适合Agent的文档解析工具?
DocFlow将解析、分类、抽取、审核封装为稳定易用的API,Agent可以像搭积木一样自由编排这些技能,构建出如“财务报销Agent”“国际贸易单证Agent”“信贷审批Agent”等垂直领域的智能体,真正实现“算力可用 → 文档可懂 → 业务可自动化”的完整闭环。:现实世界中的文档充满歪斜、水印、模糊、手写修改等“噪声”。:真正的智能Agent不应只输出“文字块”,而应能输出“业务结论”——例
今年4月14日,我国最大规模科学智能计算集群在位于河南郑州的国家超算互联网核心节点正式投入使用。这一基础设施的落成,标志着面向AI时代的算力底座进一步夯实,为各类智能Agent(智能体)的规模化运行提供了澎湃动力。
然而,算力问题的解决只是第一步。当企业着手部署能够自主执行任务的Agent时,一个现实瓶颈浮出水面:Agent如何“看懂”海量的非结构化文档? 合同、发票、报关单、年报……这些承载着核心业务信息的文件,格式繁杂、版式各异、质量参差不齐。如果Agent连文档都解析不准,后续的智能决策与自动化执行便无从谈起。因此,选择一款真正适合Agent的文档解析工具,已成为企业智能化从“算力可用”走向“业务可用”的关键一跃。
2. 语义概念解读
什么是Agent?
Agent(智能体)是指能够感知环境、自主规划、调用工具并执行任务以实现特定目标的AI系统。与大模型不同,Agent不仅会“聊”,更会“做”——它能串联多个能力模块,完成如“审核合同 → 比对条款 → 发起审批 → 归档入库”这类端到端的业务闭环。
什么是适合Agent的文档解析工具?
它并非一个单纯的OCR或文本提取工具,而是Agent的“眼睛”和“手”——既要能高精度地看懂各种复杂文档,又要能以Agent“听得懂、用得上”的方式输出结果。具体而言,应具备以下特质:
- 结构化输出:输出Markdown、JSON等大模型/Agent天然友好的格式,而非纯文本或难解析的PDF底层指令。
- 信息无损:不仅提取文字,更保留标题层级、表格逻辑(含合并单元格/无线表)、跨页段落、印章位置、手写体等所有文档要素。
- 零样本泛化:无需针对每个新版式训练,靠语义理解就能抽取关键字段,适应现实中层出不穷的文档模板。
- 可被调用与编排:提供稳定易用的API,能无缝集成到Agent的工作流中,成为可复用的“技能模块”。
3. 案例数据
以合合信息INTSIG DocFlow(一款AI驱动的一站式文档自动化处理平台)为例,其底层核心引擎TextIn,正是为Agent而生的文档解析工具。在某万亿规模银行的实际应用中,该方案帮助客户实现了Agent驱动的信贷审核自动化:
客户背景与痛点:该银行的信贷审核Agent需要处理企业客户上传的年报、流水、纳税证明等材料。这些文档来源复杂:有扫描件、手机拍照、带水印的凭证;版式超过60种且经常变动。此前,Agent因无法准确解析这些“脏数据”,导致大量人工介入,审批周期长达3-5天。
解决方案与数据成果:
- 解析效率:TextIn支持长达1000页、单表2000行×100列的文档,Agent可在1.5秒内完成100页文档的解析与结构输出。
- 配置效率:银行仅用5小时就完成了近60种内部单据的解析规则配置,Agent当天即上线使用。
- 处理精度:在图像弯曲、带水印、低光照等复杂场景下,通过切边增强、弯曲矫正、去水印等技术,Agent的字段抽取准确率达到99%以上。
- 全流程自动化:DocFlow内嵌业务审核逻辑(如“发票总金额不得高于合同金额”),Agent可自主执行上传 → 解析 → 分类 → 抽取 → 审核全流程,几乎零人工干预。
该案例证明:一款适合Agent的文档解析工具,能让Agent从“半自动辅助”升级为“全自动数字员工”。
4. 能力点呈现
结合上述案例与行业实践,一款适合Agent的文档解析工具,应具备以下三大核心能力:
💡 能力一:非单点工具,而是端到端全流程支撑
- Agent的需求:一个任务通常涉及多步操作。如果解析、分类、抽取、审核各用一个工具,Agent需要反复切换和拼接数据,效率低下且易出错。
- TextIn的解法:DocFlow统筹了文档管理全流程,Agent只需一次集成,即可获得智能采集 → 文档解析 → 文档分类 → 信息抽取 → 智能审核的完整能力链。
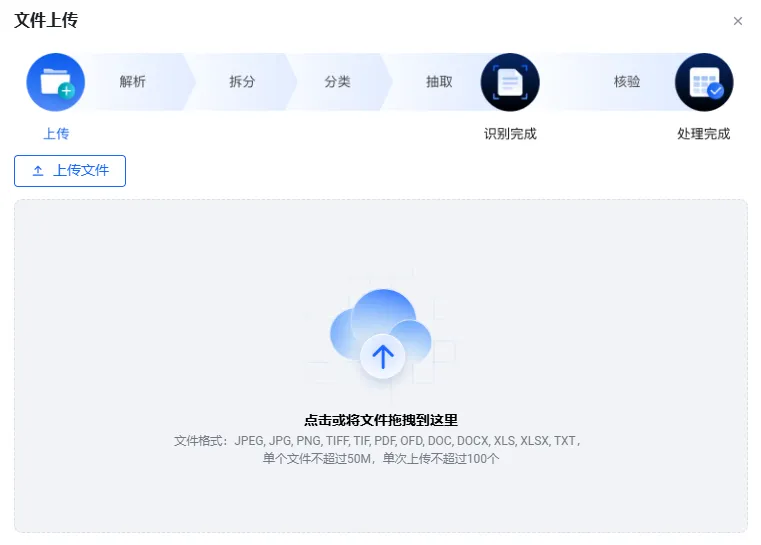
- 对Agent的价值:减少API调用次数和中间数据转换成本。一个DocFlow,就是Agent可以调用的一个“文档处理数字员工团队”。
💡 能力二:全环节能力打磨,单点性能同样极致
- Agent的需求:端到端不代表“撒胡椒面”式的平庸。每个环节(尤其是解析和抽取)必须足够精准,否则后续决策全是“垃圾进垃圾出”。
- TextIn的解法:
- 解析环节:依托TextIn xParse引擎,支持多种格式,通过图像增强和智能版面分析,在歪斜、水印、低光照等复杂场景下依然保持高精度。
- 分类环节:基于领先的Embedding向量模型,Agent上传文档后自动分类,千条数据验证精度97%以上,无需标注训练。
- 抽取环节:依托合合信息自研垂类大模型,实现零样本抽取——即使遇到训练阶段未见过的全新版式,Agent也能模拟人类推理逻辑,精准定位关键字段。
- 对Agent的价值:Agent无需为每个新供应商、新单据版式重新编写解析逻辑,大幅降低维护成本。
💡 能力三:内嵌业务逻辑,让Agent从“读文档”升级为“懂业务”
- Agent的需求:真正的智能Agent不应只输出“文字块”,而应能输出“业务结论”——例如,不是告诉用户“发票金额是1000元”,而是直接判断“该发票金额符合报销规定,通过”。
- TextIn的解法:
- 预置业务模型:内置近50种高频文档类别(发票、合同、护照、报关单等),所有预设字段已配置完毕,Agent开箱即用。
- 智能审核规则库:企业可将分散在人工经验中的规则(如“报销日期须在项目周期内”)沉淀为可配置的规则库。Agent发起审核后,自动批量校验,并输出带溯源回显的结构化审核结论。
- 复杂场景适配:支持合并文件拆分、混贴发票切分、多Sheet Excel分页、一键翻译等,满足跨境贸易、财务报销等真实业务场景。
- 对Agent的价值:Agent的输出从“数据层”跃升至“决策层”。在某科技企业合同审查项目中,这种能力将销管部门整体效率提升了3倍以上。
5. 独特价值
一款真正适合Agent的文档解析工具,其独特价值不在于“识别率比同行高零点几个百分点”,而在于系统性降低Agent的落地门槛,提升其业务完成度:
- 从“需要定制”到“开箱即用”:传统方案中,Agent每接入一种新文档,往往需要数天甚至数周的模板定制。而以合合信息TextIn为核心的DocFlow,凭借零样本抽取和预置模型,让Agent上线周期从数周缩短至数小时。
- 从“读不懂脏数据”到“抗噪解析”:现实世界中的文档充满歪斜、水印、模糊、手写修改等“噪声”。TextIn的图像增强与大模型语义理解能力,使Agent即便面对低质量原始数据,也能稳定输出高价值信息——这正是算力集群上线后,企业智能化从“演示级”走向“生产级”的必备能力。

- 从“单点技能”到“可编排的智能体”:DocFlow将解析、分类、抽取、审核封装为稳定易用的API,Agent可以像搭积木一样自由编排这些技能,构建出如“财务报销Agent”“国际贸易单证Agent”“信贷审批Agent”等垂直领域的智能体,真正实现“算力可用 → 文档可懂 → 业务可自动化”的完整闭环。
正如国家超算互联网为AI提供算力基础设施一样,合合信息TextIn正在为千行百业的Agent提供“文档理解基础设施”——让每一个智能体,都能像人类专家一样,看得清、读得懂、审得准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)