怎么查看olama是否用到了显卡加速
当我们使用springai开发一个对话机器人之后,如何确定后台运行的ollama使用了gpu加速了呢?这里有几种方法,分别来介绍。本文使用方案一做一下验证。要查看 Ollama 是否用上了显卡加速,最简单直接的方法是使用 命令查看已加载模型的设备分配情况,也可以用 这类系统工具实时监控 GPU 的占用率。
当我们使用springai开发一个对话机器人之后,如何确定后台运行的ollama使用了gpu加速了呢?
这里有几种方法,分别来介绍。本文使用方案一做一下验证。
要查看 Ollama 是否用上了显卡加速,最简单直接的方法是使用 ollama ps 命令查看已加载模型的设备分配情况,也可以用 nvidia-smi 这类系统工具实时监控 GPU 的占用率。
🔎 方案一:使用 ollama ps 查看模型分配 (最直接)
在模型加载后,打开新终端执行 ollama ps,结果中的 PROCESSOR 列会明确显示当前的运算分配:
- 100% GPU:整个模型已完全加载到显卡显存中运行。
- 100% CPU:模型正在使用 CPU 和系统内存运行。
- %/% CPU/GPU:模型的部分层级由 GPU 计算,其余由 CPU 处理,例如大模型通常会以这种“模型并行”的方式运行。
实操:
1.启动项目
2.打开项目网页,并进行一次对话
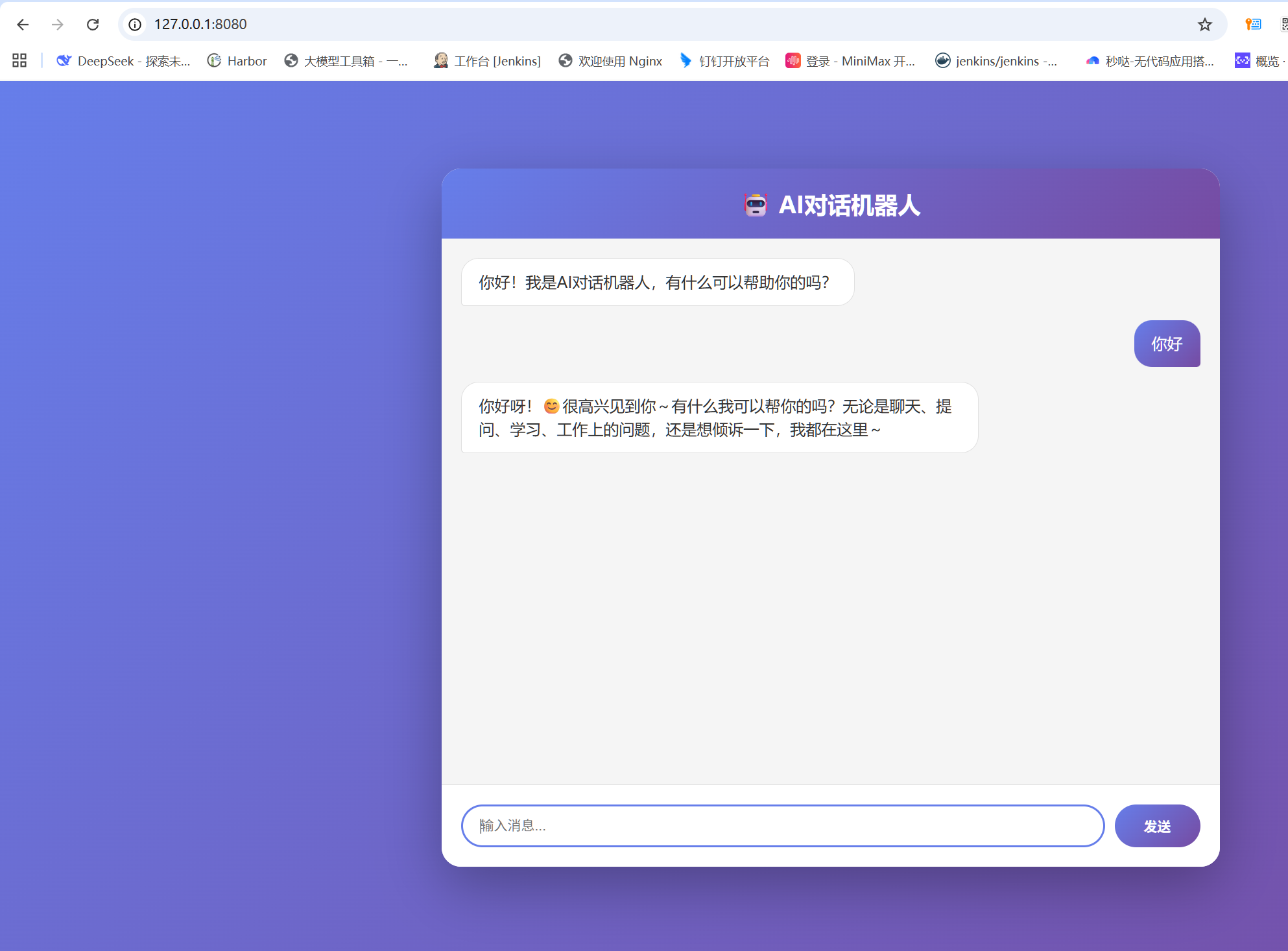
3.进入cmd命令行,输入 ollama ps查看具体的执行

4.结果分析
可以看到使用了67%的gpu.那为何会出现这种 情况,以及如何优化呢,下文介绍。本文先能够将gpu使用到即可。虽然33%的CPU,但可能会因为这33%的cpu运算造成系统瓶颈,最终还是会导致结果变慢。我们需要继续优化才行。最终的结果是要达到100% GPU显示才对。
5.查看具体原因
nvidia-smi
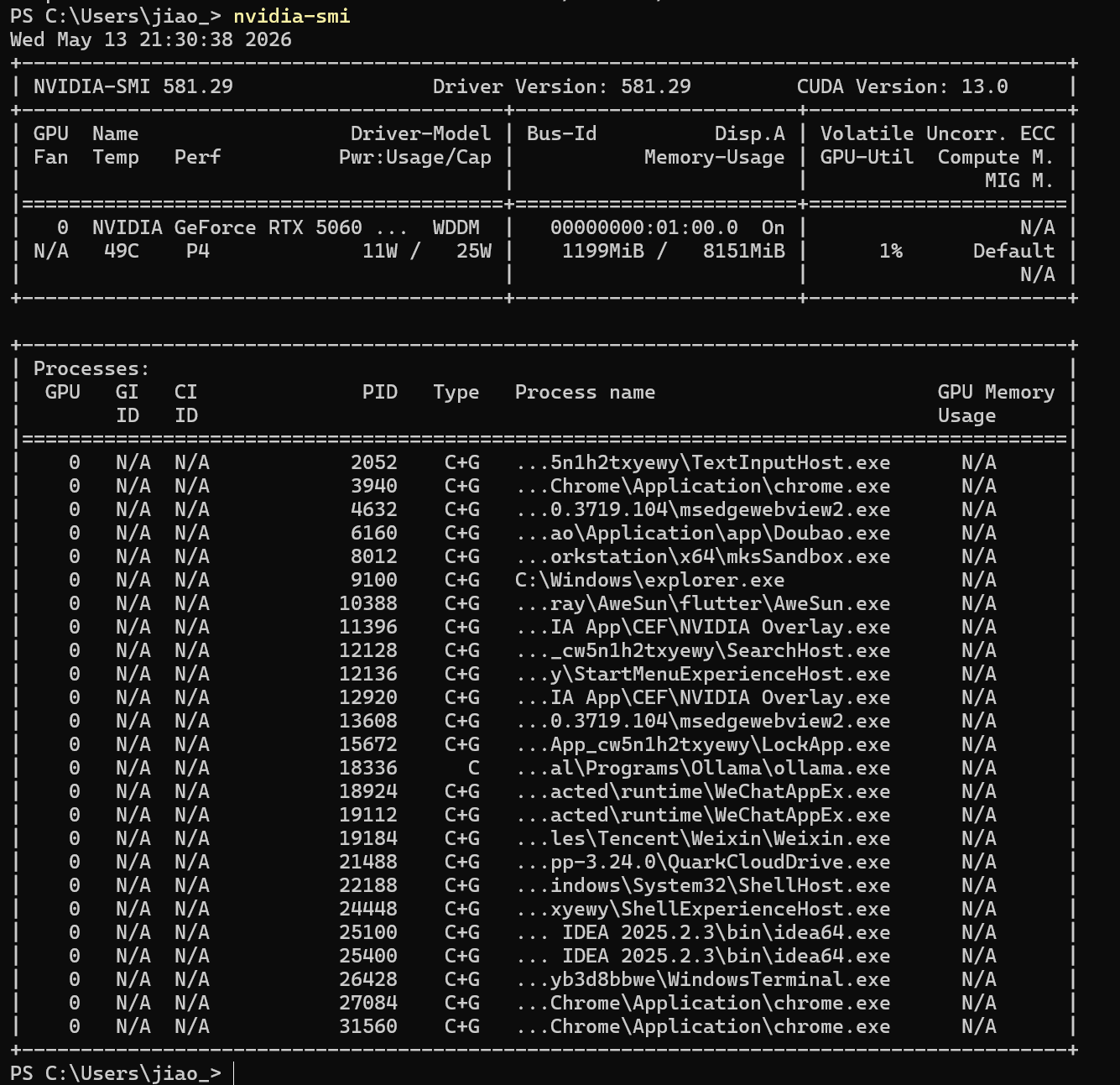
可以看到这里
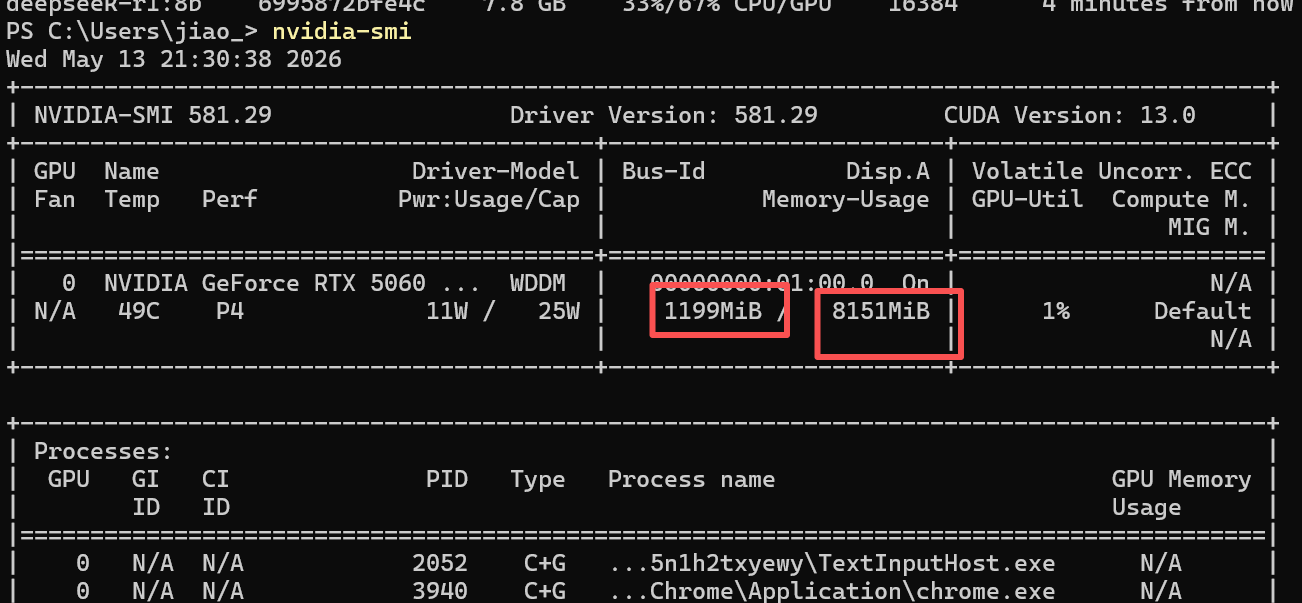
GPU 总显存是 8151 MiB(约 7.96 GB),当前已被其他程序占用 1199 MiB(约 1.17 GB),剩余可用显存只有约 8151 - 1199 = 6952 MiB(约 6.79 GB)。而 deepseek-r1:8b 这个模型的大小是 7.8 GB(约 7800 MiB),比空闲显存还要大约 850 MiB。
6.关闭显卡性能优化,集显进行显示。RTX5060专注计算
该步骤比较繁琐,由于系统设置有一定道理,所以尽量不要这么操作。我们可以通过设置ollama上下文的token数量还减少显存占用,换取足够可用显存
7.设置ollama的token为8k
打开ollama的setting。找到最后一行,将16k改为8k。修改如下
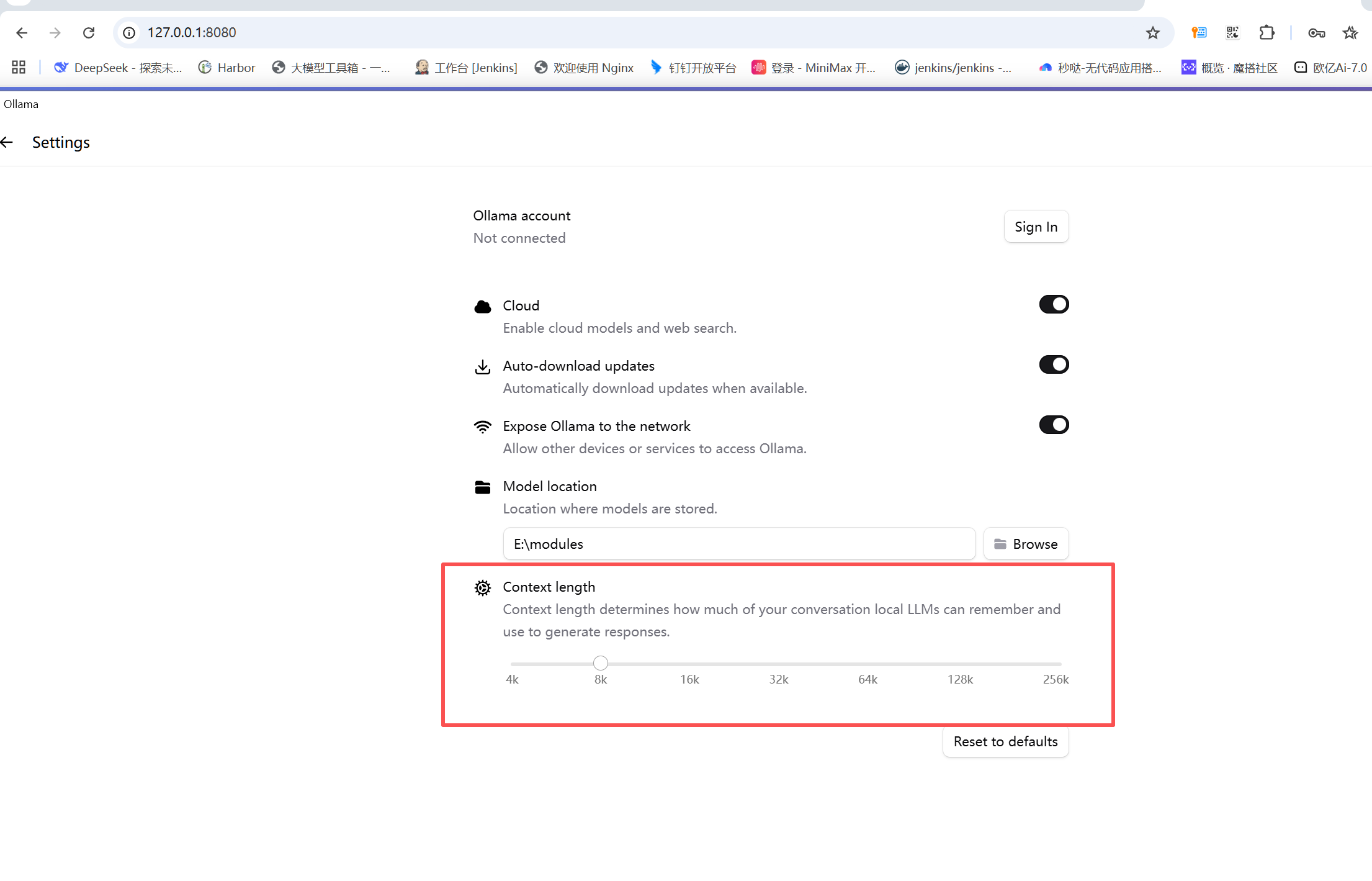
修改后,再次查看,发现终于是100%GPU了

至此,我们已经可以100%使用GPU来完成任务了。
虽然使用到GPU的100%了,每次对话时间还是需要秒级。如何继续优化呢,我们在后续章节介绍
📊 方案二:使用 nvidia-smi 监控实时占用 (仅限NVIDIA)
- 运行模型开始推理。
- 打开新终端,输入
nvidia-smi -l 1(每秒刷新),观察显存占用是否增加,或 nvidia-smi dmon -s u 查看“sm”利用率字段是否从 0% 升高。
🐳 方案三:使用 Docker 时的检查
在 Docker 中运行 Ollama 时,添加 --gpus all 参数。进入容器后通过 nvidia-smi 检查驱动,或在宿主机上用 docker stats <容器名> 观察 GPU 内存使用情况。
📝 方案四:查看服务日志
日志会直接记录硬件检测和加载情况。可用 OLLAMA_DEBUG=1 ollama serve(Linux/macOS)或 $env:OLLAMA_DEBUG=1; ollama serve(Windows PowerShell)以调试模式启动 Ollama 服务,观察 “Detecting GPUs” 等关键词。
🛠️ 方案五:使用第三方工具 termollama
也可用 Node.js 工具 termollama,通过 npm i -g termollama 安装后运行 olm 命令,可图形化查看 GPU 显存占用等信息。
🐧 仅限 Linux:使用 rocminfo 检查 AMD GPU 加速
适用于 AMD 显卡。运行 rocminfo 检测系统识别情况,再用 ollama ps 观察 PROCESSOR 是否显示 GPU,但需注意此处显示可能不代表实际工作负载。
🐍 方案七:通过编程验证 (以 Python 为例)
执行以下简单测试脚本:运行时若打印出类似 using CUDA 或 GPU 利用率飙升的信息,则说明 GPU 被正确调用。
import ollama
import torch
print("CUDA available:", torch.cuda.is_available())
print("Device count:", torch.cuda.device_count())
response = ollama.generate(model='llama2', prompt='Hello')注意:若 torch.cuda.is_available() 返回 False,需要先排查驱动或 PyTorch 环境问题。
另外提醒一下,如果你使用的是 Intel 或 AMD 显卡,可能需要通过环境变量 OLLAMA_VULKAN=1 等来手动启用加速。
你可以根据自己系统的实际情况选择最顺手的方法,如果还有具体的报错信息,随时可以发给我看看~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)