Claude Code自动记忆系统:四种记忆类型详解
本文详细介绍了Claude Code自动记忆系统的四种记忆类型:用户画像(user)、反馈偏好(feedback)、项目上下文(project)和参考指针(reference)。用户画像记录用户身份、技能等个人信息,用于个性化回答;反馈偏好记录用户纠正和认可的行为准则;项目上下文保存代码之外的业务背景和约束;参考指针存储外部资源链接。每种类型都有明确的存储规则和使用场景,形成完整的记忆体系,帮助A
目录
Claude Code自动记忆系统:四种记忆类型详解 —— 小白也能看懂
Claude Code中,自动记忆系统将记忆严格限定为 4 种类型,形成一个封闭的分类体系。每种类型有明确的“何时保存”和“如何使用”规则。核心原则:只有无法从代码/git 推导出来的信息才值得存为记忆。代码模式、架构、git 历史、文件结构……这些通过 grep/git/CLAUDE.md 就能查到,不应存为记忆。
1 四种类型速览
通过Claude Code源码src/memdir/memoryTypes.ts , 可以清楚的知道Claude Code 的记忆系统将记忆分为四类,这套分类体系解决了“谁有资格被记住”的问题。我们用下图来展示四个分类:
┌──────────────────────────────────────────────────────────────────┐
│ 记忆四分类 │
│ │
│ user feedback project reference │
│ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │ 👤 │ │ 📝 │ │ 📋 │ │ 🔗 │ │
│ │ 用户 │ │ 反馈 │ │ 项目 │ │ 参考 │ │
│ │ 画像 │ │ 偏好 │ │ 上下文│ │ 指针 │ │
│ └──────┘ └──────┘ └──────┘ └──────┘ │
│ │
│ "你是谁" "怎么做" "为什么做" "去哪找" │
│ 身份/角色 行为准则 背景/动机 外部资源 │
└──────────────────────────────────────────────────────────────────┘
~/.claude/
└── projects/
└── <sanitized-git-root>/ # Git 仓库根路径的 sanitized 版本
└── memory/ # getAutoMemPath() 返回值
├── MEMORY.md # 索引文件(入口文件,上限 200 行 / 25KB)
├── user_role.md # 记忆文件(以下为示例)
├── feedback_testing.md
├── project_deadline.md
├── reference_dashboard.md
├── logs/ # KAIROS 助手模式的每日日志
│ └── YYYY/
│ └── MM/
│ └── YYYY-MM-DD.md
├── team/ # 团队记忆(需 TEAMMEM feature + tengu_herring_clock GrowthBook 开关)
│ └── MEMORY.md
└── .consolidate-lock # autoDream 整合锁
2 user(用户画像)
2.1 一句话理解
记录"你是谁"——用户的身份、角色、技能水平、知识背景。
2.2 详细说明
这类记忆帮 AI 调整沟通方式。同样是解释一段代码,对资深工程师和对刚入门的学生,回答方式完全不同。
2.3 何时保存
当了解到用户的以下信息时:
- 角色和职位
- 技能水平和经验
- 知识领域(擅长什么、不熟悉什么)
- 工作职责和关注点
2.4 如何使用
当回答问题时,根据用户画像调整回答的深度、角度和侧重点。例如:
- 资深后端 → 用后端类比解释前端概念
- 数据科学家 → 突出数据/日志相关的内容
- 学生 → 更耐心、更详细、更多背景解释
2.5 注意事项
- 不要存负面评价或与工作无关的个人信息
- 目标是更好地帮助用户,不是评判用户
2.6 示例
| 用户说 | AI 记住什么 |
|---|---|
| “我是一名数据科学家,正在调查我们的日志系统” | user_data_scientist.md → 用户是数据科学家,当前关注可观测性/日志 |
| “我写了十年 Go,但这是我第一次碰这个项目的 React 部分” | user_go_expert.md → Go 资深,React 新手 → 用后端概念类比解释前端 |
| “我对 Rust 还不太熟,边做边学” | user_learning_rust.md → 正在学 Rust → 解释要详细,给出学习资源 |
2.7 实践
例如,我们打开一个工程输入如下内容:
我是一名intersystems iris语言工程师,对ts代码不太熟悉。
此时,Claude Code就会根据其内部机制判断是否要写入memory
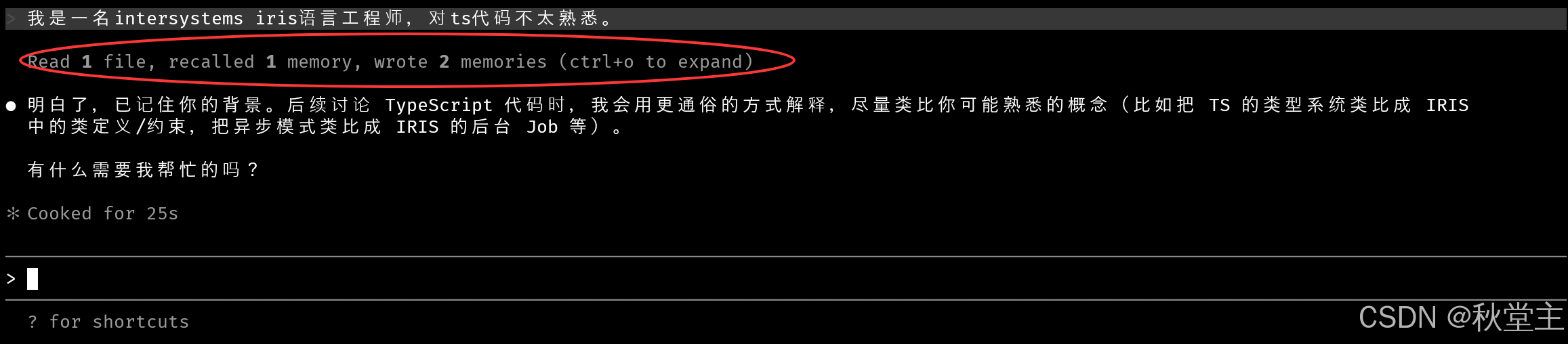
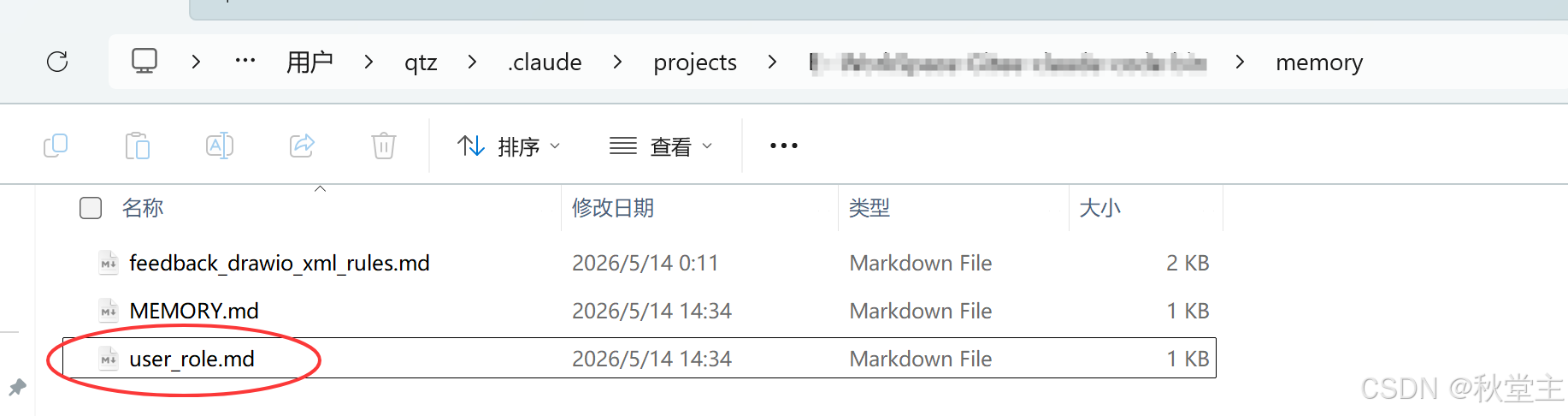
执行完成之后,会在记忆文件夹中创建了一个叫做:user_role.md 的文件。
3 feedback(反馈偏好)
3.1 一句话理解
记录"怎么做"——用户教你的行为准则,既包括纠正也包括肯定。
3.2 详细说明
这是最重要的记忆类型。用户给你的每一条反馈——不管是批评还是表扬——都应该记住。关键:不仅要记录失败(纠正),也要记录成功(认可)。如果只记录纠正,你会越来越保守;记录认可则帮你锁定用户喜欢的做法。
3.3 何时保存
| 触发场景 | 示例 |
|---|---|
| 用户纠正做法 | “别这样”、“不要”、“停止做 X” |
| 用户认可做法 | “对,就是这样”、“完美,继续这样做” |
| 用户接受一个不寻常的选择 | 没有质疑,默认通过 |
纠正好识别,认可容易被忽略——要特别注意捕捉。
3.4 文件的推荐结构
规则本身
**Why:** 用户给出这条规则的原因(知道原因才能判断边界情况)
**How to apply:** 何时/何处应用这条规则
3.5 示例
| 用户说 | AI 记住什么 |
|---|---|
| “测试里别 mock 数据库,上次 mock 测试过了但生产迁移失败了” | 集成测试必须用真实数据库。原因:mock 与生产环境差异曾导致迁移失败 |
| “别再每条回复末尾总结你干了什么,我看 diff 就知道了” | 用户要简洁回复,不要末尾总结。原因:用户会自己看 diff |
| “对,这次打包成一个 PR 是正确的,拆开就是无意义的 churn” | 此类重构用户倾向于一个 PR。原因:已验证,拆分无价值 |
3.6 实践
例如:
- 第一次:在让
Claude Code帮我绘制.drawio格式的流程图时,绘制完成之后,打开之后报错,提示非绘图文件。 - 对话:告诉他此次输出的文件,打开报错,提示:非绘图文件。
- 修复:Claude Code自动帮我修复,然后总结了2条原因。
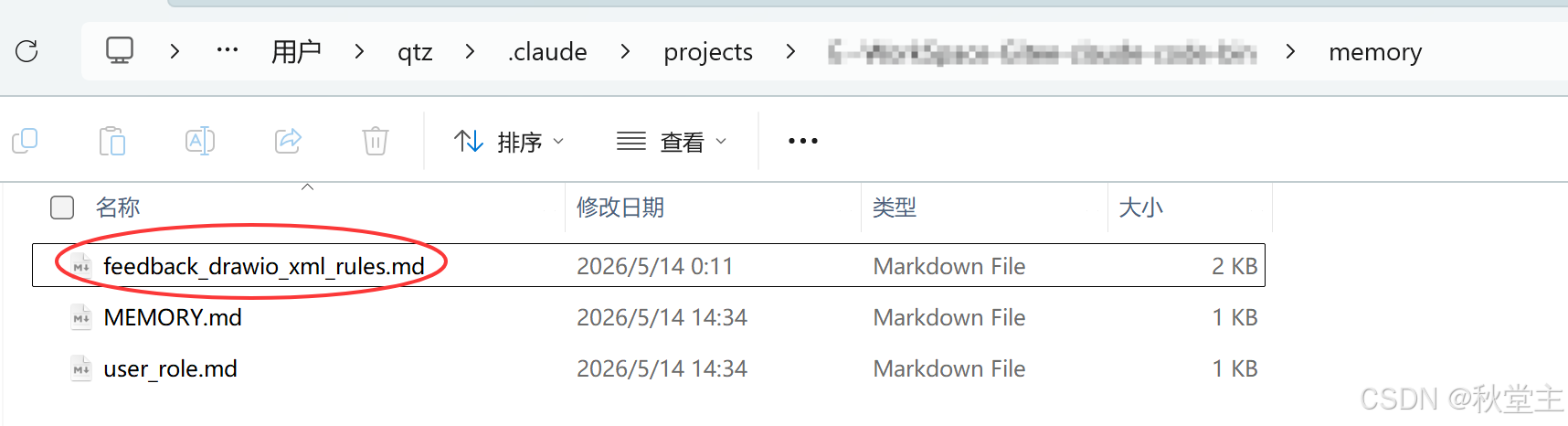
- 肯定他:让他记住此次的修复问题。之后Claude Code便会在记忆文件夹中创建了
feedback_drawio_xml_rules.md文件。
4 project(项目上下文)
4.1 一句话理解
记录"为什么做"——代码之外的动机、约束、截止日期、决策背景。
4.2 详细说明
代码告诉你"做了什么",但很少告诉你"为什么"。
- 为什么用这个方案而不是另一个?
- 这个功能的截止日期是什么?
- 谁在推动这件事?出于什么原因?
- 有没有合并冻结/发布窗口?
这些信息对做出正确决策至关重要,但代码里找不到。
4.3 何时保存
当了解到以下信息时:
- 谁在做什么、为什么要做、何时完成
- 项目的 deadline 和里程碑
- 决策背后的非技术原因(合规、法律、业务)
- 组织层面的约束(团队分工、发布节奏)
4.4 关键规则
必须把相对日期转成绝对日期!
“周四开始合并冻结” → 记成 “2026-05-18 开始合并冻结”(而不是 “周四”),因为几周后你再看这条记忆,"周四"就没有意义了。
4.5 body_structure
事实或决策
**Why:** 动机(约束、截止日期、需求方)
**How to apply:** 这条信息如何影响你的建议
4.6 示例
| 用户说 | AI 记住什么 |
|---|---|
| “周四之后冻结所有非紧急合并,移动端要切发布分支了” | 合并冻结 2026-05-18 开始。标记该日期之后的非关键 PR |
| “我们在重写认证中间件,因为法务说旧版存 session token 的方式不合规” | 认证重写是合规驱动的,不是技术债清理。方案选择应优先合规 |
| “这个任务不急,优先级低于用户那边反馈的 bug 修复” | 当前阶段 bug 修复优先级高于功能开发 |
5 reference(外部参考指针)
5.1 一句话理解
记录"去哪找"——外部系统中的资源位置,而不是内容本身。
5.2 详细说明
这类记忆不存内容本身,只存资源的坐标。因为外部系统的内容随时在变,过时风险高,存一个指针去源头查才是正确的。
5.3 何时保存
当了解到以下信息时:
- bug 在哪个系统里跟踪(Linear、Jira、GitHub Issues)
- 监控面板在哪里(Grafana、Datadog)
- 文档在哪里(Confluence、Notion、Google Docs)
- 团队沟通渠道(Slack 频道、邮件组)
5.4 如何使用
当用户提到某个系统或话题时,先查 reference 记忆找到对应的外部资源位置。
5.5 示例
| 用户说 | AI 记住什么 |
|---|---|
| “查 Linear 项目 INGEST,那里跟踪所有 pipeline bug” | 管线 bug 跟踪在 Linear 项目 “INGEST” |
| “grafana.internal/d/api-latency 是 oncall 盯的看板,改请求相关代码时注意别把延迟搞上去” | oncall 延迟看板在 grafana.internal/d/api-latency,改请求路径代码时要关注 |
| “部署文档在 notion.so/xxx-deploy-guide” | 部署文档在 Notion:notion.so/xxx-deploy-guide |
6 四类记忆对比总结
| 维度 | user | feedback | project | reference |
|---|---|---|---|---|
| 核心问题 | 你是谁? | 你要我怎么做? | 为什么做这个? | 相关信息在哪? |
| 内容性质 | 身份/能力描述 | 行为规则/偏好 | 背景/动机/约束 | 外部资源坐标 |
| 时效性 | 基本稳定 | 较稳定 | 变化快,容易过时 | 取决于外部系统 |
| 触发频率 | 低(一次性) | 中(持续积累) | 中(随项目推进) | 低 |
| 易被忽略 | — | 认可比纠正更易漏 | 相对日期忘转绝对 | — |
7 什么不该存为记忆
核心原则:即使面对明确的保存请求,也应主动追问用户 “其中哪些信息是出乎意料或非显而易见的”,仅保留具备高信息熵的核心内容。以下五类信息通常无需额外记忆:
- 代码架构与文件路径:此类信息可通过
grep或glob等工具在代码库中直接检索获取。 - 版本控制与变更记录:Git 历史记录及代码归属(谁修改了什么)应以
git log和git blame的查询结果为准,保持单一事实来源。 - 调试方案与修复记录:代码中的实际修复及 Commit Message 已包含完整的上下文,无需重复记录“修 bug 菜谱”。
- CLAUDE.md 既有内容:项目根目录的
CLAUDE.md中已明确记载的规则,严禁重复记忆。 - 临时任务与瞬时状态:进行中的工作细节、临时状态及当前对话的短期上下文,不具备长期记忆价值。
8 记忆文件的格式
每条记忆存为独立的 .md 文件,使用 YAML frontmatter:
---
name: {{记忆名称,短横线连接}}
description: {{一句话描述——用于未来判断是否相关,所以要具体}}
type: user / feedback / project / reference
---
{{记忆正文}}
- feedback/project 类型建议包含 **Why:** 和 **How to apply:** 段落
8.1 示例:一条 feedback 记忆
---
name: concise-responses
description: User prefers terse responses without trailing summaries
type: feedback
---
Rule: Keep responses short and skip end-of-turn summaries.
**Why:** The user reads diffs directly and finds summaries redundant.
**How to apply:** After completing edits or changes, state the result
in one sentence. No bullet-point recaps unless specifically requested.
8.2 user-role
---
name: user-role
description: 用户是 InterSystems IRIS 语言工程师,对 TypeScript 代码不太熟悉
metadata:
node_type: memory
type: user
originSessionId: 998bb0b8-182a-4fc6-ac33-0e037bf3696e
---
用户是一名 InterSystems IRIS(数据库/互操作性平台)语言工程师,主要使用 ObjectScript 和 IRIS 相关技术栈。对 TypeScript 代码不太熟悉,在解释 TS 代码、架构模式、类型系统等内容时需要更多的上下文说明和类比。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)