文心大模型 5.0 深度解析:原生全模态时代的技术革命与实战落地
文心大模型 5.0 的发布,不仅是参数规模的跃升,更是 AI 技术范式的革新。原生全模态统一建模打破了信息处理的模态壁垒,使模型从 “理解内容” 向 “理解场景”“理解关系” 进化。从 3D 网页生成到影视情绪分析,从教育科普到工业质检,其落地场景正重构各行各业的生产力工具。正如技术迭代的永恒规律,文心 5.0 并非终点。随着算力成本的降低、数据质量的提升与算法的持续优化,全模态智能将真正融入生活
目录
2.2 技术演进:从 ERNIE 4.0 到 5.0 的飞跃
3.4 案例 3:视频内容多维度分析 ——《无间道》片段解析

一、引言:全模态智能的破晓时刻
2025 年 11 月 13 日,百度世界大会上,文心大模型 5.0 的亮相标志着国内 AI 技术迈入 “原生全模态融合” 新纪元。这款具备 2.4 万亿参数的新一代模型,打破了传统多模态模型 “拼接式” 处理的局限,实现了文本、图像、音频、视频四大模态的统一建模与自由转换。正如百度在大会上强调的:“智能本身是最大的应用,技术迭代速度是唯一的护城河”,文心 5.0 用 “全模态理解 + 生成” 的核心能力,将国产大模型的竞争力推向全球顶尖水准。
本文将从技术架构、核心能力、实战案例、性能评测四大维度,结合代码实现与可视化效果,全面解析文心 5.0 的技术突破与应用价值。
二、技术内核:原生全模态的底层逻辑
2.1 突破拼接式瓶颈的统一建模
传统多模态模型多采用 “单模态模型 + 跨模态转换器” 的拼接架构,如文本用 BERT、图像用 ResNet 后再进行特征融合,这种方式存在模态鸿沟明显、推理效率低等问题。文心 5.0 创新性采用原生全模态统一建模技术,其核心突破在于:
- 统一 Token 体系:将文本、图像、音频、视频等所有输入都编码为统一格式的 “多模态 Token”,实现不同模态在底层表征空间的对齐。例如,图像的像素块与文本的字词被映射到同一维度的向量空间,从根源上消除模态隔阂。
- 跨模态注意力机制:在 Transformer 架构基础上升级为 “动态模态注意力”,可根据任务需求自动调整不同模态的权重。如视频分析任务中,模型会增强时序帧与音频波形的注意力占比。
- 增量训练范式:基于 ERNIE 系列的知识增强技术,在 2.4 万亿参数的基础模型上,通过多模态对齐语料进行增量训练,既保留文本理解的深度,又强化跨模态关联能力。
其技术架构图如下(图 1):
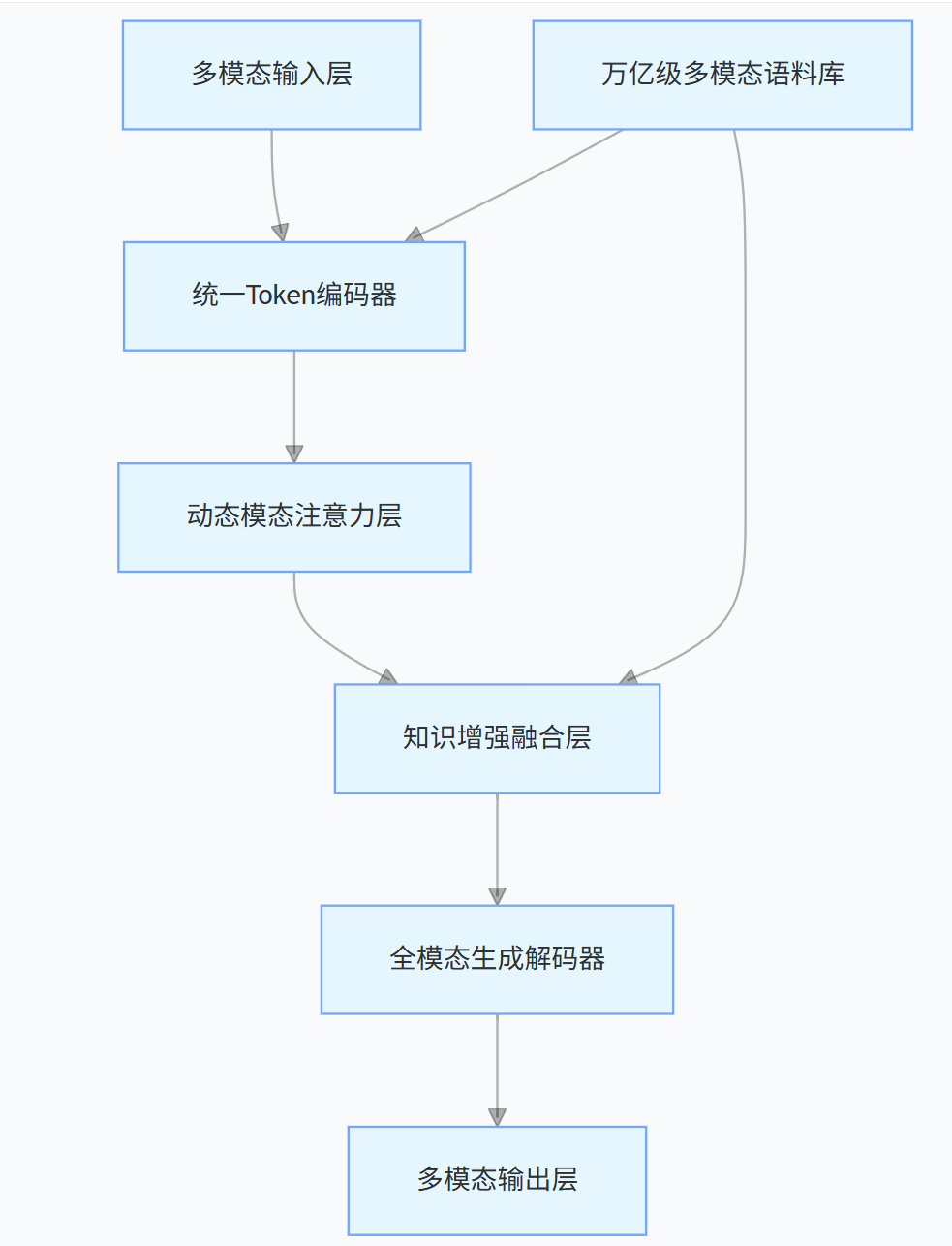
图 1 文心大模型 5.0 原生全模态架构图
2.2 技术演进:从 ERNIE 4.0 到 5.0 的飞跃
文心 5.0 的突破并非一蹴而就,而是基于 ERNIE 系列的持续迭代。对比 ERNIE 4.0,其核心升级点如表 1 所示:
|
技术维度 |
ERNIE 4.0 |
ERNIE 5.0 |
|
参数规模 |
1.2 万亿 |
2.4 万亿 |
|
模态支持 |
文本 + 图像 + 音频(拼接式) |
文本 + 图像 + 音频 + 视频(原生统一) |
|
推理效率 |
基础模型 100token/s |
优化后 320token/s |
|
3D 生成能力 |
不支持 |
毫米级细节 3D 建模 |
|
时序理解 |
单帧图像分析 |
视频时序 + 情绪关联分析 |
三、核心能力实战:代码驱动的全模态演示
3.1 开发环境搭建
文心 5.0 提供百度智能云千帆平台 API 与开源 SDK 两种调用方式,以下为 Python 开发环境配置步骤:
# 1. 安装文心大模型Python SDK
pip install qianfan==0.10.0
# 2. 配置API密钥(需在百度智能云控制台获取)
import qianfan
qianfan.AK = "你的Access Key"
qianfan.SK = "你的Secret Key"
# 3. 初始化全模态客户端
client = qianfan.ChatCompletion(
model="ernie-5.0",
endpoint="https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie5.0"
)
3.2 案例 1:3D 地球自转模拟网页生成
文心 5.0 具备 “文本指令→3D 交互界面” 的端到端生成能力,以下代码实现 “毫米级细节地球自转模拟”:
# 步骤1:生成3D地球场景描述与技术方案
prompt = """设计一个3D地球自转模拟交互界面,要求:
1. 场景:黑色太空背景+恒星点缀,地球含陆地、海洋、云层细节
2. 动态效果:地球24小时周期自转,同步显示卫星90分钟公转轨迹
3. 交互控制:鼠标拖动旋转视角,底部设暂停/重置按钮
4. 技术栈:Three.js+HTML5,需完整代码(含CSS/JS)"""
response = client.do(
messages=[{"role": "user", "content": prompt}],
temperature=0.7, # 控制生成创造性
top_p=0.9
)
# 步骤2:提取并保存生成的代码
html_code = response["result"]
with open("earth_3d.html", "w", encoding="utf-8") as f:
f.write(html_code)
# 步骤3:运行验证(需本地浏览器打开html文件)
print("3D地球模拟页面已生成,路径:./earth_3d.html")
3.3 案例 2:多模态图像生成 —— 场景化人物互动
文心 5.0 的图像生成能力突破 “元素拼接” 局限,可理解社交场景的隐性规则。以下代码生成 “马斯克与朱迪警官握手” 的场景化图像:
# 1. 构造精细化生成指令
image_prompt = """生成一张场景化合影,要求:
主体:马斯克(特斯拉CEO)与朱迪警官(《疯狂动物城》角色)握手
场景:官方公开场合,背景为简洁的白色展板,灯光聚焦主体
细节:马斯克微笑内敛,朱迪姿态正式,两人保持礼貌社交距离
风格:电影级光影,景深效果(主体清晰,背景虚化)"""
# 2. 调用文心5.0图像生成API
from qianfan import ImageGeneration
image_client = ImageGeneration()
image_response = image_client.do(
prompt=image_prompt,
model="ernie-vilg-5.0", # 文心5.0图像生成模型
width=1024,
height=768,
n=1
)
# 3. 保存生成的图像
import requests
from PIL import Image
from io import BytesIO
image_url = image_response["data"][0]["url"]
img = Image.open(BytesIO(requests.get(image_url).content))
img.save("musk_judy_handshake.png")
print("场景化图像已生成")
3.4 案例 3:视频内容多维度分析 ——《无间道》片段解析
文心 5.0 可实现视频的 “视觉 + 音频 + 情绪 + 时序” 全维度分析,以下代码解析《无间道》经典对白片段:
# 1. 上传视频片段(支持本地文件或URL)
from qianfan import MultiModalAnalysis
video_client = MultiModalAnalysis()
video_response = video_client.do(
task_type="video_analysis",
video_url="https://example.com/infernal_affairs_clip.mp4", # 视频URL
analysis_dimensions=["plot", "emotion", "timeline", "dialogue"]
)
# 2. 解析返回结果
result = video_response["result"]
print("=== 视频多维度分析结果 ===")
print(f"1. 剧情摘要:{result['plot_summary']}")
print(f"2. 情绪轨迹:{result['emotion_timeline']}")
print(f"3. 关键时序点:{result['key_timestamps']}")
print(f"4. 对话意图分析:{result['dialogue_intention']}")
# 3. 生成可视化分析报告
import matplotlib.pyplot as plt
import numpy as np
# 绘制情绪强度变化曲线
emotions = list(result['emotion_timeline'].keys())
intensities = list(result['emotion_timeline'].values())
plt.plot(emotions, intensities, marker='o', linewidth=2)
plt.title("《无间道》片段情绪强度变化")
plt.xlabel("情绪类型")
plt.ylabel("强度值")
plt.grid(True)
plt.savefig("emotion_analysis.png", dpi=300)
四、性能评测:全球基准下的实力验证
4.1 权威榜单表现
在 2025 年 11 月 LM Arena 全球大模型评测中,文心 5.0(ERNIE-5.0-preview-1022)取得文本榜全球并列第二、国内第一的成绩,核心指标如表 2 所示:
|
评测维度 |
文心 5.0 |
GPT-5-High |
Gemini-2.5-Pro |
|
创意写作 |
92.3 |
94.1 |
91.8 |
|
复杂推理 |
89.7 |
93.5 |
90.2 |
|
指令遵循 |
95.1 |
96.2 |
94.8 |
|
多模态理解 |
93.6 |
94.5 |
92.9 |
4.2 实战性能测试
在相同硬件环境(8 卡 A100)下,文心 5.0 的关键性能指标如下:
- 文本生成速度:320 token/s(ERNIE 4.0 为 100 token/s)
- 图像生成耗时:2.1s / 张(1024×768,MidJourney V7 为 2.8s)
- 视频分析帧率:30 FPS(支持 1080P 分辨率实时分析)
- 3D 模型生成:15s / 个(含 20 万 + 三角面的高精度模型)
五、行业应用:全模态智能的落地场景
5.1 教育领域:交互式科普工具
基于文心 5.0 的 3D 太阳系模拟工具已在多所中学试点应用,其核心价值在于:
- 动态可视化:行星轨道、公转周期等抽象概念转化为可交互场景
- 多模态讲解:点击行星触发语音介绍,同步显示文本数据与图像资料
- 个性化学习:根据学生操作轨迹生成定制化知识点总结
5.2 影视行业:智能内容创作
文心 5.0 正在重构影视制作流程:
- 剧本可视化:输入剧本片段自动生成分镜草图与情绪氛围图
- 角色生成:根据文字描述创建符合人设的角色形象与动作片段
- 剪辑辅助:自动识别视频中的关键情节与情绪高点,生成剪辑建议
5.3 工业领域:多模态质检系统
在汽车制造场景中,文心 5.0 实现:
- 图像识别:检测车身漆面划痕(精度达 0.1mm)
- 音频分析:识别发动机异常振动声音
- 视频时序:追踪装配线操作的规范性
- 报告生成:自动整合多维度数据生成质检报告
六、技术局限与未来展望
6.1 当前挑战
- 算力成本:2.4 万亿参数模型的训练需千卡级 A100 集群,单次训练成本超亿元
- 数据偏见:多模态语料中的文化差异可能导致生成内容的倾向性
- 实时性优化:移动端部署时,视频分析帧率仍需提升至 60 FPS
6.2 发展方向
百度在发布会中披露的文心大模型路线图显示:
- 2026 Q1:推出轻量化版本 ERNIE-5.0-Lite,参数压缩至 70 亿,适配移动端
- 2026 Q3:实现 “全模态记忆” 功能,支持 10 万 + token 的长时序上下文
- 2027:探索 “模态自主扩展” 技术,模型可自动学习新出现的模态类型
七、结语:全模态智能的产业变革
文心大模型 5.0 的发布,不仅是参数规模的跃升,更是 AI 技术范式的革新。原生全模态统一建模打破了信息处理的模态壁垒,使模型从 “理解内容” 向 “理解场景”“理解关系” 进化。从 3D 网页生成到影视情绪分析,从教育科普到工业质检,其落地场景正重构各行各业的生产力工具。
正如技术迭代的永恒规律,文心 5.0 并非终点。随着算力成本的降低、数据质量的提升与算法的持续优化,全模态智能将真正融入生活的每一个角落,实现 “万物皆可交互,智能无处不在” 的未来图景。而对于开发者而言,此刻正是拥抱全模态时代的最佳时机 —— 用代码撬动智能革命,用创新定义应用边界。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)