Spring AI ChatMemory 对话记忆配置JDBC方式到Mysql数据库实战示例与原理讲解
本文介绍了SpringAI中对话记忆从内存存储迁移到JDBC持久化的完整方案。通过使用JdbcChatMemoryRepository替代InMemoryChatMemoryRepository,解决了服务重启数据丢失和多实例共享问题。文章详细讲解了MySQL环境准备、建表脚本编写、配置参数说明等实现步骤,并深入分析了JDBC存储的底层原理,包括消息写入机制、数据库表结构设计和索引优化策略。该方案
场景
Spring AI ChatMemory 对话记忆配置指南:概念、实战与常见问题:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161020514
上述示例对话记忆使用内存方式,如何使用JDBC方式将对话记忆到Mysql中。
之前我们使用的 InMemoryChatMemoryRepository 将所有对话历史存储在 JVM 堆内存中,
服务重启后所有会话数据都会丢失,且无法在多个服务实例间共享。
将存储层切换为 JDBC(如 MySQL、PostgreSQL)后,这些痛点可以得到有效解决。
Spring AI 对存储介质做过一次重要的架构演进。早期版本直接提供了 JdbcChatMemory 类。
但在 1.1.0 版本之后,框架采用了更清晰的职责分离设计,
将原先的 JdbcChatMemory 标记为 @Deprecated,
并引入了 MessageWindowChatMemory + JdbcChatMemoryRepository 的组合模式。
这一改动的核心思想是:
存储逻辑(Repository)与内存窗口管理(ChatMemory)彻底解耦,使架构更具扩展性,
也可以更灵活地混合搭配不同的记忆策略与存储后端。
核心知识点
JdbcChatMemoryRepository
JdbcChatMemoryRepository 是 ChatMemoryRepository 接口的 JDBC 实现,它通过 JdbcTemplate 直接与关系型数据库交互,
将消息存储在一张名为 SPRING_AI_CHAT_MEMORY 的约定表中。
它开箱即用地支持 MySQL、PostgreSQL、SQL Server、HSQLDB、H2 等多种数据库。
每个会话由 conversation_id 唯一标识,该组件负责根据此 ID 进行存取操作,框架会自动完成消息的序列化与反序列化。
MessageWindowChatMemory
这是 Spring AI 当前推荐的核心记忆实现,负责维护一个固定大小的消息窗口(可通过 maxMessages 配置)。
当消息数量超过上限时,自动移除旧消息,但会保留系统消息(SystemMessage)。
在 JDBC 持久化场景下,ChatMemory Bean 注入 JdbcChatMemoryRepository 即可实现底层存储切换,
上层的滑动窗口策略完全不变。
MessageChatMemoryAdvisor
作为拦截器层,Advisor 负责在每次请求中自动注入对话历史(从 ChatMemory 中通过 conversation_id 加载),
并在收到模型回复后将新的消息写回存储。
建表脚本与自动初始化
框架约定的表名为 SPRING_AI_CHAT_MEMORY,需要包含以下列
| 列名 | 类型 | 说明 |
|---|---|---|
id |
BIGINT | 主键,自增 |
conversation_id |
VARCHAR(36) | 会话唯一标识 |
content |
TEXT | 消息内容(JSON 序列化) |
type |
VARCHAR(10) | 消息类型(USER / ASSISTANT / SYSTEM / TOOL) |
timestamp |
TIMESTAMP | 消息时间戳 |
框架支持通过配置自动执行建表脚本。
spring.ai.chat.memory.repository.jdbc.initialize-schema 的
可选值包括 always(每次启动都建表)、embedded(仅内嵌数据库自动建表)、never(不自动建表)。
开发环境建议使用 always,生产环境建议使用 never,由 DBA 手动管理表结构。
Spring AI 内置了针对各种数据库的建表 SQL,存放在 org/springframework/ai/chat/memory/jdbc/sql/ 目录下,
框架会根据检测到的数据源类型自动选择对应的脚本。也可以通过 schema 属性指定自定义脚本路径。
架构对比
| 维度 | InMemory | JDBC 持久化 |
|---|---|---|
| 数据生命周期 | 随 JVM 重启丢失 | 持久化到数据库,重启不丢 |
| 跨实例共享 | 不支持 | 支持(多实例共享同一数据库) |
| 内存压力 | 长期运行占用堆内存 | 数据库承担存储压力 |
| 审计与分析 | 不支持 | 可直接查询数据库 |
| 配置复杂度 | 零配置 | 需配置数据源,引入 JDBC 依赖 |
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
MySQL 环境准备
-- 创建数据库
CREATE DATABASE IF NOT EXISTS spring_ai DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;pom.xml
在之前依赖的基础上,移除 InMemoryChatMemoryRepository 的手动配置依赖,新增 JDBC Starter 和 MySQL 驱动:
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<!-- 新增:使用 Spring AI BOM 统一管理所有模块版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Ollama 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- Spring AI JDBC 聊天记忆持久化 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>依赖变化说明:
新增 spring-ai-starter-model-chat-memory-repository-jdbc:
提供 JdbcChatMemoryRepository 的自动配置,包含 spring-ai-autoconfigure-model-chat-memory 和 JDBC 存储实现两个模块。
新增 mysql-connector-j:
MySQL 的 JDBC 驱动(推荐使用新 artifactId mysql-connector-j 而非旧的 mysql-connector-java)。
移除 InMemoryChatMemoryRepository 的显式 Bean 声明:
框架在检测到 JdbcChatMemoryRepository 时,会自动将默认的 InMemoryChatMemoryRepository 替换为 JDBC 实现,
不再需要手动声明。
建表脚本
创建 src/main/resources/sql/schema-mysql.sql:
CREATE TABLE IF NOT EXISTS SPRING_AI_CHAT_MEMORY (
id BIGINT NOT NULL AUTO_INCREMENT,
conversation_id VARCHAR(36) NOT NULL,
content TEXT NOT NULL,
type VARCHAR(10) NOT NULL,
timestamp TIMESTAMP NOT NULL,
PRIMARY KEY (id),
INDEX idx_conv_ts (conversation_id, timestamp),
CONSTRAINT type_check CHECK (type IN ('USER', 'ASSISTANT', 'SYSTEM', 'TOOL'))
);application.yml
server:
port: 886
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url:jdbc:mysql://localhost:3306/spring_ai?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8
username: root
password: 123456 # 替换为实际密码
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2.5:7b-instruct
options:
temperature: 0.7
num-ctx: 4096 # Ollama 上下文窗口大小
chat:
memory:
repository:
jdbc:
initialize-schema: always # 开发环境每次启动都执行建表脚本
schema: classpath:sql/schema-mysql.sql # 自定义建表脚本路径
logging:
level:
org.springframework.ai.chat.client.advisor: DEBUG
org.springframework.jdbc: DEBUG # 可选:查看 SQL 执行日志
配置重点解析:
spring.datasource.*:
标准的 Spring Boot 数据源配置,连接 MySQL 数据库。
spring.ai.chat.memory.repository.jdbc.initialize-schema: always:
每次启动时执行建表脚本(开发环境推荐)。
spring.ai.chat.memory.repository.jdbc.schema:
指定自定义 SQL 脚本的路径,覆盖框架内置的建表脚本。
注意:
如果未指定 schema 属性,框架会自动从 org/springframework/ai/chat/memory/jdbc/sql/ 加载内置的建表脚本,
支持 schema-mysql.sql、schema-postgresql.sql 等。
ChatConfig 配置类
关键变化:不再手动创建 InMemoryChatMemoryRepository,改为注入由 Starter 自动提供的 JdbcChatMemoryRepository。
package com.badao.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatConfig {
@Bean
public ChatMemory chatMemory(JdbcChatMemoryRepository jdbcChatMemoryRepository) {
// 只需将 Repository 替换为 JDBC 实现,窗口策略完全不变
return MessageWindowChatMemory.builder()
.chatMemoryRepository(jdbcChatMemoryRepository)
.maxMessages(20) // 每次最多携带 20 条历史消息
.build();
}
@Bean
public ChatClient chatClient(ChatModel chatModel, ChatMemory chatMemory) {
return ChatClient.builder(chatModel)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
}改造对比:
从 InMemory 到 JDBC,
只需要在 chatMemory Bean 中将构造参数从 new InMemoryChatMemoryRepository() 替换为注入 JdbcChatMemoryRepository,
其余代码和业务逻辑全部不变。
MemoryChatController 控制器
package com.badao.ai.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory; // 导入 ChatMemory 接口
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api")
public class MemoryChatController {
private final ChatClient chatClient;
public MemoryChatController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@PostMapping("/chat/memory")
public ChatResponse chatWithMemory(@RequestBody MemoryChatRequest request) {
String result = chatClient.prompt()
.user(request.message())
.advisors(advisor -> advisor.param(
ChatMemory.CONVERSATION_ID,
request.conversationId()
))
.call()
.content();
return new ChatResponse(200, "success", result);
}
public record MemoryChatRequest(String message, String conversationId) {}
public record ChatResponse(int code, String msg, String data) {}
}测试验证
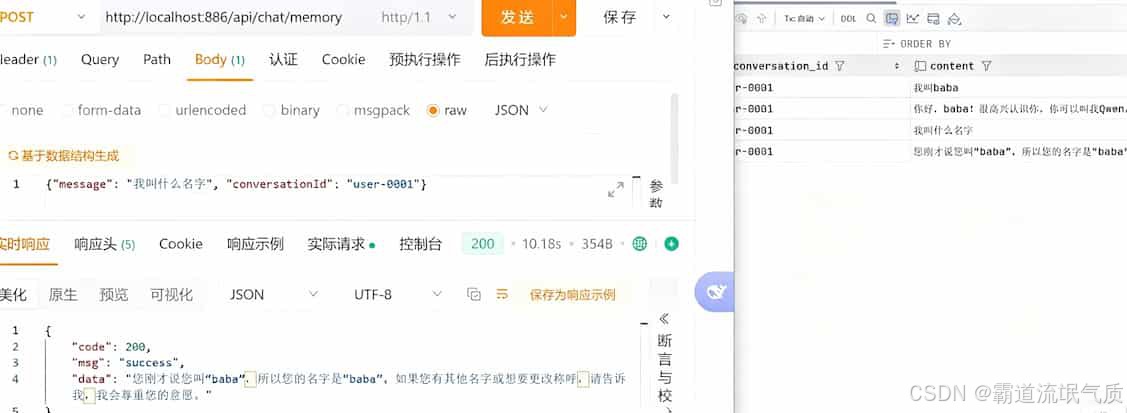
原理深入
1、Spring Boot 自动配置如何发现 JdbcChatMemory 并替换 InMemory?
整个过程由 Spring Boot 的自动配置机制驱动:
依赖触发:
在 pom.xml 中引入 spring-ai-starter-model-chat-memory-repository-jdbc 后,JdbcChatMemoryRepository 类被加入 Classpath。
条件装配:
框架中的 ChatMemoryAutoConfiguration 会检测 Classpath 中是否存在 JdbcChatMemoryRepository。
如果存在且已配置 DataSource,则自动创建一个 JdbcChatMemoryRepository Bean。
Bean 覆盖:
由于存在 JdbcChatMemoryRepository Bean,默认的 InMemoryChatMemoryRepository 自动配置会失效(被条件装配注解跳过)
ChatMemory Bean 直接注入 JdbcChatMemoryRepository,从而实现存储介质的无缝切换。
整个过程无需任何 @ConditionalOnMissingBean 的手动干预,框架已内置完整的条件装配逻辑。
2、JdbcChatMemoryRepository 如何将消息写入 MySQL?
JdbcChatMemoryRepository 的核心实现基于 Spring 的 JdbcTemplate,它直接操作 SPRING_AI_CHAT_MEMORY 表。
一条消息的写入过程如下:
MessageChatMemoryAdvisor 在 AI 返回响应后调用 ChatMemory.add(conversationId, messages)。
MessageWindowChatMemory 收到新消息后,先合并窗口中已有的消息,
再将合并后的完整消息列表通过 JdbcChatMemoryRepository.saveAll(conversationId, messages) 写回数据库。
JdbcChatMemoryRepository.saveAll() 内部采用先删后插策略:
先 DELETE 该会话的所有旧消息,再 INSERT 全部新消息。
这种“全量替换”策略的好处是避免并发场景下的增量同步困难,同时配合自增主键保证原子性。
查询消息时,findByConversationId() 会按 timestamp 升序排列所有消息,
再由 MessageWindowChatMemory 截取最近 maxMessages 条注入到 Prompt 中。
3、数据库表结构与索引设计
框架约定的表结构如下:
CREATE TABLE IF NOT EXISTS SPRING_AI_CHAT_MEMORY (
id BIGINT NOT NULL AUTO_INCREMENT,
conversation_id VARCHAR(36) NOT NULL,
content TEXT NOT NULL,
type VARCHAR(10) NOT NULL,
timestamp TIMESTAMP NOT NULL,
PRIMARY KEY (id),
INDEX idx_conv_ts (conversation_id, timestamp),
CONSTRAINT type_check CHECK (type IN ('USER', 'ASSISTANT', 'SYSTEM', 'TOOL'))
);索引设计分析:
联合索引 idx_conv_ts (conversation_id, timestamp) 覆盖了 findByConversationId() 的查询模式
(WHERE conversation_id = ? ORDER BY timestamp),形成覆盖索引,查询性能极高,无需回表。
时间类型选择说明:
TIMESTAMP 类型能自动记录消息写入时的精确时间,相比 DATETIME 更紧凑(4 字节 vs 8 字节),
且受数据库时区设置影响,适合追踪消息时序。
序列化格式说明:
content 列存储的是消息的 JSON 序列化字符串。
Spring AI 使用 Jackson 将 Message 对象序列化为 JSON,包含消息文本、元数据(如 Token 使用量、模型名称)等完整信息,
直接以 TEXT 类型存储。
4、滑动窗口如何与数据库配合?
MessageWindowChatMemory 在 get() 时只从数据库中取最近 maxMessages 条消息,而非全部加载。
SQL 查询层面按 timestamp 升序排列,再在 Java 层截断。
这保证了即使某次对话积累了成千上万条消息,每次调用 AI 时仍然只携带可控数量的上下文。
数据库中的旧消息不会被删除,可随时通过直接查询表来获取完整的对话历史。
5、ChatMemory 配置最佳实践
| 配置项 | 说明 | 生产环境推荐值 |
|---|---|---|
maxMessages |
记忆窗口大小 | 10-20 条,视模型上下文窗口而定 |
initialize-schema |
建表策略 | never(由 DBA 通过 Flyway/Liquibase 管理) |
schema |
自定义脚本路径 | classpath:sql/schema-mysql.sql(版本化管理) |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)