Leader:“代码本身正在变得不值钱。” 我:“那我工资按啥定?” Leader:“按 AI 帮公司省下的那部分。”
今天鸭鸭刷到一段挺扎心的发言:5 月 13 日,一家头部大厂的创始人在 AI 开发者大会上抛出一句让所有写代码的人心里咯噔一下的判断:“代码能力越来越重要,但代码本身正在变得不值钱。同一场演讲里他还往前推了一句:软件正在成为快消品,软件行业被重新定义。他还顺手亮了一组数字。大会上同期发布的代码智能体产品,号称 90% 的代码都是 AI 自动生成的,累计服务用户超过 1000 万,对外标的应用价值
代码降价了,签字权没降价
今天鸭鸭刷到一段挺扎心的发言:
5 月 13 日,一家头部大厂的创始人在 AI 开发者大会上抛出一句让所有写代码的人心里咯噔一下的判断:
“代码能力越来越重要,但代码本身正在变得不值钱。”
同一场演讲里他还往前推了一句:软件正在成为快消品,软件行业被重新定义。

他还顺手亮了一组数字。大会上同期发布的代码智能体产品,号称 90% 的代码都是 AI 自动生成的,累计服务用户超过 1000 万,对外标的应用价值 50 亿。
听完这两句话,脉脉评论区基本分成了几派。
有人破防:每天加班写代码的人,被一句话宣判成无效劳动。
有人附和:早晚的事,趁着工资还在赶紧攒钱。
也有人冷笑:那您先把贵司程序员都裁了,再来谈代码值不值钱。
鸭鸭看完这几派,想说一个多数文章没明说的事:
“代码不值钱”听着像在判工程师的死刑,但真正值钱的从来不是那一行行字符,是那个敢在 PR 上点合并、敢在故障群里第一个回应、敢在监控告警里签字背锅的人。代码降价了,签字权没降价。
这里面有四笔账,多数程序员没算清楚。
第一,写代码从来不等于“做软件”。陌生需求要拆解,跨部门要扯皮,老接口要兼容,上线后还要看监控、写复盘、追客诉。代码这一段确实在被 AI 接走,但拆解、扯皮、复盘、追责这些活,AI 短期内接不动。能被接走的部分降价,接不动的部分反而在悄悄升值。
第二,老板说“代码不值钱”的时候,他没说出口的下半句是“AI 的算力很值钱”。5 月 12 日,36 氪和新浪财经都报道了一条让人发凉的新闻:Uber 在 2025 年底给工程师全员部署了 Claude Code,结果不到 4 个月,烧光了全公司 2026 全年的 AI 预算。Uber CTO 自己承认:我回到了白板前面,原本估的预算被彻底突破。
新闻里给的数字更直观。每个工程师每月 AI 工具开销 500 到 2000 美元,按 6000 工程师、中位数 1000 美元算,4 个月烧掉 2400 万美元。70% 的提交代码已经由 AI 写,工程师主要在审。
翻译成大白话就是:以前公司付工资请你写代码,现在公司付算力费请 AI 写代码,再付审查费请你审。两笔账加起来,整体并没有变便宜。所以这事的尽头不是直接裁人,是“算力账”要从“工资账”里找补回来。你要么帮公司省算力,要么帮公司多吃单,要么帮公司把那 70% 的 AI 代码审住别出事。
第三,“快消品软件”不是说软件全行业都变快消品了。被 AI 抹平的是一次性脚本、内部小工具、表单页面、个人创意小 App 这一层。但企业级核心系统、订单 / 风控 / 支付 / 调度,这些代码改一行可能赔几千万的活,老板第一个不敢让 AI 全权写。这一层不仅没降价,反而被衬得更值钱了。
第四,那个 90% 由 AI 生成的代码智能体,剩下 10% 在哪?在产品经理和工程师的 review 里。这个产品真正在向外卖的不是它会生成代码的能力,是它敢上线、敢服务 1000 万用户、敢标 50 亿应用价值的那个“敢”字。背后是测试、灰度、发版、回滚、客诉处理这一整套工程化体系,AI 接不动。
四笔账拼起来其实是一句话:“代码不值钱”是真的,但老板真正想说的下半句是,这家公司不再为单纯写代码的人付溢价了。值钱的,是那个敢签字、能扛锅、判得准的人。
那这事儿能怎么办?
鸭鸭说几句实在话。
- 简历别再堆“精通 N 种框架”:3 年前是优势,今天读起来像在和 AI 比谁手快。改成写“在 X 项目里用 AI 把交付周期从 Y 压到 Z,独立 review 过多少行 AI 代码、修过多少个 AI 翻车 case”,把价值挪到“指挥 + 审查 + 背锅”这一侧。
- 把自己锁在“AI 不敢碰”的那部分活上:核心交易链路、强合规模块、跨部门改造、线上事故 P0 处理。这些活做得越多,越不容易被一句“代码不值钱”切走。
- 学会读 AI 代码,而不只是会写:能不能 5 分钟看出一段 200 行 AI 代码里哪里挖了坑、哪里调错了 API、哪里把异常吃掉了。这个能力 AI 自己短期补不上,也是面试里最该秀的肌肉。
- 把“敢签字”练成可被看见的能力:在公司里多接几次 release owner、多写几次故障复盘、多在群里发一次“这版我审过没问题”。下次绩效面谈,这些事比你贡献多少 token 更值钱。
最后说一句鸭鸭看完这场大会发言之后的判断:
“代码不值钱”是一句卖产品的口号,不是一句给程序员发工资的标准。把代码当成快消品的人,是想卖更多的代码。真正会涨价的,是那个敢说“这版我担”的人。
下次老板再拿这句话压你工资的时候,可以淡淡接一句:那您愿意把签字权也一并交给 AI 吗?
定价权,是从那个“敢”字开始重新分配的。
大家公司有没有出现“AI 写的代码越来越多,但人却更忙了”的情况?你的代码量和绩效之间,这两年还成正比吗?评论区聊聊~
……
今天鸭鸭和大家分享一道 AI 大模型面试题。
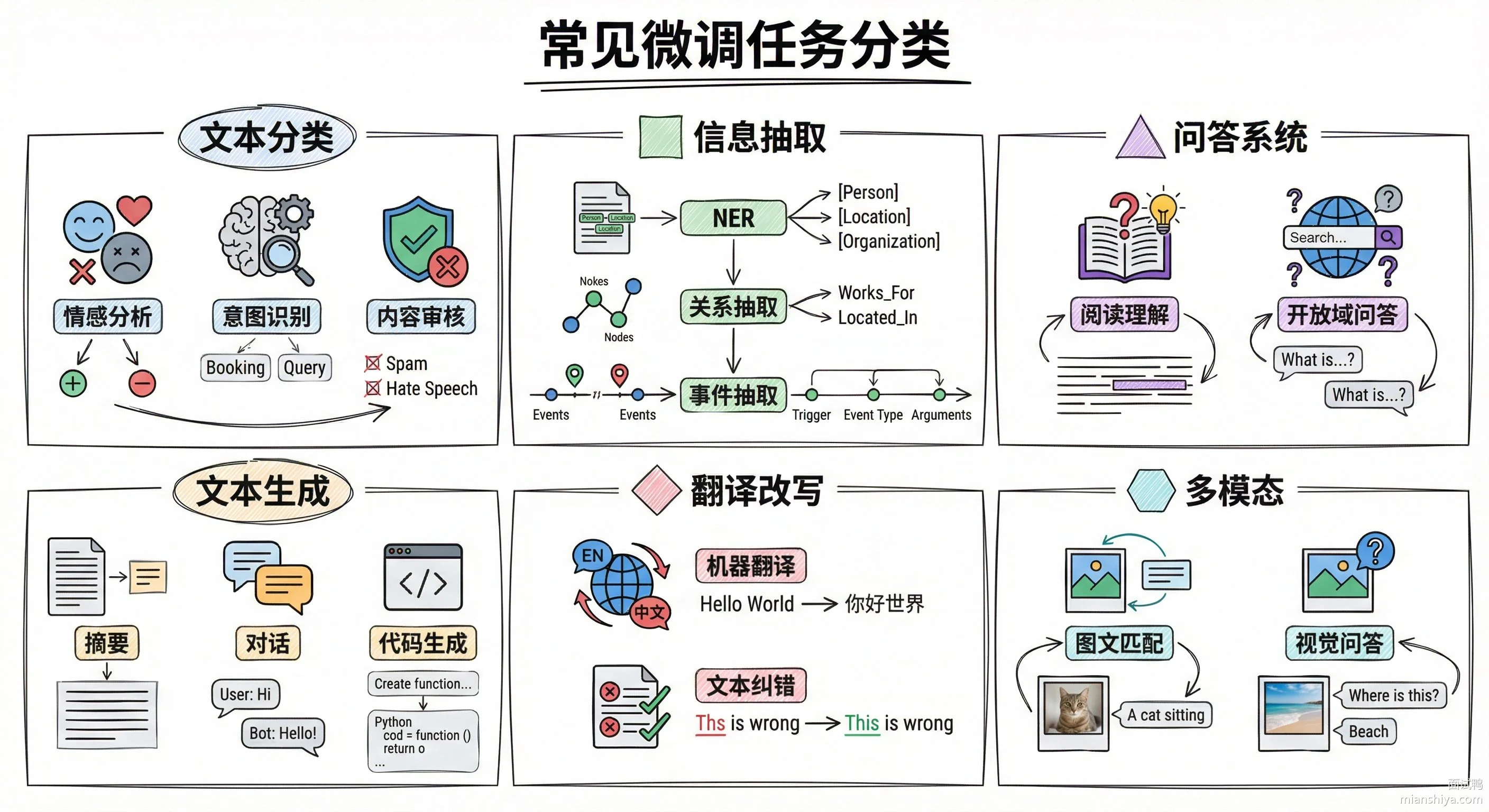
【大模型常见的微调任务有哪些? 】
回答重点
大模型微调任务按输入输出形式可以分成几大类:
1)文本分类,输入一段文本,输出一个类别标签。典型场景有垃圾邮件识别、情感分析、内容审核、意图识别。电商平台用它做商品评论的情感分析,每天处理几百万条评价
2)命名实体识别,从文本里把人名、地名、机构名、时间这些实体抽出来并标注类型。搜索引擎用它理解查询意图,知识图谱用它抽取结构化信息
3)问答系统,给一个问题和一段上下文,让模型定位答案在哪里或者直接生成答案。智能客服、文档问答都是这个任务
4)文本生成,根据输入生成相关文本,包括摘要生成、对话生成、文案写作、代码生成。ChatGPT 本质上就是做指令跟随的文本生成任务
5)机器翻译,把一种语言翻成另一种语言。虽然通用大模型翻译能力已经不错,但特定领域比如法律、医学文档翻译还是需要专门微调
6)多模态任务,处理图文混合输入,比如图像描述生成、视觉问答、图文检索
扩展知识
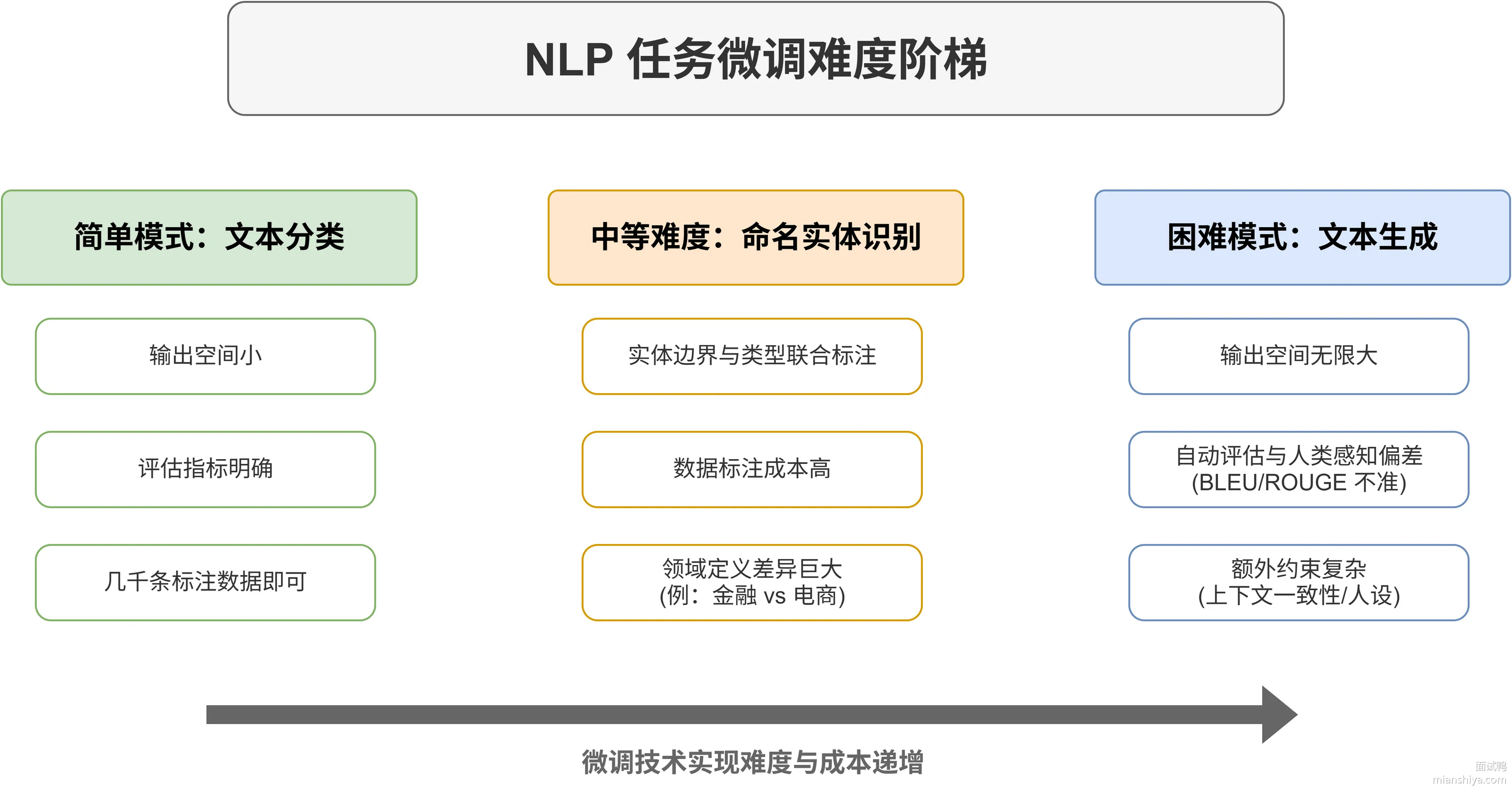
不同任务的微调难度差异
并不是所有任务微调起来难度都一样。
文本分类是最简单的,输出空间小、评估指标明确,几千条标注数据就能训出不错的效果。
命名实体识别难一些,需要处理实体边界和类型的联合标注,数据标注成本高,而且不同领域的实体定义差异大,金融领域的"产品"和电商领域的"产品"可能完全是两回事。
文本生成是最难的,输出空间无限大,评估也麻烦,自动指标如 BLEU、ROUGE 跟人类感知经常对不上。对话生成还要考虑上下文一致性、人设保持这些额外约束。
指令微调和任务微调的区别
早期的微调都是针对单一任务,训一个情感分析模型、训一个 NER 模型,各管各的。
指令微调是另一种思路,用自然语言指令描述任务,让模型学会理解指令并执行。同一个模型既能做分类也能做生成,关键看你怎么写 prompt。ChatGPT 就是典型的指令微调产物,用户用自然语言描述需求,模型理解后执行。
指令微调的数据长这样:输入是"请判断以下评论是正面还是负面:这家餐厅味道很棒",输出是"正面"。这种格式让模型学会的是理解任务本身,不是死记硬背某个特定任务的模式。
RLHF:用人类反馈做微调
单纯的监督微调有个问题,模型可能学会了任务但回答不够好。比如回答正确但啰嗦、或者语气生硬、或者遇到敏感问题不知道拒绝。
RLHF 是 ChatGPT 的核心技术之一。先收集人类对模型回答的偏好数据,训练一个奖励模型判断回答好不好,再用强化学习让模型往高奖励的方向优化。
这套流程成本很高,需要大量人工标注偏好数据,训练也复杂。后来出了 DPO 这种简化方案,直接用偏好数据训练,跳过奖励模型这一步,效果差不多但简单很多。
领域微调的数据来源
做领域微调最头疼的就是数据从哪来。几种常见做法:
1)人工标注,质量最高但成本也最高,适合核心任务
2)利用已有业务数据,比如客服系统的历史对话记录、搜索日志里的 query 和点击,清洗一下就是现成的训练数据
3)用大模型生成合成数据,比如让 GPT 生成指令数据,Alpaca、Vicuna 都是这么干的。质量取决于 prompt 设计和后处理
4)数据增强,对已有数据做回译、同义词替换、句式变换,扩充数据量
篇幅有限,更多 AI 大模型 相关面试题可以进入面试鸭进行查阅。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)