...")
image = generate_image(
prompt=args.prompt,
material_type=args.type,
aspect_ratio=args.aspect_ratio,
resolution=args.resolution,
assets=args.assets,
api_key=api_key,
model=args.model,
)
saved = save_image(image, out_path)
eprint(f"[INFO] 图片已保存至: {saved.resolve()}")
output = {
"ok": True,
"model": args.model,
"type": args.type,
"aspect_ratio": args.aspect_ratio,
"resolution": args.resolution,
"prompt": args.prompt,
"assets": args.assets or [],
"saved_path": str(saved.resolve()),
}
print(json.dumps(output, ensure_ascii=False, indent=2))
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
eprint("\n[ERROR] 用户中断执行")
sys.exit(130)
except Exception as e:
eprint(f"[ERROR] {e}")
sys.exit(1)
最终的目录结构
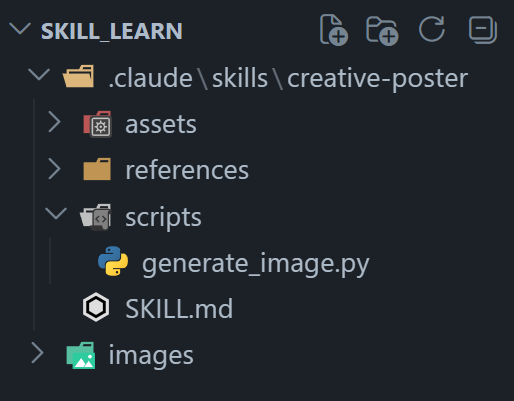
CLAUDE CODE 默认模型切换
CLAUDE CODE 官方模型由于某些原因可能不稳定,这里建议使用软件可以灵活切换不同的模型。
如果你可以用 CLAUDE CODE 官方模型,可以直接跳过这部分。
使用工具 CC Switch 来切换 CLAUDE CODE 默认使用的模型,下载地址为:
https://github.com/farion1231/cc-switch/releases/tag/v3.14.1
以 Window 为例,进入链接地址后,在页面最下面,下载 msi 安装包
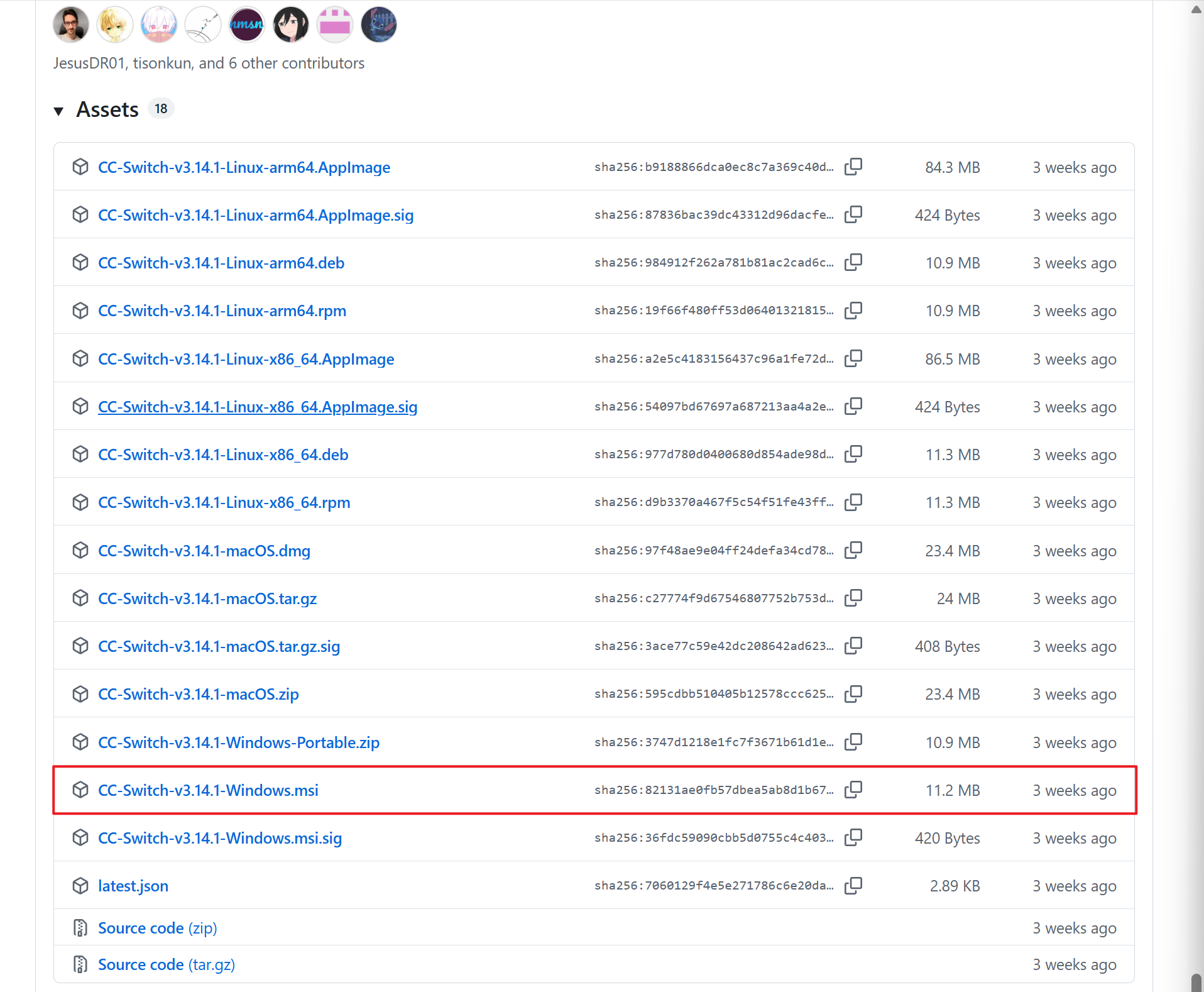
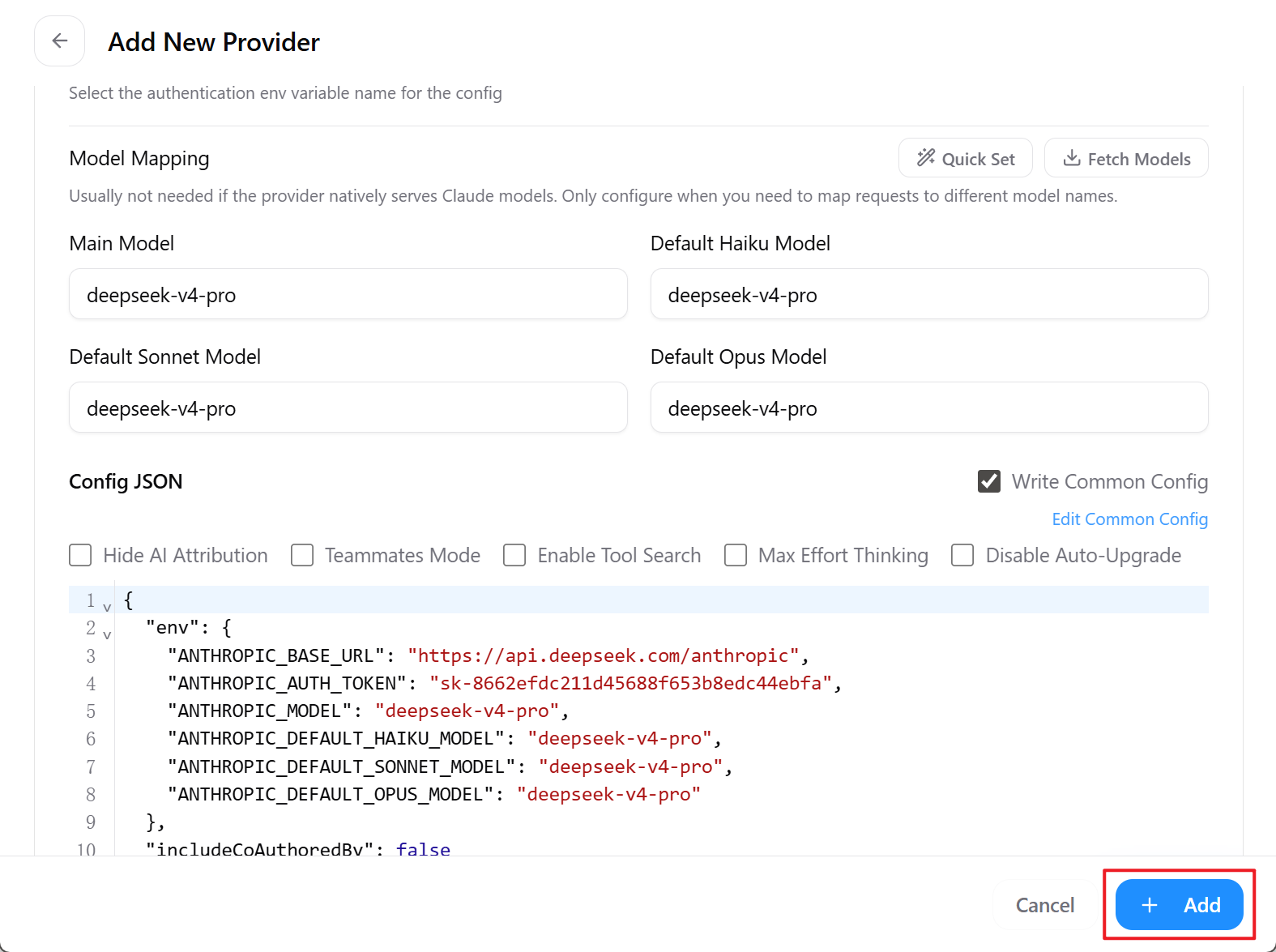
点击右上角的添加模型
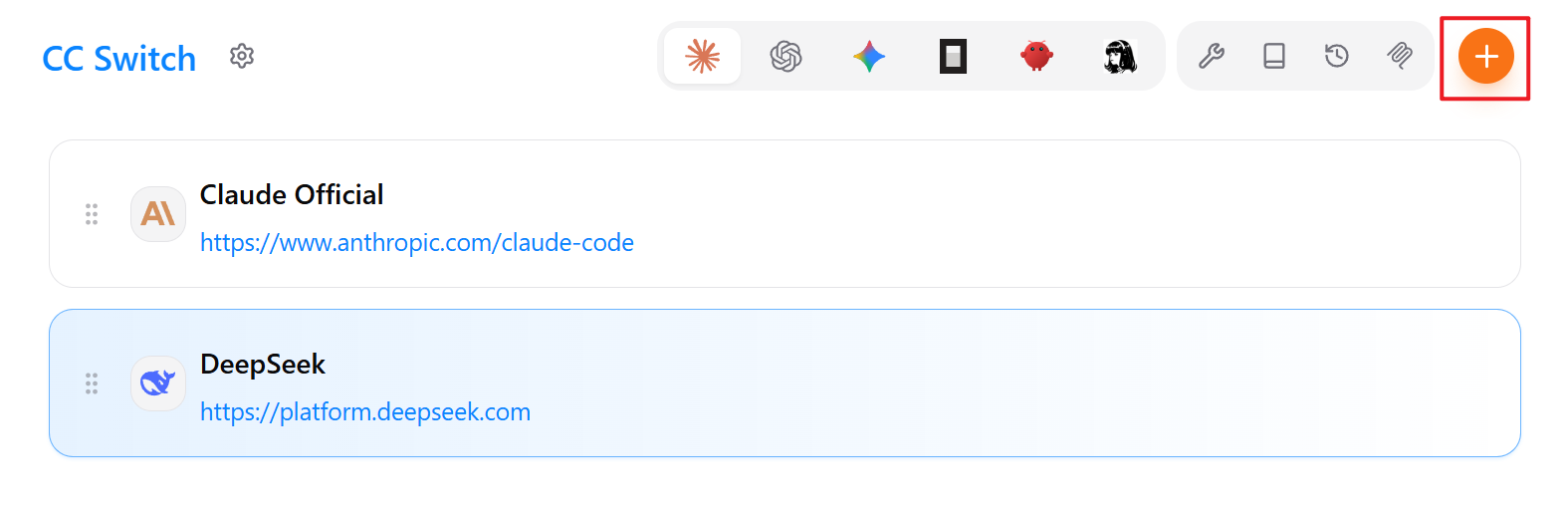
以添加 DeepSeek 模型为例,点击 DeepSeek
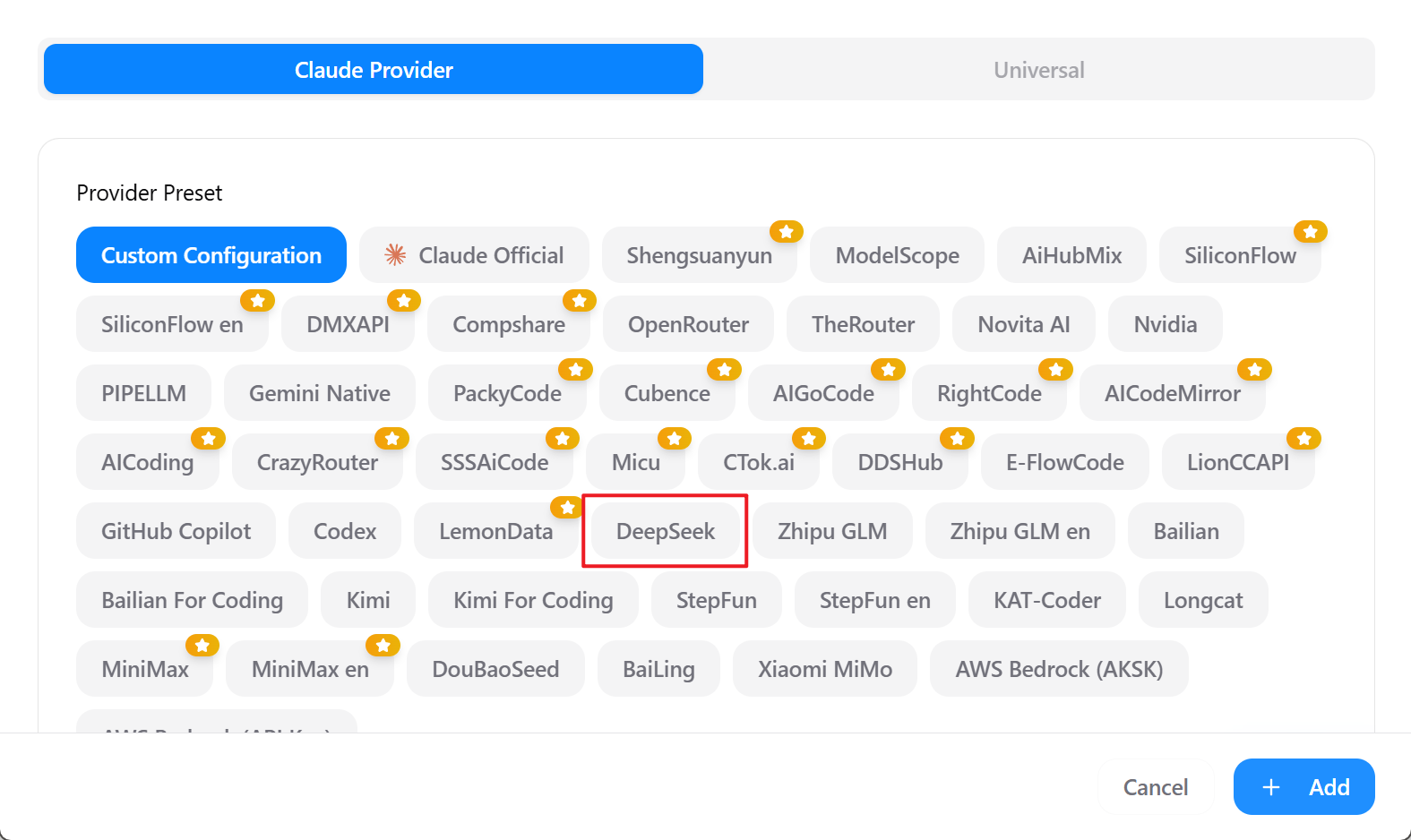
进入链接:https://platform.deepseek.com/api_keys 申请 API keys
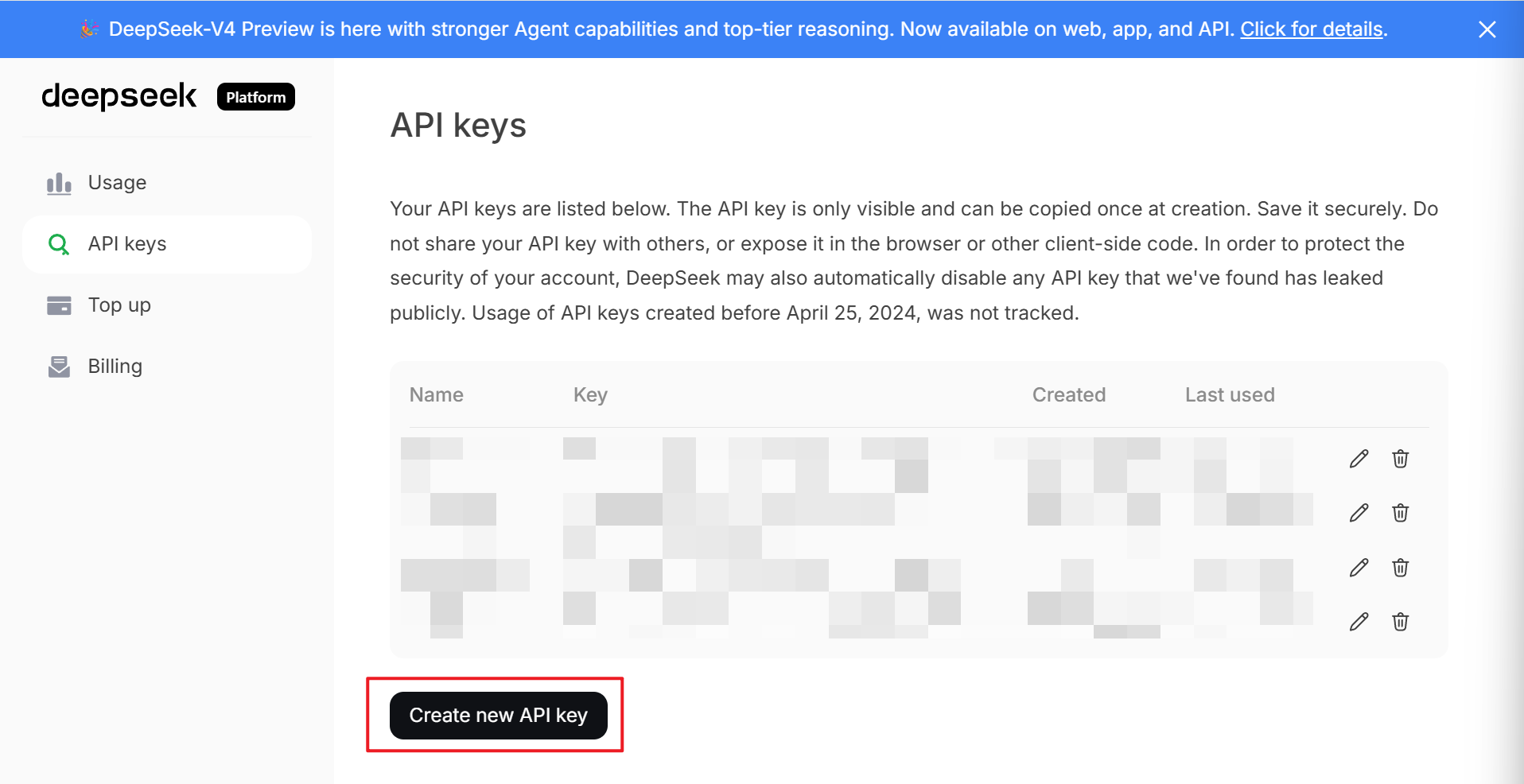
输入 API key 别名
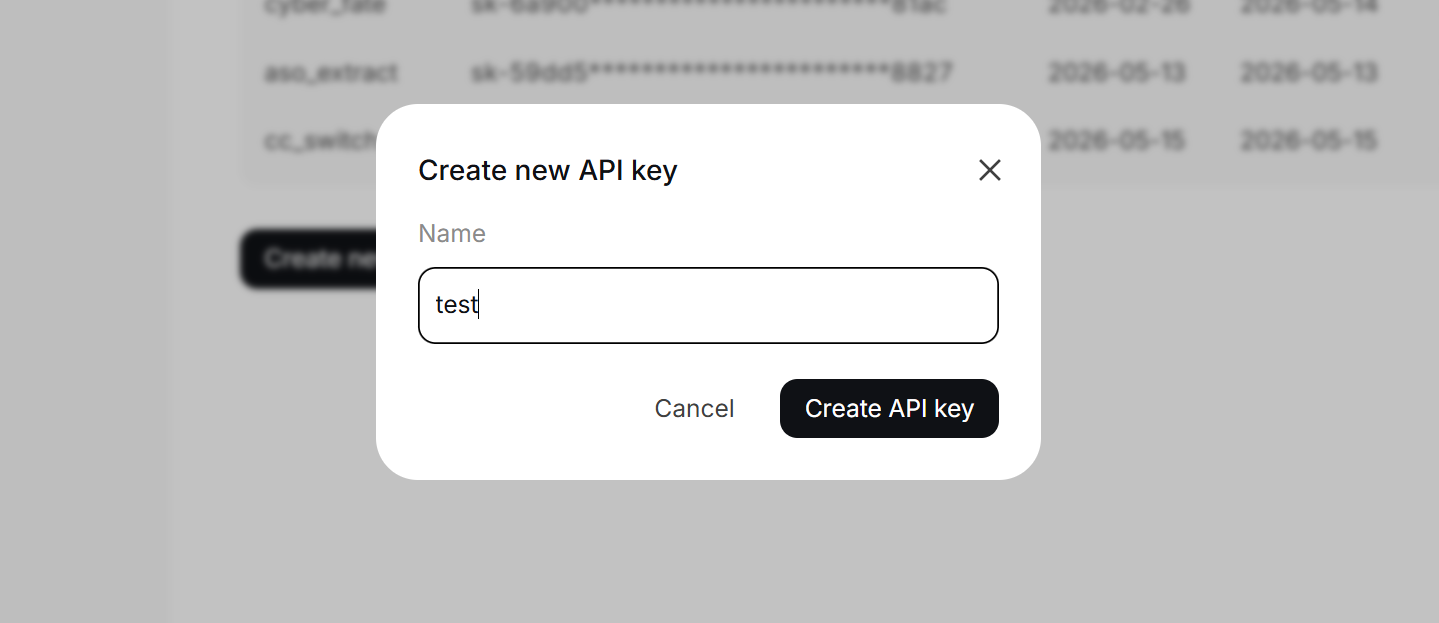
将 API key 复制到 CC Switch 的界面中
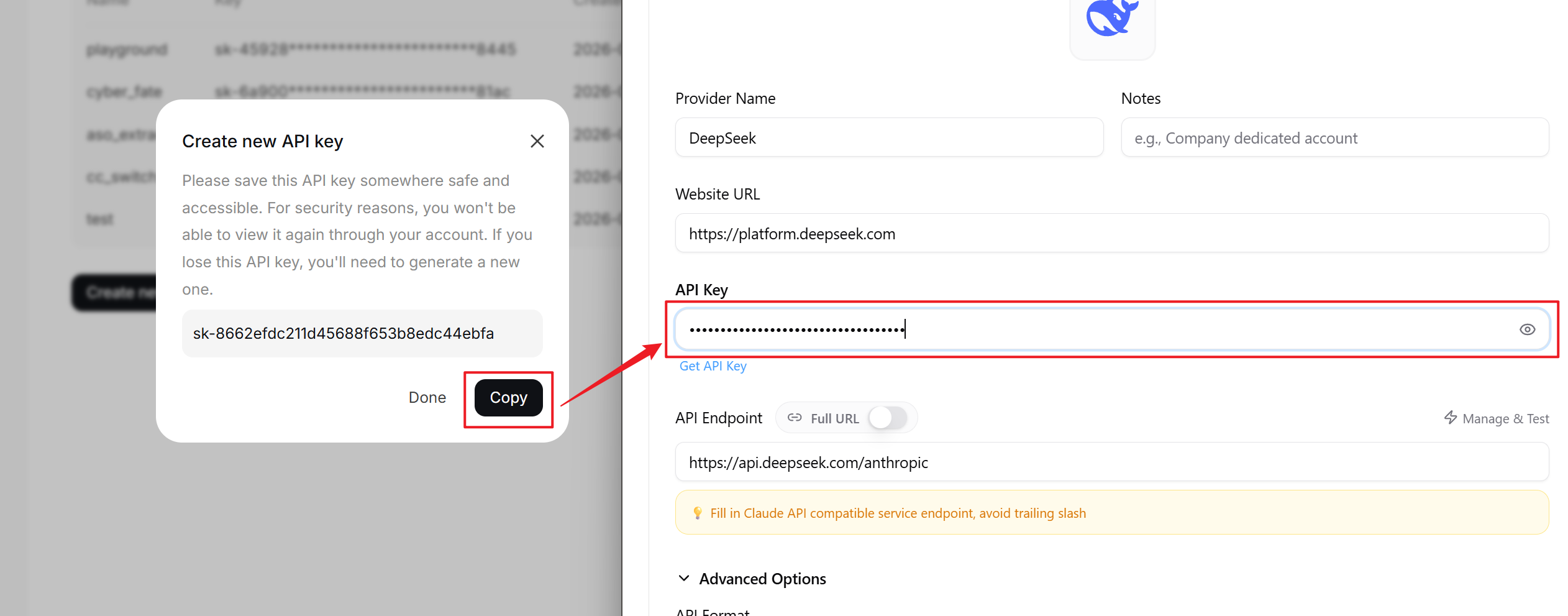
查看 DeepSeek 文档中,目前可用模型名称,设置到 CC Switch 的界面中
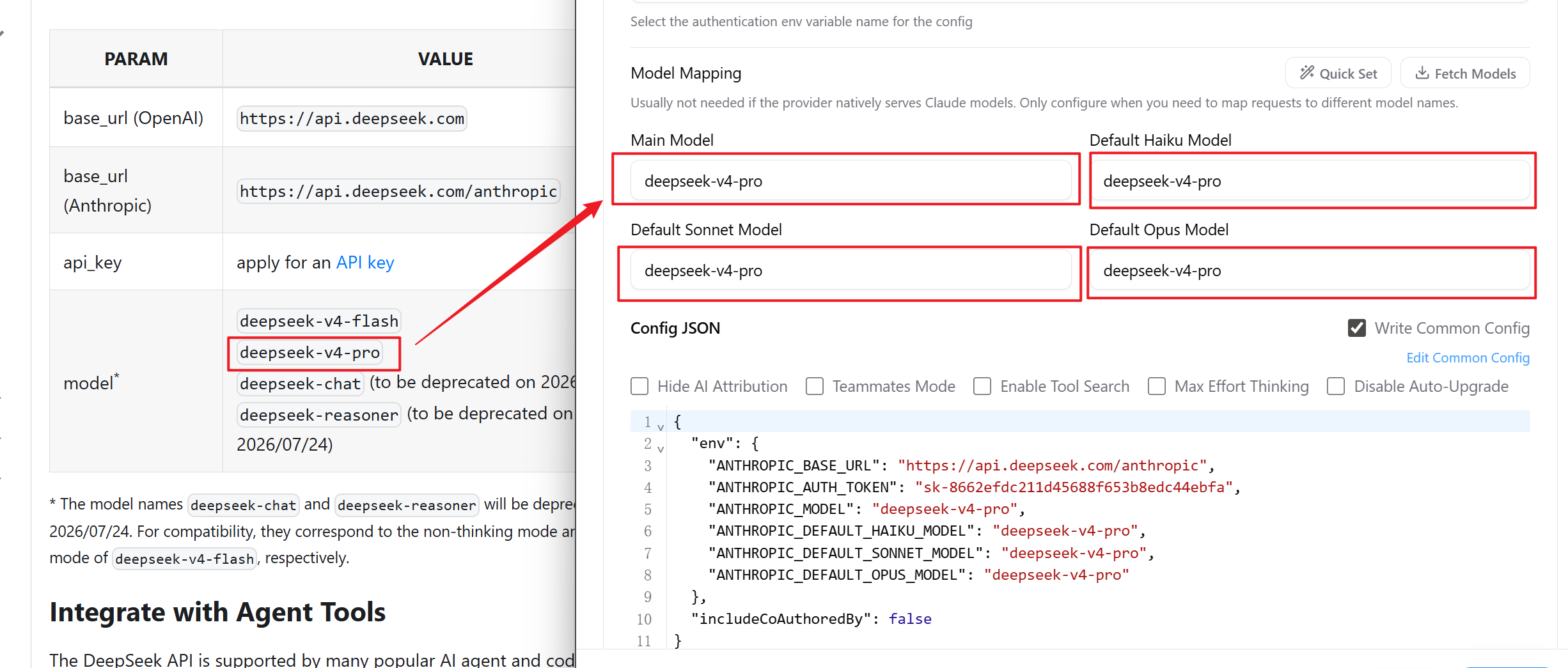
最后,点击 Add 加入
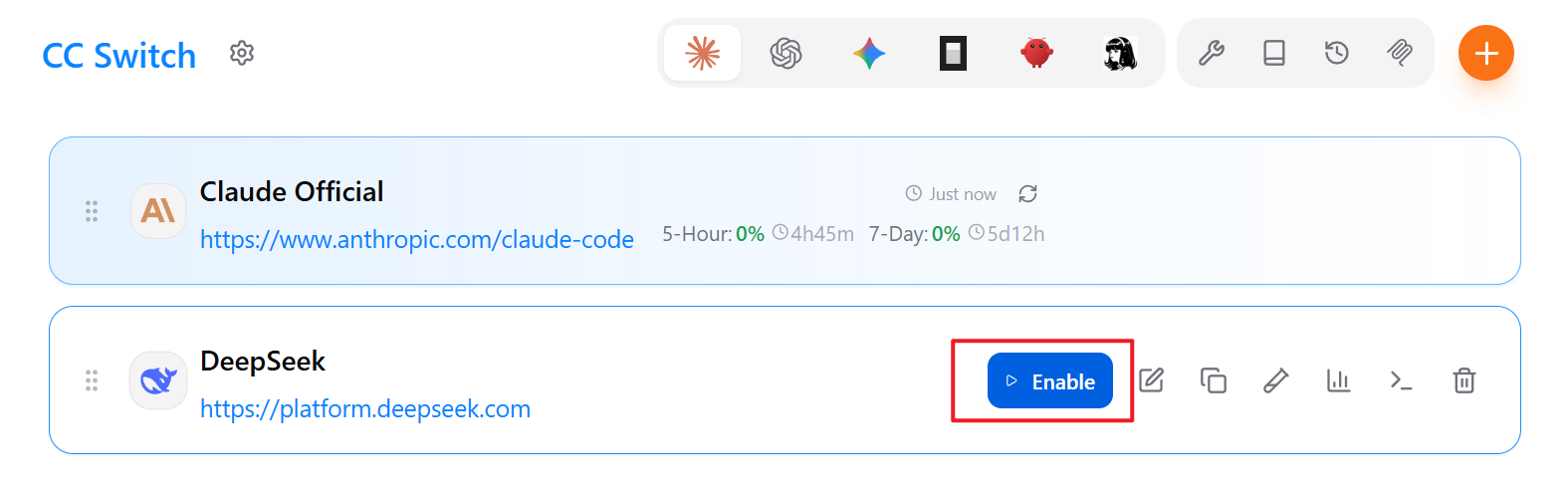
在 CC Switch 界面中启用模型
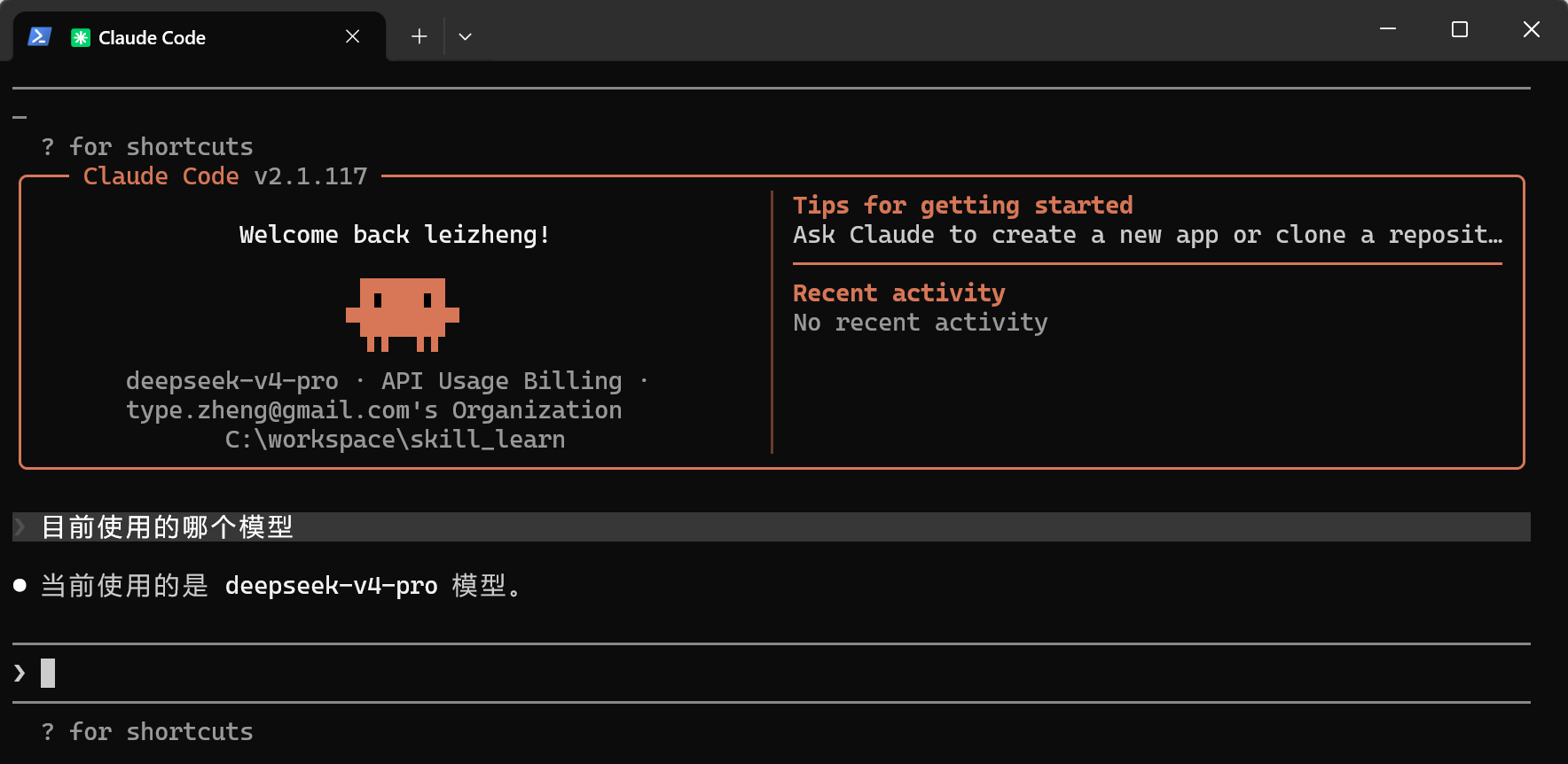
验证模型是否配置成功,进入
输入提示词
使用的模型是哪个
如果显示我们选择的模型,则切换正确
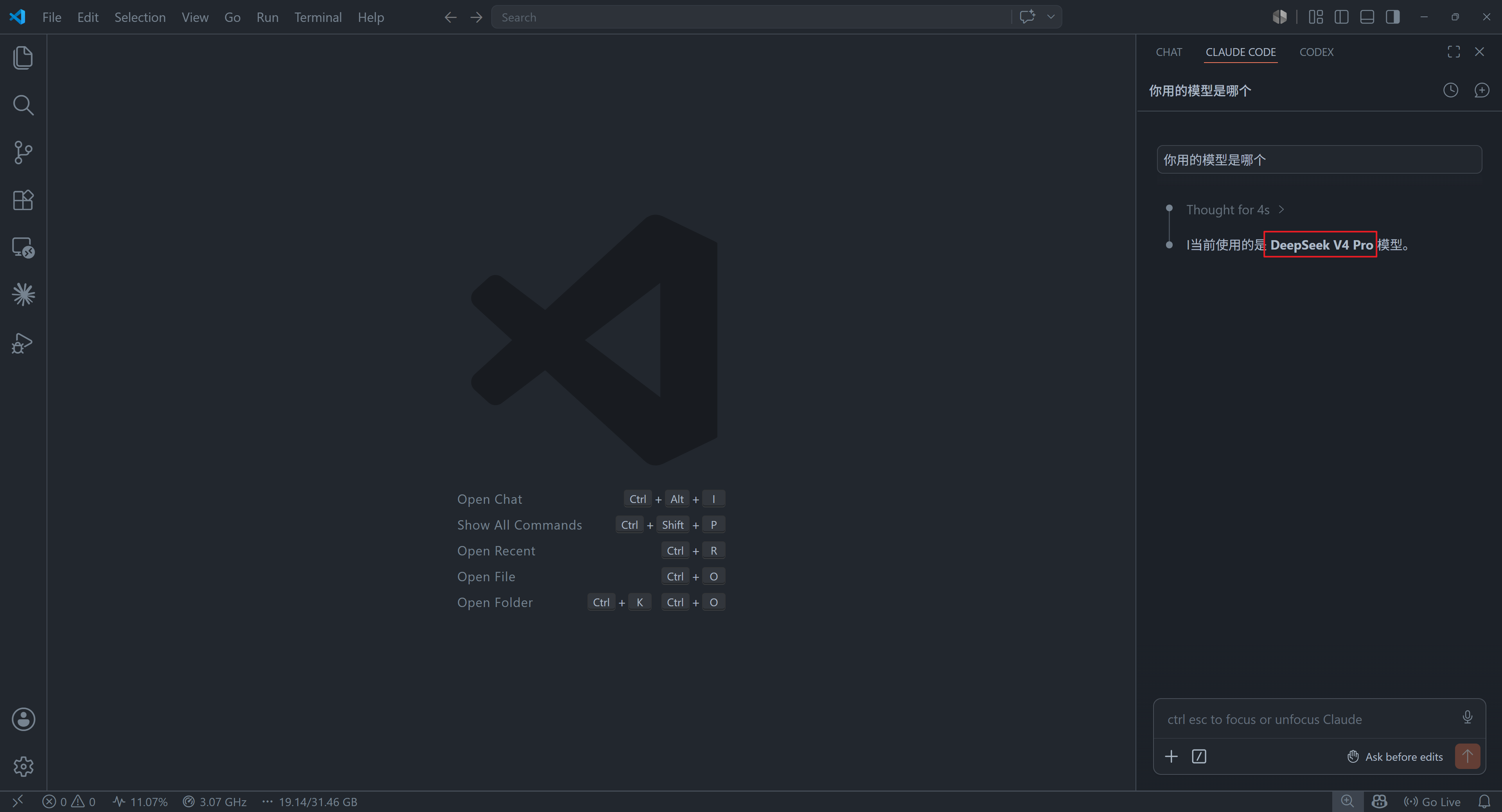
在 vscode 同样也可以使用,这是一个全局的修改
视觉模型设置
百炼视觉模型 qwen-image-2.0-pro
API 申请地址:https://bailian.console.aliyun.com/cn-beijing?tab=model#/model-usage?modelType=Vision
google 视觉模型 gemini-3-pro-image-preview
这个也就是 Nano banana Pro 的模型名,API 申请地址:https://aistudio.google.com/api-keys
注意:建议将 API_KEY 都写入环境变量,方便今后的脚本读取,提高安全性。
Linux 用户写入 ~/.bashrc
Windows 用户写入系统或用户环境变量
申请到的 API_KEY 按照固定变量名设置,方便脚本调用
# Google
GEMINI_API_KEY="XXXXXXXXXXXXXXXXXXXXXXXXXXXX"
# 百炼
DASHSCOPE_API_KEY="XXXXXXXXXXXXXXXXXXXXXXXXXXXX"
设置完成后重启 vscode
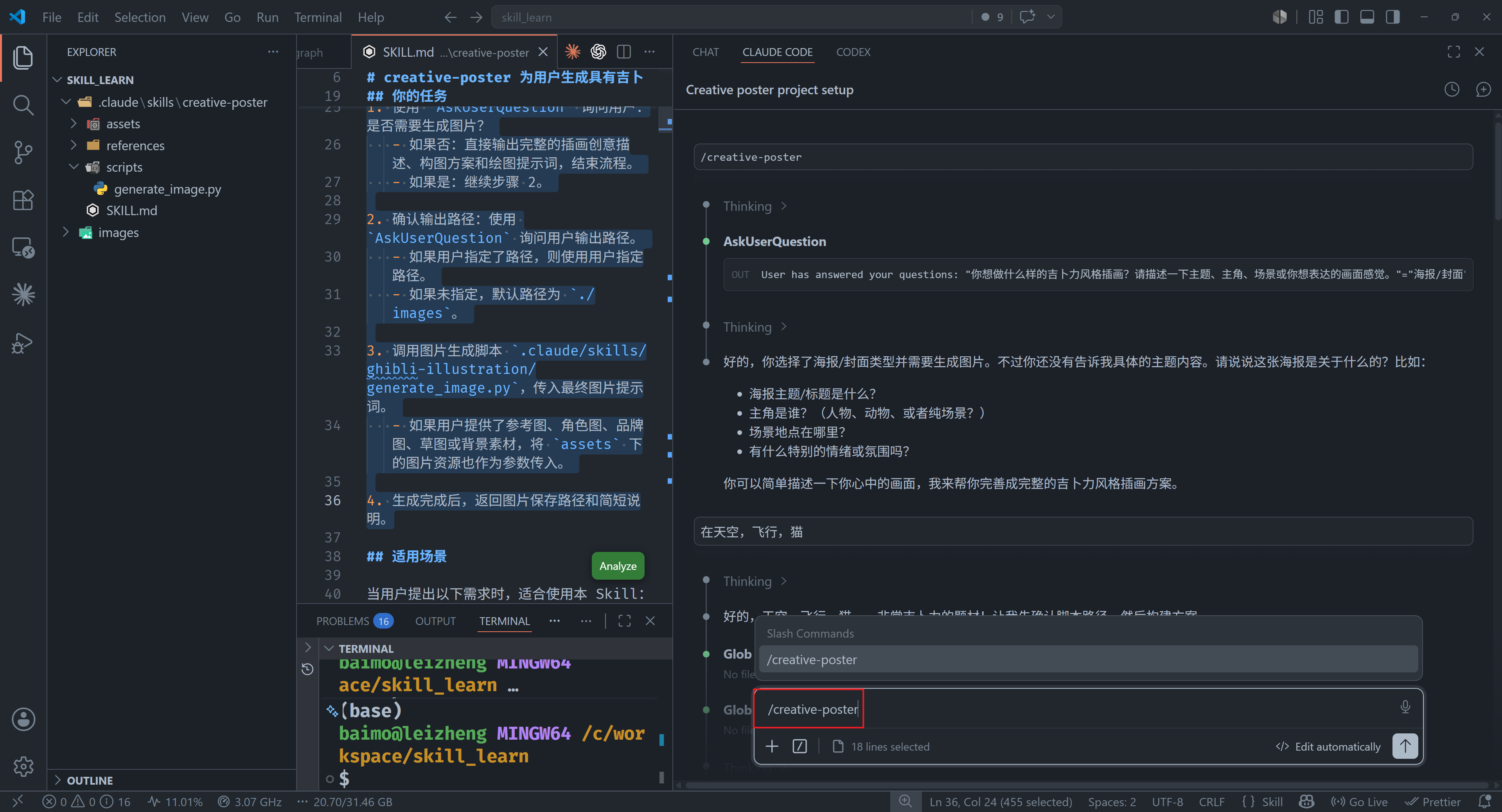
使用 SKILL 生成内容
在对话框中输入
/creative-poster
显式调用 SKILL,简单说明绘制内容后,生成图片会出现在项目目录文件夹下。
最终的成品:

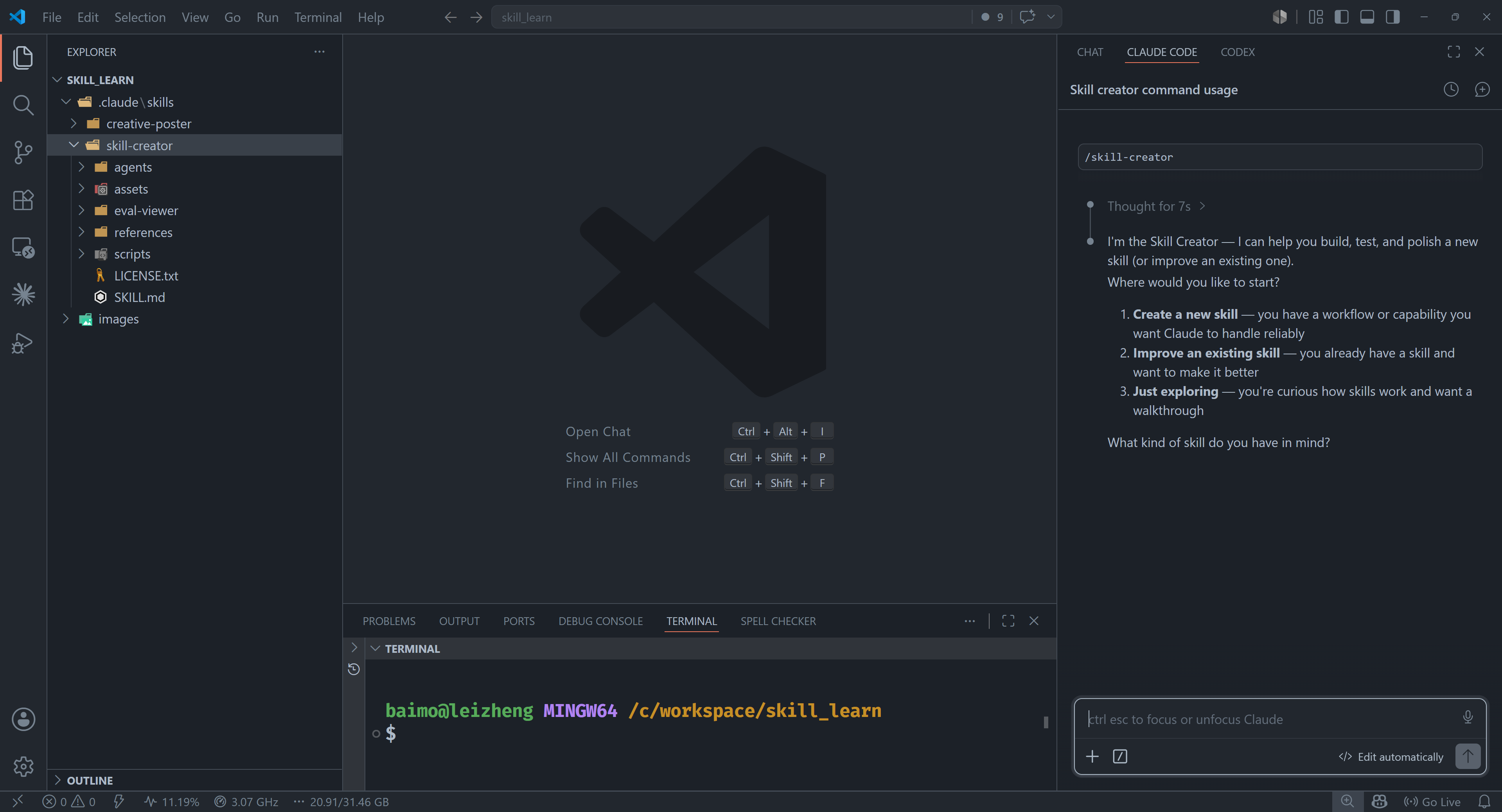
自动生成 SKILL
https://github.com/anthropics/skills/tree/main
官方有一个 SKILL Creator,可以用来根据描述生成所需要的 SKILL
将该 skill creator 下载到 skills 目录就可以使用了
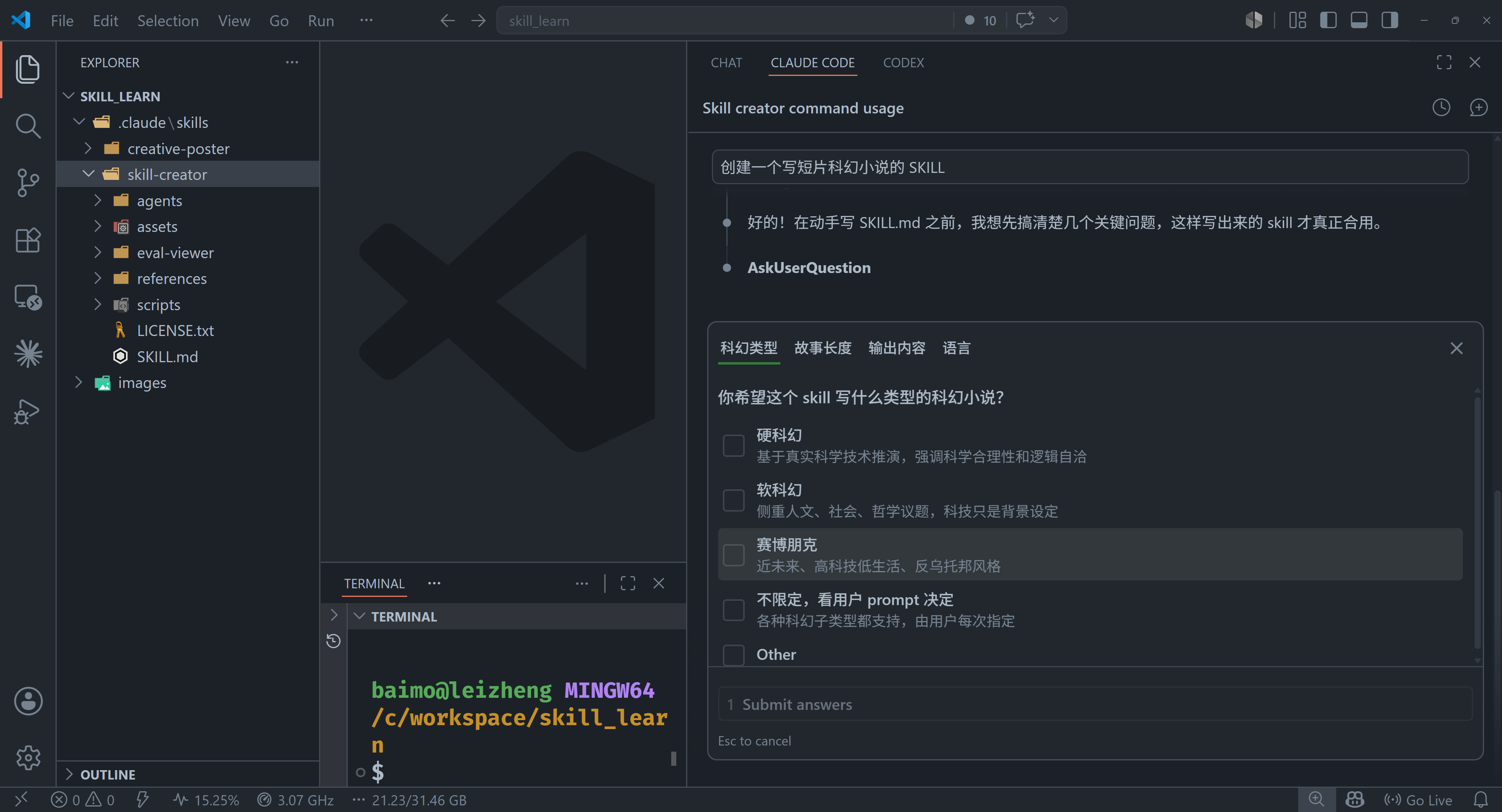
一个例子是
可能用上的技巧
调整 CLAUDE CODE 的位置
右上角打开对话框,切换到 CLAUDE CODE
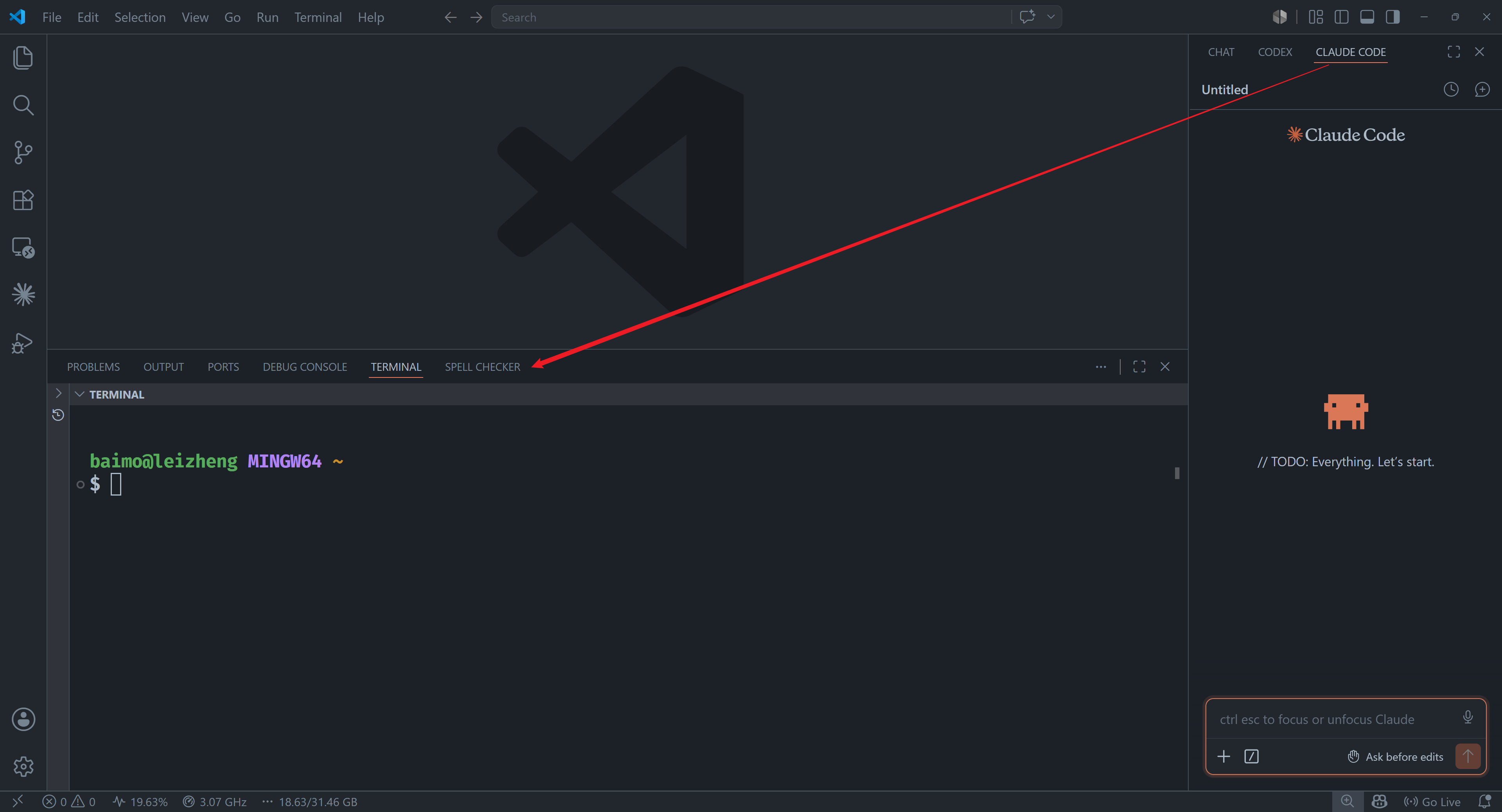
可以将 CLAUDE CODE 放在 Terminal 的位置
其他 SKILL
CLAUDE CODE 官方 SKILL:
https://raw.githubusercontent.com/anthropics/skills/refs/heads/main/skills/pdf/SKILL.md

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)