LangGraph 生产级部署全解:FastAPI + Docker
按照这个方案部署后,你的 LangGraph Agent 系统就具备了生产级的稳定性、可扩展性和可维护性,可以安全地对外提供服务。
·
一、部署架构总览
我们将基于你之前的带人工干预的双智能体系统,构建一个完整的生产级部署方案,包含三个核心部分:
- FastAPI 接口层:封装 Agent 为标准 HTTP 接口,支持任务启动、人工干预、状态查询
- Redis 持久化层:替代 MemorySaver,实现状态持久化和服务重启恢复
- Docker 容器化:打包整个应用为镜像,实现一键部署和环境一致性
标准部署架构图
plaintext
客户端 → FastAPI 接口 → LangGraph Agent → Redis(状态持久化)二、第一步:项目结构标准化
先将你的代码整理为生产级项目结构:
plaintext
langgraph-agent-deploy/
├── agent/ # Agent核心逻辑
│ ├── __init__.py
│ ├── multi_agent.py # 双智能体系统代码
│ └── state.py # 状态定义
├── main.py # FastAPI入口
├── requirements.txt # 依赖清单
├── Dockerfile # 镜像构建文件
├── docker-compose.yml # 服务编排
└── .env # 环境变量配置三、第二步:FastAPI 接口封装
3.1 核心依赖安装
bash
运行
pip install fastapi uvicorn python-multipart langgraph-checkpoint-redis
3.2 完整 FastAPI 代码
# main.py
import asyncio
import traceback
from typing import Optional
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from langgraph.types import Command, interrupt
from pydantic import BaseModel
from agent.multi_agent import build_multi_agent_system
from agent.state import MultiAgentState
# 初始化FastAPI
app = FastAPI(title="LangGraph 双智能体写作系统 API", version="1.0.0", description="Language Graph Agent")
# 配置CORS 允许前端跨域访问
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境改为具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 初始化 Agent 系统 (全局单例,避免重复初始化)
agent = build_multi_agent_system()
# 请求响应模型
class StartTaskRequest(BaseModel):
thread_id: str
task: str
topic: str
class ResumeTaskRequest(BaseModel):
thread_id: str
human_input: str
class TaskStatusResponse(BaseModel):
thread_id: str
status: str # running interrupted completed failed
current_step: Optional[str] = None
interrupt_info: Optional[dict] = None
final_article: Optional[str] = None
error: Optional[str] = None
# 核心接口
@app.post("/api/task/start", response_model=TaskStatusResponse)
async def start_task(request: StartTaskRequest):
"""启动一个新的写作任务"""
try:
config = {"configurable" : {"thread_id": request.thread_id}}
# 初始化任务状态
initial_state: MultiAgentState = {
"task": request.task,
"topic": request.topic,
"research_notes": "",
"draft": "",
"final_article": "",
"current_agent": "researcher",
"turn_count": 0,
"max_turns": 5,
"messages": [],
"error": None,
"human_feedback": ""
}
# 异步执行Agent 避免阻塞事件循环
result = await asyncio.to_thread(
agent.invoke,
initial_state,
config
)
# 构建响应
return await _build_status_response(request.thread_id, result)
except Exception as e:
print(f"❌ 详细错误:\n{traceback.format_exc()}") # 打印完整堆栈
raise HTTPException(status_code=500, detail=f'任务启动失败:{str(e)}')
@app.post("/api/task/resume", response_model=TaskStatusResponse)
async def resume_task(request: ResumeTaskRequest):
"""恢复被中断的任务,传入人类反馈"""
try:
config = {"configurable" : {"thread_id": request.thread_id}}
# 用Command 恢复执行
result = await asyncio.to_thread(
agent.invoke,
Command(resume=request.human_input),
config=config
)
return await _build_status_response(request.thread_id, result)
except Exception as e:
print(f"❌ 详细错误:\n{traceback.format_exc()}") # 打印完整堆栈
raise HTTPException(status_code=500, detail=f"任务恢复失败{str(e)}")
@app.get("/api/task/status/{thread_id}", response_model=TaskStatusResponse)
async def get_task_status(thread_id: str):
"""查询任务当前状态"""
try:
config = {"configurable" : {"thread_id": thread_id}}
#获取最新状态
state = await asyncio.to_thread(agent.get_state, config)
result = state.values
# 检查是否有中断(从 tasks 获取)
if state.tasks:
# 有待处理的任务,说明被中断了
task = state.tasks[0]
if hasattr(task, 'interrupts') and task.interrupts:
interrupt_info = task.interrupts[0].value
return TaskStatusResponse(
thread_id=thread_id,
status="interrupt",
current_step=interrupt_info.get("type"),
interrupt_info=interrupt_info,
error=interrupt_info.get("error"),
)
return await _build_status_response(thread_id, result)
except Exception as e:
print(f"❌ 详细错误:\n{traceback.format_exc()}") # 打印完整堆栈
raise HTTPException(status_code=500, detail=f"状态查询失败:{str(e)}")
# 辅助函数
async def _build_status_response(thread_id: str, result: dict) -> TaskStatusResponse:
"""构建统一的响应状态"""
# 检查是否有中断
if "__interrupt" in result:
interrupt_info = result["__interrupt"][0].value
return TaskStatusResponse(
thread_id=thread_id,
status="interrupt",
current_step=interrupt_info.get("type"),
interrupt_info=interrupt_info,
error=interrupt_info.get("error"),
)
# 检查是否完整
if result.get("final_article"):
return TaskStatusResponse(
thread_id=thread_id,
status="completed",
final_article=result["final_article"],
error=result.get("error"),
)
# 检查是否出错
if result.get("error"):
return TaskStatusResponse(
thread_id=thread_id,
status="failed",
error=result["error"],
)
# 运行中
return TaskStatusResponse(
thread_id=thread_id,
status="running",
current_step=result.get("current_agent"),
error=result.get("error")
)
# 启动服务
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)3.3 修改 Agent 代码,使用 Redis 持久化
将之前的MemorySaver替换为RedisSaver,实现状态持久化:
# agent/multi_agent.py
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", message=".*InsecureKeyLengthWarning.*")
from typing import Literal
from dotenv import load_dotenv
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage
from langchain_core.prompts import ChatPromptTemplate
from langgraph.constants import START, END
from langgraph.checkpoint.redis import RedisSaver
from langgraph.graph import StateGraph
from langgraph.types import interrupt
from pydantic_settings import BaseSettings, SettingsConfigDict
from agent.state import MultiAgentState
# 加载环境变量
load_dotenv()
class Settings(BaseSettings):
ZHIPU_API_KEY: str
ZHIPU_BASE_URL: str
LLM_MODEL: str
LLM_BACKUP_MODEL: str
LLM_TIMEOUT: int=600
MAX_TURNS: int=3
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore"
)
settings = Settings()
# 初始化LLM
llm = ChatZhipuAI(
api_key=settings.ZHIPU_API_KEY,
model=settings.LLM_BACKUP_MODEL,
temperature=0.7
)
# 智能体1:研究员(带人工确认)
def create_researcher_agent():
researcher_prompt = ChatPromptTemplate.from_messages([
("system", """
你是专业的资深研究员,擅长围绕特定主题收集、整理、提炼准确、全面的资料。
如果有人类提供的反馈,请优先根据反馈补充或修改研究笔记。
"""),
("human", """
写作任务:{task}
写作主题:{topic}
人类反馈:{human_feedback}
请提供详细的结构化研究笔记。"""
)
])
def researcher_node(state: MultiAgentState):
print("\n-- 🔬 研究员开始工作 --")
try:
# 调用LLM生成研究员笔记
response = llm.invoke(researcher_prompt.format(
task=state["task"],
topic=state["topic"],
human_feedback=state.get("human_feedback", "无")
))
research_notes = response.content
print("✅️ 研究员完成研究笔记")
except Exception as e:
print(f"❌️ 研究员工作失败:{str(e)}")
return {
"error": str(e),
"turn_count": state["turn_count"] + 1,
}
# ✅️ 关键:出发人工干预 等待人类确认
print("\n-- 🔄 等待人类确认研究笔记...")
human_approval = interrupt({
"type": "research_approval",
"topic": state["topic"],
"research_notes": research_notes,
"prompt": "请确认研究笔记是否合格?输入'通过'继续,或输入意见让研究院补充:"
})
# 当人类输入后,代码从这里继续执行
print(f"\n 📝收到人类反馈:{human_approval}")
# 如果人类输入“通过”,进入下一步
if human_approval.strip() == "通过":
return {
"research_notes": research_notes,
"current_agent": "writer",
"turn_count": state["turn_count"] + 1,
"human_feedback": "",
"messages": [AIMessage(content=f"研究员已完成研究笔记:\n{research_notes}")]
}
# 否则,研究员根据人类反馈修改研究笔记
else:
print(f'🔄 研究员根据人类反馈修改研究笔记...')
return {
"human_feedback": human_approval,
"turn_count": state["turn_count"] + 1,
"current_agent": "researcher", # 回到研究员节点,重新生成
}
builder = StateGraph(MultiAgentState)
builder.add_node("researcher", researcher_node)
builder.set_entry_point("researcher")
return builder.compile()
# 智能体2: 作家 带人工审核
def create_writer_agent():
writer_prompt = ChatPromptTemplate.from_messages([
("system", """
你是专业的资深作家,擅长基于研究员提供的资料,创作高质量、结构清晰、语言流畅的文章。
如果有人类提供的修改意见,请优先根据意见修改文章。
"""),
("human", """
写作任务:{task}
写作主题:{topic}
研究笔记:{research_notes}
人类修改意见:{human_feedback}
请写一篇完整的文章初稿。""")
])
def writer_node(state: MultiAgentState):
print("\n-- ✍️ 作家开始工作 --")
try:
# 调用LLM生成初稿
response = llm.invoke(writer_prompt.format(
task=state["task"],
topic=state["topic"],
research_notes=state["research_notes"],
human_feedback=state.get("human_feedback", "无")
))
draft = response.content
print("✅️ 作家完成文章初稿")
except Exception as e:
print(f"❌️ 作家工作失败:{str(e)}")
return {
"error": str(e),
"turn_count": state["turn_count"] + 1,
}
# ✅️ 关键:出发人工干预,等待人类审核
print("\n 🔄 等待人类审核文章初稿...")
human_approval = interrupt({
"type": "writer_approval",
"topic": state["topic"],
"draft": draft,
"prompt": "请审核文章初稿:输入'通过' 生成最终文章,或输入修改意见让作家修改:"
})
# 人类输入后继续执行
print(f"\n 📝 收到人类审核意见:{human_approval}")
if human_approval.strip() == "通过":
return {
"draft": draft,
"current_agent": "finalize",
"turn_count": state["turn_count"] + 1,
"human_feedback": "",
"messages": [AIMessage(content=f"作家已完成文章初稿:\n{draft}")]
}
else:
print("🔄 作家根据人类意见修改文章")
return {
"human_feedback": human_approval,
"turn_count": state["turn_count"] + 1,
"current_agent": "writer", # 回到作家起点 重新生成
}
builder = StateGraph(MultiAgentState)
builder.add_node("writer", writer_node)
builder.set_entry_point("writer")
return builder.compile()
def build_multi_agent_system():
researcher_agent = create_researcher_agent()
writer_agent = create_writer_agent()
builder = StateGraph(MultiAgentState)
# 把子图作为节点加入主图
builder.add_node("researcher", researcher_agent)
builder.add_node("writer", writer_agent)
# 最终汇成总节点
def finalize_node(state: MultiAgentState):
print("\n-- 🎉 任务完成 生成最终文章 --")
return {
"final_article": state["draft"],
"messages": [AIMessage(content=f"最终文章:\n{state['draft']}")],
}
builder.add_node("finalize", finalize_node)
# 条件路由
def router(state: MultiAgentState) -> Literal["researcher", "writer", "finalize", "end"]:
if state.get("error"):
print(f"❌️ 系统出错:{state['error']}, 任务结束")
return "end"
if state.get("turn_count") >= state["max_turns"]:
print("⚠️ 超过最大交互轮次,强制结束任务")
return "finalize"
current_agent = state["current_agent"]
if current_agent == "researcher":
return "researcher"
elif current_agent == "writer":
return "writer"
elif current_agent == "finalize":
return "finalize"
else:
return "finalize"
builder.add_edge(START, "researcher")
builder.add_conditional_edges(
"researcher",
router,
{
"writer": "writer",
"finalize": "finalize",
"end": END
}
)
builder.add_conditional_edges(
"writer",
router,
{
"researcher": "researcher",
"finalize": "finalize",
"end": END
}
)
builder.add_edge("finalize", END)
# 从环境变量获取Redis连接地址
checkpointer = RedisSaver("redis://localhost:6379/0")
checkpointer.setup()
return builder.compile(checkpointer=checkpointer)state.py
from typing import TypedDict, Literal, Annotated, Sequence
from langchain_core.messages import BaseMessage
from langgraph.graph import add_messages
# 全局状态定义
class MultiAgentState(TypedDict):
task: str
topic: str
research_notes: str
draft: str
final_article: str
current_agent: Literal["researcher", "writer", "human"]
turn_count: int
max_turns: int
messages: Annotated[Sequence[BaseMessage], add_messages]
error: str | None
human_feedback: str # ✅️ 新增: 存储人类反馈四、第三步:Docker 容器化
4.1 编写 requirements.txt
# requirements.txt
fastapi==0.115.0
uvicorn==0.30.6
python-multipart==0.0.12
langgraph==0.2.39
langchain==0.2.16
langchain-openai==0.1.25
pydantic-settings==2.5.2
python-dotenv==1.0.1
langgraph-checkpoint-redis==1.0.11
redis==5.2.14.2 编写 Dockerfile(多阶段构建,优化镜像体积)
dockerfile
# Dockerfile
# 第一阶段:构建阶段
FROM python:3.11-slim AS builder
# 设置工作目录
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
&& rm -rf /var/lib/apt/lists/*
# 创建虚拟环境
RUN python -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# 复制依赖文件并安装
COPY requirements.txt .
RUN pip install --no-cache-dir --upgrade pip \
&& pip install --no-cache-dir -r requirements.txt
# 第二阶段:运行阶段
FROM python:3.11-slim
# 设置工作目录
WORKDIR /app
# 复制虚拟环境
COPY --from=builder /opt/venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# 创建非root用户,增强安全性
RUN useradd -m appuser
USER appuser
# 复制应用代码
COPY --chown=appuser:appuser . .
# 暴露端口
EXPOSE 8000
# 启动命令
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4"]
4.3 编写 docker-compose.yml
yaml
# docker-compose.yml
version: '3.8'
volumes:
redis-data:
driver: local
services:
# Redis服务:状态持久化
redis:
image: redis:7-alpine
container_name: langgraph-redis
restart: unless-stopped
ports:
- "6379:6379"
volumes:
- redis-data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 1s
retries: 5
# LangGraph Agent API服务
langgraph-agent:
build: .
container_name: langgraph-agent
restart: unless-stopped
ports:
- "8000:8000"
depends_on:
redis:
condition: service_healthy
env_file:
- .env
environment:
- REDIS_URI=redis://redis:6379/0
- PYTHONUNBUFFERED=1 # 禁用Python输出缓冲,确保日志实时显示
4.4 编写 .env 配置文件
env
# .env
# 智谱API配置
ZHIPU_API_KEY=你的智谱API密钥
ZHIPU_BASE_URL=https://open.bigmodel.cn/api/paas/v4
LLM_MODEL=glm-4.6
LLM_BACKUP_MODEL=glm-4-flash
LLM_TIMEOUT=30
# Redis配置(docker-compose中会覆盖这个值)
REDIS_URI=redis://localhost:6379/0五、第四步:部署与运行
5.1 一键启动所有服务
# 构建镜像并启动服务
docker-compose up -d --build
# 查看服务状态
docker-compose ps
# 查看日志
docker-compose logs -f langgraph-agent
5.2 测试 API 接口
1. 启动任务
curl -X POST http://localhost:8000/api/task/start \
-H "Content-Type: application/json" \
-d '{
"thread_id": "test_task_001",
"task": "写一篇关于LangGraph多智能体系统的技术文章",
"topic": "LangGraph多智能体系统的原理、架构与实现"
}'
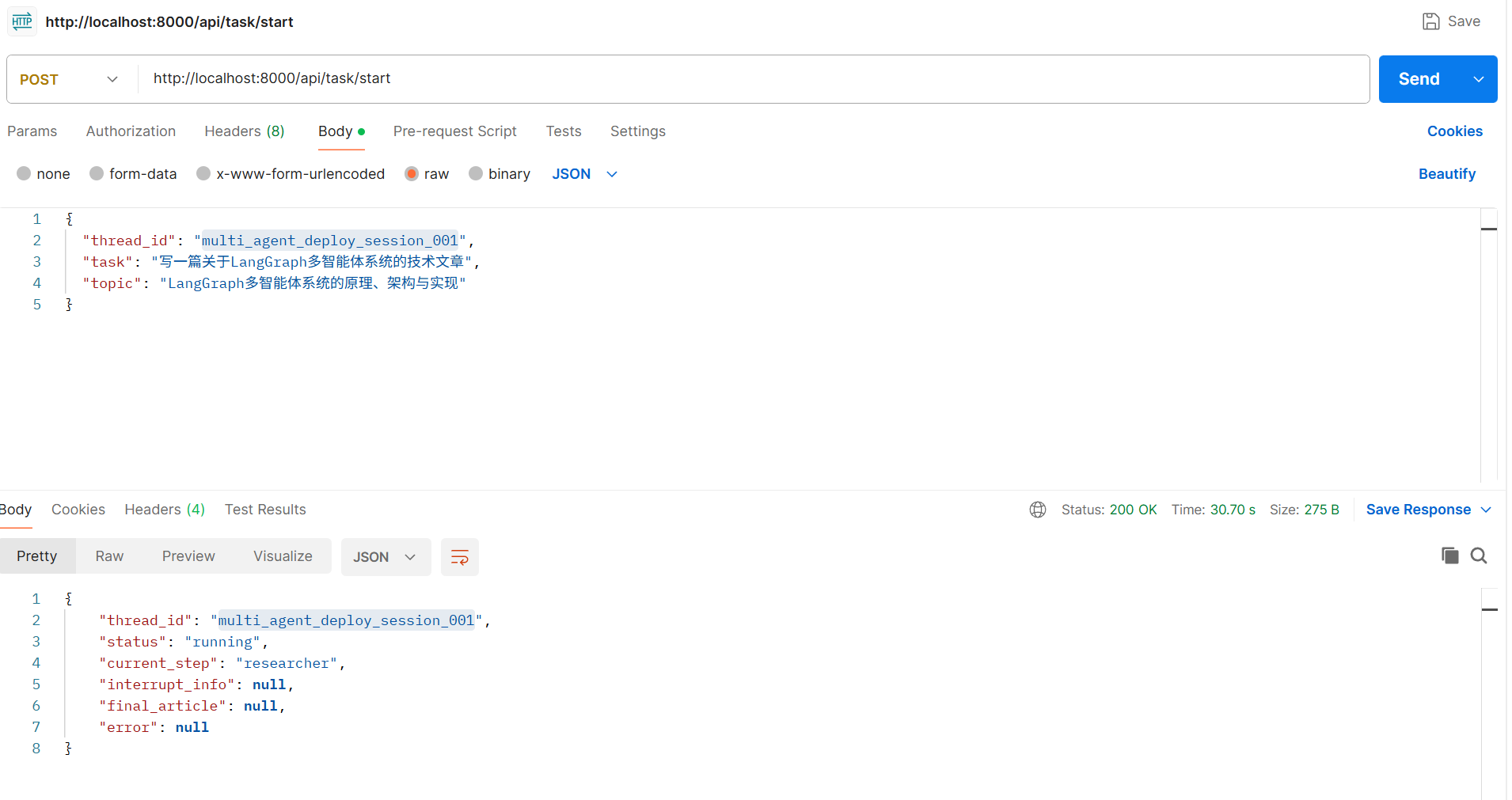
2. 查询任务状态
bash
curl http://localhost:8000/api/task/status/test_task_001
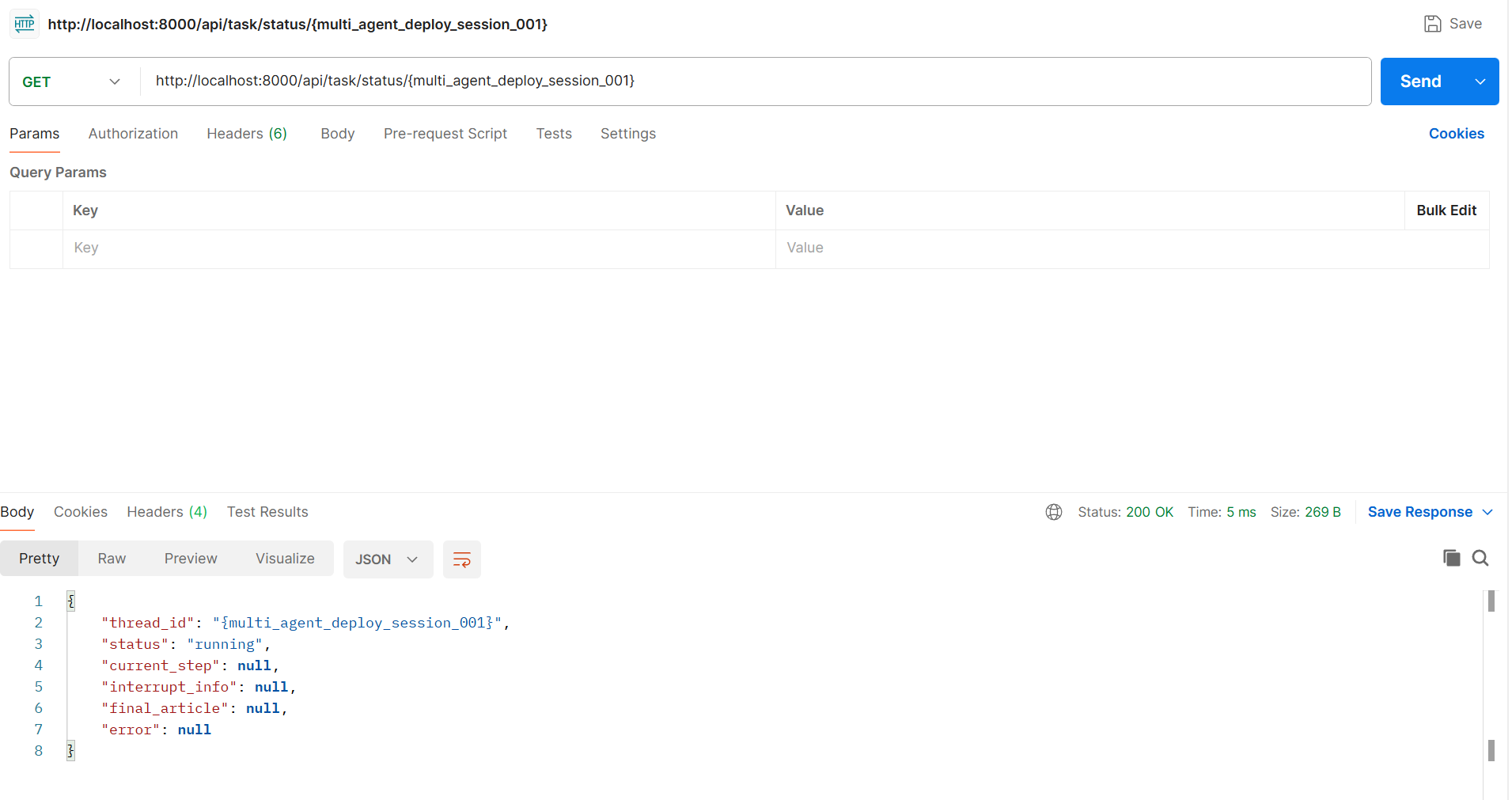
3. 恢复中断任务(当任务等待人工确认时)
bash
curl -X POST http://localhost:8000/api/task/resume \
-H "Content-Type: application/json" \
-d '{
"thread_id": "test_task_001",
"human_input": "通过"
}'
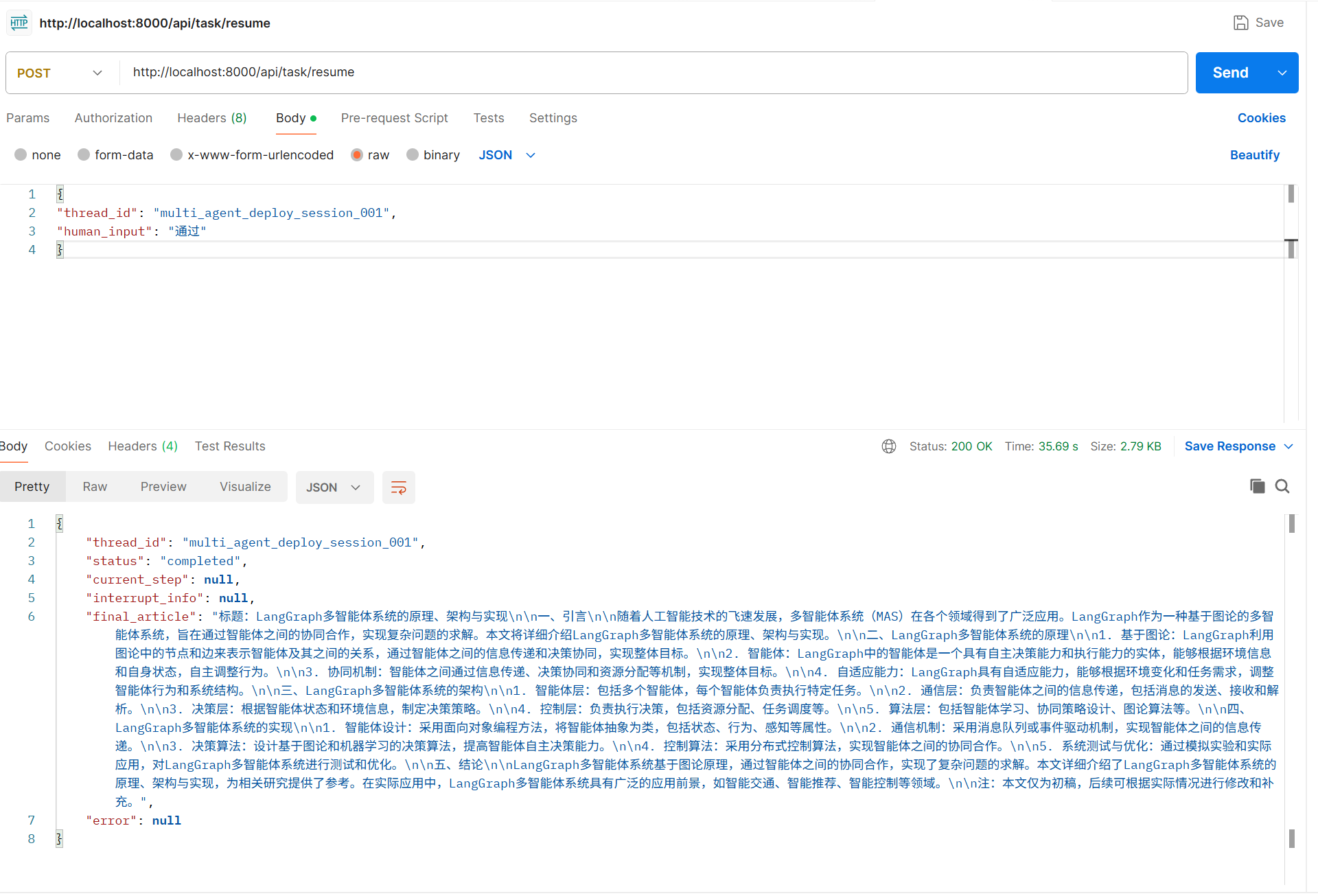
4. 访问自动生成的 API 文档
- Swagger UI:http://localhost:8000/docs
- ReDoc:http://localhost:8000/redoc
六、生产环境优化最佳实践
6.1 性能优化
- 增加 Worker 进程数:在 Dockerfile 的 CMD 中调整
--workers参数,通常设置为 CPU 核心数的 2-4 倍 - 使用 Gunicorn + Uvicorn:生产环境推荐用 Gunicorn 管理 Uvicorn Worker,提高并发能力
dockerfile
CMD ["gunicorn", "main:app", "-w", "4", "-k", "uvicorn.workers.UvicornWorker", "-b", "0.0.0.0:8000"] - 添加 Nginx 反向代理:处理静态资源、SSL 终止、负载均衡
6.2 安全优化
- 限制 CORS 来源:将
allow_origins=["*"]改为具体的前端域名 - 添加 API 密钥认证:给接口添加 API 密钥验证,防止未授权访问
- 使用 Docker Secrets:生产环境不要用.env 文件存储敏感信息,改用 Docker Secrets 或 Kubernetes Secrets
- 定期更新基础镜像:及时修复安全漏洞
6.3 可观测性
- 添加日志配置:配置结构化日志,方便日志收集和分析
- 添加健康检查接口:
python
@app.get("/health") async def health_check(): return {"status": "healthy", "timestamp": datetime.now().isoformat()} - 集成监控系统:用 Prometheus + Grafana 监控服务指标
6.4 高可用部署
- 多实例部署:启动多个 Agent 实例,用 Nginx 或 Kubernetes 进行负载均衡
- Redis 集群:生产环境使用 Redis 集群,保证数据高可用
- 自动扩缩容:根据请求量自动调整实例数量
七、常见问题排查
- Redis 连接失败:检查 docker-compose 中的 Redis 服务是否正常启动,REDIS_URI 是否正确
- 接口超时:增加 Uvicorn 的超时时间,或优化 Agent 执行逻辑
- 状态丢失:确保使用了 RedisSaver,并且 Redis 数据卷配置正确
- 镜像体积过大:使用多阶段构建,删除不必要的依赖和文件
按照这个方案部署后,你的 LangGraph Agent 系统就具备了生产级的稳定性、可扩展性和可维护性,可以安全地对外提供服务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)