我给Hermes Agent搭了套16人陪审团:踩坑实录、模式选型与务实建议
本文介绍了一个基于多Agent协同的辩论团队系统,旨在解决单Agent评审时的盲区和偏见问题。系统包含16支专业团队,各负责3个细分维度(如安全、合规、前端体验等),通过8种辩论模式(串行、并行、对抗等)进行交叉验证。作者分享了实际应用中的三阶段工作流和五种常见踩坑经验,强调模式选型比团队数量更重要。该系统通过多角色对抗显性化单Agent的隐性盲区,但需注意平台架构类结论需人工验证,且应根据项目类
这周 Kimi 额度刷新了,orchestrator 又能正常跑任务。顺手把前段时间搭的辩论团队系统整理一下,顺便写几条用 MiniMax M2.7 踩出来的经验:能用
/goal就别省,能开xhigh就别用high,旧会话该关就关,产出质量差得不是一点半点。
一、16支辩论团队:不是堆数量,是补盲区
最早搭这套系统的动机很直接:单 Agent 评审代码或者方案,盲区太大。你让一个人格去同时看安全、合规、性能、前端体验、AI 幻觉风险,它 inevitably 会漏掉几个维度,或者在某个它不够熟悉的领域给出过度自信的结论。
我的思路是:既然人做不到全栈精通,那不如拆成专业团队,各司其职,交叉验证。
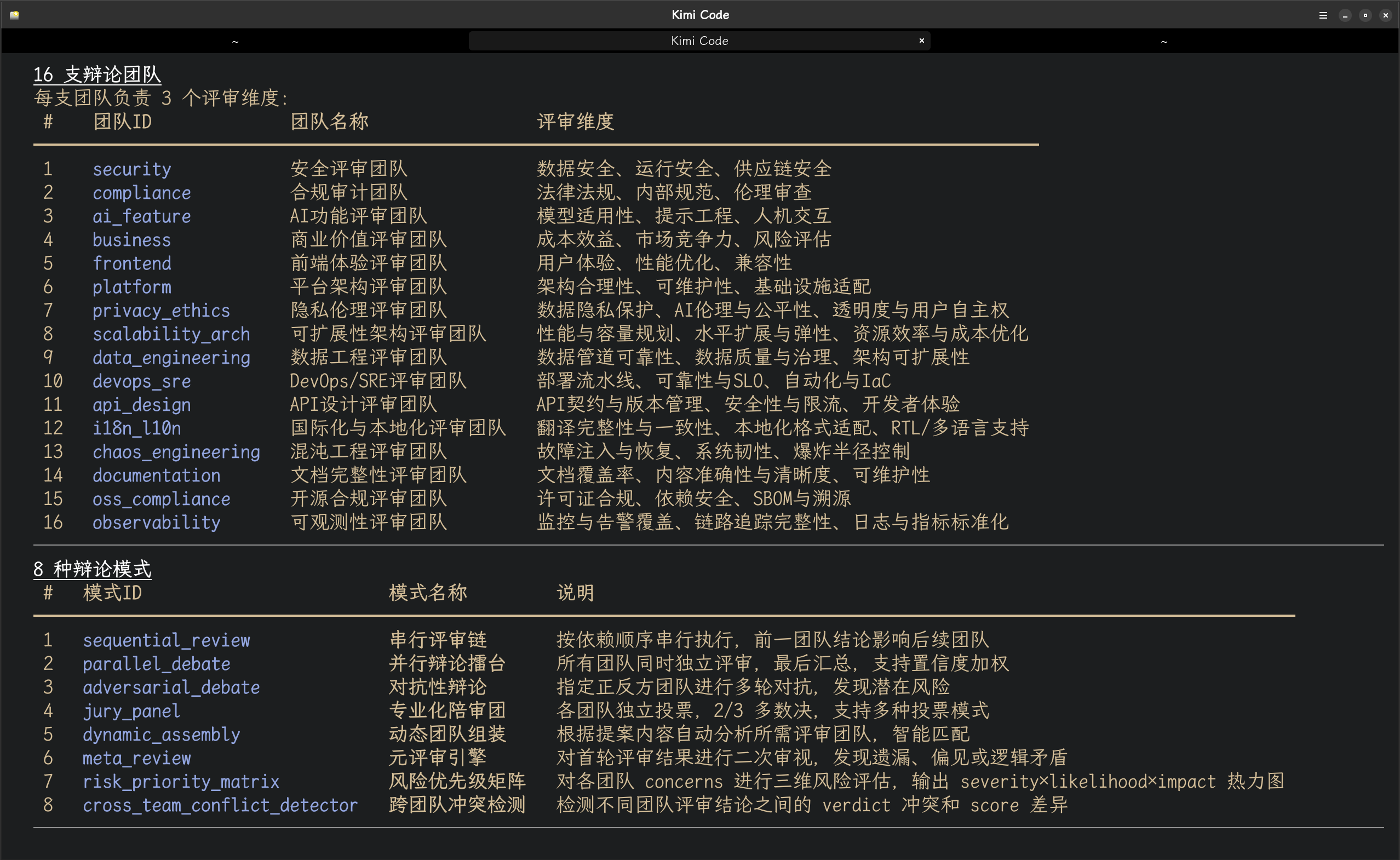
团队构成
目前注册表里挂了 16 支团队,每支负责 3 个细分维度,评审时打三维分数:
|
团队 |
核心职责 |
三个评审维度 |
|---|---|---|
|
security |
安全漏洞、注入、越权 |
数据安全 / 运行安全 / 供应链安全 |
|
compliance |
合规审计 |
法律法规 / 内部规范 / 伦理审查 |
|
data_engineering |
数据质量与治理 |
管道可靠性 / 数据质量 / 架构可扩展性 |
|
devops_sre |
可靠性、监控、灾备 |
部署流水线 / 可靠性与 SLO / 自动化与 IaC |
|
frontend |
前端体验 |
用户体验 / 性能优化 / 兼容性 |
|
ai_feature |
AI 功能正确性 |
模型适用性 / 提示工程 / 人机交互 |
|
scalability_arch |
扩展性与架构解耦 |
性能与容量规划 / 水平扩展 / 资源效率 |
|
chaos_engineering |
混沌测试与韧性 |
故障注入与恢复 / 系统韧性 / 爆炸半径控制 |
|
platform |
平台能力与集成 |
架构合理性 / 可维护性 / 基础设施适配 |
|
privacy_ethics |
隐私伦理与内容审核 |
数据隐私保护 / AI 伦理与公平性 / 透明度 |
|
oss_compliance |
开源许可与依赖 |
许可证合规 / 依赖安全 / SBOM 与溯源 |
|
observability |
可观测性 |
监控与告警覆盖 / 链路追踪 / 日志指标标准化 |
|
business |
商业模型与变现 |
成本效益 / 市场竞争力 / 风险评估 |
|
documentation |
文档完整性 |
文档覆盖率 / 内容准确性 / 可维护性 |
|
api_design |
API 契约与开发者体验 |
API 契约与版本管理 / 安全性与限流 / 开发者体验 |
|
i18n_l10n |
国际化与本地化 |
翻译完整性 / 本地化格式适配 / RTL/多语言支持 |
12个评审维度到团队的映射
实际使用中,不会每次把 16 支团队全拉出来。我按常见的 12 个评审维度做了映射,方便快速组队:
安全 ──────────────→ security
业务逻辑 ──────────→ ai_feature + business
合规 ──────────────→ compliance + oss_compliance
数据质量 ──────────→ data_engineering
SRE / 运维 ────────→ devops_sre + observability
前端体验 ──────────→ frontend
AI 功能 ───────────→ ai_feature
性能成本 ──────────→ scalability_arch + business
测试策略 ──────────→ chaos_engineering
可扩展性 ──────────→ platform + scalability_arch
内容安全 ──────────→ privacy_ethics + security
商业模型 ──────────→ business
这套映射不是死的,你可以根据项目类型动态裁剪。比如一个纯后端微服务,frontend 团队完全可以跳过;一个出海产品,i18n_l10n 团队必须拉进来。
二、8种辩论模式:选型比数量重要
团队搭好了,怎么让他们协同工作?我设计了 8 种辩论引擎,对应不同的评审策略。
模式一览
|
模式 |
核心机制 |
适用场景 |
|---|---|---|
|
sequential_review |
串行链式传递,前一团队的结论影响后续团队 |
有强依赖关系的评审,比如安全团队必须先过,业务团队才能评估影响 |
|
parallel_debate |
所有团队并行独立评审,结果加权汇总 |
时间紧、维度多,需要快速拿到全景图 |
|
adversarial_debate |
指定正反方,多轮交锋 |
技术路线争议大,需要把风险摊开来吵 |
|
jury_panel |
各团队独立投票,2/3 多数决 |
需要明确通过/不通过的决策场景 |
|
dynamic_assembly |
根据提案内容自动匹配所需团队 |
不确定该拉哪些团队时,让系统自己判断 |
|
meta_review |
对首轮评审结果做二次审视 |
怀疑首轮有遗漏或偏见时 |
|
risk_priority_matrix |
三维风险评估(severity × likelihood × impact) |
需要定量排序,决定先修哪个坑 |
|
cross_team_conflict_detector |
检测不同团队结论之间的矛盾 |
多团队评审后,发现 security 说没问题但 compliance 说违规的情况 |
模式选型决策
实际使用时怎么选?我的决策逻辑大概长这样:
开始评审
│
┌───────────┴───────────┐
▼ ▼
有时间压力? 时间充裕?
│ │
是 ───┴─── 否 是 ───┴─── 否
│ │ │ │
▼ ▼ ▼ ▼
parallel sequential adversarial jury_panel
_debate _review _debate
│ │ │ │
└────┬─────┘ └────┬─────┘
▼ ▼
结果有矛盾? 需要量化排序?
│ │
是 ──┴─ 否 是 ──┴─ 否
│ │ │ │
▼ ▼ ▼ ▼
cross_team done risk_priority done
_conflict_ _matrix
detector
三阶段工作流
在实际项目中,我把辩论流程拆成了三个阶段,不是一次性跑完就完事:
Phase 1: 议题辩论(并行)
├── 安全团队评审议题 A
├── 架构团队评审议题 B
└── AI 团队评审议题 C
│
▼
Phase 2: 方案评估辩论(串行或对抗)
├── 汇总 Phase 1 报告
├── 跨团队冲突检测
└── 输出 verdict(IMMEDIATELY_RECOMMENDED / RECOMMENDED /
RECOMMENDED_WITH_MODIFICATIONS / MODIFY / REJECT)
│
▼
Phase 3: 修复执行
├── P0(5分钟内)立即修
├── P1(48小时内)排期修
└── P2/P3 进 backlog
这个流程在茄茄顾问 MVP 的三五八步任务里跑过一次,7 个子任务全部完成,结论有效执行。 verdict 分级我直接抄过来用:
- IMMEDIATELY_RECOMMENDED
:P0,5 分钟能干完,无风险,直接动手
- RECOMMENDED
:收益大于成本,可接受风险
- RECOMMENDED_WITH_MODIFICATIONS
:有问题但能修,改完再执行
- MODIFY
:架构层面有坑,得大改
- REJECT
:风险过高或成本不划算,搁置
三、为什么非要搞这么复杂?单 Agent 不够吗?
不够。至少在我实际用下来,有三个场景单 Agent 会栽跟头。
场景一:领域盲区导致过度自信
让同一个 Agent 同时评审"前端体验"和"供应链安全",它对前者的直觉可能很准,但对后者的判断基本是猜。更危险的是,它不一定会告诉你"这块我不太熟",而是会给你一个看起来有理有据的结论。
辩论团队的设计本质上是在用多角色对抗来逼出这种盲区。security 团队不会惯着 ai_feature 团队,platform 团队也不会让 frontend 团队随便拍板。
场景二:平台架构误判
这是我最痛的一次踩坑。在茄茄顾问小程序的辩论评审中,security 团队把"微信小程序的 request 合法域名配置"理解为"云函数调用的外部 API 需要在微信后台配置域名白名单",直接给了 P0。
实际上:
wx-server-sdk云函数跑在腾讯云基础设施上
-
axios 请求从腾讯云服务器直接发起,不走微信客户端的
wx.request() -
微信的 request 合法域名限制的是前端
wx.request(),跟云函数的 outbound 流量完全没关系
这个问题不是 security 团队不专业,而是辩论天然倾向于枚举所有可能的配置问题,容易把"平台配置的多个入口"混为一谈。安全类团队又有扩大化问题的倾向,不严格区分前端限制和后端限制。
教训:涉及平台网络限制、域名配置、API 准入的 P0 结论,执行前必须验证架构前提——调用来自前端还是后端?平台限制具体作用于哪一层?
场景三:隐性偏见
单 Agent 的输出会受当前会话上下文的影响。如果它在前几轮已经倾向于某个方案,后续评审会逐渐自圆其说,而不是真正挑战前提。meta_review 模式的存在就是为了解决这个问题:让另一组团队专门审视"评审过程本身有没有漏洞"。
四、踩坑实录:这五条能省你半天时间
坑一:simulation adapter 陷阱
辩论团队系统的脚本目录下有一个 LLM 适配器,默认走的是 simulation adapter。这意味着你满怀期待地跑了一遍评审流程,出来的结果是模拟生成的,根本没有调用真实的 LLM。
怎么绕过去?别用 scripts 目录里的执行器。直接在 execute_code 里调 MiniMax API,用标准库的 urllib.request 就行。原因见下一个坑。
坑二:execute_code vs terminal 的环境差异
|
环境 |
API Key 访问 |
auth.json 访问 |
|---|---|---|
execute_code
(本进程 Python) |
os.environ
或 |
✅ 正常 |
terminal
(subprocess) |
TIRITH 过滤掉了环境变量,subprocess 看不见 |
❌ 需额外传参 |
结论:MiniMax API 调用必须在 execute_code 里完成。别在 terminal 里写 curl 脚本,跑不通的。
坑三:子 Agent 的输出路径限制
如果你用 delegate_task 分发子任务,让子 Agent 把结果写到 /media/veracrypt1/... 这类挂载路径,大概率会失败。子 Agent 的 MCP 文件系统权限可能覆盖不到这个路径。
我的 workaround:先让子 Agent 写到 /home/host/ 下某个中转目录,主 Agent 再用 Python 的 shutil.copy2 搬过去。多一步,但稳。
坑四:禁止切换模型(我这里是有 kimi做回馈模型)
在 delegate_task 的 context 里必须明确声明"禁止使用 Kimi 模型"。否则子 Agent 可能根据负载或配置漂移,切到 Kimi 上去执行,输出风格和质量完全不对齐。这不是 Kimi 不好,是多 provider 混用时要保证评审标准一致。
坑五:文档和注册表对不上
SKILL.md 里列了 16 支团队,包括 content_moderation 和 performance,但注册表 debate_registry_template.json 里实际没有这两支,取而代之的是 api_design 和 i18n_l10n。
这不是什么大问题,但如果你写自动化脚本时按文档硬编码团队 ID,会报 key error。建议以注册表为准,文档只做参考。
五、系统架构:怎么拼起来的
整套系统的物理结构不复杂,三个层次:
┌─────────────────────────────────────────┐
│ 调用层 │
│ Hermes Agent / Orchestrator / 手动脚本 │
└──────────────────┬──────────────────────┘
│
┌──────────┴──────────┐
▼ ▼
┌───────────────┐ ┌─────────────────┐
│ 8种辩论引擎 │ │ 16支辩论团队 │
│ (mode selector)│ │ (team registry) │
└───────┬───────┘ └────────┬────────┘
│ │
└──────────┬──────────┘
▼
┌─────────────────────┐
│ LLM 适配器层 │
│ simulation(默认) │ ← 坑在这里
│ direct API(生产) │ ← 实际用这个
└─────────────────────┘
真实评审时,不走 scripts 目录的适配器。直接在 execute_code 里拼 prompt、调 API、收 JSON 结果。并行策略我用的是 2 线程 × 多批次,12 个维度跑下来大概 3-20分钟左右,能接受。
JSON 结果提取时要注意,MiniMax M2.7 有时会返回带 ```json 代码块的响应,有时又会套一层思考标签。建议写一个小的提取函数,优先匹配代码块,fallback 到直接 parse。
六、结语
这套辩论团队系统不是银弹。它的价值不在于"16 个团队听起来很唬人",而在于把单 Agent 的隐性盲区显性化,让你在动手改代码之前,先知道哪些地方可能有雷。
但记住两点:
- 辩论是输入,不是判决
。团队给的 P0 结论,涉及平台架构的,一定要自己验证技术前提。
- 模式选型比团队数量重要
。不是所有项目都需要 16 支团队全上,动态裁剪、按需组队才是正经做法。
如果你也在用 Hermes + MiniMax M2.7,前面提到的 /goal、xhigh、及时切新会话这几条,优先级比这 16 支团队高得多。模型能力拉满之后,辩论系统才是锦上添花。

这里是我正在使用的提示词示例,你可以参考一下
#ai上新

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)